文章目錄
- 前言
- 一、什么是畢昇 JDK?
- 1.1、畢昇 JDK 發展歷程
- 1.2、畢昇 JDK 的支持架構
- 1.3、畢昇 JDK、OpenJDK 和 Oracle JDK 區別
- 二、為什么要做畢昇 JDK?
- 2.1、Oracle JDK 授權方式發生變化
- 2.2、高版本 JDK 有價值特性的渴望
- 2.3、應用的定制化優化訴求
- 三、畢昇 JDK 現狀
- 3.1、畢昇 JDK 研發現狀
- 3.2、畢昇 JDK 性能提升實體
- 四、畢昇 JDK 的 GC 演算法優化
- 4.1、并行復制演算法的概念
- 4.2、架構對并行復制演算法的影響
- 4.3、并行復制演算法的流程
- 4.4、演算法優化減少 membar 之 Q&A
- 4.5、G1、GC 的優化
- 4.6、ZGC 的優化
- 五、JIT 優化——SVE 演算法優化
- 5.1、SVE 演算法優化相關介紹
- 5.2、SVE 演算法優化成果
- 六、軟硬協同——鯤鵬 KAE 硬體加速
- 七、畢昇 JDK 還能帶來什么價值?
- 八、畢昇 JDK 的未來發展
- 8.1、即將面世的功能
- 8.2、未來方向
- 九、如何獲得畢昇 JDK 及幫助?
- 9.1、JDK 8 的代碼倉
- 9.2、JDK 11 的代碼倉
- 總結
前言
不知道大家是否聽說過亦或是使用過畢昇 JDK,是否從事 Java 作業?是否從事 JVM 底層開發?絕大多數 Java 開發者使用的都是 Oracle 的 JDK 或者是 OpenJDK,本文我們將介紹華為的畢昇 JDK 以及我們所做的相關技術優化,希望能在除上述兩者之外提供給大家新的選擇,
一、什么是畢昇 JDK?
1.1、畢昇 JDK 發展歷程
畢昇 JDK 是華為基于 OpenJDK 定制的開源版本,是一款高性能、可用于生產環境的 OpenJDK 發行版,穩定運行在華為內部 500 多個產品上,在華為內部廣泛使用畢昇 JDK,團隊積累了豐富的開發經驗,解決了實際業務運行中遇到的多個疑難問題,如 crash 等相關問題,我們已經在內部解決,
1.2、畢昇 JDK 的支持架構
- 目前僅支持 Linux/AArch64 架構,歡迎廣大開發者小伙伴們下載使用,
- 目前畢昇 JDK 支持 8 和 11 兩個 LTS 版本,并且已經全部開源,
1.3、畢昇 JDK、OpenJDK 和 Oracle JDK 區別
我們通過對比和分析畢昇 JDK、OpenJDK 和 Oracle JDK,來幫助大家在挑選 JDK 時有更好的選擇,
如下圖所示,我們用藍色的區域代表 OpenJDK,淺黃色和紅色分別代表 Oracle JDK 和畢昇 JDK,
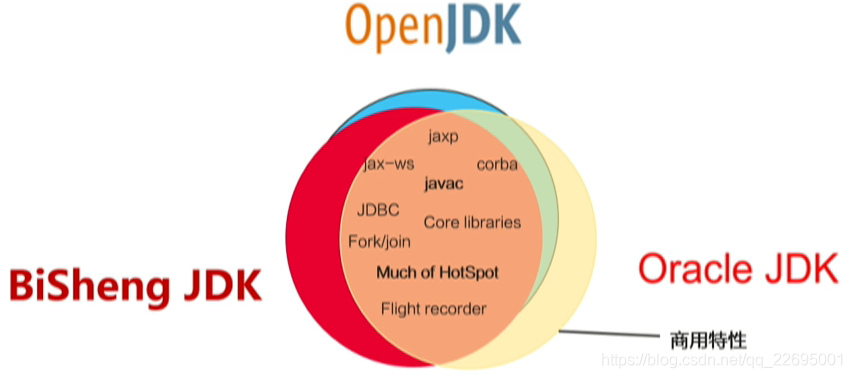
以上圖為參考,我們可以發現:
- 畢昇 JDK 和 Oracle JDK 一樣,都是基于 OpenJDK 定制得到,但是又同時賦予了各自不同的商業特性,比如,我們都知道 OpenJDK 12 添加了一個的新垃圾收集(GC)演算法——Shenandoah,但是在 Oracle JDK 的發行中是沒有附帶的,
- 畢昇 JDK 在基于 OpenJDK 定制的基礎上,存在的些許區別,主要來源于對產品功能的一些增強、問題的修復以及和上游特性的合入,
二、為什么要做畢昇 JDK?
2.1、Oracle JDK 授權方式發生變化
- 除去大家“眾所周知”的原因之外,不知道大家是否知道,Oracle JDK 在 8u212 版本之后是收費的,于公司而言,結合 JDK 自身存在的安全漏洞問題,綜合商業因素考慮的結果就是研發符合自身發展的 JDK,
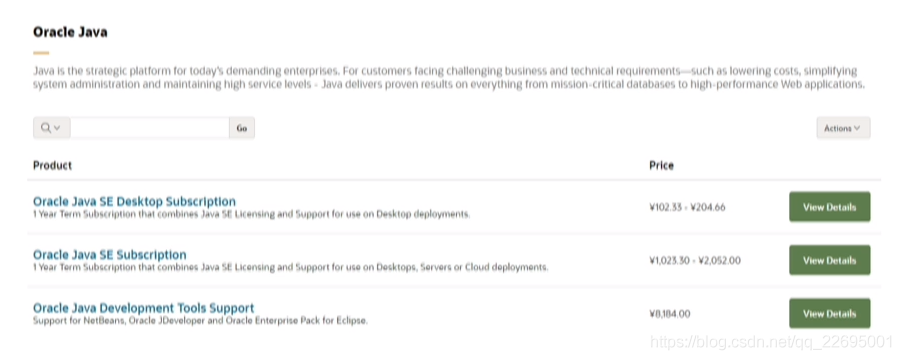
注:以上資料來自 Oracle 官網,
2.2、高版本 JDK 有價值特性的渴望
JDK 每六個月發行一次新版本,JDK 版本眾多,不同功能/特性在不同 JDK 版本,程式員期望在最熟悉的 JDK 上盡可能多的使用高版本中有價值的特性,例如 G1 GC 在 JDK12 中引入了一個特性,把不使用的記憶體歸還給作業系統,該特性在云場景中非常有價值,目前主流使用的還是 JDK8,自研 JDK 中 Blckport 特性能快速滿足需求,
2.3、應用的定制化優化訴求
應用在運行的硬體、場景有特殊的訴求,但這些訴求短期難以進入到社區,例如大資料應用在數學方面有較高訴請求,在自研 JDK 中可以針對數學計算做回圈開展、指令優化等編譯優化技術,加速計算,
三、畢昇 JDK 現狀
3.1、畢昇 JDK 研發現狀
- 畢昇 JDK 和 Oracle JDK 一樣,都是基于開源 OpenJDK 定制得到,同時團隊為上游社區貢獻了不少有價值的
Patch,涉及到:垃圾回收、JIT、運行時內容等, - 畢昇 JDK 遵循 GPLv2 著作權進行開源,并且可以從官方免費下載二進制,
- 畢昇 JDK采用社區化開發和運營,雙周會議,目前有 ARM、寶蘭德、麒麟等小伙伴一起參與,畢昇 JDK 社區不僅僅支持 ARM 平臺,任何關于 JDK 的問題都可以在畢昇 JDK 社區討論,都會在第一時間得到回復,
- 在上游社區中,團隊目前有 Reviewer 1 名,Committer 1名,Author 8 名共 10 余名同事往社區提交代碼,
- 畢昇 JDK 在 ARM 上性能、穩定性表現優異,
3.2、畢昇 JDK 性能提升實體
我們通過在測驗環境下運行畢昇 JDK 來分析其優勢何在,測驗環境如下:
- Model:Taishan 2280V2
- OS:openEuler20.09
- HW:kenpeng 920-6426 2600MHz,128 cores
- JDK:JDK8U262
我們通過比較在 SPECjbb 上的資料可以發現畢昇 JDK 在 critical 和 max 上均有較大的提升:critical 提升 55%,max 提升 16%,
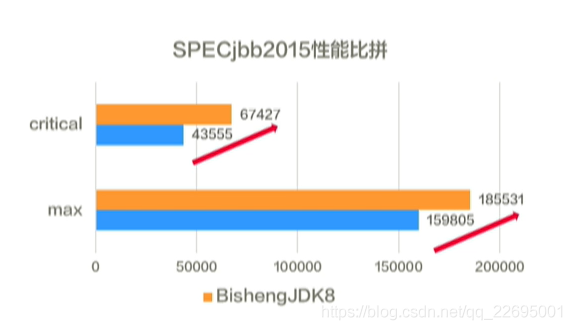
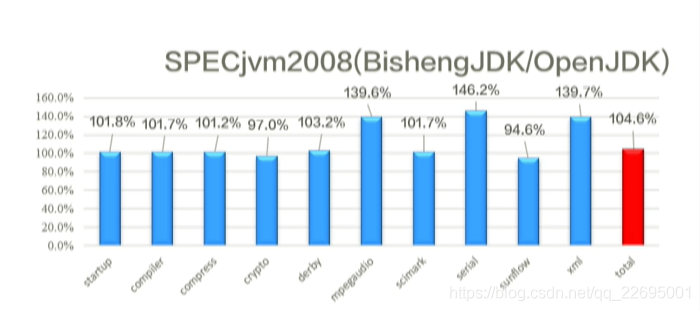
另一方面,在 SPECjvm 上的資料雖然說與上面相比并不是特別明顯,但是仍平均提升 4.6%,
四、畢昇 JDK 的 GC 演算法優化
4.1、并行復制演算法的概念
我們都知道復制是 GC 演算法里面很重要的一部分,特別是對于新生代的復制:將 from 區中的活躍物件復制到 to 區中,串行復制演算法是僅有一個執行緒負責這個事情,而這無法滿足我們的需要,所以我們用到了并行復制演算法,那么什么是并行復制演算法呢?
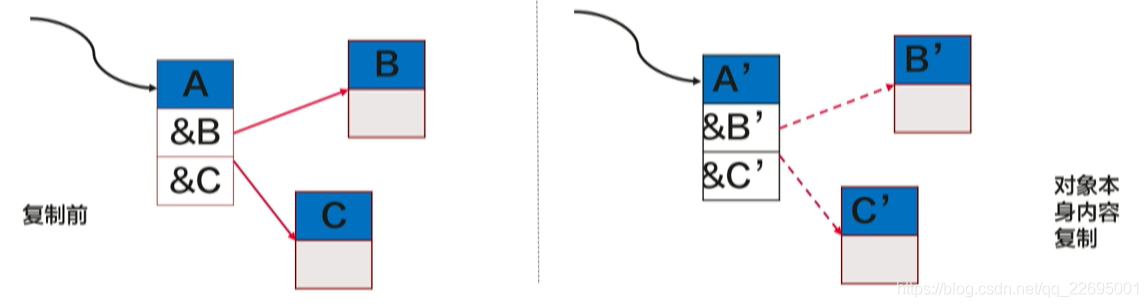
- 物件 A 和 B 在并行復制演算法中被不同的執行緒復制,可能由于:物件 A 和 B 有不同到達路徑,不同的執行緒復制,因為任務均衡的問題,執行緒可以竊取其他執行緒的復制任務,
- 例如有兩個執行緒 T1 和 T2 分別復制物件 A 和 B,T1:A→A′;T2:B→B′,
- 在復制時除了復制物件的內容外,還需要使用一個指標(Forwarding Pointer)記錄物件轉移后地址,防止物件被重復復制,
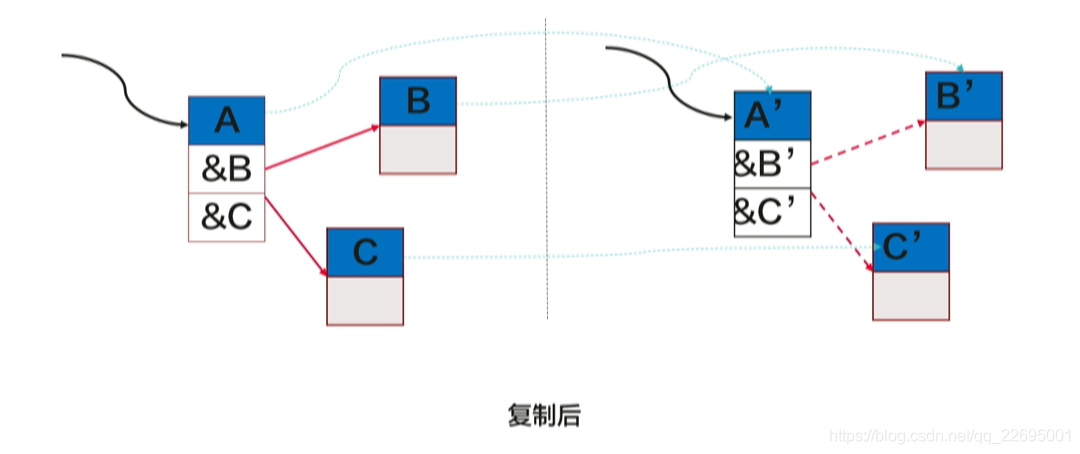
4.2、架構對并行復制演算法的影響
- 多執行緒的并行作業需要考慮不同架構的記憶體模型,X86 是一種強記憶體序架構,ARM 則是一種弱記憶體序,它們的記憶體序如下表所示:
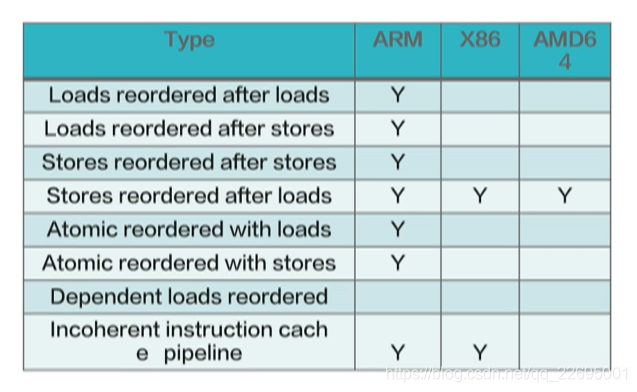
- 對于并行復制演算法來說,在弱記憶體序架構下,由于記憶體序的設計,其他執行緒可能先觀測到轉移指標已經更新,但是物件尚未復制,為保證一致性,需要在復制和更新物件頭之間插入 membar,在 JVM 關于物件頭更新統一抽象為 CAS 函式,
- CAS 在不同的體系結構實作不同,X86 中采用 cmpxchgl 指令;ARM 中采用 Ldaxr/Stlxr 指令,
4.3、并行復制演算法的流程
并行復制演算法的流程圖如下圖所示:
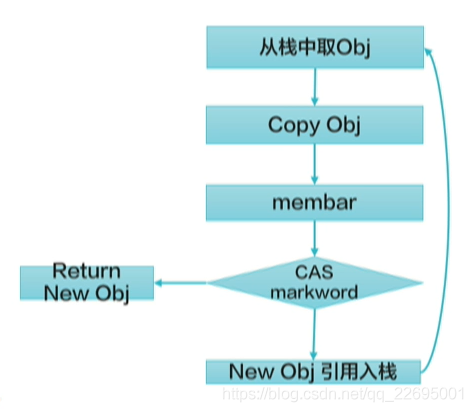
- 拷貝物件 obj 到新的物件位置 new_obj;
- 插入 Memory Barrier,物件 obj 通過 CAS 設定轉移指標,若成功則執行(3),失敗執行(4);
- 將 new_obj 的參考壓入堆疊中,回傳 new_obj;
- 撤銷之前分配的物件,將 cas 成功執行緒的 new_obj 回傳,
在熱點分析中,我們發現復制操作的 60% CPU 消耗在插入 Memory Barrier 上,
4.4、演算法優化減少 membar 之 Q&A
Q:如果不插入 Memory barrier,多個執行緒觀察到記憶體不一致的情況,在什么情況下會引入問題?
A:
- T1:尚未完成物件復制,但是已經將物件入堆疊,
- T2:從 T1 的執行緒堆疊竊取待復制的物件,并對尚未完成復制的物件進行成員變數的復制更新,導致資料不一致,
Q:對于不需要復制成員變數的物件(例如:物件的成員變數全部是非參考型別;物件的成員變數其參考型別全部為NULL,物件本身是原始型別的陣列),還有必要使用 Memory Barrier?
A: NO!
Q: 如何識別這些物件?
A:
- 靜態分析物件:可以發現物件的成員變數全部是非參考型別、原始型別的陣列,已經開源,
- 動態分析物件:通過屏障技術識別,
通過對于并行復制演算法的優化,我們分別在 SPECjbb 和 SPECjvm 達到了較好的預期成果,如下圖所示:
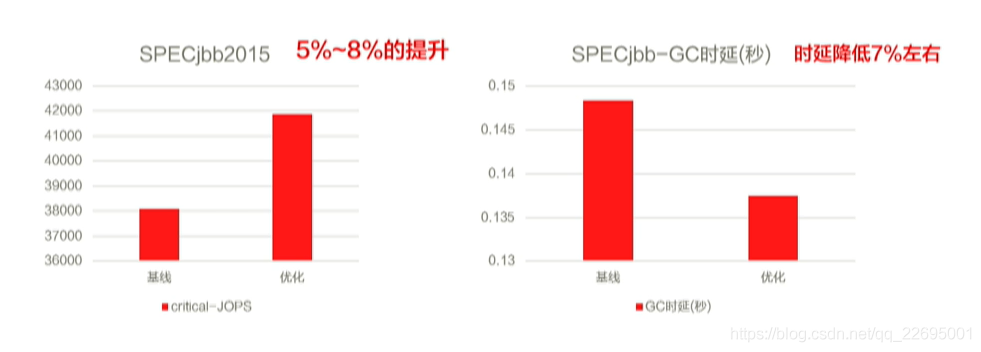
4.5、G1、GC 的優化
針對 G1 Full GC 優化,Full GC 分為 4 個階段,分別是:
- Mark:標記整個堆空間的活躍物件,并記錄活躍物件,
- Prepare:計算每個活躍物件在就地壓縮后的位置,
- Adjust:根據物件新的地址,調整物件成員變數的參考位置,
- Compact:復制物件的記憶體資料,
Compact 階段一般是最為耗時的,涉及到記憶體資料的移動,那么 能否在允許一定浪費空間的前提下,對于活躍物件多的部分磁區不移動或者少移動,從而提高演算法效率? 我們對活躍物件作下圖:
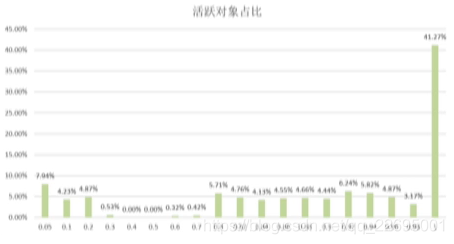
我們可以發現:
- 磁區活躍物件占比符合 U 型分布,
- 對 Benchmark 進行研究,有 41.27% 磁區活躍物件占比在 98%,
- 減少物件的移動在一定程度上也符合強分代理論的假設,
- 測驗發現,對于類似的應用性能有 3~5% 的提高,
我們已經將相關代碼貢獻到社區,歡迎大家前往查看,
4.6、ZGC 的優化
- 畢昇 JDK 11 是第一個在 ARM 架構中支持 ZGC 的 JDK,
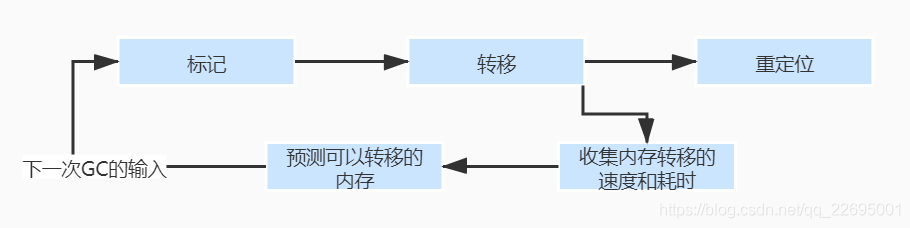
- ZGC 的目標是管理 TB 級記憶體,且垃圾回收的停頓時間控制在 10 毫秒,ZGC 的回收程序包括 3 步,分別是:并發標記(Mark)、并發轉移(Relocate)和并發重定位(Remap),在轉移的程序,為了提高轉移的效率,只有當頁面的垃圾回收空間達到一定比例才會參與轉移,目前的實作中比例通過引數 ZFragmentLimit 控制,該引數的默認值為 25,
- 如何設定 ZFragmentLimit?過大,記憶體浪費;過小,回收效率低下,
- 在 GC 執行的程序中收集轉移的資訊(記憶體轉移的速率、轉移耗時),并預測下一次 GC 可以轉移的記憶體,使用預測值來控制哪些頁面可以參與轉移,如下圖所示:
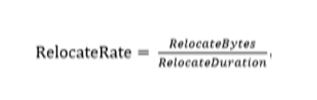
- 計算記憶體的轉移速率:
- 預測本次 GC 的轉移速率:
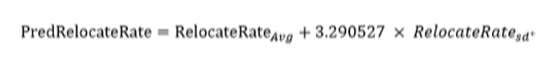
- 使用正態分布,并輔以 99% 的置信度,
- 預測本次 GC 的轉移耗時:

- 預測本次 GC 的轉移位元組:

- 對于 Benchmark 的測驗表明,效果 3~5% 的提升,代碼已經開源,正在往社區同步,
五、JIT 優化——SVE 演算法優化
5.1、SVE 演算法優化相關介紹
SVE(Scalable Vector Extension)是 ARM AArch64 架構的下一代 SIMD 指令集,
- 支持 SVE1 指令集,
- 自動判斷適應 SVE1/NEON
- 支持 Z0~Z31 暫存器,
- 支持從 128~2048 bits 全尺寸 SVE 暫存器,
- 支持 PO~P7 謂詞暫存器,
- 支持大部分自動向量化(SuperWord)Node,
5.2、SVE 演算法優化成果
VectorAPI 新增 Node 全部貢獻到上游社區,畢昇 JDK 目前暫未合入,到目前為止,SVE一共向上游社區提交了 11 個patch,相關代碼超過 3000 行,
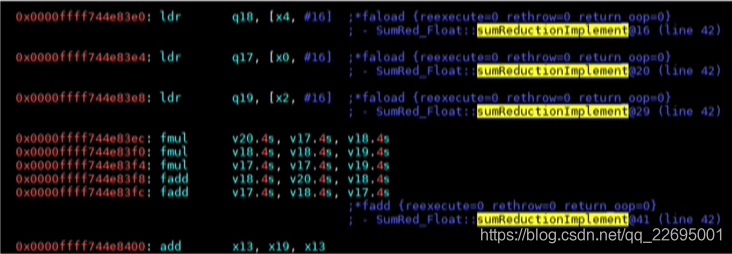
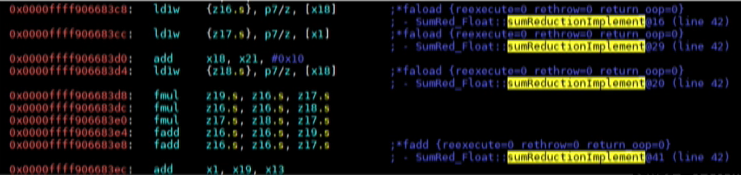
public static float sumReductionImplement(float[] a, float[] b, float[] c, float[] d, float total) {
for (int i = 0; i < a.length; i++) {
d[i] = (a[i] * b[i]) + (a[i] * c[i]) + (b[i] * c[i]);
total += d[i];
}
return total;
}
優化之后的 NEON 機器代碼如下圖所示:
優化之后的 SVE 機器代碼如下圖所示:
六、軟硬協同——鯤鵬 KAE 硬體加速
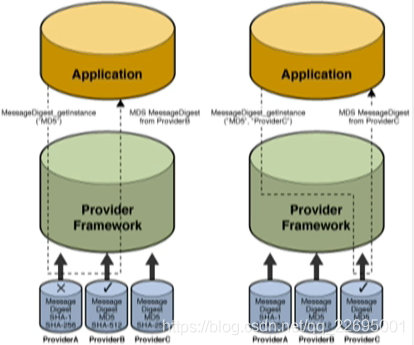
- KAE(Kunpeng Accelerator Engine)是華為鯤鵬服務器提供的硬體加速器,在鯤鵬芯片中有一個獨立的 I/O DIE 用于處理加解密功能,
- 畢昇 JDK 提供了 KAEProvider,充分發揮硬體能力,應用只需要簡單的適配,無須代碼開發,即可使用鯤鵬服務器的硬體能力,提供應用的運行效率,
- 在畢昇 JDK 最新的版本,發布了 4 款加解密演算法(AES、Digest、HMAC、RSA),在針對 Benchmark 的測驗中,部分演算法可以加速 40%,在安全領域將大大節約運行時間,目前和寶蘭德正在進行聯合開發,第二批演算法的支持將于 Q2 發布,
- 加解密方案是基于 JCA(Java Cryptography Architecture,Java 加密架構),是 Java 平臺的重要組成部分,KAE 是基于 JCA 來提供加解密服務,在畢昇 JDK 中稱為 KAEProvider,流程如下圖所示:
- JCA 提供 2 種方式選擇不同的 provider,通過代碼指定或者組態檔,如下:
- 方式 1:使用 Security API 添加 KAE Provider,并設定其優先級,
- 方式 2:修改 jre/lib/security/java.security 檔案,添加 KAE Provider,并設定其優先級,
七、畢昇 JDK 還能帶來什么價值?
- 經過評估和測驗,畢昇 JDK 目前還以社區的特性為基礎 Backport 了一批有價值的特性,
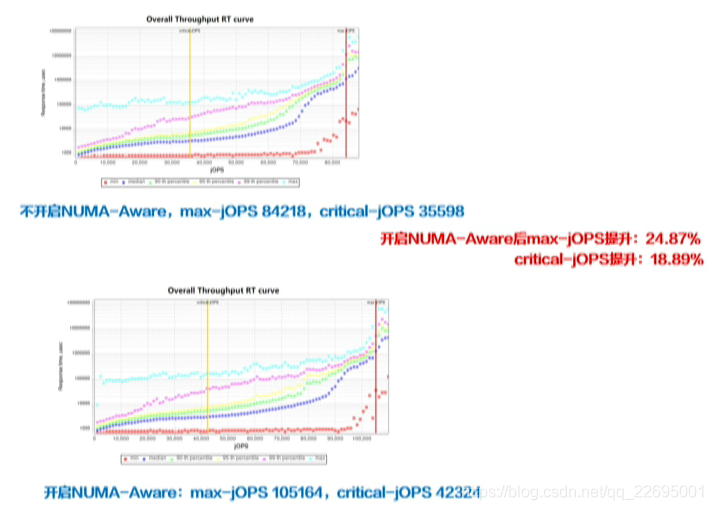
- G1 NUMA一Aware,該特性能充分發揮 NUMA 的優勢,在多核的硬體平臺中效果更佳,畢昇 JDK 中還在社區的基礎上修復了一些問題:例如因為作業系統的執行緒調度導致執行緒在多個節點遷移,遷移在 NUMA 特性上會導致一些記憶體磁區無法得到有效回收;增強了大物件的 NUMA一Aware 功能,效果提升如下圖所示:
- 在 JDK 10 中 AppCDS 的特性,其思路是將 String 物件,類元資料物件存放到一個共享檔案中,讓多個 JVM 行程能夠通過共享資訊,減少類元資料物件的加載、決議,
- 畢昇 JDK 通過移植該特性,測驗發現取得良好的效果,對于大資料的一些場景可以優化接近 10%,
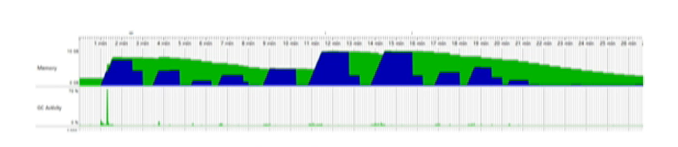
- G1 Uncommit,在記憶體使用較低的情況下,會通過周期性的觸發 GC 進行垃圾回收,并將回收后的記憶體歸還給作業系統,該特性對于云場景中,能明顯的降低記憶體的私有量,畢昇 JDK 在社區版本基礎上,將串行的記憶體釋放修改為并發(在最新的 JDK 16 中也采用了相同的實作),
在開啟 G1 Uncommit 后,我們可以在下圖中看到,在記憶體不使用的場景中會穩步下降:
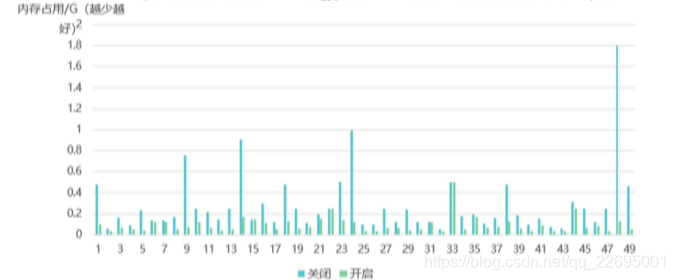
而在實際的業務場景中,效果更是顯而易見的,如下圖所示:
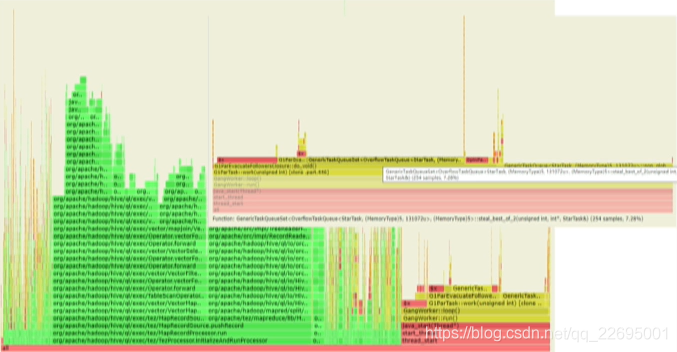
- 并行任務竊取機制優化,在一些應用發現任務竊取占比很高,對于并行任務竊取 Google 對社區貢獻了一個有價值的設計,極大的優化了并行任務竊取,在畢昇 JDK 中,PS、ParNew、G1、Shenandoah 等都因此而受益,
- 目前我們正在針對多核的服務器優化任務竊取,待成熟后會繼續開源,
八、畢昇 JDK 的未來發展
8.1、即將面世的功能
- 完善 KAE 硬體加速演算法,預計 Q2 發布,
- G1 GC 中并行 NUMA-Aware、Full GC 將落地于畢昇 JDK8,Q2,
- jmap 增強,針對 CMS 做并行 dump,
8.2、未來方向
- 積極參與社區中 SVE、Vector API 特性的開發、演進,目前提交代碼超 3000 行,
- 優化記憶體管理,正在進行:ZGC 分代、Thread Local GC、AOT 等專案,
九、如何獲得畢昇 JDK 及幫助?
下載 JDK 8 和 JDK 11:https://kunpeng.huawei.com/#/developer/devkit/complier?data=JDK

9.1、JDK 8 的代碼倉
https://gitee.com/openeuler/bishengjdk-8
9.2、JDK 11 的代碼倉
https://gitee.com/openeuler/bishengjdk-11
總結
本文我們給大家介紹了何為畢昇 JDK,整體的發展史如何,是在什么樣的形勢下華為要做畢昇 JDK,在底層的優化方面又做到了哪些?同時又潛藏了哪些值得開發的價值?正為華為編譯器資深技術專家彭成寒老師所講,把數字世界帶入每個人、每個家庭、每個組織,構建萬物互聯的智能世界,這是我們的追求!
我是白鹿,一個不懈奮斗的程式猿,望本文能對你有所裨益,歡迎大家的一鍵三連!若有其他問題、建議或者補充可以留言在文章下方,感謝大家的支持!
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/286262.html
標籤:其他