提醒:因本文章干貨滿滿,沒有什么廢話,文字很多,大都在分析程序,仔細看一定會有識訓!
??C++最重要的模塊之一就是string類,很多人在這一節點被勸退,在本篇文章中小編將逐個為你們突破,分模塊將string中幾個重要的介面實作,如果對string類有困難的讀者們,強烈推薦仔細閱讀本文章,

??本章沒有廢話,全是干貨,請讀者們仔細閱讀!!!!!!
💜💜💜💜💜💜💜💜💜💜💜💜💜💜💜💜💜💜💜💜💜💜💜💜💜💜💜💜💜💜💜💜💜
1、string類的四個默認成員函式
??一個類有6個默認成員函式,其中取地址多載相關的成員函式這里不做講解,我們實作剩下的四個默認成員函式:
??A:建構式–主要完成初始化作業
??B:拷貝建構式–同類物件的初始化
??C:賦值多載函式–把一個物件賦值給另一個物件
??D:解構式–完成清理作業
??對于上面4個默認成員函式的概念、功能以及呼叫程序我們不在本章贅述,可以查看小編的其他文章,直接干代碼!!!
1.1 建構式
??建構式需要對3個成員變數進行初始化,_size代表有效的資料個數,_capacity代表可容納的有效資料,對于一個5byte大小的記憶體空間,其size最大為4,如果將’\0’看作識別符號,我們認為capacity也為4,所以在初始化的時候,我們將_size,_capacity設定為一樣的值,這時始終要注意還有一個’\0’需要留空間,
??此外,在形參中,我們采用預設值的方式進行初始化:
??a:如果初始化的時候沒有給定初始值,我們就默認給’\0’,此時_size,_capacity均為0,
??b:如果初始化的時候給定初始值,我們就按照初始值進行初始化,此時_size,_capacity的大小就是該字串的有效長度,對于給_str陣列初始化的時候,我們先創建一個和str同樣大小的陣列,這里需要注意的是要給’\0’預留一個位元組的空間,然后呼叫stl中的strcpy函式,至此,建構式的模擬已經實作,
1.2 拷貝構造
??拷貝構造和賦值多載都涉及深淺拷貝的問題,關于深淺拷貝的問題,小編單獨寫一篇文章來幫助大家更好的理解,在這里我們需要知道的是,string類完成的是深拷貝,不僅僅是將值進行拷貝,還要在記憶體中創建一塊空間,存盤相同的內容,
??拷貝構造完成的是同型別之間的拷貝初始化,關于拷貝構造的模擬實作,我們有兩種方式:s2(s1)
方式一: 借用swap函式,首先我們將s2中的成員變數進行置0操作(關鍵!!),然后創建一個string類的臨時物件tmp,并將s1的字串物件傳過去,此時string tmp(s._str);會去呼叫上面的建構式,此時臨時物件tmp中也存在3個成員變數,然后呼叫stl中的swap函式,將s2和s1的三個成員變數分別進行交換,這就保證s2的三個成員變數都是s1的了,重點來了,因為tmp是一個臨時變數,出了作用域就要呼叫其解構式,如果第一步不采用置空的操作,s2的隨機值就會交換給s1,此時free、delete就會導致程式崩潰,但是free和delete是可以對空進行操作的,所以置空保證了程式的正常運行,至于s2為什么是隨機值,因為s2沒有呼叫建構式,而且已經被定義出來了,系統會默認給一個隨機值,
1.3 賦值多載
??賦值多載也是一種拷貝行為,拷貝構造是創建一個物件時,拿同類物件初始化的拷貝,這里的賦值多載時兩個物件已經都存在了,都被初始化過了,現在想把一個物件,賦值拷貝給另一個物件,關于賦值多載的模擬實作,我們有兩種方式:s3 = s1
方式一: 賦值多載同樣完成的是深拷貝,我們這里采用傳參考回傳,直接呼叫swap函式,將s3的三個成員變數與s1的三個成員變數進行交換,這里s采用的傳值傳參,這里會發生一次深拷貝,將s1的三個成員變數拷貝給s,然后s再和s3進行交換,如果采用傳參考傳參會導致s1發生變化,最后將s2回傳即可,
!!!拷貝構造和賦值多載的模擬實作中大量重復使用了swap函式,這里我們可以寫一個swap函式用來實作代碼的復用,!!!
1.4 解構式
??解構式的實作就比較簡單了,就相當于置空操作,代碼如下:
namespace XD
{
class string
{
public:
//1.1 建構式
string(const char* str = "")
{
_size = strlen(str);
_capacity = _size;
_str = new char[strlen(str) + 1];
strcpy(_str, str);
}
//未代碼復用前:
/*
//1.2 拷貝構造
string(const string& s)
{
_str = nullptr;
_size = 0;
_capacity = 0;
string tmp(s._str);
::swap(_str, tmp._str);
::swap(_size, tmp._size);
::swap(_capacity, tmp._capacity);
}
//1.3 賦值多載
string& operator=(string s)
{
::swap(_str, s._str);
::swap(_size, s._size);
::swap(_capacity, s._capacity);
return *this;
}
*/
//代碼復用后:
void swap(string& s)
{
//加一個域作用限定符,這樣swap就會去全域域尋找,就會找到庫函式中的swap
::swap(_str, s._str);
::swap(_size, s._size);
::swap(_capacity, s._capacity);
}
string(const string& s)
{
_str = nullptr;
_size = 0;
_capacity = 0;
string tmp(s._str);
swap(tmp);
}
string& operator=(string s)
{
swap(s);
return *this;
}
//1.4 解構式
~string()
{
delete[] _str;
_str = nullptr;
_size = 0;
_capacity = 0;
}
//輸出該物件
char* c_str()const
{
return _str;
}
private:
char* _str;
size_t _capacity;
size_t _size;
};
}
//四個默認建構式測驗
void Test1()
{
XD::string s1("Hello World!");
cout << s1.c_str() << endl;
XD::string s2(s1);
cout << s2.c_str() << endl;
XD::string s3;
s3 = s1;
cout << s3.c_str() << endl;
}
int main()
{
Test1();
return 0;
}
1.5 拷貝構造和賦值多載的方法二:
??這兩個方法本質一樣,唯一不同就是賦值多載的時候要先洗掉原s3,因為s1的大小不知道,即s1和s3記憶體空間大小不確定,所以要先洗掉s3,然后創建一個與s1同樣大小的記憶體空間,
//a:s2(s1)--拷貝構造
string(const string& s)
{
_size = strlen(s._str);
_capacity = _size;
_str = new char[strlen(s._str) + 1];
strcpy(_str, s._str);
}
//b:s3 = s1--賦值多載
string& operator=(const string& s)
{
if (this != &s)//防止自己給自己賦值s1 = s1
{
delete[] _str;
_size = strlen(s._str);
_capacity = _size;
_str = new char[strlen(s._str) + 1];
strcpy(_str, s._str);
}
return *this;
}
程式運行結果如圖: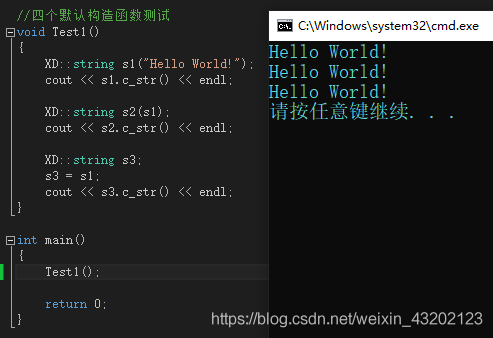
💚💚💚💚💚💚💚💚💚💚💚💚💚💚💚💚💚💚💚💚💚💚💚💚💚💚💚💚💚💚💚💚💚
2、string類的增刪改查
2.1 string的各種增操作
??不止是string,只要是資料的增操作,就涉及記憶體是否夠用的問題,因為插入資料可能會存在增容的操作,所以在這里我們同時將reserve函式模擬實作用來增容,除了reserve還有一個resize,二者的區別的聯系不用小編多說,大家應該知道,這里resize沒有什么實質性的作用,小編還是給出了其模擬實作的代和講解,幫助大家理解,
2.1.1 模擬實作resize
??string s1(“Linux”);
??s1 += ‘!’;
??resize()的情況分為多種:s1經過建構式,_size=5,_capacity=5._str=“Linux”,然后+=’!'后,_size=6,_capcacity=10,_str=“Linux!”,即有10個有效空間大小的容量,存盤有效資料6個,現在進行resize
a:resize(3) – resize的大小<_size
b:resize(8) – resize的大小>_size,但<_capacity
c:resize(15) – resize的大小>_capacity
//設定size
void resize(size_t n, char c = '\0')
{
if (n < _size)
{
_str[n] = '\0';
_size = n;
}
else
{
if (n > _capacity)
{
reserve(n);
}
for (size_t i = _size; i < n; i++)
{
_str[i] = c;
}
_str[n] = '\0';
_size = n;
}
}
2.1.2 模擬實作reserve
??對于reserve,改變的是capacity,設定一個形參n,即當需要的capacity大于本身的_capacity時就需要擴容,在這里,我們創建一個臨時陣列tmp,其大小就為我們需要的空間n,切記預留一個’\0’的位置,然后利用strncpy函式,
??這里需要注意為什么不用strcpy,stcpy是以’\0’為拷貝的結束標志,如果原字串_str后面有多個’\0’,且只有最后一個’\0’是作為識別符號的,其它都是有效字符,而strcpy只會講第一個’\0’拷貝過來,所以我們這里用strncpy,直接講有效字符的長度拷貝過來,避免出錯,
??然后置空原字串_str,因為其空間不夠了,然后改變_capacity引數即可,
//設定capacity
void reserve(size_t n)
{
if (n > _capacity)
{
char* tmp = new char[n + 1];
strncpy(tmp, _str, _size + 1);
delete[] _str;
_str = tmp;
_capacity = n;
}
}
2.1.3 模擬實作push_back
??不管在哪進行增加操作,剛上來就要進行判斷是否進行增容,如果_size=_capacity,則表明原陣列滿了,需要增容,添加字符可以每次擴容原容量的2倍,但是需要注意的是,原容量可能為0,因為我們的默認建構式的形參給的’\0’,所以這里需要主要,我們使用一個三目運算子來進行避免這個問題,
??不管是否進行擴容,代碼只要執行到if陳述句下面,就說明此時空間夠用,我們只需將字符
c添加到尾部,更新其_size即可,這里需要主要不要忘了將’\0’添加,因為原’\0’的位置被我們換成了字符c,
//push_back字符
void push_back(char c)
{
if (_size == _capacity)
{
//reserve(_capacity * 2);
reserve(_capacity == 0 ? 4 : _capacity * 2);
}
_str[_size] = c;
_str[_size + 1] = '\0';
_size++;
}
2.1.4 模擬實作append
??對于append的擴容就不能采取原容量的2倍,因為我們不知道插入的字串到底有多大,如果很大,一直2倍擴容多次,效率很低,所以我們直接計算所需要的容量,進行擴容,這是一個需要注意的地方,
??然后將需要插入的字串str,拷貝到原字串陣列_str的尾部,更新_size即可,
//append字串
void append(const char* str)
{
size_t len = strlen(str);
if ((_size + len) > _capacity)
{
reserve(_size + len);
}
strcpy(_str + _size, str);
_size += len;
}
2.1.5 +=多載
??對于+=運算子的多載,完全是復用push_back和append代碼,這里不多加贅述
//多載+=字符
string& operator+=(char c)
{
push_back(c);
return *this;
}
//多載+=字串
string& operator+=(const char* str)
{
append(str);
return *this;
}
2.1.6 模擬實作insert
??字符: 同樣,對于添加字符,仍要判斷是否擴容,方法同push_back添加字符,在挪動資料時有多種方式,我們這里采用指標的方式,定義一個尾指標指向陣列的尾部,此時指向的是’\0’的位置,然后依次往后挪動資料,直到在pos位置停下來,因為插入資料是用下標的形式,所以就實作了在pos位置之前(pos下標)的位置插入資料,當資料挪動完后,將字符c插入pos下標位置,然后更新_size,并將其以參考的形式回傳,
??字串: 字串的insert和字符的類似,首先判斷是否擴容,這個和上面的append類似,在保證容量夠的情況下開始挪動資料,此時挪動資料和添加字符挪動資料不同的是,添加字符挪動資料是后移一位,而添加字串挪動資料,是往后挪動strlen(str)個,即挪動添加字串長度,這樣挪動完資料后,從pos位置開始,就會空出len長度的字符,用來插入str,此時仍需要注意的是,這里使用的是strncpy原理在2.1.1中講過,這里不進行贅述,最后更新_size的資料,將結果回傳即可,
??我們實作insert后,insert的代碼可以讓push_back和append進行復用,為了不讓大家混淆,這里就不提供復用的代碼,避免大家一頭霧水,各位讀者有沒有感徑訓環相扣的感覺,這也就是string的魅力之處,
//在pos位置前插入字符c
string& insert(size_t pos, char c)
{
if (_size == _capacity)
{
reserve(_capacity == 0 ? 4 : _capacity * 2);
}
char* end = _str + _size;
while (end > (_str + pos))
{
*(end + 1) = *end;
--end;
}
_str[pos] = c;
_size++;
return *this;
}
// 在pos位置前插入字串str
string& insert(size_t pos, const char* str)
{
size_t len = strlen(str);
if ((_size + len) > _capacity)
{
reserve(_size + len);
}
char* end = _str + _size;
while (end > (_str + pos))
{
*(end + len) = *end;
--end;
}
strncpy(_str + pos, str, len);
_size += len;
return *this;
}
運行結果如下:
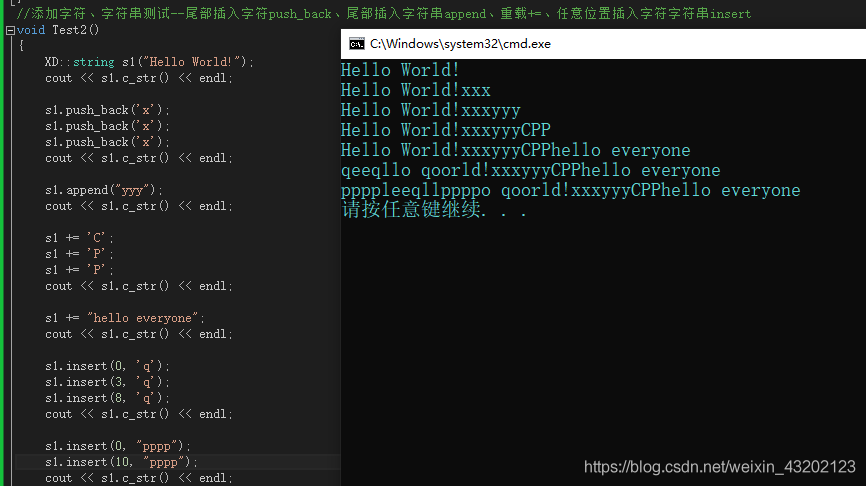
??真的是干貨滿滿,不知道各位讀者有沒有仔細閱讀,能將本文章讀完,你對string類將會有更深入的理解,加油!!!!!

2.2 string類的洗掉資料的函式模擬實作
??洗掉資料分兩種情況
??a:剩余的字符長度不夠刪,即要洗掉的長度大于等于左邊剩余的字符(后面全部刪完)
??b:剩余的字符長度夠刪,即要洗掉的長度小于左邊剩余的字符
??對于a情況,直接將pos位置的資料換為’\0’即可,然后更新_size,對于b情況,直接利用strcpy進行拷貝,因為strcpy以’\0’作為拷貝結束的標志,所以把末尾的’\0’識別符號一塊拷貝過去,再更新_size即可,
??對于b情況,即將len長度后面的資料拷貝到從pos位置開始的len長度即可,然后更新_size,這里我們在傳參里面使用預設引數將len=-1,對于無符號整數,-1是一個很大的整數,我們默認一個字串的長度沒有這么大,所以在沒有指定長度的情況下,默認洗掉到最后,
// 洗掉pos位置開始len長度的元素
string& erase(size_t pos, size_t len = -1)
{
//leftnumber代表從pos位置開始到末尾,總共有多少資料
size_t leftnumber = _size - pos;
//a情況
if (len > leftnumber)
{
_str[pos] = '\0';
_size = pos;
}
//b情況
else
{
strcpy(_str + pos, _str + pos + len);
_size -= len;
}
return *this;
}
運行結果如下
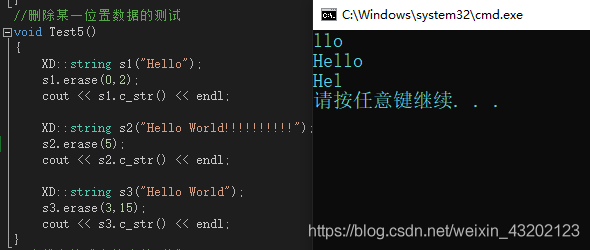
2.3 string類中[]運算子的多載-用于修改資料
??我們知道對于內置型別的陣列,我們可以使用下標的方式進行遍歷,通過使用[]下標運算子,輸出某一下標的資料,還可以通過下標對某一位置的資料進行修改,那么我們的string類可以使用這一功能嗎?答案是可以,這時候我們就需要實作對[]運算子的多載,
??這個多載比較簡單,我們直接在函式里面訪問_str陣列,然后使用[]運算子訪問這個陣列中的元素即可,使用參考回傳可以實作對資料的修改,
??下面兩個函式構成多載,這樣就可以適應const和非const物件的使用,
//*******************這個介面給const物件,只讀******************
char& operator[](size_t index)
{
return _str[index];
}
//*******************這個介面給非const物件,可讀可寫******************
const char& operator[](size_t index)const
{
return _str[index];
}
測驗結果:
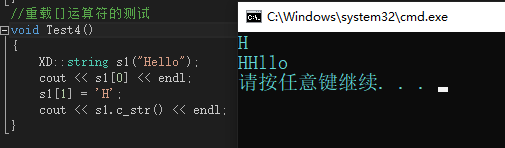
2.4 string類中查找字符或字串函式模擬實作
??對于string類中的查找操作也分為查找字符和字串,二者本質上是一樣的,只不過查找字串的時候呼叫了stl庫中的strstr函式幫我們查找,但本質也是遍歷陣列,找到符合的并回傳,strstr如果找到則回傳對應字串的起始位置下標,如果沒找到則回傳NULL,
??這兩個介面比較簡單,在這里不過多說明,大家看代碼,如果不懂給小編留言,小編給大家解答,
// 回傳c在string中第一次出現的位置
size_t find(char c, size_t pos = 0) const
{
for (size_t i = pos; i < _size; i++)
{
if (_str[i] == c)
{
return i;
}
}
return -1;
}
// 回傳子串s在string中第一次出現的位置
size_t find(const char* s, size_t pos = 0) const
{
const char* ret = strstr(_str + pos, s);
if (ret)
{
return ret - _str;
}
else
{
return -1;
}
}
運行結果如下:
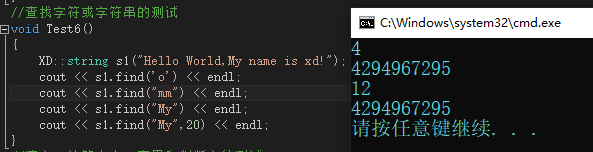
💛💛💛💛💛💛💛💛💛💛💛💛💛💛💛💛💛💛💛💛💛💛💛💛💛💛💛💛💛💛💛💛💛
3、string類多載各種比較關系運算子
??關于各種運算子的多載,我們只需要實作<和==,其它的都復用即可,
??這里我們比較兩個運算子,使用的是stl中的strcmp函式,
//比較關系的運算子多載
bool operator<(const string& s)
{
return strcmp(_str,s._str) < 0;
}
bool operator==(const string& s)
{
return strcmp(_str, s._str) == 0;
}
bool operator<=(const string& s)
{
return ((_str < s._str) || (_str == s._str));
}
bool operator>(const string& s)
{
return !((_str < s._str) || (_str == s._str));
}
bool operator>=(const string& s)
{
return !(strcmp(_str, s._str) < 0);
}
bool operator!=(const string& s)
{
return !(strcmp(_str, s._str) == 0);
}
運算結果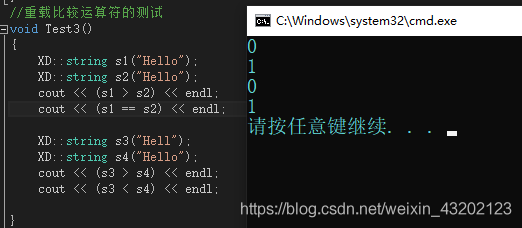
💙💙💙💙💙💙💙💙💙💙💙💙💙💙💙💙💙💙💙💙💙💙💙💙💙💙💙💙💙💙💙💙💙
4、string類的清空、計算大小、容量和判斷空的介面實作
4.1 string類中的清空介面
??直接將陣列第一個位置的元素改為’\0’,然后更改_size的值,
//清空
void clear()
{
_str[0] = '\0';
_size = 0;
}
4.2 string類中的計算大小介面
??直接回傳_size
//計算大小
size_t size()const
{
return _size;
}
4.3 string類中的計算容量介面
??直接回傳_capacity
//計算容量
size_t capacity()const
{
return _capacity;
}
4.4 string類中的判斷是否為空介面
??判斷_size是否為0,然后將結果回傳
//判斷物件是否為空
bool empty()const
{
return (_size == 0);
}
運行結果如圖:
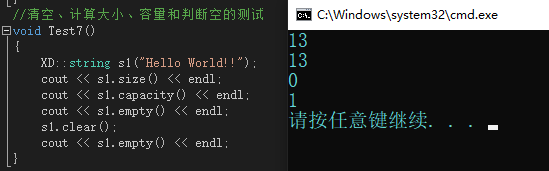
??over!!!!堅持到這里的小伙伴相信一定會有所識訓,我們已經將string類中常用的介面進行了模擬實作,文章末尾小編會給出本章的全部源代碼,供大家學習,源代碼中還會有迭代器的實作,范圍for的解釋,這幾個知識點不作為本章內容的研究,有感興趣的小伙伴可以私聊小編,

??????????????????????????????????????????????????????????????????
完整代碼:
namespace XD
{
class string
{
public:
typedef char* iterator;
typedef const char* const_iterator;
public:
//迭代器的本質是指標
iterator begin()
{
return _str;
}
iterator end()
{
return _str + _size;
}
const_iterator begin() const
{
return _str;
}
const_iterator end()const
{
return _str + _size;
}
//string的四個默認成員函式
string(const char* str = "")
{
_size = strlen(str);
_capacity = _size;
_str = new char[_capacity + 1];
strcpy(_str, str);
}
//法一:
//未代碼復用前:
/*
string(const string& s)
{
_str = nullptr;
_size = 0;
_capacity = 0;
string tmp(s._str);
::swap(_str, tmp._str);
::swap(_size, tmp._size);
::swap(_capacity, tmp._capacity);
}
string& operator=(string s)
{
::swap(_str, s._str);
::swap(_size, s._size);
::swap(_capacity, s._capacity);
return *this;
}
*/
//代碼復用后:
/*
void swap(string& s)
{
//加一個域作用限定符,這樣swap就會去全域域尋找,就會找到庫函式中的swap
::swap(_str, s._str);
::swap(_size, s._size);
::swap(_capacity, s._capacity);
}
string(const string& s)
{
_str = nullptr;
_size = 0;
_capacity = 0;
string tmp(s._str);
swap(tmp);
}
string& operator=(string s)
{
swap(s);
return *this;
}
*/
//法二:
//a:s2(s1)--拷貝構造
string(const string& s)
{
_size = strlen(s._str);
_capacity = _size;
_str = new char[strlen(s._str) + 1];
strcpy(_str, s._str);
}
//b:s3 = s1--賦值多載
string& operator=(const string& s)
{
if (this != &s)//防止自己給自己賦值s1 = s1
{
delete[] _str;
_size = strlen(s._str);
_capacity = _size;
_str = new char[strlen(s._str) + 1];
strcpy(_str, s._str);
}
return *this;
}
~string()
{
delete[] _str;
_str = nullptr;
_size = 0;
_capacity = 0;
}
//輸出該物件
const char* c_str()const
{
return _str;
}
//設定capacity
void reserve(size_t n)
{
if (n > _capacity)
{
char* tmp = new char[n + 1];//永遠留一個位置給\0
strncpy(tmp, _str, _size + 1);
delete[] _str;
_str = tmp;
_capacity = n;
}
}
//設定size
/*
string s1("Linux");
s1 += '!';
resize()的情況分為多種:s1經過建構式,_size=5,_capacity=5._str="Linux",然后+='!'后,_size=6,_capcacity=10,_str="Linux!",即有10個有效空間大小的容量,存盤有效資料6個,現在進行resize
a:resize(3) -- resize的大小<_size
b:resize(8) -- resize的大小>_size,但<_capacity
c:resize(15) -- resize的大小>_capacity
*/
void resize(size_t n, char c = '\0')
{
if (n < _size)
{
_str[n] = '\0';
_size = n;
}
else
{
if (n > _capacity)
{
reserve(n);
}
for (size_t i = _size; i < n; i++)
{
_str[i] = c;
}
_str[n] = '\0';
_size = n;
}
}
//push_back字符
void push_back(char c)
{
if (_size == _capacity)
{
//reserve(_capacity * 2);
reserve(_capacity == 0 ? 4 : _capacity * 2);
}
_str[_size] = c;
_str[_size + 1] = '\0';
_size++;
}
//append字串
void append(const char* str)
{
size_t len = strlen(str);
if ((_size + len) > _capacity)
{
reserve(_size + len);
}
strcpy(_str + _size, str);
_size += len;
}
//多載+=字符
string& operator+=(char c)
{
push_back(c);
return *this;
}
//多載+=字串
string& operator+=(const char* str)
{
append(str);
return *this;
}
// 在pos位置前插入字符c
string& insert(size_t pos, char c)
{
if (_size == _capacity)
{
reserve(_capacity == 0 ? 4 : _capacity * 2);
}
char* end = _str + _size;
while (end > _str + pos)
{
*(end + 1) = *end;
--end;
}
_str[pos] = c;
_size++;
return *this;
}
// 在pos位置前插入字串str
string& insert(size_t pos, const char* str)
{
size_t len = strlen(str);
if ((_size + len) > _capacity)
{
reserve(_size + len);
}
char* end = _str + _size;
while (end > (_str + pos))
{
*(end + len) = *end;
--end;
}
strncpy(_str + pos, str, len);
_size += len;
return *this;
}
//清空
void clear()
{
_str[0] = '\0';
_size = 0;
}
//計算大小
size_t size()const
{
return _size;
}
//計算容量
size_t capacity()const
{
return _capacity;
}
//判斷物件是否為空
bool empty()const
{
return (_size == 0);
}
//[]運算子的多載-可以用來遍歷
char& operator[](size_t index)
{
return _str[index];
}
const char& operator[](size_t index)const
{
return _str[index];
}
//比較關系的運算子多載
bool operator<(const string& s)
{
return strcmp(_str,s._str) < 0;
}
bool operator==(const string& s)
{
return strcmp(_str, s._str) == 0;
}
bool operator<=(const string& s)
{
return ((_str < s._str) || (_str == s._str));
}
bool operator>(const string& s)
{
return !((_str < s._str) || (_str == s._str));
}
bool operator>=(const string& s)
{
return !(strcmp(_str, s._str) < 0);
}
bool operator!=(const string& s)
{
return !(strcmp(_str, s._str) == 0);
}
// 回傳c在string中第一次出現的位置
size_t find(char c, size_t pos = 0) const
{
for (size_t i = pos; i < _size; i++)
{
if (_str[i] == c)
{
return i;
}
}
return -1;
}
// 回傳子串s在string中第一次出現的位置
size_t find(const char* s, size_t pos = 0) const
{
const char* ret = strstr(_str + pos, s);
if (ret)
{
return ret - _str;
}
else
{
return -1;
}
}
//洗掉pos位置開始len長度的元素
/*
洗掉資料分兩種情況
a:剩余的字符長度不夠刪,即要洗掉的長度大于等于左邊剩余的字符(后面全部刪完)
b:剩余的字符長度夠刪,即要洗掉的長度小于左邊剩余的字符
*/
string& erase(size_t pos, size_t len = -1)
{
//leftnumber代表從pos位置開始到末尾,總共有多少資料
size_t leftNum = _size - pos;
//a情況
if (len >= leftNum)
{
_str[pos] = '\0';
_size = pos;
}
//b情況
else
{
strcpy(_str + pos, _str + pos + len);
_size -= len;
}
return *this;
}
private:
char* _str;
size_t _capacity;
size_t _size;
};
}
//輸入輸出運算子!!!!
ostream& operator<<(ostream& out, const string& s)
{
for (auto ch : s)
{
out << ch;
}
return out;
}
istream& operator>>(istream& in, string& s)
{
//要先把原來的東西清空,而不是加在后面,庫里面有這個clear,我們上面自己實作
s.clear();
char ch;
//這個地方會有問題,忽略空格或者回車,在while回圈中,最后一個是回車或者空格,應該結束,但是沒有結束,而是忽略掉了回車或者空格,即根本沒拿到換行符,而是等待下一次接收,所以不對
//因為默認回車或者空格為字符間的間隔符,in>>ch,直接會忽略
//in >> ch;
ch = in.get();
while (ch != ' ' && ch != '\n')
{
//每進行一次+=,'\0'會自動添加到尾部,直到遇到退出的條件
s += ch;
//in >> ch;
ch = in.get();
}
return in;
}
//有可能字串本身就有空格,這時候我們需要獲取一行的資料,即庫中的getline
istream& getline(istream& in, string& s)
{
s.clear();
char ch;
ch = in.get();
while (ch != '\n')
{
s += ch;
ch = in.get();
}
return in;
}
//四個默認建構式測驗
void Test1()
{
XD::string s1("Hello World!");
cout << s1.c_str() << endl;
XD::string s2(s1);
cout << s2.c_str() << endl;
XD::string s3;
s3 = s1;
cout << s3.c_str() << endl;
}
//添加字符、字串測驗--尾部插入字符push_back、尾部插入字串append、多載+=、任意位置插入字符字串insert
void Test2()
{
XD::string s1("Hello World!");
cout << s1.c_str() << endl;
s1.push_back('x');
s1.push_back('x');
s1.push_back('x');
cout << s1.c_str() << endl;
s1.append("yyy");
cout << s1.c_str() << endl;
s1 += 'C';
s1 += 'P';
s1 += 'P';
cout << s1.c_str() << endl;
s1 += "hello everyone";
cout << s1.c_str() << endl;
s1.insert(0, 'q');
s1.insert(3, 'q');
s1.insert(8, 'q');
cout << s1.c_str() << endl;
s1.insert(0, "pppp");
s1.insert(10, "pppp");
cout << s1.c_str() << endl;
}
//多載比較運算子的測驗
void Test3()
{
XD::string s1("Hello");
XD::string s2("Hello");
cout << (s1 > s2) << endl;
cout << (s1 == s2) << endl;
XD::string s3("Hell");
XD::string s4("Hello");
cout << (s3 > s4) << endl;
cout << (s3 < s4) << endl;
}
//多載[]運算子的測驗
void Test4()
{
XD::string s1("Hello");
cout << s1[0] << endl;
s1[1] = 'H';
cout << s1.c_str() << endl;
}
//洗掉某一位置資料的測驗
void Test5()
{
XD::string s1("Hello");
s1.erase(0,2);
cout << s1.c_str() << endl;
XD::string s2("Hello World!!!!!!!!!!");
s2.erase(5);
cout << s2.c_str() << endl;
XD::string s3("Hello World");
s3.erase(3,15);
cout << s3.c_str() << endl;
}
//查找字符或字串的測驗
void Test6()
{
XD::string s1("Hello World,My name is xd!");
cout << s1.find('o') << endl;
cout << s1.find("mm") << endl;
cout << s1.find("My") << endl;
cout << s1.find("My",20) << endl;
}
//清空、計算大小、容量和判斷空的測驗
void Test7()
{
XD::string s1("Hello World!!");
cout << s1.size() << endl;
cout << s1.capacity() << endl;
cout << s1.empty() << endl;
s1.clear();
cout << s1.empty() << endl;
}
//迭代器的測驗
void Test8()
{
XD::string s1("Hello World!!");
XD::string::iterator it = s1.begin();
while (it != s1.end())
{
cout << *it << " ";
it++;
}
cout << endl;
//范圍for是由迭代器支持的
//依次取s1里面的值,依次賦值給ch,自動判斷結束,自動迭代++
//看起來很神奇,但是原理很簡單,這個范圍for會被編譯器替換成迭代器形式
//也就是說范圍for是由迭代器支持的
for (auto ch : s1)
{
cout << ch << " ";
}
cout << endl;
}
int main()
{
//Test1();
//Test2();
//Test3();
//Test4();
//Test5();
Test6();
//Test7();
//Test8();
return 0;
}
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/290697.html
標籤:其他