每篇激勵自己的一句話:路,是一直在腳下,好好努力,明日必定越來越好,
👨?🎓string類實作
- 🎓string建構式
- 🎓拷貝建構式
- 🎓賦值運算子多載函式
- 🎓解構式
- 🎓迭代器與npos
- ??begin與end
- 🎓容量、大小與之相關函式
- ??capacity()、size()與empty()
- ??reserve
- ??resize
- 🎓增刪交換函式
- ??push_back()
- ??append()
- ??operator +=
- ??insert()
- ??pop_back()
- ??erase()
- ??clear()
- ??swap()
- 🎓元素訪問函式
- ??at()
- ??operator []
- 🎓字串操作函式
- ??find()
- ??c_str()
- 🎓非成員函式多載
- ??operator<
- ??operator>
- ??operator==
- ??operator<=
- ?? operator>=
- ??operator!=
- ??operator<<
- ??operator>>
- ??getline
- 完整代碼如下:
🎓string建構式
在C++98語法中,string的建構式就多達7種,其中(1)、(2)、(4)使用較為頻繁,下面我們就模擬實作其建構式,

這里我們寫的是一個預設的建構式,如果傳進來的字串長度<=15,那我們就將其容量設定為15;否則就是該字串長度的兩倍,
string(const char* str="")
{
// 構造string類物件時,如果傳遞nullptr指標,認為程式非法,此處斷言下
if (str == nullptr)
{
assert(false);
}
this->m_size = strlen(str);//計算字串的長度,不包括\0
if (this->m_size <=15) //如果該字串長度<=15,則默認初始化其容量為15
{
this->m_capacity = 15;
}
else
{
this->m_capacity = strlen(str);
}
this->m_str = new char[this->m_capacity + 1]; //為存盤字串開辟空間(多開一個用于存放'\0')
strcpy(this->m_str, str); //將形參字串拷貝給我們string物件的字串陣列中
}
🎓拷貝建構式
在模擬實作拷貝建構式前,我們應該首先了解深淺拷貝:
- 在默認的拷貝函式中(亦指淺拷貝),復制的策略是直接將原物件的資料成員值按照“位拷貝”的方式復制給新物件中對應的資料成員,但倘若類中含有指標變數,那么拷貝建構式和賦值運算子多載函式就隱含了錯誤,
- 以類 string 的兩個物件 a,b 為例,假設 a.m_data的內容為"hello", b.m_data 的內容為"world",現將 a 賦給 b,賦值函式的“位拷貝”意味著執行 b.m_data = a.m_data,
這將造成以下三個錯誤:
①是 b.m_data 原有的記憶體沒被釋放,造成記憶體泄露,
②是b.m_data 和 a.m_data 指向同一塊記憶體,a 或 b任何一方變動都會影響另一方,
③是在物件被析構時,m_data 被釋放了兩次,- 對于深拷貝,針對成員變數存在指標的情況,不僅僅是簡單的指標賦值,而是重新分配記憶體空間,
下面就是我們的拷貝構造的不同寫法:
第一種寫法
①首先我們在初始化串列中,將this指標物件的m_str的空間開辟好,
②接著我們把str.m_size 和str.m_capacity的值賦給this物件中的m_size 與m_capacity,
③最后我們把str.m_size里面的內容拷貝一份到this物件的m_str中,
string(const string& str) : m_str(new char[str.m_capacity + 1]), m_capacity(str.m_capacity), m_size(str.m_size)
{
//在初始化串列中,我們已經將其容量和大小已經初始化好
//在函式體內,我們只需要將string的物件中的str.m_str拷貝給我們this指標中的str.m_str
strcpy(this->m_str, str.m_str);
}
第二種寫法
原理:基于臨時的區域物件初始化呼叫建構式,然后出了函式就會呼叫解構式釋放其記憶體,
①先創建一個臨時物件,讓后用形參str中的m_str給臨時物件讓其呼叫建構式,
②this物件在與臨時物件交換其資料,
string(const string& str)
{
string temp(str.m_str); //呼叫建構式,構造出一個字串為str._str的物件
this->swap(temp);//最后在讓臨時物件temp與this物件
}
上面的swap函式不是std命名空間的,是自己的命名空間中的一個string類的成員函式,在后面會給大家看到,
🎓賦值運算子多載函式
在拷貝建構式中我們已經說明賦值運算子多載函式在碰到有指標變數的類時也涉及深淺拷貝問題,我們同樣需要采用深拷貝,下面也提供深拷貝的兩種寫法:
第一種寫法
第一種寫法和拷貝建構式的第一種寫法相差不大,唯一的區別在于如果這個物件本身自己給自己賦值時候需要特殊處理,
string& operator =(string& str)
{
if (this != &str) //防止自己給自己賦值
{
char *temp=new char[str.m_size+1]; //創建str字符個數+1的空間,因為要給‘\0’留個空間
delete this->m_str; //將原來this物件的m_str指向的空間釋放
strcpy(this->m_str,temp);
this->m_size=str.m_size;
this->m_capacity=str.m_capacity;
}
return *this;
}
第二種方法
相較于第一種寫法,第二種寫法代碼就簡單很多,但我們要了解其運行原理,這里面同樣要防止自我賦值的情況,
原理:基于臨時的區域物件用已有的物件給其初始化,然后呼叫拷貝建構式,同樣區域string物件出了函式就會呼叫解構式釋放其記憶體,
①首先創建一個臨時變數,讓其呼叫拷貝建構式,
②在讓this物件與臨時物件temp交換,
string& operator =(string& str)
{
if (this != &str)
{
string temp(str);
swap(temp);
}
return *this;
}
🎓解構式
解構式就沒有什么好說的,但是還是要處理一些已經delete釋放的空間,再一次delete釋放,造成程式崩潰,
~string()
{
if (this->m_str != nullptr)
{
delete[]this->m_str; //銷毀空間
this->m_str = nullptr; //并把該物件的指標置nullptr
//這下面兩行寫不寫都行
this->m_capacity = 0;
this->m_size = 0;
}
}
🎓迭代器與npos
npos 是string類中的一個靜態成員常量,它的值大小是 -1,但由于是size_t (unsigned int)型別,它的值在使用時會變成無符號的最大值,靜態成員必須在類外初始化,類內宣告,
public:
typedef char* iterator; //普通迭代器
typedef const char* const_iterator; //常量迭代器
const static size_t npos;
注意:在string中的迭代器是用指標實作,這并不代表著所有的迭代器都是用指標實作的(這很重要),
??begin與end
在string中有begin(起始迭代器)和end(結束迭代器),當然實際上在string不止有這兩種迭代器,但這兩個卻是我們最經常使用的,begin()它指向的是第一的元素,end()指向的最后一個元素的下一個位置,如下圖所示:
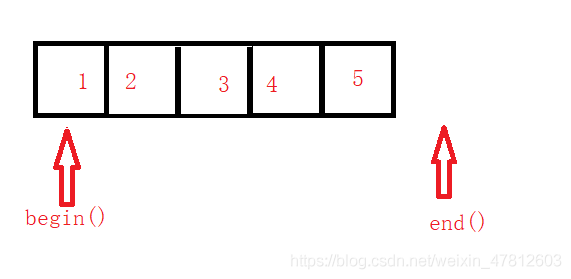
下面我們就實作這兩個迭代器函式,
iterator begin() //起始迭代器
{
//回傳該物件的實體,也就是m_str這個char型別指標的首地址
return this->m_str;
}
iterator end() //結束迭代器
{
//回傳起始就是該字串中'\0'的地址
return this->m_str + this->m_size;
}
const_iterator begin() const //具有常屬性的起始迭代器
{
return this->m_str;
}
const_iterator end() const //具有常屬性的結束迭代器
{
return this->m_str + this->m_size;
}
🎓容量、大小與之相關函式
??capacity()、size()與empty()
capacity()與size()的含義分別是用來獲取容量、大小,為什么會存在這兩個介面呢?這是因為由于其不想讓我們直接去訪問它的私有成員,所以string類設定了size和capacity這兩個成員函式,
empty是用來判斷該物件是否為空,
size_t size() const //這里必須設定成const
{
//這里的個數是不包括'\0'的長度,與strlen相同
return this->m_size;
}
size_t capacity() const //這里必須設定成const
{
//回傳容量的大小
return this->m_capacity;
}
bool empty() const
{
return this->m_size==0;
}
??reserve
功能:reserve是用來預留空間大小
規則:
?1、當n大于物件當前的capacity時,將capacity擴大到n,
?2、當n小于等于物件當前的capacity時,什么也不做,
void reserve(size_t n = 0) //給該函式設定了預設值 0
{
//如果n大于物件當前的capacity時,將capacity擴大到n
if (n > this->m_capacity)
{
char* str = new char[n + 1];
strncpy(str,this->m_str,this->m_size+1);
delete[] this->m_str;
this->m_str = str;
this->m_capacity=n;
}
}
上面為什么要用strncpy而不用strcpy呢?
這是因為里面存盤的字符就是’\0‘,并且’\0‘也是我們想要的字符時,strcpy函式是從前向后拷貝,碰到’\0’就結束,而strncpy是指定拷貝多少個位元組的大小,+1是因為我們字串結束要用’\0‘,如下圖所示:
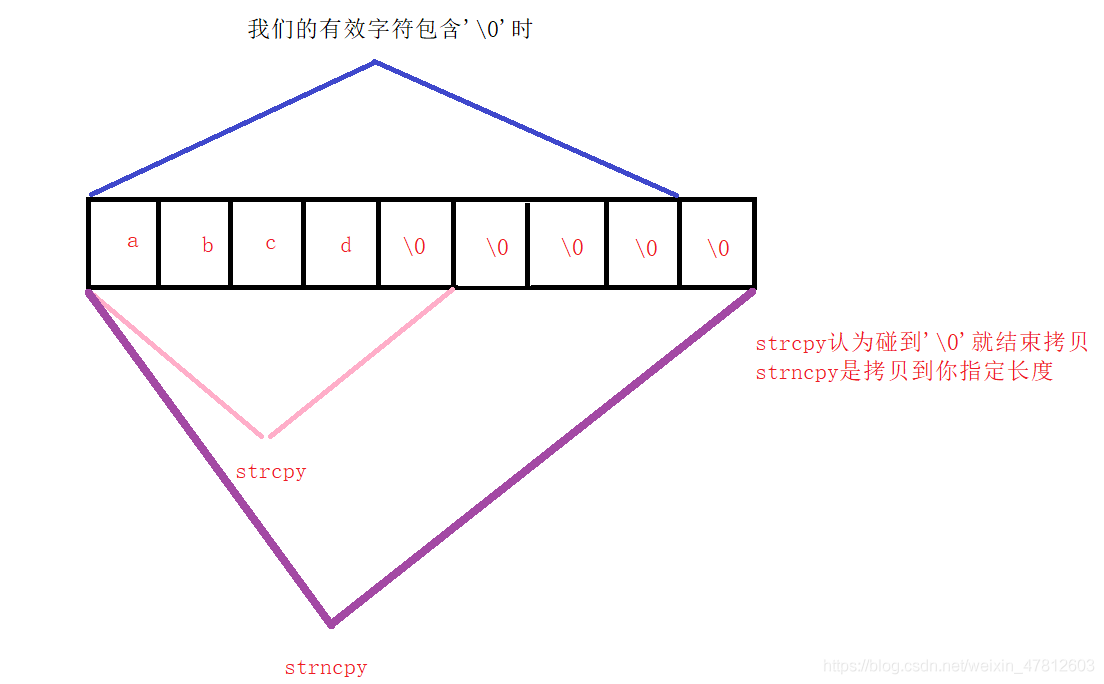
??resize
功能:將字串大小調整為n個字符的長度,
規則:
1、如果n小于當前字串長度,則當前值將縮短為其前n個字符,洗掉第n個字符以外的字符,
2、如果n大于當前字串長度,則通過在末尾插入所需數量的字符來擴展當前內容,以達到n的大小,如果指定了字符c,新元素將被初始化為c的副本,否則,它們是值初始化字符’\0‘(空字符),
void resize(size_t n, char c='\0') //給一個默認的預設值’\0‘
{
if (n > this->m_size) //如果n大于當前字串長度
{
if (n>this->m_capacity) //判斷它是否要擴容
{
reserve(n);
}
int temp=n - this->m_size;
while (temp--)
{
push_back(c);
}
}
else
{
this->m_size = n;
this->m_str[this->m_size] = '\0';
}
}
🎓增刪交換函式
??push_back()
功能:push_back()這個介面正如的它的名字一樣,意思是在它字串尾部插入一個字符,
實作程序:
①首先插入,我們要判斷其容量是否已滿,如果已滿則需要擴容后再插入,這里我們就可以簡單的擴容為原來的兩倍,
②插入資料,并讓個數+1,
③再使this->m_size的位置的資料置為’\0‘,因為其這是字串結束的標志,
void push_back(char c) //尾插
{
if (this->m_size == this->m_capacity) //此時已滿
{
reserve(this->m_capacity * 2);
}
this->m_str[this->m_size++] = c;
this->m_str[this->m_size] = '\0';
}
??append()
append函式的多載版本有很多,這里我們只實作最常用的三個,
功能:與push_back效果類似,是在尾部插入字符或字串,
string& append(const char ch)
{
//在尾部插入一個字符ch,這里我們復用了push_back()函式
this->push_back(ch);
return *this;
}
//下面的兩個都是在尾部插入一個字串
//實作程序:
//①先判斷加上字串個數后我們的容量是否超出
//②再把str拷貝到this->m_str的尾部(也就是this->m_str + this->m_size)
string& append(const char* str)
{
int len = this->m_size + strlen(str);
if (len > this->m_capacity)
{
reserve(len * 2);
}
strcpy(this->m_str + this->m_size, str);
this->m_size = len;
return *this;
}
//與上面的思路相同
string& append(const string& str)
{
int len= this->m_size + str.size();
if (len > this->m_capacity)
{
reserve(len * 2);
}
strcpy(this->m_str + this->m_size, str.m_str);
this->m_size=len;
return *this;
}
??operator +=
由于operator+=函式與append的功能一模一樣,但為什么我們不直接使用append()函式而多弄一個多載+=運算子,這是由于+=更通俗易懂,看到就大概知道怎么使用,上手成本低,
//這三個函式都是復用的push_back()或append函式,因為它們的功能是一模一樣的
string& operator+=(const char ch)
{
this->push_back(ch);
return *this;
}
string& operator+=(const char* str)
{
this->append(str);
return *this;
}
string& operator+=(const string& str)
{
this->append(str);
return *this;
}
??insert()
功能:在pos指示的字符前面的字串中插入其他字符,
// 在pos位置上插入字符c/字串str
//實作程序
//①首先先判斷插入的位置是否合法
//②在判斷插入n個字符后容量是否充足,不夠則擴容
//③把pos位置包括pos及后面的字符向后移動len-pos個位元組
//④從pos位置開始插入n個字符c
string& insert(size_t pos, size_t n,const char c)
{
assert(pos <= this->size()); //判斷插入的位置是否合法
int len = this->m_size; //存盤插入前的字符個數
this->m_size += n; //加上n個字符后,判斷其是否超出容量
if (this->m_size > this->m_capacity)
{
reserve(this->m_size*2); //擴容
}
//把pos位置包括pos及后面的字符向后移動len-pos個位元組
memmove(begin() + pos + n, begin() + pos, len-pos);
//從pos位置開始到pos+n個字符,賦值為 c
for (size_t i = pos; i < pos + n; ++i)
{
this->m_str[i] = c;
}
return *this;
}
/*
實作程序
①首先先判斷插入的位置是否合法
②在判斷插入這個字串后容量是否充足,不夠則擴容
③把pos位置包括pos及后面的字符向后移動len-pos個位元組
④在把字串里的內容挪動str.m_size個位元組到我們的this物件的pos位置
*/
string& insert(size_t pos, const string& str)
{
assert(pos <= this->size()); //判斷插入的位置合法性
int len = this->m_size;//記錄當前的長度
this->m_size += str.m_size;
if (this->m_size > this->m_capacity)//判斷加上字串后長度是否超過容量,超過就擴容
{
this->reserve(this->m_size * 2);
}
memmove(this->begin() + pos + str.m_size, this->begin() + pos, len - pos);
memmove(this->begin() + pos, str.m_str, str.m_size);
return *this;
}
string& insert(size_t pos, const char* str)
{
assert(pos <= this->size()); //判斷插入的位置合法性
int len = this->m_size; //記錄當前的長度
this->m_size += strlen(str);
if (this->m_size > this->m_capacity)//判斷加上字串后長度是否超過容量,超過就擴容
{
this->reserve(this->m_size * 2);
}
memmove(this->begin() + pos + strlen(str), this->begin() + pos, len - pos);
memmove(this->begin() + pos, str, strlen(str));
return *this;
}
??pop_back()
功能:pop_back()這個介面正如的它的名字一樣,意思是在它字串尾部洗掉一個字符,
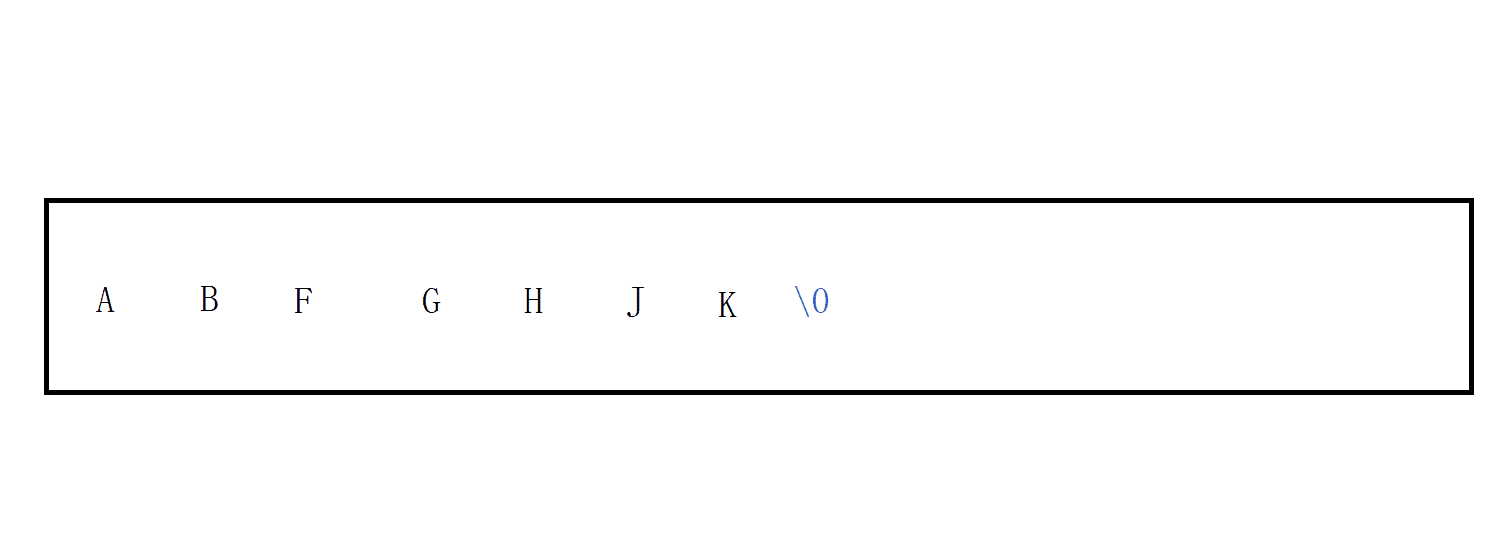
void pop_back() //尾刪
{
this->m_str[--this->m_size] = '\0';
}
??erase()
功能:erase函式的作用是洗掉字串任意pos位置開始的n個字符,默認是從pos位置后面洗掉完,首先在洗掉之前我們也是要判斷它洗掉的位置正確與否,
洗掉時有兩種情況:
①當從pos位置開始后沒有 len個字符或則沒有傳len的引數時,則表明后面全部洗掉,此時我們只需要將pos位置上值改為‘\0’做邏輯上的洗掉,并把個數改為pos個,
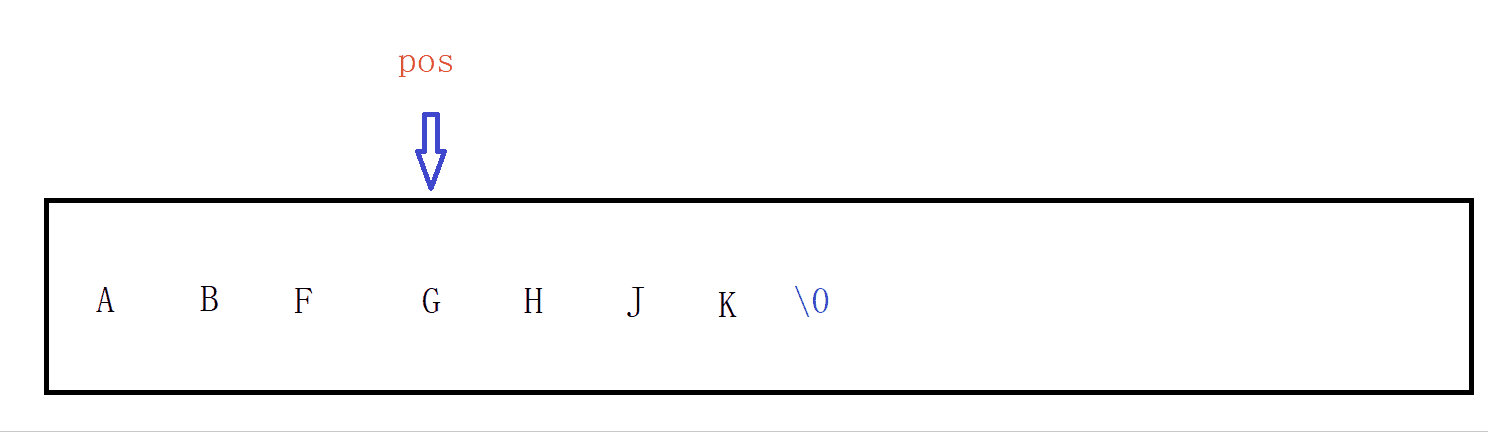
②只洗掉pos位置開始及其之后的一部分字符,
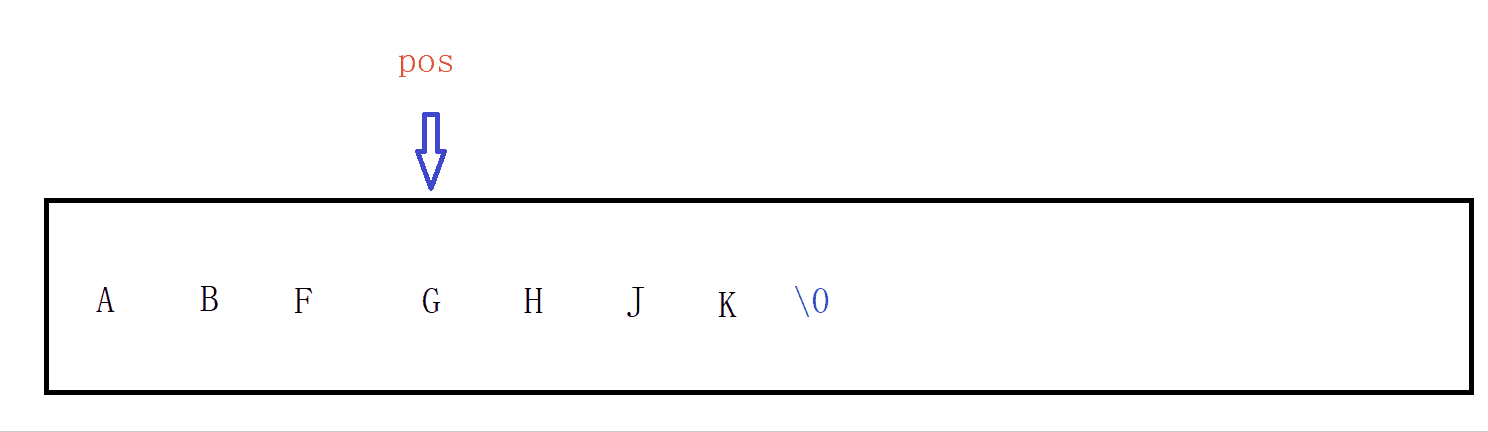
//洗掉從pos開始的n個字符
string& erase(size_t pos = 0, size_t len =string::npos)
{
assert(pos <this->size()); //判斷洗掉的位置是否正確
if (pos + len >= this->m_size) //pos位置開始后沒有 len個字符或則沒有傳len的引數時
{
//做邏輯上的洗掉
this->m_size = pos;
this->m_str[pos] = '\0';
}
else
{
for (size_t i = pos,j= pos + len; i<size()&&j<size(); ++i,++j)
{
this->m_str[i] = this->m_str[j];
}
this->m_size -= len;
this->m_str[this->m_size] = '\0';
}
return *this;
}
??clear()
功能:清空字串的內容,該字串成為空字串(長度為0個字符),容量不一定會改變成0,因為我們可能會清空后繼續使用,
void clear() //清空
{
this->m_size = 0;
this->m_str[this->m_size] = '/0';
}
??swap()
功能:用于兩個string之間進行交換
void swap(string& str)
{
//這里我們呼叫命名空間std中的swap,將兩個str的實體進行交換
std::swap<size_t>(this->m_capacity, str.m_capacity);
std::swap<size_t>(this->m_size, str.m_size);
std::swap<char*>(this->m_str, str.m_str);
}
🎓元素訪問函式
??at()
at函式相當于陣列的[]一樣,傳入一個下標的值進去,會給你回傳該下標在陣列中所對應的字符,
char& at(size_t pos) //at(可讀可寫)
{
assert(pos < this->m_size);//判斷合法性
return this->m_str[pos];
}
const char& at(size_t pos) const //const物件呼叫
{
assert(pos < this->m_size);//判斷合法性
return this->m_str[pos];
}
??operator []
operator []與at函式功能完全相同,只是[]看起來更簡單易懂,[ ]運算子的多載是為了讓string物件能像陣列一樣能通過[ ] +下標的方式獲取字串對應位置的字符,實作[ ] 運算子的多載時只需回傳物件C字串對應位置字符的參考即可,這樣便能實作對該位置的字符進行讀取和修改操作了,但需要注意在此之前檢測所給的下標合法性,
char& operator[](size_t index) //[]運算子多載(可讀可寫)
{
assert(index < this->m_size); //判斷合法性
return this->m_str[index];
}
在常物件呼叫operator[]時,我們只能用[ ] +下標的方式獲取字符而不能對其進行修改,如果用上面的那個operator[]回傳的是參考,說明是可讀可寫,但我們的物件是常物件,說明是不可以更改的,所以這是我們為什么多寫一個功能差不多類似的函式,
const char& operator[](size_t index) const //const物件呼叫
{
assert(index < this->m_size); //判斷合法性
return this->m_str[index];
}
🎓字串操作函式
??find()
find函式是用于在字串中查找一個字符或則是字串,find函式用于正向查找,即從字串開頭開始向后查找,下面是它的兩種多載版本,
// 回傳c在string中第一次出現的位置
size_t find(const char c, size_t pos = 0) const
{
for (size_t i = pos; i < this->size(); ++i)
{
if (this->m_str[i] == c)
{
return i;
}
}
return npos;
}
// 回傳子串s在string中第一次出現的位置
size_t find(const char* str, size_t pos = 0) const
{
assert(pos < this->m_size); 首先先判斷所給pos的合法性,
int index = 0;
size_t i = pos, j = 0;
//我們暴力求解,一個個的去匹配,如果不相同就回溯,相同就繼續
while( i < size() && j<strlen(str))
{
if (this->m_str[i] == str[j])
{
++i, ++j;
}
else //回溯
{
i = ++index;
j = 0;
}
}
return j==strlen(str)?index:string::npos;
}
??c_str()
這個介面是為了與C的一些代碼結合產生的,其功能是:回傳C型別的字串,
const_iterator c_str() const
{
return this->m_str; //回傳C型別的字串
}
🎓非成員函式多載
關系運算子有 >、>=、<、<=、==、!= 這6個,加上兩個友元函式operator<<、operator>>,一個全域函式getline,一共9個,下面是它們的實作,
??operator<
bool operator< (const string &str) const //<運算子多載
{
if (strcmp(this->m_str, str.m_str) < 0)
{
return true;
}
return false;
}
??operator>
bool operator>(const string& str) const //>運算子多載
{
if (strcmp(this->m_str, str.m_str)>0)
{
return true;
}
return false;
}
??operator==
bool operator==(const string& str) const //==運算子多載
{
if (strcmp(this->m_str, str.m_str) ==0)
{
return true;
}
return false;
}
??operator<=
bool operator<=(const string& str) const //<=運算子多載
{
if (!(*this > str)) //復用多載的>
{
return true;
}
return false;
}
?? operator>=
bool operator>=(const string& str) const
{
if (!(*this < str)) //復用多載的<
{
return true;
}
return false;
}
??operator!=
bool operator!=(const string& str) const //!=運算子多載
{
if (!(*this == str)) //復用多載的==
{
return true;
}
return false;
}
??operator<<
功能:多載<<運算子是為了讓string物件能夠像內置型別一樣使用<<運算子直接輸出列印,
//因為我們要訪問它的私有成員,故我將其多載為友元函式
ostream& operator<< (ostream& os, const string& str)
{
//這里不能直接os<<str
for (size_t i = 0; i < str.size(); ++i)
{
os << str.m_str[i];
}
return os; //回傳os,以便鏈式的輸出,
}
??operator>>
多載>>運算子是為了讓我們模擬的string物件能夠像內置型別一樣使用>>運算子直接輸入,輸入前我們需要先將物件里的C字串清空,然后從標準輸入流讀取字符,直到讀取到’ '(空格)或是’\n’便停止讀取,
//因為我們要訪問它的私有成員,故我將其多載為友元函式
istream& operator>> (istream& is, string& str)
{
str.clear(); //如果str中已經有元素了,則把的內容清空
char ch;
ch = is.get();
while (ch==' '|| ch == '\n') //讀取一個字符后判斷它是不是有效字符,如果是’ ‘(空格)或是’\n’就繼續讀取
{
ch = is.get();
}
//到了這里就表示我們已經至少讀到過一個不是’ ‘(空格)或是’\n的字符,此時我們直到讀取到’ ‘(空格)或是’\n’便停止讀取,
while (ch != ' ' && ch != '\n')
{
str.push_back(ch);
ch = is.get();
}
return is; //回傳is,以便鏈式的輸出,
}
可能有的小伙伴會問operator>>與operator<<為什么不直接多載為成員函式?
簡單來說就是this物件會和cout與cin搶第一個位置,即cout與cin的左邊,
??getline
getline函式用于讀取一行含有空格的字串,實作時基于>>運算子的多載基本相同,只是當讀取到’\n’的時候才停止讀取字符,
istream& getline(istream& is, string& str)
{
str.clear(); //如果str中已經有元素了,則把的內容清空
char ch;
ch = is.get();
while (ch == '\n') //讀取一個字符后判斷它是不是有效字符,如果是’\n’就繼續讀取
{
ch = is.get();
}
//到了這里就表明至少讀取到一個不是’\n’的字符,此時我們如果讀取到’\n’便停止讀取,
while (ch != '\n')
{
str.push_back(ch);
ch = is.get();
}
return is; //回傳is,以便鏈式的輸出,
}
完整代碼如下:
#define _CRT_SECURE_NO_WARNINGS 1
#include<string.h>
#include<assert.h>
#include<iostream>
using namespace std;
namespace ZJ
{
class string
{
friend ostream& operator<< (ostream& os, const string& str);
friend istream& operator>> (istream& is, string& str);
public:
typedef char* iterator;
typedef const char* const_iterator;
const static size_t npos;
public:
string(const char* str="")
{
// 構造string類物件時,如果傳遞nullptr指標,認為程式非法,此處斷言下
if (str == nullptr)
{
assert(false);
}
this->m_size = strlen(str);//計算字串的長度,不包括\0
if (this->m_size <=15) //如果該字串長度<=15,則默認初始化其容量為15
{
this->m_capacity = 15;
}
else
{
this->m_capacity = strlen(str);
}
this->m_str = new char[this->m_capacity + 1]; //為存盤字串開辟空間(多開一個用于存放'\0')
strcpy(this->m_str, str); //將形參字串拷貝給我們string物件的字串陣列中
}
string(const string& str) : m_str(new char[str.m_capacity + 1]), m_capacity(str.m_capacity), m_size(str.m_size)
{
strcpy(this->m_str, str.m_str);
}
void swap(string& str)
{
std::swap<size_t>(this->m_capacity, str.m_capacity);
std::swap<size_t>(this->m_size, str.m_size);
std::swap<char*>(this->m_str, str.m_str);
}
string& operator =(string& str)
{
if (this != &str)
{
string temp(str);
swap(temp);
}
return *this;
}
~string()
{
if (this->m_str != nullptr)
{
delete[]this->m_str;
this->m_capacity = 0;
this->m_size = 0;
this->m_str = nullptr;
}
}
const_iterator c_str() const
{
return this->m_str;
}
size_t size() const
{
return this->m_size;
}
size_t capacity() const
{
return this->m_capacity;
}
bool empty() const
{
return this->m_size==0;
}
char& operator[](size_t index)
{
assert(index < this->m_size);
return this->m_str[index];
}
const char& operator[](size_t index) const
{
assert(index < this->m_size);
return this->m_str[index];
}
char& at(size_t pos)
{
assert(pos < this->m_size);
return this->m_str[pos];
}
const char& at(size_t pos) const
{
assert(pos < this->m_size);
return this->m_str[pos];
}
//洗掉從pos開始的n個字符
string& erase(size_t pos = 0, size_t len =string::npos)
{
assert(pos <this->size());
if (pos + len >= this->m_size)
{
this->m_size = pos;
this->m_str[pos] = '\0';
}
else
{
for (size_t i = pos,j= pos + len; i<size()&&j<size(); ++i,++j)
{
this->m_str[i] = this->m_str[j];
}
this->m_size -= len;
this->m_str[this->m_size] = '\0';
}
return *this;
}
// 在pos位置上插入字符c/字串str
string& insert(size_t pos, size_t n,const char c)
{
assert(pos <= this->size());
int len = this->m_size;
this->m_size += n;
if (this->m_size > this->m_capacity)
{
reserve(this->m_size*2);
}
memmove(begin() + pos + n, begin() + pos, len-pos);
for (size_t i = pos; i < pos + n; ++i)
{
this->m_str[i] = c;
}
return *this;
}
string& insert(size_t pos, const string& str)
{
assert(pos <= this->size());
string temp = *this;
int len = temp.m_size;
temp.m_size += str.m_size;
if (temp.m_size > this->m_capacity)
{
temp.reserve(this->m_size * 2);
}
memmove(temp.begin() + pos + str.m_size, temp.begin() + pos, len - pos);
memmove(temp.begin() + pos, str.m_str, str.m_size);
swap(temp);
return *this;
}
string& insert(size_t pos, const char* str)
{
assert(pos <= this->size());
string temp = *this;
int len = this->m_size;
temp.m_size += strlen(str);
if (temp.m_size > this->m_capacity)
{
temp.reserve(temp.m_size * 2);
}
memmove(temp.begin() + pos + strlen(str), temp.begin() + pos, len - pos);
memmove(temp.begin() + pos, str, strlen(str));
swap(temp);
return *this;
}
void reserve(size_t n = 0)
{
if (n > this->m_capacity)
{
char* str = new char[n + 1];
strncpy(str,this->m_str,this->m_size+1);
delete[] this->m_str;
this->m_str = str;
this->m_capacity=n;
}
}
void resize(size_t n, char c='\0')
{
if (n > this->m_size)
{
if (n>this->m_capacity)
{
reserve(n);
}
while (n - this->m_size)
{
push_back(c);
}
}
else
{
this->m_size = n;
this->m_str[this->m_size] = '\0';
}
}
string& append(const char ch)
{
this->push_back(ch);
return *this;
}
string& append(const char* str)
{
int len = this->m_size + strlen(str);
if (len > this->m_capacity)
{
reserve(len * 2);
}
strcpy(this->m_str + this->m_size, str);
this->m_size = len;
return *this;
}
string& append(const string& str)
{
int len= this->m_size + str.size();
if (len > this->m_capacity)
{
reserve(len * 2);
}
strcpy(this->m_str + this->m_size, str.m_str);
this->m_size=len;
return *this;
}
string& operator+=(const char ch)
{
this->push_back(ch);
return *this;
}
string& operator+=(const char* str)
{
this->append(str);
return *this;
}
string& operator+=(const string& str)
{
this->append(str);
return *this;
}
iterator begin() //起始迭代器
{
return this->m_str;
}
iterator end() //結束迭代器
{
return this->m_str + this->m_size;
}
const_iterator begin() const
{
return this->m_str;
}
const_iterator end() const //結束迭代器
{
return this->m_str + this->m_size;
}
char& back() //獲得最后一個元素
{
return this->m_str[this->m_size - 1];
}
char& front() //獲得第一個元素
{
return this->m_str[0];
}
void push_back(char c) //尾插
{
if (this->m_size == this->m_capacity) //此時已滿
{
reserve(this->m_capacity * 2);
}
this->m_str[this->m_size++] = c;
this->m_str[this->m_size] = '\0';
}
void pop_back() //尾刪
{
this->m_str[--this->m_size] = '\0';
}
void clear() //清空
{
this->m_size = 0;
this->m_str[this->m_size] = '/0';
}
bool operator< (const string &str) const
{
if (strcmp(this->m_str, str.m_str) < 0)
{
return true;
}
return false;
}
bool operator==(const string& str) const
{
if (strcmp(this->m_str, str.m_str) ==0)
{
return true;
}
return false;
}
bool operator>(const string& str) const
{
if (strcmp(this->m_str, str.m_str)>0)
{
return true;
}
return false;
}
bool operator<=(const string& str) const
{
if (!(*this > str))
{
return true;
}
return false;
}
bool operator>=(const string& str) const
{
if (!(*this < str))
{
return true;
}
return false;
}
bool operator!=(const string& str) const
{
if (!(*this == str))
{
return true;
}
return false;
}
// 回傳c在string中第一次出現的位置
size_t find(const char c, size_t pos = 0) const
{
for (size_t i = pos; i < this->size(); ++i)
{
if (this->m_str[i] == c)
{
return i;
}
}
return npos;
}
// 回傳子串s在string中第一次出現的位置
size_t find(const char* str, size_t pos = 0) const
{
assert(pos < this->m_size);
int index = 0;
size_t i = pos, j = 0;
while( i < size() && j<strlen(str))
{
if (this->m_str[i] == str[j])
{
++i, ++j;
}
else
{
i = ++index;
j = 0;
}
}
return j==strlen(str)?index:string::npos;
}
private:
char* m_str;
size_t m_size; //個數
size_t m_capacity; //容量
};
const size_t string::npos = -1;
ostream& operator<< (ostream& os, const string& str)
{
for (size_t i = 0; i < str.size(); ++i)
{
os << str.m_str[i];
}
return os;
}
istream& operator>> (istream& is, string& str)
{
str.clear();
char ch;
ch = is.get();
while (ch==' '|| ch == '\n')
{
ch = is.get();
}
while (ch != ' ' && ch != '\n')
{
str.push_back(ch);
ch = is.get();
}
return is;
}
istream& getline(istream& is, string& str)
{
str.clear();
char ch;
ch = is.get();
while (ch == '\n')
{
ch = is.get();
}
while (ch != '\n')
{
str.push_back(ch);
ch = is.get();
}
return is;
}
}

如有錯誤之處,還請各位指出,謝謝大家!!!
END...
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/290480.html
標籤:其他
上一篇:C語言-函式遞回
下一篇:[C語言]詳解指標合集