Kafka系統架構———Zookeeper+Kafka集群部署
- 一. Kafka 概述
- 1. 什么是訊息佇列
- 2. 為什么需要訊息佇列(MQ)
- 3. 使用訊息佇列的好處
- 4. 訊息佇列的兩種模式
- 二. Kafka 定義
- 三. Kafka 簡介
- 四. Kafka 的特性
- 五. Kafka 系統架構
- 1. Broker
- 2. Topic
- 3. Partition
- ==3.1 Partation 資料路由規則==
- 3.2 磁區的原因
- 4. Leader
- 5. Follower
- 6. Replica
- 7. Producer
- 8. Consumer
- 9. Consumer Group(CG)
- 10. offset 偏移量
- 11. Zookeeper
- 六. 部署 Zookeeper 集群
- 七. 部署Kafka
- 1. 安裝Kafka
- 2. 修改組態檔
- 3. 修改環境變數
- 4. 配置 Kafka啟動腳本
- 5. 設定開機自啟
- 6. Kafka 命令列操作

一. Kafka 概述
1. 什么是訊息佇列
訊息(Message)是指在應用之間傳送的資料,訊息可以非常簡單,比如只包含文本字串,也可以更復雜,可能包含嵌入物件,
??訊息佇列(Message Queue)是一種應用間的通信方式,訊息發送后可以立即回傳,有訊息系統來確保資訊的可靠專遞,訊息發布者只管把訊息發布到MQ中而不管誰來取,訊息使用者只管從MQ中取訊息而不管誰發布的,這樣發布者和使用者都不用知道對方的存在,
2. 為什么需要訊息佇列(MQ)
主要原因是由于在高并發環境下,同步請求來不及處理,請求往往會發生阻塞,比如大量的請求并發訪問資料庫,導致行鎖表鎖,最后請求執行緒會堆積過多,從而觸發 too many connection 錯誤,引發雪崩效應,
??我們使用訊息佇列,通過異步處理請求,從而緩解系統的壓力,訊息佇列常應用于異步處理,流量削峰,應用解耦,訊息通訊等場景,
??當前比較常見的 MQ 中間件 ActiveMQ、RabbitMQ、RocketMQ、Kafka 等,

3. 使用訊息佇列的好處
(1)解耦
??允許你獨立的擴展或修改兩邊的處理程序,只要確保它們遵守同樣的介面約束,
(2)可恢復性
??系統的一部分組件失效時,不會影響到整個系統,訊息佇列降低了行程間的耦合度,所以即使一個處理訊息的行程掛掉,加入佇列中的訊息仍然可以在系統恢復后被處理,
(3)緩沖
??有助于控制和優化資料流經過系統的速度,解決生產訊息和消費訊息的處理速度不一致的情況,
(4)靈活性 & 峰值處理能力
??在訪問量劇增的情況下,應用仍然需要繼續發揮作用,但是這樣的突發流量并不常見,如果為以能處理這類峰值訪問為標準來投入資源隨時待命無疑是巨大的浪費,使用訊息佇列能夠使關鍵組件頂住突發的訪問壓力,而不會因為突發的超負荷的請求而完全崩潰,
(5)異步通信
??很多時候,用戶不想也不需要立即處理訊息,訊息佇列提供了異步處理機制,允許用戶把一個訊息放入佇列,但并不立即處理它,想向佇列中放入多少訊息就放多少,然后在需要的時候再去處理它們,
4. 訊息佇列的兩種模式
(1)點對點模式(一對一,消費者主動拉取資料,訊息收到后訊息清除)
??訊息生產者生產訊息發送到訊息佇列中,然后訊息消費者從訊息佇列中取出并且消費訊息,訊息被消費以后,訊息佇列中不再有存盤,所以訊息消費者不可能消費到已經被消費的訊息,訊息佇列支持存在多個消費者,但是對一個訊息而言,只會有一個消費者可以消費,
(2)發布/訂閱模式(一對多,又叫觀察者模式,消費者消費資料之后不會清除訊息)
??訊息生產者(發布)將訊息發布到 topic 中,同時有多個訊息消費者(訂閱)消費該訊息,和點對點方式不同,發布到 topic 的訊息會被所有訂閱者消費,
??發布/訂閱模式是定義物件間一種一對多的依賴關系,使得每當一個物件(目標物件)的狀態發生改變,則所有依賴于它的物件(觀察者物件)都會得到通知并自動更新,
二. Kafka 定義
Kafka 是一個分布式的基于發布/訂閱模式的訊息佇列(MQ,Message Queue),主要應用于大資料實時處理領域,
三. Kafka 簡介
Kafka 是最初由 Linkedin 公司開發,是一個分布式、支持磁區的(partition)、多副本的(replica),基于 Zookeeper 協調的分布式訊息中間件系統,它的最大的特性就是可以實時的處理大量資料以滿足各種需求場景,比如基于 hadoop 的批處理系統、低延遲的實時系統、Spark/Flink 流式處理引擎,nginx 訪問日志,訊息服務等等,用 scala 語言撰寫,
??Linkedin 于 2010 年貢獻給了 Apache 基金會并成為頂級開源專案,
四. Kafka 的特性
- 高吞吐量、低延遲
Kafka 每秒可以處理幾十萬條訊息,它的延遲最低只有幾毫秒,每個 topic 可以分多個 Partition,Consumer Group 對 Partition 進行消費操作,提高負載均衡能力和消費能力,
-
可擴展性
??kafka 集群支持熱擴展 -
持久性、可靠性
??訊息被持久化到本地磁盤,并且支持資料備份防止資料丟失 -
容錯性
??允許集群中節點失敗(多副本情況下,若副本數量為 n,則允許 n-1 個節點失敗) -
高并發
??支持數千個客戶端同時讀寫
五. Kafka 系統架構
1. Broker
一臺 kafka 服務器就是一個 broker,一個集群由多個 broker 組成,一個 broker 可以容納多個 topic,
2. Topic
可以理解為一個佇列,生產者和消費者面向的都是一個 topic,
類似于資料庫的表名或者 ES 的 index 物理上不同 topic的訊息分開存盤
3. Partition
為了實作擴展性,一個非常大的 topic 可以分布到多個 broker(即服務器)上,一個 topic 可以分割為一個或多個 partition,每個 partition 是一個有序的佇列,Kafka 只保證 partition 內的記錄是有序的,而不保證
topic 中不同 partition 的順序,
每個 topic 至少有一個 partition,當生產者產生資料的時候,會根據分配策略選擇磁區,然后將訊息追加到指定的磁區的佇列末尾,
3.1 Partation 資料路由規則
-
1.指定了 patition,則直接使用;
-
2.未指定 patition 但指定 key(相當于訊息中某個屬性),通過對 key 的 value 進行 hash 取模,選出一個 patition;
-
3.patition 和 key 都未指定,使用輪詢選出一個 patition,
每條訊息都會有一個自增的編號,用于標識訊息的偏移量,標識順序從 0 開始, 每個 partition 中的資料使用多個 segment檔案存盤, ??
如果 topic 有多個 partition,消費資料時就不能保證資料的順序,嚴格保證訊息的消費順序的場景下(例如商品秒殺、搶紅包),需要將 partition 數目設為 1,
- broker 存盤 topic 的資料,如果某 topic 有 N 個 partition,集群有 N 個 broker,那么每個 broker 存盤該 topic 的一個 partition,
- 如果某 topic 有 N 個 partition,集群有 (N+M) 個 broker,那么其中有 N 個 broker 存盤 topic 的一個 partition, 剩下的 M 個 broker 不存盤該 topic 的 partition 資料,
- 如果某 topic 有 N 個 partition,集群中 broker 數目少于 N 個,那么一個 broker 存盤該 topic 的一個或多個 partition,在實際生產環境中,盡量避免這種情況的發生,這種情況容易導致 Kafka 集群資料不均衡,
3.2 磁區的原因
- 方便在集群中擴展,每個Partition可以通過調整以適應它所在的機器,而一個topic又可以有多個Partition組成,因此整個集群就可以適應任意大小的資料了;
- 可以提高并發,因為可以以Partition為單位讀寫了,
4. Leader
每個 partition 有多個副本,其中有且僅有一個作為 Leader,Leader 是當前負責資料的讀寫的 partition,
5. Follower
Follower 跟隨 Leader,所有寫請求都通過 Leader 路由,資料變更會廣播給所有 Follower,Follower 與 Leader 保持資料同步,Follower 只負責備份,不負責資料的讀寫,
??如果 Leader 故障,則從 Follower 中選舉出一個新的 Leader,
??當 Follower 掛掉、卡住或者同步太慢,Leader 會把這個 Follower 從 ISR(Leader 維護一個和 Leader 保持同步的 Follower 集合) 串列中洗掉,重新創建一個 Follower,
6. Replica
副本,為保證集群中的某個節點發生故障時,該節點上的 partition 資料不丟失,且 kafka 仍然能夠繼續作業,kafka 提供了副本機制,一個 topic 的每個磁區都有若干個副本,一個 leader 和若干個 follower,
7. Producer
生產者即資料的發布者,該角色將訊息發布到 Kafka 的 topic 中,
??broker 接收到生產者發送的訊息后,broker 將該訊息追加到當前用于追加資料的 segment 檔案中,
??生產者發送的訊息,存盤到一個 partition 中,生產者也可以指定資料存盤的 partition,
8. Consumer
消費者可以從 broker 中讀取資料,消費者可以消費多個 topic 中的資料,
9. Consumer Group(CG)
消費者組,由多個 consumer 組成,
??所有的消費者都屬于某個消費者組,即消費者組是邏輯上的一個訂閱者,可為每個消費者指定組名,若不指定組名則屬于默認的組,
??將多個消費者集中到一起去處理某一個 Topic 的資料,可以更快的提高資料的消費能力,
??消費者組內每個消費者負責消費不同磁區的資料,一個磁區只能由一個組內消費者消費,防止資料被重復讀取,
??消費者組之間互不影響,
10. offset 偏移量
可以唯一的標識一條訊息,
??偏移量決定讀取資料的位置,不會有執行緒安全的問題,消費者通過偏移量來決定下次讀取的訊息(即消費位置),
??訊息被消費之后,并不被馬上洗掉,這樣多個業務就可以重復使用 Kafka 的訊息,
??某一個業務也可以通過修改偏移量達到重新讀取訊息的目的,偏移量由用戶控制,
??訊息最侄訓是會被洗掉的,默認生命周期為 1 周(7*24小時),
11. Zookeeper
Kafka 通過 Zookeeper 來存盤集群的 meta 資訊,
由于 consumer 在消費程序中可能會出現斷電宕機等故障,consumer 恢復后,需要從故障前的位置的繼續消費,所以 consumer 需要實時記錄自己消費到了哪個 offset,以便故障恢復后繼續消費,
Kafka 0.9 版本之前,consumer 默認將 offset 保存在 Zookeeper 中;從 0.9 版本開始,consumer 默認將 offset 保存在 Kafka 一個內置的 topic 中,該 topic 為 __consumer_offsets,
六. 部署 Zookeeper 集群
部署 Zookeeper 集群
七. 部署Kafka
三臺服務器都需要安裝
| 主機名 | 作業系統 | IP地址 | 安裝包 |
|---|---|---|---|
| Centos7-3 | Centos7 | 192.168.118.13 | apache-zookeeper-3.6.3-bin.tar |
| Centos7-5 | Centos7 | 192.168.118.15 | apache-zookeeper-3.6.3-bin.tar |
| Centos7-6 | Centos7 | 192.168.118.16 | apache-zookeeper-3.6.3-bin.tar |
因為前面的實驗zookeeper 已經安裝好了,這邊啟動下就行,下面安裝Kafka
1.下載安裝包
官方下載地址:http://kafka.apache.org/downloads.html
cd /opt
wget https://mirrors.tuna.tsinghua.edu.cn/apache/kafka/2.7.1/kafka_2.13-2.7.1.tgz**
1. 安裝Kafka
cd /opt/
tar zxvf kafka_2.13-2.7.1.tgz
mv kafka_2.13-2.7.1 /usr/local/kafka_2.13-2.7.1
2. 修改組態檔
cd /usr/local/kafka_2.13-2.7.1/config/
cp server.properties{,.bak}
vim server.properties
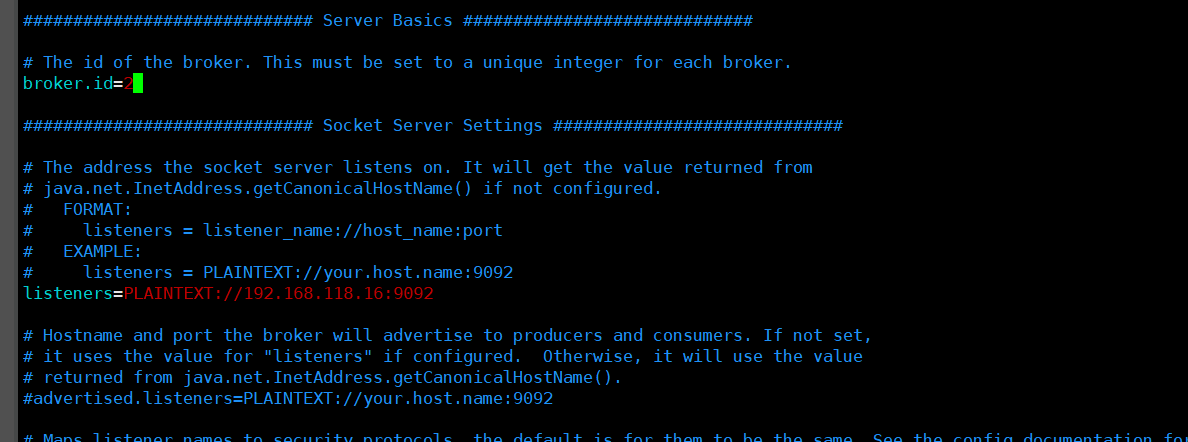
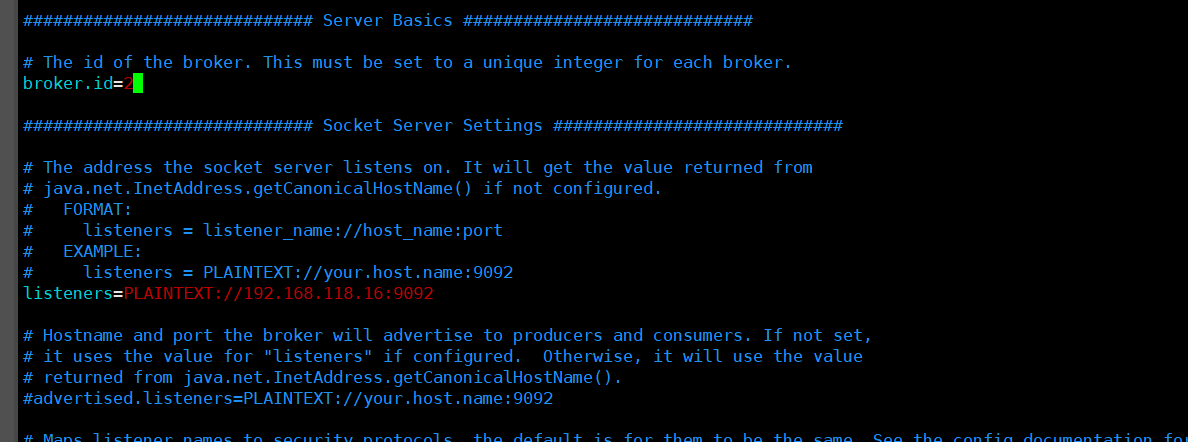
broker.id=0 #21行,broker的全域唯一編號,每個broker不能重復,因此要在其他機器上配置 broker.id=1、broker.id=2
listeners=PLAINTEXT://192.168.73.66:9092 #31行,指定監聽的IP和埠,如果修改每個broker的IP需區分開來,也可保持默認配置不用修改
num.network.threads=3 #42行,broker 處理網路請求的執行緒數量,一般情況下不需要去修改
num.io.threads=8 #45行,用來處理磁盤IO的執行緒數量,數值應該大于硬碟數
socket.send.buffer.bytes=102400 #48行,發送套接字的緩沖區大小
socket.receive.buffer.bytes=102400 #51行,接收套接字的緩沖區大小
socket.request.max.bytes=104857600 #54行,請求套接字的緩沖區大小
log.dirs=/usr/local/kafka/logs #60行,kafka運行日志存放的路徑,也是資料存放的路徑
num.partitions=1 #65行,topic在當前broker上的默認磁區個數,會被topic創建時的指定引數覆寫
num.recovery.threads.per.data.dir=1 #69行,用來恢復和清理data下資料的執行緒數量
log.retention.hours=168 #103行,segment檔案(資料檔案)保留的最長時間,單位為小時,默認為7天,超時將被洗掉
log.segment.bytes=1073741824 #110行,一個segment檔案最大的大小,默認為 1G,超出將新建一個新的segment檔案
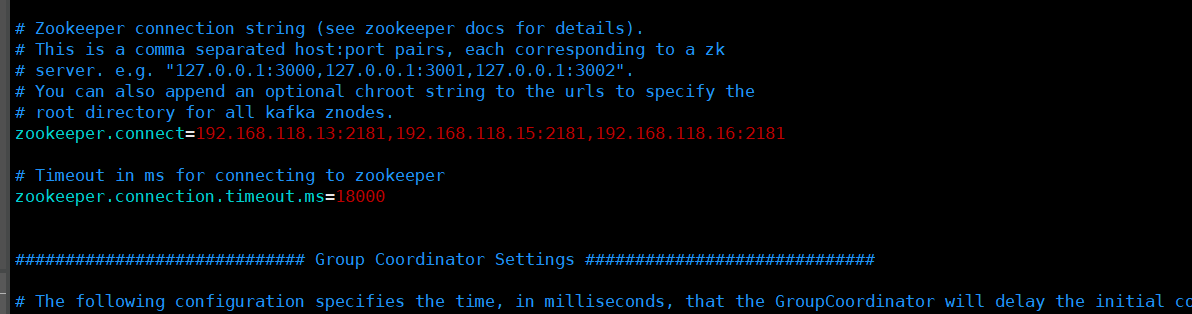
zookeeper.connect=192.168.80.10:2181,192.168.80.11:2181,192.168.80.12:2181 ●123行,配置連接Zookeeper集群地址
3. 修改環境變數
vim /etc/profile
export KAFKA_HOME=/usr/local/kafka_2.13-2.7.1
export PATH=$PATH:$KAFKA_HOME/bin
source /etc/profile
4. 配置 Kafka啟動腳本
vim /etc/init.d/kafka
#!/bin/bash
#chkconfig:2345 22 88
#description:Kafka Service Control Script
KAFKA_HOME='/usr/local/kafka_2.13-2.7.1'
case $1 in
start)
echo "---------- Kafka 啟動 ------------"
${KAFKA_HOME}/bin/kafka-server-start.sh -daemon ${KAFKA_HOME}/config/server.properties
;;
stop)
echo "---------- Kafka 停止 ------------"
${KAFKA_HOME}/bin/kafka-server-stop.sh
;;
restart)
$0 stop
$0 start
;;
status)
echo "---------- Kafka 狀態 ------------"
count=$(ps -ef | grep kafka | egrep -cv "grep|$$")
if [ "$count" -eq 0 ];then
echo "kafka is not running"
else
echo "kafka is running"
fi
;;
*)
echo "Usage: $0 {start|stop|restart|status}"
esac
5. 設定開機自啟
chmod +x /etc/init.d/kafka
chkconfig --add kafka
//分別啟動 Kafka
service kafka start

6. Kafka 命令列操作
//創建topic
kafka-topics.sh --create --zookeeper 192.168.80.10:2181,192.168.80.11:2181,192.168.80.12:2181 --replication-factor 2 --partitions 3 --topic test
-------------------------------------------------------------------------------------
--zookeeper:定義 zookeeper 集群服務器地址,如果有多個 IP 地址使用逗號分割,一般使用一個 IP 即可
--replication-factor:定義磁區副本數,1 代表單副本,建議為 2
--partitions:定義磁區數
--topic:定義 topic 名稱
-------------------------------------------------------------------------------------
//查看當前服務器中的所有 topic
kafka-topics.sh --list --zookeeper 192.168.80.10:2181,192.168.80.11:2181,192.168.80.12:2181
//查看某個 topic 的詳情
kafka-topics.sh --describe --zookeeper 192.168.80.10:2181,192.168.80.11:2181,192.168.80.12:2181
//發布訊息
kafka-console-producer.sh --broker-list 192.168.80.10:9092,192.168.80.11:9092,192.168.80.12:9092 --topic test
//消費訊息
kafka-console-consumer.sh --bootstrap-server 192.168.80.10:9092,192.168.80.11:9092,192.168.80.12:9092 --topic test --from-beginning
-------------------------------------------------------------------------------------
--from-beginning:會把主題中以往所有的資料都讀取出來
-------------------------------------------------------------------------------------
//修改磁區數
kafka-topics.sh --zookeeper 192.168.73.66:2181,192.168.73.168:2181,192.168.73.55:2181 --alter --topic test --partitions 6
//洗掉 topic
kafka-topics.sh --delete --zookeeper 192.168.73.66:2181,192.168.73.168:2181,192.168.73.55:2181 --topic test
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/289833.html
標籤:其他
上一篇:WebSocket實作實時通信