Hive與優化方法
文章目錄
- Hive與優化方法
- 一、Hive概念
- 二、Hive架構
- 三、Hive與資料庫的比較
- 四、Hive中一些重要的概念
- 4.1 內部表和外部表
- 4.2 磁區表
- 4.3 Hive排序關鍵字
- 4.4 Hive分桶
- 4.5 三種排序窗函式的區別
- 五、Hive調優
- 5.1 部分場景下盡可能避免啟用MR
- 5.2 表的優化
- 5.3 資料傾斜優化
- 5.3 其他優化
Java、大資料開發學習要點(持續更新中…)
一、Hive概念
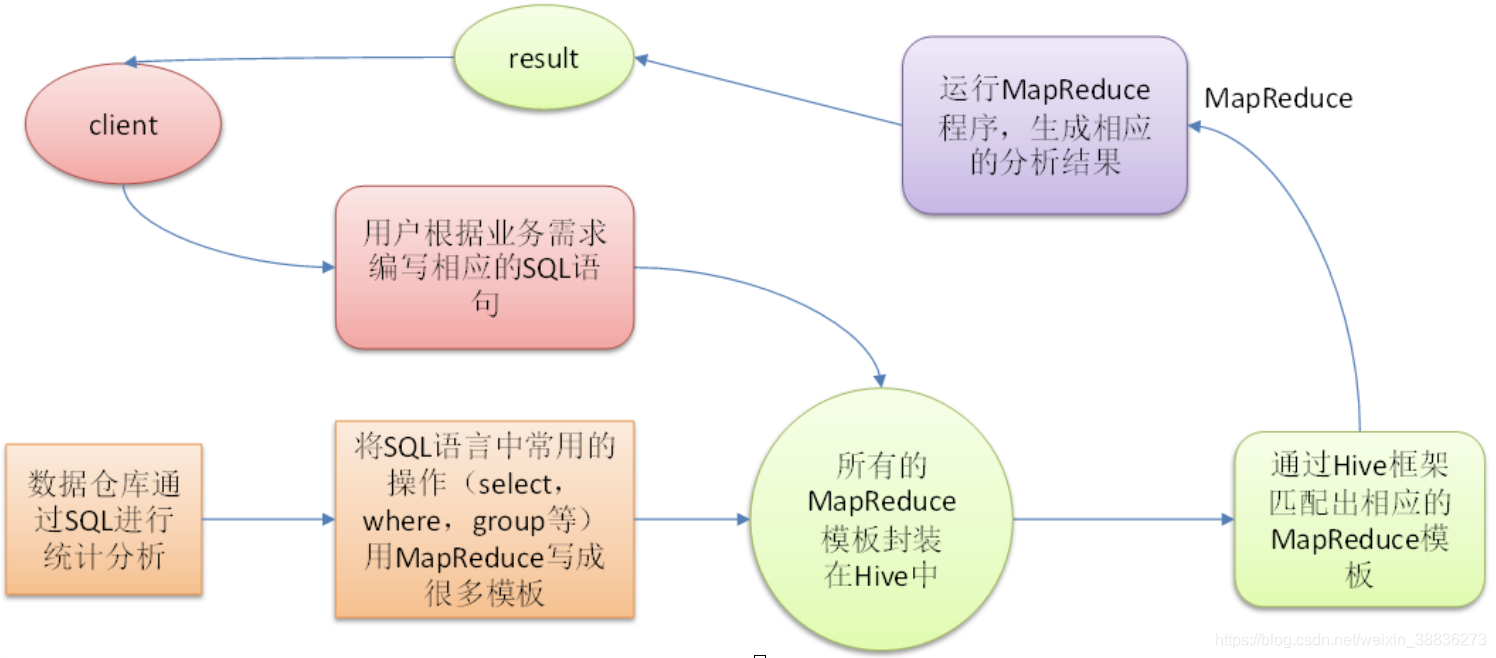
??Hive是基于Hadoop的一個資料倉庫工具,可以將結構化的資料檔案映射為一張表,并提供類SQL查詢功能,其本質是,將HQL轉化成MapReduce程式,底層資料存盤在HDFS上,由于延遲較大所以一般適用于離線大批量的資料計算和分析,
二、Hive架構
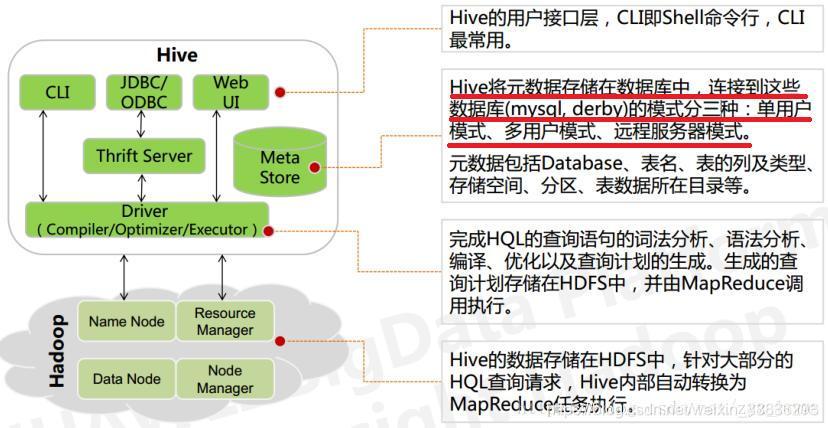
- 用戶介面Client:
CLI(hive shell)、JDBC/ODBC(java訪問hive)、WEBUI(瀏覽器訪問hive) - 元資料Metastore:
元資料包括:表名、表所屬的資料庫(默認是default)、表的擁有者、列/磁區欄位、表的型別(是否是外部表)、表的資料所在目錄等;默認存盤在自帶的derby資料庫中,推薦使用MySQL存盤Metastore, - Hadoop:
使用HDFS進行存盤,使用MapReduce進行計算, - 驅動器Driver:
- 決議器(SQL Parser):將SQL字串轉換成抽象語法樹AST,這一步一般都用第三方工具庫完成,比如antlr;對AST進行語法分析,比如表是否存在、欄位是否存在、SQL語意是否有誤,
- 編譯器(Physical Plan):將AST編譯生成邏輯執行計劃,
- 優化器(Query Optimizer):對邏輯執行計劃進行優化,
- 執行器(Execution):把邏輯執行計劃轉換成可以運行的物理計劃,對于Hive來說,就是MR/Spark,
三、Hive與資料庫的比較
??Hive 和資料庫除了擁有類似的查詢語言,再無類似之處,其實記住Hive是數倉工具就可以將其與資料庫區別開來,
- Hive與傳統資料庫的區別:
- 資料更新:由于Hive是針對資料倉庫應用設計的,而資料倉庫的內容是讀多寫少的,因此,Hive中不建議對資料的改寫,所有的資料都是在加載的時候確定好的,而資料庫中的資料通常是需要經常進行更新,
- 資料查詢:傳統資料庫資料由于索引的存在,在資料量較小的情況下查詢較快,并且自己提供執行引擎,而Hive資料查詢是整表或者磁區表的掃描,只有在大資料情況下分布式運算才有優勢,依靠MR或Spark來執行,
- 資料存盤:Hive資料存盤沒有固定的格式,用戶可以自己指定存盤的格式(Parquet、SequenceFile等),并自己指定壓縮格式(Snappy、ORC),資料庫的存盤引擎定義了自己的存盤格式,
- Hive與HBase的區別:
其實沒有什么可以比較的,HBase是一個分布式列簇式存盤KV資料庫,Hive是一個數倉工具,Hive擅長于大資料離線計算和分析,而HBase則是提供快速資料寫入和查詢的資料庫應用在實時查詢的場景,
四、Hive中一些重要的概念
4.1 內部表和外部表
??內部表生命周期是受Hive控制的,洗掉內部表則資料和元資料都會被洗掉;將資料匯入外部表,資料并不會移動,即使洗掉外部表,只是洗掉外部表元資料原來的資料還是會存在,
使用的例子,HDFS定期收到用戶行為日志檔案,在日志檔案上建立外部表,中間表和結果表則以內部表的形式存盤,
4.2 磁區表
??磁區表實際上就是對應一個HDFS檔案系統上的獨立的檔案夾,該檔案夾下是該磁區所有的資料檔案,Hive根據某列或者某些列的值(這些列在表中并不真實存在)將資料磁區,放在表檔案夾下不同子檔案夾中存盤,Hive中的磁區就是分目錄,把一個大的資料集根據業務需要分割成小的資料集,
- 靜態磁區和動態磁區:
- 靜態磁區:在建表中指定磁區條件,資料匯入或者插入時需要指定磁區,
- 動態磁區:按照某個或某些欄位的值不同自動地進行磁區,底層實際是利用MapReduce的mutipleOutputs(根據條件判斷,將結果寫入不同目錄不同檔案),
- 靜態磁區必須在動態磁區前,
- 磁區的注意事項:
Hive磁區過多,導致每個磁區的檔案小,會導致HDFS小檔案過多的問題,
(1)小檔案數量過多造成NameNode負擔過大,
(2)Hive運行Mapreduce時,每個block對應一個切片,而小檔案則會直接對應一個map任務,使得map任務過多使得運行效率低下(Yarn頻繁申請銷毀容器),
4.3 Hive排序關鍵字
-
ORDER BY:全域排序,強制只有一個Reducer,但是當資料規模較大時,會導致消耗較長的計算時間,
-
SORT BY:區域排序,每個task內部排序,使得reduce結果都是區域有序的,
由此,可以想到全域有序的一個方法,先SORT BY將分組內的資料有序資料,再用ORDER BY使得資料全域有序,實際就是兩階段MapReduce,第一次輸出區域有序,第二次輸出后全域有序,
-
DISTRIBUTE BY:類似MR中的Partition磁區器,根據某一列進行磁區,使用DISTRIBUTE BY+SORT BY來實作分桶排序查詢,如:
hive (default)> set mapreduce.job.reduces=3; --根據col1進行磁區,再根據col2進行磁區內的降序排序 hive (default)> select col1,col2 from emp distribute by col1 sort by col2 desc; -
CLUSTER BY:當DISTRIBUTE BY和SORT BY欄位相同時,可以使用CLUSTER BY代替,但只能升序排列,
4.4 Hive分桶
??對Hive表分桶可以將表中資料按分桶鍵的哈希值散列到多個檔案中,這些小檔案稱為桶,
表磁區是用不同的子檔案夾管理不同的資料;而表分桶用不同的檔案管理不同的資料,
- 分桶的好處:
- join兩個相同分桶劃分的表時可以使用map-side join,優化join查詢,
- 根據某些列進行分桶可以使Hive查詢時利用分桶的結構加快查詢效率,
- 對于非常大的資料集,有時用戶需要使用的是一個具有代表性的查詢結果而不是全部結果,Hive可以通過對表進行抽樣來滿足這個需求,而分桶的結構恰好滿足抽樣所需的資料結構,使得抽樣更加高效,
4.5 三種排序窗函式的區別
- RANK() n個排序相同時排名會重復,但下一個排名會跳躍至n個名次開始,(跳躍)
- DENSE_RANK() n個排序相同時排名會重復,但下一個排名繼續上一個排名加1開始,(連續)
- ROW_NUMBER() 會根據順序依次編號,
五、Hive調優
5.1 部分場景下盡可能避免啟用MR
由于MapReduce的啟動任務調度通常在資料集小的情況下耗時比job本身時間要長,所以Hive在有些場景下可以盡量避免啟動MR來執行任務,比如資料抓取(Fetch)在全表資料獲取、欄位查找、limit查找的情況下可以不走MapReduce;再比如資料集較小的情況下,開啟本地模式單機處理所有任務也能比走集群計算得到更好的時間效率,
5.2 表的優化
- 小表JOIN大表:
- JOIN有個特點是其中一個表需要作為全量讀取的表先加載至記憶體,所以小表寫在JOIN左邊(當然這點Hive的開發者已經對此進行了優化),
- 小表JOIN大表的情況下,盡量使用map-side join,將小表廣播到大表所在的map任務中,以減少小表shuffler所帶來的IO開銷,
- 大表JOIN大表:
- 要注意的是大表的資料量基本都比較大,JOIN容易出現reducer的OOM,所以要注意JOIN前資料的過濾與某些空key資料產生的資料傾斜問題(隨機賦值),
-
替換COUNT DISTINCT去重統計
COUNT DISTINCT通過一個Reducer來完成去重統計,在資料量巨大的場景下效率低下,將COUNT DISTINCT用兩階段進行替換:先GROUP BY再開啟一個任務進行COUNT, -
避免笛卡爾積
表的無條件JOIN(沒有指定ON條件,或條件無效),Hive只能用一個Reducer完成,效率極其低下, -
行過濾
在表的JOIN關聯中,將附表的過濾作為子查詢寫在ON條件之前,否則會導致先關聯再過濾的問題產生,
5.3 資料傾斜優化
-
map-side join來緩解資料傾斜問題
如果不指定MapJoin或者不符合MapJoin的條件,那么Hive決議器會將Join操作轉換成Common Join,即:在Reduce階段完成join,容易發生資料傾斜,可以用Map-side Join把小表全部加載到記憶體在Map端進行join,避免Reducer處理,(引數設定set hive.auto.convert.join = true;默認是true) -
Group by開啟Map端預聚合
默認情況下,Map階段同一Key資料分發給一個Reducer,當一個key資料過大時就傾斜了,并不是所有的聚合操作都需要在Reduce端完成,很多聚合操作都可以先在Map端進行部分聚合,最后在Reduce端得出最終結果,兩個引數hive.map.aggr = true(默認) 和 hive.groupby.skewindata = true(非默認),分別是開啟Map端預聚合和資料傾斜時進行負載均衡,當選項設定為 true,生成的查詢計劃會有兩個MR Job,第一個MR Job中,Map的輸出結果會隨機分布到Reduce中,每個Reduce做部分聚合操作,并輸出結果,這樣處理的結果是相同的Group By Key有可能被分發到不同的Reduce中,從而達到負載均衡的目的;第二個MR Job再根據預處理的資料結果按照Group By的Key分布到Reducer中(這個程序可以保證相同的Key被分布到同一個Reducer中),最后完成最終的聚合操作,
-
合理設定Map任務數和Reduce任務數
-
合理的Map任務數:
- 每個小檔案對應一個Map任務是不明智的,導致Map任務數過多,且任務啟動調度的時間遠大于任務邏輯執行的時間,
- 每個Map的大小接近128M呢?則會使得單個Map任務的執行時間過長,
所以,Map任務需要按照場景進行調整,小檔案多的情況下減少Map任務并設定Hive的InputFormat為CombineHiveInputFormat;而檔案較大的情況下,增加Map數量來分擔單檔案大資料量的計算壓力,
-
合理的Reduce任務數:
與Map任務類似,Reducer數量也要合理,太多增大調度資源和小檔案的產生,過少單個Reduce任務執行時間過長,
5.3 其他優化
-
并行執行:
Hive會將一個查詢轉化成一個或者多個階段,這樣的階段可以是MapReduce階段、抽樣階段、合并階段、limit階段,或者Hive執行程序中可能需要的其他階段,默認情況下,Hive一次只會執行一個階段,不過,某個特定的job可能包含眾多的階段,而這些階段可能并非完全互相依賴的,也就是說有些階段是可以并行執行的,這樣可能使得整個job的執行時間縮短,不過,如果有更多的階段可以并行執行,那么job可能就越快完成, -
嚴格模式:
- 對于磁區表,除非where陳述句中含有磁區欄位過濾條件來限制范圍,否則不允許執行,換句話說,就是用戶不允許掃描所有磁區,進行這個限制的原因是,通常磁區表都擁有非常大的資料集,而且資料增加迅速,沒有進行磁區限制的查詢可能會消耗令人不可接受的巨大資源來處理這個表,
- 對于使用了order by陳述句的查詢,要求必須使用limit陳述句,因為order by為了執行排序程序會將所有的結果資料分發到同一個Reducer中進行處理,強制要求用戶增加這個LIMIT陳述句可以防止Reducer額外執行很長一段時間,
- 限制笛卡爾積的查詢,對關系型資料庫非常了解的用戶可能期望在執行JOIN查詢的時候不使用ON陳述句而是使用WHERE陳述句,這樣關系資料庫的執行優化器就可以高效地將WHERE陳述句轉化成那個ON陳述句,不幸的是,Hive并不會執行這種優化,因此,如果表足夠大,那么這個查詢就會出現不可控的情況,
-
JVM重用:
JVM重用是Hadoop調優引數的內容,其對Hive的性能具有非常大的影響,特別是對于很難避免小檔案的場景或task特別多的場景,這類場景大多數任務執行時間都很短,
-
合理壓縮:
比如使用Parquet列式存盤資料,這種格式按列存盤資料,沒列資料型別相同,天然對壓縮友好,建議可以使用Parquet存盤格式+Snappy壓縮格式的組合,
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/287138.html
標籤:其他