文章目錄
- 前言
- 擼起袖子開始看新聞(爬新聞)
- 完整代碼
- 爬取結果(看新聞嘍)
- CSDN獨家福利降臨!!!
- 最后
前言
真的好久好久沒寫爬蟲了,都快忘干凈了,簡歷上寫了熟悉爬蟲,我總不能跟面試官說我忘記了吧🤣
正好今天抽點空,寫個爬蟲來回憶回憶,
標題是真的,只不過是沒上大學之前家長說的,我記得他們說的以后出去了要學會跟人交流,不能在那大眼瞪小眼,多看看新聞,跟人家還有點話題說說…
其實長時間沒寫爬蟲不是因為不想寫,是不知道寫什么了,小伙伴們有什么建議寫的可以在評論區留下言,我有空有能力就寫寫,當然,必須是正經的網站(手動狗頭)
話不多說,開造!!!
擼起袖子開始看新聞(爬新聞)
先看網頁
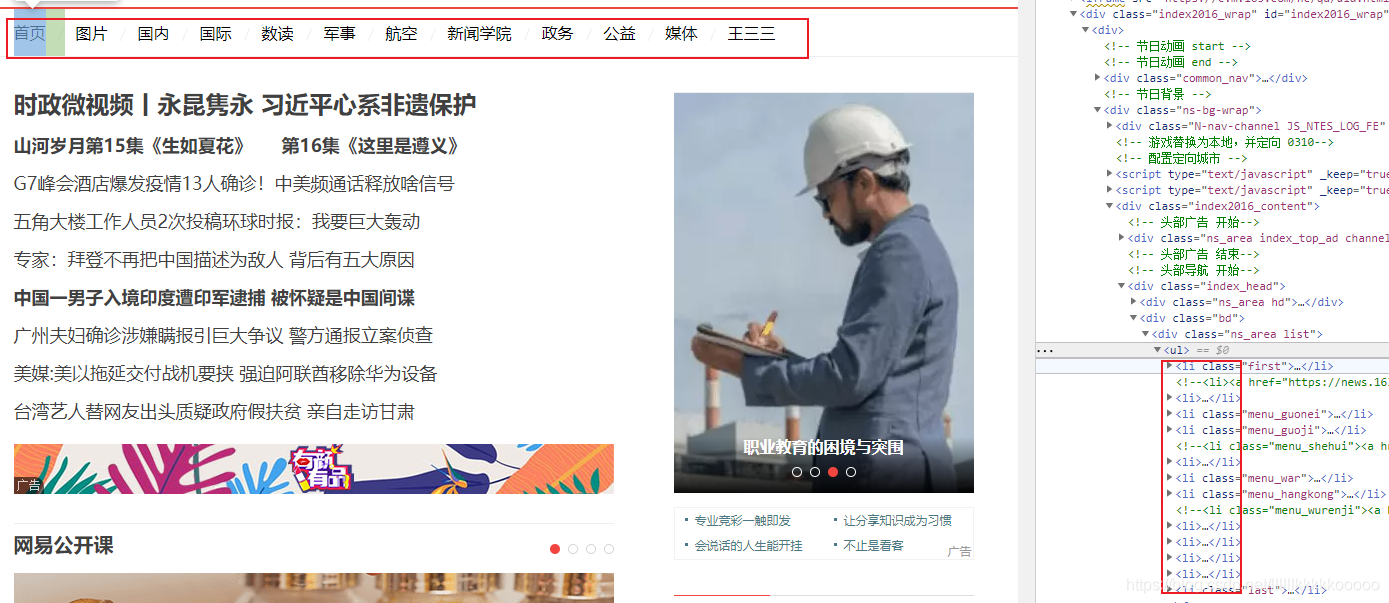
一個個模塊對應著一個 li,所以我們拿到 li 的父標簽 ul 遍歷即可獲得所有 li(模塊)
插上一句,本片文章適合有基礎的小伙伴們看,如果是剛入門的小伙伴可來我的爬蟲專欄學習,一步步成為大佬!!!
爬蟲專欄
import requests
from bs4 import BeautifulSoup
import os
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Safari/537.36 Edg/91.0.864.41"
}
url = "https://news.163.com/"
response = requests.get(url=url,headers=headers)
data = BeautifulSoup(response.text,"html.parser")
li_list = data.find(class_="ns_area list").find_all("li")
print(li_list)
這樣就拿到了標題和標題詳情頁的URL
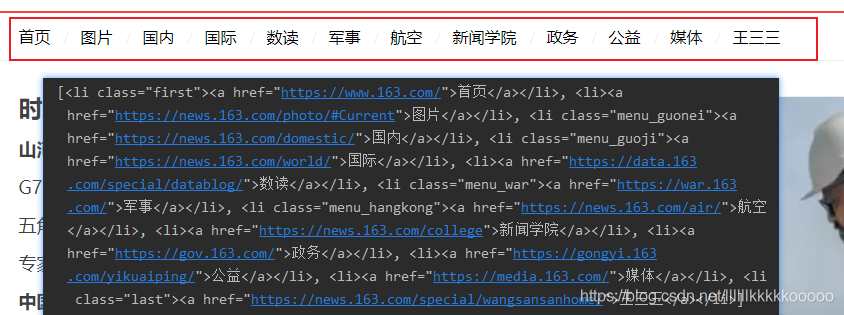
拿到這些模塊的URL,那么我們就要去獲取這些模塊詳情頁一片片文章的URL了
一篇文章對應一個div,所以我們去獲取這些文章的父標簽

根據class定位到父標簽之后,在獲取改標簽下的所有div標簽即可獲得所有文章的div標簽
而所有文章div標簽下有共同點,那就是在文章div標簽下有 <div class= new_title>標簽,在這個標簽下有a標簽存放著文章詳情頁的URL
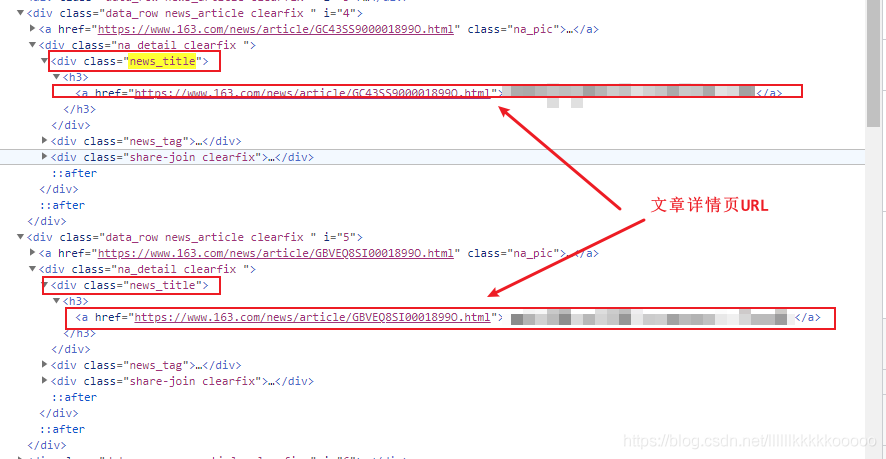
#獲取文章標簽下所有class為news_title的標簽
div_list = model_data.find(class_="ndi_main").find_all(class_="news_title")
for i in div_list:
#獲取news_title標簽下的a標簽的href屬性,即文章詳情頁URL
detail_url = i.find("a")["href"]
parse_detail(detail_url, model_path)
獲得到文章詳情頁URL后,那么就要去文章詳情頁獲取資料了
可見文章內容都在一個class值為post_body的div標簽下,而文章的內容也都是在一個個p標簽下
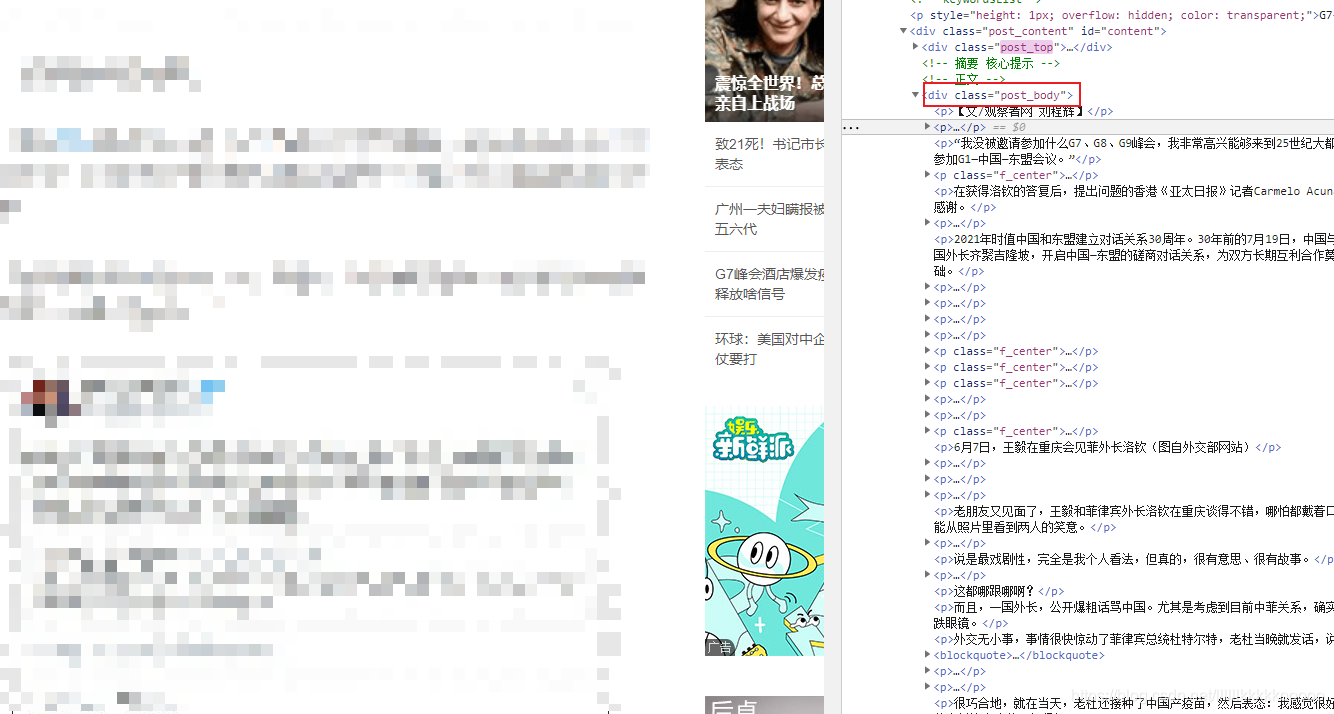
#文章標題
title = detail_data.find(class_="post_title").text
#因為要保存為txt檔案所以要把標題有些字符替換掉
title = replaceTitle(title)
#獲取所有p標簽
body = detail_data.find(class_="post_body").find_all("p")
完整代碼
from selenium import webdriver
import time
import os
import requests
from selenium.webdriver.chrome.options import Options
from selenium.webdriver import ChromeOptions
from bs4 import BeautifulSoup
path = "./網易新聞"
# 初始化
def init():
# 實作無可視化界面得操作
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
# 設定chrome_options=chrome_options即可實作無界面
driver = webdriver.Chrome(chrome_options=chrome_options)
# driver = webdriver.Chrome()
# 把瀏覽器實作全屏
# driver.maximize_window()
# 回傳driver
return driver
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Safari/537.36 Edg/91.0.864.41"
}
# 獲取模塊URL
def getUrl(driver):
url = "https://news.163.com/"
driver.get(url)
response = driver.page_source
# 目標標題索引
target_list = [2, 3, 5]
data = BeautifulSoup(response, "html.parser")
li_list = data.find(class_="ns_area list").find_all("li")
for index in target_list:
url = li_list[index].find("a")["href"]
title = li_list[index].find("a").text
# 如果模塊檔案埃及不存在就要創建
if not os.path.exists(path):
os.mkdir(path)
model_path = path + "/" + str(title)
# 如果模塊檔案不存在就要創建
if not os.path.exists(model_path):
os.mkdir(model_path)
parse_model(driver, url, model_path)
# 獲取模塊頁面URL
def parse_model(driver, url, model_path):
driver.get(url)
model_response = driver.page_source
model_data = BeautifulSoup(model_response, "html.parser")
div_list = model_data.find(class_="ndi_main").find_all("div")
for i in div_list:
if i.find("a") is not None and i.find("a").find("img") is not None:
detail_url = i.find("a")["href"]
parse_detail(detail_url, model_path)
# 爬取詳情頁
def parse_detail(detail_url, model_path):
detail_response = requests.get(url=detail_url, headers=headers).text
detail_data = BeautifulSoup(detail_response, "html.parser")
if detail_data.find(class_="post_title") is None:
return
#文章標題
title = detail_data.find(class_="post_title").text
title = replaceTitle(title)
body = detail_data.find(class_="post_body").find_all("p")
print("正在保存:" + title)
try:
with open(model_path + "/" + title + ".txt", "w", encoding="utf-8") as f:
for i in body:
f.write(str(i.text.strip()) + "\n")
f.close()
except:
os.remove(model_path + "/" + title + ".txt")
symbol_list = ["\\", "/", "<", ":", "*", "?", "<", ">", "|","\""]
def replaceTitle(title):
for i in symbol_list:
if title.find(str(i)) != -1:
print(title)
title = title.replace(str(i),"")
return title
if __name__ == '__main__':
driver = init()
getUrl(driver)
爬取結果(看新聞嘍)



CSDN獨家福利降臨!!!
最近CSDN有個獨家出品的活動,也就是下面的《Python的全堆疊知識圖譜》,路線規劃的非常詳細,尺寸 是870mm x 560mm 小伙伴們可以按照上面的流程進行系統的學習,不要自己隨便找本書亂學,要系統的有規律的學習,它的基礎才是最扎實的,在我們這行,《基礎不牢,地動山搖》尤其明顯,
最后,如果有興趣的小伙伴們可以酌情購買,為未來鋪好道路!!!

最后
我是 CRUD大師,一個熱愛分享知識的 皮皮蝦愛好者,未來的日子里會不斷更新出對大家有益的博文,期待大家的關注!!!
創作不易,如果這篇博文對各位有幫助,希望各位小伙伴可以一鍵三連哦!,感謝支持,我們下次再見~~~
分享大綱
大廠面試題專欄
Java從入門到入墳學習路線目錄索引
開源爬蟲實體教程目錄索引
更多精彩內容分享,請點擊 Hello World (●’?’●)

轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/287778.html
標籤:其他
上一篇:被鵝廠面怕了!