爆肝整理!堪稱全網最詳細的十大常用經典排序演算法總結!!!
寫在開頭,本文經過參考多方資料整理而成,全部參考目錄會附在文章末尾,很多略有爭議性的細節都是在不斷查閱相關資料后總結的,具有一定普適性,
總表:
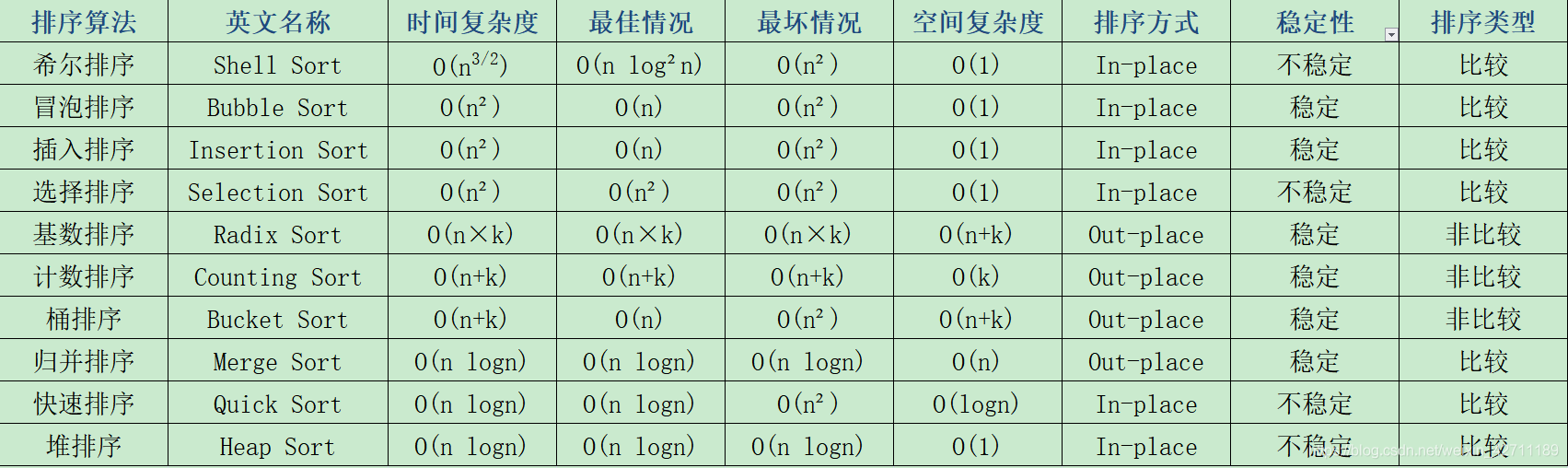
相關解釋:
穩定:如果原本序列中a在b前面且a=b,排序后a仍在b前面,順序不變;
不穩定:如果原本序列中a在b前面且a=b,排序后a可能在b后面,順序可能發生改變;
內排序:所有排序操作均在記憶體中完成;
外排序:由于資料量太大,將其放入磁盤中,排序程序中需要磁盤與記憶體之間的資料傳輸;
時間復雜度:一個排序演算法在執行程序中所耗費的時間量級的度量;
空間復雜度:一個排序演算法在運行程序中臨時占用存盤空間大小的度量;
附加:
本表格已上傳至個人資源,并設定了1積分下載(歡迎支持啦!!),有需要的朋友可以自取;
該表格已同步上傳至網盤,附網盤下載鏈接:
鏈接:https://pan.baidu.com/s/1Ov7yFpZnbQy1cf_fBCGyEA
提取碼:p400
規律性記憶:
歸納總結:
1. 穩定性記憶方法——“快希選堆”不穩定,
2. 需要使用額外空間的四種排序——基數、計數、桶排、歸并,
3. 常用時間復雜度大小關系:O(1)<O(logn)<O(n)<O(n logn)<O(n2)<O(n3)<O(2^n)<O(n!)<O(n^n),
4. 空間復雜度為O(1) 的排序:冒泡、插入、選擇、希爾、堆排;
5. 時間復雜度最優情況可達O(n)的排序:冒泡、插入、桶排;
6. 最優、平均、最差時間復雜度一致的排序:選擇、堆排、歸并、基數、計數;
7. 最差情況下時間復雜度仍為O(n logn)的排序:堆排、歸并;
8. 最差情況下時間復雜度仍在線性時間范圍內的排序:計數;
排序方法選取規則:
1. 如果待排序列中資料含有大量重復值——優先使用計數排序;
2. 如果待排序列中資料近乎有序——優先使用插入排序;
3. 如果待排序列中資料取值范圍有限——優先使用計數排序;
4. 如果待排序列中資料要求穩定——優先使用歸并排序;
5. 如果待排序列需要使用鏈表——優先鏈表歸并、鏈表快排;
6. 如果待排序列中資料無法全部裝到記憶體——優先使用外部排序;
十大排序演算法詳解:
一、冒泡排序(Bubble Sort)
遍歷所有的資料,每次對相鄰元素進行兩兩比較,如果順序和預先規定的順序不一致,則進行位置交換;這樣一次遍歷會將最大或最小的資料上浮到頂端,之后再重復同樣的操作,直到所有的資料有序,資料是反序時,耗費時間最長O(n2);資料是正序時,耗費時間最短O(n),
平均時間復雜度為O(n2),空間復雜度為O(1),是一種穩定的排序演算法,
附演算法實作原始碼:
//冒泡排序
template <class T>
void BubbleSort(T data[],int n)
{
int flag=0;
for(int i=0;i<n;i++)
{
flag=0;
for(int j=1;j<n-i;j++)
{
if(data[j]<data[j-1])
{
flag=1;
T t=data[j];
data[j]=data[j-1];
data[j-1]=t;
}
}
if(flag==0)
return;
}
}二、快速排序(Quick Sort)
快速排序采用分治法,首先從數列中挑出一個元素作為中間值,依次遍歷資料,所有比中間值小的元素放在左邊,所有比中間值大的元素放在右邊,然后按此方法對左右兩個子序列分別進行遞回操作,直到所有資料有序,最理想的情況是,每次劃分所選擇的中間數恰好將當前序列幾乎等分(均勻排布),整個演算法的時間復雜度為O(n logn), 最壞的情況是,每次所選的中間數是當前序列中的最大或最小元素(正序和逆序都是最壞),整個排序演算法的時間復雜度為O(n2),
平均時間復雜度為O(n logn),空間復雜度為O(logn),是一種不穩定的排序演算法,
附演算法實作原始碼:
//快速排序
template <class T>
int Partition(T data[],int left,int right)
{
T pivot=data[left];
while(left<right)
{
while(left<right&&data[right]>pivot)
right--;
data[left]=data[right];
while(left<right&&data[right]<=pivot)
left++;
data[right]=data[left];
}
data[left]=pivot;
return left;
}
template <class T>
void QuickSort(T data[],int left,int right)
{
if(left<right)
{
int p=Partition(data,left,right);
QuickSort(data,left,p-1);
QuickSort(data,p+1,right);
}
}
三、選擇排序(Selection Sort)
遍歷所有資料,先在資料中找出最大或最小的元素,放到序列的起始;然后再從余下的資料中繼續尋找最大或最小的元素,依次放到序列中直到所有資料有序,原始資料的排列順序不會影響程式耗費時間O(n2),相對費時,不適合大量資料排序,
平均時間復雜度為O(n2),空間復雜度為O(1),是一種不穩定的排序演算法,
附演算法實作原始碼:
//選擇排序
template <class T>
void SelectionSort(T data[],int n)
{
for(int i=1;i<n;i++)
{
int k=i-1;
for(int j=i;j<n;j++)
{
if(data[j]<data[k])
{
k=j;
}
}
if(k!=i-1)
{
T t=data[k];
data[k]=data[i-1];
data[i-1]=t;
}
}
}
四、插入排序(Insertion Sort)
將前i個(初始為1)資料假定為有序序列,依次遍歷資料,將當前資料插入到前述有序序列的適當位置,形成前i+1個有序序列,依次遍歷完所有資料,直至序列中所有資料有序,資料是反序時,耗費時間最長O(n2);資料是正序時,耗費時間最短O(n),適用于部分資料已經排好的少量資料排序,
平均時間復雜度為O(n2),空間復雜度為O(1),是一種穩定的排序演算法,
附演算法實作原始碼(直接插入+折半插入):
//直接插入排序
template <class T>
void InsertionSort(T Data[],int n)
{
int p,i;
for(p=1;p<n;p++)
{
T temp=Data[p];
i=p-1;
while(i>=0&&Data[i]>temp)
{
Data[i+1]=Data[i];
i--;
}
Data[i+1]=temp;
}
}
//折半插入排序
template <class T>
void BinaryInsertionSort(T Data[],int n)
{
int left,mid,right,p;
for(p=1;p<n;p++)
{
T temp=Data[p];
left =0;
right=n-1;
while(left<=right)
{
mid=(left+right)/2;
if(Data[mid]>temp)
right=mid-1;
else
left=mid+1;
}
for(int i=p-1;i>=left;i--)
Data[i+1]=Data[i];
Data[left]=temp;
}
}
五、希爾排序(Shell Sort)
希爾排序也稱遞減增量排序,是對插入排序的改進,以犧牲穩定性的方法提高效率,基本思路是先將整個資料序列分割成若干子序列分別進行直接插入排序,待整個序列中的記錄基本有序時,再對全部資料進行依次直接插入排序,直至所有資料有序,希爾排序演算法的性能與所選取的分組長度序列有很大關系,復雜度下界為O(n log2n),在中等規模的資料中表現良好,
平均時間復雜度為O(n^3/2),空間復雜度為O(1),是一種不穩定的排序演算法,
附演算法實作原始碼:
//希爾排序
template <class T>
void ShellSort(T Data[],int n)
{
int d=n/2;
while(d>=1)
{
for(int k=0;k<d;k++)
{
for(int i=k+d;i<n;i+=d)
{
T temp=Data[i];
int j=i-d;
while(j>=k&&Data[j]>temp)
{
Data[j+d]=Data[j];
j-=d;
}
Data[j+d]=temp;
}
}
d=d/2;
}
}
六、堆排序(Heap Sort)
堆排序利用堆這種近似完全二叉樹的資料結構進行排序,堆積的性質:即子結點的鍵值或索引總是小于(或者大于)它的父節點,以最大堆為例,堆中的最大值總是位于根節點,首先將待排序的n個資料構造為大根堆,將頂端資料與末尾資料進行交換并將堆的尺寸減一,然后剩余n-1個資料再次構造為大根堆,再次交換,再次縮減,直至所有資料有序,建堆復雜度為O(n),調整堆復雜度為O(n logn),最優的情況為所有葉節點鋪滿最底層,最差情況所有葉節點都沒鋪滿,對復雜度的影響在常數級別,時間復雜度均為O(n logn),
平均時間復雜度為O(n logn),空間復雜度為O(1),是一種不穩定的排序演算法,
附演算法實作原始碼:
//堆排序
template <class T>
void SiftDown(int left, int n, T Data[])
{
int i = left;
int j = 2*i + 1;
T temp = Data[i];
while(j < n)
{
if((j < n - 1)&&(Data[j] < Data[j+1])) j++;
if(temp < Data[j])
{
Data[i] = Data[j];
i = j;
j = 2*j + 1;
}
else break;
}
Data[i] = temp;
}
template <class T>
void BuildHeap(int n, T Data[])
{
for (int i = n/2-1; i >= 0; i--)
SiftDown(i, n, Data);
}
template <class T>
void Remove(T Data[], int n)
{
SiftDown(0, n, Data);
}
template <class T>
void HeapSort(T Data[], int n)
{
BuildHeap(n, Data);
for(int i = n-1; i > 0; i--)
{
T t = Data[0];
Data[0] = Data[i];
Data[i] = t;
Remove(Data, i);
}
}
七、歸并排序(Merge Sort)
歸并排序采用分治法,基本思想為將已有序的子序列合并,得到完全有序的序列,以二路歸并為例,首先將整個資料樣本拆分為兩個子樣本, 并分別對它們進行排序,拆分后的兩個子樣本序列,再繼續遞回的拆分為更小的子資料樣本序列, 再分別進行排序, 直到最后資料序列長度為1無法拆分,最后將同一級別下的子資料樣本兩兩合并在一起,直到所有資料有序,歸并排序的終極優化版本為TimSort,最好情況下可將時間復雜度降至O(n),還有一種改進的原地歸并演算法可犧牲部分時間效率將空間復雜度降至O(1),
平均時間復雜度為O(n logn),空間復雜度為O(n),是一種穩定的排序演算法,
附演算法實作原始碼:
//歸并排序
template <class T>
void Merge(T data[],int start,int mid,int end)
{
int len1=mid-start+1;
int len2=end-mid;
int i,j,k;
T* left=new T[len1];
T* right=new T[len2];
for(i=0;i<len1;i++)
{
left[i]=data[i+mid+1];
}
for(i=0;i<len2;i++)
{
right[i]=data[i+mid+1];
}
i=0,j=0;
for(k=start;k<end;k++)
{
if(i==len1||j==len2)
break;
if(left[i]<=right[j])
data[k]=left[i++];
else
data[k]=right[j++];
}
while(i<len1)
{
data[k++]=left[i++];
}
while(j<len2)
{
data[k++]=left[j++];
}
delete[] left;
delete[] right;
}
template <class T>
void MergeSort(T data[],int start,int end)
{
if(start<end)
{
int mid=(start+end)/2;
MergeSort(data,start,mid);
MergeSort(data,mid+1,end);
Merge(data,start,mid,end);
}
}
八、基數排序(Radix Sort)
基數排序是一種基于非比較的整數排序演算法,其原理是將整數按位數切割成不同的數字,然后按每個不同數位分別比較,原始基數排序的演算法思想是將所有待比較數值(正整數)統一為同樣的數位長度,數位較短的數前面補零,然后從最低位開始依次進行一次排序,直到所有資料有序,基數排序時間復雜度為O(n×k),其中n為資料個數,k為資料位數,主要分為兩種實作方法MSD(最高位優先)和LSD(最低位優先),
平均時間復雜度為O(n×k),空間復雜度為O(n+k),是一種穩定的排序演算法,
附演算法實作原始碼:
//基數排序
const int RADIX=10;
template <class T>
struct LinkNode
{
T data;
LinkNode* next;
};
template <class T>
struct TubNode
{
LinkNode<T>* rear;
LinkNode<T>* front;
};
template <class T>
TubNode <T>* Distribute(T data[],int n,int ith)
{
TubNode<T>* tube = new TubNode<T>[RADIX];
memset(tube,0,sizeof(TubNode<T>)*RADIX);
LinkNode<T>* t;
for(int i=0;i<n;i++)
{
T v=data[i];
int j=ith-1;
while(j--)
v=v/RADIX;-
v=v%RADIX;
t=new LinkNode<T>;
t->data=data[i];
t->next=NULL;
if(tube[v].front)
{
tube[v].rear->next=t;
tube[v].rear=t;
}
else
{
tube[v].front=tube[v].rear=t;
}
}
return tube;
}
template <class T>
void Collect(T data[],TubNode<T>*tube)
{
LinkNode<T>*t,*p;
int index=0;
for(int i=0;i<RADIX;i++)
{
p=t=tube[i].front;
while(t)
{
data[index++]=t->data;
t=t->next;
delete p;
p=t;
}
}
delete[] tube;
}
template <class T>
void RadixSort(T data[],int n,int keys)
{
TubNode<T>* tube;
for(int i=0;i<keys;i++)
{
tube=Distribute<T>(data,n,i+1);
Collect<T>(data,tube);
}
}九、計數排序(Counting Sort)
計數排序是一種基于非比較的線性時間復雜度的排序方法,計數排序要求輸入的資料必須是有確定范圍K的整數,假定輸入的元素是 n 個 0 到 k 之間的整數,它的運行時間是 Θ(n + k),首先要找出待排序的陣列中的最大元素和最小元素,然后統計陣列中每個值為i的元素出現的次數存入陣列Count[i],在之后對所有的計數進行累加(從陣列Count第一個元素開始,每一項與前一項相加),最后反向填充目標陣列(具體操作為:將每個元素i放在新陣列的第Count[i]項,每放一個元素對應Count[i]減去一),適用于對最大值不是很大的整型元素序列進行排序的情況,最好最壞復雜度都處在線性范圍O(n+k),
平均時間復雜度為O(n+k),空間復雜度為O(k),是一種穩定的排序演算法,
附演算法實作原始碼:
//計數排序
template <class T>
void CountingSort(T in_data[], T out_data[], int length,int k)
{
T *temp = new T[k];
for (int i = 0; i < k; i++)
{
temp[i] = 0;
}
for (int i = 0; i < length; i++)
{
temp[in_data[i]] += 1;
}
for (int i = 1; i < k; i++)
{
temp[i] = temp[i] + temp[i - 1];
}
for (int i = length - 1; i >= 0; i--)
{
out_data[temp[in_data[i]]-1] = in_data[i];
temp[in_data[i]] -= 1;
}
delete[]temp;
}
十、桶排序(Bucket Sort)
桶排序屬于計數排序的升級強化版,同時利用了分治的思想,將待排資料劃分到一定數量的有序的桶里,然后再對每個桶中的資料進行排序(桶排序的穩定性取決于桶內排序演算法是否穩定),最后再將各個桶里的資料有序的合并到一起,最理想的情況下,輸入資料可以被均勻的分配在每一個桶中,時間復雜度可以降到O(n);最壞的情況為所有資料在同一個桶中進行排序,且使用了復雜度較高的排序演算法,此時時間復雜度會變為O(n2),為了使桶排序更加高效,需要做到以下兩點:①在額外空間充足的情況下,盡量增加桶的數量,②使用的映射函式能夠將輸入的 N 個資料均勻的分配到 K 個桶中,
平均時間復雜度為O(n+k),空間復雜度為O(n+k),是一種穩定的排序演算法,
附演算法實作原始碼:
//桶排序
template <class T>
void Bucket_sort(T data[], int n, int max)
{
T *buckets;
if (data==NULL || n<1 || max<1)
{
return;
}
if ((buckets=(T *)malloc(max*sizeof(T)))==NULL)
{
return;
}
memset(buckets, 0, max*sizeof(T));
for (int i = 0; i < n; i++)
{
buckets[data[i]]++;
}
for (int i = 0, j = 0; i < max; i++)
{
while( (buckets[i]--) >0 )
{
data[j++] = i;
}
}
free(buckets);
}
相關代碼后續會上傳至網盤及個人資源,有需要者可自行下載,當然也可私信或留言博主私下獲取!!!
鏈接:https://pan.baidu.com/s/1y9QuUpYLqzWxrQkD89tsSw
提取碼:6blj
參考目錄:
首先感謝參考文獻中各位大佬的整理、總結與分享,如果在文章中出現侵犯您的著作權或隱私的行為,請私信或留言聯系博主,博主會在第一時間進行回復并做出相應修改,再次感謝參考目錄中出現的各位大佬,Thanks~~
排序:https://baike.baidu.com/item/%E6%8E%92%E5%BA%8F
冒泡排序:https://baike.baidu.com/item/%E5%86%92%E6%B3%A1%E6%8E%92%E5%BA%8F
插入排序:https://baike.baidu.com/item/%E6%8F%92%E5%85%A5%E6%8E%92%E5%BA%8F
選擇排序:https://baike.baidu.com/item/%E9%80%89%E6%8B%A9%E6%8E%92%E5%BA%8F
快速排序:https://baike.baidu.com/item/%E5%BF%AB%E9%80%9F%E6%8E%92%E5%BA%8F%E7%AE%97%E6%B3%95
希爾排序:https://baike.baidu.com/item/%E5%B8%8C%E5%B0%94%E6%8E%92%E5%BA%8F
堆排序:https://baike.baidu.com/item/%E5%A0%86%E6%8E%92%E5%BA%8F
桶排序:https://baike.baidu.com/item/%E6%A1%B6%E6%8E%92%E5%BA%8F
計數排序:https://baike.baidu.com/item/%E8%AE%A1%E6%95%B0%E6%8E%92%E5%BA%8F
基數排序:https://baike.baidu.com/item/%E5%9F%BA%E6%95%B0%E6%8E%92%E5%BA%8F
歸并排序:https://baike.baidu.com/item/%E5%BD%92%E5%B9%B6%E6%8E%92%E5%BA%8F
十大經典排序演算法總結:https://jingyan.baidu.com/article/d3b74d64900eb05f77e609b7.html
上官致遠_十大經典排序演算法:https://zhuanlan.zhihu.com/p/41923298
blackboydec_排序演算法時間復雜度、空間復雜度、穩定性比較:https://blog.csdn.net/yushiyi6453/article/details/76407640
排序演算法時間復雜度以及空間復雜度:https://blog.csdn.net/liwei123liwei123/article/details/77868195
茶還是咖啡_八大排序總結:https://www.jianshu.com/p/8edba972b4b0
_code_x_十大常見排序演算法的復雜度與代碼實作:https://www.jianshu.com/p/4753b10a482c
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/282657.html
標籤:其他
上一篇:Linux:詳解行程信號(信號的捕捉流程,信號的阻塞、volatile關鍵字)(二)
下一篇:rand函式和srand函式詳解