文章目錄
- 一、鏈表的概念及其結構
- 二、單鏈表的實作
- 1.單鏈表的訪問
- 2.單鏈表頭部插入資料
- 3.單鏈表尾部插入資料
- 4.單鏈表頭部洗掉資料
- 5.單鏈表尾部洗掉資料
- 6.查找單鏈表中值為x的結點
- 7.在某一結點的后面插入一個結點
- 8.在某一結點的后面洗掉一個結點
- 三、單鏈表的優劣
- 四、 帶頭回圈雙向鏈表的實作
- 1.雙向鏈表的初始化
- 2.雙向鏈表尾部插入資料
- 3.雙向鏈表頭部插入資料
- 4.雙向鏈表尾部洗掉資料
- 5.雙向鏈表頭部洗掉資料
- 6.尋找雙向鏈表中值為x的結點
- 7.在pos位置前插入一個結點
- 8.洗掉pos結點
- 9.得到鏈表的結點個數
- 感謝閱讀,如有錯誤請批評指正
一、鏈表的概念及其結構
概念:鏈表是一種物理存盤結構上非連續、非順序的存盤結構,資料元素的邏輯結構是通過鏈表中的指標鏈接實作的 ,
實際中鏈表的結構非常多樣,以下情況組合起來有8種鏈表結構:
(1)單向、雙向(是否支持向前訪問)
(2)帶頭、不帶頭(在鏈表開頭是否有一個不存放資料的頭結點)
(3)回圈、非回圈(是否能通過鏈表的尾結點直接訪問到鏈表的第一個結點)
雖然有這么多的鏈表的結構,但是實際中最常用的還是下面兩種結構:
(1)不帶頭單向非回圈鏈表
結構如下(邏輯結構):

每個結點都是一個結構體,分為兩個部分,前一個部分存放資料(資料域),后一個部分存放指向下一個結點的指標(指標域),
這種鏈表結構簡單,一般不會單獨用來存資料,實際中更多是作為其他資料結構的子結構,如哈希桶、圖的鄰接表等等,另外這種結構在筆試面試中出現很多,
(2)帶頭回圈雙向鏈表
結構如下(邏輯結構):
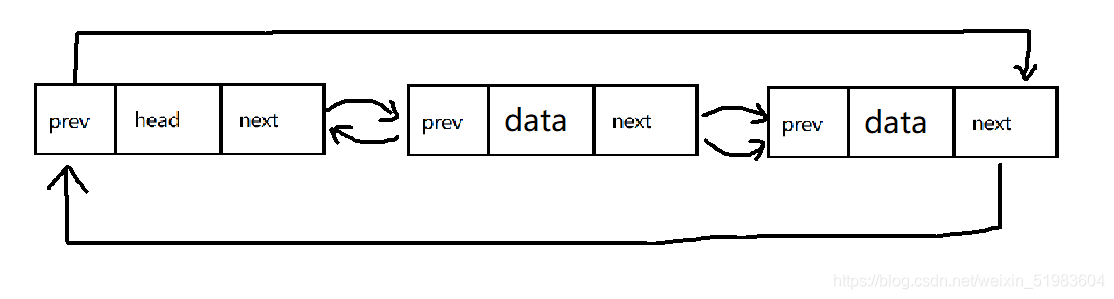
每個結點都是一個結構體,分為三個部分,第一個部分存放指向前一個結點的指標,中間部分存放資料,最后一個部分存放指向下一個結點的指標,
這種鏈表結構最復雜,一般用來單獨存盤資料,實際中使用的鏈表資料結構,大多數是帶頭雙向回圈鏈表,這個結構雖然結構復雜,但是使用代碼實作以后會帶來很多優勢,實作起來反而更加簡單,
二、單鏈表的實作
實作不帶頭單向非回圈鏈表
鏈表的結構:
typedef int DataType;
typedef struct ListNode
{
DataType a;
struct ListNode* next;
}ListNode;
1.單鏈表的訪問
通常我們有鏈表的第一個結點的地址(plist),那么如何遍歷訪問每一個結點呢?
只需在每次操作后將plist更新為plist->next,這就讓plist向后走了一個結點,
代碼如下(示例):
void ListNodePrint(ListNode* plist)
{
while (plist != NULL)
{
printf("%d->", plist->a);
plist = plist->next;
}
printf("NULL\n");
}
2.單鏈表頭部插入資料
可以很輕松地寫出如下代碼,
代碼如下(示例):
void ListNodePushFront(ListNode* plist, DataType x)
{
ListNode* newnode = (ListNode*)malloc(sizeof(ListNode));
newnode->a = x;
newnode->next = plist;
}
但是這段代碼執行結束后雖然在鏈表頭部插入了資料為a的新結點,但是plist指向的仍是鏈表中原來的頭結點,plist沒有隨著頭插更新,
注意這里由于需要更新頭結點,也就是需要在函式中對一級指標的值進行修改,所以傳參時需要傳遞二級指標(之后的代碼同理),
(由于創建一個值為x的結點的程序需要使用多次,所以這里將其封裝為BuyListNode)
代碼如下(示例):
//創建一個值為x的新結點并回傳其地址
ListNode* BuyListNode(DataType x)
{
ListNode* newnode = (ListNode*)malloc(sizeof(ListNode));
newnode->a = x;
newnode->next = NULL;
return newnode;
}
//頭插
void ListNodePushFront(ListNode** pplist, DataType x)
{
if (*pplist == NULL)
return;
ListNode* newnode = BuyListNode(x);
newnode->next = *pplist;//將newnode與第一個結點連接
*pplist = newnode;//更新第一個結點
}
3.單鏈表尾部插入資料
不帶頭單向非回圈鏈表在找尾結點時需從頭遍歷,時間復雜度為O(N),這也是它的缺點,
代碼如下(示例):
void ListNodePushBack(ListNode** pplist, DataType x)
{
ListNode* newnode = BuyListNode(a);
if (*pplist == NULL)//鏈表為空
{
*pplist = newnode;
return;
}
ListNode* cur = *pplist;//從頭開始遍歷
while (cur->next != NULL)//找到最后一個結點,注意回圈結束的判斷條件
cur = cur->next;//迭代來讓cur指標向后遍歷
cur->next = newnode;
}
4.單鏈表頭部洗掉資料
由于鏈表可以直接訪問頭部,所以對頭部的操作比較簡單,
這里只需要先保存第一個結點的下一個結點next,釋放第一個結點,然后將鏈表的頭變為next,
(注意這里的next與鏈表結構體中的next無關)
代碼如下(示例):
void ListNodePopFront(ListNode** pplist)
{
//1.鏈表中沒有結點
if (*pplist == NULL)
return;
//2.鏈表中有多個結點
else
{
ListNode* next = (*pplist)->next;//加小括號保證先進行解參考操作
free(*pplist);//將第一個結點釋放
*pplist = next;//更新鏈表的第一個結點
}
}
5.單鏈表尾部洗掉資料
這一步驟情況較多:
(1)鏈表為空,直接回傳
(2)鏈表中只有一個結點,則洗掉該節點并將鏈表的頭置為NULL
(3)鏈表中有多個結點,遍歷到尾結點并將其洗掉
代碼如下(示例):
void ListNodePopBack(ListNode** pplist)
{
//1.沒有結點
if (*pplist == NULL)
return;
//2.只有一個結點
else if ((*pplist)->next == NULL)
{
free(*pplist);
*pplist = NULL;
return;
}
//3.多個結點
ListNode* tail = *pplist;
ListNode* prev = *pplist;
//遍歷找到尾結點
//由于需要得到尾結點的前一個結點(這個結點是新的尾結點),這里用prev表示它的前一個結點
while (tail->next != NULL)
{
prev = tail;
tail = tail->next;
}
//洗掉尾結點
free(tail);
tail = NULL;
//將新的尾結點的next置為NULL
prev->next = NULL;
}
6.查找單鏈表中值為x的結點
這一功能只需從頭遍歷函式,當碰到(第一個)值為x的結點,直接回傳它的地址,若找不到則回傳NULL,
代碼如下(示例):
ListNode* ListNodeFind(ListNode* plist, DataType x)
{
ListNode* cur = plist;
while (cur != NULL)
{
if (cur->a == x)
return cur;//找到直接回傳
cur = cur->next;
}
return NULL;//找不到回傳NULL
}
7.在某一結點的后面插入一個結點
這個函式通常和ListNodeFind函式一起用,即用ListNodeFind函式來找到“某一結點”,然后在這一結點后插入一個新的結點,
(這里實作的是在某一結點的后面插入新結點,如果要在其前面插入新結點,由于當前鏈表結構無法訪問前一個結點,實作時會非常麻煩)
代碼如下(示例):
//在pos結點的后面插入一個結點
void ListNodeInsertAfter(ListNode* pos, DataType x)
{
assert(pos);
ListNode* next = pos->next;
ListNode* cur = BuyListNode(x);
//將三個結點連接起來
pos->next = cur;
cur->next = next;
}
8.在某一結點的后面洗掉一個結點
這一函式與ListNodeInsertAfter相似,
代碼如下(示例):
void ListNodeEraseAfter(ListNode* pos)
{
assert(pos);
if (pos->next == NULL)
return;
ListNode* next = pos->next->next;//得到被洗掉結點的下一個結點的地址
free(pos->next);
pos->next = next;//將鏈表連接起來
}
三、單鏈表的優劣
單鏈表的優勢:
(1)可在O(1)的時間復雜度內插入和洗掉資料,操作時只需要改變指標的指向即可,
(2)動態分配記憶體空間,用多少開辟多少,不會出現記憶體浪費的情況,記憶體利用率高,
單鏈表的劣勢:
(1)以結點為單位存盤,在對任意位置進行插入和洗掉操作時的時間復雜度為O(N),
四、 帶頭回圈雙向鏈表的實作
上述單鏈表的功能由于其結構簡單,有些地方實作起來較麻煩,下面的雙向鏈表雖然結構復雜一些,但是實作其功能時非常方便,下面實作雙向鏈表的基本功能,
雙向鏈表的結構
typedef int DLData;
typedef struct DListNode
{
struct DListNode* prev;//指向前一個結點的指標
struct DListNode* next;//指向后一個結點的指標
DLData val;//存盤資料
}DListNode;
1.雙向鏈表的初始化
這里實作兩個函式,初始化一個雙向鏈表和創建一個新結點,
代碼如下(示例):
//創建一個新結點
DListNode* BuyDListNode(DLData x)
{
DListNode* newnode = (DListNode*)malloc(sizeof(DListNode));
newnode->val = x;
newnode->prev = NULL;
newnode->next = NULL;
return newnode;
}
//初始化一個雙向鏈表
DListNode* DListNodeInit()
{
DListNode* newnode = (DListNode*)malloc(sizeof(DListNode));
newnode->val = -1;//這里可隨意賦值,因為雙向鏈表在訪問時不會訪問頭結點的值
//初始把頭結點的prev和next指標都指向自己
newnode->next = newnode;
newnode->prev = newnode;
return newnode;
}
2.雙向鏈表尾部插入資料
代碼如下(示例):
void DListNodePushBack(DListNode* phead, DLData x)
{
assert(phead);
DListNode* newnode = BuyDListNode(x);//創建新結點
DListNode* tail = phead->prev;//找尾,頭結點的prev指標就是尾結點
//連接原來的尾結點和新結點
tail->next = newnode;//原來的尾結點的next指向新結點
newnode->prev = tail;//新結點的prev指向原來的尾結點
//連接誒頭結點和新結點
phead->prev = newnode;//頭結點的prev指向新結點(也是新的尾結點)
newnode->next = phead;//新結點的next指向頭結點
}
3.雙向鏈表頭部插入資料
注意雙向鏈表頭部插入資料是指在頭結點的下一個結點的位置插入資料,
代碼如下(示例):
void DListNodePushFront(DListNode* phead, DLData x)
{
assert(phead);
DListNode* newnode = BuyDListNode(x);
DListNode* first = phead->next;//找到頭結點的下一個結點
//將新結點前后的結點與新結點連接
first->prev = newnode;
newnode->next = first;
newnode->prev = phead;
phead->next = newnode;
}
4.雙向鏈表尾部洗掉資料
代碼如下(示例):
void DListNodePopBack(DListNode* phead)
{
assert(phead);
assert(phead != phead->next);//防止鏈表中只有一個phead,沒有別的結點
DListNode* tail = phead->prev;//找到尾結點
DListNode* tailPrev = phead->prev->prev;//找到尾結點的前一個結點(這將是新的尾結點)
free(tail);
//連接頭結點和新的尾結點
tailPrev->next = phead;
phead->prev = tailPrev;
}
5.雙向鏈表頭部洗掉資料
代碼如下(示例):
void DListNodePopFront(DListNode* phead)
{
assert(phead);
assert(phead != phead->next);
DListNode* first = phead->next;
DListNode* firstNext = phead->next->next;//找到新的連接在頭結點后的結點
free(first);
phead->next = firstNext;
firstNext->prev = phead;
}
6.尋找雙向鏈表中值為x的結點
這里回傳的仍是鏈表從前往后第一個值為x的結點,一旦找到立刻結束,
代碼如下(示例):
DListNode* DListNodeFind(DListNode* phead, DLData x)
{
assert(phead);
DListNode* cur = phead->next;
//從頭結點的下一個結點開始遍歷尋找
while (cur != phead)
{
if (cur->val == x)
return cur;
cur = cur->next;
}
//找不到回傳空
return NULL;
}
7.在pos位置前插入一個結點
實作單鏈表時提到,在某一個位置前插入結點很麻煩,因為單鏈表的結構決定了它很難訪問前面的結點,但到了雙向鏈表就可以很輕松地訪問前后的結點,所以在某一個位置前插入結點也很容易實作,
代碼如下(示例):
void DListNodeInsertBefore(DListNode* pos, DLData x)
{
assert(pos);
DListNode* newnode = BuyDListNode(x);
DListNode* prev = pos->prev;//找到pos位置的前一個結點
//連接新結點,pos結點,pos原來的前一個結點
prev->next = newnode;
newnode->prev = prev;
newnode->next = pos;
pos->prev = newnode;
}
8.洗掉pos結點
代碼如下(示例):
void DListNodeErase(DListNode* pos)
{
assert(pos);
//找到pos的前后兩個結點
DListNode* prev = pos->prev;
DListNode* next = pos->next;
//連接這兩個結點
prev->next = next;
next->prev = prev;
free(pos);
}
9.得到鏈表的結點個數
代碼如下(示例):
//判斷鏈表是否為空
int DListNodeEmpty(DListNode* phead)
{
//如果頭結點的下一個還是頭結點,說明雙向鏈表中只有這一個結點,認為是空
return (phead->next == phead);
}
//得到鏈表的結點個數
int DListNodeSize(DListNode* phead)
{
assert(phead);
int size = 0;
DListNode* cur = phead->next;
//從第一個結點開始遍歷即可
while (cur != phead)
{
size++;
cur = cur->next;
}
return size;
}
感謝閱讀,如有錯誤請批評指正
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/282667.html
標籤:其他