目錄
資料準備
資料展示
模型搭建
構建模型
K近鄰演算法
模型評估
總結與歸納
每文一語
資料準備
鳶尾花資料附帶在Python scikit-learn 的 datasets 模塊中,我們只需要呼叫這個資料即可,用于打開機器學習的大門,
from sklearn.datasets import load_iris
iris_dataset = load_iris()load_iris 回傳的 iris 物件是一個 Bunch 物件,與字典非常相似,里面包含鍵和值:
我們如何區分了,看看下面這個例子:
In [1]: from sklearn.datasets import base
...: buch = base.Bunch(A=1,B=2,c=3)
In [2]: type(buch)
Out[2]: sklearn.datasets.base.Bunch
In [3]: buch
Out[3]: {'A': 1, 'B': 2, 'c': 3} #類似于字典的格式
In [4]: buch['A'] #通過字典類似的方法也可以呼叫
Out[4]: 1
In [5]: buch.A #物件.屬性,用該方法也可以呼叫
Out[5]: 1
In [6]: dt = {'A':1,'B':2,'C':3}
In [7]: type(dt)
Out[7]: dict
In [8]: dt['A']
Out[8]: 1
In [9]: dt.A #但是字典就不可以了,這就是它們的最大區別
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input-9-7b8328c57719> in <module>()
----> 1 dt.A這個就是它們的區別,有些東西需要了解,不一定要精通
資料展示
print("前五行的資料展示:\n", iris_dataset['data'][:5])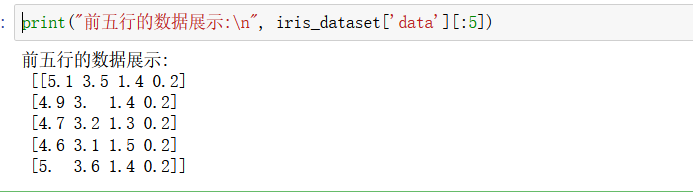
print("Type of data:", type(iris_dataset['data']))
因為我們的資料型別型別現在已經變成了numpy的陣列型別了,所以我們用的是索引切片,約束我們的資料,
模型搭建
在機器學習的程序中,模型的選擇和搭建是非常的重要的,一個好的模型可以讓我們的資料變得更有價值,
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
iris_dataset['data'], iris_dataset['target'], random_state=0)scikit-learn 中的資料通常用大寫的 X 表示,而標簽用小寫的 y 表示,這是受到了數學標準公式 f(x)=y 的啟發,其中 x 是函式的輸入, y 是輸出,我們用大寫的 X 是因為資料是一個二維陣列(矩陣),用小寫的 y 是因為目標是一個一維陣列(向量),這也是數學中的約定,
scikit-learn 中的 train_test_split 函式可以打亂資料集并進行拆分,這個函式將 75% 的
行資料及對應標簽作為訓練集,剩下 25% 的資料及其標簽作為測驗集,訓練集與測驗集的
分配比例可以是隨意的,但使用 25% 的資料作為測驗集是很好的經驗法則,這樣的分配原則在模型的訓練和測驗是比較的智能科學的,
為了確保多次運行同一函式能夠得到相同的輸出,我們利用 random_state 引數指定了隨機
數生成器的種子,這樣函式輸出就是固定不變的,所以這行代碼的輸出始終相同,
我們可以看看我們的具體的資料型別,這樣我們就可以明顯的了解到為什么會有兩個變數接收,在上面的引數解釋,也說明了,因為是一個二維陣列,對應的資料

觀察資料和檢查資料
在構建機器學習模型之前,通常最好檢查一下資料,看看如果不用機器學習能不能輕松完成任務,或者需要的資訊有沒有包含在資料中,
檢查資料的最佳方法之一就是將其可視化,一種可視化方法是繪制散點圖(scatter plot),資料散點圖將一個特征作為 x 軸,另一個特征作為 y 軸,將每一個資料點繪制為圖上的一個點,不幸的是,計算機螢屏只有兩個維度,所以我們一次只能繪制兩個特征(也可能是3 個),用這種方法難以對多于 3 個特征的資料集作圖,解決這個問題的一種方法是繪制散點圖矩陣(pair plot),從而可以兩兩查看所有的特征,
iris_dataframe = pd.DataFrame(X_train, columns=iris_dataset.feature_names)
pd.plotting.scatter_matrix(iris_dataframe, c=y_train, figsize=(15, 15),
marker='o', hist_kwds={'bins': 20}, s=60,
alpha=.8, cmap=mglearn.cm3)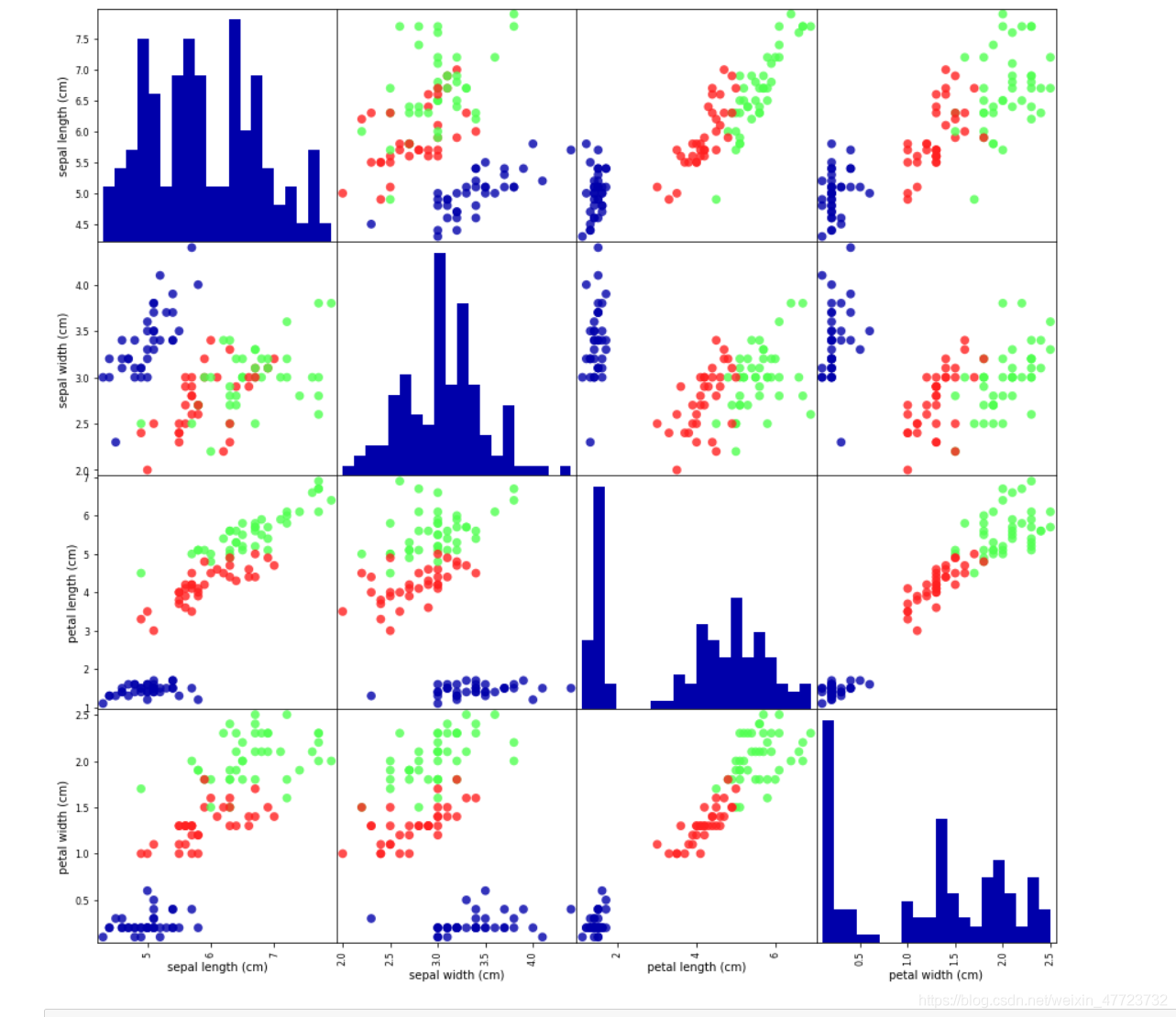
通過觀察我們,可以發現不同的標簽,也呈現出“物以類聚”的特點,這就說明機器學習可以比較很好的區分出,也是比較的適合分類演算法的
引數解釋
dataframe:iris_dataframe 按行取資料
c=y_train 顏色,用不同著色度區分不同種類
figsize=(15,15) 影像區域大小,英寸為單位
marker=‘0’ 點的形狀,0是圓,1是¥
hist_kwds={‘bins’:50} 對角線上直方圖的引數元組
s=60 描出點的大小
alpha=.8 影像透明度,一般取(0,1]
cmap=mglearn.cm3 mylearn實用函式庫,主要對圖進行一些美化等私有功能
構建模型
K近鄰演算法
k 近鄰演算法中 k 的含義是,我們可以考慮訓練集中與新資料點最近的任意 k 個鄰居(比如
說,距離最近的 3 個或 5 個鄰居),而不是只考慮最近的那一個,然后,我們可以用這些
鄰居中數量最多的類別做出預測,
模型引數比較重要
KNeighborsClassifier 最重要的引數就是鄰居的數目,這里我們設為 1:
knn 物件對演算法進行了封裝,既包括用訓練資料構建模型的演算法,也包括對新資料點進行
預測的演算法,它還包括演算法從訓練資料中提取的資訊,對于 KNeighborsClassifier 來說,
里面只保存了訓練集,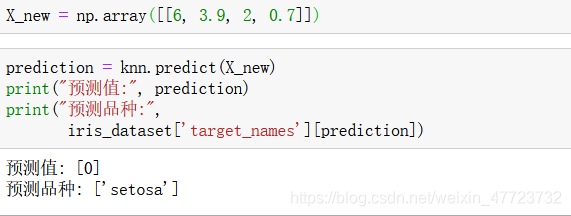
根據我們模型的預測,這朵新的鳶尾花屬于類別 0,也就是說它屬于 setosa 品種,這里我們也可以自動的要求我們的用戶輸入,直接可以出結果,
模型評估
我們可以通過計算精度(accuracy)來衡量模型的優劣,精度就是品種預測正確的花所占的比例:
可以使用 knn 物件的 score 方法來計算測驗集的精度:

總結與歸納
我們構思了一項任務,要利用鳶尾花的物理測量資料來預測其品種,我們在構建模型時用到了由專家標注過的測量資料集,專家已經給出了花的正確品種,因此這是一個監督學習問題,一共有三個
品種: setosa、 versicolor 或 virginica,因此這是一個三分類問題,在分類問題中,可能的品種被稱為類別(class),每朵花的品種被稱為它的標簽(label),
鳶尾花(Iris)資料集包含兩個 NumPy 陣列:一個包含資料,在 scikit-learn 中被稱為 X;一個包含正確的輸出或預期輸出,被稱為 y,陣列 X 是特征的二維陣列,每個資料點對應一行,每個特征對應一列,陣列 y 是一維陣列,里面包含一個類別標簽,對每個樣本都是一個 0 到 2 之間的數,
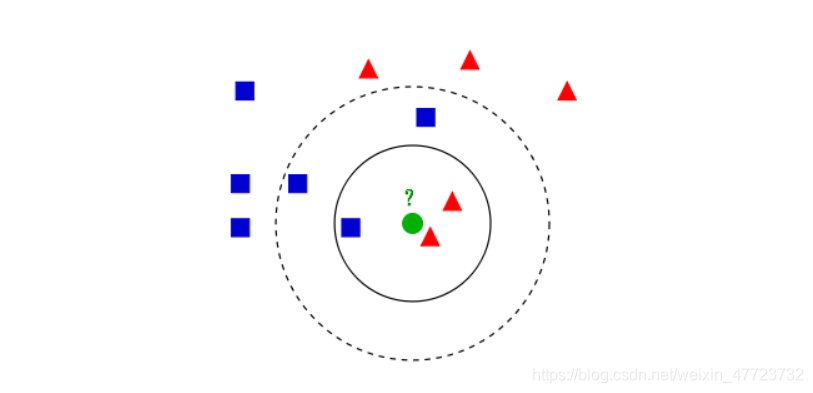
K近鄰演算法,即是給定一個訓練資料集,對新的輸入實體,在訓練資料集中找到與該實體最鄰近的K個實體,這K個實體的多數屬于某個類,就把該輸入實體分類到這個類中,(這就類似于現實生活中少數服從多數的思想)
這里我們使用了,K近鄰演算法進行模型的搭建,當然也可以運用其他的演算法模型進行預測,比如邏輯回歸......
使用k近鄰演算法的條件:
1. 你需要一個訓練的資料集,這個資料集包含各種特征值和對應的label值 ,在使用前需要將各種特征歸一化處理,
2. 利用訓練的資料集來對要分類的資料進行分類:
根據歐式距離計算出要預測的資料與訓練資料集中距離最短的前k個值,然后根據前k個值對應的label
統計出 label值最最多的,如選擇的前k個對應的label:['dog','dog','dog','fish'] ,那么這個結果是dog類,
k近鄰演算法特點:
優點: 計算精度高,不受例外值影響,
缺點: 計算復雜度高,空間復雜度高
適用于: 帶lable的數值類
每文一語
有的人21歲畢業,到27歲才找到作業;有的人一畢業就擁有了一切;有的人沒有上過大學,卻在20出頭的年紀里,干著自己熱愛的事業;有的人明明彼此相愛卻不能在一起,其實人生中的每一件事,都取決于我們的時間安排;有些人也許遙遙領先于我們,有些人也許落后與我們,但凡事都有它自己的節奏;30歲還沒結婚,按但只要過得快樂也是一種幸福;耐心一點,踏實一點,;因為愛因斯坦說過:并不是每一件算得出來的事都有意義,也不是每一件有意義的事都能被算出來,真正重要的是:打破傳統思維,獲得精神上的自由,我們要創造一個屬于自己充滿意義的人生,不嫉妒、不羨慕、不被任何事影響!
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/289902.html
標籤:其他