還沒有女朋友的朋友們,你們有福了,學會CycleGAN把男朋友變成女朋友
- 前言
- 效果展示
- 使用 CycleGAN 進行不成對的影像轉換
- 不成對的資料集
- CycleGAN模型
- 資料集
- 資料加載與預處理
- 模型構建
- 訓練結果可視化函式
- 訓練步驟
- 效果二次展示
前言
事情的起因是這樣的,室友在經歷的4年的找女朋友之旅后,終于放棄了,而我為了讓他的青春不留遺憾,只能使用 CycleGAN 把下鋪壯漢變成萌妹了,
轉眼又到了畢業季,還在為沒有女朋友而著急么?還在為沒有談一場青春的戀愛而遺憾么?還沒有女朋友的朋友們,你們有福了!!!沒有女朋友,還能沒有男朋友么?學會 CycleGAN ,把男朋友變成女朋友,趕快學起來吧,
效果展示
在學習之前,大家肯定想先知道CycleGAN模型進行男女性別轉換的效果如何,所以先讓大家看看模型訓練的效果.




效果這么驚人,還不快學起來???
使用 CycleGAN 進行不成對的影像轉換
CycleGAN 可以使用兩個生成器和兩個鑒別器訓練不成對(unpaired)的影像,
本文主要以實戰為主,如果想要了解 CycleGAN 背后的具體原理,請參考 CycleGAN 原理與實作(采用tensorflow2.x實作).
不成對的資料集
CycleGAN 的一個重要貢獻是,改變了pix2pix需要成對的訓練資料集的缺點,某些情況下,我們可以很容易地創建成對資料集,如彩色的影像對應的灰度影像資料集,完成成對資料集的構建,從而用于訓練灰度影像上色的深度學習模型,但是,更多數的情況下,無法創建成對的資料集,例如從男性到女性的影像轉換,
這便是 CycleGAN 的優勢所在,因為它不需要成對的資料, CycleGAN 可以訓練不成對的資料集!
CycleGAN模型
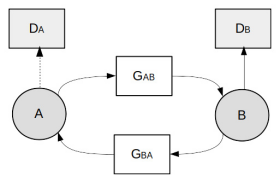
簡單看下CycleGAN的體系架構:
資料集
資料集取自 Celeb A ,可以自行構建資料集,也可以使用此資料集,提取碼:nql9,
資料加載與預處理
# 匯入必要庫
import tensorflow as tf
import os
import time
from matplotlib import pyplot as plt
import tensorflow_datasets as tfds
AUTOTUNE = tf.data.experimental.AUTOTUNE
# 定義超引數
BUFFER_SIZE = 128
BATCH_SIZE = 1
IMG_WIDTH = 256
IMG_HEIGHT = 256
OUTPUT_CHANNELS = 3
LAMBDA = 10
EPOCHS = 100
"""
# 資料預處理函式
"""
def random_crop(image):
cropped_image = tf.image.random_crop(image, size=[IMG_HEIGHT, IMG_WIDTH, 3])
return cropped_image
# normalizing the images to [-1, 1]
def normalize(image):
image = tf.cast(image, tf.float32)
image = (image / 127.5) - 1
return image
def random_jitter(image):
# resizing to 286 x 286 x 3
image = tf.image.resize(image, [286, 286], method=tf.image.ResizeMethod.NEAREST_NEIGHBOR)
# randomly cropping to 256 x 256 x 3
image = random_crop(image)
# random mirroring
image = tf.image.random_flip_left_right(image)
return image
def preprocess_image_train(image):
image = random_jitter(image)
image = normalize(image)
return image
def preprocess_image_test(image):
image = normalize(image)
return image
def load(image_file):
image = tf.io.read_file(image_file)
image = tf.image.decode_jpeg(image)
input_image = tf.cast(image, tf.float32)
return input_image
def load_image_train(image_file):
image = load(image_file)
image = preprocess_image_train(image)
return image
def load_image_test(image_file):
image = load(image_file)
image = preprocess_image_test(image)
return image
# 加載男性圖片,構建訓練資料集
train_man = tf.data.Dataset.list_files('./man2woman/trainA/*.jpg')
train_man = train_man.map(load_image_train, num_parallel_calls=tf.data.experimental.AUTOTUNE)
train_man = train_man.shuffle(BUFFER_SIZE)
train_man = train_man.batch(BATCH_SIZE, drop_remainder=True)
# 加載女性圖片,構建訓練資料集
train_woman = tf.data.Dataset.list_files('./man2woman/trainB/*.jpg')
train_woman = train_woman.map(load_image_train, num_parallel_calls=tf.data.experimental.AUTOTUNE)
train_woman = train_woman.shuffle(BUFFER_SIZE)
train_woman = train_woman.batch(BATCH_SIZE, drop_remainder=True)
模型構建
在 CycleGAN 中,使用實體歸一化代替批歸一化,但在 tensorflow 中,未包含實體歸一化層,因此需要自行實作,
class InstanceNormalization(tf.keras.layers.Layer):
"""Instance Normalization Layer."""
def __init__(self, epsilon=1e-5):
super(InstanceNormalization, self).__init__()
self.epsilon = epsilon
def build(self, input_shape):
self.scale = self.add_weight(
name='scale',
shape=input_shape[-1:],
initializer=tf.random_normal_initializer(1., 0.02),
trainable=True)
self.offset = self.add_weight(
name='offset',
shape=input_shape[-1:],
initializer='zeros',
trainable=True)
def call(self, x):
mean, variance = tf.nn.moments(x, axes=[1, 2], keepdims=True)
inv = tf.math.rsqrt(variance + self.epsilon)
normalized = (x - mean) * inv
return self.scale * normalized + self.offset
為了減少代碼量,定義上采樣塊和下采樣塊:
# 下采樣塊
def downsample(filters, size, norm_type='batchnorm', apply_norm=True):
initializer = tf.random_normal_initializer(0., 0.02)
result = tf.keras.Sequential()
result.add(
tf.keras.layers.Conv2D(filters, size, strides=2, padding='same',
kernel_initializer=initializer, use_bias=False))
if apply_norm:
if norm_type.lower() == 'batchnorm':
result.add(tf.keras.layers.BatchNormalization())
elif norm_type.lower() == 'instancenorm':
result.add(InstanceNormalization())
result.add(tf.keras.layers.LeakyReLU())
return result
# 上采樣快
def upsample(filters, size, norm_type='batchnorm', apply_dropout=False):
initializer = tf.random_normal_initializer(0., 0.02)
result = tf.keras.Sequential()
result.add(
tf.keras.layers.Conv2DTranspose(filters, size, strides=2,
padding='same',
kernel_initializer=initializer,
use_bias=False))
if norm_type.lower() == 'batchnorm':
result.add(tf.keras.layers.BatchNormalization())
elif norm_type.lower() == 'instancenorm':
result.add(InstanceNormalization())
if apply_dropout:
result.add(tf.keras.layers.Dropout(0.5))
result.add(tf.keras.layers.ReLU())
return result
接下來構建生成器:
def unet_generator(output_channels, norm_type='batchnorm'):
down_stack = [
downsample(64, 4, norm_type, apply_norm=False),
downsample(128, 4, norm_type),
downsample(256, 4, norm_type),
downsample(512, 4, norm_type),
downsample(512, 4, norm_type),
downsample(512, 4, norm_type),
downsample(512, 4, norm_type),
downsample(512, 4, norm_type),
]
up_stack = [
upsample(512, 4, norm_type, apply_dropout=True),
upsample(512, 4, norm_type, apply_dropout=True),
upsample(512, 4, norm_type, apply_dropout=True),
upsample(512, 4, norm_type),
upsample(256, 4, norm_type),
upsample(128, 4, norm_type),
upsample(64, 4, norm_type),
]
initializer = tf.random_normal_initializer(0., 0.02)
last = tf.keras.layers.Conv2DTranspose(
output_channels, 4, strides=2,
padding='same', kernel_initializer=initializer,
activation='tanh') # (bs, 256, 256, 3)
concat = tf.keras.layers.Concatenate()
inputs = tf.keras.layers.Input(shape=[None, None, 3])
x = inputs
# Downsampling through the model
skips = []
for down in down_stack:
x = down(x)
skips.append(x)
skips = reversed(skips[:-1])
# Upsampling and establishing the skip connections
for up, skip in zip(up_stack, skips):
x = up(x)
x = concat([x, skip])
x = last(x)
return tf.keras.Model(inputs=inputs, outputs=x)
構建鑒別器:
def discriminator(norm_type='batchnorm', target=True):
initializer = tf.random_normal_initializer(0., 0.02)
inp = tf.keras.layers.Input(shape=[None, None, 3], name='input_image')
x = inp
if target:
tar = tf.keras.layers.Input(shape=[None, None, 3], name='target_image')
x = tf.keras.layers.concatenate([inp, tar]) # (bs, 256, 256, channels*2)
down1 = downsample(64, 4, norm_type, False)(x) # (bs, 128, 128, 64)
down2 = downsample(128, 4, norm_type)(down1) # (bs, 64, 64, 128)
down3 = downsample(256, 4, norm_type)(down2) # (bs, 32, 32, 256)
zero_pad1 = tf.keras.layers.ZeroPadding2D()(down3) # (bs, 34, 34, 256)
conv = tf.keras.layers.Conv2D(
512, 4, strides=1, kernel_initializer=initializer,
use_bias=False)(zero_pad1) # (bs, 31, 31, 512)
if norm_type.lower() == 'batchnorm':
norm1 = tf.keras.layers.BatchNormalization()(conv)
elif norm_type.lower() == 'instancenorm':
norm1 = InstanceNormalization()(conv)
leaky_relu = tf.keras.layers.LeakyReLU()(norm1)
zero_pad2 = tf.keras.layers.ZeroPadding2D()(leaky_relu) # (bs, 33, 33, 512)
last = tf.keras.layers.Conv2D(
1, 4, strides=1,
kernel_initializer=initializer)(zero_pad2) # (bs, 30, 30, 1)
if target:
return tf.keras.Model(inputs=[inp, tar], outputs=last)
else:
return tf.keras.Model(inputs=inp, outputs=last)
實體化生成器與鑒別器:
generator_g = unet_generator(OUTPUT_CHANNELS, norm_type='instancenorm')
generator_f = unet_generator(OUTPUT_CHANNELS, norm_type='instancenorm')
discriminator_x = discriminator(norm_type='instancenorm', target=False)
discriminator_y = discriminator(norm_type='instancenorm', target=False)
損失函式與優化器的定義:
loss_obj = tf.keras.losses.BinaryCrossentropy(from_logits=True)
# 鑒別器損失
def discriminator_loss(real, generated):
real_loss = loss_obj(tf.ones_like(real), real)
generated_loss = loss_obj(tf.zeros_like(generated), generated)
total_disc_loss = real_loss + generated_loss
return total_disc_loss * 0.5
# 生成器損失
def generator_loss(generated):
return loss_obj(tf.ones_like(generated), generated)
# 回圈一致性損失
def calc_cycle_loss(real_image, cycled_image):
loss1 = tf.reduce_mean(tf.abs(real_image - cycled_image))
return LAMBDA * loss1
# identity loss
def identity_loss(real_image, same_image):
loss = tf.reduce_mean(tf.abs(real_image - same_image))
return LAMBDA * 0.5 * loss
# 優化器
generator_g_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)
generator_f_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)
discriminator_x_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)
discriminator_y_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)
訓練結果可視化函式
創建 generate_images 函式用于在訓練程序中查看模型效果.
def generate_images(model, test_input):
prediction = model(test_input)
plt.figure(figsize=(12, 12))
display_list = [test_input[0], prediction[0]]
title = ['Input Image', 'Predicted Image']
for i in range(2):
plt.subplot(1, 2, i+1)
plt.title(title[i])
# getting the pixel values between [0, 1] to plot it.
plt.imshow(display_list[i] * 0.5 + 0.5)
plt.axis('off')
# plt.show()
plt.savefig('results/{}.png'.format(int(time.time())))
訓練步驟
首先需要定義訓練函式:
@tf.function
def train_step(real_x, real_y):
with tf.GradientTape(persistent=True) as tape:
# Generator G translates X -> Y
# Generator F translates Y -> X.
fake_y = generator_g(real_x, training=True)
cycled_x = generator_f(fake_y, training=True)
fake_x = generator_f(real_y, training=True)
cycled_y = generator_g(fake_x, training=True)
# same_x and same_y are used for identity loss.
same_x = generator_f(real_x, training=True)
same_y = generator_g(real_y, training=True)
disc_real_x = discriminator_x(real_x, training=True)
disc_real_y = discriminator_y(real_y, training=True)
disc_fake_x = discriminator_x(fake_x, training=True)
disc_fake_y = discriminator_y(fake_y, training=True)
# calculate the loss
gen_g_loss = generator_loss(disc_fake_y)
gen_f_loss = generator_loss(disc_fake_x)
total_cycle_loss = calc_cycle_loss(real_x, cycled_x) + calc_cycle_loss(real_y, cycled_y)
# Total generator loss = adversarial loss + cycle loss
total_gen_g_loss = gen_g_loss + total_cycle_loss + identity_loss(real_y, same_y)
total_gen_f_loss = gen_f_loss + total_cycle_loss + identity_loss(real_x, same_x)
disc_x_loss = discriminator_loss(disc_real_x, disc_fake_x)
disc_y_loss = discriminator_loss(disc_real_y, disc_fake_y)
# Calculate the gradients for generator and discriminator
generator_g_gradients = tape.gradient(total_gen_g_loss, generator_g.trainable_variables)
generator_f_gradients = tape.gradient(total_gen_f_loss, generator_f.trainable_variables)
discriminator_x_gradients = tape.gradient(disc_x_loss, discriminator_x.trainable_variables)
discriminator_y_gradients = tape.gradient(disc_y_loss, discriminator_y.trainable_variables)
# Apply the gradients to the optimizer
generator_g_optimizer.apply_gradients(zip(generator_g_gradients, generator_g.trainable_variables))
generator_f_optimizer.apply_gradients(zip(generator_f_gradients, generator_f.trainable_variables))
discriminator_x_optimizer.apply_gradients(zip(discriminator_x_gradients, discriminator_x.trainable_variables))
discriminator_y_optimizer.apply_gradients(zip(discriminator_y_gradients, discriminator_y.trainable_variables))
最后進行模型的訓練:
for epoch in range(EPOCHS):
start = time.time()
n = 0
for image_x, image_y in tf.data.Dataset.zip((train_man, train_woman)):
train_step(image_x, image_y)
# generate_images(generator_g, sample_man)
if n % 10 == 0:
print ('.', end='')
n += 1
# 采樣測驗資料集, 測驗模型效果
sample_man = next(iter(train_man))
sample_woman = next(iter(train_woman))
generate_images(generator_g, sample_man)
generate_images(generator_f, sample_woman)
print ('Time taken for epoch {} is {} sec\n'.format(epoch + 1, time.time()-start))
效果二次展示
我們已經在開始時看到了 CycleGAN 在男性轉換為女性的結果,再看下將女性轉換為男性的效果吧!


轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/287421.html
標籤:其他