概述
排序:給定一個元素序列,按照每個元素的關鍵碼將元素重新排列,使關鍵碼從小到大(正序)或從大到小(逆序)排列,
排序可根據是否將全部元素放入記憶體分為內部排序和外部排序,
內部排序:資料元素全部放在記憶體中的排序,
外部排序:資料元素太多不能同時放在記憶體中,根據排序程序的要求不能在內外存之間移動資料的排序,
穩定性:假定在待排序的記錄序列中,存在多個具有相同的關鍵字的記錄,若經過排序,這些記錄的相對次序保持不變,即在原序列中,r[i]=r[j],且r[i]在r[j]之前,而在排序后的序列中,r[i]仍在r[j]之前,則稱這種排序演算法是穩定的;否則稱為不穩定的,
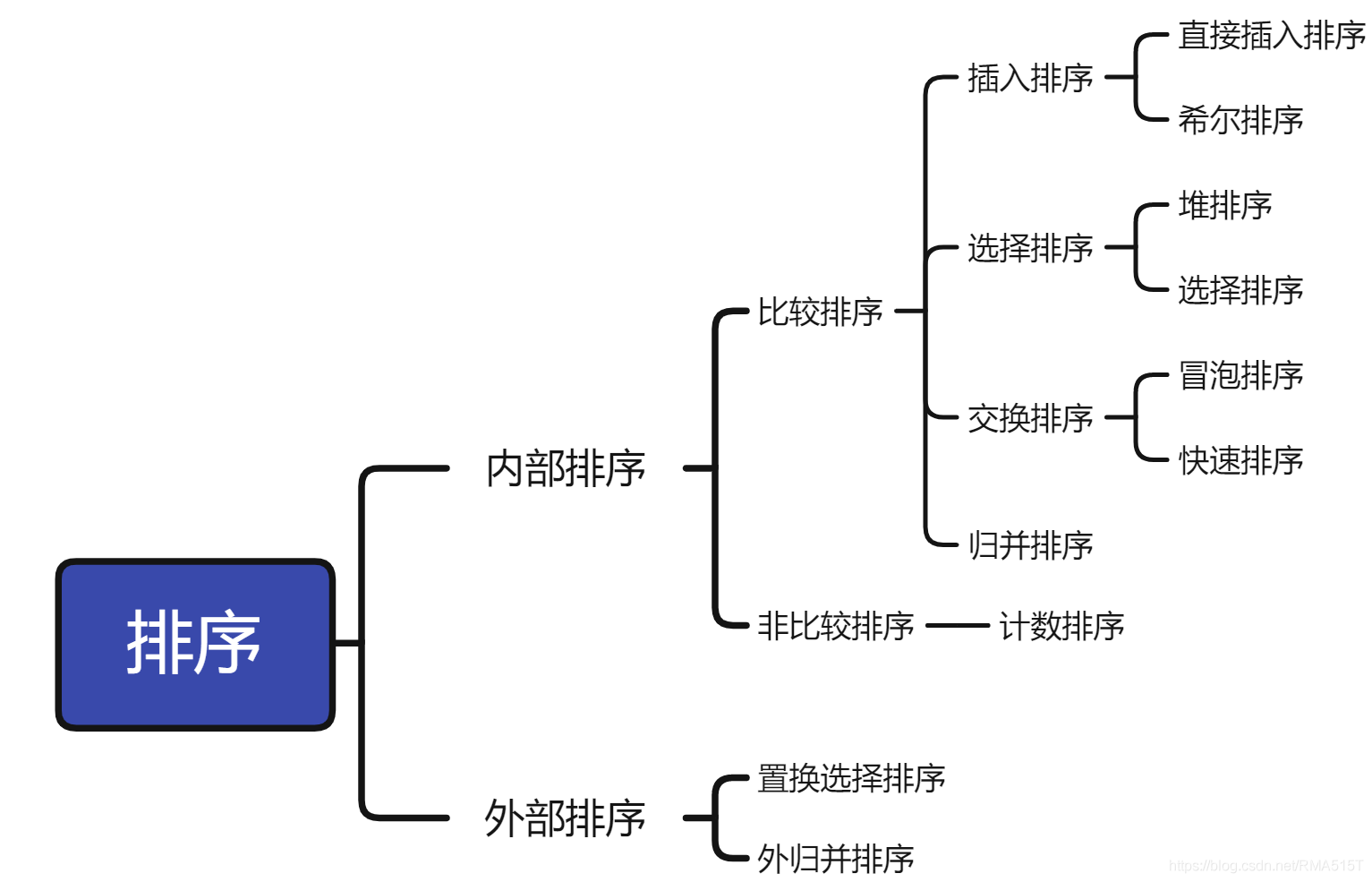
這里所說的八大排序就是內部排序,
下面對八大排序演算法進行性能比較,包括時間復雜度的最好最壞平均情況,空間復雜度,穩定性,
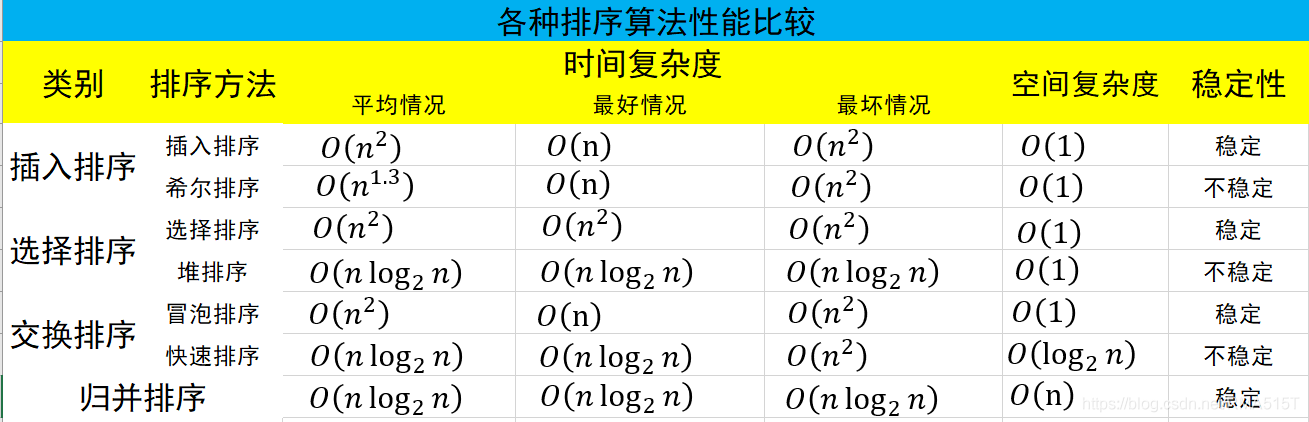
快速排序:是目前基于比較的內部排序中被認為是最好的方法,當待排序的關鍵字是隨機分布時,快速排序的平均時間最短;
下面對每種排序進行詳解(均以升序為例)
介面程式:
void Print(int* a, int n); //列印
void InsertSort(int* a, int n); //插入排序
void ShellSort(int* a, int n); // 希爾排序
void SelectSort(int* a, int n); // 選擇排序
void AdjustDown(int* a, int n, int root); //重建大堆
void HeapSort(int* a, int n); // 堆排序
// 冒泡排序
void BubbleSort(int* a, int n);
// 快速排序遞回實作
// 快速排序hoare版本
int PartSort1(int* a, int left, int right);
// 快速排序挖坑法
int PartSort2(int* a, int left, int right);
// 快速排序前后指標法
int PartSort3(int* a, int left, int right);
void QuickSort(int* a, int begin, int end);
//非遞回
void QuickSortNonR(int* a, int begin, int end);
//歸并
void MergeSrt(int* a, int n);
//歸并,非遞回
void MergeSrtNonR(int* a, int n);
void CountSort(int* a, int n); //計數排序
1.插入排序—直接插入排序(Straight Insertion Sort)
基本思想
直接插入排序是一種簡單的插入排序法,其基本思想是:把待排序的記錄按其關鍵碼值的大小逐個插入到一個已經排好序的有序序列中,直到所有的記錄插入完為止,得到一個新的有序序列 ,實際中我們玩撲克牌時,就用了插入排序的思想,
它的作業原理是通過構建有序序列,對于未排序資料,在已排序序列中從后向前掃描,找到相應位置并插入,
演算法步驟:
1)將第一待排序序列第一個元素看做一個有序序列,把第二個元素到最后一個元素當成是未排序序列;
2)從頭到尾依次掃描未排序序列,將掃描到的每個元素插入有序序列的適當位置(相同則插入相等元素后邊),

元素集合越接近有序,直接插入排序演算法的時間效率越高,是一種穩定的排序演算法,
演算法實作
void InsertSort(int* a, int n)
{
for (int i = 0; i < n - 1; i++)
{
int end = i;
int tmp = a[end + 1]; //tmp在每回圈內不變
while (end >= 0)
{
//int tmp = a[end + 1]; 每次進來就會更新掉tmp達不到目的
if (tmp < a[end])
{
a[end + 1] = a[end];
end--;
}
else
{
//a[end + 1] = tmp;
break;
}
}
a[end + 1] = tmp; //還要考慮end<0跳出回圈的情況,即tmp比a[0]還要小,所以要在回圈外
}
}
2. 插入排序—希爾排序(Shell`s Sort)
基本思想
希爾排序是1959 年由D.L.Shell 提出來的,相對直接排序有較大的改進,希爾排序又叫縮小增量排序,
基本思想是:先選定一個整數,把待排序檔案中所有記錄分組,所有距離為的記錄分在同一組內,并對每一組內的記錄進行排序,然后,取,重復上述分組和排序的作業,當到達gap=1時,所有記錄在統一組內排好序,
1)選擇一個增量序列d[1],t[2],…,d[k],其中d[i]>d[j],d[k]=1;
2)按增量序列個數k,對序列進行k 趟排序;
3)每趟排序,根據對應的增量ti,將待排序列分割成若干長度為m 的子序列,分別對各子表進行直接插入排序,僅增量因子為1 時,整個序列作為一個表來處理,表長度即為整個序列的長度,
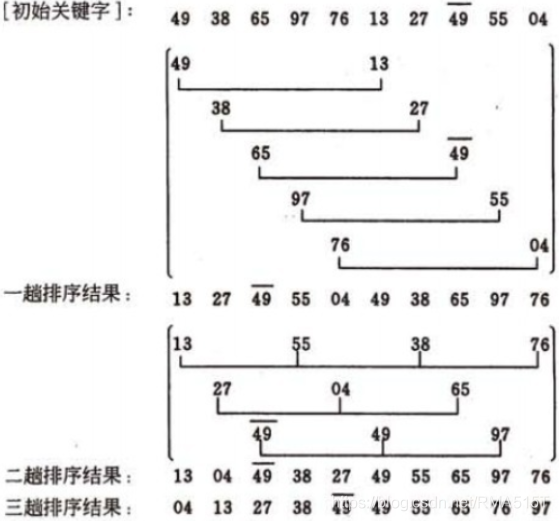
希爾排序是對直接插入排序的優化,當gap > 1時都是預排序,目的是讓陣列更接近于有序,當gap == 1時,陣列已經接近有序的了,這樣就
會很快,這樣整體而言,可以達到優化的效果,我們實作后可以進行性能測驗的對比,
演算法實作
void ShellSort(int* a, int n) // 希爾排序
{
int gap = n;
while (gap > 1) //因為是進入回圈后才操作gap,所以最后一次回圈必然是 gap == 1.即一次直接插入排序
{
gap = (gap / 5 + 1); //防止gap/5 = 0,所以需要+1,
for (int i = 0; i < n - gap; i++) //直接++就可以回到之前的那一組
{
int end = i;
int tmp = a[end + gap]; //所有地方相當于把直接插入排序的1變成了gap
while (end >= 0)
{
if (tmp < a[end])
{
a[end + gap] = a[end];
end -= gap;
}
else
{
break;
}
}
a[end + gap] = tmp;
}
}
}
3. 選擇排序—簡單選擇排序(Simple Selection Sort)
基本思想
在要排序的一組數中,選出最小(或者最大)的一個數與第1個位置的數交換;然后在剩下的數當中再找最小(或者最大)的與第2個位置的數交換,依次類推,直到第n-1個元素(倒數第二個數)和第n個元素(最后一個數)比較為止,每趟回圈只能確定一個元素排序后的定位,我們可以考慮改進為每趟回圈確定兩個元素(當前趟最大和最小記錄)的位置,從而減少排序所需的回圈次數,改進后對n個資料進行排序,最多只需進行[n/2]趟回圈即可,
1)在元素集合array[i]–array[n-1]中選擇關鍵碼最大(小)的資料元素
2)若它不是這組元素中的最后一個(第一個)元素,則將它與這組元素中的最后一個(第一個)元素交換
3)在剩余的array[i]–array[n-2](array[i+1]–array[n-1])集合中,重復上述步驟,直到集合剩余1個元素
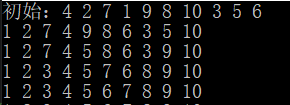
直接選擇排序思考非常好理解,但是效率不是很好,實際中很少使用,
演算法實作
void SelectSort(int* a, int n) // 選擇排序
{
int left = 0;
int right = n - 1;
while (left < right) //當錯過了,或相等就結束了
{
int max = left; //都設定為第一個元素,每次換完上下界都要更新
int min = left;
for (int i = left; i <= right; i++)
{
if (a[i] > a[max])
{
max = i;
}
if (a[i] < a[min])
{
min = i;
}
}
Swap(&a[min], &a[left]);
if (max == left) //可能存在max == left,此時已經被換走了,所以要找當前的位置,即min
{
max = min;
}
Swap(&a[max], &a[right]);
left++;
right--;
}
}
4. 選擇排序—堆排序(Heap Sort)
基本思想
堆排序是一種樹形選擇排序,是對直接選擇排序的有效改進,利用堆這種資料結構所設計的一種排序演算法,堆積是一個近似完全二叉樹的結構,并同時滿足堆積的性質:即子結點的鍵值或索引總是小于(或者大于)它的父節點,需要注意的是排升序要建大堆,排降序建小堆,
演算法步驟:
1)創建一個堆H[0…n-1]
2)把堆首(最大值)和堆尾互換
3)把新的陣列頂端資料調整到相應位置
4) 重復步驟2,直到堆的尺寸為1
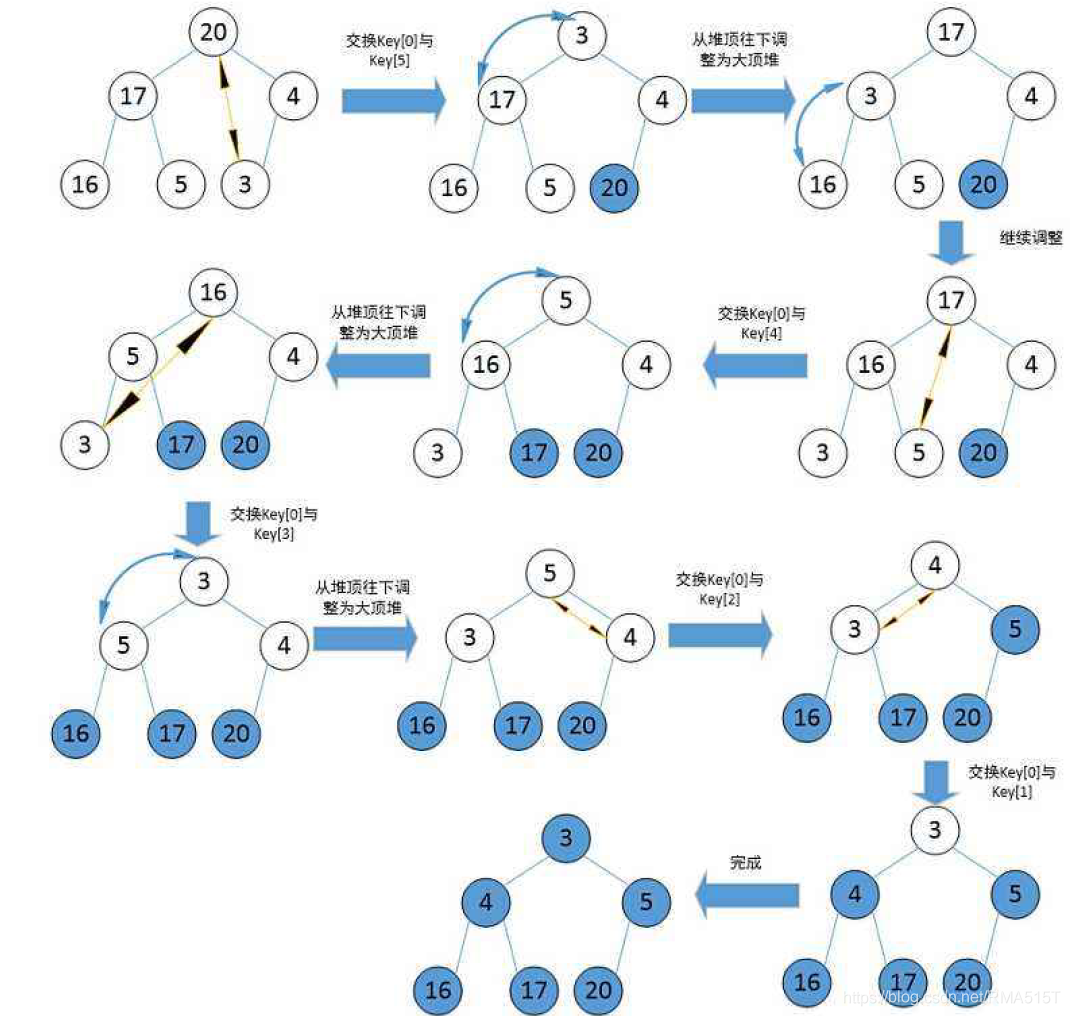
堆排序使用堆來選數,效率就高了很多,
演算法實作
/*
* 堆是陣列
n: 陣列大小
root: 根位置
*/
void AdjustDown(int* a, int n, int root) //重建大堆
{
int parent = root;
int child = 2 * parent + 1;
while (child < n) //保證合法性
{
if (child + 1 < n && a[child] < a[child + 1]) //找更大的孩子
{
child++;
}
if (a[child] > a[parent])
{
Swap(&a[child], &a[parent]); //如果孩子更大,交換
parent = child; //交換后的子樹需要重新判定
child = 2 * parent + 1;
}
else //沒有發生交換,因為兩個子樹都是有序的,所以整個樹都是有序
{
break;
}
}
}
void HeapSort(int* a, int n) // 堆排序1.建堆 2.排序
{
assert(a);
int j = (n - 2) / 2; //最小的父親,從最小的父親開始,-1就是上一個父親,從此建堆
for (; j >= 0; j--)
{
AdjustDown(a, n, j);
}
int i = n;
while (i--) //排序,0位置和最后一個位置交換
{
Swap(&a[0], &a[i]);
AdjustDown(a, i, 0); //還剩i個
}
}
5. 交換排序—冒泡排序(Bubble Sort)
基本思想
根據序列中兩個記錄鍵值的比較結果來對換這兩個記錄在序列中的位置,交換排序的特點是:將鍵值較大的記錄向序列的尾部移動,鍵值較小的記錄向序列的前部移動,**每當兩相鄰的數比較后發現它們的排序與排序要求相反時,就將它們互換,**某一趟排序程序中是否有資料交換,如果進行某一趟排序時并沒有進行資料交換,則說明資料已經按要求排列好,可立即結束排序,避免不必要的比較程序,

冒泡排序是一種非常容易理解的排序,
演算法實作
void BubbleSort(int* a, int n)
{
for (int j = n; j > 0; --j)
{
int change = 0;
for (int i = 0; i < j - 1; i++)
{
if (a[i] > a[i + 1])
{
change = 1;
Swap(&a[i], &a[i + 1]);
}
}
if (change == 0)
{
break;
}
}
}
6. 交換排序—快速排序(Quick Sort)
快速是目前基于比較的內部排序中被認為是最好的方法,當待排序的關鍵字是隨機分布時,快速排序的平均時間最短;
基本思想
快速排序是Hoare于1962年提出的一種二叉樹結構的交換排序方法,通過排序將序列分割為兩部分,左邊都是比基線條件小的數,右邊都是比它大的數;然后再按照這個方法對分割后的兩個序列排序,
將區間按斬訓準值劃分為左右兩半部分的常見方式有:
- hoare版本
- 挖坑法
- 前后指標版本
優化
- 三數取中法選key
- 遞回到小的子區間時,可以考慮使用插入排序
hoare版本
int GetMid(int* a, int left, int right) //防止有序時退化
{
int mid = (left + right) >> 1; //相當于除二
if (a[left] > a[mid])
{
if (a[mid] > a[right])
{
return mid;
}
else if (a[left] < a[right])
{
return left;
}
else
{
return right;
}
}
else
{
if (a[right] > a[mid])
{
return mid;
}
else if (a[right] < a[left])
{
return left;
}
else
{
return right;
}
}
}
// 快速排序hoare版本
int PartSort1(int* a, int left, int right)
{
int midIndex = GetMid(a, left, right);
Swap(&a[left], &a[midIndex]); //把找到的中放在最左側,不用改演算法
int keyi = left;
while (left < right)
{
while (left < right && a[right] >= a[keyi]) //做key的另一個先走,就一定是比key小的停下來
{
right--;
}
while (left < right && a[left] <= a[keyi]) //left < right &&防止越界
{
left++;
}
Swap(&a[right], &a[left]);
}
Swap(&a[keyi], &a[left]); //交換,把key放在應在的位置
return left;
}
挖坑法
// 快速排序挖坑法
int PartSort2(int* a, int left, int right)
{
int midIndex = GetMid(a, left, right);
Swap(&a[left], &a[midIndex]); //把找到的中放在最左側,不用改演算法
int key = a[left]; //存起來
while (left < right)
{
while (left < right && a[right] >= key) //做key的另一個先走,就一定是比key小的停下來
{
right--;
}
a[left] = a[right]; //把小的放在坑里,然后自己變成坑
while (left < right && a[left] <= key) //left < right &&防止越界
{
left++;
}
a[right] = a[left]; //把大的放在坑里,然后自己變成坑
}
a[left] = key;
return left;
}
前后指標版本
int PartSort3(int* a, int left, int right) //前后指標
{
int midIndex = GetMid(a, left, right);
Swap(&a[left], &a[midIndex]);
int keyi = left;
int per = left, cur = left + 1;
while (cur <= right)
{
if (a[cur] <= a[keyi] && ++per != cur)
{
Swap(&a[cur], &a[per]);
}
cur++;
}
Swap(&a[keyi], &a[per]);
return per; //回傳per,此時per才是本次排序的key
}
void QuickSort(int* a, int begin, int end )
{
if (begin >= end)
{
return;
}
if (end - begin > 20) //小區間優化,小于10時減少遞回
{
int keyi = PartSort3(a, begin, end);
QuickSort(a, begin, keyi - 1); //左右兩個子區間
QuickSort(a, keyi + 1, end);
}
else
{
InsertSort(a + begin, end - begin + 1); //注意區間
}
}
快排非遞回法
//快排非遞回
//用堆疊來保存下來要處理的區間
void QuickSortNonR(int* a, int begin, int end)
{
Stack st;
StackInit(&st);
StackPush(&st, begin); //先把初始的給進去
StackPush(&st, end);
while (StackEmpty(&st)) //不為空就繼續
{
int left, right;
right = StackTop(&st); //將資料取出
StackPop(&st);
left = StackTop(&st); //存先左后右,取時反過來
StackPop(&st);
int keyi = PartSort3(a, left, right);
if (keyi - 1 > left) //左右區間不為零
{
StackPush(&st, left); //key的左側
StackPush(&st, keyi - 1);
}
if (keyi + 1 < right)
{
StackPush(&st, keyi + 1); //key的右側
StackPush(&st, right);
}
}
}
7.歸并排序(Merge Sort)
基本思想
歸并(Merge)排序法是將兩個(或兩個以上)有序表合并成一個新的有序表,即把待排序序列分為若干個子序列,每個子序列是有序的,然后再把有序子序列合并為整體有序序列,
該演算法是采用分治法(Divide andConquer)的一個非常典型的應用,將已有序的子序列合并,得到完全有序的序列;即先使每個子序列有
序,再使子序列段間有序,若將兩個有序表合并成一個有序表,稱為二路歸并,
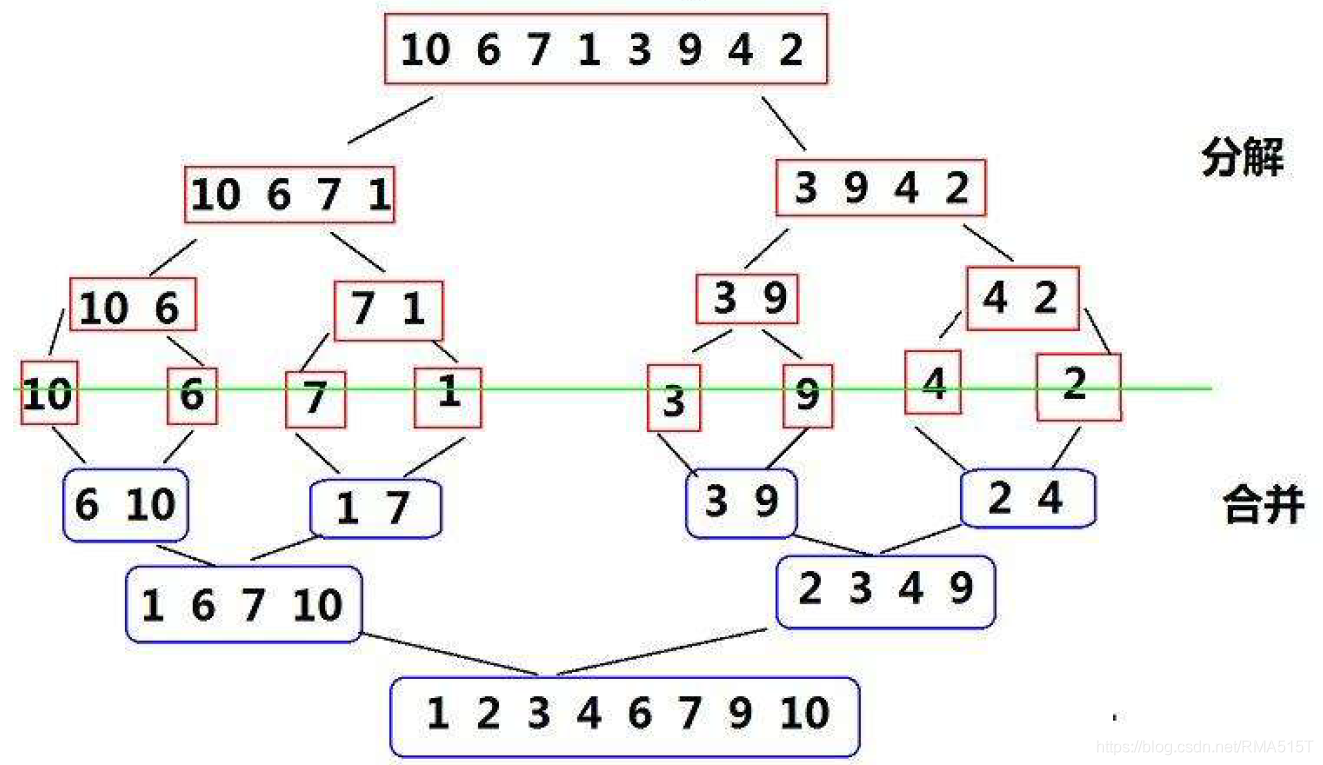
歸并的缺點在于需要O(N)的空間復雜度,歸并排序的思考更多的是解決在磁盤中的外排序問題,
演算法實作
遞回:
void _Merge(int* a, int* tmp, int begin11,int end11, int begin22, int end22) //合并兩個部分
{
int begin1 = begin11, end1 = end11;
int begin2 = begin22, end2 = end22;
int i = begin11; //tmp下表
while (begin1 <= end1 && begin2 <= end2) //有一區間走完就完了
{
if (a[begin1] > a[begin2])
tmp[i++] = a[begin2++]; //合并
else
tmp[i++] = a[begin1++];
}
while (begin1 <= end1) //把剩下的也添加到陣列
tmp[i++] = a[begin1++];
while (begin2 <= end2)
tmp[i++] = a[begin2++];
for (int j = begin11; j <= end22; j++) //拷貝回原陣列,j可以等于RIGHT
{
a[j] = tmp[j];
}
}
void _MergeSrt(int* a,int* tmp, int left, int right)
{
if (left >= right) //最小單位
return;
int mid = (left + right) >> 1; //找中間
_MergeSrt(a, tmp, left, mid); //左右半邊排序,mid本身也要處理,不能-1
_MergeSrt(a, tmp, mid + 1, right);
//歸并,兩個區間的合并
int begin1 = left, end1 = mid;
int begin2 = mid + 1, end2 = right;
_Merge(a, tmp, begin1, end1, begin2, end2);
}
// 時間復雜度:O(N*logN)
// 空間復雜度:O(N)
void MergeSrt(int* a, int n)
{
int* tmp = (int*)malloc(sizeof(int) * n);
if (tmp == NULL)
{
exit(-1);
}
_MergeSrt(a, tmp, 0, n - 1);
free(tmp);
}
非遞回
//歸并,非遞回
void MergeSrtNonR(int* a, int n)
{
int* tmp = (int*)malloc(sizeof(int) * n);
if (tmp == NULL)
{
exit(-1);
}
int gap = 1;
while (gap < n) //從1開始,到n,不斷地合并分組,進行歸并,遞回的下半部分,
{
for (int i = 0;i<n ;i += 2 * gap) //找不同的小組
{
int begin1 = i, end1 = i + gap - 1; //第一個區間,i- (i+gap-1)
int begin2 = i + gap, end2 = i + 2 * gap - 1; //第二個區間i + gap- i + 2 * gap - 1(i + gap+gap-1)
//所以第二次gap直接乘二,因為每2gap內都不需要再拍
if (begin2 >= n) //1.第一個區間就不夠了,2.第二個區間不存在 3.第二個區間不玩整 , 1和2的情況一樣,1不完整自然2就不存在,且只存在有序的1或不完整的有序1,都是不需要進行繼續排序的,
//3.的情況需要將不完整的第二區間進行歸并,
{
break; //陣列的最后,也就是這個GAP最后的一次回圈,所以直接跳出即可
}
if (end2 >= n)
{
end2 = n - 1; //修正
}
_Merge(a, tmp, begin1, end1, begin2, end2);
}
gap *= 2; //每次是之前的2倍,11一組,22一組,44一組,這樣每組內部就是排好序的
}
free(tmp);
}
8.非比較排序—計數排序
基本思想
計數排序又稱為鴿巢原理,是對哈希直接定址法的變形應用, 計數排序在資料范圍集中時,效率很高,但是適用范圍及場景有限,操作步驟:
- 統計相同元素出現次數
- 根據統計的結果將序列回收到原來的序列中
演算法實作
void CountSort(int* a, int n) //計數排序
{
int max = a[0], min = a[0]; //相對映射
int i = 0;
for (i = 0 ; i < n; i++)
{
if (max < a[i])
max = a[i];
if (min > a[i])
min = a[i];
}
int range = max - min + 1; //范圍
int* count = (int*)malloc(sizeof(int) * range);
memset(count, 0, sizeof(int) * range); //初始化
for (int k = 0; k < n; k++)
{
count[a[k] - min]++; //相對位置加1
}
i = 0;
for (int j = 0; j < range; j++)
{
while (count[j]--) //同一個位置的n次
{
a[i++] = j + min;
}
}
free(count);
}
謝謝大家
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/287426.html
標籤:其他