Deep Reinforcement Learning for List-wise Recommendations
文章目錄
- 1. 論文所解決的問題
- 2. 互動模型
- 3. 互動模擬器
- 3.1. 用在線資料構建存盤
- 3.2. 生成模擬資料
- 4. Actor-Critic框架
- 4.1. Actor網路
- 4.2. Critic網路
- 6. 訓練程序
- 6.1. 整體流程
- 6.2. 對Actor網路更新的說明
1. 論文所解決的問題
- 構建了一個在線的用戶-Agent互動環境模擬器,該模擬器適用于模擬在線推薦系統,以在離線的情況下對引數進行預訓練和評估;
- 提出了一個基于深度強化學習推薦框架:LIRD(LIst-wise Recommendation framework based on
Deep reinforcement learning),該框架適用于具有大型動態項空間的推薦場景,并可顯著地降低計算量; - 在真實的電子商務資料集中驗證了所提出框架的有效性,并驗證了串列式推薦對精準推薦的重要性,
2. 互動模型
LIRD演算法中用戶與推薦系統的互動模型是基于MDP模型建立的: M D P = ( S , A , P , R , γ ) MDP=(S,A,P,R,\gamma) MDP=(S,A,P,R,γ)主要包含以下幾個引數變數:
-
S
S
S: State space
S = { s 1 , s 2 , . . . , s t , . . . , s T } , s t = { s t 1 , s t 2 , . . . , s t N } S=\{s_1,s_2,...,s_t,...,s_T\},s_t=\{s_t^1,s_t^2,...,s_t^N\} S={s1?,s2?,...,st?,...,sT?},st?={st1?,st2?,...,stN?},即狀態空間,定義為用戶的歷史瀏覽記錄,即用戶在時間 t t t之前瀏覽的前 N N N個專案, s t s_t st?(session)中的瀏覽項按時間順序排序; -
A
A
A: Action space
A = { a 1 , a 2 , . . . , a t , . . . , a T } , a t = { a t 1 , a t 2 , . . . , a t K } A=\{a_1,a_2,...,a_t,...,a_T\},a_t=\{a_t^1,a_t^2,...,a_t^K\} A={a1?,a2?,...,at?,...,aT?},at?={at1?,at2?,...,atK?},即動作空間,是當前狀態 s t s_t st?向用戶推薦的推薦串列,其中 K K K是RA(Recommender Agent)每次推薦用戶的項的數量; -
R
R
R: Reward
R = r ( s t , a t ) R=r(s_t,a_t) R=r(st?,at?),即立即反饋值,RA在 s t s_t st?時推薦了專案串列 a t a_t at?后,即向用戶推薦專案串列后,用戶會瀏覽這些其中的專案并提供反饋,用戶可以跳過(不點擊)、點擊或訂購其中的專案,RA將根據用戶的反饋獲得立即反饋, -
P
P
P: Transition probability
P = p ( s t + 1 ∣ s t , a t ) P=p(s_{t+1}|s_t,a_t) P=p(st+1?∣st?,at?),即狀態轉移概率,定義為RA推薦專案串列 a t a_t at?后從狀態 s t s_t st?轉移到 s t + 1 s_{t+1} st+1?的概率, P P P滿足MDP的定義,即: P = p ( s t + 1 ∣ s t , a t , s t ? 1 , a t ? 1 . . . , s 1 , a 1 ) = p ( s t + 1 ∣ s t , a t ) P=p(s_{t+1}|s_t,a_t,s_{t-1},a_{t-1}...,s_1,a_1)=p(s_{t+1}|s_t,a_t) P=p(st+1?∣st?,at?,st?1?,at?1?...,s1?,a1?)=p(st+1?∣st?,at?)如果用戶在狀態 s t s_t st?時不點擊任何 a t a_t at?中的專案,則下一個狀態 s t + 1 = s t s_{t+1}=s_t st+1?=st?;如果用戶點擊、訂購專案串列 a t a_t at?中的專案,則下一個狀態 s t + 1 s_{t+1} st+1?將進行更新, -
γ
\gamma
γ: Discount factor
γ ∈ [ 0 , 1 ] \gamma\in[0,1] γ∈[0,1],即折扣因子,定義為對未來獎勵的現值的折扣系數,當 γ = 0 \gamma=0 γ=0時,RA只計算立即反饋;當 γ = 1 \gamma=1 γ=1時,未來所有的反饋都被完全計入在 a t a_t at?中,
3. 互動模擬器
說明:
互動模擬器用于模擬在線狀態時的用戶與推薦系統的互動資料,在線情況時,給定當前狀態
s
t
s_t
st?,RA(Recommender Agent)向用戶推薦一個專案串列
a
t
a_t
at?,用戶瀏覽對
a
t
a_t
at?中的專案
a
t
i
a_t^i
ati?做出反饋(跳過、點擊、訂購等),RA會根據用戶的反饋獲得立即反饋
r
(
s
t
,
a
t
)
r(s_t,a_t)
r(st?,at?),模擬在線情況時,可以根據當前狀態和選定的行動來預測獎勵,然后將
s
t
,
a
t
,
r
t
s_t,a_t,r_t
st?,at?,rt?存盤起來,
3.1. 用在線資料構建存盤
演算法1 構建在線模擬器的存盤
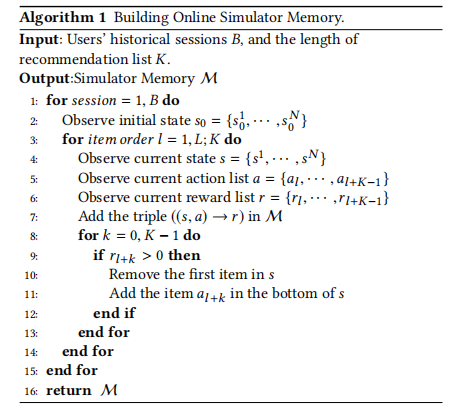
符號解釋:
- M M M: M = { m 1 , m 2 , . . . , m i , . . . } M=\{m_1,m_2,...,m_i,...\} M={m1?,m2?,...,mi?,...},存盤,來存盤用戶的歷史瀏覽歷史,每一個 m i m_i mi?都代表了一個互動元組 ( ( s i , a i ) → r i ) ((s_i,a_i)\to r_i) ((si?,ai?)→ri?);
- B B B: B = { a 1 , a 2 , . . . , a L } B=\{a_1,a_2,...,a_L\} B={a1?,a2?,...,aL?},用戶會話記錄集合(論文中是這樣寫的,按道理應該是 ( s 0 , s 1 , s 2 , . . . ) (s_0,s_1,s_2,...) (s0?,s1?,s2?,...));
- s 0 s_0 s0?: s 0 = { s 0 1 , s 0 2 , . . . , s 0 N } s_0=\{s_0^1,s_0^2,...,s_0^N\} s0?={s01?,s02?,...,s0N?},用戶過去的會話記錄,即用戶在過去會話中曾經瀏覽、點擊、購買過的物品,可能為空(如果是新用戶),也可能已經有記錄(之前會話留下的記錄),簡單來說,當前狀態 s s s之前的所有狀態全部可以視作初始狀態 s 0 s_0 s0?;
- s s s: s = { s 1 , s 2 , . . . , s L } ∈ B s=\{s^1,s^2,...,s^L\}\in B s={s1,s2,...,sL}∈B,用戶當前的會話記錄,即用戶在當前會話瀏覽、點擊、購買過的物品,大小固定為 L L L,只能存盤近期的記錄,在會話開始時, s = s 0 s=s_0 s=s0?,隨著用戶與系統的互動逐漸更新;
- K K K:即推薦串列長度,它在 s s s中以滑動視窗的形式讀取用戶歷史會話記錄;
- a a a: a = { a L , a L + 1 , . . . , a L + i , . . . a L + K ? 1 } a=\{a_L,a_{L+1},...,a_{L+i},...a_{L+K-1}\} a={aL?,aL+1?,...,aL+i?,...aL+K?1?},推薦串列,其中 a L + k a_{L+k} aL+k?代表推薦串列中的一個推薦項,用戶可以對它做出瀏覽、點擊、購買等行為,同時會產生對應的反饋值,之所以是從 a L a_L aL?開始是因為在過去的會話,隨著用戶與推薦串列 a a a中推薦項的互動, a L + k a_{L+k} aL+k?會逐個追加到 s s s中;
- r r r: r = { r L , r L + 1 , . . . r L + k , . . . r L + K ? 1 } r=\{r_L,r_{L+1},...r_{L+k},...r_{L+K-1}\} r={rL?,rL+1?,...rL+k?,...rL+K?1?},反饋值串列,其中 r L + k r_{L+k} rL+k?代表對應推薦項 a L + k a_{L+k} aL+k?的反饋值,
輸入:
- 用戶的歷史會話 B B B
- 推薦串列的長度 K K K
輸出:
- 在線資料存盤 M M M
流程:
- 回圈 取出 B B B中的每一個會話 s e s s i o n = 1 , . . . , B session=1,...,B session=1,...,B:
- \qquad 觀測先前會話的初始狀態 s 0 = { s 0 1 , s 0 2 , . . . , s 0 N } s_0=\{s_0^1,s_0^2,...,s_0^N\} s0?={s01?,s02?,...,s0N?}
- \qquad 回圈 按時間順序觀測 K K K個專案, K K K是 l l l上的滑動視窗:
- \qquad\qquad 觀測當前狀態串列 s = { s 1 , s 2 , . . . , s N } s=\{s^1,s^2,...,s^N\} s={s1,s2,...,sN}
- \qquad\qquad 觀測當前的專案 a = { a l , a l + 1 , . . . , a l + K ? 1 } a=\{a_l,a_{l+1},...,a_{l+K-1}\} a={al?,al+1?,...,al+K?1?}
- \qquad\qquad 觀測當前專案的反饋值 r = { r l , r l + 1 , . . . , r l + K ? 1 } r=\{r_l,r_{l+1},...,r_{l+K-1}\} r={rl?,rl+1?,...,rl+K?1?},該反饋值只用于選取 a l + k a_{l+k} al+k?,不是推薦串列的反饋值,
- \qquad\qquad 將元組 ( ( s , a ) → r ) ((s,a)\to r) ((s,a)→r)存盤在 M M M中
- \qquad\qquad 回圈 獲取每一個推薦項 a l + k a_{l+k} al+k?和對應反饋項 r l + k r_{l+k} rl+k? , k = 1 , , , . K ? 1 ,k=1,,,.K-1 ,k=1,,,.K?1:
- \qquad\qquad\qquad 若 r l + k > 0 r_{l+k}>0 rl+k?>0,即用戶對推薦項 a l + k a_{l+k} al+k?產生了行為:
- \qquad\qquad\qquad\qquad 移除 s s s的第一個元素
- \qquad\qquad\qquad\qquad 向 s s s的末尾追加專案 a l + k a_{l+k} al+k?
- 回傳 M M M
3.2. 生成模擬資料
在線環境下,RA可以直接從用戶與推薦串列的互動中獲取反饋值,但是在模擬資料中如何獲取反饋值呢?一個簡單辦法是通過計算模擬生成的“狀態-動作對”與存盤 M M M中已存在的“狀態-動作對”的相似度來選取的,
為了計算模擬生成的 ( s t , a t ) (s_t,a_t) (st?,at?)對與 M M M中的每對 ( s i , a i ) (s_i,a_i) (si?,ai?)對的相似性 模擬生成的“狀態-動作對”: p t ( s t , a t ) \text{模擬生成的“狀態-動作對”:}p_t(s_t,a_t) 模擬生成的“狀態-動作對”:pt?(st?,at?) 在線存盤的“狀態-動作對”: m i ( ( s i , a i ) → r i ) \text{在線存盤的“狀態-動作對”:}m_i((s_i,a_i)\to r_i) 在線存盤的“狀態-動作對”:mi?((si?,ai?)→ri?)采用余弦相似度對 p t p_t pt?和 m i m_i mi?的相似度進行計算: C o s i n e ( p t , m i ) = α s t s i T ∥ s t ∥ ∥ s i ∥ + ( 1 ? α ) a t a i T ∥ a t ∥ ∥ a i ∥ Cosine(p_t,m_i)=\alpha\frac{s_ts_i^T}{\Vert s_t\Vert\Vert s_i \Vert}+(1-\alpha)\frac{a_ta_i^T}{\Vert a_t\Vert\Vert a_i \Vert} Cosine(pt?,mi?)=α∥st?∥∥si?∥st?siT??+(1?α)∥at?∥∥ai?∥at?aiT??前一項評估狀態相似度,后一項評估動作相似度,引數 α \alpha α控制兩個相似度的權重, p t p_t pt?與 m i m_i mi?越相似, p t p_t pt?能獲得對應反饋值 r t r_t rt?的概率越高,可以用以下公式將 p t p_t pt?映射到 r i r_i ri?: P ( p t → r i ) = C o s i n e ( p t , m i ) ∑ m j ∈ M C o s i n e ( p t , m j ) P(p_t\to r_i)=\frac{Cosine(p_t,m_i)}{\sum_{m_j\in M}Cosine(p_t,m_j)} P(pt?→ri?)=∑mj?∈M?Cosine(pt?,mj?)Cosine(pt?,mi?)?
要注意的是,這里的映射概率并不是獨立的,而是合并的,也就是說,計算出所有的 P = { P ( p 1 → r 1 ) , . . . , P ( p t → r i ) , . . . } P=\{P(p_1\to r_1),...,P(p_t\to r_i),...\} P={P(p1?→r1?),...,P(pt?→ri?),...}后,其和 ∑ P = 1 \sum P=1 ∑P=1(想象一個餅狀圖),總有一個 r i r_i ri?會被選到, P ( p t → r i ) P(p_t\to r_i) P(pt?→ri?)越大越容易被選到,
為了降低 P ( p t → r i ) P(p_t\to r_i) P(pt?→ri?)的計算復雜度,論文不直接把 p t p_t pt?映射到單個 m i m_i mi?的反饋值,而是映射到反饋值的分組 U x \mathcal{U}_x Ux?,
這樣做的好處顯而易見,例如現在有有一個大小為2的推薦串列,用戶跳過/點擊/訂購推薦項的獎勵分別為0、1、5,如果每次都向具體的反饋值映射,則映射的總數為 2 M 2 M 2M,而向分組映射時映射的總數為 9 9 9, 9 < < 2 M 9<<2M 9<<2M: U = { U 1 , U 2 , . . . U x , . . . U 9 } = { ( 0 , 0 ) , ( 1 , 0 ) , ( 0 , 1 ) , ( 1 , 1 ) , ( 5 , 0 ) , ( 0 , 5 ) , ( 1 , 5 ) , ( 5 , 1 ) , ( 5 , 5 ) } \mathcal{U}=\{\mathcal{U}_1,\mathcal{U}_2,...\mathcal{U}_x,...\mathcal{U}_9\}=\{(0,0),(1,0),(0,1),(1,1),(5,0),(0,5),(1,5),(5,1),(5,5)\} U={U1?,U2?,...Ux?,...U9?}={(0,0),(1,0),(0,1),(1,1),(5,0),(0,5),(1,5),(5,1),(5,5)}
將 p t p_t pt?映射到 U x \mathcal{U}_x Ux?的計算公式為: P ( p t → U x ) = ∑ r i ∈ U x C o s i n e ( p t , m i ) ∑ m j ∈ M C o s i n e ( p t , m j ) = N x ( α s t s x ? T ∥ s t ∥ + ( 1 ? α ) a t a x ? T ∥ a t ∥ ) ∑ U y ∈ U N y ( α s t s y ? T ∥ s t ∥ + ( 1 ? α ) a t a y ? T ∥ a t ∥ ) P(p_t\to \mathcal{U}_x)=\frac{\sum_{r_i\in \mathcal{U}_x}Cosine(p_t,m_i)}{\sum_{m_j\in M}Cosine(p_t,m_j)}=\frac{\mathcal{N}_x(\alpha\frac{s_t{s^-_x}^T}{\Vert s_t\Vert}+(1-\alpha)\frac{a_t{a^-_x}^T}{\Vert a_t\Vert})}{\sum_{\mathcal{U}_y\in\mathcal{U}}\mathcal{N}_y(\alpha\frac{s_t{s^-_y}^T}{\Vert s_t\Vert}+(1-\alpha)\frac{a_t{a^-_y}^T}{\Vert a_t\Vert})} P(pt?→Ux?)=∑mj?∈M?Cosine(pt?,mj?)∑ri?∈Ux??Cosine(pt?,mi?)?=∑Uy?∈U?Ny?(α∥st?∥st?sy??T?+(1?α)∥at?∥at?ay??T?)Nx?(α∥st?∥st?sx??T?+(1?α)∥at?∥at?ax??T?)?
其中, N x \mathcal{N}_x Nx?是指具有 r = U x r=\mathcal{U}_x r=Ux?的用戶的歷史瀏覽歷史記錄組的大小; s x ? s^-_x sx??和 a x ? a^-_x ax??是 r = U x r=\mathcal{U}_x r=Ux?的平均狀態向量和平均動作向量: s x ? = 1 N x ∑ r i = U x s i ∥ s i ∥ , a x ? = 1 N x ∑ r i = U x a i ∥ a i ∥ s^-_x=\frac{1}{\mathcal{N}_x}\sum_{r_i=\mathcal{U}_x}\frac{s_i}{\Vert s_i\Vert},\quad a^-_x=\frac{1}{\mathcal{N}_x}\sum_{r_i=\mathcal{U}_x}\frac{a_i}{\Vert a_i\Vert} sx??=Nx?1?ri?=Ux?∑?∥si?∥si??,ax??=Nx?1?ri?=Ux?∑?∥ai?∥ai??在實際操作中, N x \mathcal{N}_x Nx?、 s x ? s^-_x sx??和 a x ? a^-_x ax??每1000個episodes更新一次,
為了把得到的反饋值向量 P ( p t → U x ) P(p_t\to \mathcal{U}_x) P(pt?→Ux?)轉換為對推薦串列 a t a_t at?的具體反饋值,可以用下列公式進行計算: r t = ∑ k = 1 K Γ k ? 1 U x k r_t=\sum_{k=1}^{K}\Gamma^{k-1}\mathcal{U}_x^k rt?=k=1∑K?Γk?1Uxk?其中, k k k是推薦串列中推薦項的順序; Γ ∈ ( 0 , 1 ] \Gamma\in(0,1] Γ∈(0,1],顯然,由于 Γ \Gamma Γ的存在,推薦串列前部的推薦項對整體的反饋值會有更高的貢獻,這使得RA更容易在推薦串列的前部向用戶推薦高反饋值的推薦項,
到此,由 p t ( s t , a t ) → r t p_t(s_t,a_t)\to r_t pt?(st?,at?)→rt?就可以組成一條模擬資料 ( s t , a t , r t ) (s_t,a_t,r_t) (st?,at?,rt?)了,
4. Actor-Critic框架
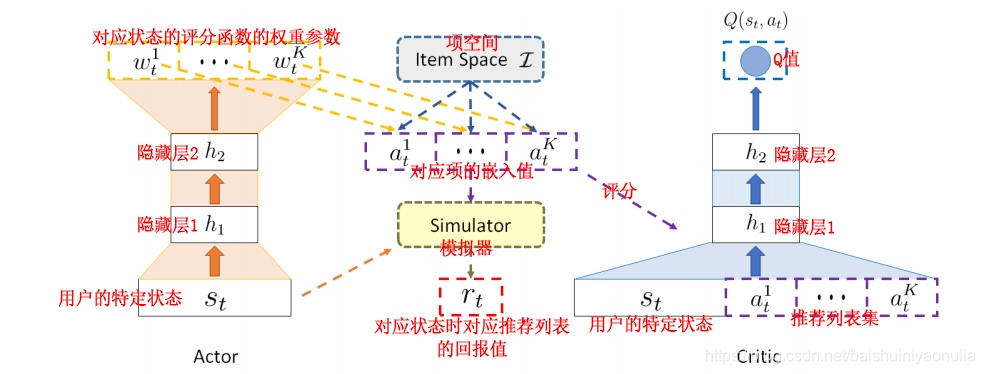
4.1. Actor網路
說明:
Actor網路是一個串列型的項推薦程式,它括兩個部分,即:
- 生成特定狀態的評分函式引數
評分函式用于根據用戶當前的特定狀態(有過動作的推薦項記錄,例如點擊、購買等)對推薦項進行評分,Actor網路用于生成評分函式的引數, - 生成推薦動作,
演算法2 串列型項推薦演算法

符號解釋:
- f θ π f_{\theta^\pi} fθπ?: f θ π : s t → w t f_{\theta^\pi}:s_t\to w_t fθπ?:st?→wt?,即Actor,是一個神經網路,用于根據用戶當前的特定狀態 s t s_t st?生成評分函式的權重引數 w t w_t wt?向量( w t w_t wt?就是 s t s_t st?中每一個元素的Q值向量); θ π \theta^\pi θπ是神經網路的引數;
- s o c r e i socre_i socrei?: s o c r e i = w t k e i T socre_i=w_t^ke_i^T socrei?=wtk?eiT?,項 i i i的評分, w t k w_t^k wtk?是指狀態 s t s_t st?時推薦項 i i i對應的第 k k k個權重引數(由 f θ π f_{\theta^\pi} fθπ?生成); e i e_i ei?是項空間 I I I中第 i i i個推薦項的嵌入值( e i e_i ei?的維度與 s t s_t st?相同); T T T是轉置的意思,
輸入:
- 當前的特定狀態 s t s_t st?
- 項空間(動作空間) I I I
- 推薦串列的長度 K K K
輸出:
- 特定狀態 s t s_t st?時的推薦串列 a t a_t at?
流程:
- 由 f θ π f_{\theta^\pi} fθπ?根據 s t s_t st?生成權重向量串列 w t = { w t 1 , . . . , w t K } w_t=\{w_t^1,...,w_t^K\} wt?={wt1?,...,wtK?}
- 回圈 k = 1 , . . . , K k=1,...,K k=1,...,K:
- \qquad 對 I I I中的所有項 i i i進行評分
- \qquad 選擇評分 s o c r e i socre_i socrei?最高的專案 a l k a_l^k alk?
- \qquad 將專案 a l k a_l^k alk?追加到推薦串列 a t a_t at?中
- \qquad 從 I I I中去除 a l k a_l^k alk?
- 回傳 推薦串列 a t a_t at?
4.2. Critic網路
Critic網路用于學習 Q ( s t , a t ) Q(s_t,a_t) Q(st?,at?),該Q值用于判斷Actor產生的動作 a t a_t at?是否與當前狀態 s t s_t st?相匹配,然后,根據Q值更新Actor的引數,改進Actor以生成更佳的動作,
由于Actor網路已經提供了確定性的 a t a_t at?,因此Critic網路計算Q值的公式為: Q ( s t , a t ) = E s t + 1 [ r t + γ Q ( s t + 1 , a t + 1 ) ∣ s t , a t ] Q(s_t,a_t)=\mathbb{E}_{s_{t+1}}[r_t+\gamma Q(s_{t+1},a_{t+1})|s_t,a_t] Q(st?,at?)=Est+1??[rt?+γQ(st+1?,at+1?)∣st?,at?]即Q值為持續利用Actor生成 a t a_t at?所獲得的 r t r_t rt?的折扣期望值,該Q值將用于 f θ π f_{\theta^\pi} fθπ?的引數更新,
在論文中,用神經網路來擬合Q值(DQN),即有: Q ( s t , a t ) ≈ Q ( s t , a t ; θ μ ) = = E s t + 1 [ r t + γ Q ( s t + 1 , a t + 1 ; θ μ ) ∣ s t , a t ] Q(s_t,a_t)\approx Q(s_t,a_t;\theta^\mu)==\mathbb{E}_{s_{t+1}}[r_t+\gamma Q(s_{t+1},a_{t+1};\theta^\mu)|s_t,a_t] Q(st?,at?)≈Q(st?,at?;θμ)==Est+1??[rt?+γQ(st+1?,at+1?;θμ)∣st?,at?]其中, θ μ \theta^\mu θμ是DQN神經網路的引數,DQN的損失函式定義如下: L ( θ μ ) = E s t , a t , r t , s t + 1 [ ( y t ? Q ( s t , a t ; θ μ ) 2 ) ] L(\theta^\mu)=\mathbb{E}_{s_t,a_t,r_t,s_{t+1}}[(y_t-Q(s_t,a_t;\theta^\mu)^2)] L(θμ)=Est?,at?,rt?,st+1??[(yt??Q(st?,at?;θμ)2)]在實踐中使用隨機梯度下降法來優化損失函式 L ( θ μ ) L(\theta^\mu) L(θμ),在優化損失函式的時候,引數 θ μ \theta^\mu θμ會被更新,
在 L ( θ μ ) L(\theta^\mu) L(θμ)中, y t y_t yt?是每次迭代時的目標價值(目標Critic網路的Q值): y t = E s t + 1 [ r t + γ Q ′ ( s t + 1 , a t + 1 ; θ μ ′ ) ∣ s t , a t ] y_t=\mathbb{E}_{s_{t+1}}[r_t+\gamma Q'(s_{t+1},a_{t+1};{\theta^\mu}')|s_t,a_t] yt?=Est+1??[rt?+γQ′(st+1?,at+1?;θμ′)∣st?,at?]之所以 y t y_t yt?選用目標網路進行計算,是因為 Q ′ Q' Q′網路由 Q Q Q網路更新而來,在計算損失函式時引數 θ μ \theta^\mu θμ的差異不至于過大,可以讓 Q Q Q網路的更新更加穩定,使得收斂方向更加確定,
6. 訓練程序
6.1. 整體流程
演算法3. 使用DDPG演算法對所提出的DEV框架進行引數訓練的程序

符號解釋:
- M M M: M = { m 1 , m 2 , . . . , m i , . . . } M=\{m_1,m_2,...,m_i,...\} M={m1?,m2?,...,mi?,...},存盤,來存盤用戶的歷史瀏覽歷史,每一個 m i m_i mi?都代表了一個互動元組 ( ( s i , a i ) → r i ) ((s_i,a_i)\to r_i) ((si?,ai?)→ri?);
- s 0 s_0 s0?: s 0 = { s 0 1 , s 0 2 , . . . , s 0 N } s_0=\{s_0^1,s_0^2,...,s_0^N\} s0?={s01?,s02?,...,s0N?},用戶過去的會話記錄,即用戶在過去會話中曾經瀏覽、點擊、購買過的物品,可能為空(如果是新用戶),也可能已經有記錄(之前會話留下的記錄),簡單來說,當前狀態 s s s之前的所有狀態全部可以視作初始狀態 s 0 s_0 s0?;
- T T T:會話內所經歷的時間步;
- K K K:推薦串列的長度;
- N N N:是minibatch中資料量的大小,也指時間步的數量,也指訓練時episode的數量;
- τ \tau τ: τ = 0.001 \tau=0.001 τ=0.001,是更新目標Actor和Critic網路時平衡之前網路引數與更新引數之間的權重
初始化:
- 隨機初始化actor網路 f θ π f_{\theta^\pi} fθπ?和critic網路 Q ( s , a ∣ θ μ ) Q(s,a|\theta^\mu) Q(s,a∣θμ)的權重;
- 使用 f θ π f_{\theta^\pi} fθπ?和 Q ( s , a ∣ θ μ ) Q(s,a|\theta^\mu) Q(s,a∣θμ)的權值初始化目標網路 f ′ f' f′和 Q ′ Q' Q′;
- 初始化回放池 D D D的容量
流程:
- 回圈 獲取 M M M中的每一個會話, s e s s i o n = 1 , M session=1,M session=1,M:
- \qquad 重置項空間 I I I
- \qquad 從先前的會話中初始化初始狀態 s 0 s_0 s0?
- \qquad 回圈 獲取會話中的每一個時間步 t = 1 , T t=1,T t=1,T:
- \qquad\qquad 階段1:狀態轉移生成階段
- \qquad\qquad 根據演算法二選擇動作(推薦串列) a t = { a t 1 , . . . , a t K } a_t=\{a_t^1,...,a_t^K\} at?={at1?,...,atK?}
- \qquad\qquad 向用戶展示推薦串列 a t a_t at?,并且獲得其中每一個推薦項的反饋值,組成反饋串列 { r t 1 , . . . , r t K } \{r_t^1,...,r_t^K\} {rt1?,...,rtK?},該反饋值串列只用于選取 a l k a_l^k alk?,不是推薦串列 a t a_t at?的反饋值,
- \qquad\qquad 初始化下一個狀態的值 s t + 1 = s t s_{t+1}=s_t st+1?=st?
- \qquad\qquad 回圈 獲取每一個推薦項 a t k a_t^k atk?和對應反饋項 r t k r_t^k rtk?,k=1,K:
- \qquad\qquad\qquad 若 反饋值 r t k > 0 r_t^k>0 rtk?>0,即用戶對推薦項 a t k a_t^k atk?產生了行為
- \qquad\qquad\qquad\qquad 在 s t + 1 s_{t+1} st+1?中追加 a t k a_t^k atk?
- \qquad\qquad\qquad\qquad 移除 s t + 1 s_{t+1} st+1?的首位元素
- \qquad\qquad 根據 s t s_t st?和 a t a_t at?計算推薦串列的反饋值 r t r_t rt?
- \qquad\qquad 在 D D D中存盤狀態轉移 ( s t , a t , r t , s t + 1 ) (s_t,a_t,r_t,s_{t+1}) (st?,at?,rt?,st+1?)
- \qquad\qquad 轉移到下一個狀態 s t = s t + 1 s_t=s_{t+1} st?=st+1?
- \qquad\qquad 階段2:引數更新階段
- \qquad\qquad 從 D D D中采樣含有 N N N個轉移 ( s , a , r , s ′ ) (s,a,r,s') (s,a,r,s′)的minibatch(經驗回放)
- \qquad\qquad 根據演算法2通過目標Actor網路在狀態 s ′ s' s′時生成推薦串列 a ′ a' a′
- \qquad\qquad 設定目標價值 y = r + γ Q ′ ( s ′ , a ′ ; θ μ ′ ) y=r+\gamma Q'(s',a';{\theta^\mu}') y=r+γQ′(s′,a′;θμ′)
- \qquad\qquad 用梯度下降法最小化損失 ( y ? Q ( s , a ; θ μ ) ) (y-Q(s,a;{\theta^\mu})) (y?Q(s,a;θμ))以更新Critic網路: ? θ μ L ( θ μ ) ≈ 1 N [ ( y ? Q ( s , a ; θ μ ) ) ? θ μ Q ( s , a ; θ μ ) ] \nabla_{\theta^\mu}L(\theta^\mu)\approx \frac{1}{N}[(y-Q(s,a;{\theta^\mu}))\nabla_{\theta^\mu}Q(s,a;{\theta^\mu})] ?θμ?L(θμ)≈N1?[(y?Q(s,a;θμ))?θμ?Q(s,a;θμ)]
- \qquad\qquad 用采樣策略梯度法更新Actor網路: ? θ π f θ π ≈ 1 N ∑ i ? a Q ( s , a ; θ μ ) ? θ π f θ π ( s ) \nabla_{\theta^\pi}f_{\theta^\pi}\approx \frac{1}{N}\sum_{i}\nabla_{a}Q(s,a;{\theta^\mu})\nabla_{\theta^\pi}f_{\theta^\pi}(s) ?θπ?fθπ?≈N1?i∑??a?Q(s,a;θμ)?θπ?fθπ?(s)
- \qquad\qquad 更新目標Critic網路: θ μ ′ = τ θ μ + ( 1 ? τ ) θ μ ′ {\theta^\mu}'=\tau {\theta^\mu}+(1-\tau){\theta^\mu}' θμ′=τθμ+(1?τ)θμ′
- \qquad\qquad 更新目標Actor網路: θ π ′ = τ θ π + ( 1 ? τ ) θ π ′ {\theta^\pi}'=\tau {\theta^\pi}+(1-\tau){\theta^\pi}' θπ′=τθπ+(1?τ)θπ′
在訓練完成之后,RA就可以得到訓練好的引數,即 θ μ \theta^\mu θμ和 θ π \theta^\pi θπ,之后就可以在模擬環境中進行模型測驗了,模型測驗的方法也是演算法3,即引數在測驗階段也可以被不斷更新,與訓練階段的主要區別是測驗階段會在每次獲取會話之前重置 θ μ \theta^\mu θμ和 θ π \theta^\pi θπ,以便在每個推薦階段之間進行公平比較,
6.2. 對Actor網路更新的說明
采用策略梯度法更新Actor網路的思路是 Q ( s , a ; θ μ ) Q(s,a;{\theta^\mu}) Q(s,a;θμ)中輸入的 a a a與 f θ π ( s ) f_{\theta^\pi}(s) fθπ?(s)(經評分后)輸出的是一致的, Q ( s , a ; θ μ ) Q(s,a;{\theta^\mu}) Q(s,a;θμ)中輸入的 s s s與 f θ π ( s ) f_{\theta^\pi}(s) fθπ?(s)的輸入 s s s是一致的,因此有 f θ π ( s ) f_{\theta^\pi}(s) fθπ?(s)的梯度為: ? f θ π ( s ) = ∑ i ? a Q ( s , a ; θ μ ) f θ π ( s ) \nabla f_{\theta^\pi}(s)=\sum_{i}\nabla_{a}Q(s,a;{\theta^\mu})f_{\theta^\pi}(s) ?fθπ?(s)=i∑??a?Q(s,a;θμ)fθπ?(s)其中 i i i代表一個時間步的 ( s , a ) (s,a) (s,a),再進一步求引數 θ π \theta^\pi θπ的梯度得: ? θ π f θ π ∝ ∑ i ? a Q ( s , a ; θ μ ) ? θ π f θ π ( s ) \nabla_{\theta^\pi}f_{\theta^\pi}\propto\sum_{i}\nabla_{a}Q(s,a;{\theta^\mu})\nabla_{\theta^\pi}f_{\theta^\pi}(s) ?θπ?fθπ?∝i∑??a?Q(s,a;θμ)?θπ?fθπ?(s)再對 N N N個episode的梯度求平均得: ? θ π f θ π ≈ 1 N ∑ i ? a Q ( s , a ; θ μ ) ? θ π f θ π ( s ) \nabla_{\theta^\pi}f_{\theta^\pi}\approx \frac{1}{N}\sum_{i}\nabla_{a}Q(s,a;{\theta^\mu})\nabla_{\theta^\pi}f_{\theta^\pi}(s) ?θπ?fθπ?≈N1?i∑??a?Q(s,a;θμ)?θπ?fθπ?(s)
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/290133.html
標籤:其他
上一篇:初始C語言(三)(C語言初階)
下一篇:c語言基礎筆記