初識爬蟲
- 一、了解爬蟲和瀏覽器的原理
- 1.瀏覽器的作業原理
- 2.爬蟲的作業原理
- 2.1初識爬蟲撰寫
- 二、簡要學習HTML
- 1.什么是HTML
- 2.HTML的標簽和元素
- 3.< head > 和 < body >
- 3.1< head >
- 3.2< body >
- 4.設定標簽的屬性
- 5.兩個常用屬性:class & id
- 6.HTML的閱讀和修改
- 三、撰寫第一個爬蟲
- 1.BeautifulSoup模塊功能簡述
- 2.BeautiSoup的使用
- 2.1 使用BeautiSoup決議資料
- 2.2使用BeautifulSoup庫提取資料
學習爬蟲之前需要進行 相關環境的搭建,因為需要用到不屬于python標準庫的庫或模塊,
一、了解爬蟲和瀏覽器的原理
1.瀏覽器的作業原理
給大家提供一個演示鏈接進行爬蟲的學習(請使Google Chrome瀏覽器進行實操),
這個網站上有一個菜品串列,如果我們希望保存部分想要的內容,可以將這部分內容粘貼到本地檔案, 這個程序就是一個人和瀏覽器在交流的程序:

我們在瀏覽器中輸入一個網址(URL),瀏覽器就會去存盤放置這個網址資源檔案的服務器獲取這個網址的內容,這個程序就叫做「請求」(Request);當服務器收到了「請求」之后,會把對應的網站資料回傳給瀏覽器,這個程序叫做「回應」(Response),
所以當我們使用瀏覽器去瀏覽網頁的時候,都是瀏覽器去向服務器請求資料,服務器回傳資料給瀏覽器的程序,
當瀏覽器收到服務器回傳的資料時,它會先「決議資料」,把資料變成人能看得懂的網頁頁面,然后我們就可以在這個頁面內選擇我們需要的內容進行保存,也即「篩選資料」,
2.爬蟲的作業原理
上介紹到了瀏覽器的作業原理,下面我們開始了解爬蟲,爬蟲,從本質上來說,就是利用程式模擬人的瀏覽行為,在網上拿到我們所需要的資料,爬蟲的能力很大,它既能給很多商業公司做資料分析,也能給我們的日常生活提供許多便利,比如我們最熟悉的搜索引擎——百度,它的核心技術之一就是爬蟲,而且是 “一只” 巨大的爬蟲,比如我們輸入一個關鍵詞:
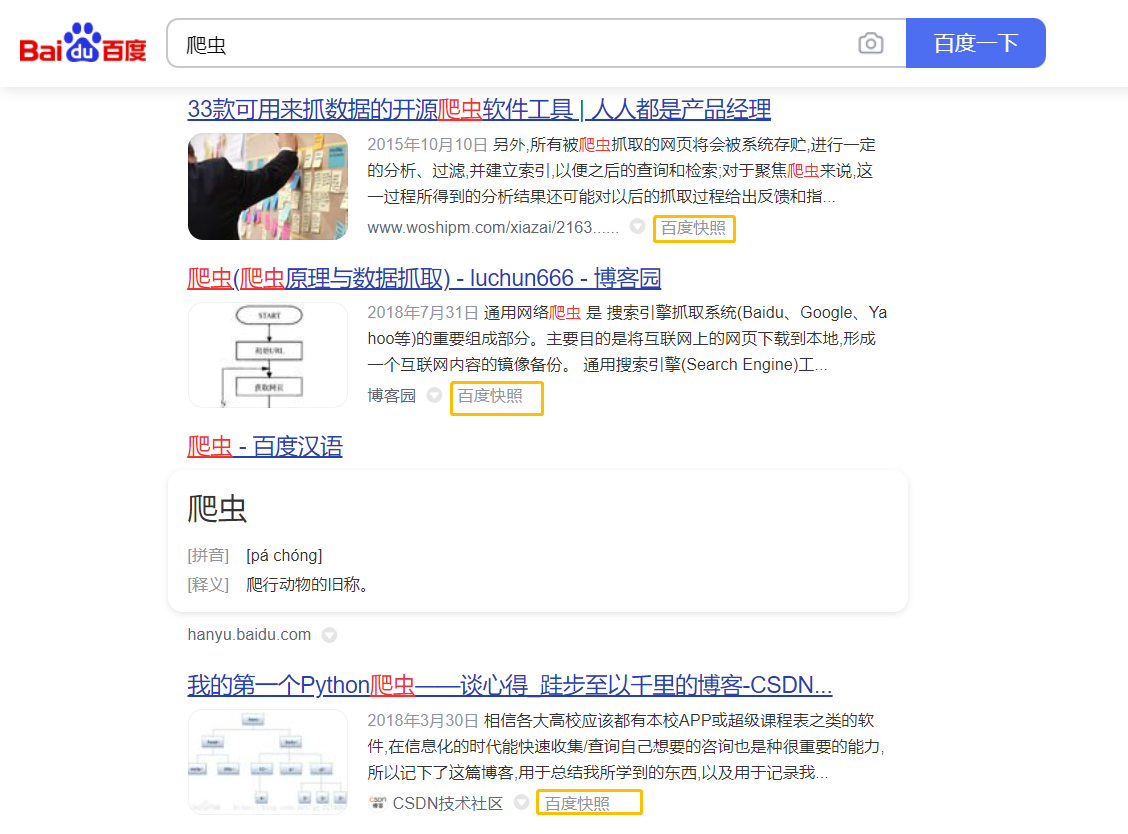
在使用百度搜索的時候,很多搜索結果下都會有一個 “百度快照” 的按鈕,然后我們做一個實驗,選一個結果分別點擊詞條和百度快照,對比以下顯示結果:
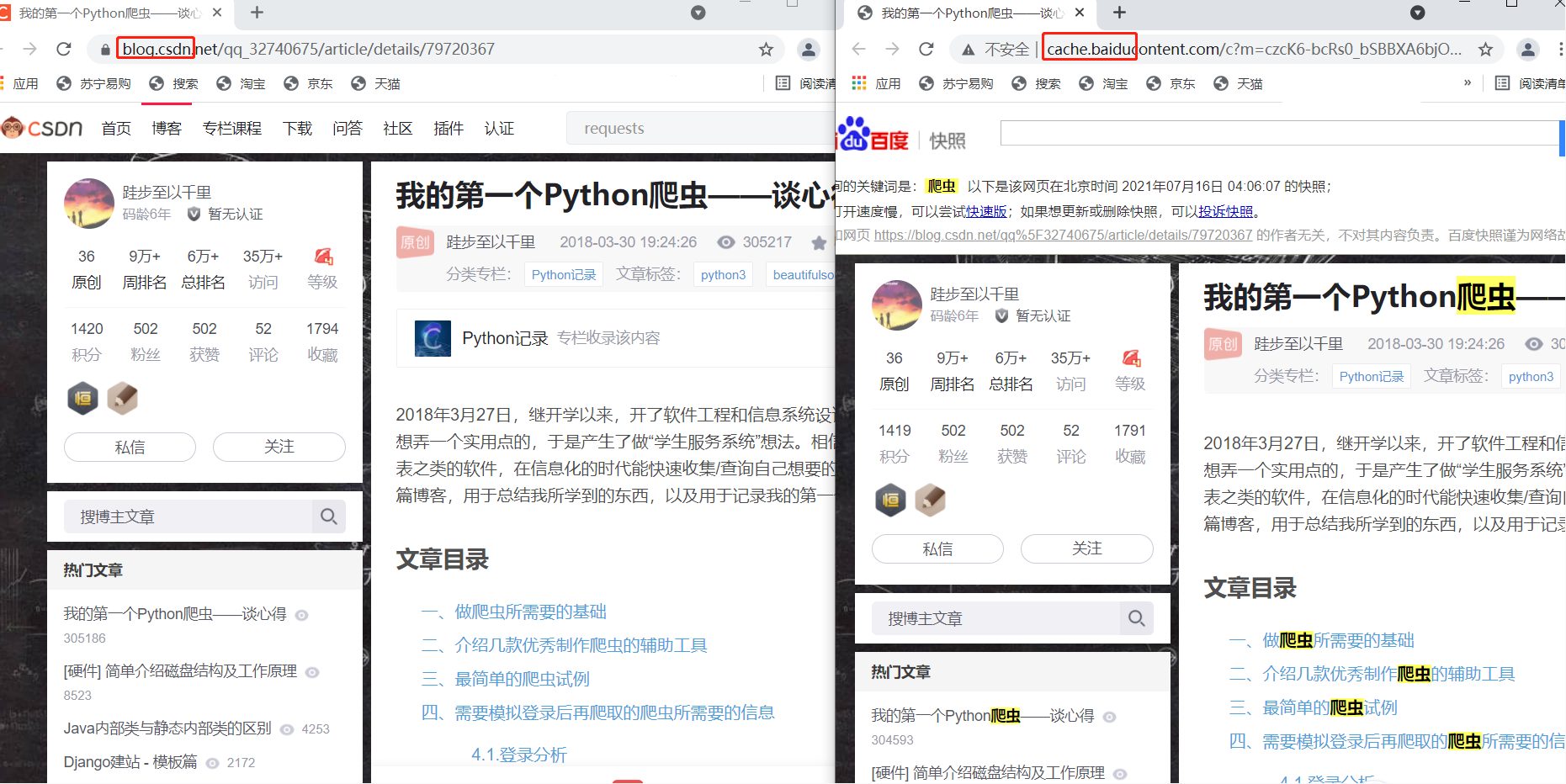
左面是點擊詞條進入的,右面是點擊百度快照進入的,可以發現這兩個頁面顯示內容是一樣的,但點擊百度快照進入的網頁,其網址含有baidu字樣,也就是這個網頁屬于百度而非CSDN博客,百度搜索的爬蟲會一直在互聯網上 “爬行”,把爬到的所有網站都保存到百度的服務器上,所以在百度搜索中能夠搜到這些網站的超鏈接,點擊后就可跳轉到相應的網站,因此,我們和瀏覽器互動的程序也就成了:

然而爬蟲的功能遠不止于此,我們從網頁內摘取有用的資訊并保存的要求,爬蟲都可以替我們完成,學會了爬蟲,篩選資料、保存資料的程序就可以有爬蟲一并代勞:

牢記爬蟲的四個步驟:獲取資料、決議資料、篩選資料、存盤資料
2.1初識爬蟲撰寫
i.了解requests庫
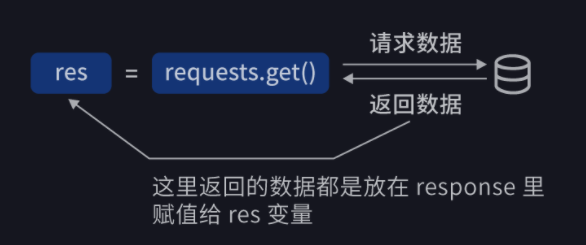
Python 是一門面向物件編程的語言,在面向物件的世界中,一切皆可為物件,Response 也是一個物件,它有自己的屬性和方法,下面會挑一些常用到的給大家介紹,首先,我們需要用requests庫的get方法完成獲取資料,其具體使用方法為:
import requests
# 參考requests庫
res=requests.get('URL')
# requests庫中get()方法可以向服務器發送請求,URL是我們需要請求的網址
# 當請求得到回應后,服務器回傳的資料就被賦值到變數res里
用一幅圖片來展示這個程序:
注:沒有安裝requests庫的小伙伴請回到文章開頭進行相關環境的搭建
下面給大家提供一個練習URL,網頁的內容為《滕文閣序》
import requests
res=requests.get('https://xiaoke.kaikeba.com/example/gexu/tengwanggexu.txt')
print(type(res))
# 輸出res的型別
print(res)
# 輸出為:<class 'requests.models.Response'>
# <Response [200]>
我們希望獲得的結果為res的型別以及網頁的內容,從結果可以看出,res的型別是“requests.models.Response”,但res的內容并不是我們希望看到的,下面給大家具體解釋:
正如我們之前提到,requests是一個物件,它也有自己的屬性和方法,我們最常用的屬性有四種:
| 屬性 | 功能 |
|---|---|
| requests.status_code | 檢測請求是否成功 |
| requests.content | response物件的二進制資料 |
| requests.text | response物件的字符資料 |
| requests.encoding | 查看或修改response物件使用的編碼方式 |
因此我們想要輸出網頁的文字需要對剛剛的代碼進行以下修改:
import requests
res=requests.get('https://xiaoke.kaikeba.com/example/gexu/tengwanggexu.txt')
print(res.status_code)
# 檢測請求是否成功
print(res.encoding)
# 查看response物件使用的編碼方式
# 如果需要修改編碼方式,如改為gbk,代碼要這樣寫:
# res.encoding = 'gbk'
# 有興趣的小伙伴可以嘗試一下,看會有什么樣的結果~
print(res.text)
# 列印網頁的內容
# 輸出為:200
# utf-8
# 「網頁內容」
但是,在運行這段代碼的時候,我們遇到了有些小伙伴可能會遇到編碼錯誤的問題,解決這個問題我們可以改變pycharm的檔案編碼方式的方法解決或者使用重新編譯碼的方式,將最后一句代碼
print(res.text)
改為
res=res.text.encode('utf-8')
print(res.decode('utf-8-sig'))
注:如果出現這樣的錯誤:

在檔案第一行加上“ # coding=UTF8 ”就可以解決,下同,
接下來,我們看看200是個什么意思:
| 回應狀態碼 | 說明 | 例 | 例子解釋 |
|---|---|---|---|
| 1xx | 請求接收 | 100 | 繼續提出請求 |
| 2xx | 請求成功 | 200 | 請求成功 |
| 3xx | 重定向 | 305 | 應使用代理訪問 |
| 4xx | 客戶端錯誤 | 403 | 禁止訪問 |
| 5xx | 服務器錯誤 | 503 | 服務器不可用 |
我們不需要都記清楚,只需要知道除了200之外,其他都是請求遇到問題了,其他的回應碼的具體含義可以在百度上搜索,
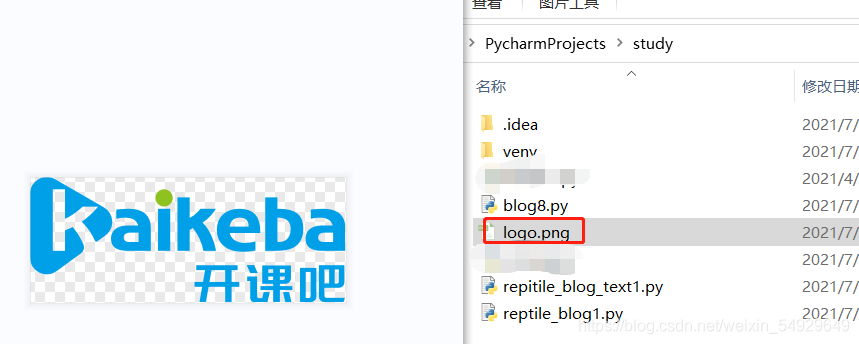
再來說一下requests.content的功能,以二進制資料存盤可以用于存盤影像、音頻、視頻等,我們用一個存有一幅圖片的網頁進行演示:
import requests
res = requests.get('https://img.kaikeba.com/web/kkb_index/img_index_logo.png')
pho=res.content
# pho存盤網頁內圖片的二進制資料
with open('logo.png','wb') as p:
p.write(pho)
這里沒有輸出結果,但會生成一個png檔案,存盤網掌上的圖片:
到這里,response的幾個基礎功能我們就介紹完了,
二、簡要學習HTML
借用爬蟲去網頁爬取資料,必須了解一個網頁的結構,所以我們先學習網頁的基礎 —— HTML,
1.什么是HTML
HTML(Hyper Text Markup Language) 是用來描述網頁的一種語言,也叫超文本標記語言,把文本和文本以外的相關資訊(例如大小,高度,顏色,位置等)組合在一起的語言,
HTML 是前端工程師使用的語言,用來設計 “網頁的結構圖”, 通過瀏覽器輸入網站,瀏覽器會去這個網站對應的服務器請求,然后這個服務器會回傳給我們這個網頁的 HTML 代碼,進而瀏覽器會把 HTML 決議成我們看到的網頁,
下面我們用一個演示網站一起學習HTML代碼,(請使Google Chrome瀏覽器進行實操),打開網頁后點擊右鍵,選擇查看源代碼(或ctrl+u),而后我們就可以看到HTML的源代碼了:
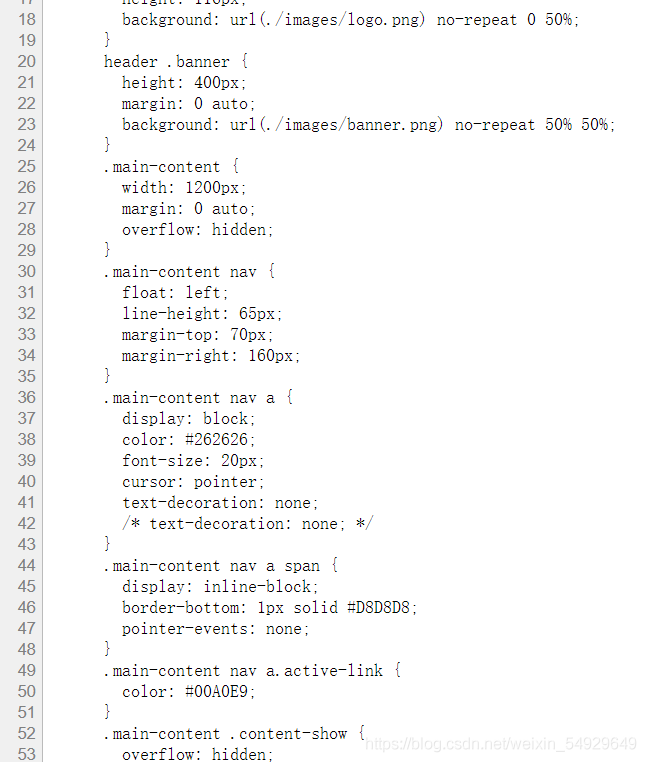
代碼可以在一個新的頁面看到,但是大部分網站都會將 HTML 代碼壓縮,查看的時候比較費勁,所以我們可以在網頁的空白處點擊右鍵,然后選擇 “檢查”(ctrl + Shift + I),就可以在一個頁面下見到網頁內容和源代碼類容了:
當我們把滑鼠移動到代碼上時,滑鼠選到的這行代碼對應著的左側網頁上這部分內容會被標亮,可以看到上述圖片中,很多陳述句前都會有一個三角形符號,點擊可以展開或合上對應的一段代碼,這代表了HTML的層級關系,每一個可以展開和合上的小三角形里包含的內容,都是一個層級,它很像電腦中一層一層的檔案夾,下面我們來具體學習HTML代碼:
2.HTML的標簽和元素
我們先建立一個.txt檔案,在檔案內寫入以下內容:
<html>
<head>
<meta charset="utf-8">
</head>
<body>
<h1>我是一級標題</h1>
<h2>我是二級標題</h2>
<h3>我是三級標題</h3>
<p>我是一個段落啦</p>
</body>
</html>
然后保存起來,將檔案的后綴改為.html,雙擊打開就可以看到一個網頁:

在這段代碼中,我們可以看到很多的“<>”括號,這種尖括號里面包含的就是標簽,標簽通常成對存在,分為開始標簽(如< body >)和結束標簽(如< /body >),當然也有單獨出現的標簽比如 < meta charset=“utf-8” >,定義網頁編碼格式,
除了標簽之外,我們還需要了解元素,所謂的元素,就是開始標簽和結束標簽以及夾在其之間的內容:

下面我們列出一些常用的元素:
| 開始標簽 | 標簽意義 | 結束標簽 |
|---|---|---|
| < h1 > | 一級標題 | < /h1 > |
| < h2 > | 二級標題 | < /h2 > |
| < a > | 鏈接 | < /a> |
| < div > | 塊,用來包含其他標簽 | < /div > |
| < p > | 段落 | < /p > |
這就是HTML的一些基礎知識了,
3.< head > 和 < body >
回到剛才的例子,我們可以看到在HTML的最外層有一個< html >標簽,下面分別是< head >和< body >,< head > 元素就是網頁頭,< body > 元素就是網頁體,他們構成了HTML的基本結構,也就是HTML的框架實際上是:

HTML中的元素和網頁的內容是對應的, 但是網頁頭的內容是不會在網頁中顯示的,網頁上看到的內容都是寫在網頁體里面的,讓我們逐個了解:
3.1< head >
<head>
<meta charset="utf-8">
<title> title 標簽里面包含的就是網頁的名字 </title>
</head>
meta標簽負責定義網頁的編碼格式,title元素用來設計網頁的標題,會顯示在瀏覽器的選項卡上:
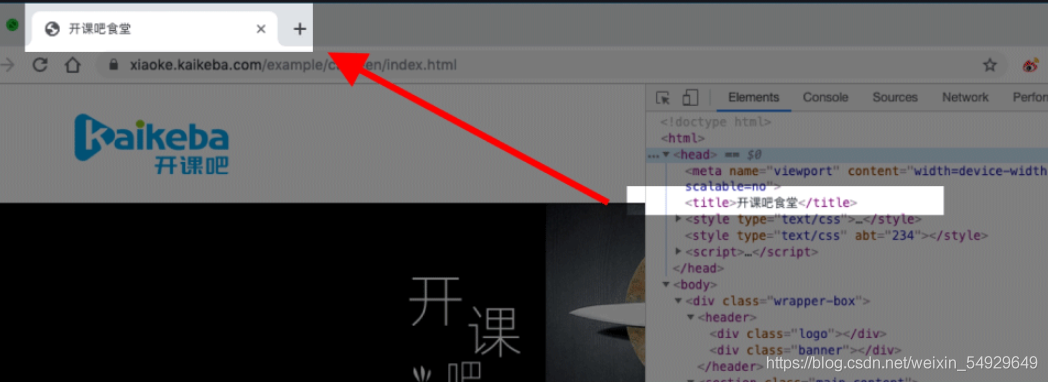
3.2< body >
前面已經介紹過,< head >標簽中的內容只會顯示在瀏覽器的選項卡上,所以想要在網頁的內容中顯示的元素,要寫到 < body > 標簽中,我們對上文中的例子做一些完善:
<html>
<head>
<meta charset="utf-8">
<title>選項卡標題</title>
</head>
<body>
<h1>我是一級標題</h1>
<h3>我是三級標題</h3>
<h2>我是二級標題</h2>
<p>我是一個段落啦</p>
</body>
</html>
還是按照上文的方法操作,打開網頁后,我們就可以看到:
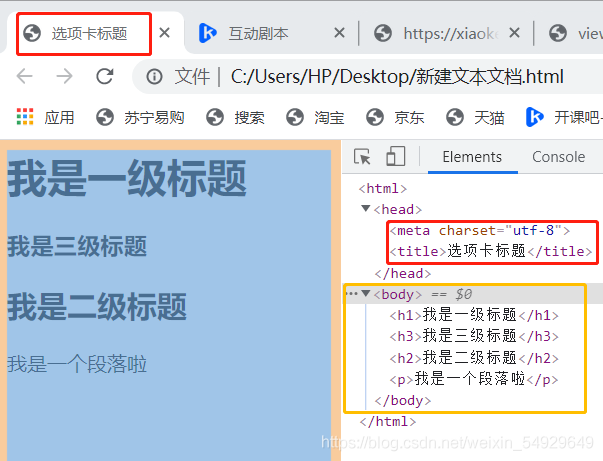
4.設定標簽的屬性
我們先來觀察以下代碼:
<html>
<head>
<meta charset="utf-8">
<title>選項卡標題</title>
</head>
<body>
<h1 style="color:#ff0000;">歡迎來到我的主頁</h1>
<a href="https://blog.csdn.net/weixin_54929649?spm=1001.2100.3001.5343" target="_blank">這里是我的主頁~</a>
<br>
<p>感謝大家的支持,博主會為大家繼續帶來作品~</p>
</body>
</html>
打開網頁,可以發現< h1 > 標簽的顏色發生了改變,下面還添加了一個博主主頁的鏈接,這些都是靠標簽的屬性1來完成的:
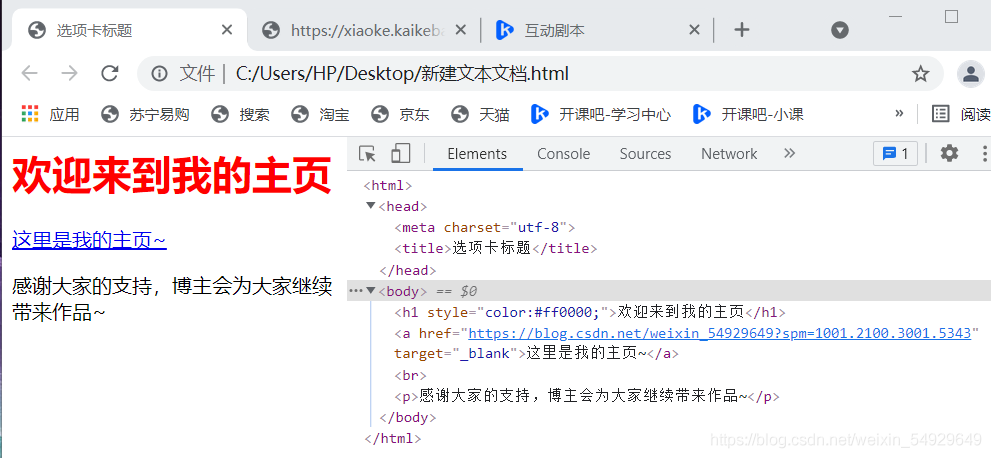
通過 HTML 屬性,我們可以給標簽設定各種資訊,這里的
<h1 style="color:#ff0000;">歡迎來到我的主頁</h1>
就是給< h1 >標題添加style屬性,顯示字體為紅色,HTML的屬性格式為:
<「開始標簽」「space」「style="開始標簽(例)" 」>
“style” 屬性可以用來給文本類的標簽定義多種樣式,包括但不限于字體,字體顏色,字體大小,字體間距,文字對齊方式,屬性只能在 HTML的開始標簽中設定,在結束標簽中設定屬性不會生效,
在上面的例子中,我們還添加了一個可以跳轉到官網的文字鏈接:
<a href="https://blog.csdn.net/weixin_54929649?spm=1001.2100.3001.5343" target="_blank">這里是我的主頁~</a>
< a > 標簽本身只是一個文字標簽,用于展示文字內容,但加上了 “href” 屬性之后,就可以為這段文字系結一個鏈接,系結后,我們可以通過點擊文字直達規定的URL地址,
5.兩個常用屬性:class & id
設想一下以下場景:網頁需要有一個統一的字體樣式,我們需要怎么來設定?
最樸素的辦法就是給每一段文字單獨設定字體樣式,但是這種方法會讓作業量大大增加,有沒有什么簡單的辦法幫我們完成這樣的作業呢?
在 HTML 檔案中,我們有一個關鍵詞為 “class” 的屬性,“class” 可以使屬性值相同的元素復用同一套樣式,修改一下我們之前的文本:
<html>
<head>
<meta charset="utf-8">
<title>選項卡標題</title>
<style>
.menu { /*以下是.menu的具體樣式規定*/
float: left; /*控制元素浮動*/
margin: 10px; /*新建框外邊距左側邊框和上文文字均為 10 像素*/
padding: 15px; /*文字與上述邊框上下左右距離為均 15 像素*/
width: 350px; /*新建邊框橫向長度為 350 像素*/
height: 100px; /*新建邊框縱向高度為 100 像素*/
border: 3px solid #ff0000; /*新建邊框線條粗細為 3 像素,顏色為 ff0000*/
}
</style>
</head>
<body>
<h1 style="color:#ff0000;">歡迎來到我的主頁</h1>
<h3>希望我的分享可以給大家帶來幫助:</h3>
<a href="https://blog.csdn.net/weixin_54929649?spm=1001.2100.3001.5343" target="_blank">這里是我的主頁,歡迎您的訪問~</a>
<p></p>
<div class="menu">
<p>我是一個小程式員,通過寫博客的方式記錄我的學習程序,希望我的分享可以幫大家解除疑惑,也歡迎大家關注我,能給個贊的話更是不勝榮幸啦~
</p>
</div>
</body>
</html>
這段代碼新增了一個屬性,其代表的意義在的對應位置有所注釋,我們來看修改后的檔案樣式:
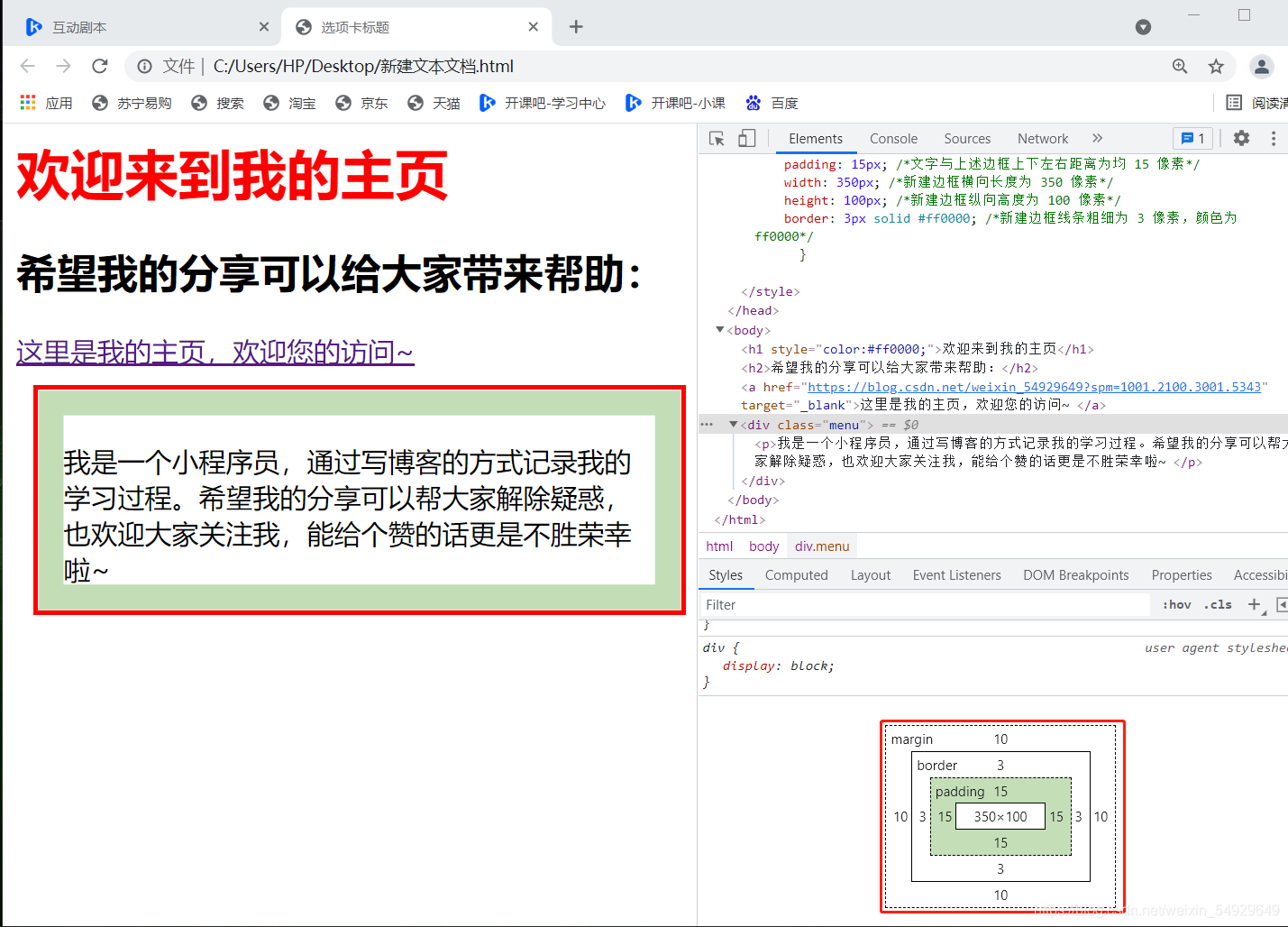
注:右下角用紅框圈出來的圖示就是我們使用的自定義menu,把滑鼠移到不同的單詞上,左側對應的部分會增亮,可以更直觀的學習,
觀察這段代碼,我們可以發現,在 < head > 的 < style > 中,我們定義了一個 “class”(menu前面的「.」)叫做 “menu” ,后面的大串樣式代碼是對 “menu” 這個“class” 的屬性進行了描述,后面我們在 < body > 中的 < div > 標簽定義它的 “class” = “menu” ,那么這個標簽里就和 < head > 中 “menu” 定義的樣式產生聯系,也可以認為在這里使用了menu,在HTML中, 一個“class” 屬性可以被多個不同的標簽使用,用法相同,有興趣的小伙伴可以自行嘗試2,
說完class,我們來說一下id,id與class在< body >中的用法類似,它們存在的目的都是為了查找、定位元素,或者為元素設定樣式,但是,id在< head >中的寫法可是和class大不相同,下面我們用id來描述上述class描述出的樣式:
<html>
<head>
<meta charset="utf-8">
<title>選項卡標題</title>
<style type="text/css">
#menu {float: left; margin: 10px;padding: 15px;width: 350px;height: 100px; border: 3px solid #ff0000;}
</style>
</head>
/*后面的代碼和之前基本一樣,只是把“class=”改成了“id=”,此處不再放了*/
仔細觀察兩者間< style >的不同,這幾乎是兩個屬性唯一的區別了,
定義上,“id” 屬性用于標識唯一的元素,而 “class” 用于標識一系列的元素,因此兩者的關系可以以下圖表示:

現在,我們可以對常用的屬性進行一個總結了:
| 屬性 | 用途 |
|---|---|
| class | 為HTML設定類名 |
| id | 為HTML元素設定唯一的id |
| href | URL融入文字 |
| style | 定義元素的樣式 |
6.HTML的閱讀和修改
不知不覺,我已經學完了HTML 的組成:標簽、元素、結構、屬性,現在讓我們對照網頁,嘗試閱讀一下:練習網址
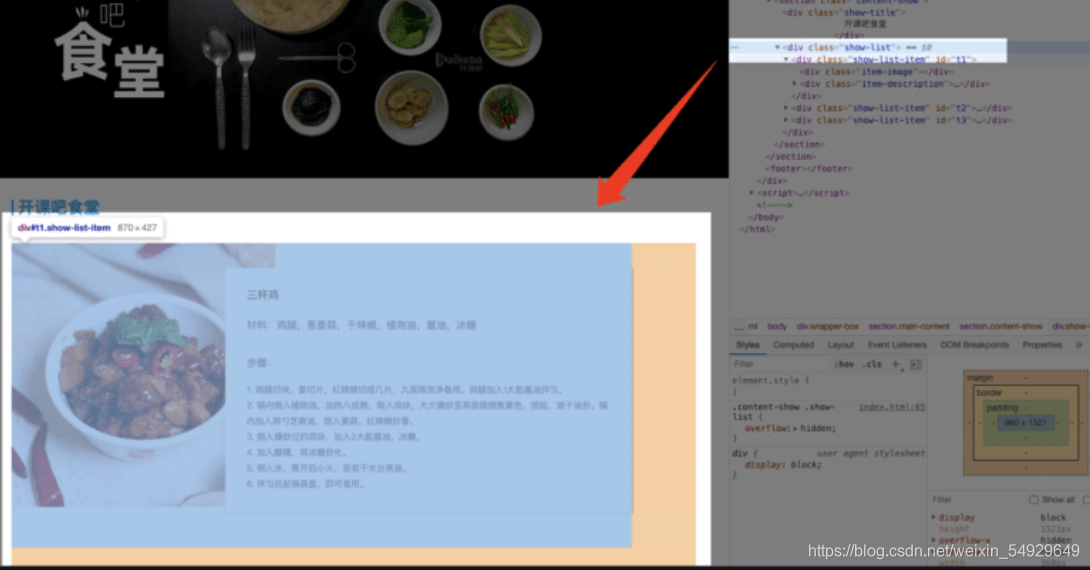
網頁體有三大部分,< header >、 < section > 、< footer >,分別對應了我們看到的網頁的頭部,中間內容,底部,
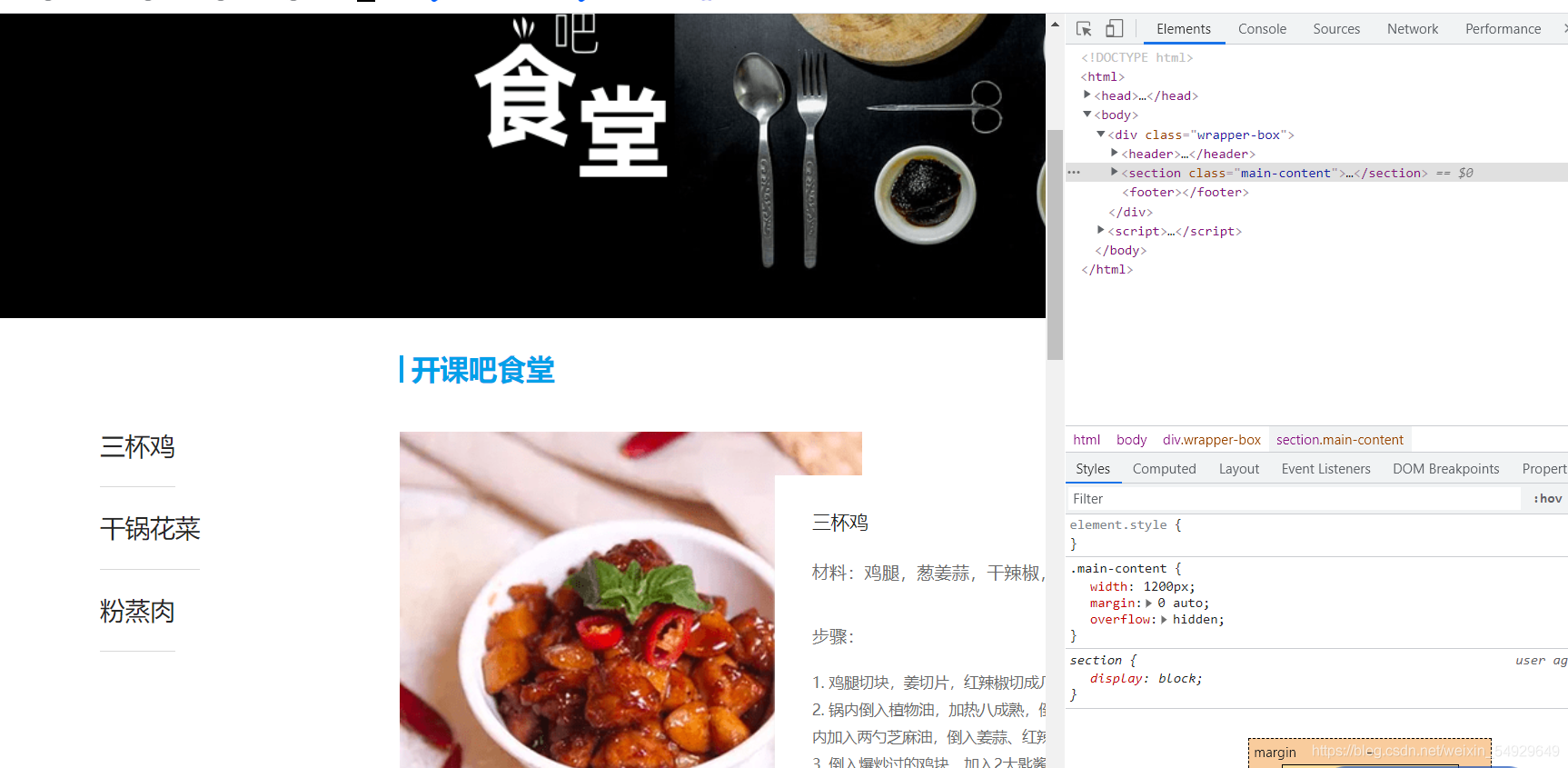
展開 < header > 標簽,可以看到 < div class=“logo” > 和 < div class=“banner” > ,分別代表了最上面的網頁 logo 和 logo 下面的 “開課吧食堂” 大圖:
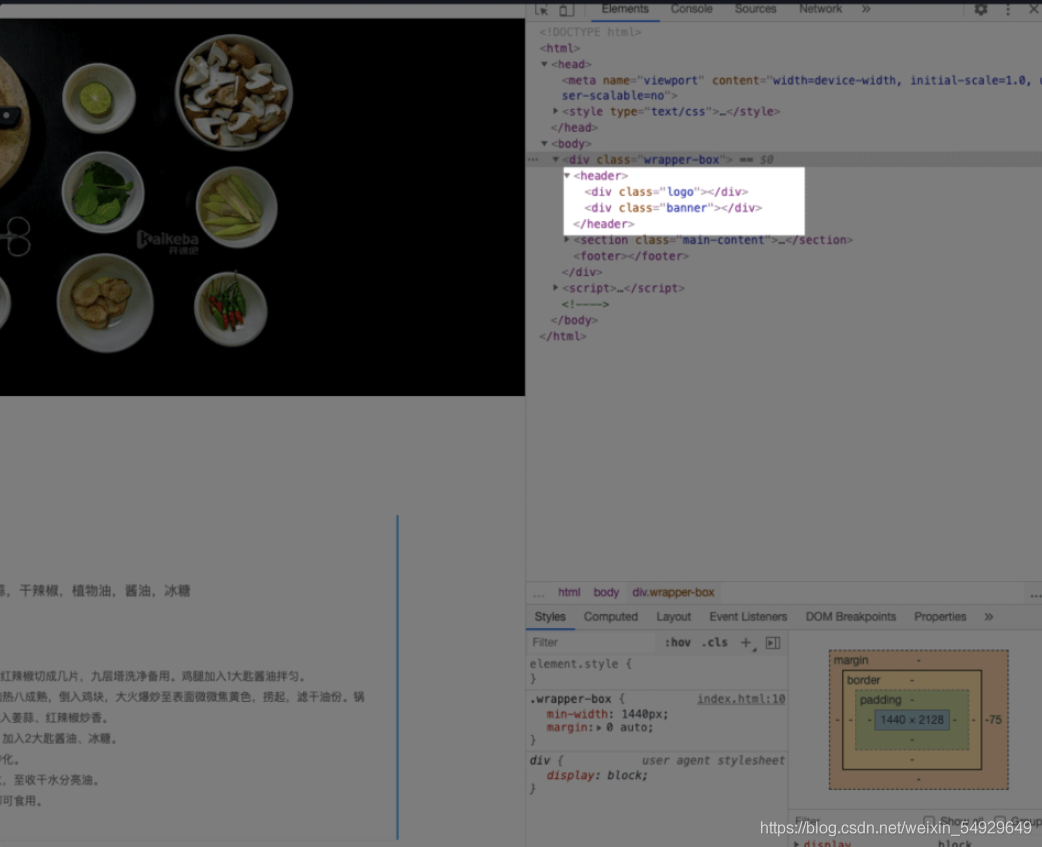
接著我們看看代表網頁正文的
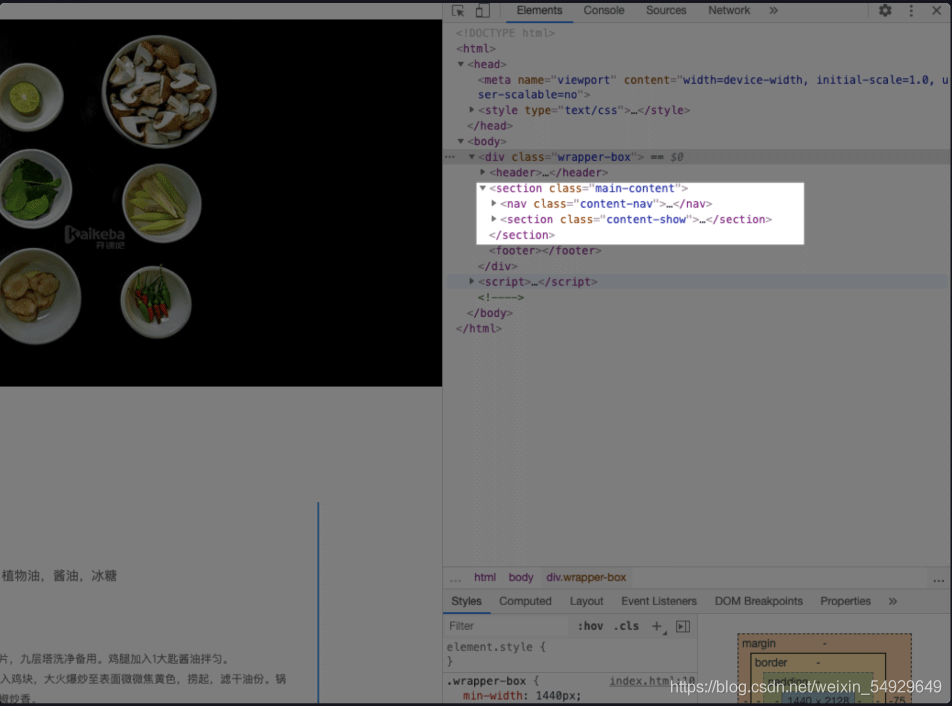
< section > 里面分為兩部分,分別是 < nav class = “content-nav” > 和 < section class = “content-show” > ,代表了左邊的菜品導航欄和右邊的菜品內容,
很多標簽的英文意思差不多對應了它的用途,比如說在 < body > 中的 < header > ,就定義了網頁的最上面,也就是頭部的部分,最下面的部分由 < footer > 標簽來定義, < nav > 就是 Navigation 這個單詞的縮寫,也就是導航欄的意思:
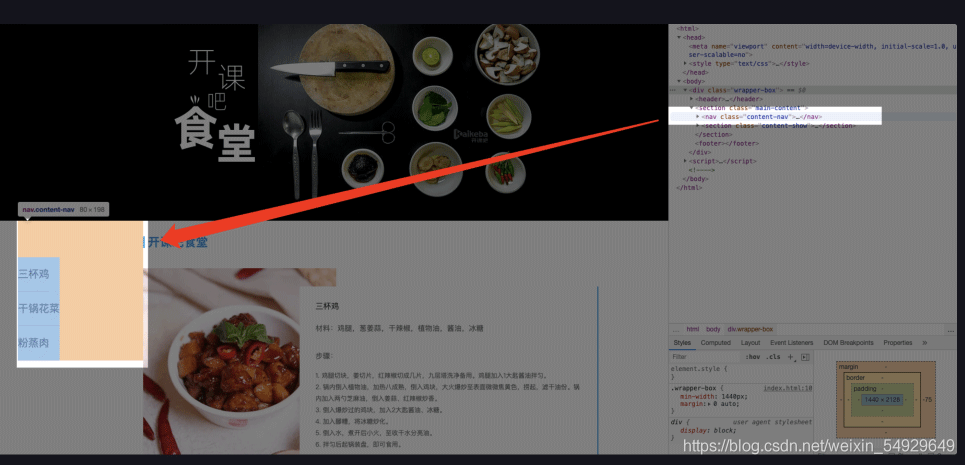
每個 < div > 都包含了一個 < a > 標簽,分別對應了三個菜品 “三杯雞”,“干鍋花菜” 和 “粉蒸肉”,他們都由 “href” 屬性定義了一個內部鏈接,點擊的話,頁面會滾動到相應菜品的位置,
接下來我們展開 < section >,里面先用一個 < div > 定義了標題,然后一個 < div > 定義了一個菜品串列,展開菜品串列的 < div class = “show-list” > ,里面又是三個 < div class = “show-list-item” >:
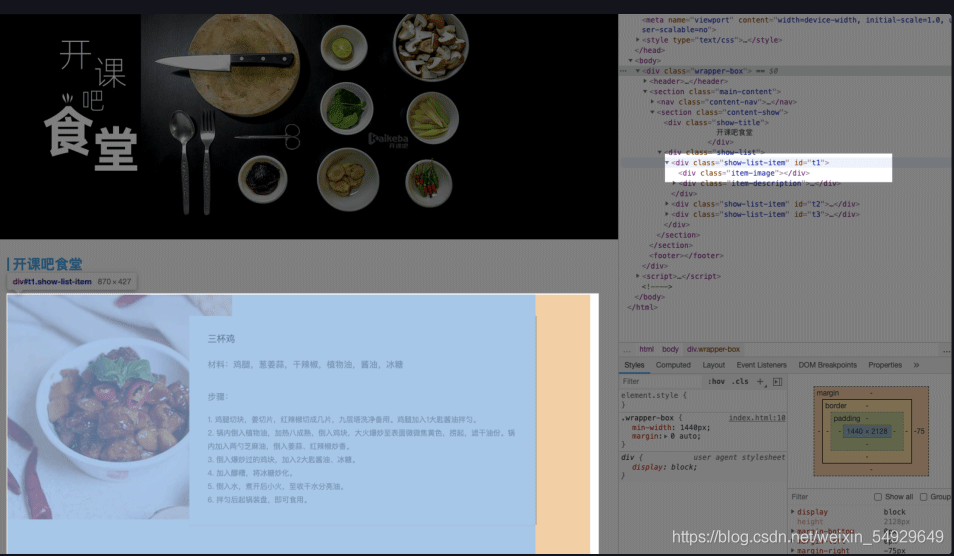
這樣,我們也就基本上可以看懂代碼在說什么了,雖然很多陳述句都還沒有接觸到,不過并不妨礙我們對網頁有了一個宏觀的理解,想深度學習的小伙伴給大家推薦一個網站: w3school
下面我們學習修改網頁,首先,給大家介紹一個功能:
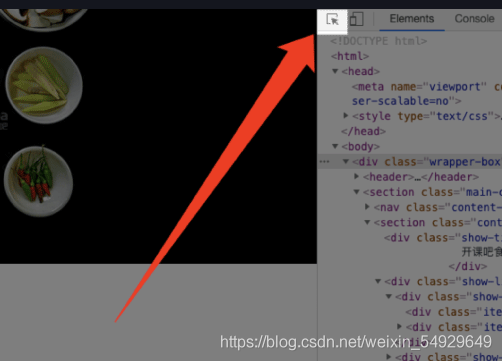
點擊這個圖示,然后把滑鼠移到左面頁面想要修改的位置,對應的代碼就會在右側高亮:
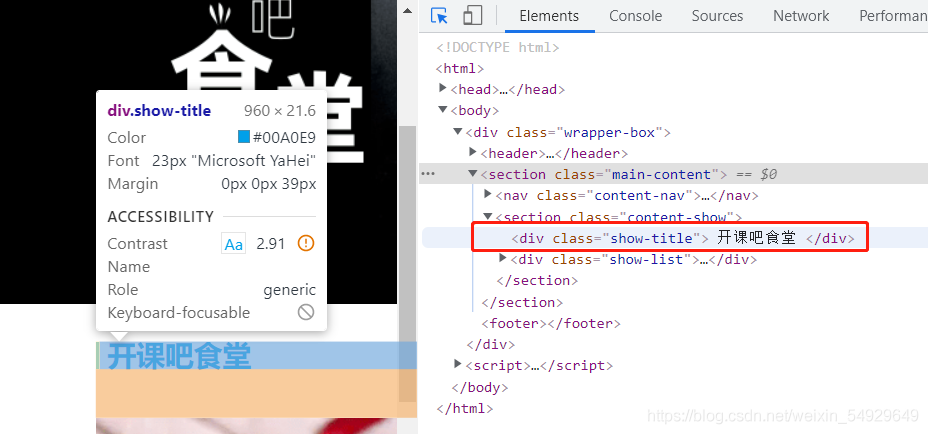
如果我們想修改這五個字,就可以雙擊高亮部分的文字,從而進行修改,或者右擊這行代碼選擇Edit as HTML,然后進行修改,修改之后我們可以看到網頁的變化:
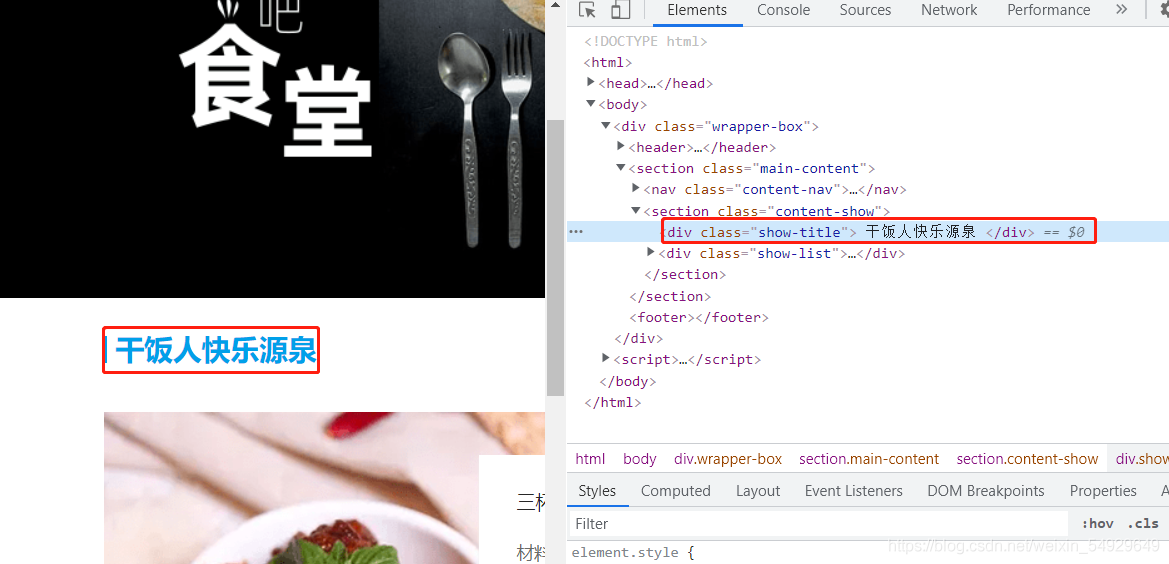
這種方法很常用,如修改價格、清單等,但需要注意的是,我們這樣的改動只能在當且頁面生效,如果重新打開頁面,顯示的還是修改前的內容,
三、撰寫第一個爬蟲
在這一節中我們學習如何在已有的網頁源代碼中獲取需要的資訊,這個程序需要借助BeautifulSoup 模塊,
1.BeautifulSoup模塊功能簡述
先讓我們回顧一下爬蟲的四個步驟:獲取資料、決議資料、提取資料、存盤資料,在第一節的學習中,我們介紹了獲取資料, 第二節的HTML知識,則有助于我們決議和提取網頁源代碼中的資料,而BeautifulSoup模塊的主要功能在于決議資料和提取資料,那么什么是決議資料呢?我們在瀏覽網頁時,服務器會回傳HTML的源代碼,瀏覽器需要將代碼翻譯成我們能看懂的樣子,之后我們才能閱讀網頁進行各種操作,這個程序就叫做決議資料,相應地,爬蟲也需要使用類似的工具將HTML源代碼翻譯成程式員讀得懂的代碼,在決議資料完成后,我們需要將需要的資料從源代碼中有針對性的提取出來,這個程序就叫提取資料,
2.BeautiSoup的使用
2.1 使用BeautiSoup決議資料
BeautifulSoup 決議資料的方法比較容易理解:
bs物件=BeautiSoup(要決議的文本,'決議器')
需要被決議的文本必須是字串型別的值或變數,決議器的種類有很多,這里介紹一個 Python 內置庫:html.parser,這個決議器相對來說比較簡單,下面我們觀察以下代碼:
import requests
from bs4 import BeautifulSoup as bs
ht=requests.get('https://xiaoke.kaikeba.com/example/canteen/index.html')
print(type(ht.text))
# 查看ht.text的資料型別
print(ht.text)
# 查看ht.text內容
soup=bs(ht.text,'html.parser')
# 第一個引數必須是字串型別的資料,所以要寫成ht.test
print(type(soup))
# 查看soup的資料型別
print(soup)
# 查看soup的內容
# 輸出為:<class 'str'>
# 網頁的源代碼
# <class 'bs4.BeautifulSoup'>
# 網頁的源代碼
觀察結果不難發現,列印soup和ht.text的結果都為網頁的源代碼,好像雖然使用了 BeautifulSoup來決議資料,但從直觀上來看,得到的結果和沒決議之前一樣,不過仔細觀察可以發現,這兩者的型別并不相同,列印出來的是一樣的文本,是因為BeautifulSoup物件在直接列印它的時候會自動呼叫該物件內的str方法,所以直接列印bs物件顯示字串是str的回傳結果,
之后我們還需要進行提取資料的操作,如果我們得到的結果是沒有經過決議的,也就是說沒有一個BeautifulSoup物件,將無法呼叫相關的屬性和方法,所以使用BeautifulSoup庫進行決議是必要的,
2.2使用BeautifulSoup庫提取資料
上文已經將網頁的源代碼保存到了變數soup里,下面我們就要學習如何從soup里提取出我們需要的內容,首先給大家介紹一個函式select,這個函式可以幫助我們在bs4.BeautifulSoup型別的變數中提取所需要的資訊:
| 格式 | 示例 | 功能 |
|---|---|---|
| 變數名.select(‘標簽名’) | soup.select(‘div’) | 提取對應標簽名(< div >)下的所有內容 |
| 變數名.select(’.類名’) | soup.select(’.desc-material’) | 提取< body >中使用了該類名的所有內容 |
| 變數名.select(’#id名’) | soup.select(’#form’) | 提取< body >中使用了該id名的標簽,這里會輸出< form …>…< /form >這段內容 |
| 變數名.select(‘標簽名#id名’) | soup.select(‘a#link’) | 組合查找,提取開始標簽內同時含a和id=link的內容 |
| 變數名.select(‘外標簽>內標簽’) | soup.select(‘head>tittle’) | 提取< head >標簽下的< tittle >標簽內容 |
下面我們舉個例子,提取演示網頁中的菜名
首先,我們找到菜名對應的標簽:
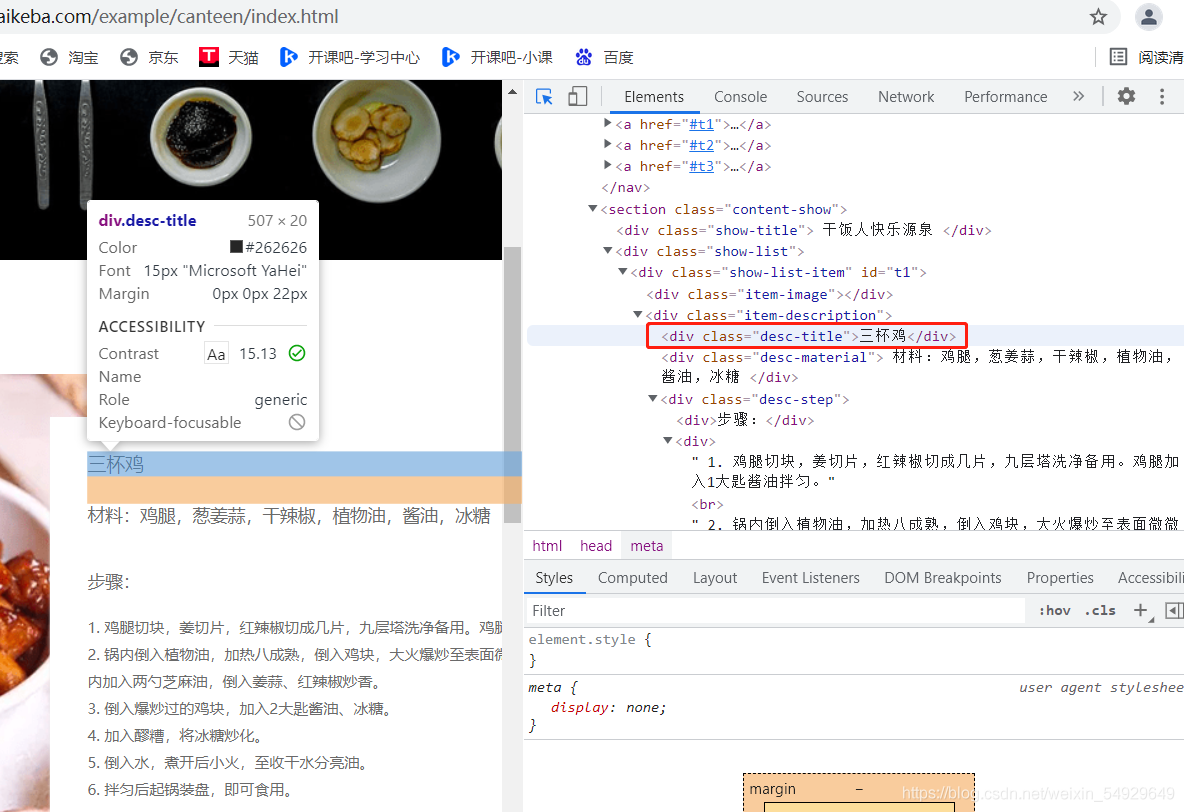
看到了class=“…”了嗎?這說明菜名前都會呼叫class,因此我們可以用變數名.select(’.類名’) 格式提取所有的菜名:
import requests
from bs4 import BeautifulSoup as bs
res=requests.get('https://xiaoke.kaikeba.com/example/canteen/index.html')
html=res.text
sp = bs(html, 'html.parser')
desc=sp.select('.desc-title')
print(desc)
print(type(desc))
# 查看desc的型別
# 輸出為:[<div class="desc-title">三杯雞</div>, <div class="desc-title">干鍋花菜</div>, <div class="desc-title">粉蒸肉</div>]
# <class 'bs4.element.ResultSet'>
這樣一來我們的菜名就都找出來了,看到desc的資料型別和列印出的結果不難發現,bs4.element.ResultSet的資料型別非常類似于串列,事實上,我們可以把他就當做串列進行后續處理,其實提取內容一般都可以依據標簽和屬性進行,因此給大家介紹函式find()和find_all():
| 方法 | 作用 | 用法 | 示例 | 要點提示 |
|---|---|---|---|---|
| find() | 提取滿足要求的首個資料 | 物件.find(標簽,屬性) | desc.find(div,class_=‘desc-title’)或desc.find(class_=‘desc-title’) | 標簽和屬性任選其一或同時存在 |
| find_all() | 提取滿足要求的全部資料 | 物件.find_all (標簽(可省略),屬性) | desc.find(div,class_=‘desc-title’) | 標簽和屬性任選其一或同時存在 |
這個種用法和select的功能相似,并且這兩種函式可以滿足我們大部分的需求,需要注意的是,當使用的定位屬性是class時,需要寫成class_= '…'的形式,用以區分python語法中的類,大家可以將上文代碼中的
desc=sp.select('.desc-title')
替換為
desc=sp.find_all('class_=desc-title')
運行看結果(輸出結果和型別)是否一致,
我們使用
print(desc)
列印出來的內容是一個bs4.element.ResultSet(理解成串列)型別的資料,因此,如果需要把這部分內容存入我們自己的txt檔案中,就需要將串列中的每個元素逐一列出:
**加粗樣式**import requests
from bs4 import BeautifulSoup as bs
res=requests.get('https://xiaoke.kaikeba.com/example/canteen/index.html')
html=res.text
sp = bs(html, 'html.parser')
desc=sp.find_all(class_='desc-title')
with open('menu.txt','a') as f:
for i in desc:
f.write(i+'\n')
我們希望這樣就可以得到一個不夠完美的檔案,里面存著菜名和一部分網頁源代碼,運行試試:
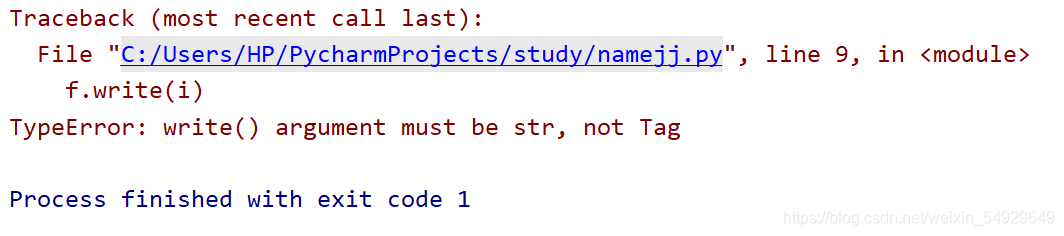
這里出現了一個錯誤提示,從這個提示中,我們可以看出,i是一個Tag型別的資料,是 Tag 物件,而write函式只能操作str型別,那么什么是Tag物件呢?
可以查看一下,無論使用.find_all()、.find()還是.select() 提取到的資料都是Tag物件,Tag物件也有屬于自己的屬性和方法,這里介紹幾個最常用的:
| 屬性/方法 | 作用 |
|---|---|
| < bs4.BeautifulSoup>型別資料.find(引數) / find_all(引數) | 提取內容,結果為Tag,如果沒填寫引數則把< bs4.BeautifulSoup>型別資料轉化為< bs4.BeautifulSoup.Tag>型別資料 |
| Tag物件. text | 提取Tag物件中的文字 |
| Tag[‘屬性名’] | 提取Tag中的這個屬性的值 |
這么看來,我們使用Tag.text可以直接在提取到的源代碼中篩選文字內容進行保存,修改一下之前的代碼驗證看看:
import requests
from bs4 import BeautifulSoup as bs
res=requests.get('https://xiaoke.kaikeba.com/example/canteen/index.html')
html=res.text
sp = bs(html, 'html.parser')
desc=sp.find_all(class_='desc-title')
with open('menu.txt','a') as f:
for i in desc:
f.write(i.text+'\n')
運行后,我們看到一個新的檔案:
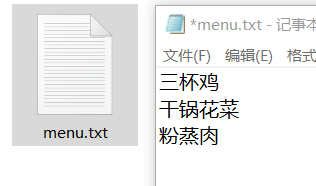
很符合我們的預期,
到這里,我們已經學完了如何使用BeautifulSoup庫的相關知識來決議和提取資料,現在在進行一下梳理:
其實說白了,從最開始用 requests 庫獲取資料,到用 BeautifulSoup 庫來決議資料,再繼續用 BeautifulSoup 庫提取資料,不斷經歷的是我們操作物件的型別轉換,
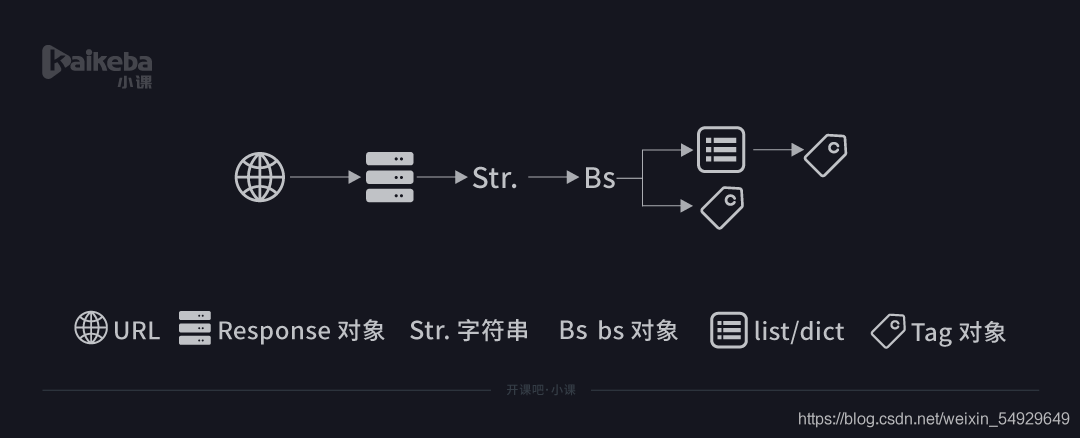
這樣看起來是不是形象很多?那么這次的內容就介紹完了,順便提一嘴,find()和find_all()的引數其實不止標簽和屬性兩種,依照官方的定義,它們的的引數是:
find(tag,attributes,recursive,text,keywords)
find_all(tag,attributes,recursive,text,keywords)
但是上文介紹的方法足以應付大多數情況,因此這里就先不給大家介紹了,有興趣的小伙伴可以去官網學習,
這里的屬性不是python的屬性, ??
比如可以把< div >…< /div >中的內容全部復制再粘貼到< /div >后面查看結果,注意保持相同的縮進, ??
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/290486.html
標籤:其他