親愛的同學們,我們的世界是3D世界,我們的雙眼能夠觀測三維資訊,幫助我們感知距離,導航避障,從而翱翔于天地之間,而當今世界是智能化的世界,我們的科學家們探索各種機器智能技術,讓機器能夠擁有人類的三維感知能力,并希望在速度和精度上超越人類,比如自動駕駛導航中的定位導航,無人機的自動避障,測量儀中的三維掃描等,都是高智機器智能技術在3D視覺上的具體實作,
立體視覺是三維重建領域的重要方向,它模擬人眼結構用雙相機模擬雙目,以透視投影、三角測量為基礎,通過邏輯復雜的同名點搜索演算法,恢復場景中的三維資訊,它的應用十分之廣泛,自動駕駛、導航避障、文物重建、人臉識別等諸多高科技應用都有它關鍵的身影,
本課程將帶大家由淺入深的了解立體視覺的理論與實踐知識,我們會從坐標系講到相機標定,從被動式立體講到主動式立體,甚至可能從深度恢復講到網格構建與處理,感興趣的同學們,來和我一起探索立體視覺的魅力吧!
本課程是電子資源,所以行文并不會有太多條條框框的約束,但會以邏輯清晰、淺顯易懂為目標,水平有限,若有不足之處,還請不吝賜教!
個人微信:EthanYs6,加我申請進技術交流群 StereoV3D,一起技術暢聊,
CSDN搜索 :Ethan Li 李迎松,查看網頁版課程,
隨課代碼,將上傳至github上,地址:StereoV3DCode:https://github.com/ethan-li-coding/StereoV3DCode
前兩篇博主介紹了兩種單相機標定方法,有同學一定會有所疑惑,本系列明明是立體視覺,為什么要介紹單相機標定而不是雙相機標定呢?原因很簡單,那就是單相機標定是雙相機標定的基礎,具體來說,雙相機標定正是先分別完成兩個單相機的標定,再進行整體標定的,且聽我娓娓道來~
文章目錄
- 雙視立體
- 雙相機標定
- 演算法部分
- 總結
- 作業
雙視立體
有一個常識性認知,即立體視覺一般而言是指雙相機組成的立體系統,就像人眼一樣,當兩個相機拍攝的視圖之間存在重疊區,它們便形成了基本的雙視立體,

雙視圖通過極線校正和立體匹配,可以通過三角關系得到三維點,

但這一切實作的前提:
- 要準確的知道雙相機之間的位置關系,即其中一個相機對于另一個相機的旋轉 R R R和平移 t t t,即相機的外引數
- 要準確的知道雙相機內部的設備引數,比如像主點 ( x 0 , y 0 ) (x_0,y_0) (x0?,y0?)、焦距 f f f、畸變引數等,即相機的內引數
關于內外引數的介紹,請看前篇:立體視覺入門指南(1):坐標系與相機引數
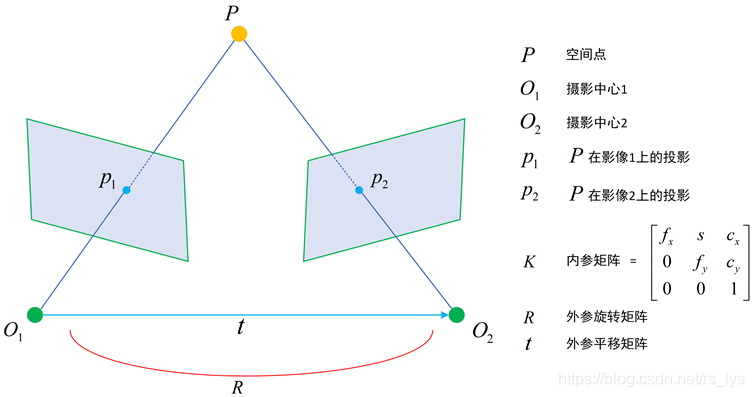
雙相機標定
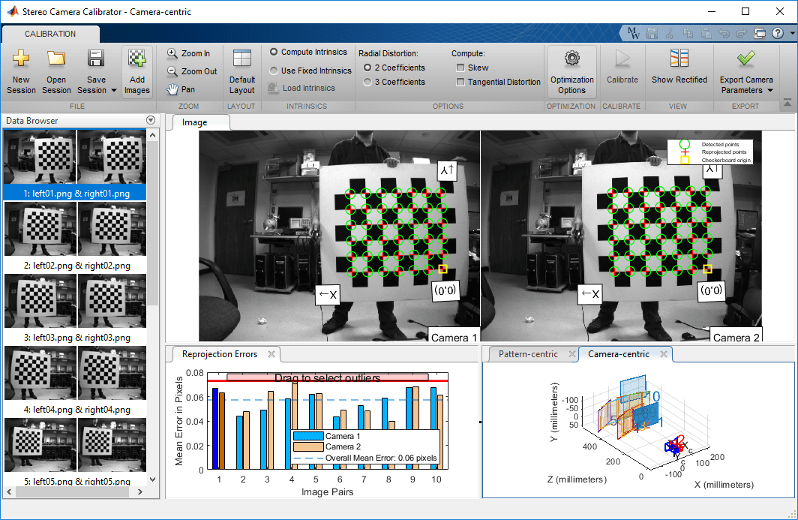
一般情況下,我們所見到的最多的雙視立體,由兩個不同的相機固定在剛性的結構上,構成穩定的雙目立體系統,在使用程序中,相機之間不會有明顯的相互移動,穩定的雙視結構可以在任意時刻完成單幀深度資訊的獲取,下圖為一些示例:

|

|

|
前面我們說到,單相機可以得到相機內參矩陣 K K K、外參矩陣 R , t R,t R,t,而雙相機標定相比單相機標定來說
- 多了一個相對外參,即右相機相對于左相機的旋轉矩陣 R R R 和平移向量 t t t,
- 少了兩個絕對外參,即單相機自身標定出來的外參矩陣不再需要了,即只保留1得到的相對外參,稱之為立體視覺系統的外參,(實際上單相機標定一般也不需要絕對外參,只是作為標定的輸出自然產出,在雙相機標定中,絕對外參可以作為中間變數計算相對外參)
我們在文章開頭說到,雙相機標定是基于單相機標定做的,我想聰明的同學已經想到了一部分思路,首先我們采用同樣的拍攝方法采集標定標定圖案,大部分操作方式和注意點都是一樣的,詳見立體視覺入門指南(3):相機標定之張式標定法【超詳細值得收藏】
不同的地方在于:
- 每一次拍攝時,要注意兩個相機的重疊區是否足夠,一般超過1/2的影像區域就可以了,當然越大越好,在一些偏的較大的角度下,可以犧牲一定的重疊度,
- 注意兩個相機盡量保持在統一的距離下采集,這樣是為了保證兩個視圖的尺度和清晰度一致,減小不一致帶來的誤差,
示意圖:
演算法部分
影像采集后,進入演算法部分,如前所述,第一步我們對兩個相機單獨做單相機標定,得到兩個相機各自的內參矩陣K、絕對外參 R , t R,t R,t(即每次采集時相機相對于標定板的外參),和畸變系數 d d d(這里的 d d d是所有畸變系數的集合)
- 對兩個相機單獨做單相機標定,得到兩個相機各自的內參矩陣K、絕對外參 R , t R,t R,t,和畸變系數 d d d
然后有的同學可能想到了,根據每次采集的絕對外參,即可以計算出相對外參,但是顯然我們會生成N個相對外參(N是采集的像對數量,也就是采集位置數),取哪一個好呢?取均值?還是取中值?
有經驗的同學會發現,這兩種都不太可靠,首先取均值就對顯著性例外值毫無魯棒性,只要某一對的絕對外參求錯了,均值就影響很大;其次取中值由于只取某一對,又沒有利用到多次測量的誤差平均特性,
所以比較可靠的做法是,計算每次采集的相對外參,并取中值作為初值,再基于最小化重投影誤差,非線性迭代優化得到最優解,在此方案下,相機的內參可以做為固定值,未知數為N組左相機的絕對外參 ( R i , t i ) , i = 1 , . . n (R_i,t_i),i=1,..n (Ri?,ti?),i=1,..n、1組右相對相對于左相機的相對外參 R ′ , t ′ R',t' R′,t′,最小重投影誤差方程和單相機標定一樣,只是右相機的絕對外參通過左相機的絕對外參和相對外參計算得到,
- 計算每次采集的相對外參,并取中值作為初值,再基于最小化重投影誤差,非線性迭代優化得到最優解
由于第二次迭代優化時,相機內參是固定的,外參位置數也減少了,所以迭代會相對更容易收斂且更精確,
總結
立體視覺通過立體匹配計算深度的前提:
- 要準確的知道相機之間的位置關系,即其中一個相機對于另一個相機的旋轉 R R R和平移 t t t,即相機的外引數
- 要準確的知道相機內部的設備引數,比如像主點 ( x 0 , y 0 ) (x_0,y_0) (x0?,y0?)、焦距 f f f、畸變引數等,即相機的內引數
雙相機標定相比單相機標定來說:
- 多了一個相對外參,即右相機相對于左相機的旋轉矩陣 R R R 和平移向量 t t t,
- 少了兩個絕對外參,即單相機自身標定出來的外參矩陣不再需要了,即只保留1得到的相對外參,稱之為立體視覺系統的外參,
雙相機影像采集的相比單相機影像采集不同的地方在于:
- 每一次拍攝時,要注意兩個相機的重疊區是否足夠,一般超過1/2的影像區域就可以了,當然越大越好,在一些偏的較大的角度下,可以犧牲一定的重疊度,
- 注意兩個相機盡量保持在統一的距離下采集,這樣是為了保證兩個視圖的尺度和清晰度一致,減小不一致帶來的誤差,
雙相機標定演算法步驟:
- 對兩個相機單獨做單相機標定,得到兩個相機各自的內參矩陣K、絕對外參 R , t R,t R,t,和畸變系數 d d d
- 計算每次采集的相對外參,并取中值作為初值,再基于最小化重投影誤差,非線性迭代優化得到最優解
所以你

作業
這里為大家準備了一些練習題,可以通過實踐加深理解:
1 通過opencv開源庫提供的介面完成雙相機標定,
2 更高階的是,你能夠自己不依賴opencv庫寫一套雙相機標定演算法嗎?或者只使用opencv來檢測角點坐標,其他步驟自己來實作,
參考答案地址:https://github.com/ethan-li-coding/StereoV3DCode [不好意思放了,代碼其實很久沒更新了,但是你相信我有一天會更的對嗎?]
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/289653.html
標籤:其他
下一篇:一個故事看懂機械硬碟原理