一. C語言概述
歡迎大家來到c語言的世界,c語言是一種強大的專業化的編程語言,
程式員必備硬核資料,點擊下載
1.1 C語言的起源
貝爾實驗室的Dennis Ritchie在1972年開發了C,當時他正與ken Thompson一起設計UNIX作業系統,然而,C并不是完全由Ritchie構想出來的,它來自Thompson的B語言,
1.2 使用C語言的理由
在過去的幾十年中,c語言已成為最流行和最重要的編程語言之一,它之所以得到發展,是因為人們嘗試使用它后都喜歡它,過去很多年中,許多人從c語言轉而使用更強大的c++語言,但c有其自身的優勢,仍然是一種重要的語言,而且它還是學習c++的必經之路,
-
高效性,c語言是一種高效的語言,c表現出通常只有匯編語言才具有的精細的控制能力(匯編語言是特定cpu設計所采用的一組內部制定的助記符,不同的cpu型別使用不同的匯編語言),如果愿意,您可以細調程式以獲得最大的速度或最大的記憶體使用率,
-
可移植性,c語言是一種可移植的語言,意味著,在一個系統上撰寫的c程式經過很少改動或不經過修改就可以在其他的系統上運行,
-
強大的功能和靈活性,c強大而又靈活,比如強大靈活的UNIX作業系統便是用c撰寫的,其他的語言(Perl、Python、BASIC、Pascal)的許多編譯器和解釋器也都是用c撰寫的,結果是當你在一臺Unix機器上使用Python時,最終由一個c程式負責生成最后的可執行程式,
1.3 C語言標準
1.3.1 K&R C
起初,C語言沒有官方標準,1978年由美國電話電報公司(AT&T)貝爾實驗室正式發表了C語言,布萊恩?柯林漢(Brian Kernighan) 和 丹尼斯?里奇(Dennis Ritchie) 出版了一本書,名叫《The C Programming Language》,這本書被 C語言開發者們稱為K&R,很多年來被當作 C語言的非正式的標準說明,人們稱這個版本的 C語言為K&R C,
K&R C主要介紹了以下特色:結構體(struct)型別;長整數(long int)型別;無符號整數(unsigned int)型別;把運算子=+和=-改為+=和-=,因為=+和=-會使得編譯器不知道使用者要處理i = -10還是i =- 10,使得處理上產生混淆,
即使在后來ANSI C標準被提出的許多年后,K&R C仍然是許多編譯器的最準要求,許多老舊的編譯器仍然運行K&R C的標準,
1.3.2 ANSI C/C89標準
1970到80年代,C語言被廣泛應用,從大型主機到小型微機,也衍生了C語言的很多不同版本,1983年,美國國家標準協會(ANSI)成立了一個委員會X3J11,來制定 C語言標準,
1989年,美國國家標準協會(ANSI)通過了C語言標準,被稱為ANSI X3.159-1989 "Programming Language C",因為這個標準是1989年通過的,所以一般簡稱C89標準,有些人也簡稱ANSI C,因為這個標準是美國國家標準協會(ANSI)發布的,
1990年,國際標準化組織(ISO)和國際電工委員會(IEC)把C89標準定為C語言的國際標準,命名為ISO/IEC 9899:1990 - Programming languages -- C[5] ,因為此標準是在1990年發布的,所以有些人把簡稱作C90標準,不過大多數人依然稱之為C89標準,因為此標準與ANSI C89標準完全等同,
1994年,國際標準化組織(ISO)和國際電工委員會(IEC)發布了C89標準修訂版,名叫ISO/IEC 9899:1990/Cor 1:1994[6] ,有些人簡稱為C94標準,
1995年,國際標準化組織(ISO)和國際電工委員會(IEC)再次發布了C89標準修訂版,名叫ISO/IEC 9899:1990/Amd 1:1995 - C Integrity[7] ,有些人簡稱為C95標準,
1.3.3 C99標準
1999年1月,國際標準化組織(ISO)和國際電工委員會(IEC)發布了C語言的新標準,名叫ISO/IEC 9899:1999 - Programming languages -- C ,簡稱C99標準,這是C語言的第二個官方標準,
例如:
-
增加了新關鍵字 restrict,inline,_Complex,_Imaginary,_Bool
-
支持 long long,long double _Complex,float _Complex 這樣的型別
-
支持了不定長的陣列,陣列的長度就可以用變數了,宣告型別的時候呢,就用 int a[*] 這樣的寫法,不過考慮到效率和實作,這玩意并不是一個新型別,
二、記憶體磁區
2.1 資料型別
2.1.1 資料型別概念
什么是資料型別?為什么需要資料型別? 資料型別是為了更好進行記憶體的管理,讓編譯器能確定分配多少記憶體,
我們現實生活中,狗是狗,鳥是鳥等等,每一種事物都有自己的型別,那么程式中使用資料型別也是來源于生活,
當我們給狗分配記憶體的時候,也就相當于給狗建造狗窩,給鳥分配記憶體的時候,也就是給鳥建造一個鳥窩,我們可以給他們各自建造一個別墅,但是會造成記憶體的浪費,不能很好的利用記憶體空間,
我們在想,如果給鳥分配記憶體,只需要鳥窩大小的空間就夠了,如果給狗分配記憶體,那么也只需要狗窩大小的記憶體,而不是給鳥和狗都分配一座別墅,造成記憶體的浪費,
當我們定義一個變數,a = 10,編譯器如何分配記憶體?計算機只是一個機器,它怎么知道用多少記憶體可以放得下10?
所以說,資料型別非常重要,它可以告訴編譯器分配多少記憶體可以放得下我們的資料,
狗窩里面是狗,鳥窩里面是鳥,如果沒有資料型別,你怎么知道冰箱里放得是一頭大象!
資料型別基本概念:
-
型別是對資料的抽象;
-
型別相同的資料具有相同的表示形式、存盤格式以及相關操作;
-
程式中所有的資料都必定屬于某種資料型別;
-
資料型別可以理解為創建變數的模具: 固定大小記憶體的別名;

2.1.2 資料型別別名
typedef unsigned int u32;
typedef struct _PERSON{
char name[64];
int age;
}Person;
void test(){
u32 val; //相當于 unsigned int val;
Person person; //相當于 struct PERSON person;
}
2.1.3 void資料型別
void字面意思是”無型別”,void* 無型別指標,無型別指標可以指向任何型別的資料,
void定義變數是沒有任何意義的,當你定義void a,編譯器會報錯,
void真正用在以下兩個方面:
-
對函式回傳的限定;
-
對函式引數的限定;
//1. void修飾函式引數和函式回傳
void test01(void){
printf("hello world");
}
//2. 不能定義void型別變數
void test02(){
void val; //報錯
}
//3. void* 可以指向任何型別的資料,被稱為萬能指標
void test03(){
int a = 10;
void* p = NULL;
p = &a;
printf("a:%d\n",*(int*)p);
char c = 'a';
p = &c;
printf("c:%c\n",*(char*)p);
}
//4. void* 常用于資料型別的封裝
void test04(){
//void * memcpy(void * _Dst, const void * _Src, size_t _Size);
}
2.1.4 sizeof 運算子
sizeof 是 c語言中的一個運算子,類似于++、--等等,sizeof 能夠告訴我們編譯器為某一特定資料或者某一個型別的資料在記憶體中分配空間時分配的大小,大小以位元組為單位,
基本語法:
sizeof(變數);
sizeof 變數;
sizeof(型別);
sizeof 注意點:
-
sizeof回傳的占用空間大小是為這個變數開辟的大小,而不只是它用到的空間,和現今住房的建筑面積和實用面積的概念差不多,所以對結構體用的時候,大多情況下就得考慮位元組對齊的問題了;
-
sizeof回傳的資料結果型別是unsigned int;
-
要注意陣列名和指標變數的區別,通常情況下,我們總覺得陣列名和指標變數差不多,但是在用sizeof的時候差別很大,對陣列名用sizeof回傳的是整個陣列的大小,而對指標變數進行操作的時候回傳的則是指標變數本身所占得空間,在32位機的條件下一般都是4,而且當陣列名作為函式引數時,在函式內部,形參也就是個指標,所以不再回傳陣列的大小;
//1. sizeof基本用法
void test01(){
int a = 10;
printf("len:%d\n", sizeof(a));
printf("len:%d\n", sizeof(int));
printf("len:%d\n", sizeof a);
}
//2. sizeof 結果型別
void test02(){
unsigned int a = 10;
if (a - 11 < 0){
printf("結果小于0\n");
}
else{
printf("結果大于0\n");
}
int b = 5;
if (sizeof(b) - 10 < 0){
printf("結果小于0\n");
}
else{
printf("結果大于0\n");
}
}
//3. sizeof 碰到陣列
void TestArray(int arr[]){
printf("TestArray arr size:%d\n",sizeof(arr));
}
void test03(){
int arr[] = { 10, 20, 30, 40, 50 };
printf("array size: %d\n",sizeof(arr));
//陣列名在某些情況下等價于指標
int* pArr = arr;
printf("arr[2]:%d\n",pArr[2]);
printf("array size: %d\n", sizeof(pArr));
//陣列做函式函式引數,將退化為指標,在函式內部不再回傳陣列大小
TestArray(arr);
}
2.1.5 資料型別總結
-
資料型別本質是固定記憶體大小的別名,是個模具,C語言規定:通過資料型別定義變數;
-
資料型別大小計算(sizeof);
-
可以給已存在的資料型別起別名typedef;
-
資料型別的封裝(void 萬能型別);
2.2 變數
2.1.1 變數的概念
既能讀又能寫的記憶體物件,稱為變數;
若一旦初始化后不能修改的物件則稱為常量,
變數定義形式: 型別 識別符號, 識別符號, … , 識別符號
2.1.2 變數名的本質
-
變數名的本質:一段連續記憶體空間的別名;
-
程式通過變數來申請和命名記憶體空間 int a = 0;
-
通過變數名訪問記憶體空間;
-
不是向變數名讀寫資料,而是向變數所代表的記憶體空間中讀寫資料;
修改變數的兩種方式:
void test(){
int a = 10;
//1. 直接修改
a = 20;
printf("直接修改,a:%d\n",a);
//2. 間接修改
int* p = &a;
*p = 30;
printf("間接修改,a:%d\n", a);
}
2.3 程式的記憶體磁區模型
2.3.1 記憶體磁區
2.3.1.1 運行之前
我們要想執行我們撰寫的c程式,那么第一步需要對這個程式進行編譯, 1)預處理:宏定義展開、頭檔案展開、條件編譯,這里并不會檢查語法
2)編譯:檢查語法,將預處理后檔案編譯生成匯編檔案
3)匯編:將匯編檔案生成目標檔案(二進制檔案)
4)鏈接:將目標檔案鏈接為可執行程式
? 代碼區
存放 CPU 執行的機器指令,通常代碼區是可共享的(即另外的執行程式可以呼叫它),使其可共享的目的是對于頻繁被執行的程式,只需要在記憶體中有一份代碼即可,代碼區通常是只讀的,使其只讀的原因是防止程式意外地修改了它的指t令,另外,代碼區還規劃了區域變數的相關資訊,
? 全域初始化資料區/靜態資料區(data段)
該區包含了在程式中明確被初始化的全域變數、已經初始化的靜態變數(包括全域靜態變數和t)和常量資料(如字串常量),
? 未初始化資料區(又叫 bss 區)
存入的是全域未初始化變數和未初始化靜態變數,未初始化資料區的資料在程式開始執行之前被內核初始化為 0 或者空(NULL),
總體來講說,程式源代碼被編譯之后主要分成兩種段:程式指令(代碼區)和程式資料(資料區),代碼段屬于程式指令,而資料域段和.bss段屬于程式資料,
那為什么把程式的指令和程式資料分開呢?
-
程式被load到記憶體中之后,可以將資料和代碼分別映射到兩個記憶體區域,由于資料區域對行程來說是可讀可寫的,而指令區域對程式來講說是只讀的,所以磁區之后呢,可以將程式指令區域和資料區域分別設定成可讀可寫或只讀,這樣可以防止程式的指令有意或者無意被修改;
-
當系統中運行著多個同樣的程式的時候,這些程式執行的指令都是一樣的,所以只需要記憶體中保存一份程式的指令就可以了,只是每一個程式運行中資料不一樣而已,這樣可以節省大量的記憶體,比如說之前的Windows Internet Explorer 7.0運行起來之后, 它需要占用112 844KB的記憶體,它的私有部分資料有大概15 944KB,也就是說有96 900KB空間是共享的,如果程式中運行了幾百個這樣的行程,可以想象共享的方法可以節省大量的記憶體,
2.3.1.1 運行之后
程式在加載到記憶體前,代碼區和全域區(data和bss)的大小就是固定的,程式運行期間不能改變,然后,運行可執行程式,作業系統把物理硬碟程式load(加載)到記憶體,除了根據可執行程式的資訊分出代碼區(text)、資料區(data)和未初始化資料區(bss)之外,還額外增加了堆疊區、堆區,
? 代碼區(text segment)
加載的是可執行檔案代碼段,所有的可執行代碼都加載到代碼區,這塊記憶體是不可以在運行期間修改的,
? 未初始化資料區(BSS)
加載的是可執行檔案BSS段,位置可以分開亦可以緊靠資料段,存盤于資料段的資料(全域未初始化,靜態未初始化資料)的生存周期為整個程式運行程序,
? 全域初始化資料區/靜態資料區(data segment)
加載的是可執行檔案資料段,存盤于資料段(全域初始化,靜態初始化資料,文字常量(只讀))的資料的生存周期為整個程式運行程序,
? 堆疊區(stack)
堆疊是一種先進后出的記憶體結構,由編譯器自動分配釋放,存放函式的引數值、回傳值、區域變數等,在程式運行程序中實時加載和釋放,因此,區域變數的生存周期為申請到釋放該段堆疊空間,
? 堆區(heap)
堆是一個大容器,它的容量要遠遠大于堆疊,但沒有堆疊那樣先進后出的順序,用于動態記憶體分配,堆在記憶體中位于BSS區和堆疊區之間,一般由程式員分配和釋放,若程式員不釋放,程式結束時由作業系統回收,
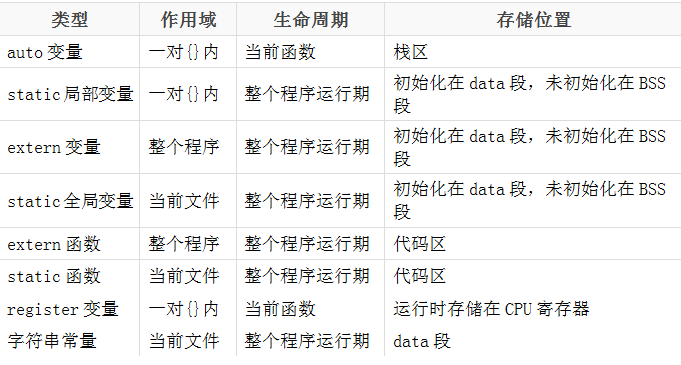
2.3.2 磁區模型
2.3.2.1 堆疊區
由系統進行記憶體的管理,主要存放函式的引數以及區域變數,在函式完成執行,系統自行釋放堆疊區記憶體,不需要用戶管理,
#char* func(){
char p[] = "hello world!"; //在堆疊區存盤 亂碼
printf("%s\n", p);
return p;
}
void test(){
char* p = NULL;
p = func();
printf("%s\n",p);
}
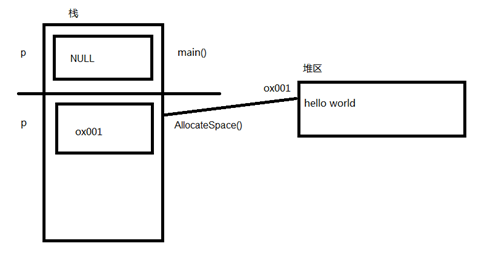
2.3.2.2 堆區
由編程人員手動申請,手動釋放,若不手動釋放,程式結束后由系統回收,生命周期是整個程式運行期間,使用malloc或者new進行堆的申請,
char* func(){
char* str = malloc(100);
strcpy(str, "hello world!");
printf("%s\n",str);
return str;
}
void test01(){
char* p = NULL;
p = func();
printf("%s\n",p);
}
void allocateSpace(char* p){
p = malloc(100);
strcpy(p, "hello world!");
printf("%s\n", p);
}
void test02(){
char* p = NULL;
allocateSpace(p);
printf("%s\n", p);
}
堆分配記憶體API:
#include <stdlib.h>
void *calloc(size_t nmemb, size_t size);
功能:
在記憶體動態存盤區中分配nmemb塊長度為size位元組的連續區域,calloc自動將分配的記憶體 置0,
引數:
nmemb:所需記憶體單元數量 size:每個記憶體單元的大小(單位:位元組)
回傳值:
成功:分配空間的起始地址
失敗:NULL
#include <stdlib.h>
void *realloc(void *ptr, size_t size);
功能:
重新分配用malloc或者calloc函式在堆中分配記憶體空間的大小, realloc不會自動清理增加的記憶體,需要手動清理,如果指定的地址后面有連續的空間,那么就會在已有地址基礎上增加記憶體,如果指定的地址后面沒有空間,那么realloc會重新分配新的連續記憶體,把舊記憶體的值拷貝到新記憶體,同時釋放舊記憶體,
引數:
ptr:為之前用malloc或者calloc分配的記憶體地址,如果此引數等于NULL,那么和realloc與malloc功能一致
size:為重新分配記憶體的大小, 單位:位元組
回傳值:
成功:新分配的堆記憶體地址
失敗:NULL
void test01(){
int* p1 = calloc(10,sizeof(int));
if (p1 == NULL){
return;
}
for (int i = 0; i < 10; i ++){
p1[i] = i + 1;
}
for (int i = 0; i < 10; i++){
printf("%d ",p1[i]);
}
printf("\n");
free(p1);
}
void test02(){
int* p1 = calloc(10, sizeof(int));
if (p1 == NULL){
return;
}
for (int i = 0; i < 10; i++){
p1[i] = i + 1;
}
int* p2 = realloc(p1, 15 * sizeof(int));
if (p2 == NULL){
return;
}
printf("%d\n", p1);
printf("%d\n", p2);
//列印
for (int i = 0; i < 15; i++){
printf("%d ", p2[i]);
}
printf("\n");
//重新賦值
for (int i = 0; i < 15; i++){
p2[i] = i + 1;
}
//再次列印
for (int i = 0; i < 15; i++){
printf("%d ", p2[i]);
}
printf("\n");
free(p2);
}
2.3.2.3 全域/靜態區
全域靜態區內的變數在編譯階段已經分配好記憶體空間并初始化,這塊記憶體在程式運行期間一直存在,它主要存盤全域變數、靜態變數和常量,
注意:
(1)這里不區分初始化和未初始化的資料區,是因為靜態存盤區內的變數若不顯示初始化,則編譯器會自動以默認的方式進行初始化,即靜態存盤區內不存在未初始化的變數,
(2)全域靜態存盤區內的常量分為常變數和字串常量,一經初始化,不可修改,靜態存盤內的常變數是全域變數,與區域常變數不同,區別在于區域常變數存放于堆疊,實際可間接通過指標或者參考進行修改,而全域常變數存放于靜態常量區則不可以間接修改,
(3)字串常量存盤在全域/靜態存盤區的常量區,
int v1 = 10;//全域/靜態區
const int v2 = 20; //常量,一旦初始化,不可修改
static int v3 = 20; //全域/靜態區
char *p1; //全域/靜態區,編譯器默認初始化為NULL
//那么全域static int 和 全域int變數有什么區別?
void test(){
static int v4 = 20; //全域/靜態區
}
char* func(){
static char arr[] = "hello world!"; //在靜態區存盤 可讀可寫
arr[2] = 'c';
char* p = "hello world!"; //全域/靜態區-字串常量區
//p[2] = 'c'; //只讀,不可修改
printf("%d\n",arr);
printf("%d\n",p);
printf("%s\n", arr);
return arr;
}
void test(){
char* p = func();
printf("%s\n",p);
}
2.3.2.4 總結
在理解C/C++記憶體磁區時,常會碰到如下術語:資料區,堆,堆疊,靜態區,常量區,全域區,字串常量區,文字常量區,代碼區等等,初學者被搞得云里霧里,在這里,嘗試捋清楚以上磁區的關系,
資料區包括:堆,堆疊,全域/靜態存盤區,
-
全域/靜態存盤區包括:常量區,全域區、靜態區,
-
常量區包括:字串常量區、常變數區,
-
代碼區:存放程式編譯后的二進制代碼,不可尋址區,
可以說,C/C++記憶體磁區其實只有兩個,即代碼區和資料區,
2.3.3 函式呼叫模型
2.3.3.1 函式呼叫流程
堆疊(stack)是現代計算機程式里最為重要的概念之一,幾乎每一個程式都使用了堆疊,沒有堆疊就沒有函式,沒有區域變數,也就沒有我們如今能見到的所有計算機的語言,在解釋為什么堆疊如此重要之前,我們先了解一下傳統的堆疊的定義:
在經典的計算機科學中,堆疊被定義為一個特殊的容器,用戶可以將資料壓入堆疊中(入堆疊,push),也可以將壓入堆疊中的資料彈出(出堆疊,pop),但是堆疊容器必須遵循一條規則:先入堆疊的資料最后出堆疊(First In Last Out,FILO).
在經典的作業系統中,堆疊總是向下增長的,壓堆疊的操作使得堆疊頂的地址減小,彈出操作使得堆疊頂地址增大,
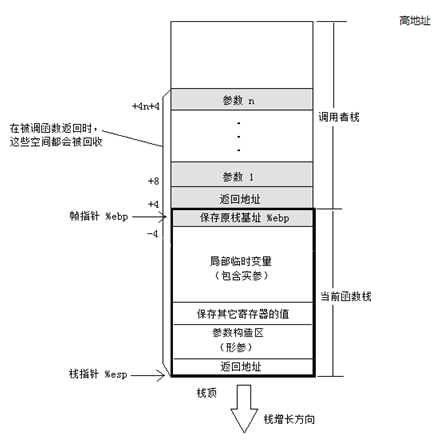
堆疊在程式運行中具有極其重要的地位,最重要的,堆疊保存一個函式呼叫所需要維護的資訊,這通常被稱為堆疊幀(Stack Frame)或者活動記錄(Activate Record).一個函式呼叫程序所需要的資訊一般包括以下幾個方面:
-
函式的回傳地址;
-
函式的引數;
-
臨時變數;
-
保存的背景關系:包括在函式呼叫前后需要保持不變的暫存器,
我們從下面的代碼,分析以下函式的呼叫程序:
int func(int a,int b){
int t_a = a;
int t_b = b;
return t_a + t_b;
}
int main(){
int ret = 0;
ret = func(10, 20);
return EXIT_SUCCESS;
}
程式員必備硬核資料,點擊下載
2.3.3.2 呼叫慣例
現在,我們大致了解了函式呼叫的程序,這期間有一個現象,那就是函式的呼叫者和被呼叫者對函式呼叫有著一致的理解,例如,它們雙方都一致的認為函式的引數是按照某個固定的方式壓入堆疊中,如果不這樣的話,函式將無法正確運行,
如果函式呼叫方在傳遞引數的時候先壓入a引數,再壓入b引數,而被呼叫函式則認為先壓入的是b,后壓入的是a,那么被呼叫函式在使用a,b值時候,就會顛倒,
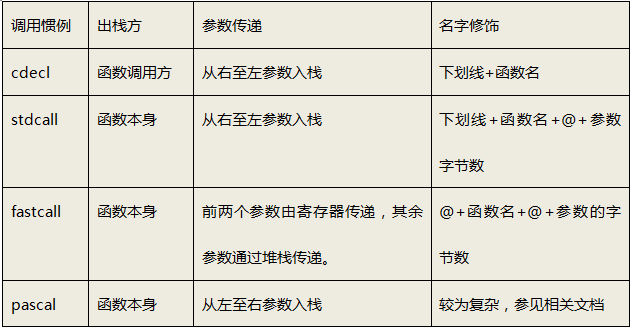
因此,函式的呼叫方和被呼叫方對于函式是如何呼叫的必須有一個明確的約定,只有雙方都遵循同樣的約定,函式才能夠被正確的呼叫,這樣的約定被稱為”呼叫慣例(Calling Convention)”.一個呼叫慣例一般包含以下幾個方面:
函式引數的傳遞順序和方式
函式的傳遞有很多種方式,最常見的是通過堆疊傳遞,函式的呼叫方將引數壓入堆疊中,函式自己再從堆疊中將引數取出,對于有多個引數的函式,呼叫慣例要規定函式呼叫方將引數壓堆疊的順序:從左向右,還是從右向左,有些呼叫慣例還允許使用暫存器傳遞引數,以提高性能,
堆疊的維護方式
在函式將引數壓入堆疊中之后,函式體會被呼叫,此后需要將被壓入堆疊中的引數全部彈出,以使得堆疊在函式呼叫前后保持一致,這個彈出的作業可以由函式的呼叫方來完成,也可以由函式本身來完成,
為了在鏈接的時候對呼叫慣例進行區分,呼叫慣例要對函式本身的名字進行修飾,不同的呼叫慣例有不同的名字修飾策略,
事實上,在c語言里,存在著多個呼叫慣例,而默認的是cdecl.任何一個沒有顯示指定呼叫慣例的函式都是默認是cdecl慣例,比如我們上面對于func函式的宣告,它的完整寫法應該是:
int _cdecl func(int a,int b);
注意: cdecl不是標準的關鍵字,在不同的編譯器里可能有不同的寫法,例如gcc里就不存在_cdecl這樣的關鍵字,而是使用__attribute_((cdecl)).
2.3.3.2 函式變數傳遞分析
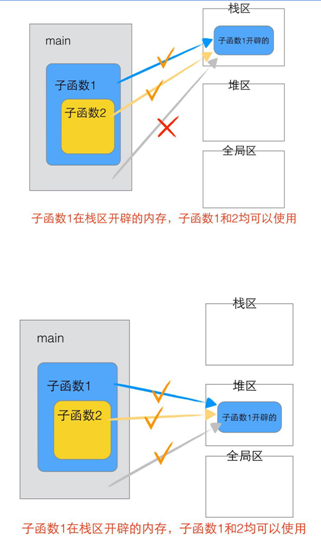
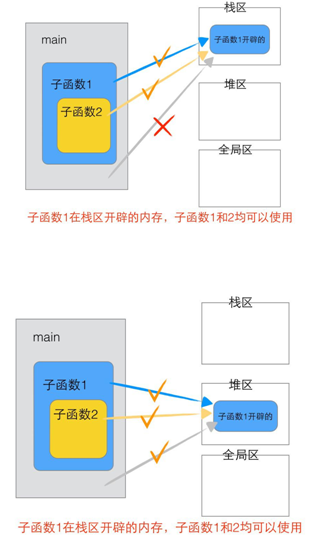
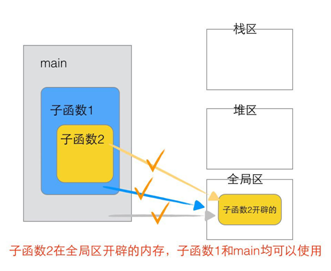
程式員必備硬核資料,點擊下載
2.3.4 堆疊的生長方向和記憶體存放方向
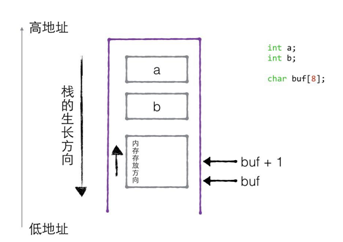
//1. 堆疊的生長方向
void test01(){
int a = 10;
int b = 20;
int c = 30;
int d = 40;
printf("a = %d\n", &a);
printf("b = %d\n", &b);
printf("c = %d\n", &c);
printf("d = %d\n", &d);
//a的地址大于b的地址,故而生長方向向下
}
//2. 記憶體生長方向(小端模式)
void test02(){
//高位位元組 -> 地位位元組
int num = 0xaabbccdd;
unsigned char* p = #
//從首地址開始的第一個位元組
printf("%x\n",*p);
printf("%x\n", *(p + 1));
printf("%x\n", *(p + 2));
printf("%x\n", *(p + 3));
}
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/289657.html
標籤:其他