資料倉庫分層
- 把復雜問題簡單化,把一個復雜的任務分解成多個步驟來完成,每一層只處理單一的步驟,比較簡單和容易理解
- 清晰的資料結構,每一層都有它的作用域,這樣我們在使用表的時候能更方便的定位和理解, 便于維護資料的準確性,當資料出現問題的時候,可以不用修復所有的資料,只需要從有問題的步驟開始修復
- 減少重復開發,規范資料分層,通過中間層資料,能夠減少極大的重復計算,增加一次計算結果的復用性
- 隔離原始資料,使得真是資料與統計資料接耦
分層結構圖

- ODS層(原始資料層)
原始資料層,存放原始資料,直接加載原始日志、資料,資料保持原貌不做處理, - DWD層(明細資料層)
結構和粒度與ODS層保持一致,對ODS層資料進行清洗(去除空值,臟資料,超過極限范圍的資料),也有公司叫DWI, - DWS層(服務資料層)
以DWD為基礎,進行輕度匯總,一般聚集到以用戶當日,設備當日,商家當日,商品當日等等的粒度,在這層通常會有以某一個維度為線索,組成跨主題的寬表,比如,一個用戶的當日的簽到數、收藏數、評論數、抽獎數、訂閱數、點贊數、瀏覽商品數、添加購物車數、下單數、支付數、退款數、點擊廣告陣列成的多串列, - ADS層(資料應用層)
資料應用層,也有公司或書把這層命名為APP層、DAL層等,面向實際的資料需求,以DWD或者DWS層的資料為基礎,組成的各種統計報表,統計結果最終同步到RDS以供BI或應用系統查詢使用,
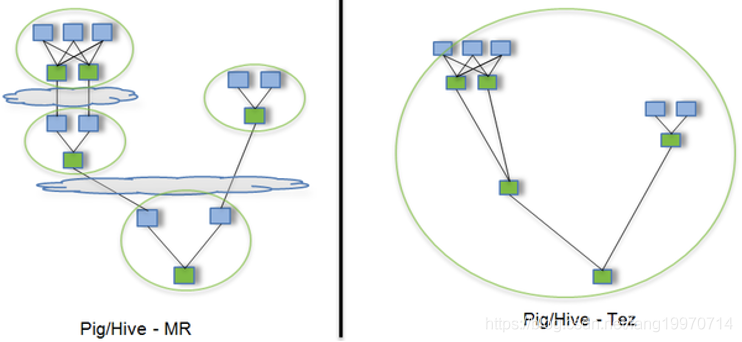
Hive運行引擎Tez
性能優于MapReduce,用Hive直接撰寫程式,假設有四個有依賴關系的MapReduce作業,綠色是Rgmallce Task,云狀表示寫屏蔽,需要將中間結果持久化寫到HDFS,Tez可以將多個有依賴的作業轉換為一個作業,這樣只需寫一次HDFS,且中間節點較少,從而大大提升DAG作業的性能,
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/287142.html
標籤:其他
上一篇:嬰兒檢測管理系統 springboot+mybatis前后端分離專案
下一篇:雙活資料中心構建方法及實作技術