歡迎小伙伴訂閱我的新專欄“Java高薪面試寶典”,在這里我將和大家分享在Java面試中常見的核心考點和技術,為大家的Java學習之路助一臂之力!
HashMap高頻面試題
1,Map介面和List介面是什么關系?
2、Map有哪些常用的實作類?
3、請闡述HashMap的put程序?
4、鏈表中是按照怎樣的順序存放資料的?
5、Hash(key)方法是如何實作的?
6、為什么HashMap的容量一直是2的倍數?
7、Hash沖突如何解決?
8、HashMap是如何擴容的?
9、擴容后元素怎么存放的?
10、JDK1.7和JDK1.8對HashMap的實作比較
Hello,你好呀,我是灰小猿!一個超會寫bug的程式猿!
Map介面大家應該都聽說過吧?它是在Java中對鍵值對進行存盤的一種常用方式,同樣其中的HashMap我相信大家應該也不會陌生,一說到HashMap,我想稍微知道點的小伙伴應該都說是:這是存盤鍵值對的,存盤方式是陣列加鏈表的形式,但是其中真正是如何進行存盤以及它的底層架構是如何實作的,這些你有了解嗎?
可能很多小伙伴該說了,我只需要知道它怎么使用就可以了,不需要知道它的底層實作,但其實恰恰相反,只知道它怎么使用是完全不夠的,而且在Java開發的面試之中,HashMap底層實作的提問和考察已經是司空見慣的了,所以今天我就來和大家分析一下Map介面的詳細使用以及HashMap的底層是如何實作的?
小伙伴們慢慢往下看,看完絕對會讓你識訓滿滿的!
1,Map介面和List介面是什么關系?
對于這個問題,如果非要說這兩個介面之間存在怎樣的關系的話,那無非就只有一個,就都是集合,存放資料的,在其他上面,Map介面和List介面的聯系其實并不大,為什么這么說?
先來看List介面,關于List介面我在之前也和大家提到過,《【Java高薪面試寶典】Day2、談一談List介面的實作?》,它是繼承于Collection介面的,是Collection介面的子介面,只是用于對資料的單列存盤,繼承關系如下圖:
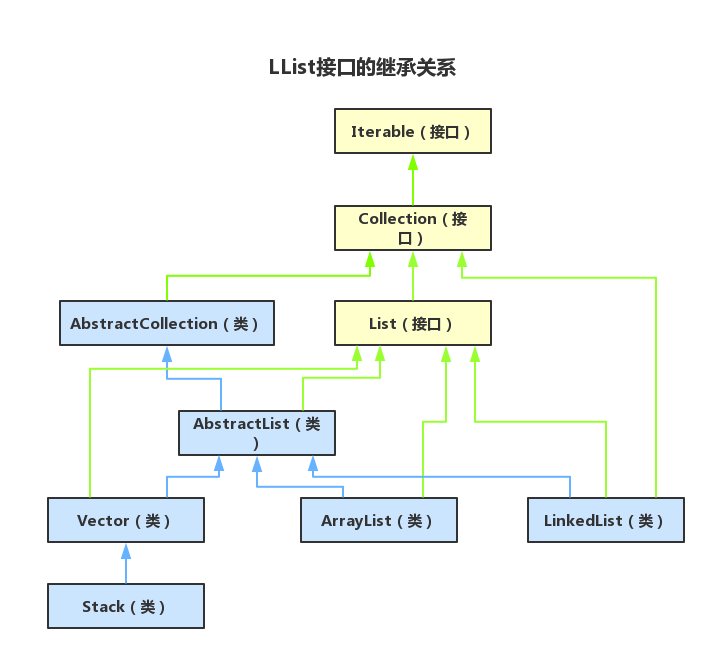
而Map介面是一個頂層介面,下面包含了很多不同的實作類,它是用于對鍵值對(key:value)進行存盤的,實作關系如下圖:
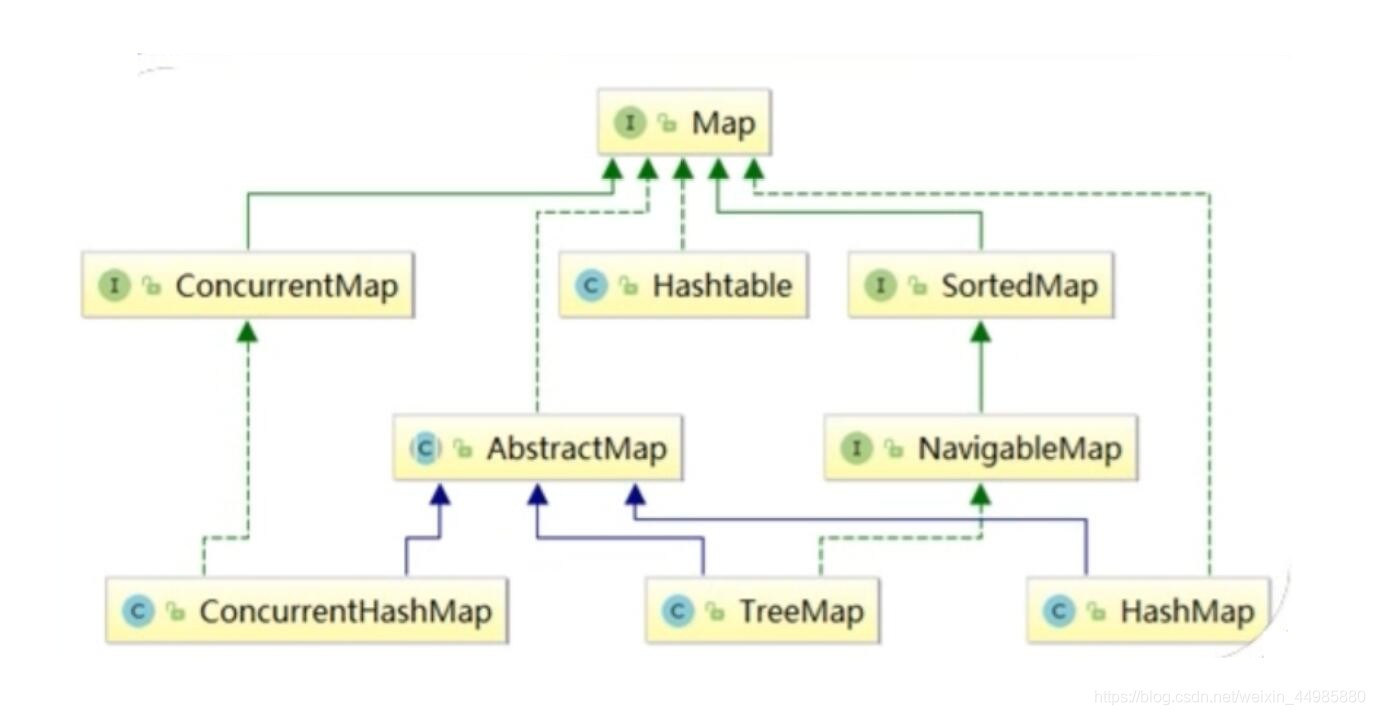
所以Map介面和List介面的關系和使用不要混淆了!
2、Map有哪些常用的實作類?
上面關于Map的繼承結構我們已經了解了,我們也看了其中很多不同的實作類,這些類很多也是我們比較熟悉的,比如HashMap、TreeMap以及HashTable,在面試的時候,面試官往往就還會問,Map介面下有哪些常用的實作類以及它們的作用,那么接下來我們就來對這幾個介面進行簡單的介紹和分析一下,
HashMap:上面也說了,HashMap的底層實作是陣列+鏈表+紅黑樹的形式的,同時它的陣列的默認初始容量是16、擴容因子為0.75,每次采用2倍的擴容,也就是說,每當我們陣列中的存盤容量達到75%的時候,就需要對陣列容量進行2倍的擴容,
HashTable:HashTable介面是執行緒安全,但是很早之前有使用,現在幾乎屬于一個遺留類了,在開發中不建議使用,
ConcurrentHashMap:這是現階段使用使用比較多的一種執行緒安全的Map實作類,在1.7以前使用的是分段鎖機制實作的執行緒安全的,但是在1.8以后使用synchronized關鍵字實作的執行緒安全,
其中關于HashMap的考察和提問在面試中是最頻繁的,這也是在日常開發中最應該深入理解和掌握的,所以接下來就主要和大家詳細分析一下HashMap的實作原理以及面試中的常考問題,
3、請闡述HashMap的put程序?
我們知道HaahMap使用put的方式進行資料的存盤,其中有兩個引數,分別是key和value,那么關于這個鍵值對是如何進行儲存的呢?我們接下來進行分析一下,
在HashMap中使用的是陣列+鏈表的實作方式,在HashMap的上層使用陣列的形式對“相同”的key進行存盤,下層對相應的key和value使用鏈表的形式進行鏈接和存盤,
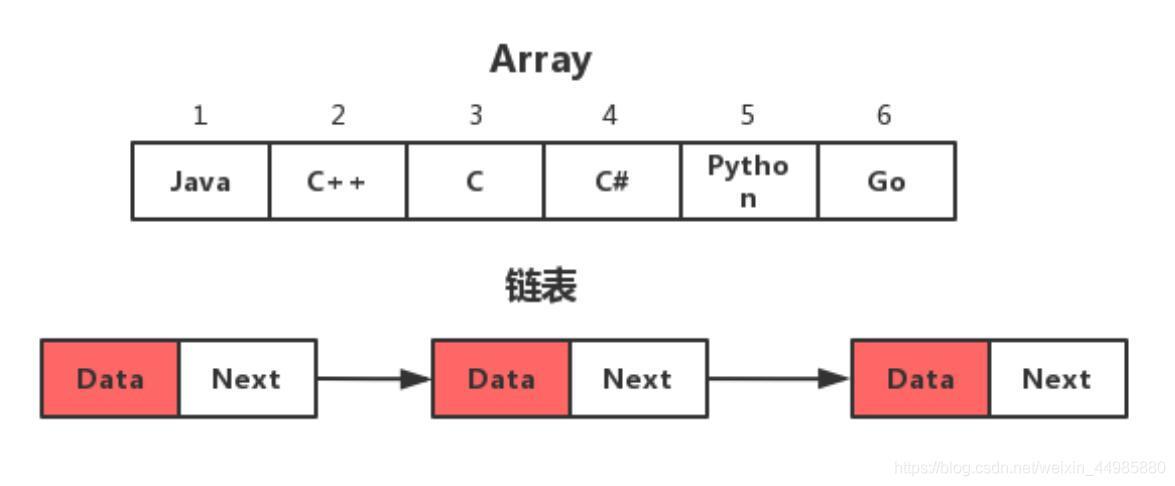
注意:這里所說的相同并不一定是key的數值相同,而是存在某種相同的特征,具體是哪種特征罵我們繼續往下看!
HashMap將將要存盤的值按照key計算其對應的陣列下標,如果對應的陣列下標的位置上是沒有元素的,那么就將存盤的元素存放上去,但是如果該位置上已經存在元素了,那么這就需要用到我們上面所說的鏈表存盤了,將資料按照鏈表的存盤順序依次向下存盤就可以了,這就是put的簡單程序,存盤結果如下:
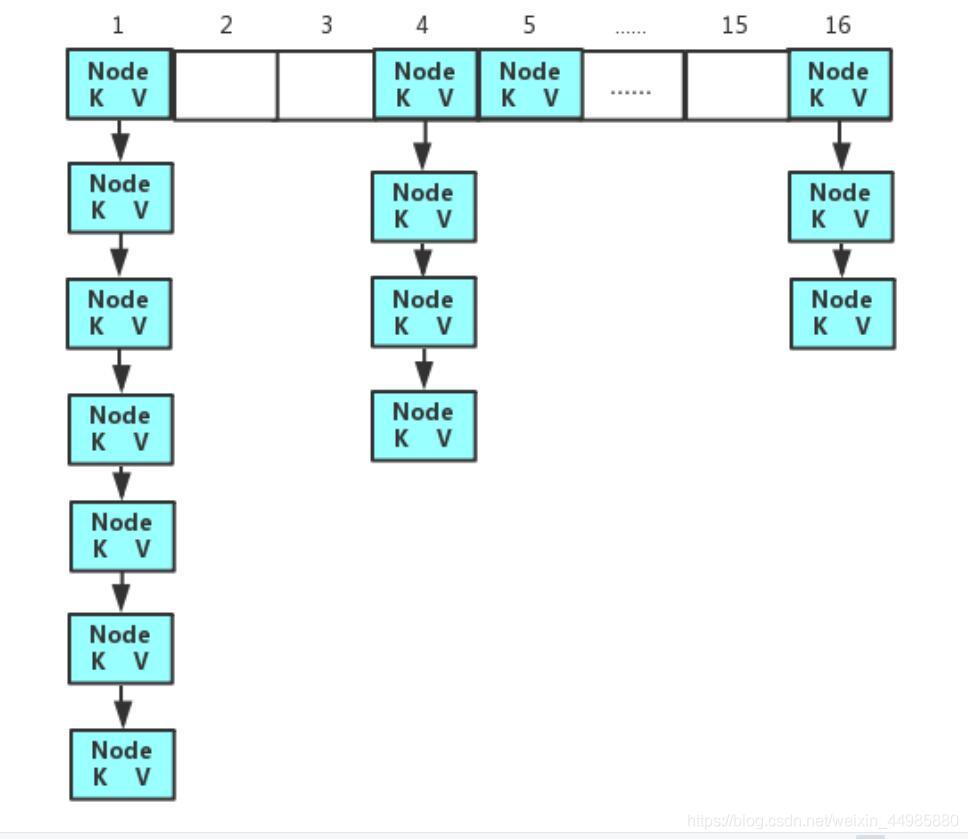
但是我們有時候存盤的資料會很多,那么如果一直使用鏈表的形式進行資料的存盤的話就或造成我們的鏈表的長度非常大,這樣無論在進行洗掉還是在進行插入操作都是十分麻煩的,因此對于這種情況應該怎么辦呢?
這里就涉及到了一個鏈表中資料存盤時,進行“樹化”和“鏈化”的一個程序,那么什么是“樹化”和“鏈化”呢?
當我們在對鍵值對進行存盤的時候,如果我們在同一個陣列下標下存盤的資料過多的話,就會造成我們的鏈表長度過長,導致進行洗掉和插入操作比較麻煩,所以在java中規定,當鏈表長度大于8時,我們會對鏈表進行“樹化”操作,將其轉換成一顆紅黑樹(一種二叉樹,左邊節點的值小于根節點,右邊節點的值大于根節點),這樣我們在對元素進行查找時,就類似于進行二分查找了,這樣的查找效率就會大大增加,
但是當我們進行洗掉操作,將其中的某些節點洗掉了之后,鏈表的長度不再大于8了,這個時候怎么辦?難道就要趕緊將紅黑樹轉化為鏈表的形式嗎?其實并不是,只有當鏈表的長度小于6的時候,我們才會將紅黑樹重新轉化為鏈表,這個程序就叫做“鏈化”,
程序圖示如下:
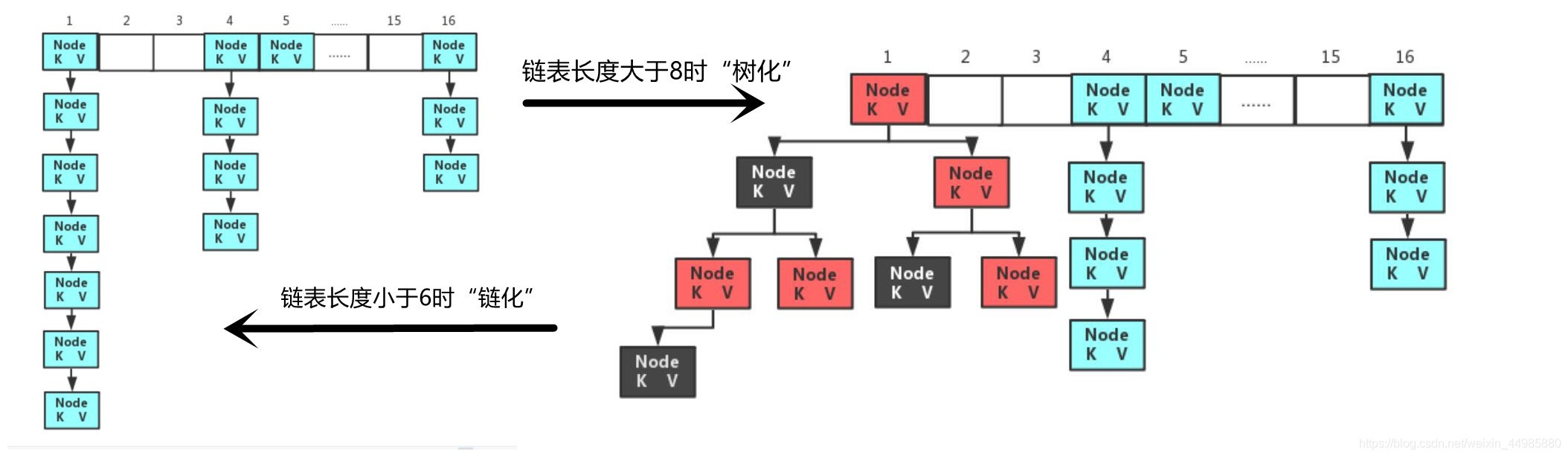
那么為什么要在長度8的時候進行“樹化”,而在長度小于6的時候才進行“鏈化”呢?為什么不直接在長度小于8的時候就進行“鏈化”?
主要原因是因為:當洗掉一個元素,鏈表長度小于8的時候直接進行“鏈化”,而再增加一個元素,長度又等于8的時候,又要進行“樹化”,這樣反復的進行“鏈化”和“樹化”操作特別的消耗時間,而且也比較麻煩,所以程式就規定,只有當當鏈表長度大于等于8的時候才進行“樹化”,而長度小于6的時候才進行“鏈化”,其中關于8樹化、6鏈化這兩個閾值希望大家牢記!
4、鏈表中是按照怎樣的順序存放資料的?
我們現在已經知道了HashMap中的元素是如何存放的,但是有時候面試官可能還會問我們,在HashMap中,向鏈表中存盤元素是在頭結點存盤的還是在尾節點存盤的?
這個我們需要知道,對于HashMap中鏈表元素的存盤,
在JDK1.7以及前是在頭結點插入的,在JDK1.8之后是在尾節點插入的,
5、Hash(key)方法是如何實作的?
我們現在已經知道了HashMap中的元素是如何存盤的了,那么現在就是如何應該根據key值進行相應的陣列下標的計算呢?
我們知道HashMap的初始容量是16位,那么對于初始的16個資料位,如果將資料按照key的值進行計算存盤,一般最簡單的方法就是根據key值獲取到一個int值,方法是:
int hashCode = key.hashCode()
然后對獲取到的hashCode與16進行取余運算,
hashCode % 16 = 0~15
這樣得到的永遠都是0—15的下標,這也是最最原始的計算hash(key)的方法,
但是在實際情況下,這種方法計算的hash(key)并不是最優,存放到陣列中的元素并不是最分散的,而且在計算機中進行余運算其實是非常不方便的、
所以為了計算結果盡可能的離散,現在計算陣列下標最常用的方法是:先根據key的值計算到一個hashCode,將hashCode的高16位二進制和低16位二進制進行異或運算,得到的結果再與當前陣列長度減一進行與運算,最終得到一個陣列下標,程序如下:
int hashCode = key.hashCode()
int hash = hash(key) = key.hashCode()的高16位^低16位&(n-1) 其中n是當前陣列長度
同時在這里要提醒一點,
在JDK1.7和JDK1.8的時候對hash(key)的計算是略有不同的
JDK1.8時,計算hash(key)進行了兩次擾動
JDK1.7時,計算hash(key)進行了九次擾動,分別是四次位運算和五次異或運算
其中擾動可能理解為運算次數
以上就是Hash(key)方法的實作程序,
6、為什么HashMap的容量一直是2的倍數?
HashMap的容量之所以一直是2的倍數,其實是與上面所說的hash(key)演算法有關的,
原因是只有參與hash(key)的演算法的(n-1)的值盡可能都是1的時候,得到的值才是離散的,假如我們當前的陣列長度是16,二進制表示是10000,n-1之后是01111,使得n-1的值盡可能都是1,對于其他是2的倍數的值減1之后得到值也是這樣的,
所以只有當陣列的容量長度是2的倍數的時候,計算得到的hash(key)的值才有可能是相對離散的,
7、Hash沖突如何解決?
什么是Hash沖突?就是當我計算到某一個陣列下標的時候,該下標上已經存放元素了,這就叫Hash沖突,很顯然,如果我們計算陣列下標的演算法不夠優秀的時候,很容易將存盤的資料積累到同一個下標上面,造成過多的Hash沖突,
那么如何解決hash沖突?
最應該解決的其實就是讓存盤的key計算得到的陣列下標盡可能的離散,也就是要求hash(key)盡可能的優化,陣列長度是2的倍數,這也就是Hash沖突的主要解決方法,
具體可以查看下面HashMap關鍵部分的底層原始碼:
Hash(key)的底層實作
/**
* Applies a supplemental hash function to a given hashCode, which
* defends against poor quality hash functions. This is critical
* because HashMap uses power-of-two length hash tables, that
* otherwise encounter collisions for hashCodes that do not differ
* in lower bits. Note: Null keys always map to hash 0, thus index 0.
*/
static int hash(int h) {
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}put(key,value)方法的底層實作
/**
* Associates the specified value with the specified key in this map.
* If the map previously contained a mapping for the key, the old
* value is replaced.
*
* @param key key with which the specified value is to be associated
* @param value value to be associated with the specified key
* @return the previous value associated with <tt>key</tt>, or
* <tt>null</tt> if there was no mapping for <tt>key</tt>.
* (A <tt>null</tt> return can also indicate that the map
* previously associated <tt>null</tt> with <tt>key</tt>.)
*/
public V put(K key, V value) {
if (key == null)
return putForNullKey(value);
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}
8、HashMap是如何擴容的?
我們在上面說到了HashMap的陣列的初始容量是16,但是很顯然16個存盤位是顯然不夠的,那么HashMap應該如何擴容呢?
在這里需要用到一個引數叫“擴容因子”,在HashMap中“擴容因子”的大小是0.75,
我們上面也提到過,對于初始長度為16的陣列,當其中存盤的資料長度等于16*0.75=12時,就會對陣列元素進行擴容,擴容量是原來陣列容量的2倍,也就是當前是15話,再擴容就是擴容32個資料位,
9、擴容后元素怎么存放的?
我們知道HashMap的陣列在進行擴容之后,陣列長度是增加的,那么這個時候,后面新擴容的部分就是空的,但是這個時候我們就應該讓后面的資料位空著嗎?顯然是不可能的,這樣會造成記憶體的很大浪費,
因此在HashMap的陣列擴容之后,原先HashMap陣列中存放的資料元素會進行重新的位置分配,重新將元素在新陣列中進行存盤,以充分利用陣列空間,
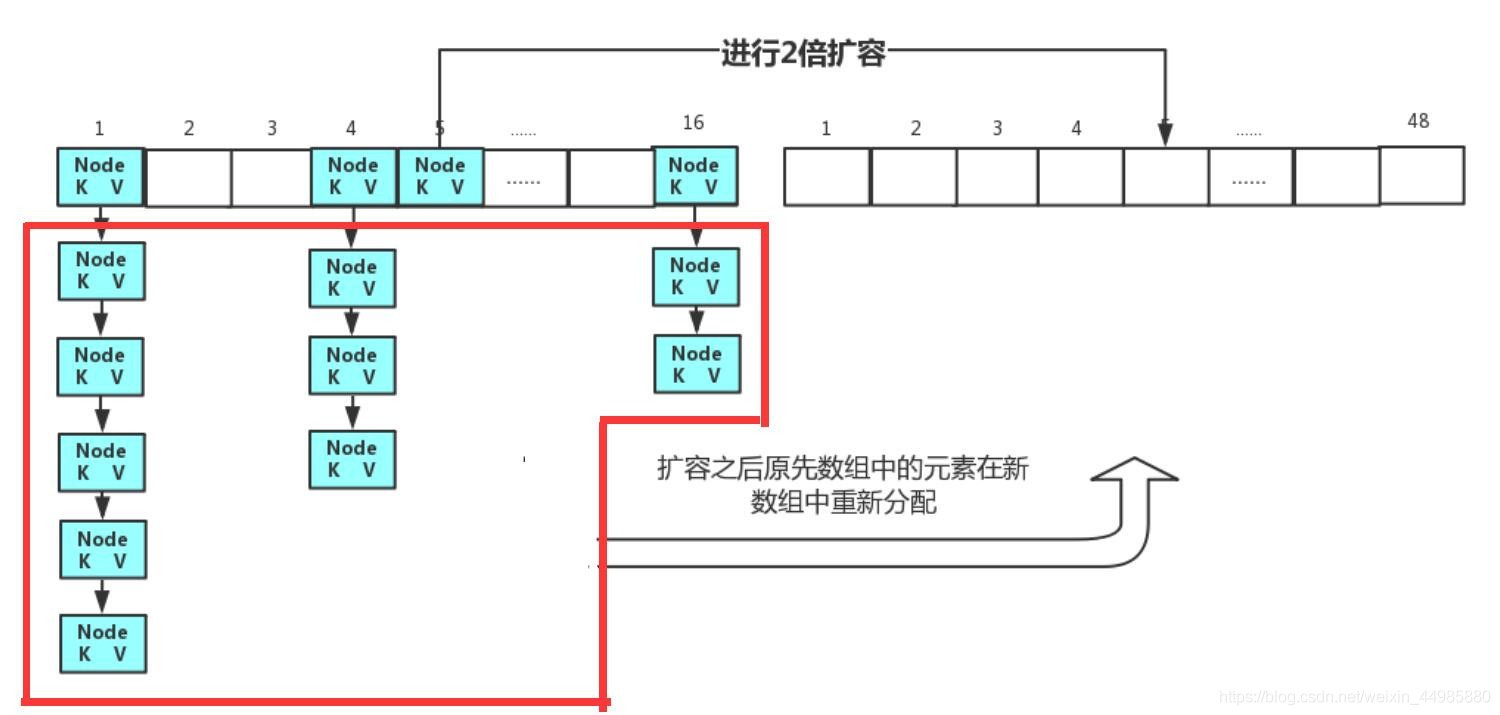
10、JDK1.7和JDK1.8對HashMap的實作比較
在JDK1.7和JDK1.8中對HashMap的實作是略有不同的,最后我們根據上面的講解對JDK1.7和JDK1.8在HashMap的實作中的不同進行分析比較,
(1)、底層資料結構不同
在HashMap的put程序中,JDK1.7時是沒有紅黑樹這一概念的,直接是進行的鏈表存盤,在JDK1.8之后才引入了紅黑樹的概念,來優化存盤和查找,
(2)、鏈表的插入方式不同
在HashMap向鏈表中插入元素的程序中,JDK1.7時是在表頭節點插入的,JDK1.8之后是在尾節點插入的,
(3)、Hash(key)的計算方式不同
在Hash(key)的計算中,JDK1.7進行了九次擾亂,分別是四次位運算和五次異或運算,JDK1.8之后只進行了兩次擾動,
(4)、擴容后數存盤位置的計算方式不同
在擴容后對存盤資料的重新排列上,JDK1.7是將所有資料的位置打亂,然后根據hash(key)進行重新的計算,而在JDK1.8之后是對原來的資料下標進行了兩次for回圈,計算出新下標位置只能是在原下標位置或者在原下標位置加上原容量位置,
好了,關于Map介面和HashMap的底層實作的程序,以及在面試中參考的核心問題就和大家分析到這里!
有問題的小伙伴可以在評論區留言提出!覺得不錯記得點贊關注喲!
我是灰小猿!我們下期見!

轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/286269.html
標籤:其他