| 作者:江夏
| 知乎:https://www.zhihu.com/people/1024-paper-96
| GitHub:https://github.com/JiangXia-1024?tab=repositories
| 博客地址:https://blog.csdn.net/qq_41153943
| 掘金:https://juejin.cn/post/6986279448853086216
| 公眾號:1024筆記
本文大概11088字,讀完共需25分鐘
什么是負載均衡
負載均衡(Load balance,LB),是一種計算機技術,用來在多個計算機(計算機集群)、網路連接、CPU、磁盤驅動器或其他資源中分配負載,以達到最優化資源使用、最大化吞吐率、最小化回應時間、同時避免過載的目的,
通俗點理解有點類似于常說的一句話,一碗水端平,如果我們只有一個碗,那么無論有多少水,那么我們只能裝一碗水,在單服務器的應用場景,碗就是服務器,而水就是流量,所以我們知道,一旦水(流量)過大時,一個碗肯定是不夠用的,這時候就需要多來幾個碗(服務器)來支撐更多的水(流量),但是不能讓這個碗接的水滿滿的,而有的碗沒有水,或者水少,水就是負載,而這種就是負載不均衡了,負載均衡就是為了讓所有碗里的水都盡量一樣多,不至于讓有的服務器壓力大,而有的服務器壓力小甚至用不上,
那么我們知道盡管有很多的碗,能夠裝得下足夠多的水,但是這么多碗,哪個先用,哪個后用呢?這時候我們可以想象以前讀書的時候的洗衣池,一個池子上面有n個水龍頭,這時候每個水龍頭下都放這一個碗,這樣就能夠保證這些碗基本是同時被使用到的,而這種就是分布式服務器集群的基本概念了,
那么這些碗如何能夠達到負載均衡呢?因為會有有得水龍頭流量大,有得水龍頭流量小的情況,這樣的話流量大的地方的碗的負載壓力就大,那么這時候,如果我們把所有的碗都打通,然后再用一個水管把他們連起來,這樣是不是就能夠基本保證,所有的碗的水都一樣多了?因為水多的碗里面的水也很流到水少的碗里,這樣就能夠達到負載均衡的目的了,這里面用來連接碗之間的水管就是連通器的概念,但是連通器其實只是用于解決服務器之間的通信問題,其并不是減輕服務器性能的演算法,負載均衡就是通過分流演算法,合理的分攤服務器壓力,達到服務器性能的最大優化,但是這里也不能簡單地理解為分配給所有實際服務器一樣多的作業量,因為不同的服務器在硬體配置、網路帶寬的不同,導致它們具體的承載能力也不相同,這里的“均衡”,其實就是盡可能地使得所有的服務器都不要過載,并且能夠最大程式地發揮作用,
總結:負載均衡(Load Balance),就是是將負載(作業任務,訪問請求)進行平衡、分攤到多個操作單元(服務器,組件)上進行執行,用來解決高性能,單點故障(高可用),擴展性(水平伸縮)的場景需求!
幾種常見的負載均衡方案
1、HTTP重定向
當我們向web服務器發送一個請求后,web服務器可以通過http回應頭資訊中的Location標記來回傳一個新的URL,然后瀏覽器需要繼續請求這個新的URL,完成自動跳轉,
HTTP重定向協議實作負載均衡大概作業原理如下圖:
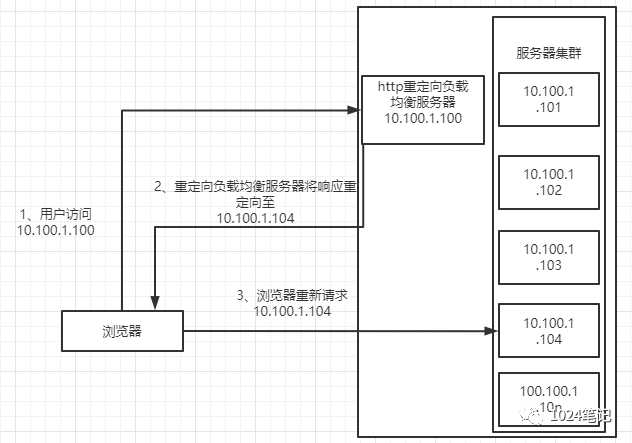
HTTP重定向服務器是一臺普通的應用服務器,其唯一個功能就是根據用戶的HTTP請求計算出一臺真實的服務器地址,并將該服務器地址寫入HTTP重定向回應中(重定向回應狀態碼為302)回傳給用戶瀏覽器,用戶瀏覽器在獲取到回應之后,根據回傳的資訊,重新發送一個請求到真實的服務器上,如上圖所示,當用戶請求訪問某個網址,通過DNS服務器決議到IP地址為10.100.1.100,即HTTP重定向服務器的IP地址,然后重定向服務器根據負載均衡演算法算出真實的服務器地址為10.100.1.104并回傳給用戶瀏覽器,用戶瀏覽器得到回傳后重新對10.100.1.104發起了請求,完成自動跳轉,
這種 HTTP重定向負載均衡方案的優點是比較簡單,但是也存在一些缺點:
1、性能較差
瀏覽器需要請求兩次才能完成一次訪問,同時,重定向服務器本身的處理能力有可能成為瓶頸,整個集群的伸縮性規模有限;使用HTTP回傳碼302重定向,有可能使搜索引擎判斷為SEO作弊,降低搜索排名,
2、吞吐率限制
主站點服務器的吞吐率平均分配到了被轉移的服務器,現假設使用RR(Round Robin)調度策略,子服務器的最大吞吐率為1000reqs/s,那么主服務器的吞吐率要達到3000reqs/s才能完全發揮三臺子服務器的作用,那么如果有100臺子服務器,那么主服務器的吞吐率可想而知得有大?相反,如果主服務的最大吞吐率為6000reqs/s,那么平均分配到子服務器的吞吐率為2000reqs/s,而現子服務器的最大吞吐率為1000reqs/s,因此就得增加子服務器的數量,增加到6個才能滿足,
3、重定向訪問深度不同
有的重定向一個靜態頁面,有的重定向相比復雜的動態頁面,那么實際服務器的負載差異是不可預料的,而主站服務器卻一無所知,因此整站使用重定向方法做負載均衡不太好,
需要權衡轉移請求的開銷和處理實際請求的開銷,前者相對于后者越小,那么重定向的意義就越大,例如下載,你可以去很多鏡像下載網站試下,會發現基本下載都使用了Location做了重定向,
因此在實際應用中很少使用這種負載均衡方案來部署,
2、DNS負載均衡
DNS(Domain Name System)是因特網的一項服務,它作為域名和IP地址相互映射的一個分布式資料庫,能夠使人更方便的訪問互聯網,DNS負責提供域名決議服務,當訪問某個站點時,實際上首先需要通過該站點域名的DNS服務器來獲取域名指向的IP地址,在這一程序中,DNS服務器完成了域名到IP地址的映射,同樣,這樣映射也可以是一對多的,這時候,DNS服務器便充當了負載均衡調度器,它就像http重定向轉換策略一樣,將用戶的請求分散到多臺服務器上,但是它的實作機制完全不同,
利用DNS作業原理處理負載均衡的作業原理圖大致如下:
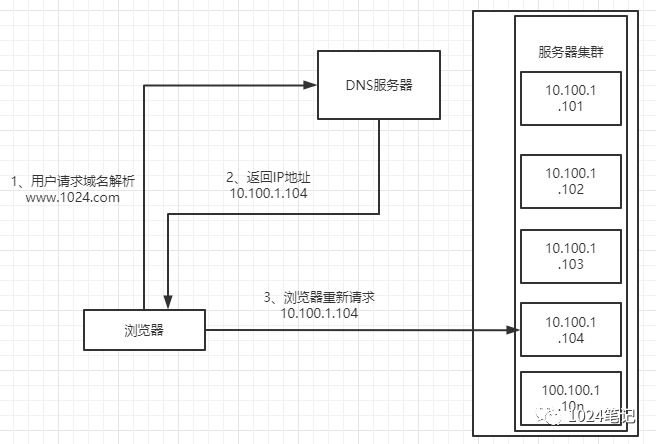
在DNS系統中有一個比較重要的的資源型別叫做主機記錄也稱為A記錄,A記錄是用于名稱決議的重要記錄,它將特定的主機名映射到對應主機的IP地址上,如果你有一個自己的域名,那么要想別人能訪問到你的網站,你需要到特定的DNS決議服務商的服務器上填寫A記錄,過一段時間后,別人就能通過你的域名訪問你的網站了,
通過上面的原理圖可以看出,在DNS服務器中應該配置了多個A記錄,如:
www.1024.com IN A 10.100.1.101;
www.1024.com IN A 10.100.1.102;
www.1024.com IN A 10.100.1.103;
www.1024.com IN A 10.100.1.104;
因此,每次域名決議請求都會根據對應的負載均衡演算法計算出一個不同的IP地址并回傳,這樣A記錄中配置多個服務器就可以構成一個集群,并可以實作負載均衡,上圖中,用戶請求www.1024.com,DNS根據A記錄和負載均衡演算法計算得到一個IP地址10.100.1.104,并回傳給瀏覽器,瀏覽器根據該IP地址,訪問真實的物理服務器10.100.1.104,所有這些操作對用戶來說都是透明的,用戶可能只知道www.1024.com這個域名,
基于DNS負載均衡和http重定向的負載均衡相比,它完全節省了所謂的主站點,也可以說DNS服務器充當了主站點,但不同的是,作為調度器,DNS服務器本身的性能是足夠的,因為DNS記錄可以被用戶瀏覽器或者互聯網接入服務商的各級DNS服務器快取,只有當快取過期后才會重新向域名的DNS服務器請求決議,也就是說DNS不存在上面說到的http重定向的吞吐率限制,在理論上是可以無限增加實際服務器的數量,
DNS域名決議負載均衡具有以下的一些優點:
1、將負載均衡的作業交給DNS,省去了網站管理維護負載均衡服務器的麻煩,
2、技術實作比較靈活、方便,簡單易行,成本低,使用于大多數TCP/IP應用,
3、對于部署在服務器上的應用來說不需要進行任何的代碼修改即可實作不同機器上的應用訪問,
4、服務器可以位于互聯網的任意位置,
5、同時許多DNS還支持基于地理位置的域名決議,即會將域名決議成距離用戶地理最近的一個服務器地址,這樣就可以加速用戶訪問,改善性能,
但是它也有一定的缺點,比如:
1、動態DNS:在每次IP地址變更時,需要及時更新DNS服務器,但是因為快取,所以存在一定的延遲,
2、策略的局限性,如果無法將HTTP請求的背景關系引入到調度策略中,而在前面介紹的基于HTTP重定向的負載均衡系統中,調度器作業在HTTP層面,它可以充分理解HTTP請求后根據站點的應用邏輯來設計調度策略,比如根據請求不同的URL來進行合理的過濾和轉移,
3、如果要根據實際服務器的實時負載差異來調整調度策略,這需要DNS服務器在每次決議操作時分析各服務器的健康狀態,對于DNS服務器來說,這種自定義開發存在較高的門檻,更何況大多數站點只是使用第三方DNS服務,
4、DNS記錄快取,各級節點的DNS服務器不同程式的快取會讓人很難弄清楚,
5、沒有用戶能直接看到DNS決議到了哪一臺實際服務器,給服務器運維人員的除錯帶來了不便,
6、不能夠按服務器的處理能力來分配負載,DNS負載均衡采用的是簡單的輪詢演算法,不能區分服務器之間的差異,不能反映服務器當前運行狀態,所以其的負載均衡效果并不是太好,
其實大型網站總是部分使用DNS域名決議,將其作為第一級負載均衡手段,即通過域名決議得到的一組服務器并不是實際提供服務的物理服務器,而是同樣提供負載均衡服務器的內部服務器,這組內部負載均衡服務器再進行負載均衡,請請求發到真實的服務器上,最終完成請求,
基于以上幾點,DNS服務器并不能很好地完成作業量均衡分配,所以是否選擇基于DNS的負載均衡方式取決于實際場景和業務的需要,
三、反向代理負載均衡
反向代理(Reverse Proxy)應該是平常聽到最多的了,因為幾乎所有主流的Web服務器都熱衷于支持基于反向代理的負載均衡,它的核心作業就是轉發HTTP請求,
有反向代理肯定就有正向代理,在說反向代理之前先來說說正向代理,
這里的代理可以理解為就是一個代表、一個渠道,正向代理是針對客戶端而言的,客戶端想訪問一個網站,但上不了網,可是客戶端卻能訪問一個叫做代理服務器的東西,代理服務器可以幫助客戶端上網,客戶端先將請求發給代理服務器,代理服務器再將請求轉發給網站,網站的回應結果先發給代理服務器,然后再由代理服務器轉發給客戶端,
可以理解正向代理就是指代理服務器幫助客戶端上網,
隨著網站業務不斷發展,用戶規模越來越大,由于復雜的網路環境,不同地區的用戶訪問網站時,速度差別也極大,有研究表明,網站訪問延遲和用戶流失率正相關,網站訪問越慢,用戶越容易失去耐心而離開,為了提供更好的用戶體驗,留住用戶,網站需要加速網站訪問速度,其中一個方法就是加反向代理服務器,
傳統代理服務器位于瀏覽器一側,代理瀏覽器將HTTP請求發送到互聯網上,而反向代理服務器位于網站機房一側,代理網站Web服務器接收HTTP請求,和傳統代理服務器可以保護瀏覽器安全一樣,反向代理服務器也具有保護網站安全的作用,來自互聯網的訪問請求必須經過代理服務器,相當于在Web服務器和可能的網路攻擊之間建立了一個屏障,
除了安全功能,代理服務器也可以通過配置快取功能加速Web請求,當用戶第一次訪問靜態內容的時候,靜態內容就被快取在反向代理服務器上,這樣當其他用戶訪問該靜態內容的時候,就可以直接從反向代理服務器回傳,加速Web請求回應速度,減輕Web服務器負載壓力,
事實上,有些網站會把動態內容也快取在代理服務器上,比如維基百科及某些博客論壇網站,把熱門詞條、帖子、博客快取在代理服務器上加速用戶訪問速度,當這些動態內容有變化時,通過內部通知機制通知反向代理快取失效,反向代理會重新加載最新的動態內容再次快取起來,
此外,反向代理也可以實作負載均衡的功能,而通過負載均衡構建的應用集群可以提高系統總體處理能力,進而改善網站高并發情況下的性能,
相比前面的HTTP重定向和DNS決議,反向代理的調度器扮演的是用戶和實際服務器中間人的角色:反向代理方式是指以代理服務器來接受internet上的連接請求,然后將請求轉發給內部網路上的服務器,并將從服務器上得到的結果回傳給internet上請求連接的客戶端,此時代理服務器對外就表現為一個反向代理服務器,
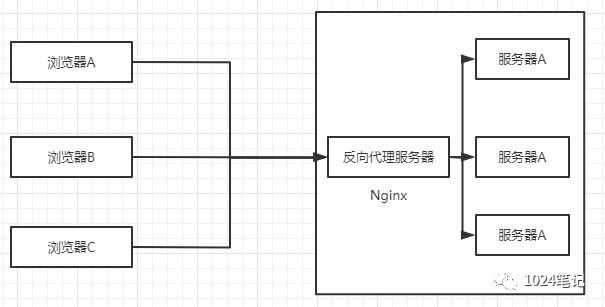
1、任何對于實際服務器的HTTP請求都必須經過調度器
2、調度器必須等待實際服務器的HTTP回應,并將它反饋給用戶(前兩種方式不需要經過調度反饋,是實際服務器直接發送給用戶)
特性:
1、調度策略豐富,例如可以為不同的實際服務器設定不同的權重,以達到能者多勞的效果,
2、對反向代理服務器的并發處理能力要求高,因為它作業在HTTP層面,
3、反向代理服務器進行轉發操作本身是需要一定開銷的,比如創建執行緒、與后端服務器建立TCP連接、接收后端服務器回傳的處理結果、分析HTTP頭部資訊、用戶空間和內核空間的頻繁切換等,雖然這部分時間并不長,但是當后端服務器處理請求的時間非常短時,轉發的開銷就顯得尤為突出,例如請求靜態檔案,更適合使用前面介紹的基于DNS的負載均衡方式,
4、反向代理服務器可以監控后端服務器,比如系統負載、回應時間、是否可用、TCP連接數、流量等,從而根據這些資料調整負載均衡的策略,
5、反射代理服務器可以讓用戶在一次會話周期內的所有請求始終轉發到一臺特定的后端服務器(粘滯會話),這樣的好處一是保持session的本地訪問,二是防止后端服務器的動態記憶體快取的資源浪費,
Nginx (engine x) 是一個高性能的HTTP和反向代理web服務器,
官方網站下載地址:
https://nginx.org/en/download.html
選擇合適版本下載
下載后解壓,雙擊nginx.exe檔案即可啟動nginx,
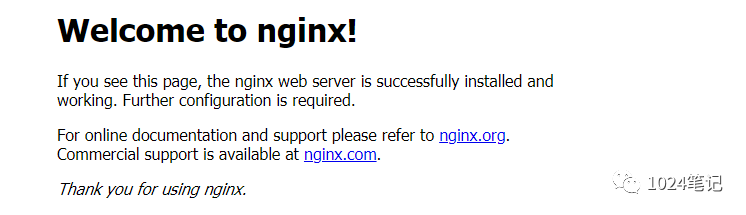
啟動后瀏覽器輸入:
http://localhost
出現以下頁面,則nginx啟動成功
或者進入nginx解壓的目錄,輸入命令列:nginx也可以啟動nginx,
停止nginx有兩種方式:
命令列進入nginx根目錄,執行如下命令,停止服務器:
# 強制停止nginx服務器,如果有未處理的資料,丟棄
E:\nginx\nginx-1.20.1>nginx -s stop
#如果有未處理的資料,等待處理完成之后停止
E:\nginx\nginx-1.20.1>nginx -s quit
nginx服務器的配置資訊主要集中在nginx.conf這個組態檔中,
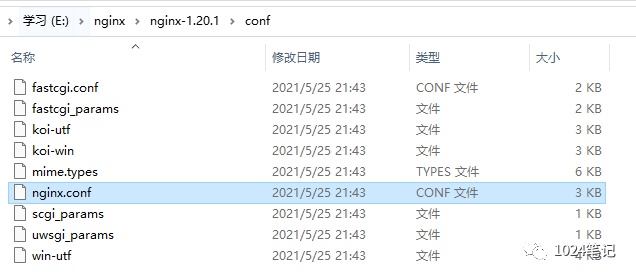
該檔案主要由6個部分組成:
main:用于進行nginx全域資訊的配置
events:用于nginx作業模式的配置
http:用于進行http協議資訊的一些配置
server:用于進行服務器訪問資訊的配置
location:用于進行訪問路由的配置
upstream:用于進行負載均衡的配置
篇幅有限,其具體的使用以及配置,這里暫時先不說明,
LVS-Linux Virtual Server
還有三種負載均衡,在介紹這三種負載均衡之前先聊一下**LVS,**因為這三種負載均衡模式都是和LVS有關,
LVS(Linux Virtual Server),即Linux虛擬服務器,它是由章文嵩博士主導的開源負載均衡專案,目前LVS已經被集成到Linux內核模塊中,
從Linux2.4內核開始,其內置的Netfilter模塊在內核中維護著一些資料包過濾表,這些表包含了用于控制資料包過濾的規則,可喜的是,Linux提供了iptables來對過濾表進行插入、修改和洗掉等操作,更加令人振奮的是,Linux2.6.x內核中內置了IPVS模塊,它的作業性質型別于Netfilter模塊,不過它更專注于實作IP負載均衡,IPVS的管理工具是ipvsadm,它為提供了基于命令列的配置界面,可以通過它快速實作負載均衡系統,這就是LVS,
該專案在Linux內核中實作了基于IP的資料請求負載均衡調度方案,其體系結構如下圖所示:
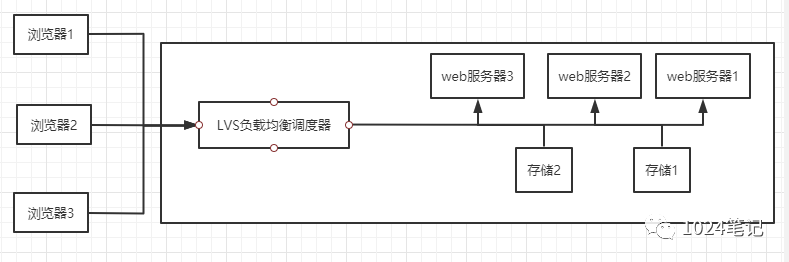
通過上圖可以發現終端互聯網用戶從外部訪問公司的外部負載均衡服務器,終端用戶的請求會發送給LVS調度器,調度器根據自己預設的演算法決定將該請求發送給后端的某臺Web服務器,比如,輪詢演算法可以將外部的請求平均分發給后端的所有服務器,終端用戶訪問LVS調度器雖然會被轉發到后端真實的服務器,但如果真實服務器連接的是相同的存盤,提供的服務也是相同的服務,最終用戶不管是訪問哪臺真實服務器,得到的服務內容都是一樣的,整個集群對用戶而言都是透明的,最后根據LVS作業模式的不同,真實服務器會選擇不同的方式將用戶需要的資料發送到終端用戶,LVS根據作業模式的不同可以分為LVS-NAT模式(IP負載均衡)、LVS-TUN模式(IP隧道)、以及LVS-DR模式(直接路由),
四、IP負載均衡(LVS-NAT)
NAT(Network Address Translation)即網路地址轉換,其作用是通過資料報頭的修改,使得位于企業內部的私有IP地址可以訪問外網,以及外部用用戶可以訪問位于公司內部的私有IP主機,
因為反向代理服務器作業在HTTP層,其本身的開銷就已經嚴重制約了可擴展性,從而也限制了它的性能極限,而NAT服務器:它作業在傳輸層,它可以修改發送來的IP資料包,將資料包的目標地址修改為實際服務器地址,其原理如下圖:
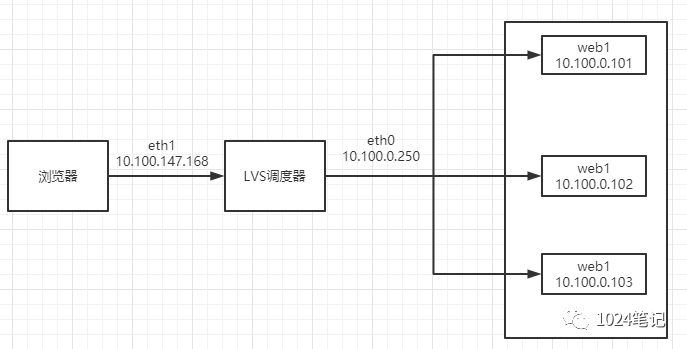
由上圖可知LVS負載調度器可以使用兩塊網卡配置不同的IP地址,eth0設定為私鑰IP與內部網路通過交換設備相互連接,eth1設備為外網IP與外部網路聯通,
用戶通過互聯網DNS服務器決議到公司負載均衡設備上面的外網地址,相對于真實服務器而言,LVS外網IP又稱VIP(Virtual IP Address),用戶通過訪問VIP,即可連接后端的真實服務器(Real Server),而這一切對用戶而言都是透明的,用戶以為自己訪問的就是真實服務器,但他并不知道自己訪問的VIP僅僅是一個調度器,也不清楚后端的真實服務器到底在哪里、有多少真實服務器,
用戶將請求發送至10.100.147.168,此時LVS將根據預設的演算法選擇后端的一臺真實服務器(10.100.0.101~10.100.0.103),將資料請求包轉發給真實服務器,并且在轉發之前LVS會修改資料包中的目標地址以及目標埠,目標地址與目標埠將被修改為選出的真實服務器IP地址以及相應的埠,
最后真實的服務器將回應資料包回傳給LVS調度器,調度器在得到回應的資料包后會將源地址和源埠修改為VIP及調度器相應的埠,修改完成后,由調度器將回應資料包發送回終端用戶,另外,由于LVS調度器有一個連接Hash表,該表中會記錄連接請求及轉發資訊,當同一個連接的下一個資料包發送給調度器時,從該Hash表中可以直接找到之前的連接記錄,并根據記錄資訊選出相同的真實服務器及埠資訊,
具體使用:
1、打開調度器的資料包轉發選項
echo 1 > /proc/sys/net/ipv4/ip_forward
2、檢查實際服務器是否已經將NAT服務器作為自己的默認網關,如果不是,如添加
route add default gw xx.xx.xx.xx
3、使用ipvsadm配置
ipvsadm -A -t 111.11.11.11:80 -s rr
添加一臺虛擬服務器,-t 后面是服務器的外網ip和埠,-s rr是指采用簡單輪詢的RR調度策略(這屬于靜態調度策略,除此之外,LVS還提供了系列的動態調度策略,比如最小連接(LC)、帶權重的最小連接(WLC),最短期望時間延遲(SED)等,關于LVS的調度演算法最后會具體介紹)
ipvsadm -a -t 111.11.11.11:80 -r 10.10.120.210:8000 -m
ipvsadm -a -t 111.11.11.11:80 -r 10.10.120.211:8000 -m
添加兩臺實際服務器(不需要有外網ip),-r后面是實際服務器的內網ip和埠,-m表示采用NAT方式來轉發資料包
運行
ipvsadm -L -n
可以查看實際服務器的狀態,這樣就大功告成了,
實驗證明使用基于NAT的負載均衡方案,作為調度器的NAT服務器可以將吞吐率提升到一個新的高度,幾乎是反向代理服務器的兩倍以上,這大多歸功于在內核中進行請求轉發的較低開銷,但是一旦請求的內容過大時,不論是基于反向代理還是NAT,負載均衡的整體吞吐量都差距不大,這說明對于一些開銷較大的內容,使用簡單的反向代理來搭建負載均衡系統是值考慮的,
這么強大的系統還是有它的瓶頸,那就是NAT服務器的網路帶寬,包括內部網路和外部網路,當然如果你不差錢,可以去花錢去購買千兆交換機或萬兆交換機,甚至負載均衡硬體設備,但是該方案花銷較大,除此之外還有一個簡單有效的辦法就是將基于NAT的集群和前面的DNS混合使用,比如5個100Mbps出口寬帶的集群,然后通過DNS來將用戶請求均衡地指向這些集群,同時,你還可以利用DNS智能決議實作地域就近訪問,這樣的配置對于大多數業務是足夠了,但是對于提供下載或視頻等服務的大規模站點,NAT服務器還是不夠出色,
五、直接路由(LVS-DR)
上面介紹的NAT是作業在網路分層模型的傳輸層(第四層),而直接路由是作業在資料鏈路層(第二層),它通過修改資料包的目標MAC地址(沒有修改目標IP),將資料包轉發到實際服務器上,不同的是,實際服務器的回應資料包將直接發送給客戶端,而不經過調度器,
在LVS(TUN)模式下,由于需要在LVS調度器與真實服務器之間創建隧道連接,這同樣會增加服務器的負擔,在直接路由模式中LVS依然僅承擔資料的入站請求以及根據演算法選出合理的真實服務器,最終由后端真實服務器負責將回應資料包發送回傳給客戶端,與隧道模式不同的是,直接路由模式要求調度器與后端服務器必須在同一個局域網內,VIP地址需要在調度器與后端所有的服務器間共享,因為最終的真實服務器給客戶端回應資料包時需要設定源IP為VIP地址,目標IP為客戶端IP,這樣客戶端訪問的是調度器的VIP地址,回應的源地址也依然是該VIP地址(真實服務器上的VIP),客戶端是感覺不到后端服務器存在的,由于多臺計算機都設定了同樣一個VIP地址,所以在直接路由模式中要求調度器的VIP地址是對外可見的,客戶端需要將請求資料包發送到調度器主機,而所有的真實服務器的VIP地址必須配置在Non-ARP的網路設備上,也就是該網路設備并不會向外廣播自己的MAC及對應的IP地址,真實服務器的VIP對外界是不可見的,但真實服務器卻可以接受目標地址VIP的網路請求,并在回應資料包時將源地址設定為該VIP地址,調度器根據演算法在選出真實服務器后,在不修改資料報文的情況下,將資料幀的MAC地址修改為選出的真實服務器的MAC地址,通過交換機將該資料幀發給真實服務器,整個程序中,真實服務器的VIP不需要對外界可見,
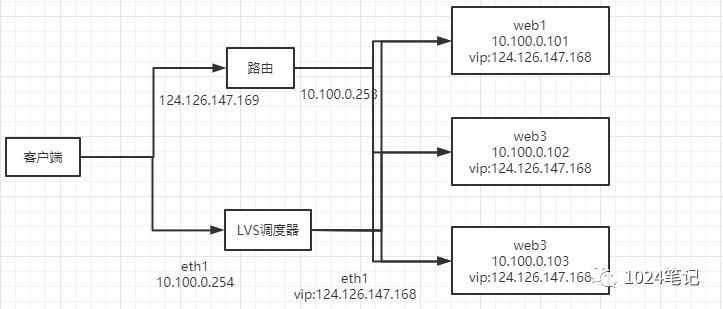
1、網路設定
假設由一臺負載均衡調度器,兩臺實際服務器,購買三個外網ip,一臺機一個,三臺機的默認網關需要相同,最后再設定同樣的ip別名,這里假設別名為10.10.120.193,這樣一來,將通過10.10.120.193這個IP別名來訪問調度器,你可以將站點的域名指向這個IP別名,
2、將ip別名添加到回環介面上
這是為了讓實際服務器不要去尋找其他擁有這個IP別名的服務器,在實際服務器中運行:
另外還要防止實際服務器回應來自網路中針對IP別名的ARP廣播,為此還要執行:
echo "1" > /proc/sys/net/ipv4/conf/lo/arp_ignore
echo "2" > /proc/sys/net/ipv4/conf/lo/arp_announce
echo "1" > /proc/sys/net/ipv4/conf/all/arp_ignore
echo "1" > /proc/sys/net/ipv4/conf/all/arp_announce
配置完了就可以使用ipvsadm配置LVS-DR集群了
ipvsadm -A -t 10.10.120.193:80 -s rr
ipvsadm -a -t 10.10.120.193:80 -r 10.10.120.210:8000 -g
ipvsadm -a -t 10.10.120.193:80 -r 10.10.120.211:8000 -g
-g 就意味著使用直接路由的方式轉發資料包
LVS-DR 相較于LVS-NAT的最大優勢在于LVS-DR不受調度器寬帶的限制,例如假設三臺服務器在WAN交換機出口寬帶都限制為10Mbps,只要對于連接調度器和兩臺實際服務器的LAN交換機沒有限速,那么,使用LVS-DR理論上可以達到20Mbps的最大出口寬帶,因為它的實際服務器的回應資料包可以不經過調度器而直接發往用戶端啊,所以它與調度器的出口寬帶沒有關系,只能自身的有關系,而如果使用LVS-NAT,集群只能最大使用10Mbps的寬帶,所以,越是回應資料包遠遠超過請求資料包的服務,就越應該降低調度器轉移請求的開銷,也就越能提高整體的擴展能力,最終也就越依賴于WAN出口寬帶,
總的來說,LVS-DR適合搭建可擴展的負載均衡系統,不論是Web服務器還是檔案服務器,以及視頻服務器,它都擁有出色的性能,前提是你必須為服務器購買一系列的合法IP地址,
六、IP隧道(LVS-TUN)
在LVS(NAT)模式的集群環境中,由于所有的資料請求及回應的資料包都需要經過LVS調度器轉發,如果后端服務器的數量大于10臺,則調度器就會成為整個集群環境的瓶頸,因為回應資料包中包含有客戶需要的具體資料,所以資料請求包往往遠小于回應資料包的大小所以LVS-TUN模式就是將請求與回應資料分離,讓調度器僅處理資料請求,而讓真實服務器回應資料包直接回傳給客戶端,
基于IP隧道的請求轉發機制:將調度器收到的IP資料包封裝在一個新的IP資料包中,轉交給實際服務器,然后實際服務器的回應資料包可以直接到達用戶端,目前Linux大多支持,可以用LVS來實作,稱為LVS-TUN,與LVS-DR不同的是,實際服務器可以和調度器不在同一個WANt網段,調度器通過IP隧道技術來轉發請求到實際服務器,所以實際服務器也必須擁有合法的IP地址,
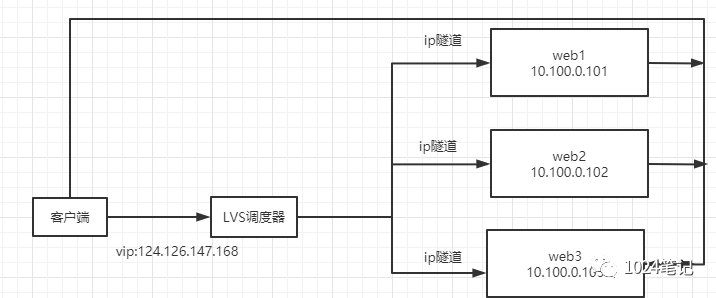
總體來說,LVS-DR和LVS-TUN都適合回應和請求不對稱的Web服務器,如何從它們中做出選擇,取決于你的網路部署需要,因為LVS-TUN可以將實際服務器根據需要部署在不同的地域,并且根據就近訪問的原則來轉移請求,所以有類似這種需求的,就應該選擇LVS-TUN,
LVS負載均衡調度演算法
不管實際應用中采用的是上面三種模式的哪種模式,調度演算法進行調度的策略與演算法都是LVS的核心技術,LVS在內核中主要實作了以下十種調度演算法,
1.輪詢調度
輪詢調度(Round Robin 簡稱’RR’)演算法就是按依次回圈的方式將請求調度到不同的服務器上,該演算法最大的特點就是實作簡單,輪詢演算法假設所有的服務器處理請求的能力都一樣的,調度器會將所有的請求平均分配給每個真實服務器,
2.加權輪詢調度
加權輪詢(Weight Round Robin 簡稱’WRR’)演算法主要是對輪詢演算法的一種優化與補充,LVS會考慮每臺服務器的性能,并給每臺服務器添加一個權值,如果服務器A的權值為1,服務器B的權值為2,則調度器調度到服務器B的請求會是服務器A的兩倍,權值越高的服務器,處理的請求越多,
3.最小連接調度
最小連接調度(Least Connections 簡稱’LC’)演算法是把新的連接請求分配到當前連接數最小的服務器,最小連接調度是一種動態的調度演算法,它通過服務器當前活躍的連接數來估計服務器的情況,調度器需要記錄各個服務器已建立連接的數目,當一個請求被調度到某臺服務器,其連接數加1;當連接中斷或者超時,其連接數減1,
(集群系統的真實服務器具有相近的系統性能,采用最小連接調度演算法可以比較好地均衡負載,)
4.加權最小連接調度
加權最少連接(Weight Least Connections 簡稱’WLC’)演算法是最小連接調度的超集,各個服務器相應的權值表示其處理性能,服務器的預設權值為1,系統管理員可以動態地設定服務器的權值,加權最小連接調度在調度新連接時盡可能使服務器的已建立連接數和其權值成比例,調度器可以自動問詢真實服務器的負載情況,并動態地調整其權值,
5.基于區域的最少連接
基于區域的最少連接調度(Locality-Based Least Connections 簡稱’LBLC’)演算法是針對請求報文的目標IP地址的 負載均衡調度,目前主要用于Cache集群系統,因為在Cache集群客戶請求報文的目標IP地址是變化的,這里假設任何后端服務器都可以處理任一請求,演算法的設計目標是在服務器的負載基本平衡情況下,將相同目標IP地址的請求調度到同一臺服務器,來提高各臺服務器的訪問區域性和Cache命中率,從而提升整個集群系統的處理能力,LBLC調度演算法先根據請求的目標IP地址找出該目標IP地址最近使用的服務器,若該服務器是可用的且沒有超載,將請求發送到該服務器;若服務器不存在,或者該服務器超載且有服務器處于一半的作業負載,則使用’最少連接’的原則選出一個可用的服務器,將請求發送到服務器,
6.帶復制的基于區域性的最少連接
帶復制的基于區域性的最少連接(Locality-Based Least Connections with Replication 簡稱’LBLCR’)演算法也是針對目標IP地址的負載均衡,目前主要用于Cache集群系統,它與LBLC演算法不同之處是它要維護從一個目標IP地址到一組服務器的映射,而LBLC演算法維護從一個目標IP地址到一臺服務器的映射,按’最小連接’原則從該服務器組中選出一一臺服務器,若服務器沒有超載,將請求發送到該服務器;若服務器超載,則按’最小連接’原則從整個集群中選出一臺服務器,將該服務器加入到這個服務器組中,將請求發送到該服務器,同時,當該服務器組有一段時間沒有被修改,將最忙的服務器從服務器組中洗掉,以降低復制的程度,
7.目標地址散列調度
目標地址散列調度(Destination Hashing 簡稱’DH’)演算法先根據請求的目標IP地址,作為散列鍵(Hash Key)從靜態分配的散串列找出對應的服務器,若該服務器是可用的且并未超載,將請求發送到該服務器,否則回傳空,
8.源地址散列調度U
源地址散列調度(Source Hashing 簡稱’SH’)演算法先根據請求的源IP地址,作為散列鍵(Hash Key)從靜態分配的散串列找出對應的服務器,若該服務器是可用的且并未超載,將請求發送到該服務器,否則回傳空,它采用的散列函式與目標地址散列調度演算法的相同,它的演算法流程與目標地址散列調度演算法的基本相似,
9.最短的期望的延遲
最短的期望的延遲調度(Shortest Expected Delay 簡稱’SED’)演算法基于WLC演算法,舉個例子吧,ABC三臺服務器的權重分別為1、2、3 ,那么如果使用WLC演算法的話一個新請求進入時它可能會分給ABC中的任意一個,使用SED演算法后會進行一個運算
A:(1+1)/1=2 B:(1+2)/2=3/2 C:(1+3)/3=4/3 就把請求交給得出運算結果最小的服務器,
10.最少佇列調度
最少佇列調度(Never Queue 簡稱’NQ’)演算法,無需佇列,如果有realserver的連接數等于0就直接分配過去,不需要在進行SED運算,
參考文章:
https://blog.csdn.net/weixin_40470303/article/details/80541639
https://www.cnblogs.com/deepalley/p/12910129.html
https://www.cnblogs.com/bonelee/p/8890920.html
https://blog.51cto.com/u_14227204/2436891
相關推薦:
-
Spring注解(三):@scope設定組件作用域
-
Spring常用注解大全,值得你的收藏!!!
-
Spring注解(七):使用@Value對Bean進行屬性賦值
-
SpringBoot開發Restful風格的介面實作CRUD功能
-
Spring注解(六):Bean的生命周期中自定義初始化和銷毀方法的四種方式
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/289238.html
標籤:其他
下一篇:為什么使用nginx