目錄
- 一、簡介
- 二、方法
- 1.任務
- 2. 模型架構
- Utterance Representation
- Turns-aware Aggregation
- Matching Attention Flow
- Response Matching
- Attentive Turns Aggregation
- 三、實驗
- 1. 資料集
- 2. 評價指標
- 3. 實驗設定
- 4. 實驗結果
- 四、結果分析
- 1. 實驗結果分析
- 2. 注意力可視化
- 3. 消融實驗.
- 4. 錯誤分析

DUA模型: 使用深度話語聚合建模多輪對話
paper地址:https://arxiv.org/pdf/1806.09102v2.pdf
代碼地址:https://github.com/cooelf/DeepUtteranceAggregation
一、簡介
基于檢索的多輪對話回復選擇的相關作業只是簡單地將對話話語串聯起來,忽略了先前話語之間的互動作用,
本文使用提出的DUA深度話語聚合模型將先前的話語轉化為背景關系,以形成細粒度的背景關系表示,然后引入自匹配注意來傳遞每句話中的重要資訊,對每個精細化的話語進行匹配,通過注意轉向聚合得到最終的匹配分數,
實驗結果表明,在三個多回合對話基準上,包括一個新引入的電子商務對話語料庫,本模型優于當時現有的方法,
二、方法
1.任務
多輪對話回復檢索任務中的每個會話可以描述為一個< C, R, Y >的三元組, C = U 1 , … , U t C = {U_1,…, U_t} C=U1?,…,Ut?是會話背景關系,{Uk}表示第k個話語,R是會話的回復,Y屬于{0,1},其中 Y i = 1 Y_i= 1 Yi?=1表示回復是適當的,否則 Y i = 0 Y_i= 0 Yi?=0,
目標:在< C, R, Y >上建立一個鑒別器 F ( ? , ? ) F(·, ·) F(?,?),對于每個背景關系回復對{C, R},$ F(C, R)$度量對的匹配分數,
2. 模型架構
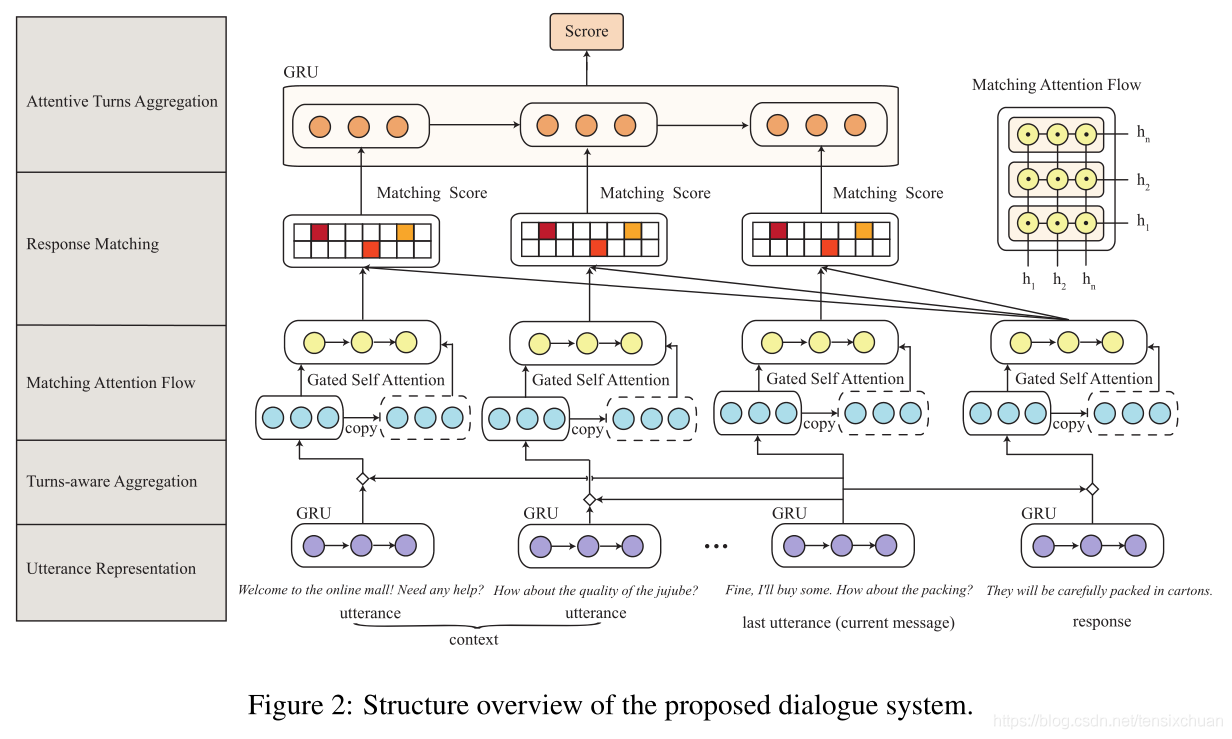
DUA中有五個模塊:
- Utterance Representation,每一個話語或回復被輸入到第一個模塊,形成一個話語或回復嵌入,
- Turns-aware Aggregation,第二模塊將最后一句話和前面的一句話結合起來,
- Matching Attention Flow,第三個模塊過濾冗余資訊,挖掘話語和回復中的顯著特征,
- Response Matching,第四個模塊在單詞和話語兩級匹配回復和每個話語,為卷積神經網路(CNN)編碼成匹配向量,
- Attentive Turns Aggregation,在最后一個模塊中,將匹配向量按照背景關系中的話語的時間順序傳遞給GRU,得到最終的匹配得分{U, R},
優勢:
- 在對話中最重要的最后一句話在前一句話中被特別融合,從而使最后一句話中的關鍵指導資訊在語意上更加切題,
- 在每句話語中,突出的資訊都能被突出,而冗余的部分在一定程度上被忽略,這兩者都能有效地指導后續的回復匹配,
- 第三,經過細心的轉向聚合后,再次對會話中的連接進行累積,計算匹配分數,
Utterance Representation
給定背景關系回復對{C, R},其背景關系被分割為話語,C = {U1,…, Ut},一個查找表用于將每個單詞映射到一個低維向量, n u n_u nu?和 n r n_r nr?表示第k個話語和回復的長度, U k U_k Uk?、 R R R可以表示為 U k = [ u 1 , … , u n u ] Uk= [u_1,…,u_{n_u}] Uk=[u1?,…,unu??], R = [ r 1 , … , r n r ] R = [r1,…,r_{n_r}] R=[r1,…,rnr??],其中ui, ri是話語和回復中的第i個單詞,
用GRU沿著單詞序列
U
k
U_k
Uk?和
R
R
R傳遞資訊,對每個話語和回復進行編碼,令
H
k
=
[
h
1
,
…
,
h
n
]
H_k= [h_1,…, h_n]
Hk?=[h1?,…,hn?]為輸入序列的隱藏狀態
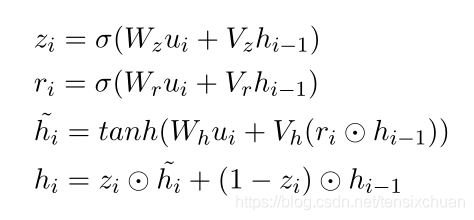
Turns-aware Aggregation
以上述方式對話語序列和回復進行編碼的缺點是,會話中的所有話語都得到了公平的處理,未能挖掘出最后一句話語與前一句話語之間的聯系,為此,提出了一種第一階段的回合感知聚合機制,
S
=
[
S
1
,
…
,
S
t
,
S
r
]
S = [S_1,…, S_t, S_r]
S=[S1?,…,St?,Sr?]表示話語和回復的表征,假設
F
=
[
F
1
,
…
,
F
t
,
F
r
]
F = [F_1,…, F_t, F_r]
F=[F1?,…,Ft?,Fr?]是每個
S
j
∈
S
S_j∈S
Sj?∈S與最后一個話語
S
t
S_t
St?的融合,對于每
個
?
j
∈
1
,
…
,
r
個?j∈{1,…, r}
個?j∈1,…,r,
F
j
∈
F
F_j∈F
Fj?∈F:
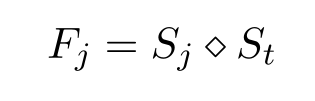
這里采用了一個簡單的連接策略(串聯),通過聚合得到了回合感知的表示F,
Matching Attention Flow
經過 turns-aware aggregation后,前一個話語和回復的表征由最后一個話語進行細化,然而,這些序列相當長且冗余,這使得提取關鍵資訊變得困難,為了解決這個問題,本文采用了一種自匹配的注意機制,直接將融合的表征與自身進行匹配,動態地從輸入序列中收集資訊,并過濾冗余資訊,輸入
?
F
=
[
f
1
,
…
,
f
n
]
∈
F
?F = [f_1,…, f_n]∈F
?F=[f1?,…,fn?]∈F,輸出
P
=
[
p
1
,
…
p
n
]
P = [p_1,…p_n]
P=[p1?,…pn?]
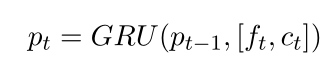
ct就是自匹配注意力的結果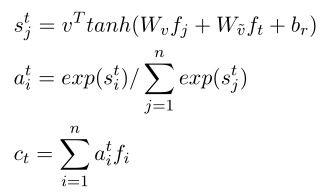
其中 v T v^T vT是隨機初始化并聯合訓練的背景關系矩陣
自匹配注意通過融合前一段和后一段話語,根據當前詞和整個話語表征,從話語中定位重要部分
Response Matching
使用詞語級和話語級表示構建兩個匹配矩陣,并使用CNN從矩陣中獲取顯著匹配資訊,假設我們在單詞級和話語級對每個話語-回復對有匹配矩陣m1和m2,然后?k, Uk∈U,?(i, j)分別定義m1和m2的第(i, j)個元素:
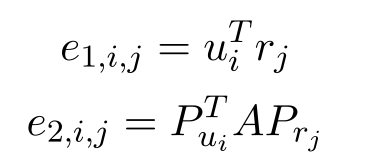
其中
p
u
i
p_{u_i}
pui??和
p
r
j
p_{r_j}
prj??分別表示匹配注意流后的話語輸出和回復輸出,
A
∈
R
c
×
c
A∈R^{c×c}
A∈Rc×c是一個線性變換矩陣,
對于每一個表述,首先對M1和M2進行卷積運算,然后進行最大池化運算,卷積層用于提取和組合相鄰單詞的區域特征,接下來的最大池化層形成當前單詞的表示,對于卷積運算,利用了一組可變大小l?l和偏置b的濾波器矩陣K,該濾波器將單詞矩陣M1和M2轉換為另外兩個矩陣
M
1
c
M_{1c}
M1c?和
M
2
c
M_{2c}
M2c?,?i, k∈(1,2),變換矩陣
M
k
c
M_{kc}
Mkc?定義為:
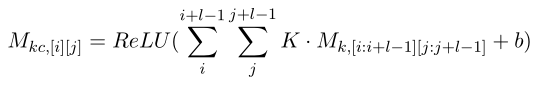
其中I和j分別指向第i行第j列的元素,接下來,采用最大池化操作,將池化后的兩個矩陣扁平化并連接,得到會話中第p個話語的表示mp:
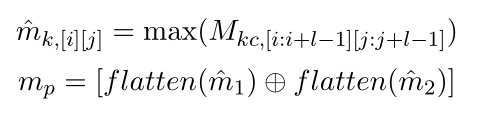
其中flatten()為扁平化運算,⊕為級聯運算,
Attentive Turns Aggregation
為了對最后階段的attentive turns 注意轉向匹配資訊進行聚合,CNN的輸出M = [m1,…, mn],給GRU得到Hm= [hm1,…]定義為:
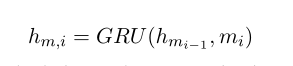
v
f
=
L
(
H
m
)
v_f= L(H_m)
vf?=L(Hm?)為注意操作
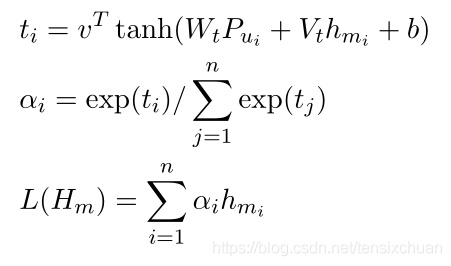
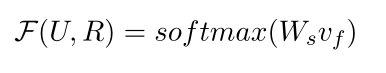
在訓練階段,根據交叉熵損失更新模型引數,
需要注意的是,Turns-aware Aggregation 回合意識聚合和Attentive Turns Aggregation注意回合聚合可以被視為話語互動的兩個階段(我們將這兩個程序稱為“語境融合”),.前者是在話語表征后對更豐富的輪覺資訊的簡單組合,后者是在注意學習后對每個話語本身和回復的匹配狀態進行聚合,
三、實驗
1. 資料集
-
Ubuntu Dialogue Corpus
-
Douban Conversation Corpus
-
E-commerce Dialogue Corpus
2. 評價指標
-
Rn@k,n個候選項中k處的查全率
-
MAP ,Mean Average Precision,平均準確率,
例如,假設有兩個對話,對話1有4個相關回復,對話2有5個相關回復,某系統對于對話1檢索出4個相關回復,其rank分別為1, 2, 4, 7;對于對話2檢索出3個相關回復,其rank分別為1,3,5,對于對話1,平均準確率為(1/1+2/2+3/4+4/7)/4=0.83,對于對話2,平均準確率為(1/1+2/3+3/5+0+0)/5=0.45,則MAP= (0.83+0.45)/2=0.64,
-
MRR ,Mean Reciprocal Rank,把標準答案在被評價系統給出結果中的排序取倒數作為它的準確度,再對所有的問題取平均,
-
P@1,Precision-at-one
3. 實驗設定
-
將最多的話語數限定為10個,每個話語最多包含50個單詞,在必要時應用截斷和零填充,
-
對訓練資料進行word embedding 預訓練,維數為200
-
模型是使用Theano實作的,使用ADAM進行優化
-
batch size為200,初始學習率為0.001,卷積和池化的視窗大小為(3,3),GRU的隱藏單位數設定為200,
-
所有的模型都運行在單個GPU (GeForce GTX 1080ti)上
-
運行所有的模型直到5個epoch,并選擇在驗證中獲得最佳結果的模型
4. 實驗結果
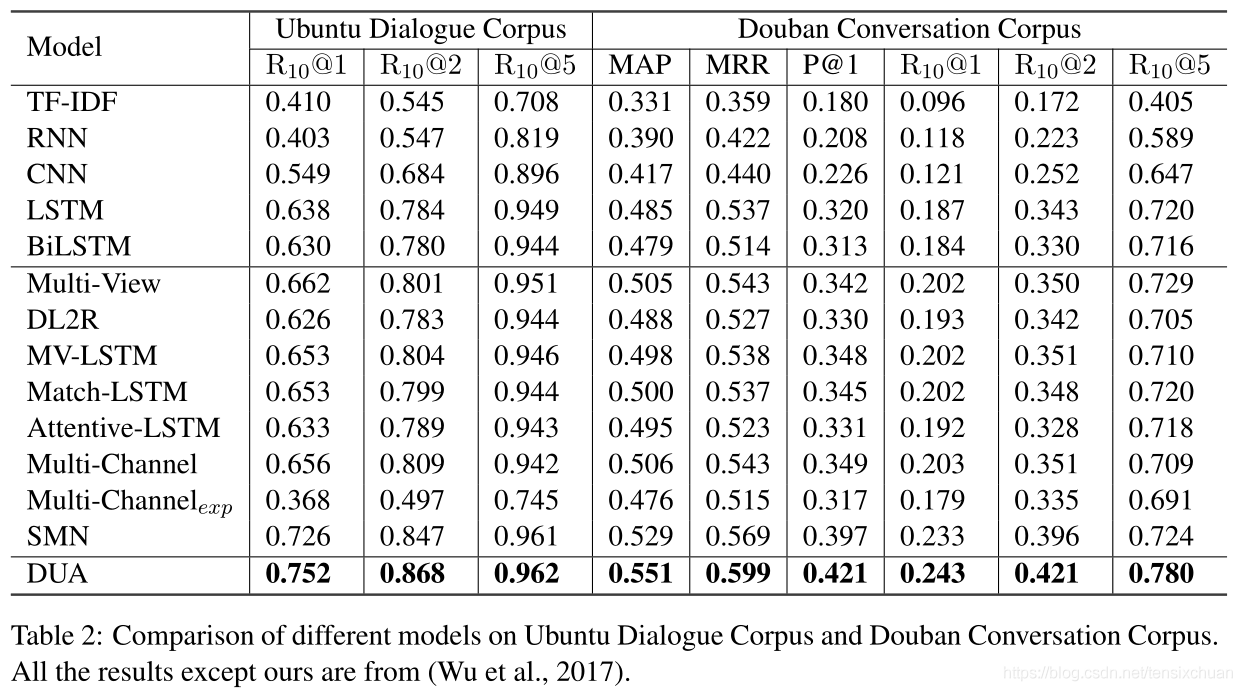
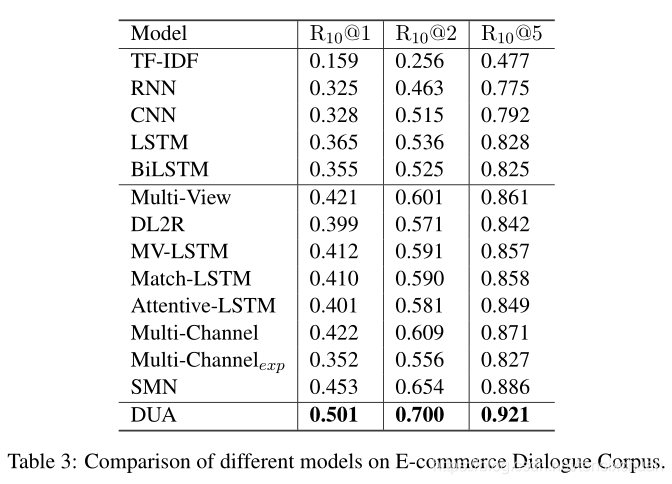
四、結果分析
1. 實驗結果分析
-
以前連接話語的單個匹配模型,表現得比DUA差得多,顯示話語關系的重要性和簡單地將話語連接在一起并不是多輪對話建模的合適解決方案,
-
DUA與當前最先進的多輪回復匹配模型SMN相比取得了很大的進步(ECD 語料庫上的 R10@1 為 4.8%),SMN匹配每個話語和回復,無需輪流感知聚合和匹配注意力流,這些比較表明本文的背景關系組合方法的有效性,DUA可以很好地模仿向客戶服務的真實對話,而不僅僅是擅長閑聊,
-
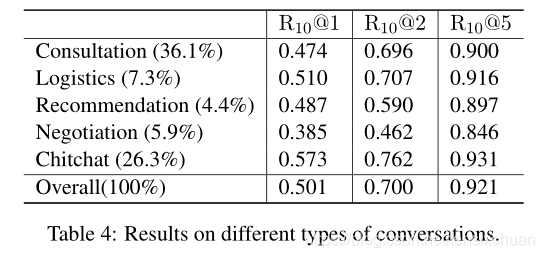
將ECD測驗集分為5類:咨詢、物流、推薦、談判、閑聊,表4顯示了統計資料和模型結果,閑聊和物流的型別往往很容易處理,建議、咨詢和談判往往涉及到不同的話題(如相關商品)和意圖,相對來說更難回復,這使得本文的語料庫比以往的聊天或問答語料庫更具挑戰性,
2. 注意力可視化
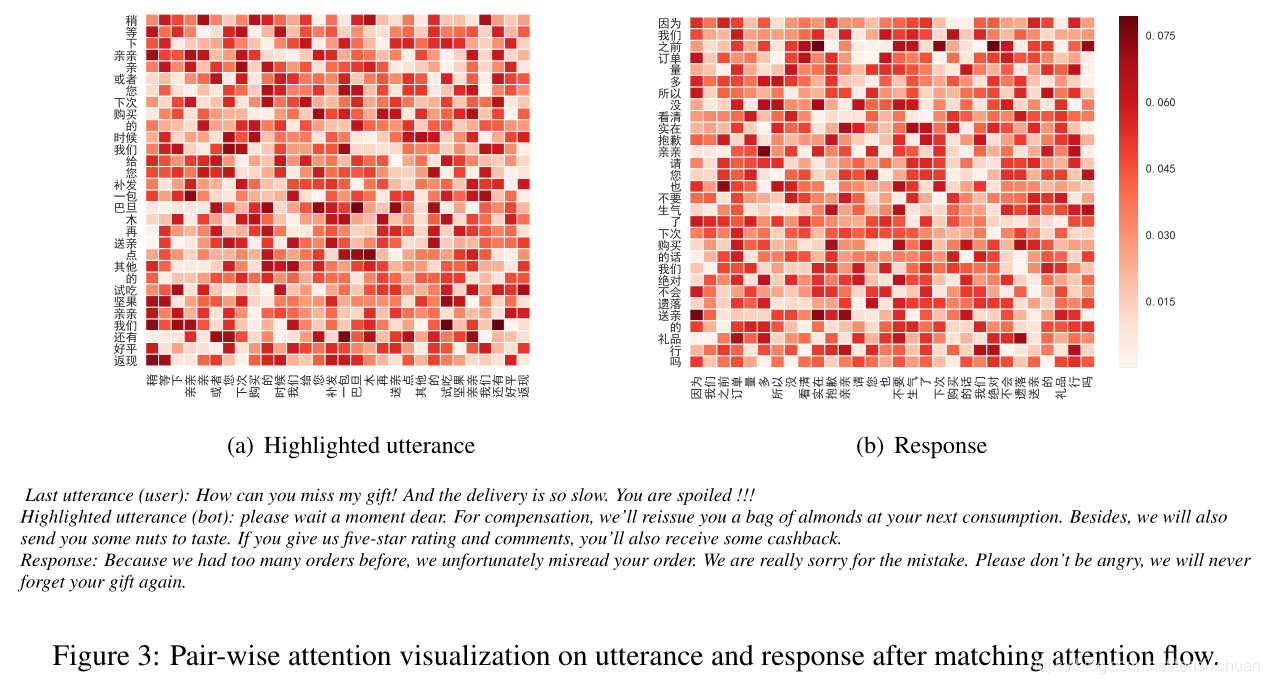
從ECD資料的驗證集來看,圖3分別顯示了一個重要話語(在回復匹配組件中權重很高)和回復的詞權值,我們看到模型可以準確的從話語中提煉出關鍵,{下次消費,再發,一包杏仁,送你,一些堅果,回款},并從回復{之前訂單太多,真的很抱歉,別生氣,你的禮物},當用戶抱怨缺少禮物、傳遞速度慢時,我們的模型能夠在自匹配后區分用戶的意圖,并根據所呈現話語的癥結本質上尋找合適的回應,這說明我們的模型在匹配注意流后的關鍵點選擇上是有效的,可以引導回復匹配層收集更多的相關片段,
3. 消融實驗.
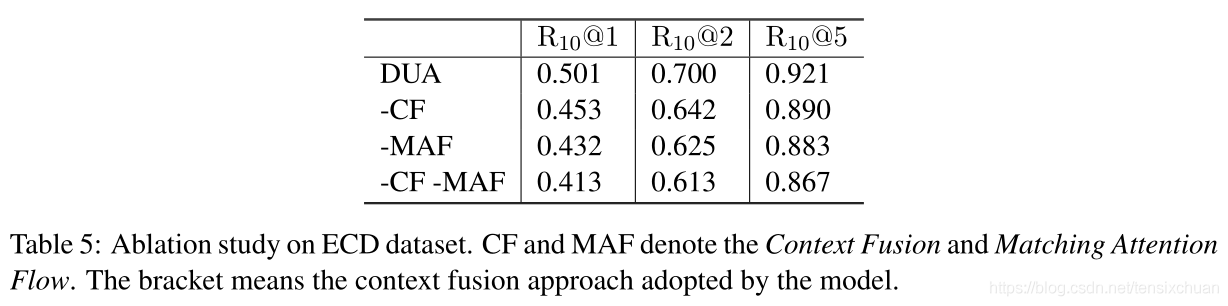
-
洗掉Matching Attention Flow匹配注意流時,觀察到最大的下降(6.9% R10@1),這表明繪制每個話語的關鍵很重要,
-
洗掉Context Fusion 背景關系融合,包括第一回合感知聚合(第一階段聚合)和替換最后一階段聚合(最后階段聚合),用多層感知器進行匹配積累時,性能也會顯著下降(4.8% R10@1),這表明話語關系很重要,
-
在沒有Context Fusion 背景關系融合與Matching Attention Flow匹配注意流機制的情況下,該模型的表現最差,驗證了該機制確實從根本上改善了背景關系表示
4. 錯誤分析
-
Multiple intentions多意圖,在電子商務會話中,用戶極有可能在單個訊息中表達不同的意圖,這是除了不同商品之間的會話型別不同之外,有別于以往的多輪會話語料庫的另一大區別,例如:{用戶:那護膚產品的包裝呢?順便問一下,請問是哪個快遞公司負責發貨,我能收到貨物的時間是多久?} 這將嚴重混淆模型,即給定的回應可能優先于某個方面或另一個方面,
-
Topic errors話題錯誤,模型根據與背景關系的語意相似度檢索回應,沒有特別注意會話主題,如當前討論的商品,當對話涉及到幾種商品時,例如:{用戶:堅果怎么樣?機器人:堅果不錯,用戶:好吧,那粽子呢?},模型可能會給出與背景關系更相關的堅果的回應,而不是粽子,
-
Multiple suitable responses多個正確回復,由于精確匹配的嚴格限制,有多個正確回復時某些正確回復可能會在評估是判定為錯誤
參考:IR的評價指標-MAP,NDCG和MRR
有幫助的話可以點個贊喔~

轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/286265.html
標籤:其他