動態規劃求解流水線問題
- 一、實驗目的與要求
- 1. 實驗目的:
- 2. 實驗亮點:
- 二、實驗內容與方法
- 1. 實驗內容:
- 2. 實驗要求:
- 三、實驗步驟與程序
- (一)暴力窮舉法
- 1、演算法描述:
- 2、時間復雜度分析:
- 3、編程實作:
- 4、運行并測驗:
- (二)動態規劃法
- 1、演算法描述:
- (1)分析規劃程序:
- (2)分析動態規劃方程:
- 2、時間復雜度分析:
- 3、編程實作:
- 4、運行并測驗:
- (三)效率對比分析
- 四、實驗結論或體會
- 五、思考(時間與空間優化)
- 1、演算法描述:
- 2、進行優化:
- 3、進行測驗:
- 4、只用記憶體進行運算:
一、實驗目的與要求
1. 實驗目的:
(1) 掌握動態規劃演算法設計思想,
(2) 掌握流水線問題的動態規劃解法,
2. 實驗亮點:
(1)使用動態規劃演算法進行了優化,大大降低了程式的運行時間,并給出了詳細的規劃方程,
(2)選用了更合理的資料結構進行優化,將程式可處理的資料量上限提高到
1
0
1
3
10^13
1013并將程式運行的時間降低至
1
/
100
1/100
1/100,
(3)每個演算法均有詳細的偽代碼描述,并對不同資料量級下做對比并做出資料折線圖,
(4)對演算法的正確性進行了邏輯上與資料上的驗證,
二、實驗內容與方法
1. 實驗內容:
汽車廠有兩條流水線,每條流水線有n個處理環節(station): S 1 , 1 S_{1,1} S1,1?,…, S 1 , n S_{1,n} S1,n? 和 S 2 , 1 S_{2,1} S2,1?,…, S 2 , n S_{2,n} S2,n?,其中下標的第一個字母表示流水線編號(流水線1和流水線2),其中 S 1 , j S_{1,j} S1,j? 和 S 2 , j S_{2,j} S2,j?完成相同的功能,但是花費的時間不同,分別是 a 1 , j a_{1,j} a1,j? , a 2 , j a_{2,j} a2,j? ,兩條流水線的輸入時間分別為 e 1 e_1 e1? 和 e 2 e_2 e2?, 輸出時間是 x 1 x_1 x1? 和 x 2 x_2 x2?,
每個安裝步驟完成后,有兩個選擇:
1)停在同一條安裝線上,沒有轉移代價;
2)轉到另一條安裝線上,轉移代價:
S
i
,
j
S_{i,j}
Si,j? 的代價是
t
i
,
j
t_{i,j}
ti,j?, j = 1,…,n - 1

問題: 如何選擇安裝線1和安裝線2的節點組合,從而最小化安裝一臺車的總時間?
2. 實驗要求:
- 給出解決問題的動態規劃方程;
- 隨機產生 S 1 , j S_{1, j} S1,j?, S 2 , j S_{2, j} S2,j? , t i , j t_{i, j} ti,j?的值,對小資料模型利用蠻力法測驗演算法的正確性;
- 隨機產生 S 1 , j S_{1, j} S1,j?, S 2 , j S_{2, j} S2,j? , t i , j t_{i, j} ti,j?的值,對不同資料規模( n n n的值)測驗演算法效率,并與理論效率進行比對,請提供能處理的資料最大規模,注意要在有限時間內處理完;
- 該演算法是否有效率提高的空間?包括空間效率和時間效率,
三、實驗步驟與程序
(一)暴力窮舉法
1、演算法描述:
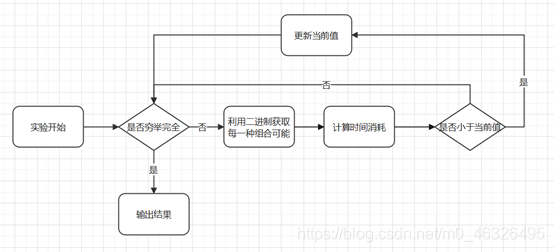
對于暴力窮舉解決流水線問題,只需對所有組合可能進行完備窮舉,并選擇較小的時間消耗作為最終結果,由于暴力法是對每一種解的完備搜索,因此暴力法的正確性有很高的保證,
2、時間復雜度分析:
對于一條流水線上的每個單元,存在兩種選擇,即選擇在流水線1上或在流水線2上,因此,對于 n n n個單元,存在 2 n 2^n 2n種不同的選擇,因此暴力窮舉法時間復雜度為 O ( 2 n ) O(2^n ) O(2n)
3、編程實作:
偽代碼如下
//find each combination by binary
bitset<LEN> flagBit;
//least cost
int res = 1e9
//cost of chassis enters
int e[2]
//cost of each station
int a[2][LEN]
//cost of transform
int t[2][LEN]
//Use binary to brute force each combination
while (flagBit!=0):
//Use binary to identify the combination
//'0' for line 0, '1' for line 1
currentCost = 0
//chassis enters
if (flagBit[0] == 0):
currentCost += (e[0] + a[0][0])
else:
currentCost += (e[1] + a[1][0])
//each station
for i from 1 to LEN:
//cost of a station
currentCost += a[flagBit[i]][i]
//if transform
if flagBit[i] != flagBit[i - 1]
currentCost += t[flagBit[i - 1]][i - 1]
res = min(res, currentCost)
flagBit--
print(res)
①通過二進制表示每個流水線的選擇情況,如果為0則選擇第一個流水線,如果為1則選擇第二個流水線
②在回圈中進行判斷,如果當前環節流水線與上一環節的流水線不相同,則需額外加上轉移流水線消耗的時間,
③進入流水線與退出流水線的消耗時間直接加到當前運行時間即可
④完成一次可能的計算后,將當前時間消耗值與當前最小時間消耗值進行比較,如果小于當前最小時間消耗值,則進行更新,
⑤完成所有可能的窮舉后即可獲得最小時間消耗值,
4、運行并測驗:
使用亂數生成器生成了不同大小的多組測驗資料,為了避免運行時的偶然情況,對于每個數量級下的多組資料進行20次測驗并取平均值作為該資料量級下的結果,并統計如下:
| 資料量 | 21 | 22 | 23 | 24 | 25 |
|---|---|---|---|---|---|
| 時間消耗 | 1365.37 | 2801.65 | 5773.67 | 11980 | 24755.9 |
| 資料量 | 26 | 27 | 28 | 29 | 30 |
| 時間消耗 | 50664.1 | 103965 | 210728 | 436047 | 893954 |
選取資料量為25時的運行時間為理論值,將各個資料取對數并作圖如下:
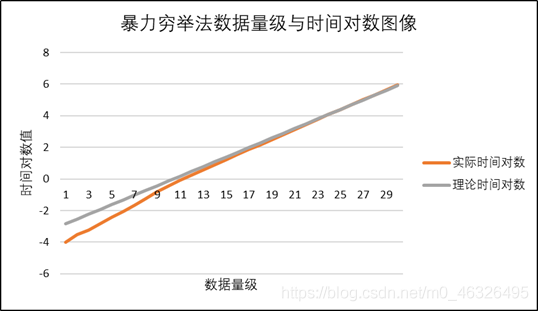
通過分析可知,對于全體資料,時間復雜度大致滿足
O
(
2
n
)
O(2^n )
O(2n),證明時間復雜度分析是正確的,通過觀察影像,我們也可以發現,當資料量較小時,實際運行時間要比理論運行時間短這是因為演算法運行程序中每運行一次都要開辟動態空間,每次開辟空間均會對后面演算法的執行造成影響,當資料量較小時,已經開辟的動態空間較少,對演算法影響小,因此會比較快;但當資料量較大時,已經開辟了很多空間,對演算法影響較大,因此會比較慢,
(二)動態規劃法
1、演算法描述:
(1)分析規劃程序:
通過分析,我們可以知道,當流水線運行到第j個配件站是最優的,則到達該配件站前可能為
S
(
1
,
j
?
1
)
S(1,j-1)
S(1,j?1)或
S
(
2
,
j
?
1
)
S(2,j-1)
S(2,j?1),且到達
S
(
1
,
j
?
1
)
S(1,j-1)
S(1,j?1)或
S
(
2
,
j
?
1
)
S(2,j-1)
S(2,j?1)的路徑同樣也為最短的,即到達S(1,j)的最優解包含了到達
S
(
1
,
j
?
1
)
S(1,j-1)
S(1,j?1)或
S
(
2
,
j
?
1
)
S(2,j-1)
S(2,j?1)的最優解,對于通過的最優路線,必然通過了流水線1或流水線2的
j
?
1
j-1
j?1配件站,因此,通過
S
(
1
,
j
)
S(1,j)
S(1,j)的最優路線只能是如下兩種選擇:
①通過配件站
S
(
1
,
j
?
1
)
S(1,j-1)
S(1,j?1),然后直接到達
S
(
1
,
j
)
S(1,j)
S(1,j)
②通過配件站
S
(
2
,
j
?
1
)
S(2,j-1)
S(2,j?1),然后從流水線2到流水線1最后到達
S
(
1
,
j
)
S(1,j)
S(1,j)
由于流水線1與流水線2是完全對稱的,因此需要找到到達某一配件站的最短時間,只需解決兩個子問題的最短時間,并通過對子問題的求解最后構造出整個問題的最優解即可,
(2)分析動態規劃方程:
首先我們將到達最后出口的最短時間記作
f
?
f^*
f?,流水線長度都為
n
n
n,則有:
f
?
=
m
i
n
?
(
f
1
[
n
]
+
x
1
,
f
2
[
n
]
+
x
2
)
f^*=min?(f_1 [n]+x_1,f_2 [n]+x_2 )
f?=min?(f1?[n]+x1?,f2?[n]+x2?)
當進入流水線第一個環節時,則可得:
f
1
[
1
]
=
e
1
+
a
1
,
1
f_1 [1]=e_1+a_{1,1}
f1?[1]=e1?+a1,1?
f
2
[
1
]
=
e
2
+
a
2
,
1
f_2 [1]=e_2+a_{2,1}
f2?[1]=e2?+a2,1?
通過對上面的分析,有:
f
1
[
j
]
=
{
e
1
+
a
1
,
1
j=1
m
i
n
?
(
f
1
[
j
?
1
]
+
a
1
,
j
,
f
2
[
j
?
1
]
+
t
2
,
j
?
1
+
a
1
,
j
j≥2
f_1 [j]= \begin{cases} e_1+a_{1,1}& \text{j=1}\\ min?(f_1 [j-1]+a_{1,j} ,f_2 [j-1]+t_{2,j-1}+a_{1,j}& \text{j≥2} \end{cases}
f1?[j]={e1?+a1,1?min?(f1?[j?1]+a1,j?,f2?[j?1]+t2,j?1?+a1,j??j=1j≥2?
f 2 [ j ] = { e 2 + a 2 , 1 j=1 m i n ? ( f 2 [ j ? 1 ] + a 2 , j , f 1 [ j ? 1 ] + t 1 , j ? 1 + a 2 , j j≥2 f_2 [j]= \begin{cases} e_2+a_{2,1}& \text{j=1}\\ min?(f_2 [j-1]+a_{2,j} ,f_1 [j-1]+t_{1,j-1}+a_{2,j}& \text{j≥2} \end{cases} f2?[j]={e2?+a2,1?min?(f2?[j?1]+a2,j?,f1?[j?1]+t1,j?1?+a2,j??j=1j≥2?
2、時間復雜度分析:
通過分析演算法描述中的運行程序可知,在運行程序中,僅需按照流水線順序進行從頭至尾一次掃描即可,因此時間復雜度為 O ( n ) O(n) O(n)
3、編程實作:
撰寫偽代碼如下:
f1[1]<- e1+a1,1 //處理第一個環節
f2[1]<- e2+a2,1 //處理第一個環節
for j<-2 to n //對第2到第n個環節進行處理
do if f1[j-1]+a1,j <=f2[j-1]+t2,j-1+a1,j //對第一條流水線的最優解進行判斷
then
f1[j]<-f1[j-1]+a1,j
l1[j]<-1
else
f1[j]<-f2[j-1]+t2,j-1+a1,j
l1[j]<-2
if f2[j-1]+a2,j <=f1[j-1]+t1,j-1+a2,j //對第二條流水線的最優解進行判斷
then
f1[j]<-f2[j-1]+a2,j
l2[j]<-1
else
f1[j]<-f1[j-1]+t1,j-1+a2,j
l1[j]<-2
if f1[n]+x1<=f2[n]+x2 //最終最優解判斷
then
f* <-f1[n]+x1
l* <-1
else
f* <-f2[n]+x2
l* <-2
4、運行并測驗:
①正確性檢驗:
為了驗證動態規劃演算法的正確性,生成大量隨機資料并使用暴力窮舉法和動態規劃法進行同步運行,并比較運行結果是否一致,生成了
1
0
5
10^5
105組不同的測驗資料,在兩種方法線下均可以得到相同的結果,結合邏輯分析,可以證明動態規劃演算法是正確的,
②效率分析:
使用亂數生成器生成了不同大小的多組測驗資料,為了避免運行時的偶然情況,對于每個數量級下的多組資料進行20次測驗并取平均值作為該資料量級下的結果,并統計如下:
| 資料量 | 1 0 3 10^3 103 | 1 0 4 10^4 104 | 1 0 5 10^5 105 | 1 0 6 10^6 106 | 1 0 7 10^7 107 | 1 0 8 10^8 108 |
|---|---|---|---|---|---|---|
| 時間消耗 | 0.1326 | 2.0574 | 25.3951 | 256.145 | 2560.04 | 25584 |
選取資料量為
1
0
6
10^6
106時的運行時間為理論值,取對數并作圖如下:
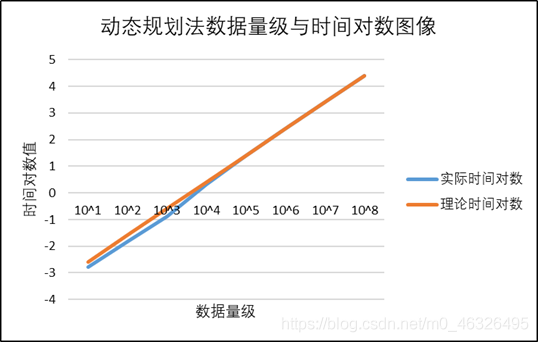
通過分析可知,對于全體資料,時間復雜度大致滿足 O ( n ) O(n) O(n),證明時間復雜度分析是正確的,整體影像大致成線性,擬合效果比較好,
(三)效率對比分析
對于暴力窮舉以及動態規劃兩種演算法,根據現有資料以及時間復雜度分析,大致做出如下表:
| 資料量 | 10 | 50 | 100 | 500 | 1000 | 10000 |
|---|---|---|---|---|---|---|
| 暴力窮舉 | 0.3582ms | 29y | 100y+ | 100y+ | 100y+ | 100y+ |
| 動態規劃 | 0.0017 | 0.0691 | 0.0145 | 0.0710 | 0.1326 | 2.0574 |
從上表以及對兩演算法的運行時間圖沖大致可以看出,暴力窮舉演算法的時間復雜度是十分恐怖的,對于一些稍微大一些的資料,需要若干年才能得出結果,而動態規劃只需若干毫秒,時間對比十分明顯,因此在進行流水線調度問題時,我們要選擇動態規劃法進行計算,
四、實驗結論或體會
- 常規窮舉法的效率常常是非常低的,對于一些問題,可以將大問題轉為若干個子問題,并利用動態規劃思想進行運算可以很大程度上降低運行時間,
- 在進行演算法優化程序中,除了降低演算法的時間復雜度,降低演算法運行的常數級時間也是很重要的,也可以極大的降低程式的時間消耗,
- 演算法的空間消耗也很重要,可以通過采用更優的資料結構降低空間消耗,
- 選取合適的資料結構可以又降低運行時間又減少運行空間,
五、思考(時間與空間優化)
1、演算法描述:
在運行動態規劃演算法的代碼時,經常發現,演算法能運行的資料大小是有限的,無法運行一些特別大的資料,比如超過 1 0 8 10^8 108的資料,
當資料量大到一定程度后,會造成由于陣列太大造成記憶體不足,而拋出std::bad_alloc例外(俗稱爆記憶體),這限制了程式對更大資料量的處理,通過分析程式,我們可以發現,在對動態規劃的路徑保存程序中,使用了32位整型int對路徑進行存盤,但對于本題來講,路徑值只可能為0或1,因此造成了大量的空間冗余浪費,不妨采取一種新的資料結構對路徑進行優化存盤,
并且運行中采用了一個另外的陣列來記錄當前的最小時間消耗值,但通過邏輯分析,可以發現,該陣列被創建后,僅僅最后一個元素被二次訪問過,中間的元素只被創建,并沒有多次訪問,因此創建陣列是無意義的,可以直接采用unsigned long long型變數對當前最小值進行存盤
2、進行優化:
①引入bitset資料結構:
為了更好的存盤0或1,而盡少占用空間,可以引入bitset這一資料結構,在bitset中,僅對0或1的值進行存盤,因而每位bitset只占1位元,而int型占32位元,采用該資料結構成功將記憶體占用降低為之前的1/32,并且,由于bitset是基于底層位邏輯,因此采用bitset資料結構后,程式的運行時間也會降低很多,
②減少無用陣列:
在編程程序中對當前最優時間的存盤采用了陣列進行存盤,由于陣列只創建,并在運算程序中進行了單次呼叫,因此可以使用last_1_cost,last_2_cost,current_1_cost,current_1_cost四個unsigned long long型變數存盤上一次流水線1,2的最優時間和當前流水線1,2的最優時間,這不僅減少了程式運行消耗的空間,也避免了反復對陣列進行大量操作,從而降低程式運行時間,
③避免一次加載所有資料:
由于記錄流水線的每個環節消耗時間與流水線切換時間的陣列是采用int型,并且是不可預設的,若直接一次性加載到記憶體中將占用很多記憶體,因此,不妨分多次將資料加載到記憶體中,一次加載
1
0
7
10^7
107的資料到記憶體中,并進行運算,當運算完加載的資料后,再將大小為
1
0
7
10^7
107的資料加載到記憶體中,依次回圈,
3、進行測驗:
| 資料量 | 1 0 2 10^2 102 | 1 0 3 10^3 103 | 1 0 4 10^4 104 | 1 0 5 10^5 105 | 1 0 6 10^6 106 | 1 0 7 10^7 107 |
|---|---|---|---|---|---|---|
| 優化前 | 0.0145 | 0.1326 | 2.0574 | 25.3951 | 256.145 | 2560.04 |
| 優化后 | 0.1963 | 0.2327 | 0.301 | 0.387 | 2.6621 | 25.2525 |
| 資料量 | 1 0 8 10^8 108 | 1 0 9 10^9 109 | 1 0 10 10^{10} 1010 | 1 0 11 10^{11} 1011 | 1 0 12 10^{12} 1012 | 1 0 13 10^{13} 1013 |
| 優化前 | 25584 | 記憶體超限 | 記憶體超限 | 記憶體超限 | 記憶體超限 | 記憶體超限 |
| 優化后 | 166.232 | 1750.7 | 15811.2 | 157603 | 1511351 | 1.5 × 1 0 7 1.5×10^7 1.5×107 |
可以看到,優化之后的演算法與優化前相比,不僅能處理更大的資料,并且運行時間得到了很大提升,大約縮短至原 1 / 100 1/100 1/100,因此演算法優化是有效的,并且是高效的,
4、只用記憶體進行運算:
此外,如果不采用記憶體進行保存結果,只采用記憶體進行運算,即一邊進行動態規劃,一邊進行讀入資料,可以在理論上做到處理無窮大的資料,
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/287194.html
標籤:其他
上一篇:從0-1搭建一個天氣預報網站