目錄
- BeautifulSoup庫
- 安裝BeautifulSoup庫
- BeautifulSoup庫簡介
- 選擇解釋器
- 基礎用法
- 節點選擇器
- 獲取節點名稱屬性內容
- 獲取所有子節點
- 獲取所有子孫節點
- 父節點與兄弟節點
- 方法選擇器
- find_all()方法
- find()方法
- CSS選擇器
- 嵌套選擇節點
- 獲取屬性與文本
- 通過瀏覽器直接Copy-CSS選擇器
- 實戰:抓取酷狗飆升榜榜單
BeautifulSoup庫
雖然說XPath比正則運算式用起來方便,但是沒有最方便,只有更方便,我們的BeautifulSoup庫就能做到更方便的爬取想要的東西,
安裝BeautifulSoup庫
使用之前,還是老規矩,先安裝BeautifulSoup庫,指令如下:
pip install beautifulsoup4
其中文開發檔案:
https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html
BeautifulSoup庫簡介
BeautifulSoup庫是一個強大的Python語言的XML和HTML決議庫,它提供了一些簡單的函式來處理導航、搜索、修改分析樹等功能,
BeautifulSoup庫還能自動將輸入的檔案轉換為Unicode編碼,輸出檔案轉換為UTF-8編碼,
所以,在使用BeautifulSoup庫的程序中,不需要開發中考慮編碼的問題,除非你決議的檔案,本身就沒有指定編碼方式,這才需要開發中進行編碼處理,
下面,我們來詳細介紹BeautifulSoup庫的使用規則,
選擇解釋器
下面,我們來詳細介紹BeautifulSoup庫的重點知識,
首先,BeautifulSoup庫中一個重要的概念就是選擇解釋器,因為其底層依賴的全是這些解釋器,我們有必要認識一下,博主專門列出了一個表格:
| 解釋器 | 使用方式 | 優點 | 缺點 |
|---|---|---|---|
| Python標準庫 | BeautifulSoup(code,‘html.parser’) | Python的內置標準庫,執行速度適中,容錯能力強 | Python2.7.3以及Python3.2.2之前的版本容錯能力差 |
| lxml HTML決議器 | BeautifulSoup(code,‘lxml’) | 決議速度快,容錯能力強 | 需要安裝C語言庫 |
| lxml XML決議器 | BeautifulSoup(code,‘xml’) | 決議速度快,唯一支持XML的決議器 | 需要安裝C語言庫 |
| html5lib | BeautifulSoup(code,‘html5lib’) | 最好的容錯性,以瀏覽器的方式決議檔案,生成HTML5格式的檔案 | 決議速度慢 |
從上面表格觀察,我們一般爬蟲使用lxml HTML決議器即可,不僅速度快,而且兼容性強大,只是需要安裝C語言庫這一個缺點(不能叫缺點,應該叫麻煩),
基礎用法
要使用BeautifulSoup庫,需要和其他庫一樣進行匯入,但你雖然安裝的是beautifulsoup4,但匯入的名稱并不是beautifulsoup4,而是bs4,用法如下:
from bs4 import BeautifulSoup
soup = BeautifulSoup('<h1>Hello World</h1>', 'lxml')
print(soup.h1.string)
運行之后,輸出文本如下:

節點選擇器
基礎的用法很簡單,這里不在贅述,從現在開始,我們來詳細學習BeautifulSoup庫的所有重要知識點,第一個就是節點選擇器,
所謂節點選擇器,就是直接通過節點的名稱選擇節點,然后再用string屬性就可以得到節點內的文本,這種方式獲取最快,
比如,基礎用法中,我們使用h1直接獲取了h1節點,然后通過h1.string即可得到它的文本,但這種用法有一個明顯的缺點,就是層次復雜不適合,
所以,我們在使用節點選擇器之前,需要將檔案縮小,比如一個檔案很多很大,但我們獲取的內容只在id為blog的div中,那么我們先獲取這個div,再在div內部使用節點選擇器就非常合適了,
HTML示例代碼:
<!DOCTYPE html>
<html>
<head lang="en">
<meta charset="utf-8">
<title>我是一個測驗頁面</title>
</head>
<body>
<ul class="ul">
<li class="li1"><a href="https://liyuanjinglyj.blog.csdn.net/">我的主頁</a></li>
<li class="li2"><a href="https://www.csdn.net/">CSDN首頁</a></li>
<li class="li3"><a href="https://www.csdn.net/nav/python" class="aaa">Python板塊</a></li>
</ul>
</body>
</html>
下面的一些示例,我們還是使用這個HTML代碼進行節點選擇器的講解,
獲取節點名稱屬性內容
這里,我們先來教會大家如何獲取節點的名稱屬性以及內容,示例如下:
from bs4 import BeautifulSoup
with open('demo.html', 'r', encoding='utf-8') as f:
html = f.read()
soup = BeautifulSoup(html, 'lxml')
# 獲取節點的名稱
print(soup.title.name)
# 獲取節點的屬性
print(soup.meta.attrs)
print(soup.meta.attrs['charset'])
# 獲取節點的內容(如果檔案有多個相同屬性,默認獲取第一個)
print(soup.a.string)
# 也可以一層一層的套下去
print(soup.body.ul.li.a.string)
運行之后,效果如下:
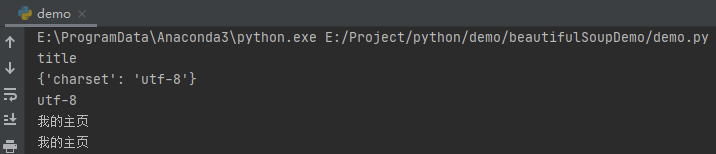
這里的注釋代碼都很詳細,就不在贅述,
獲取所有子節點
一般來說一個節點的子節點有可能很多,通過上面的方式獲取,只能得到第一個,如果要獲取一個標簽的所有子節點,這里有2種方式,先來看代碼:
from bs4 import BeautifulSoup
with open('demo.html', 'r', encoding='utf-8') as f:
html = f.read()
soup = BeautifulSoup(html, 'lxml')
# 獲取直接子節點
print("獲取直接子節點")
contents = soup.head.contents
print(contents)
for content in contents:
print(content)
children = soup.head.children
print(children)
for child in children:
print(child)
運行之后,效果如下:
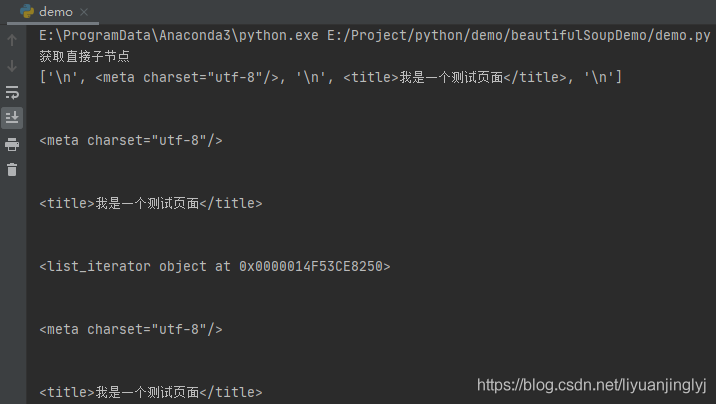
如上面代碼所示,我們有2種方式獲取所有子節點,一種是通過contents屬性,一種是通過children屬性,2者遍歷的結果都是一樣的,
但需要特別注意,這里獲取所有子節點,它是把換行符一起算進去了,所以你會看到控制臺輸出了很多空行,所以,在實際的爬蟲中,遍歷之時一定要洗掉這些空行,
獲取所有子孫節點
既然能獲取直接子節點,那么獲取所有子孫節點也是肯定可以的,BeautifulSoup庫給我們提供了descendants屬性獲取子孫節點,示例如下:
from bs4 import BeautifulSoup
with open('demo.html', 'r', encoding='utf-8') as f:
html = f.read()
soup = BeautifulSoup(html, 'lxml')
# 獲取ul的所有子孫節點
print('獲取ul的所有子孫節點')
lis = soup.body.ul.descendants
print(lis)
for li in lis:
print(li)
運行之后,效果如下:
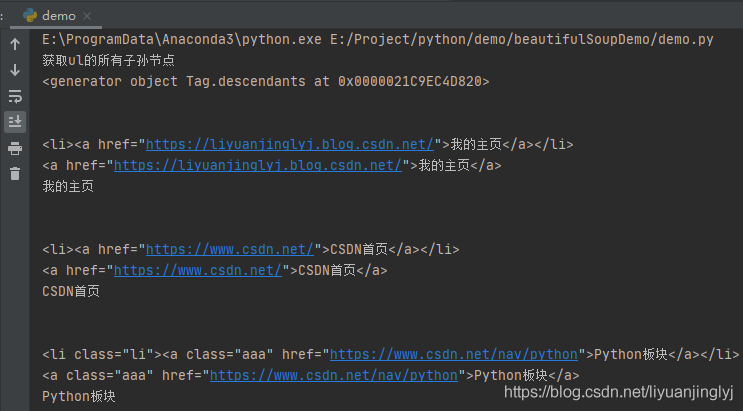
同樣的,descendants獲取子孫節點也算入了換行符,而且需要特別注意的是,descendants屬性把文本內容本身也算作子孫節點,
父節點與兄弟節點
同樣的,在實際的爬蟲程式中,我們有時候也需要通過逆向查找父節點,或者查找兄弟節點,
BeautifulSoup庫,給我們提供了parent屬性獲取父節點,同時提供了next_sibling屬性獲取當前節點的下一個兄弟節點,previous_sibling屬性獲取上一個兄弟節點,
示例代碼如下:
from bs4 import BeautifulSoup
with open('demo.html', 'r', encoding='utf-8') as f:
html = f.read()
soup = BeautifulSoup(html, 'lxml')
# 獲取第一個a標簽的父親節點的class屬性
print(soup.a.parent['class'])
li1 = soup.li
li3 = li1.next_sibling.next_sibling.next_sibling.next_sibling
li2 = li3.previous_sibling.previous_sibling
print(li1)
print(li2)
print(li3)
for sibling in li3.previous_siblings:
print(sibling)
運行之后,效果如下:
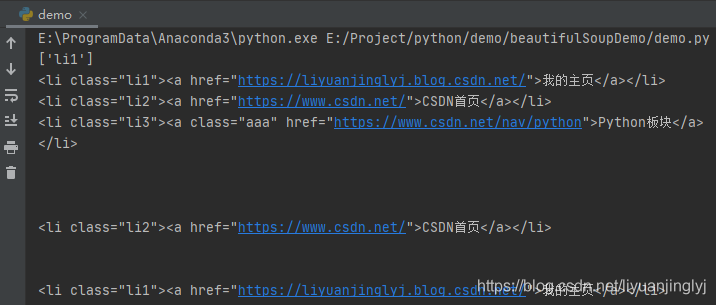
前面已經提示了,節點選擇器是把換行符‘\n’也算一個節點,所以第一個li需要通過兩個next_sibling才能獲取到下一個li節點,同樣的,上一個也是,其實還有一個更簡單的方法,能避免這些換行符被統計在內,那就是在獲取網頁源代碼的時候,直接去掉換行與空格即可,
方法選擇器
對于節點選擇器,博主已經介紹了相對于文本內容較少的完全可以這么做,但實際的爬蟲爬的網址都是大量的資料,開始使用節點選擇器就不合適了,所以,我們要考慮通過方法選擇器進行先一步的處理,
find_all()方法
find_all()方法主要用于根據節點的名稱、屬性、文本內容等選擇所有符合要求的節點,其完整的定義如下所示:
def find_all(self, name=None, attrs={}, recursive=True, text=None,
limit=None, **kwargs):
| 引數 | 意義 |
|---|---|
| name | 指定節點名稱 |
| attrs | 指定屬性名稱與值,比如查找value="text"的節點,attrs={“value”:“text”} |
| recursive | 布爾型別,值True查找子孫節點,值False直接子節點,默認為True |
| text | 指定需要查找的文本 |
| limit | 因為find_all回傳的是一個串列,所以可長可短,而limit與資料庫語法類似,限制獲取的數量,不設定回傳所有 |
【實戰】還是測驗上面的HTML,我們獲取name=a,attr={“class”:“aaa”},并且文本等于text="Python板塊"板塊的節點,
示例代碼如下所示:
from bs4 import BeautifulSoup
with open('demo.html', 'r', encoding='utf-8') as f:
html = f.read()
soup = BeautifulSoup(html.strip(), 'lxml')
a_list = soup.find_all(name='a', attrs={"class": 'aaa'}, text='Python板塊')
for a in a_list:
print(a)
運行之后,效果如下所示:

find()方法
find()與find_all()僅差一個all,但結果卻有2點不同:
- find()只查找符合條件的第一個節點,而find_all()是查找符合條件的所有節點
- find()方法回傳的是bs4.element.Tag物件,而find_all()回傳的是bs4.element.ResultSet物件
下面,我們來查找上面HTML中的a標簽,看看回傳結果有何不同,示例如下:
from bs4 import BeautifulSoup
with open('demo.html', 'r', encoding='utf-8') as f:
html = f.read()
soup = BeautifulSoup(html.strip(), 'lxml')
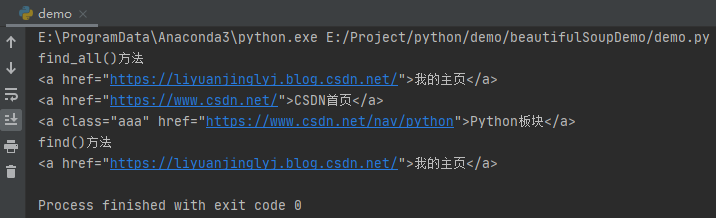
a_list = soup.find_all(name='a')
print("find_all()方法")
for a in a_list:
print(a)
print("find()方法")
a = soup.find(name='a')
print(a)
運行之后,效果如下:
CSS選擇器
首先,我們來了解一下CSS選擇器的規則:
- .classname:選取樣式名為classname的節點,也就是class屬性值是classname的節點
- #idname:選取id屬性為idname的節點
- nodename:選取節點名為nodename的節點
一般來說,在BeautifulSoup庫中,我們使用函式select()進行CSS選擇器的操作,示例如下:
from bs4 import BeautifulSoup
with open('demo.html', 'r', encoding='utf-8') as f:
html = f.read()
soup = BeautifulSoup(html.strip(), 'lxml')
li = soup.select('.li1')
print(li)
這里,我們選擇class等于li1的節點,運行之后,效果如下:

嵌套選擇節點
因為,我們需要實作嵌套CSS選擇器的用法,但上面的HTML不合適,這里,我們略作修改,僅僅更改<ul>標簽內的代碼,
<ul class="ul">
<li class="li"><a href="https://liyuanjinglyj.blog.csdn.net/">我的主頁</a></li>
<li class="li"><a href="https://www.csdn.net/">CSDN首頁</a></li>
<li class="li"><a href="https://www.csdn.net/nav/python" class="aaa">Python板塊</a>
</ul>
我們僅僅洗掉了li后面的數字,現在我們可以實作一個嵌套選擇節點的效果了,示例代碼如下所示:
from bs4 import BeautifulSoup
with open('demo.html', 'r', encoding='utf-8') as f:
html = f.read()
soup = BeautifulSoup(html.strip(), 'lxml')
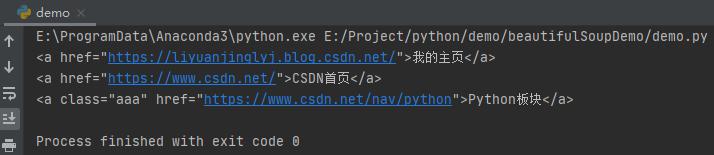
ul = soup.select('.ul')
for tag in ul:
a_list = tag.select('a')
for a in a_list:
print(a)
運行之后,效果如下:
獲取屬性與文本
我們再次將上面的代碼改造一下,因為上面獲取的標簽,現在我們來獲取其中的文本以及href屬性的值,示例如下:
from bs4 import BeautifulSoup
with open('demo.html', 'r', encoding='utf-8') as f:
html = f.read()
soup = BeautifulSoup(html.strip(), 'lxml')
ul = soup.select('.ul')
for tag in ul:
a_list = tag.select('a')
for a in a_list:
print(a['href'], a.get_text())
運行之后,效果如下:
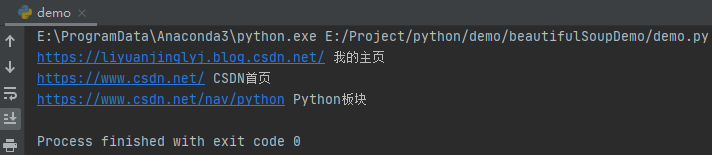
可以看到,我們通過[‘屬性名’]進行屬性值的獲取,通過get_text()獲取文本,
通過瀏覽器直接Copy-CSS選擇器
與XPath類似,我們可以直接通過F12瀏覽器進行Copy任何節點的CSS選擇器代碼,具體操作如下圖所示:
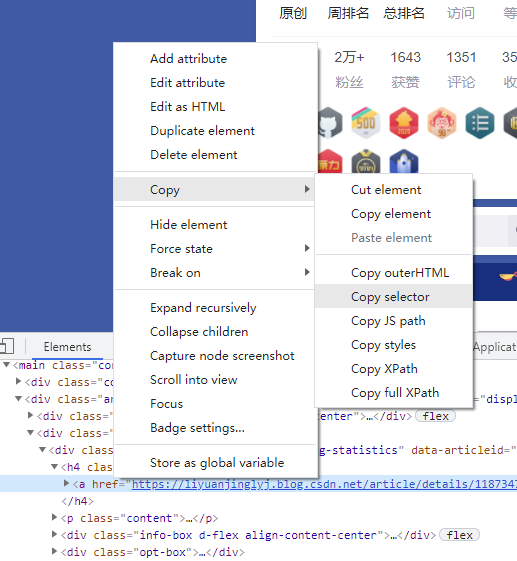

copy之后,直接將上面復制的內容粘貼到select()方法中即可使用,
實戰:抓取酷狗飆升榜榜單
上面基本上是BeautifulSoup庫的全部用法,既然我們已經學習掌握了,不抓緊爬點什么,總感覺自己很虧,所以我們選擇酷狗飆升榜榜單進行爬取,
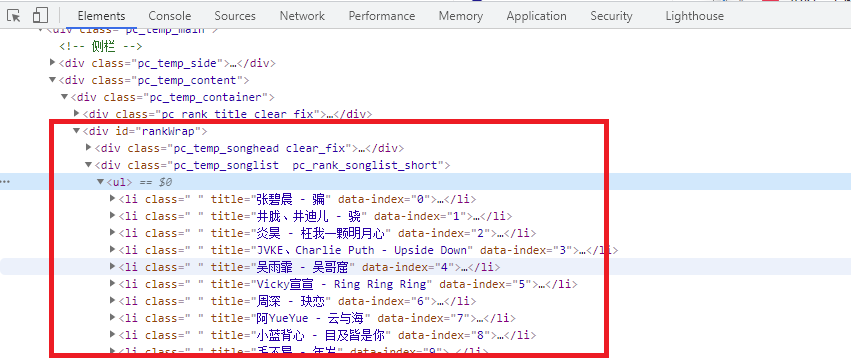
如上圖所示,我們的榜單資訊全在id="rankWrap"的div標簽下的ul之中,所以,首先我們必須獲取ul,示例代碼如下:
from bs4 import BeautifulSoup
import requests
url = "https://www.kugou.com/yy/html/rank.html"
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
result = requests.get(url=url, headers=headers)
print(result.text)
soup = BeautifulSoup(result.text.strip(), 'lxml')
ul = soup.select('#rankWrap > div.pc_temp_songlist.pc_rank_songlist_short > ul')
print(tbody)
獲取ul之后,我們就可以在獲取其中的所有li節點資訊,然后分解li的標簽,獲取重要的歌曲作者,歌曲名稱等,不過,我們先來分析網頁li內部代碼:
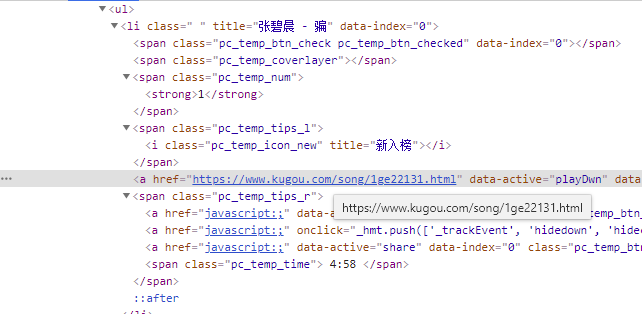
可以看到,我們要的歌曲名稱與作者就在li的title屬性中,而歌曲的網頁鏈接在li下,第4個span的標簽下的a節點的href屬性之中(也可以直接就是第一個a標簽之中),知道這些之后,我們可以完善代碼了,
from bs4 import BeautifulSoup
import requests
url = "https://www.kugou.com/yy/html/rank.html"
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
result = requests.get(url=url, headers=headers)
soup = BeautifulSoup(result.text.strip(), 'lxml')
ul = soup.select('#rankWrap > div.pc_temp_songlist.pc_rank_songlist_short > ul')
lis = ul[0].select('li')
for li in lis:
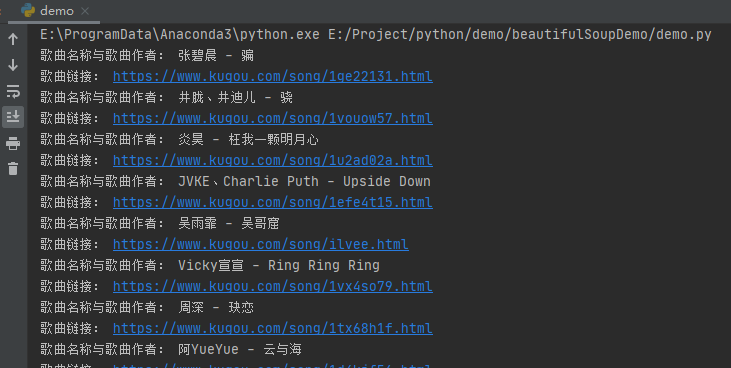
print("歌曲名稱與歌曲作者:", li['title'])
print("歌曲鏈接:", li.find('a')['href'])
如上面代碼所示,我們只用了不到14行代碼,就可以爬取酷狗音樂的飆升榜單,BeautifulSoup庫是不是非常的強大呢?
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/290130.html
標籤:其他
上一篇:C++內功修煉干貨,進大廠必須會的C++左值與右值,最適合小白看的文章!
下一篇:C語言之函式詳解