序言
昨天被YOLOX刷屏了,各大公眾號強推:性能超yolov5!!吊打一切yolo!!看麻了我,標題還能再夸張點嘛?出于對前沿技術的渴望,還是要去學習學習,論文中改進了很多地方,這里就不再介紹,刷屏的文章中都已經介紹了,直接來看下作者給的性能對比圖:
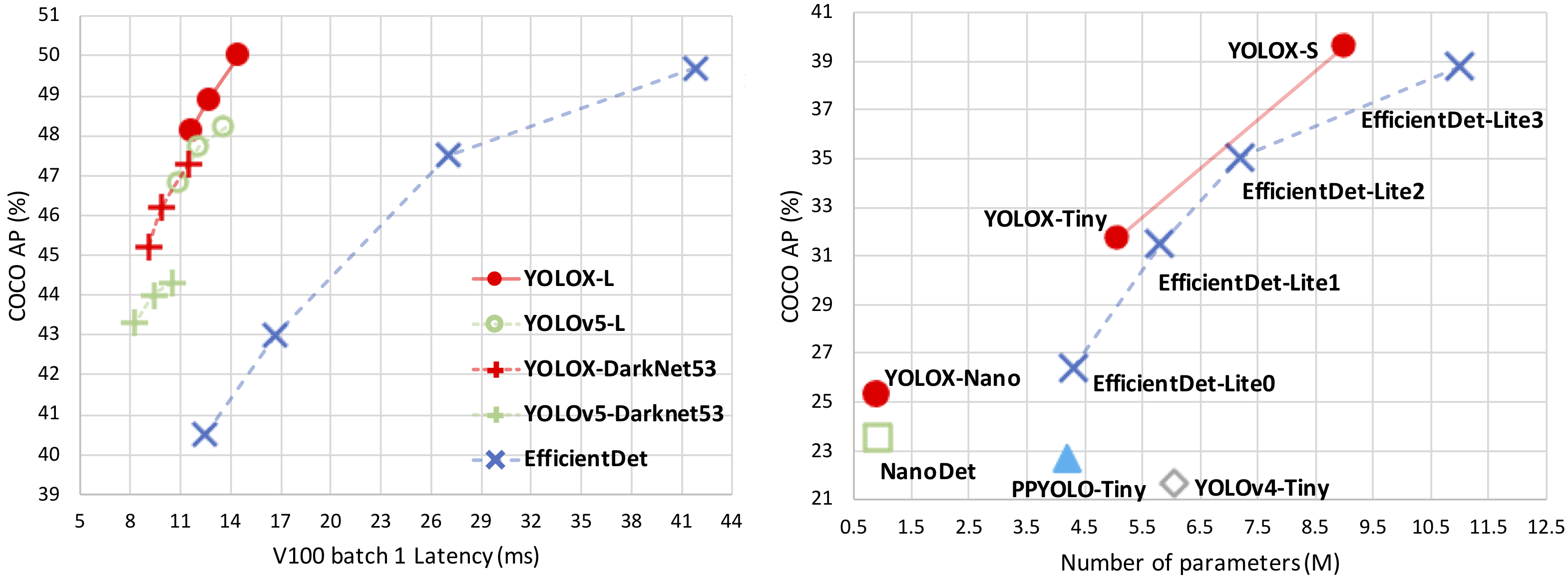
左邊是大模型的性能對比,右邊是各自輕量型模型的對比,可以看到越靠近左上角性能越優,此外作者還一次性開源了tensorrt、ncnn、openvino、onnx部署代碼,可謂業界良心,從訓練到部署一條龍服務,
習慣了yolo格式訓練方式的我,在踩了無數的坑后,決定寫一篇訓練教程文章,記錄自己踩坑的程序,也給后來人做參考,
話說在前頭,坑是真的多,給我整麻了,要訓練的同學做好debug的心理準備,

YOLOX官方倉庫
一、配置環境
訓練之前,按照官方的環境配一下,先介紹我的硬體情況:
- ubuntu18
- rtx 3070
- cuda 11.1
因為要裝的東西很多,我這里直接創建了一個conda虛擬環境,避免和我之前的環境產生沖突:
conda create -n yolox python=3.7 # 創建環境
source activate yolox # 激活環境
然后按照官方給的安裝示例,配置必須的包:
git clone git@github.com:Megvii-BaseDetection/YOLOX.git
cd YOLOX
pip3 install -U pip
pip3 install -r requirements.txt # 在requirements.txt 里我把torch注釋掉了
python3 setup.py develop
我這里獨自pip install安裝的pytorch,版本是1.8,因為默認requirements.txt安裝的話是安裝最新版的1.9,而我在跑代碼的時候因為1.9版本的問題報錯了,張量cuda加載不上,如果你遇到同樣的問題的話建議獨自安裝1.8版本的torch,
然后安裝nvidia混合精度庫apex:
git clone https://github.com/NVIDIA/apex
cd apex
pip3 install -v --disable-pip-version-check --no-cache-dir --global-option="--cpp_ext" --global-option="--cuda_ext" ./
在安裝apex的時候遇到了新問題,我的電腦cuda版本是11.1,而我安裝的pytorch cuda版本是cuda 11.0 的,所以編譯沒通過,解決辦法是安裝cuda 11.1的torch版本,這兩個版本要同步,torch離線包的網站有對應的whl檔案,下載下來重新安裝即可,如果這一步沒報錯的話,可以直接跳過這段話,
再然后安裝pycocotools,我這一步比較順利,直接通過:
pip3 install cython; pip3 install 'git+https://github.com/cocodataset/cocoapi.git#subdirectory=PythonAPI'
二、demo測驗
環境配置完后,來運行一下demo測驗,看看環境是否安裝成功,在hub中將權重檔案下載下來:
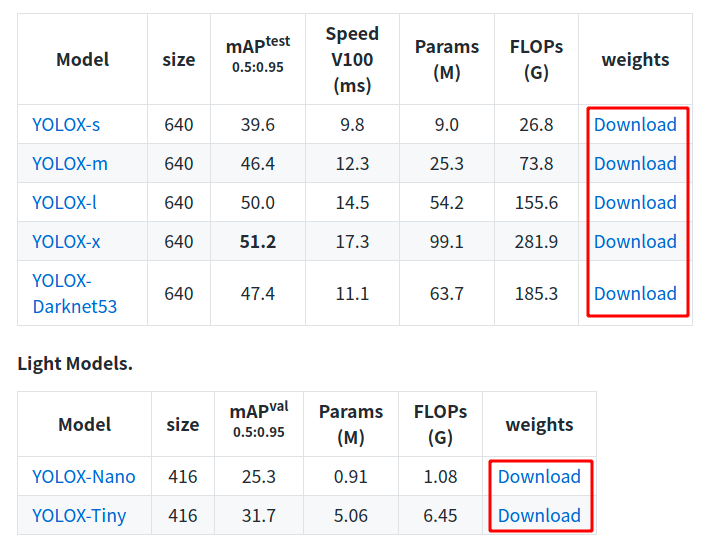
有點大,耐心等待,下載下來后我在YOLOX主目錄中創建了一個weights檔案夾,用于存放這些權重檔案,然后直接運行:
python tools/demo.py image -n yolox-s -c /path/to/your/yolox_s.pth.tar --path assets/dog.jpg --conf 0.3 --nms 0.65 --tsize 640 --save_result # 這是官方的示例
python tools/demo.py image -n yolox-s -c weights/yolox_s.pth.tar --path assets/bus.jpg --conf 0.3 --nms 0.65 --tsize 640 --save_result #這是我的
其中:
- image是推理模式,如果是輸入視頻則為video
- -n 是模型的名字
- -c 為權重檔案地址
- –path是測驗的圖片路徑
- –conf 置信度閾值
- –nms nms的iou閾值
- –tsize 測驗圖片大小
- –save_result 是否保存推理結果
運行成功示例如下(注意:他這里的demo代碼出錯了也不會報錯,直接跳出終止,所以如果你運行了發現沒有如下的運行結果,可能是程式終止了,需要自己排查,我在這里遇到的問題是img的張量cuda加載不上,后面排查是因為torch1.9的問題,就換了1.8,正如前面所說):

推理后的圖片保存在data檔案夾中,效果還不錯的樣子:

這步之后環境基本上沒問題了,接下來準備資料開始訓練吧,
三、資料準備和配置修改
官方配置教程
程式中提供了voc和coco兩種格式的資料訓練,我這里用的是voc格式訓練,voc格式的檔案結構如下:
├── data #手動創建data、VOCdevkit、VOC2007、Annotations、JPEGImages、ImageSets、Main這些檔案夾
│ ├── VOCdevkit
│ │ ├── VOC2007
│ │ │ ├── Annotations #把test.txt、trainval.txt對應的xml檔案放在這
│ │ │ ├── JPEGImages #把test.txt、trainval.txt對應的圖片放在這
│ │ │ ├── ImageSets
│ │ │ │ ├── Main
│ │ │ │ │ ├── test.txt
│ │ │ │ │ ├── trainval.txt
我的初始檔案夾只有兩個,通常標注完后只有這兩個檔案夾:
所以新建一個ImageSets檔案,并在其子目錄再新建一個Main檔案,然后運行如下代碼,劃分資料集,得到test.txt和trainval.txt檔案(路徑看著修改):
import os
import random
trainval_percent = 0.1
train_percent = 0.9
xmlfilepath = '/home/cai/data/VOCdevkit/VOC2007/Annotations'
txtsavepath = '/home/cai/data/VOCdevkit/VOC2007/ImageSets'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftest = open('/home/cai/data/VOCdevkit/VOC2007/ImageSets/test.txt', 'w')
ftrain = open('/home/cai/data/VOCdevkit/VOC2007/ImageSets/trainval.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftest.write(name)
else:
ftrain.write(name)
ftrain.close()
ftest.close()
要嚴格按照這個格式制作資料集,因為程式中是按照這個結構讀取,然后修改exps/example/yolox_voc/yolox_voc_s.py檔案三個地方,把你的類別和檔案路徑改過來,
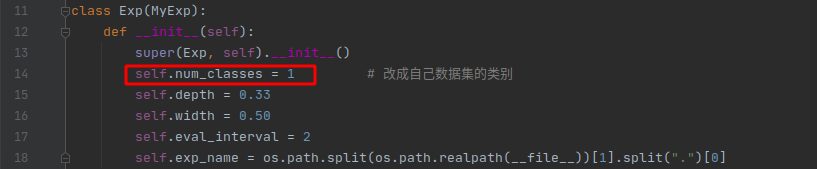
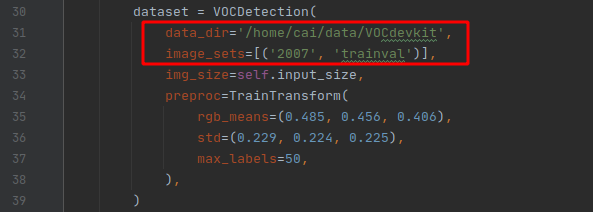
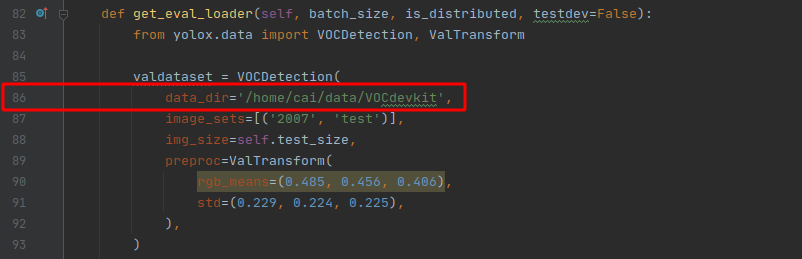
在我寫這篇文章的時候,這個檔案還有其他三個報錯的地方,如下:
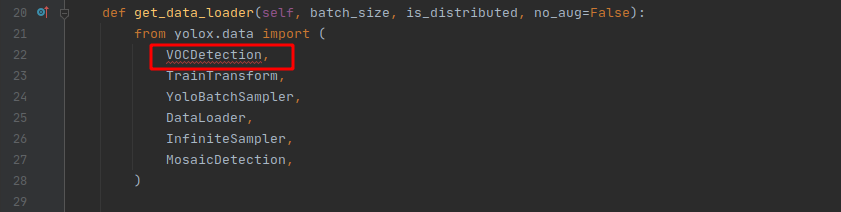
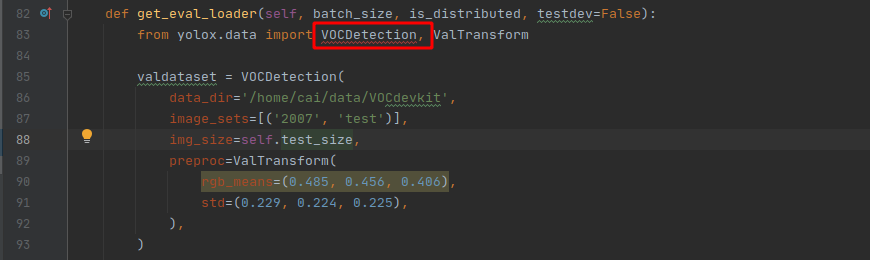
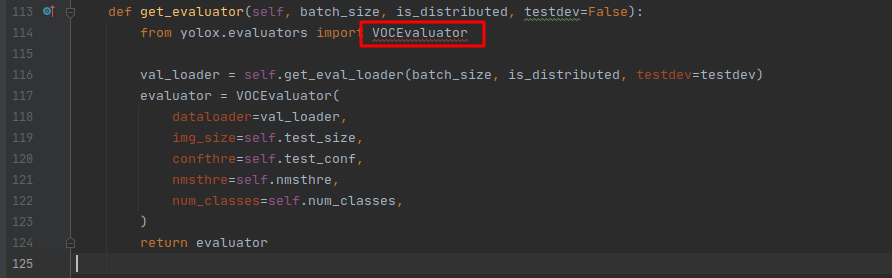
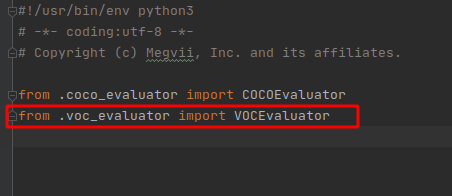
解決辦法分別在yolox/data/datasets/init.py、yolox/evaluators/init.py兩個檔案中添加:
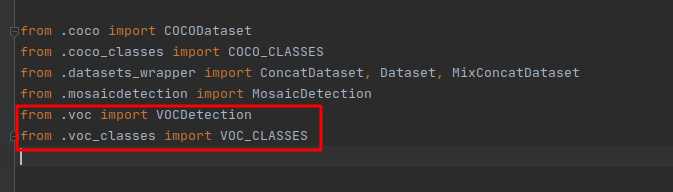
然后修改yolox/data/datasets/voc_classes.py,這里加上自己的類別,注釋掉原始類別:
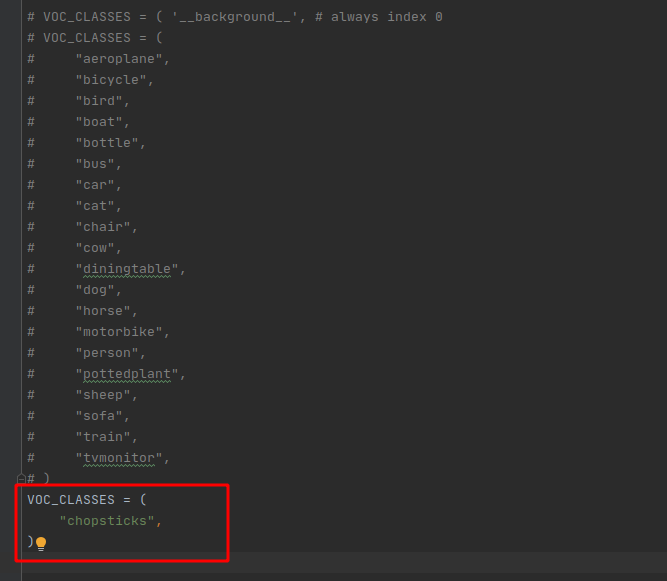
修改完過后直接運行如下命令開始訓練:
python tools/train.py -f exps/example/yolox_voc/yolox_voc_s.py -d 1 -b 16 --fp16 -o -c weights/yolox_s.pth.tar
- -d 使用多少張顯卡訓練
- -b 批次大小
- –fp16 是否開啟半精度訓練
yolox_voc_s.py檔案里的EXP類是繼承于yolox_base.py,有一些引數可以看著修改,運行過后進入如下界面開始訓練,列印了一堆的東西,我只截取了一部分:

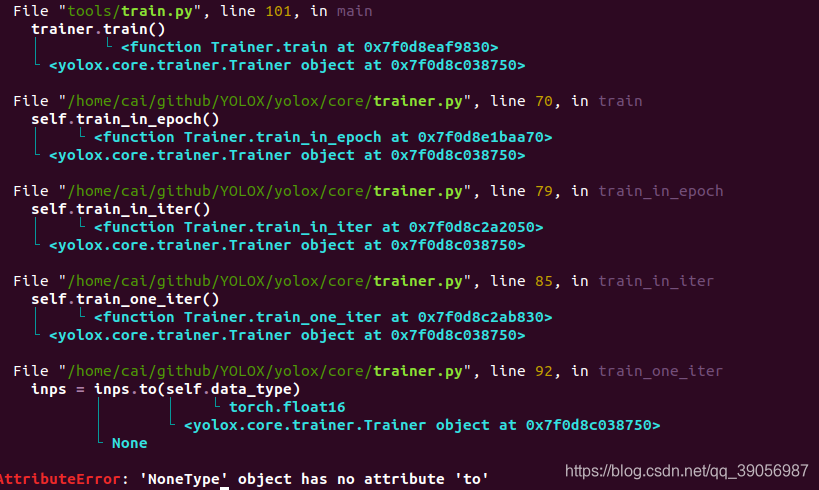
然后你可能會遇到這樣的問題,在迭代第二輪的時候迭代出來的內容為None,這時候需要去yolox/data/data_prefetcher.py檔案下修改:
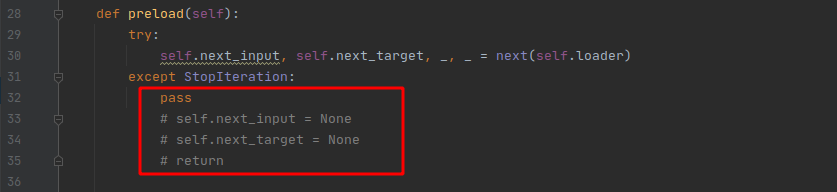
注釋掉后面三行,改為pass,然后繼續訓練,正常訓練后的輸出如下,每兩個輪次評估一次,可以在yolox_voc_s.py中修改self.eval_interval = 2來選擇,這里只用了兩百張左右的圖片訓練,可以看到收斂的速度非常的快,在兩輪后已經有這么高的精度了:
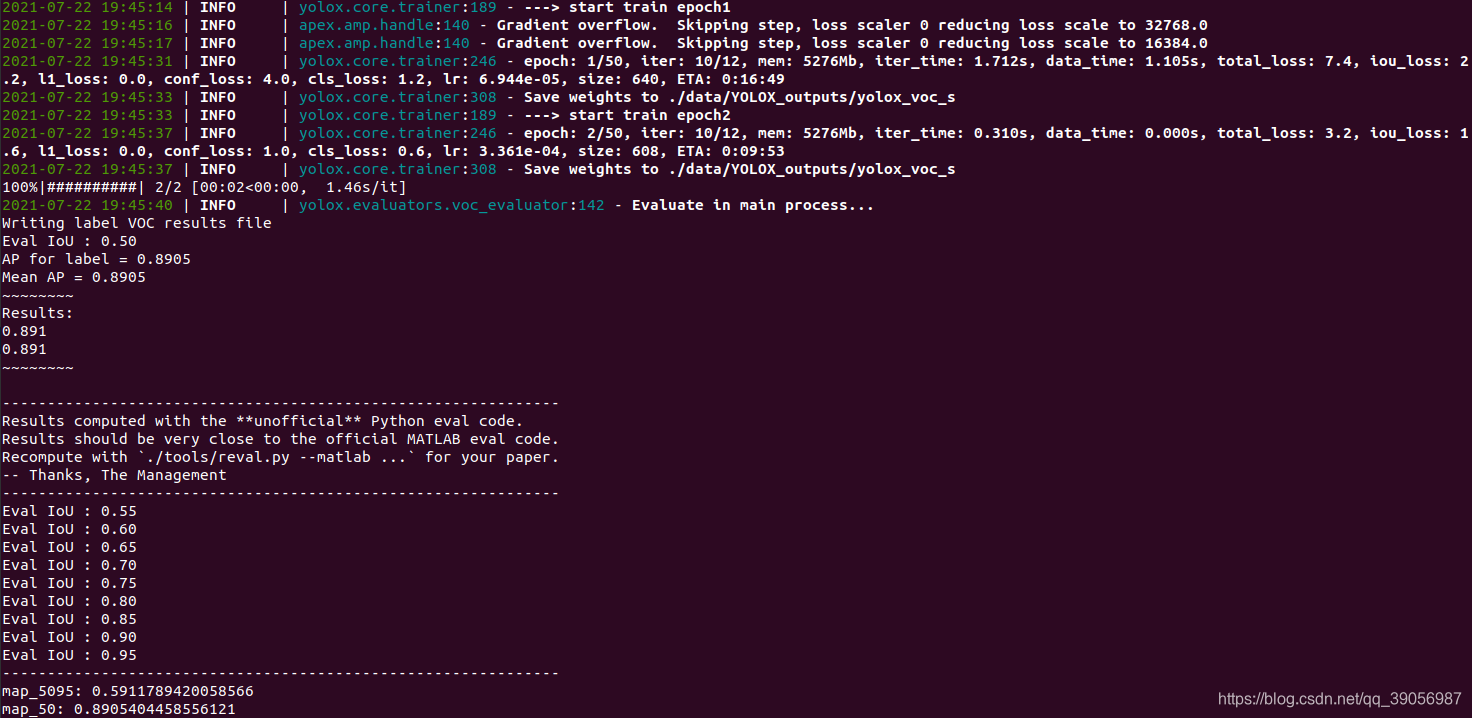
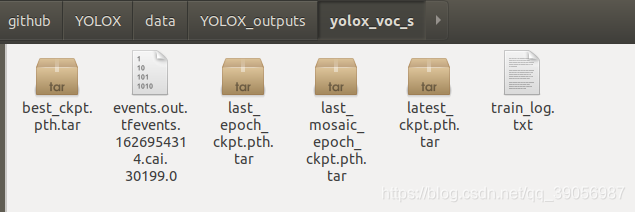
緊接著,模型訓練完后保存在data/YOLOX_outputs/yolox_voc_s檔案夾中,只需要best模型即可,因為這個模型保存的是最好的精度:
四、模型測驗
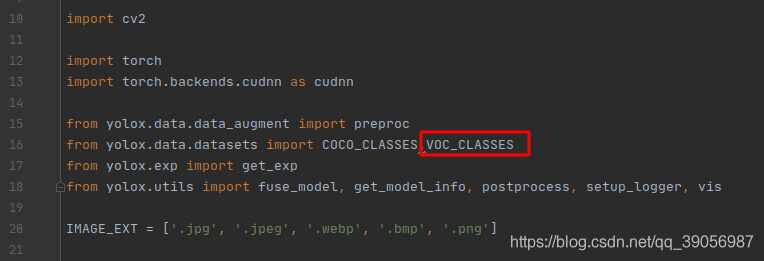
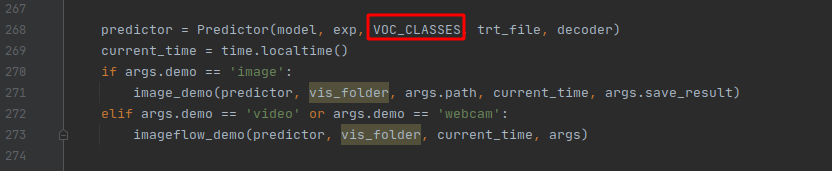
緊接著是測驗,同樣是運行之前的demo.py檔案,但是需要修改一下demo.py,匯入VOC_classes,然后修改可視化函式的傳參
修改exps/default/yolox_s.py檔案
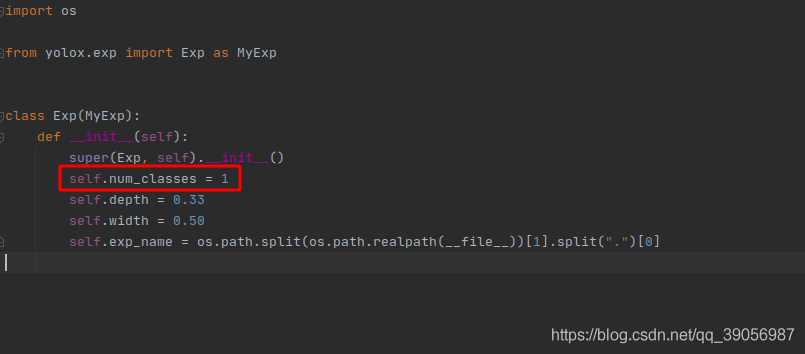
修改你的類別數,不加的話會按照默認的coco 80類初始化網路,然后訓練的權值無法加載會中斷程式,這里我把best的權重放到了weights檔案夾下,如果不修改運行后像這樣:

不報錯也不提示,坑爹啊

不過修改后就可以了,正確運行的界面如下,我們來看下我兩百張圖片訓練出來的效果,用的還是之前筷子的資料集:


效果感覺也還行吧,和v5s的效果差不多,精度也比較接近,總的來說,yolox也對得起這個名字,畢竟人家不僅開源了訓練代碼,部署的也給你放出來了,卷啊卷啊卷,,,只不過這個代碼,真是一堆的問題,差點給我整吐了,萬幸還是跑出來了,大家遇到問題的話需要耐心除錯,可以先去查yolox的issues,里面可能有你遇到的問題的解決方案,實在沒有的話只能print,
五、最后補充
因為是跑通了之后才寫的文章,有一些細節可能忘記加上去了,踩的坑有點多,遇到的問題也比較多,大部分都是比較容易解決的,我隱約感覺有一些修改的地方忘記寫上去了,如果是用我提供的筷子資料集訓練的話,可能會遇到這樣的問題,因為我的有一些標簽是通程序式生成的(之前的yolov5半標注),所以在xml檔案中沒有這兩個屬性:
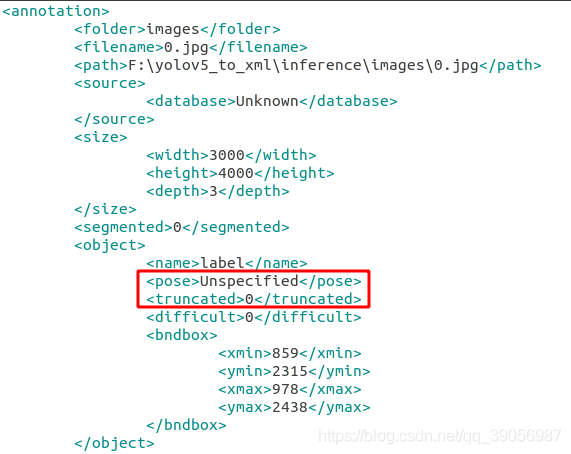
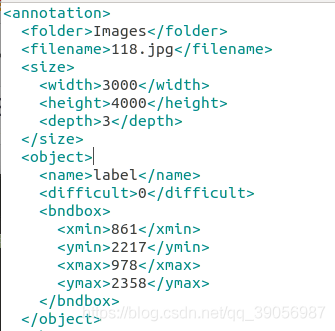
上面是用labelimg標注的標準xml檔案,下面是程式生成的,沒有pose和truncated屬性:
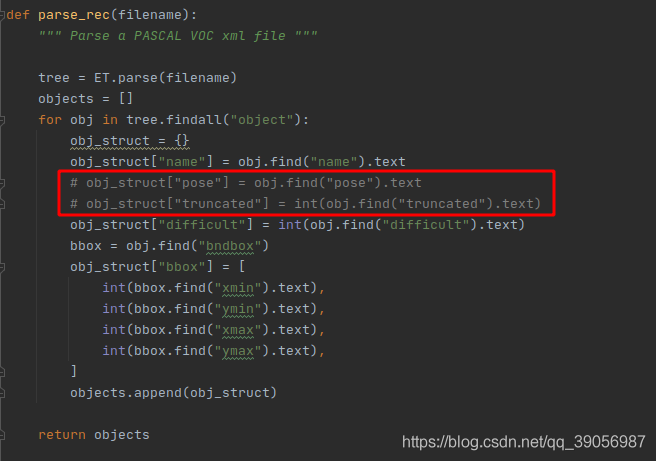
但是在yolox/evaluators/voc_eval.py中,決議xml的時候是有這兩個屬性的,我看了前后的代碼,發現這兩個屬性可有可無,所以如果報錯的話可以將其注釋掉:
寫的有點亂,但是大致的訓練程序就是這樣,中間大大小小的問題實在是太多了,記起來的都已經寫出來了,可能會有遺漏,演算法是好演算法,不過這個代碼在易用性上實在是有點不可恭維,希望后續作者能再優化好一些吧,

轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/289908.html
標籤:其他