系列文章目錄
https://zhuanlan.zhihu.com/p/367683572
目錄- 系列文章目錄
- 一. 使用方式
- step 1: 設定必要引數
- step 2: 創建KafkaProducer
- step 3:構造要發送的訊息
- step 4:發送訊息
- 二. 執行緒模型
- 三. 原始碼分析
- 1. 主執行緒
- 1.1 KafkaProducer屬性分析
- 1.2 ProducerInterceptors
- 1.3 元資料獲取
- 1.4 Serialize
- 1.5 Partition選擇
- 2. RecordAccumulator
- 3. Sender執行緒
- 3.1 NetworkClient
- 3.2 Sender執行緒業務邏輯
- 1. 主執行緒
- 四. 總結
一. 使用方式
show the code.
public class KafkaProducerDemo {
public static void main(String[] args) {
// step 1: 設定必要引數
Properties config = new Properties();
config.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,
"127.0.0.1:9092,127.0.0.1:9093");
config.setProperty(ProducerConfig.ACKS_CONFIG, "-1");
config.setProperty(ProducerConfig.RETRIES_CONFIG, "3");
// step 2: 創建KafkaProducer
KafkaProducer<String, String> producer = new KafkaProducer<>(config);
// step 3: 構造要發送的訊息
String topic = "kafka-source-code-demo-topic";
String key = "demo-key";
String value = "https://www.cnblogs.com/zhanghao2244/p/村口老張頭: This is a demo message.";
ProducerRecord<String, String> record =
new ProducerRecord<>(topic, key, value);
// step 4: 發送訊息
Future<RecordMetadata> future = producer.send(record);
}
}
step 1: 設定必要引數
代碼中涉及的幾個配置:
- bootstrap.servers:指定Kafka集群節點串列(全部 or 部分均可),用于KafkaProducer初始獲取Server端元資料(如完整節點串列、Partition分布等等);
- acks:指定服務端有多少個副本完成同步,才算該Producer發出的訊息寫入成功(后面講副本的文章會深入分析,這里按下不表);
- retries:失敗重試次數;
更多引數可以參考ProducerConfig類中的常量串列,
step 2: 創建KafkaProducer
KafkaProducer兩個模板引數指定了訊息的key和value的型別
step 3:構造要發送的訊息
- 確定目標topic;
String topic = "kafka-source-code-demo-topic"; - 確定訊息的key
key用來決定目標Partition,這個下文細聊,String key = "demo-key"; - 確定訊息體
這是待發送的訊息內容,傳遞業務資料,String value = "https://www.cnblogs.com/zhanghao2244/p/村口老張頭: This is a demo message.";
step 4:發送訊息
Future<RecordMetadata> future = producer.send(record);
KafkaProducer中各類send方法均回傳Future,并不會直接回傳發送結果,其原因便是執行緒模型設計,
二. 執行緒模型
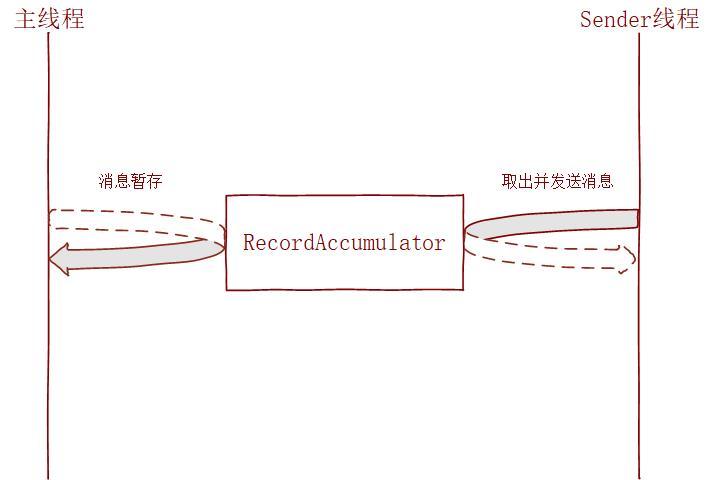
這里主要存在兩個執行緒:主執行緒 和 Sender執行緒,主執行緒即呼叫KafkaProducer.send方法的執行緒,當send方法被呼叫時,訊息并沒有真正被發送,而是暫存到RecordAccumulator,Sender執行緒在滿足一定條件后,會去RecordAccumulator中取訊息并發送到Kafka Server端,
那么為啥不直接在主執行緒就把訊息發送出去,非得搞個暫存呢?為了Kafka的目標之一——高吞吐,具體而言有兩點好處:
- 可以將多條訊息通過一個ProduceRequest批量發送出去;
- 提高資料壓縮效率(一般壓縮演算法都是資料量越大越能接近預期的壓縮效果);
三. 原始碼分析
先給個整體流程圖,然后咱們再逐步分析,
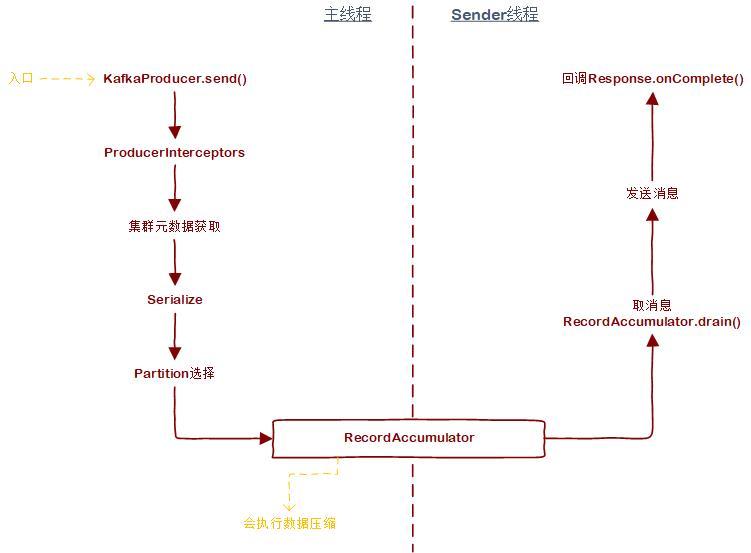
1. 主執行緒
1.1 KafkaProducer屬性分析
這里列出KafkaProducer的核心屬性,至于全部屬性說明,可參考我的"注釋版Kafka原始碼":https://github.com/Hao1296/kafka
| 欄位名 | 欄位型別 | 說明 |
|---|---|---|
| clientId | String | 生產者唯一標識 |
| partitioner | Partitioner | 磁區選擇器 |
| metadata | Metadata | Kafka集群元資料 |
| accumulator | RecordAccumulator | 訊息快取器 |
| sender | Sender | Sender執行緒業務邏輯封裝,繼承Runnable |
| ioThread | Thread | Sender執行緒對應的執行緒物件 |
| interceptors | ProducerInterceptors | 訊息攔截器,下文會說明 |
1.2 ProducerInterceptors
ProducerInterceptors,訊息攔截器集合,維護了多個ProducerInterceptor物件,用于在訊息發送前對訊息欄位外的業務操作,使用時可按如下方式設定:
Properties config = new Properties();
// interceptor.classes
config.setProperty(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG,
"com.kafka.demo.YourProducerInterceptor,com.kafka.demo.InterceptorImpl2");
KafkaProducer<String, String> producer = new KafkaProducer<>(config);
ProducerInterceptor本身是一個介面:
public interface ProducerInterceptor<K, V> extends Configurable {
ProducerRecord<K, V> onSend(ProducerRecord<K, V> record);
void onAcknowledgement(RecordMetadata metadata, Exception exception);
void close();
}
其中,onAcknowledgement是得到Server端正確回應時的回呼,后面再細說,onSend是訊息在發送前的回呼,可在這里做一些訊息變更邏輯(如加減欄位等),輸入原始訊息,輸出變更后的訊息,KafkaProducer的send方法第一步就是執行ProducerInterceptor:
@Override
public Future<RecordMetadata> send(ProducerRecord<K, V> record, Callback callback) {
// intercept the record, which can be potentially modified;
// this method does not throw exceptions
// 關注這里
ProducerRecord<K, V> interceptedRecord = this.interceptors.onSend(record);
return doSend(interceptedRecord, callback);
}
// 該send方法多載核心邏輯仍是上面的send方法
@Override
public Future<RecordMetadata> send(ProducerRecord<K, V> record) {
return send(record, null);
}
1.3 元資料獲取
接上文,ProducerInterceptors執行完畢后會直接呼叫doSend方法執行發送相關的邏輯,到這為止有個問題,我們并不知道目標Topic下有幾個Partition,分別分布在哪些Broker上;故,我們也不知道訊息該發給誰,所以,doSend方法第一步就是搞清楚訊息集群結構,即獲取集群元資料:
private Future<RecordMetadata> doSend(ProducerRecord<K, V> record, Callback callback) {
TopicPartition tp = null;
try {
throwIfProducerClosed();
ClusterAndWaitTime clusterAndWaitTime;
try {
// 獲取集群元資料
clusterAndWaitTime = waitOnMetadata(record.topic(), record.partition(), maxBlockTimeMs);
} catch (KafkaException e) {
if (metadata.isClosed())
throw new KafkaException("Producer closed while send in progress", e);
throw e;
}
... ...
}
waiteOnMetadata方法內部大體分為2步:
private ClusterAndWaitTime waitOnMetadata(String topic, Integer partition, long maxWaitMs) throws InterruptedException {
// 第1步, 判斷是否已經有了對應topic&partition的元資料
Cluster cluster = metadata.fetch();
Integer partitionsCount = cluster.partitionCountForTopic(topic);
if (partitionsCount != null && (partition == null || partition < partitionsCount))
// 若已存在, 則直接回傳
return new ClusterAndWaitTime(cluster, 0);
// 第2步, 獲取元資料
do {
... ...
// 2.1 將目標topic加入元資料物件
metadata.add(topic);
// 2.3 將元資料needUpdate欄位置為true, 并回傳當前元資料版本
int version = metadata.requestUpdate();
// 2.4 喚醒Sender執行緒
sender.wakeup();
// 2.5 等待已獲取的元資料版本大于version時回傳, 等待時間超過remainingWaitMs時拋例外
try {
metadata.awaitUpdate(version, remainingWaitMs);
} catch (TimeoutException ex) {
throw new TimeoutException(
String.format("Topic %s not present in metadata after %d ms.",
topic, maxWaitMs));
}
// 2.6 檢查新版本元資料是否包含目標partition;
// 若包含, 則結束回圈; 若不包含, 則進入下一個迭代, 獲取更新版本的元資料
cluster = metadata.fetch();
......
partitionsCount = cluster.partitionCountForTopic(topic);
} while (partitionsCount == null || (partition != null && partition >= partitionsCount));
return new ClusterAndWaitTime(cluster, elapsed);
}
我們看到,waitOnMetadata的思想也和簡單,即:喚醒Sender執行緒來更新元資料,然后等待元資料更新完畢,至于Sender執行緒是如何更新元資料的,放到下文詳解,
1.4 Serialize
這一步是用通過"key.serializer"和"value.serializer"兩個配置指定的序列化器分別來序列化key和value
private Future<RecordMetadata> doSend(ProducerRecord<K, V> record, Callback callback) {
.....
// key序列化
byte[] serializedKey;
try {
serializedKey = keySerializer.serialize(record.topic(), record.headers(), record.key());
} catch (ClassCastException cce) {
throw new SerializationException("Can't convert key of class " + record.key().getClass().getName() +
" to class " + producerConfig.getClass(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG).getName() +
" specified in key.serializer", cce);
}
// value序列化
byte[] serializedValue;
try {
serializedValue = https://www.cnblogs.com/zhanghao2244/p/valueSerializer.serialize(record.topic(), record.headers(), record.value());
} catch (ClassCastException cce) {
throw new SerializationException("Can't convert value of class " + record.value().getClass().getName() +
" to class " + producerConfig.getClass(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG).getName() +
" specified in value.serializer", cce);
}
......
}
Kafka內置了幾個Serializer,如果需要的話,諸君也可以自定義:
org.apache.kafka.common.serialization.StringSerializer;
org.apache.kafka.common.serialization.LongSerializer;
org.apache.kafka.common.serialization.IntegerSerializer;
org.apache.kafka.common.serialization.ShortSerializer;
org.apache.kafka.common.serialization.FloatSerializer;
org.apache.kafka.common.serialization.DoubleSerializer;
org.apache.kafka.common.serialization.BytesSerializer;
org.apache.kafka.common.serialization.ByteBufferSerializer;
org.apache.kafka.common.serialization.ByteArraySerializer;
1.5 Partition選擇
到這里,我們已經有了Topic相關的元資料,但也很快遇到了一個問題:Topic下可能有多個Partition,作為生產者,該將待發訊息發給哪個Partition?這就用到了上文提到過的KafkaProducer的一個屬性——partitioner,
private Future<RecordMetadata> doSend(ProducerRecord<K, V> record, Callback callback) {
......
// 確定目標Partition
int partition = partition(record, serializedKey, serializedValue, cluster);
......
}
private int partition(ProducerRecord<K, V> record, byte[] serializedKey, byte[] serializedValue, Cluster cluster) {
// 若ProducerRecord中強制指定了partition, 則以該值為準
Integer partition = record.partition();
// 否則呼叫Partitioner動態計算對應的partition
return partition != null ?
partition :
partitioner.partition(
record.topic(), record.key(), serializedKey, record.value(), serializedValue, cluster);
}
在創建KafkaProducer時,可以通過"partitioner.class"配置來指定Partitioner的實作類,若未指定,則使用Kafka內置實作類——DefaultPartitioner,DefaultPartitioner的策略也很簡單:若未指定key,則在Topic下多個Partition間Round-Robin;若指定了key,則通過key來hash到一個partition,
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
int numPartitions = partitions.size();
if (keyBytes == null) {
// 若未指定key
int nextValue = https://www.cnblogs.com/zhanghao2244/p/nextValue(topic);
List availablePartitions = cluster.availablePartitionsForTopic(topic);
if (availablePartitions.size() > 0) {
int part = Utils.toPositive(nextValue) % availablePartitions.size();
return availablePartitions.get(part).partition();
} else {
// no partitions are available, give a non-available partition
return Utils.toPositive(nextValue) % numPartitions;
}
} else {
// hash the keyBytes to choose a partition
return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;
}
}
2. RecordAccumulator
RecordAccumulator作為訊息暫存者,其思想是將目的地Partition相同的訊息放到一起,并按一定的"規格"(由"batch.size"配置指定)劃分成多個"批次"(ProducerBatch),然后以批次為單位進行資料壓縮&發送,示意圖如下:
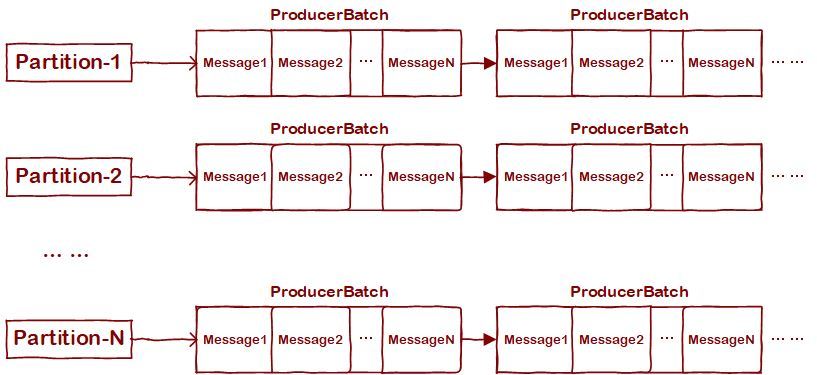
RecordAccumulator核心屬性如下:
| 欄位名 | 欄位型別 | 說明 |
|---|---|---|
| batches | ConcurrentMap<TopicPartition, Deque<ProducerBatch>> | 按Partition維度存盤訊息資料, 即上文示意圖描述的結構 |
| compression | CompressionType | 資料壓縮演算法 |
RecordAccumulator有兩個核心方法,分別對應"存"和"取":
/**
* 主執行緒會呼叫此方法追加訊息
*/
public RecordAppendResult append(TopicPartition tp,
long timestamp,
byte[] key,
byte[] value,
Header[] headers,
Callback callback,
long maxTimeToBlock) throws InterruptedException;
/**
* Sender執行緒會呼叫此方法提取訊息
*/
public Map<Integer, List<ProducerBatch>> drain(Cluster cluster,
Set<Node> nodes,
int maxSize,
long now);
3. Sender執行緒
3.1 NetworkClient
在分析Sender執行緒業務邏輯前,先來說說通信基礎類,
NetworkClient有兩個核心方法:
public void send(ClientRequest request, long now);
public List<ClientResponse> poll(long timeout, long now);
其中,send方法很有迷惑性,乍一看,覺得其業務邏輯是將request同步發送出去,然而,send方法其實并不實際執行向網路埠寫資料的動作,只是將請求"暫存"起來,poll方法才是實際執行讀寫動作的地方(NIO),當請求的目標channel可寫時,poll方法會實際執行發送動作;當channel有資料可讀時,poll方法讀取回應,并做對應處理,
NetworkClient有一個核心屬性:
/* 實際實作類為 org.apache.kafka.common.network.Selector */
private final Selectable selector;
send和poll方法都是通過selector來完成的:
public void send(ClientRequest request, long now) {
doSend(request, false, now);
}
private void doSend(ClientRequest clientRequest, boolean isInternalRequest, long now) {
... ...
doSend(clientRequest, isInternalRequest, now, builder.build(version));
}
private void doSend(ClientRequest clientRequest, boolean isInternalRequest, long now, AbstractRequest request) {
... ...
selector.send(send);
}
public List<ClientResponse> poll(long timeout, long now) {
... ...
this.selector.poll(Utils.min(timeout, metadataTimeout, defaultRequestTimeoutMs));
... ...
}
org.apache.kafka.common.network.Selector 內部則通過 java.nio.channels.Selector 來實作,
值得關注的一點是,NetworkClient的poll方法在呼叫Selector的poll方法前還有段業務邏輯:
// 在selector.poll前有此行邏輯
long metadataTimeout = metadataUpdater.maybeUpdate(now);
try {
this.selector.poll(Utils.min(timeout, metadataTimeout, defaultRequestTimeoutMs));
} catch (IOException e) {
log.error("Unexpected error during I/O", e);
}
metadataUpdater.maybeUpdate可以看出是為元資料更新服務的,其業務邏輯是:判斷是否需要更新元資料;若需要,則通過NetworkClient.send方法將MetadataRequest也加入"暫存",等待selector.poll中被實際發送出去,
3.2 Sender執行緒業務邏輯
KafkaProducer中,和Sender執行緒相關的有兩個屬性:
| 欄位名 | 欄位型別 | 說明 |
|---|---|---|
| ioThread | Thread | Sender執行緒實體 |
| sender | Sender | Runnable實體,為Sender執行緒的具體業務邏輯 |
在KafkaProducer的建構式中被創建:
KafkaProducer(ProducerConfig config,
Serializer<K> keySerializer,
Serializer<V> valueSerializer,
Metadata metadata,
KafkaClient kafkaClient) {
... ...
this.sender = new Sender(logContext,
client,
this.metadata,
this.accumulator,
maxInflightRequests == 1,
config.getInt(ProducerConfig.MAX_REQUEST_SIZE_CONFIG),
acks,
retries,
metricsRegistry.senderMetrics,
Time.SYSTEM,
this.requestTimeoutMs,
config.getLong(ProducerConfig.RETRY_BACKOFF_MS_CONFIG),
this.transactionManager,
apiVersions);
String ioThreadName = NETWORK_THREAD_PREFIX + " | " + clientId;
this.ioThread = new KafkaThread(ioThreadName, this.sender, true);
this.ioThread.start();
... ...
}
Sender執行緒的業務邏輯也很清晰:
public void run() {
log.debug("Starting Kafka producer I/O thread.");
// 主回圈
while (running) {
try {
run(time.milliseconds());
} catch (Exception e) {
log.error("Uncaught error in kafka producer I/O thread: ", e);
}
}
log.debug("Beginning shutdown of Kafka producer I/O thread, sending remaining records.");
// 下面是關閉流程
// okay we stopped accepting requests but there may still be
// requests in the accumulator or waiting for acknowledgment,
// wait until these are completed.
while (!forceClose && (this.accumulator.hasUndrained() || this.client.inFlightRequestCount() > 0)) {
try {
run(time.milliseconds());
} catch (Exception e) {
log.error("Uncaught error in kafka producer I/O thread: ", e);
}
}
if (forceClose) {
// We need to fail all the incomplete batches and wake up the threads waiting on
// the futures.
log.debug("Aborting incomplete batches due to forced shutdown");
this.accumulator.abortIncompleteBatches();
}
try {
this.client.close();
} catch (Exception e) {
log.error("Failed to close network client", e);
}
log.debug("Shutdown of Kafka producer I/O thread has completed.");
}
主回圈中僅僅是不斷呼叫另一個run多載,該多載的核心業務邏輯如下:
void run(long now) {
... ...
// 1. 發送請求,并確定下一步的阻塞超時時間
long pollTimeout = sendProducerData(now);
// 2. 處理埠事件,poll的timeout為上一步計算結果
client.poll(pollTimeout, now);
}
其中,sendProducerData會呼叫RecordAccumulator.drain方法獲取待發送訊息,然后構造ProduceRequest物件,并呼叫NetworkClient.send方法"暫存",sendProducerData方法之后便是呼叫NetworkClient.poll來執行實際的讀寫操作,
四. 總結
本文分析了KafkaProducer的業務模型及核心原始碼實作,才疏學淺,不一定很全面,歡迎諸君隨時討論交流,后續還會有其他模塊的分析文章,具體可見系列文章目錄: https://zhuanlan.zhihu.com/p/367683572
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/285995.html
標籤:架構設計
上一篇:當年,我是如何把微服務落地的