深入YARN系列主要分為:
- 深入YARN系列1:窺全貌之YARN架構,設計,通信原理等
- 深入YARN系列2:剖析ResourceManaer的架構與核心原始碼分析
- 深入YARN系列3:剖析NodeManager架構,組件機制,生產應用
- 深入YARN系列4:剖析ApplicationMaster的任務管理機制與生產調優
- 深入YARN系列5:YARN三大組件配合使用與YARN生產性能優化
1.YARN的架構與設計
YARN的總體架構模式是Master/Slave主從模式,一個全域的ResourceManager ( RM,主 ,可以多個HA),多個NodeManager共同構成計算框架, NodeManager (NM)是每臺機器的框架代理,管理單個節點的資源和任務,比如負責容器container、監控其資源使用情況(cpu、記憶體、磁盤、網路)等,既然YARN是為了給計算框架做資源調度分配與管理的,那么少不了應用程式管理相關的框架:ApplicationMaster (AM) 實際上是一個特定框架的庫,其作用是負責管理整個系統中所有的應用程式(從任務提交到結束),協商來自 ResourceManager 的資源,同時與 NodeManager 一起執行和監視任務,
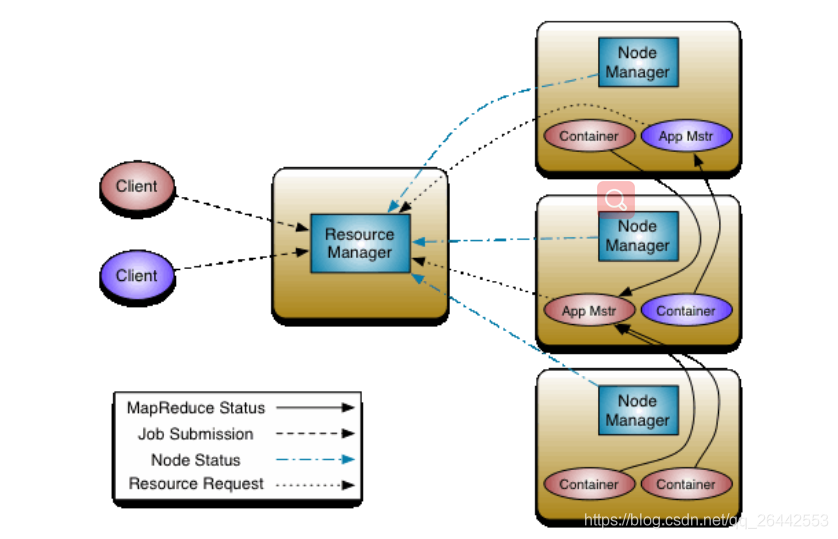
從上面這張Hadoop官網的照片我們可以清晰的看出,YARN主要有以下三個組件構成.ResourceManager,NodeManager,ApplicationMaster構成,
2.透視YARN三大組件全貌
YARN 可以看出一個大的云作業系統,它負責為應用程式啟動 ApplicationMaster(相當于主執行緒),然后再由 ApplicationMaster 負責資料切分、任務分配、 啟動和監控等作業,而由 ApplicationMaster 啟動的各個 Task(相當于子執行緒)僅負責自己的計算任務,當所有任務計算完成后,ApplicationMaster 認為應用程式運行完成,然后退出,
2.1.ResourceManager全域資源管理器
RM負責整個系統的資源分配與管理;它主要有調度器ResourceScheduler和應用程式管理器(APPlications Manager)構成;
2.1.1ResourceScheduler
Resource Scheduler調度器只負責資源的細分調度,比如按照佇列,容量等指標,給每個請求的應用程式分配的指定數量的資源, Hadoop 提供了三種不同的資源調度器供選用,用戶可以在組態檔中加以選擇,這三種調度器是FIFO Scheduler, FAIR Scheduler,CAPACITY Scheduler,詳細使用可以參考官網或我的其他博客,yarn組態檔 yarn-sire.xml 中<yarn. resourcemanager. scheduler. class >來指定調度器,Apache Hadoop集群默認的調度器 是 CapacityScheduler ,而CDH默認的則是FAIR Scheduler.
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value>
</property>2.1.2APPlications Manager
APPlications Manager 應用程式管理器負責整個系統中所有應用程式的管理,包括管理啟動的所有ApplicationMaster (AM)實體,比如啟動AM,和AM通信并監控所有AM實體的運行狀態,某個AM失敗時,在失敗次數范圍內時對其進行重啟等(默認一個應用的AM可以啟動2次),區別APPlications Manager和APPlications Master,兩者不同,前者管理后者的實體,
2.2 NodeManger,節點資源管理器
NM是單個節點的資源管理器,管理者單個節點的資源分配與任務,所以如果hadoop集群特殊情況時想做存盤與計算分離,則某些節點可以只啟動Datanode,或只啟動Nodemanger即可,這樣可以只做存盤節點或者計算節點,當然也可以通過引數限制存盤的使用和計算的使用比例,所以NM是YARN的實際計算節點,
- NM和RM保持心跳機制,定時匯報自己節點的資源使用情況和Container的運行狀態
- Container,全稱是Resouce Container是YARN中的資源抽象(主要包含了CPU,記憶體,網路等),應用程式向RM請求資源的個體就是Container,由NodeManager分配,YARN會為每個任務分配一個container,且任務能使用的資源值就是container中分配的資源(新Capacity調度支持container資源的動態擴容)
- NM接受來自AM的Container分配,啟動與停止
- YARN使用了輕量級資源隔離機制CGroups,CGroups 是 Linux 內核功能,從 YARN 的角度來看,這允許限制容器的資源使用,沒有 CGroups,就很難限制容器 CPU 使用率,
- NM只負責AM管理的應用程式的部分作業,不管整個程式的失敗與否,只負責執行Container,
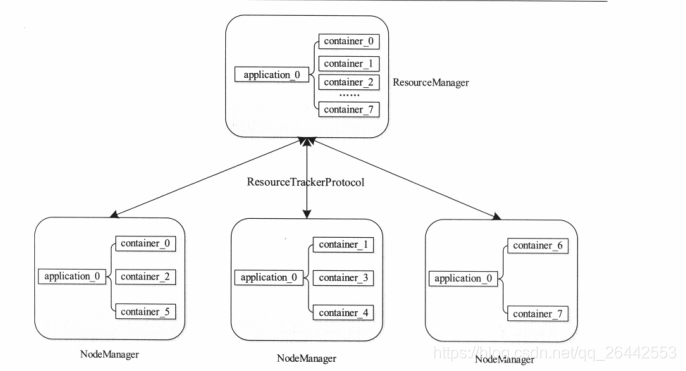
尖叫總結:RM內部有個 ResourceTrackerService 類的物件 resourceTracker ,它跟蹤管理著 NodeManager 節點所知道的資源變動,同時 NodesListManager 類的物件nodesListManager 則維持著一個節點清單,記錄著哪些節點當前是可用的,哪些則是不可用的,而 ResourceTrackerService 和 NodesListManager 掌握的則是來自所有 NodeManager 節點的心跳報告,通過心跳進行互動的資訊如節點當前狀態,資源使用情況等,這些資訊最終都要匯集到ResourceScheduler,通過調度器將資源分配出去給用戶使用,
2.3 Application Master應用程式主管理器
客戶端每使用YARN啟動執行一個應用程式之前,先啟動一個AM(其實本質就是一個運行的Container,一個程式最早啟動的container實體)
- 每個提交到YARN的任務都會啟動一個唯一的AM實體,如果AM失敗了,默認可以重試啟動一次,
- AM與RM通信提交需要的資源,AM與RM調度器Scheduler通信協商以獲取資源Container,得到Container后分配給自己的任務執行執行,比如map任務的執行,分配的多少個Container就有多少個map并行執行,
- AM從RM得到的資源只是資源串列,hosts,container數量,資源大小等,這時候AM需要與NM通信,啟動任務,啟動container,
- AM監管者該任務所有任務實體的運行狀態,比如一個MapReduce任務,該任務AM監管所有的MapTask,ReduceTask的運行狀態,如果AM監管到任務失敗了后,可以進行重新申請資源重啟,包括可以主動殺死任務,停止任務等,
尖叫總結:從上面可以看出,YARN三大組件的RM,NM都只與資源分配有關,只有AM跟應用程式有關,所以如果想將一個新的計算框架(比如自定義的)/應用程式使用YARN進行資源調度和任務管理,只需要從重新實作兩個組件即可,前者是提交任務使用的客戶端Client,后者就是Application Master,比如MapReduce計算引擎能直接配置使用YARN進行調度,就是YARN默認給他實作了可以提交任務通信的客戶端JobClient和任務管理器MapReduce Application Master(簡稱MRAppMaster),
3.YARN組件之間的通信RPC/IPC
開發人員經常會在任務中看到RPC通信例外,也有IPC通信例外,報錯等?或者查到監控指標RPC請求延遲等?大家應該都不陌生,那么這些報錯意味著什么呢?如何解決呢?
3.1RPC通信與IPC通信
RPC通信是指遠程程序呼叫(Remote Procedure Call)通信協議,主要用來讓遠程的兩臺服務器之間A主機的程式可以呼叫B主機的子程式,是一種遠程分布式網路呼叫通信協議,我們不用太關注底層網路通信細節(不用關注TCP,UDP等),是一種封裝好了的通信協議,直接拿來用即可,真香,
IPC通信是指行程間通信(Inter-Process Communication ,IPC)協議,這個是分布式系統通信的基石,
盡管Java自帶了一套RPC通信組件(RMI,remote method Invocation),但是Hadoop并沒有使用該框架,因為相比Java的RMI,后者更加輕量級,高性能和可控性,Hadoop的RPC框架也是C/S模式,分成了四個模塊,分別是序列化層,函式呼叫層,網路傳輸層以及server端處理層,當前開源的RPC框架很多,比如Apache的AVRO,Google的Protocol Buffer等,
YARN的RPC通信為了更好的兼容默認使用Google的Protocol Buffer作為默認的序列化機制,而不是Hadoop自帶的Writtable,在 YARN 中,任何兩個需相互通信的組件之間僅有一個 RPC 協 議,而對于任何一個 RPC 協議,通信雙方有一端是 Client,另一端為 Server,且 Client 總 是主動連接 Server 的,因此,YARN 實際上采用的是拉式(pull-based)通信模型,
比如NM和RM之前的遠程通信就是基于RPC,通過ResouceTracker實作,其中RM是服務端,NM是客戶端,NM主要通過呼叫ResouceTracker中兩個RPC函式與之互動,前者是NM剛啟動時通過registerNodeManager函式向RM進行注冊,然后再通過nodeHeartBeat像RM發送周期性心跳,維護兩者之間的互動,如下圖所示,因為RPC分成了四層次序列化層,函式呼叫層,網路傳輸層以及server端處理層,所有不同組件之間實作通信的“協議”是不同的,
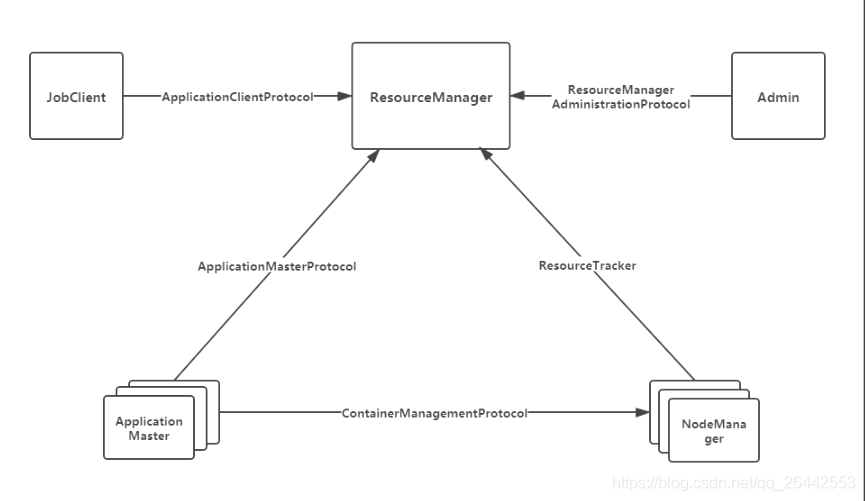
- 1.JobClient(作業提交客戶端)與 RM 之間JobClient 通過該 RPC 協議提交應用程式、查詢應用程式狀態,使用的協議 是ApplicationClientProtocol ,
- 2.AM 與 RM 之間的協議是ApplicationMasterProtocol ,AM 通過該 RPC 協議向 RM 注冊并為各個任務申請資源,或者使用完以后進行銷毀自己,
- 3. AM 與 NM 之 間 的 協 議 是ContainerManagementProtocol ,AM 通 過 該 RPC 協議要 求 NM 啟動/停止 Container,同時獲取各個 Container 的狀態資訊等,
- 4.NM 與 RM 之間的協議是ResourceTracker ,NM 通過該 RPC 協議向 RM 注冊,并且周期性發送心跳資訊匯報當前節點的資源使用情況和 Container 運行情況,
- 5.Admin與 RM 之間的通信協議是ResourceManagerAdministrationProtocol,超級用戶通過該 RPC 協議更新系統組態檔,比如節點上下線名單、用戶佇列權限等,
尖叫總結:RM,NM,AM三大組件互相通信,通過不同RPC框架協議進行通信,進而保持整個YARN資源的調度和任務監控實施,
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/286565.html
標籤:其他