文章目錄
- 1 Local模式
- 2 Standalone模式
- 2.1 上傳軟體
- 2.2 修改組態檔
- 2.3 啟動集群
- 3 Yarn模式
- 3.1 上傳軟體
- 2.2 修改組態檔
- 2.3 啟動集群
- 4 對比
Spark部署模式主要有四種:Local模式(單機模式)、Standalone模式(使用Spark自帶的簡單集群管理器)、YARN模式(使用YARN作為集群管理器)和Mesos模式(使用Mesos作為集群管理器),甚至還可以在學習階段使用Windows模式,
spark下載地址:http://spark.apache.org/downloads.html
1 Local模式
Spark的Local模式就是單機模式,沒有進行任務的集群環境配置,僅僅將軟體包進行解壓就可以使用了,通常用于學習階段,
解壓 -> 切換目錄 -> 重命名
tar -zxvf spark-3.0.0-bin-hadoop3.2.tgz -C /opt/module
cd /opt/module
mv spark-3.0.0-bin-hadoop3.2 spark-local
進入到spark-local目錄,并打開local模式
cd spark-local/
bin/spark-shel
執行成功會出現spark的Logo標志
在/opt/module/spark-local/data目錄下創建一個data.txt檔案,里面隨便寫幾行單詞,每個單詞用空格分開,在命令列中執行如下命令:
sc.textFile("data/word.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect

能夠正確輸出結果,表示單機模式可以正常使用,
這種模式很少使用,一般就是作為hello world使用的
2 Standalone模式
獨立部署(Standalone)模式由 Spark 自身提供計算資源,無需其他框架提供資源,這種方式降低了和其他第三方資源框架的耦合性,獨立性非常強,
2.1 上傳軟體
解壓 -> 切換目錄 -> 重命名
tar -zxvf spark-3.0.0-bin-hadoop3.2.tgz -C /opt/module
cd /opt/module
mv spark-3.0.0-bin-hadoop3.2 spark-standalone
2.2 修改組態檔
復制組態檔slaves.template,并添加work節點,以你的集群環境的hostname為準
cp slaves.template slaves
hadoop102
hadoop103
hadoop104
復制組態檔 spark-env.sh.template,并添加JDK資訊和設定master節點的位置
mv spark-env.sh.template spark-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_144
SPARK_MASTER_HOST=hadoop102
SPARK_MASTER_PORT=7077
把spark-standalone整個檔案夾分發到集群其他節點
xsync spark-standalone
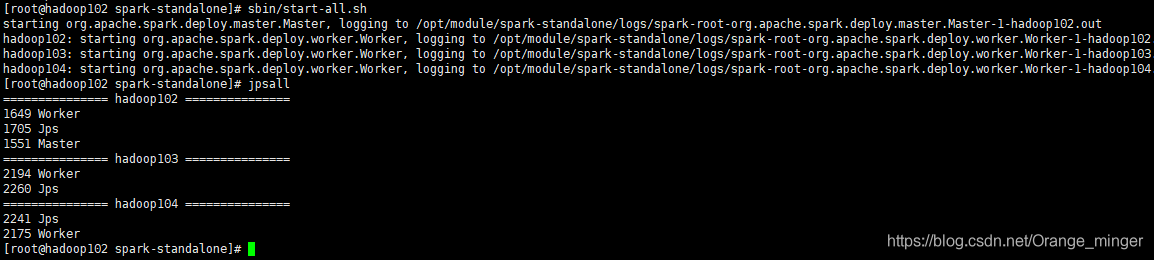
2.3 啟動集群
當看到主節點有Master和Worker兩個行程,并且從節點有Worker行程表示啟動成功
3 Yarn模式
3.1 上傳軟體
解壓 -> 切換目錄 -> 重命名
tar -zxvf spark-3.0.0-bin-hadoop3.2.tgz -C /opt/module
cd /opt/module
mv spark-3.0.0-bin-hadoop3.2 spark-yarn
2.2 修改組態檔
修改 hadoop 組態檔/opt/module/hadoop/etc/hadoop/yarn-site.xml
<!--是否啟動一個執行緒檢查每個任務正使用的物理記憶體量,如果任務超出分配值,則直接將其殺掉,默認是 true -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!--是否啟動一個執行緒檢查每個任務正使用的虛擬記憶體量,如果任務超出分配值,則直接將其殺掉,默認是 true -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
修改 conf/spark-env.sh,添加 JAVA_HOME 和 YARN_CONF_DIR 配置
export JAVA_HOME=/opt/module/jdk1.8.0_144
YARN_CONF_DIR=/opt/module/hadoop/etc/hadoop
2.3 啟動集群
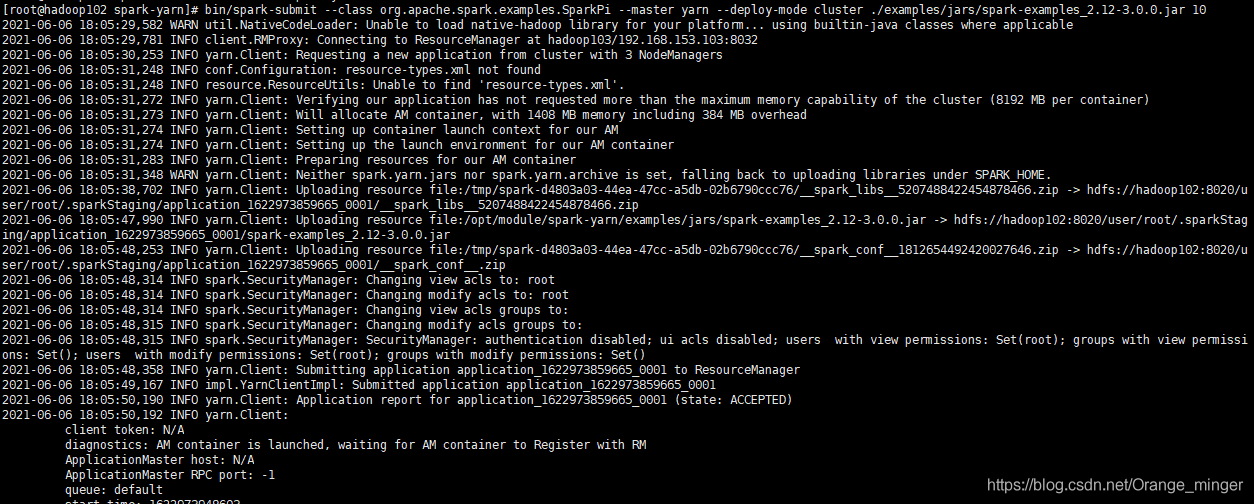
首先需要啟動HDFS和YARN集群,然后在spark-yarn目錄下執行命令
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
./examples/jars/spark-examples_2.12-3.0.0.jar \
10
可以正確輸出以下內容表示環境搭建正確
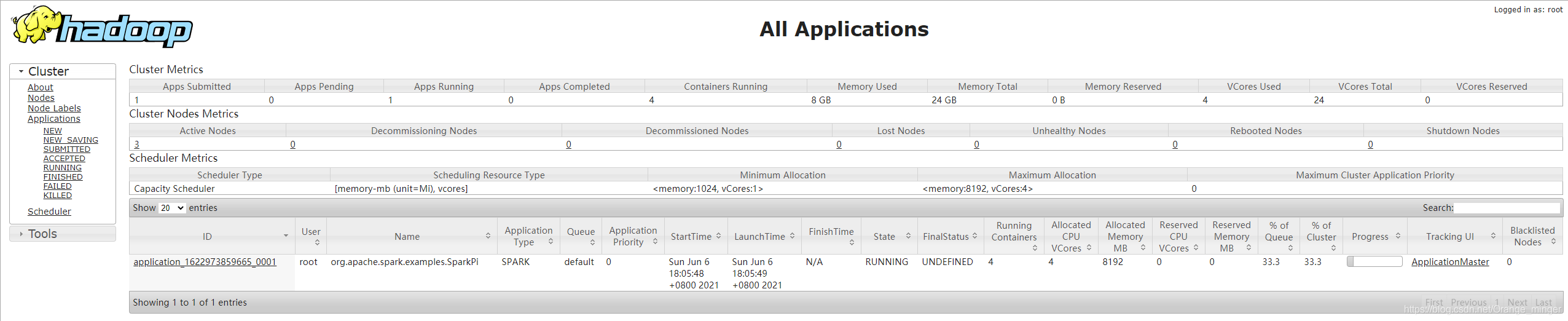
打開hadoop的資源管理器可以看到任務的輸出結果
4 對比
Standalone模式
與MapReduce1.0框架類似,Spark框架本身也自帶了完整的資源調度管理服務,可以獨立部署到一個集群中,而不需要依賴其他系統來為其提供資源管理調度服務,當采用 Standalone 模式時,在架構的設計上,Spark與MapReduce1.0完全一致,都是由一個Master和若干個Slave構成,并且以槽(Slot)作為資源分配單位,不同的是,Spark中的槽不再像MapReduce1.0那樣分為Map 槽和Reduce槽,而是只設計了統一的一種槽提供給各種任務來使用,
Spark on YARN模式
Spark可運行于YARN之上,與Hadoop進行統一部署,即“Spark on YARN”,其架構如圖3-15所示,資源管理和調度依賴YARN,分布式存盤則依賴HDFS,
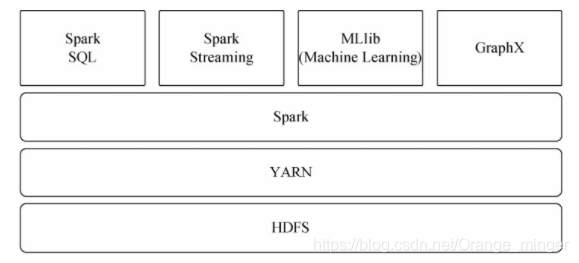
三種模式最常用的就是Yarn模式,依托于Hadoop的Yarn做任務調度,可以完美地兼容其它框架,此模式下不要在每臺服務器安裝spark,僅需要在其中一臺服務器安裝spark,在執行任務時,Yarn集群會將任務分發到所有集群的服務器上,

轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/286267.html
標籤:其他