🙉飯不食,水不飲,題必須刷🙉
C語言免費動漫教程,和我一起打卡! 🌞《光天化日學C語言》🌞
LeetCode 太難?先看簡單題! 🧡《C語言入門100例》🧡
資料結構難?不存在的! 🌳《資料結構入門》🌳
LeetCode 太簡單?演算法學起來! 🌌《夜深人靜寫演算法》🌌
究極演算法奧義!深度學習! 🟣《深度學習100例》🟣
文章目錄
- 前言
- 💨一、排序
- 🥖二、線性列舉
- 💤三、線性迭代
- 🥂四、二分列舉
- 🥢五、雙指標
- 1、來回跳躍
- 2、滑動視窗
- a、無重復覆寫
- b、最小覆寫
- 🍴六、坐標轉換
- 🅱七、位運算
- 1、位與
- 2、位或
- 3、異或
- 4、左移
- ?八、遞推
- 1、一維遞推
- 2、二維遞推
- 💥九、遞回
- 1、分治問題
- 2、連通塊問題
- 3、全排列列舉
- 🚕十、簡單動態規劃
- 1、線性DP
- 1)遞推型
- 2)最大子段和
- 3)最長遞增子序列
- 2、序列匹配問題
- 1)正則運算式匹配
- 2)最長公共子序列
- 3)最短編輯距離
- 3、背包問題
- 4、記憶化搜索
前言
??我們平時在 「 求職面試 」 的時候,總會遇到被要求做一個演算法題,如果你寫不出來,可能你的 「 offer 」 年包就打了 七折,或者直接與 「 offer 」 失之交臂,都是有可能的,
??當然,它不能完全代表你的「 編碼能力 」,因為有些 「 演算法 」 確實是很巧妙,加上當時緊張的面試氛圍,想不出來其實也是正常的,但是你能確保面試官是這么想的嗎?不能!
??我們要做的是十足的準備,既然決定出來,offer 當然是越高越好,畢竟大家都要「 養家糊口 」,房價又這么貴,如果能夠在演算法這一塊取得先機,也不失為一個捷徑,
??但是,「 茫茫多的演算法題,我們從何刷起呢? 」那么,接下來,我會介紹幾個簡單的入門演算法,并且介紹下每個演算法對應的題型,希望對你有所幫助!

💨一、排序
- 一般網上的文章在講各種 「 排序 」 演算法的時候,都會甩出一張 「 思維導圖 」,如下:
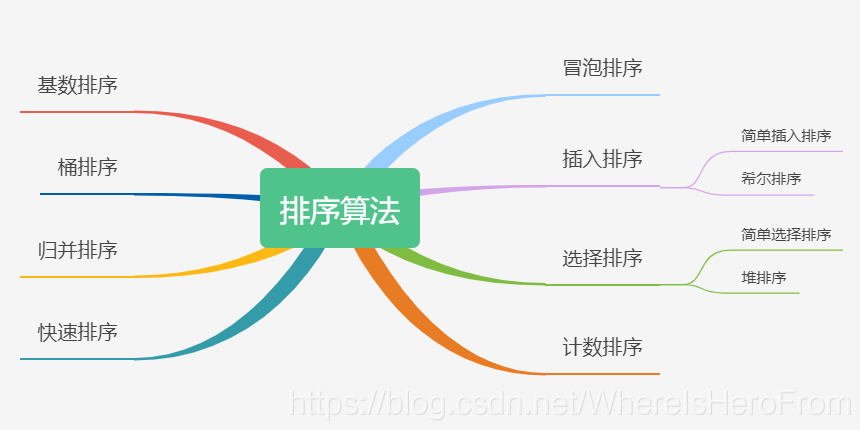
- 當然,我也不例外……
- 這些概念也不用多說,只要你能夠把「 快速排序 」的思想理解了,基本上其它演算法的思想也都能學會,這個思路就是經典的:「 要學就學最難的,其它肯定能學會 」,因為當你連「 最難的 」都已經 「 KO 」 了,其它的還不是「 小菜一碟 」?信心自然就來了,
- 我們要戰勝的其實不是「 演算法 」本身,而是我們對 「 演算法 」 的恐懼,一旦建立起「 自信心 」,后面的事情,就「 水到渠成 」了,
- 然而,實際情況比這可要簡單得多,實際在上機刷題的程序中,不可能讓你手寫一個排序,你只需要知道 C++ 中 STL 的 sort 函式就夠了,它的底層就是由【快速排序】實作的,
- 所有的排序題都可以做,我挑一個來說,至于上面說到的那十個排序演算法,如果有緣,我會在八月份的這個專欄 ??《資料結構入門》導航 ?? 中更新,盡情期待~~
I、例題描述
??給你兩個有序整數陣列 n u m s 1 nums1 nums1 和 n u m s 2 nums2 nums2,請你將 n u m s 2 nums2 nums2 合并到 n u m s 1 nums1 nums1 中,使 n u m s 1 nums1 nums1 成為一個有序陣列,初始化 n u m s 1 nums1 nums1 和 n u m s 2 nums2 nums2 的元素數量分別為 m m m 和 n n n ,你可以假設 n u m s 1 nums1 nums1 的空間大小等于 m + n m + n m+n,這樣它就有足夠的空間保存來自 n u m s 2 nums2 nums2 的元素,
??樣例輸入: n u m s 1 = [ 1 , 2 , 3 , 0 , 0 , 0 ] , m = 3 , n u m s 2 = [ 2 , 5 , 6 ] , n = 3 nums1 = [1,2,3,0,0,0], m = 3, nums2 = [2,5,6], n = 3 nums1=[1,2,3,0,0,0],m=3,nums2=[2,5,6],n=3
??樣例輸出: [ 1 , 2 , 2 , 3 , 5 , 6 ] [1,2,2,3,5,6] [1,2,2,3,5,6]
??原題出處: LeetCode 88. 合并兩個有序陣列
II、基礎框架
- c++ 版本給出的基礎框架代碼如下:
class Solution {
public:
void merge(vector<int>& nums1, int m, vector<int>& nums2, int n) {
}
};
III、思路分析
- 這個題別想太多,直接把第二個陣列的元素加到第一個陣列元素的后面,然后直接排序就成,
IV、時間復雜度
- STL 排序函式的時間復雜度為 O ( n l o g 2 n ) O(nlog_2n) O(nlog2?n),遍歷的時間復雜度為 O ( n ) O(n) O(n),所以總的時間復雜度為 O ( n l o g 2 n ) O(nlog_2n) O(nlog2?n),
IV、原始碼詳解
class Solution {
public:
void merge(vector<int>& nums1, int m, vector<int>& nums2, int n) {
for(int i = m; i < n + m; ++i) {
nums1[i] = nums2[i-m]; // (1)
}
sort(nums1.begin(), nums1.end()); // (2)
}
};
- ( 1 ) (1) (1) 簡單合并兩個陣列;
- ( 2 ) (2) (2) 對陣列1進行排序;
VI、本題小知識
??只要能夠達到最終的結果, O ( n ) O(n) O(n) 和 O ( n l o g 2 n ) O(nlog_2n) O(nlog2?n) 的差距其實并沒有那么大,只要是和有序相關的,就可以呼叫這個函式,直接就出來了,
🥖二、線性列舉
- 線性列舉,一般配合的 資料結構 是 【陣列】 或者 【鏈表】,實作方式就是一個回圈,正因為只有一個回圈,所以線性列舉解決的問題一般比較簡單,而且很容易從題目中看出來,
I、例題描述
??撰寫一個函式,將輸入的字串反轉過來,輸入字串以字符陣列 char[] 的形式給出,
必須原地修改輸入陣列、使用 O(1) 的額外空間解決這一問題,
??樣例輸入: [ “ a ” , “ b ” , “ c ” , “ d ” ] [“a”, “b”, “c”, “d”] [“a”,“b”,“c”,“d”]
??樣例輸出: [ “ d ” , “ c ” , “ b ” , “ a ” ] [ “d”, “c”, “b”, “a”] [“d”,“c”,“b”,“a”]
??原題出處: LeetCode 344. 反轉字串
II、基礎框架
- c++ 版本給出的基礎框架代碼如下,要求不采用任何的輔助陣列;
- 也就是空間復雜度要求 O ( 1 ) O(1) O(1),
class Solution {
public:
void reverseString(vector<char>& s) {
}
};
III、思路分析
??翻轉的含義,相當于就是 第一個字符 和 最后一個交換,第二個字符 和 最后第二個交換,… 以此類推,所以我們首先實作一個交換變數的函式
swap,然后再列舉 第一個字符、第二個字符、第三個字符 …… 即可,
??對于第 i i i 個字符,它的交換物件是 第 l e n ? i ? 1 len-i-1 len?i?1 個字符 (其中 l e n len len 為字串長度),swap函式的實作,可以參考:《C語言入門100例》 - 例2 | 交換變數,
IV、時間復雜度
- 線性列舉的程序為 O ( n ) O(n) O(n),交換變數為 O ( 1 ) O(1) O(1),兩個程序是相乘的關系,所以整個演算法的時間復雜度為 O ( n ) O(n) O(n),
IV、原始碼詳解
class Solution {
public:
void swap(char& a, char& b) { // (1)
char tmp = a;
a = b;
b = tmp;
}
void reverseString(vector<char>& s) {
int len = s.size();
for(int i = 0; i < len / 2; ++i) { // (2)
swap(s[i], s[len-i-1]);
}
}
};
-
(
1
)
(1)
(1) 實作一個變數交換的函式,其中
&是C++中的參考,在函式傳參是經常用到,被稱為:參考傳遞(pass-by-reference),即被調函式的形式引數雖然也作為區域變數在堆疊中開辟了記憶體空間
,但是這時存放的是由主調函式放進來的實參變數的地址,被調函式對形參的任何操作都被處理成間接尋址,即通過堆疊中存放的地址訪問主調函式中的實參變數,
簡而言之,函式呼叫的引數,可以傳參考,從而使得函式回傳時,傳參值的改變依舊生效,
- ( 2 ) (2) (2) 這一步是做的線性列舉,注意列舉范圍是 [ 0 , l e n / 2 ? 1 ] [0, len/2-1] [0,len/2?1],
VI、本題小知識
函式呼叫的引數,可以傳參考,從而使得函式回傳時,傳參值的改變依舊生效,
💤三、線性迭代
- 迭代就是一件事情重復的做,干的事情一樣,只是引數的不同,一般配合的 資料結構 是 【陣列】 或者 【鏈表】,實作方式也是一個回圈,比 列舉 稍微復雜一點,
I、例題描述
??給定單鏈表的頭節點 h e a d head head ,要求反轉鏈表,并回傳反轉后的鏈表頭,
??樣例輸入: [ 1 , 2 , 3 , 4 ] [1,2,3,4] [1,2,3,4]
??樣例輸出: [ 4 , 3 , 2 , 1 ] [4, 3, 2, 1] [4,3,2,1]
??原題出處: LeetCode 206. 反轉鏈表
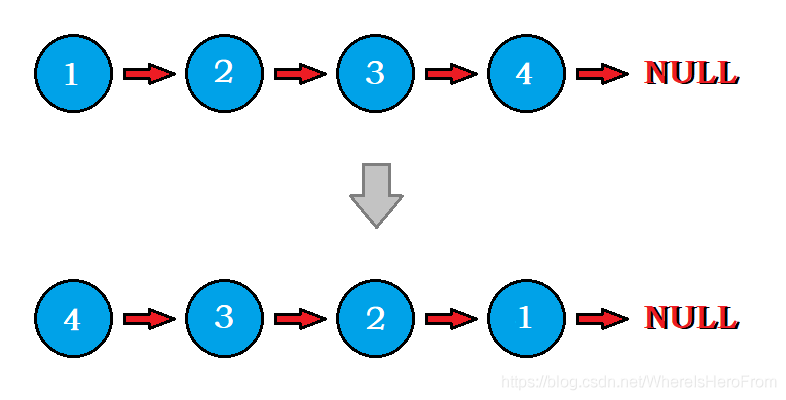
II、基礎框架
- c++ 版本給出的基礎框架代碼如下:
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* reverseList(ListNode* head) {
}
};
- 這里引入了一種資料結構 鏈表
ListNode; - 成員有兩個:資料域
val和指標域next, - 回傳的是鏈表頭結點;
III、思路分析
- 這個問題,我們可以采用頭插法,即每次拿出第 2 個節點插到頭部,拿出第 3 個節點插到頭部,拿出第 4 個節點插到頭部,… 拿出最后一個節點插到頭部,
- 于是整個程序可以分為兩個步驟:洗掉第 i i i 個節點,將它放到頭部,反復迭代 i i i 即可,
- 如圖所示:
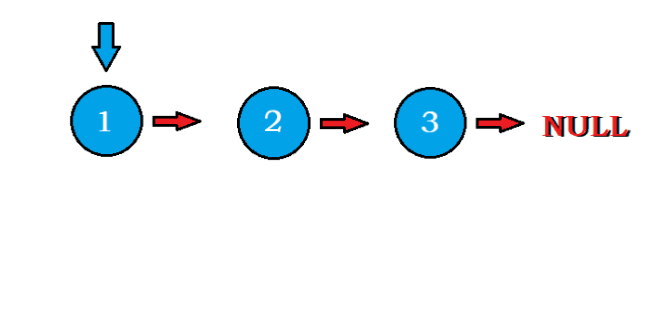
- 我們發現,圖中的藍色指標永遠固定在最開始的鏈表頭結點上,那么可以以它為貧訓,每次洗掉它的
next,并且插到最新的頭結點前面,不斷改變頭結點head的指向,迭代 n ? 1 n-1 n?1 次就能得到答案了,
IV、時間復雜度
- 每個結點只會被訪問一次,執行一次頭插操作,總共 n n n 個節點的情況下,時間復雜度 O ( n ) O(n) O(n),
V、原始碼詳解
class Solution {
ListNode *removeNextAndReturn(ListNode* now) { // (1)
if(now == nullptr || now->next == nullptr) {
return nullptr; // (2)
}
ListNode *retNode = now->next; // (3)
now->next = now->next->next; // (4)
return retNode;
}
public:
ListNode* reverseList(ListNode* head) {
ListNode *doRemoveNode = head; // (5)
while(doRemoveNode) { // (6)
ListNode *newHead = removeNextAndReturn(doRemoveNode); // (7)
if(newHead) { // (8)
newHead->next = head;
head = newHead;
}else {
break; // (9)
}
}
return head;
}
};
-
(
1
)
(1)
(1)
ListNode *removeNextAndReturn(ListNode* now)函式的作用是洗掉now的next節點,并且回傳; - ( 2 ) (2) (2) 本身為慷訓者下一個節點為空,回傳空;
- ( 3 ) (3) (3) 將需要洗掉的節點快取起來,供后續回傳;
- ( 4 ) (4) (4) 執行洗掉 now->next 的操作;
-
(
5
)
(5)
(5)
doRemoveNode指向的下一個節點是將要被洗掉的節點,所以doRemoveNode需要被快取起來,不然都不知道怎么進行洗掉; - ( 6 ) (6) (6) 沒有需要洗掉的節點了就結束迭代;
- ( 7 ) (7) (7) 洗掉 doRemoveNode 的下一個節點并回傳被洗掉的節點;
- ( 8 ) (8) (8) 如果有被洗掉的節點,則插入頭部;
- ( 9 ) (9) (9) 如果沒有,則跳出迭代,
VI、本題小知識
??復雜問題簡單化的最好辦法就是將問題拆細,比如這個問題中,將一個節點取出來插到頭部這件事情可以分為兩步:
??1)洗掉給定節點;
??2)將洗掉的節點插入頭部;
🥂四、二分列舉
- 能用二分列舉的問題,一定可以用線性列舉來實作,只是時間上的差別,二分列舉的時間復雜度一般為對數級,效率上會高不少,同時,實作難度也會略微有所上升,我們通過平時開發時遇到的常見問題來舉個例子,
I、例題描述
??軟體開發的時候,會有版本的概念,由于每個版本都是基于之前的版本開發的,所以錯誤的版本之后的所有版本都是錯的,假設你有 n n n 個版本 [ 1 , 2 , . . . , n ] [1, 2, ..., n] [1,2,...,n],你想找出導致之后所有版本出錯的第一個錯誤的版本,可以通過呼叫
bool isBadVersion(version)介面來判斷版本號version是否在單元測驗中出錯,實作一個函式來查找第一個錯誤的版本,應該盡量減少對呼叫 API 的次數,
??樣例輸入: 5 5 5 和 b a d = 4 bad = 4 bad=4
??樣例輸出: 4 4 4
??原題出處: LeetCode 278. 第一個錯誤的版本
II、基礎框架
- c++ 版本給出的基礎框架代碼如下,其中
bool isBadVersion(int version)是供你呼叫的 API,也就是當你呼叫這個 API 時,如果version是錯誤的,則回傳true;否則,回傳false;
// The API isBadVersion is defined for you.
// bool isBadVersion(int version);
class Solution {
public:
int firstBadVersion(int n) {
}
};
III、思路分析
- 由題意可得,我們呼叫它提供的 API 時,回傳值分布如下:
- 000...000111...111 000...000111...111 000...000111...111
- 其中 0 代表
false,1 代表true;也就是一旦出現 1,就再也不會出現 0 了, - 所以基于這思路,我們可以二分位置;
歸納總結為 2 種情況,如下:
??1)當前二分到的位置 m i d mid mid,給出的版本是錯誤,那么從當前位置以后的版本不需要再檢測了(因為一定也是錯誤的),并且我們可以肯定,出錯的位置一定在 [ l , m i d ] [l, mid] [l,mid];并且 m i d mid mid 是一個可行解,記錄下來;
??2)當前二分到的位置 m i d mid mid,給出的版本是正確,則出錯位置可能在 [ m i d + 1 , r ] [mid+1, r] [mid+1,r];
IV、時間復雜度
- 由于每次都是將區間折半,所以時間復雜度為 O ( l o g 2 n ) O(log_2n) O(log2?n),
V、原始碼詳解
// The API isBadVersion is defined for you.
// bool isBadVersion(int version);
class Solution {
public:
int firstBadVersion(int n) {
long long l = 1, r = n; // (1)
long long ans = (long long)n + 1;
while(l <= r) {
long long mid = (l + r) / 2;
if( isBadVersion(mid) ) {
ans = mid; // (2)
r = mid - 1;
}else {
l = mid + 1; // (3)
}
}
return ans;
}
};
-
(
1
)
(1)
(1) 需要這里,這里兩個區間相加可能超過
int,所以需要采用 64 位整型long long; - ( 2 ) (2) (2) 找到錯誤版本的嫌疑區間 [ l , m i d ] [l, mid] [l,mid],并且 m i d mid mid 是確定的候選嫌疑位置;
- ( 3 ) (3) (3) 錯誤版本不可能落在 [ l , m i d ] [l, mid] [l,mid],所以可能在 [ m i d + 1 , r ] [mid+1, r] [mid+1,r],需要繼續二分迭代;
VI、本題小知識
二分時,如果區間范圍過大,
int難以招架時,需要動用long long;
🥢五、雙指標
- 雙指標的概念就是對于一個線性表,通過兩個變數的游走,來逐步解決問題,
1、來回跳躍
I、例題描述
??給定一個按 非遞減順序 排序的整數陣列 nums,回傳 每個數字的平方 組成的新陣列,要求也按 非遞減順序 排序,
??樣例輸入: n u m s = [ ? 4 , ? 1 , 0 , 3 , 9 ] nums = [-4,-1,0,3,9] nums=[?4,?1,0,3,9]
??樣例輸出: [ 0 , 1 , 9 , 16 , 81 ] [0,1,9,16,81] [0,1,9,16,81]
??原題出處: LeetCode 977. 有序陣列的平方
II、基礎框架
- c++ 版本給出的基礎框架代碼如下,要求回傳一個
vector<int>型別的資料;
class Solution {
public:
vector<int> sortedSquares(vector<int>& nums) {
}
};
III、思路分析
- 首先,如果所有的數都是非負整數,那么直接按照原順序,對數字平方塞入新的陣列就是答案了,
- 否則,需要找到負數中,下標最大的,令它為 i i i,然后定義令一個指標 j = i + 1 j = i + 1 j=i+1,不斷比較 i i i 和 j j j 對應的數的平方的大小關系,然后選擇小的那個塞入新的陣列,并且更新指標的位置,直到兩個指標都到陣列邊緣時,運算完畢,
IV、時間復雜度
- 兩個指標只會往一個方向遍歷,最多遍歷一次,所以時間復雜度為 O ( n ) O(n) O(n),
V、原始碼詳解
class Solution {
public:
vector<int> sortedSquares(vector<int>& nums) {
vector <int> ans; // (1)
if (nums.size() == 0) { // (2)
return ans;
}
else if(nums[0] >= 0) {
for(int i = 0; i < nums.size(); ++i) { // (3)
ans.push_back(nums[i] * nums[i]);
}
}
else {
int i, j;
for(int p = nums.size()-1; p >= 0; --p) {
if(nums[p] < 0) {
i = p;
break; // (4)
}
}
j = i + 1; // (5)
while(i >= 0 || j < nums.size()) { // (6)
if(i < 0) { // (7)
ans.push_back(nums[j] * nums[j]);
++j;
}else if(j >= nums.size()) { // (8)
ans.push_back(nums[i] * nums[i]);
--i;
}else {
int i2 = nums[i] * nums[i];
int j2 = nums[j] * nums[j];
if(i2 < j2) { // (9)
ans.push_back(i2);
--i;
}else {
ans.push_back(j2);
++j;
}
}
}
}
return ans;
}
};
-
(
1
)
(1)
(1)
ans為結果陣列,用來存盤最終答案; - ( 2 ) (2) (2) 如果給定陣列長度為 0,則直接回傳空陣列;
- ( 3 ) (3) (3) 給定陣列所有元素都為非負整數時,直接有序的生成新的陣列,陣列元素為原陣列元素的平方;
- ( 4 ) (4) (4) 找到負數中,下標最大的數,記為 i i i;
- ( 5 ) (5) (5) 初始化指標 j = i + 1 j = i + 1 j=i+1;
- ( 6 ) (6) (6) 開始對兩個指標進行迭代列舉,結束條件是兩個指標都碰到陣列的邊界;
- ( 7 ) (7) (7) 左指標退化,左邊元素耗盡了;
- ( 8 ) (8) (8) 右指標退化,右邊元素耗盡了;
- ( 9 ) (9) (9) 左右元素都在,需要選擇小的那個先進結果陣列,然后向外擴展指標;
VI、本題小知識
輸入引數為陣列時,如果要判斷陣列第一個元素的狀態,記得對陣列進行判空;
2、滑動視窗
a、無重復覆寫
I、例題描述
??給定一個長度為 n ( 1 ≤ n ≤ 1 0 7 ) n (1 \le n \le 10^7) n(1≤n≤107) 的字串 s s s,求一個最長的滿足所有字符不重復的子串的長度,
??樣例輸入:" a b c a b c b b g abcabcbbg abcabcbbg"
??樣例輸出: 3 3 3
??原題出處: LeetCode 3. 無重復字符的最長子串
II、基礎框架
- c++ 版本給出的基礎框架代碼如下:
class Solution {
public:
int lengthOfLongestSubstring(string s) {
}
};
- 其中
string是 C++ 的 STL 中的模板類,可以用來做字串的各種操作;
III、思路分析
- 我們考慮一個子串以
s
i
s_i
si? 為左端點,
s
j
s_j
sj? 為右端點,且
s
[
i
:
j
?
1
]
s[i:j-1]
s[i:j?1] 中不存在重復字符,
s
[
i
:
j
]
s[i:j]
s[i:j] 中存在重復字符(換言之,
s
j
s_j
sj? 和
s
[
i
:
j
?
1
]
s[i:j-1]
s[i:j?1] 中某個字符相同),如圖所示:
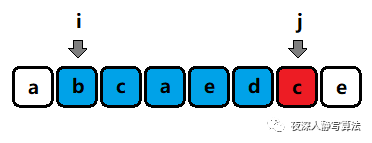
- 那么我們沒必要再去檢測 s [ i : j + 1 ] s[i:j+1] s[i:j+1], s [ i : j + 2 ] s[i:j+2] s[i:j+2], s [ i : n ? 1 ] s[i:n-1] s[i:n?1] 這幾個字串的合法性,因為當前情況 s [ i : j ] s[i:j] s[i:j] 是非法的,而這些字串是完全包含 s [ i : j ] s[i:j] s[i:j] 的,所以它們必然也是不合法的,
- 那么我們可以把列舉的左端點自增,即: i = i + 1 i = i +1 i=i+1,這時,按照樸素演算法的實作,右端點需要重置,即 j = i j = i j=i,實際上這里的右端點可以不動,
- 可以這么考慮,由于
s
j
s_j
sj? 這個字符和
s
[
i
:
j
?
1
]
s[i:j-1]
s[i:j?1] 中的字符產生了重復,假設這個重復的字符的下標為
k
k
k,那么
i
i
i 必須滿足
i
>
k
i \gt k
i>k,換言之,
i
i
i 可以一直自增,直到
i
=
k
+
1
i = k+1
i=k+1,如圖所示:

- 這個問題是 雙指標 問題的原題,詳細的演算法可以參考:夜深人靜寫演算法(二十八)- 尺取法,
IV、時間復雜度
- 兩個指標都只會遞增各一次,所以時間復雜度為 O ( n ) O(n) O(n),
V、原始碼詳解
class Solution {
int hash[257];
public:
int lengthOfLongestSubstring(string s) {
memset(hash, 0, sizeof(hash));
int maxLen = 0;
int i = 0, j = -1; // (1)
int len = s.length(); // (2)
while(j++ < len - 1) {
++hash[ s[j] ]; // (3)
while(hash[ s[j] ] > 1) { // (4)
--hash[ s[i] ]; // (5)
++i;
}
if(j - i + 1 > maxLen) { // (6)
maxLen = j - i + 1;
}
}
return maxLen;
}
};
- ( 1 ) (1) (1) 代表一開始是空串;
-
(
2
)
(2)
(2) 之所以要這么做,是因為
s.length()是無符號整型,當j == -1的情況為無符號整型的最大值,永遠都無法進入下面的while(j++ < len - 1)這個回圈; - ( 3 ) (3) (3) 嘗試向右移動 右指標;
- ( 4 ) (4) (4) 合法性判定:所有字符個數不超過1;
- ( 5 ) (5) (5) 嘗試向右移動 左指標;
- ( 6 ) (6) (6) 更新最大合法長度;
VI、本題小知識
無符號整型在進行判斷的時候,如果賦值為 -1,就有可能導致變成整數最大值導致邏輯錯誤;
b、最小覆寫
I、例題描述
??給你一個字串 s s s 、一個字串 t t t ,回傳 s s s 中涵蓋 t t t 所有字符的最小子串,如果 s s s 中不存在涵蓋 t t t 所有字符的子串,則回傳空字串
"",對于 t t t 中重復字符,尋找的子字串中該字符數量必須不少于 t t t 中該字符數量,如果 s s s 中存在這樣的子串,我們保證它是唯一的答案,兩個字串的長度都不大于 1 0 5 10^5 105,
??樣例輸入: s = “AOBECODEBAJC”, t = “ABC”
??樣例輸出: “BAJC”
??原題出處: LeetCode 76. 最小覆寫子串
II、基礎框架
- c++ 版本給出的基礎框架代碼如下:
class Solution {
public:
string minWindow(string s, string t) {
}
};
- 其中
string是 c++ 的 STL 中的模板類,可以用來做字串的各種操作;
III、思路分析
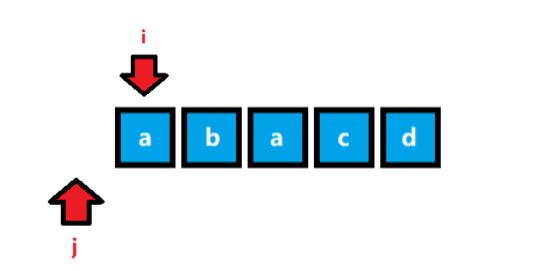
-
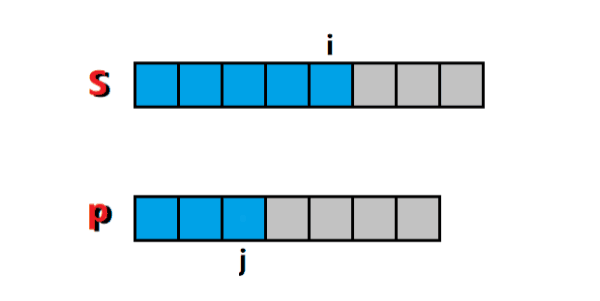
這是一個經典的雙指標問題,左指標 i i i 和 右指標 j j j 下標范圍內的字串就是我們要求的子串,通過主指標 j j j 的右移,帶動輔助指標 i i i 的右移,每個指標最多右移 n n n 次,如圖所示:
-
詳細的演算法實作可以參考:夜深人靜寫演算法(二十八)- 尺取法,
IV、時間復雜度
- 兩個指標都只會遞增各一次,所以時間復雜度為 O ( n ) O(n) O(n),
V、原始碼詳解
class Solution {
int hash[256];
public:
string minWindow(string s, string t) {
memset(hash, 0, sizeof(hash)); // (1)
int cnt = 0, needCnt = 0; // (2)
for(int i = 0; i < t.length(); ++i) {
if(!hash[ t[i] ]) {
++needCnt;
}
++ hash[ t[i] ];
}
int i = 0, j = -1; // (3)
int l = 0, r = -1, ans = 1000000; // (4)
int size = s.length();
while(j < size - 1) {
++j; // (5)
if(--hash[ s[j] ] == 0) {
++cnt;
}
while(cnt == needCnt) {
if(j - i + 1 < ans) { // (6)
ans = j - i + 1;
l = i;
r = j;
}
if( ++hash[ s[i] ] > 0 ) { // (7)
--cnt;
}
++i;
}
}
string ret;
for(int i = l; i <= r; ++i) {
ret.push_back(s[i]);
}
return ret;
}
};
-
(
1
)
(1)
(1) 利用一個哈希陣列
hash[]來標記字串 t t t 中每個字符出現的次數; -
(
2
)
(2)
(2)
cnt代表要取的 子字串 中某一類字符的出現次數;needCnt代表 字串 t t t 中不同字符的出現次數; -
(
3
)
(3)
(3)
i和j代表在字串 s s s 上的兩個雙指標,初始化為空串,所以需要保證j - i + 1 == 0; -
(
4
)
(4)
(4)
l和r代表 子字串 的左右下標,ans的值恒等于j - i + 1; -
(
5
)
(5)
(5) 每次迭代回圈移動右指標
j,并且執行--hash[ s[j] ],一旦出現hash[ s[j] ] == 0,表示當前的 子字串 s [ i : j ] s[i:j] s[i:j] 中已經完全包含了 字串 t t t 中的 s [ j ] s[j] s[j] 字符,所以 執行cnt自增; -
(
6
)
(6)
(6) 當
cnt == needCnt時,通過 s [ i : j ] s[i:j] s[i:j] 是一個可行解,記錄下標到l和r; -
(
7
)
(7)
(7) 移動左指標
j,并且繼續判斷是否滿足題意;
VI、本題小知識
無符號整型在進行判斷的時候,如果賦值為 -1,就有可能導致變成整數最大值導致邏輯錯誤;
🍴六、坐標轉換
- 坐標轉換是比較常用的數學知識,一般用在一維轉二維,二維轉一維上,
I、例題描述
??給出一個由二維陣串列示的矩陣,以及兩個正整數 r r r 和 c c c ,分別表示想要的 重構 的矩陣的行數和列數,重構 后的矩陣需要將原始矩陣的所有元素以相同的行遍歷順序填充,如果具有給定引數 重構的操作是可行且合理的,則輸出新的重塑矩陣;否則,輸出原始矩陣,
??樣例輸入: n u m s = [ [ 1 , 2 ] , [ 3 , 4 ] ] , r = 1 , c = 4 nums = [[1,2],[3,4]], r = 1, c = 4 nums=[[1,2],[3,4]],r=1,c=4
??樣例輸出: [ [ 1 , 2 , 3 , 4 ] ] [[1,2,3,4]] [[1,2,3,4]]
??原題出處: LeetCode 566. 重塑矩陣
II、基礎框架
- c++ 版本給出的基礎框架代碼如下:
class Solution {
public:
vector<vector<int>> matrixReshape(vector<vector<int>>& mat, int r, int c) {
}
};
- 輸入陣列引數型別是
vector<vector<int>>&,代表的是一個參考型別的二維陣列,按照題目要求,需要回傳一個二維陣列;
III、思路分析
- 首先,原矩陣的個數統計出來,和 給出的引數的乘積 r × c r \times c r×c 比較,不相等則輸出原矩陣,
- 否則,我們來看個圖:
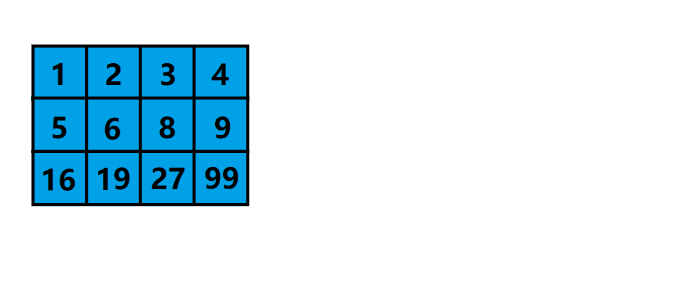
- 可以將原先的二維矩陣通過行遍歷轉換成一維的,然后再根據 r r r 和 c c c,每 r r r 個作為新矩陣的 行,進行重新填充,
- 對于一個 n × m n \times m n×m 的矩陣,我們可以從左往右,從上往下進行編號,令一維編號為 i d id id,
- 二維轉一維:
- i d = r × m + c id = r \times m + c id=r×m+c
- 一維轉二維:
- r = ? i d m ? c = i d m o d m r = \lfloor \frac {id} m \rfloor \\ c = {id} \ mod \ m r=?mid??c=id mod m
IV、時間復雜度
- 時間復雜度為 O ( n m ) O(nm) O(nm),
V、原始碼詳解
class Solution {
public:
vector<vector<int>> matrixReshape(vector<vector<int>>& mat, int r, int c) {
vector<vector<int>> ans;
int n = mat.size(); // (1)
int m = mat[0].size(); // (2)
if(n*m != r*c) {
return mat;
}
for(int i = 0; i < r; ++i) {
vector <int> v;
for(int j = 0; j < c; ++j) {
int id = i * c + j; // (3)
v.push_back(mat[id / m][id % m]); // (4)
}
ans.push_back(v); // (5)
}
return ans;
}
};
- ( 1 ) (1) (1) 獲取矩陣的行 n n n;
- ( 2 ) (2) (2) 獲取矩陣的列 m m m;
-
(
3
)
(3)
(3)
id = i * c + j代表原矩陣轉換成一維線性陣列以后的編號; - ( 4 ) (4) (4) 坐標的反向轉換,從一維重新轉換成二維;
- ( 5 ) (5) (5) 將一維向量塞到二維向量中,
VI、本題小知識
可以用 除法 和 取模 來實作兩個分量的坐標轉換,
🅱七、位運算
- 位運算可以理解成對二進制數字上的每一個位進行操作的運算,
- 位運算分為 布爾位運算子 和 移位位運算子,
- 布爾位運算子又分為 位與(&)、位或(|)、異或(^)、按位取反(~);移位位運算子分為 左移(<<) 和 右移(>>),
- 如圖所示:
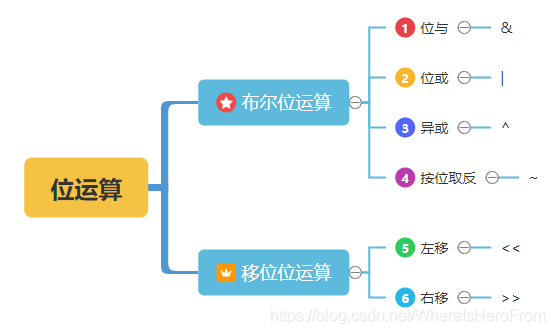
- 位運算的特點是陳述句短,但是可以干大事!
1、位與
??【例題7】給出一個整數,現在要求將這個整數轉換成二進制以后,將末尾連續的1都變成0,輸出改變后的數(以十進制輸出即可),
- 我們知道,這個數的二進制表示形式一定是:
- . . . 0 11...11 ? k ...0\underbrace{11...11}_{\rm k} ...0k 11...11??
- 如果,我們把這個二進制數加上1,得到的就是:
- . . . 1 00...00 ? k ...1\underbrace{00...00}_{\rm k} ...1k 00...00??
- 我們把這兩個數進行位與運算,得到:
- . . . 0 00...00 ? k ...0\underbrace{00...00}_{\rm k} ...0k 00...00??
- 所以,你學會了嗎?代碼如下:
x &= x - 1;
2、位或
【例題8】給定一個整數 x x x,將它低位連續的 0 都變成 1,
- 假設這個整數低位連續有 k k k 個零,二進制表示如下:
- . . . 1 00...00 ? k ...1\underbrace{00...00}_{\rm k} ...1k 00...00??
- 那么,如果我們對它進行減一操作,得到的二進制數就是:
- . . . 0 11...11 ? k ...0\underbrace{11...11}_{\rm k} ...0k 11...11??
- 我們發現,只要對這兩個數進行位或,就能得到:
- . . . 1 11...11 ? k ...1\underbrace{11...11}_{\rm k} ...1k 11...11??
- 也正是題目所求,所以代碼實作如下:
#include <stdio.h>
int main() {
int x;
scanf("%d", &x);
printf("%d\n", x | (x-1) ); // (1)
return 0;
}
-
(
1
)
(1)
(1)
x | (x-1)就是題目所求的 “低位連續零變一” ,
3、異或
【例題9】給定兩個數 a a a 和 b b b,用異或運算交換它們的值,
- 這個是比較老的面試題了,直接給出代碼:
#include <stdio.h>
int main() {
int a, b;
while (scanf("%d %d", &a, &b) != EOF) {
a = a ^ b; // (1)
b = a ^ b; // (2)
a = a ^ b; // (3)
printf("%d %d\n", a, b);
}
return 0;
}
- 我們直接來看
(
1
)
(1)
(1) 和
(
2
)
(2)
(2) 這兩句話,相當于
b等于a ^ b ^ b,根據異或的幾個性質,我們知道,這時候的b的值已經變成原先a的值了, - 而再來看第
(
3
)
(3)
(3) 句話,相當于
a等于a ^ b ^ a,還是根據異或的幾個性質,這時候,a的值已經變成了原先b的值, - 從而實作了變數
a和b的交換,
4、左移
- 對于 x x x 模上一個 2 的次冪的數 y y y,我們可以轉換成位與上 2 y ? 1 2^y-1 2y?1,
- 即在數學上的:
- x m o d 2 y x \ mod \ 2^y x mod 2y
- 在計算機中就可以用一行代碼表示:
x & ((1 << y) - 1),
?八、遞推
- 遞推也是數學中非常常見的問題,一般遞推問題在數學中有個名詞叫 遞推公式,我們可以通過遞推公式,加上計算機的回圈來實作最后的結果,最經典的當屬斐波那契數列了,
1、一維遞推
I、例題描述
??斐波那契數,通常用 F ( n ) F(n) F(n) 表示,形成的序列稱為 斐波那契數列 ,該數列由 0 和 1 開始,后面的每一項數字都是前面兩項數字的和,也就是: F ( 0 ) = 0 , F ( 1 ) = 1 F ( n ) = F ( n ? 1 ) + F ( n ? 2 ) F(0) = 0,F(1) = 1 \\ F(n) = F(n - 1) + F(n - 2) F(0)=0,F(1)=1F(n)=F(n?1)+F(n?2) 給定 n n n ,求 F ( n ) F(n) F(n),
??樣例輸入: 4
??樣例輸出: 5
??原題出處: LeetCode 509. 斐波那契數
II、基礎框架
- c++ 版本給出的基礎框架代碼如下:
class Solution {
public:
int fib(int n) {
}
};
III、思路分析
- 直接一層回圈列舉,遞推計算即可,
IV、時間復雜度
- 時間復雜度為一個
for回圈的次數,即 O ( n ) O(n) O(n),
V、原始碼詳解
class Solution {
int f[1000]; // (1)
public:
int fib(int n) {
f[0] = 0; // (2)
f[1] = 1;
for(int i = 2; i <= n; ++i) { // (3)
f[i] = f[i-1] + f[i-2];
}
return f[n]; // (4)
}
};
- ( 1 ) (1) (1) 用一個陣列來快取結果;
- ( 2 ) (2) (2) 初始化 n = 0 , 1 n=0,1 n=0,1 的情況;
- ( 3 ) (3) (3) 遞推求解;
- ( 4 ) (4) (4) 回傳最后的結果;
VI、本題小知識
數學上的遞推問題,在程式中不需要計算出通項公式,可以直接通過一個回圈來搞定!
2、二維遞推
I、例題描述
??給定一個非負整數 n u m R o w s numRows numRows,生成楊輝三角的前 n u m R o w s numRows numRows 行,
在楊輝三角中,每個數是它 左上方 和 右上方 的數的和,
??樣例輸入: 5
??樣例輸出:
??原題出處: LeetCode 118. 楊輝三角

II、基礎框架
- c++ 版本給出的基礎框架代碼如下:
class Solution {
public:
vector<vector<int>> generate(int numRows) {
}
};
- 可以理解成回傳的是一個二維陣列,
III、思路分析
- 根據楊輝三角的定義,我們可以簡單將上面的圖進行一個變形,得到:
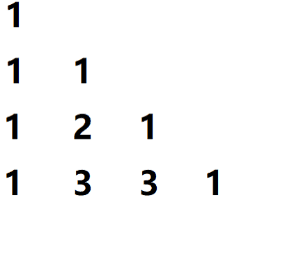
于是,我們可以得出以下結論:
??1)楊輝三角的所有數可以存盤在一個二維陣列中,行代表第一維,列代表第二維度;
??2)第 i i i 行的元素個數為 i i i 個;
??3)第 i i i 行 第 j j j 列的元素滿足公式: c [ i ] [ j ] = { 1 i = 0 c [ i ? 1 ] [ j ? 1 ] + c [ i ? 1 ] [ j ] o t h e r w i s e c[i][j] = \begin{cases} 1 & i=0\\ c[i-1][j-1] + c[i-1][j] & otherwise \end{cases} c[i][j]={1c[i?1][j?1]+c[i?1][j]?i=0otherwise?
- 于是就可以兩層回圈列舉了,
IV、時間復雜度
- 兩層回圈嵌套,所以時間復雜度 O ( n 2 ) O(n^2) O(n2),
V、原始碼詳解
class Solution {
public:
vector<vector<int>> generate(int numRows) {
vector<vector<int>> ans;
for(int i = 0; i < numRows; ++i) { // (1)
vector<int> v;
for(int j = 0; j <= i; ++j) { // (2)
if(j == 0 || j == i) {
v.push_back(1); // (3)
}else {
v.push_back( ans[i-1][j-1] + ans[i-1][j] ); // (4)
}
}
ans.push_back(v);
}
return ans;
}
};
- ( 1 ) (1) (1) 第一層回圈列舉行;
- ( 2 ) (2) (2) 第二層回圈列舉列,列的上限為行編號;
- ( 3 ) (3) (3) 楊輝三角兩邊恒為 1;
-
(
4
)
(4)
(4) 楊輝三角中間的數,為
c[i-1][j-1] + c[i-1][j];
VI、本題小知識
組合數的遞推求解,又被稱為 楊輝三角,
💥九、遞回
- 遞回說白了就是函式自己呼叫自己,只是呼叫引數的不同,
1、分治問題
I、例題描述
??給定兩個二叉樹,想象當你將它們中的一個覆寫到另一個上時,兩個二叉樹的一些節點便會重疊,需要將它們合并為一個新的二叉樹,合并的規則是如果兩個節點重疊,那么將他們的值相加作為節點合并后的新值,否則不為 NULL 的節點將直接作為新二叉樹的節點,
??樣例輸入:
??樣例輸出:
??原題出處: LeetCode 617. 合并二叉樹


II、基礎框架
- c++ 版本給出的基礎框架代碼如下:
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
TreeNode* mergeTrees(TreeNode* root1, TreeNode* root2) {
}
};
TreeNode代表一個二叉樹節點,有資料域和指標域兩部分組成,資料域為val,指標域為left和right,分別指向左右兩個子樹的根節點;
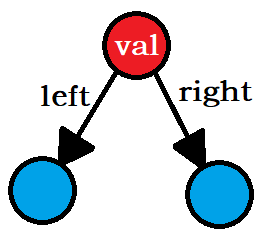
TreeNode* mergeTrees(TreeNode* root1, TreeNode* root2)這個介面,傳參root1和root2為兩個需要合并的二叉樹的根節點,回傳的是合并后的二叉樹的根節點,
III、思路分析
遇到二叉樹問題,基本第一個思路就是遞回,根據經驗,來談談遞回需要注意的點:
??1)遞回出口一定要考慮好,這個題的遞回出口就是兩棵樹中任意一棵是空樹的情況;
??2)對于非遞回出口,先處理根節點,再遞回處理 左子樹 和 右子樹,處理的程序中一定要清楚明白,處理的事情是什么,回傳值是什么,這個題中處理的事情就是將兩棵樹的根節點合并,回傳值就是合并后的樹根,合并后的樹根可以使用新申請的記憶體,
??3)需要注意,千萬不要回傳堆疊上變數的地址,函式銷毀的時候,堆疊變數的生命周期也就結束了,
IV、時間復雜度
- 每個節點只會訪問一次,時間復雜度為 O ( n ) O(n) O(n),
V、原始碼詳解
class Solution {
public:
TreeNode* mergeTrees(TreeNode* root1, TreeNode* root2) {
TreeNode *p = new TreeNode(); // (1)
if(root1 == nullptr) {
return root2; // (2)
}else if(root2 == nullptr) {
return root1; // (3)
}else {
p->val = root1->val + root2->val; // (4)
p->left = mergeTrees(root1->left, root2->left); // (5)
p->right = mergeTrees(root1->right, root2->right); // (6)
}
return p;
}
};
-
(
1
)
(1)
(1) 必須在堆上申請記憶體,否則函式回傳時就銷毀了;這里的
p為合并后的樹的根節點指標; -
(
2
)
(2)
(2) 如果
root1為空樹,則直接回傳root2; -
(
3
)
(3)
(3) 如果
root2為空樹,則直接回傳root1; -
(
4
)
(4)
(4) 當兩者都不為空樹時,將兩棵樹的根節點的值相加,賦值給合并后的樹根的資料域
val; - ( 5 ) (5) (5) 遞回合并左子樹;
- ( 6 ) (6) (6) 遞回合并右子樹;
VI、本題小知識
遞回問題,千萬不要回傳堆疊上變數的地址(從堆上申請),函式銷毀的時候,堆疊變數的生命周期也就結束了,
2、連通塊問題
I、例題描述
??給定一個包含了一些 0 和 1 的非空二維陣列 g r i d grid grid ,一個 島嶼 是由一些相鄰的 1 (代表土地) 構成的組合,這里的「相鄰」要求兩個 1 必須在水平或者豎直方向上相鄰,你可以假設 g r i d grid grid 的四個邊緣都被 0(代表水)包圍著,找到給定的二維陣列中最大的島嶼面積,
??樣例輸入1: [ [ 1 , 0 , 1 ] , [ 1 , 1 , 1 ] , [ 0 , 0 , 1 ] ] [[1,0,1],[1,1,1],[0,0,1]] [[1,0,1],[1,1,1],[0,0,1]]
??樣例輸出1: 6 6 6
??
??樣例輸入2: [ [ 1 , 0 , 1 ] , [ 0 , 1 , 0 ] , [ 0 , 0 , 1 ] ] [[1,0,1],[0,1,0],[0,0,1]] [[1,0,1],[0,1,0],[0,0,1]]
??樣例輸出2: 1 1 1
??原題出處: LeetCode 695. 島嶼的最大面積
II、基礎框架
- c++ 版本給出的基礎框架代碼如下,定義一個函式
maxAreaOfIsland,函式的引數是一個vector的嵌套,代表的是一個二維陣列; vector<vector<int>>可以理解成vector<T>,其中T代表vector的元素,并且這個元素是另一個vector<int>,當然,可以嵌套的實作三維陣列,甚至更高維的陣列,
class Solution {
public:
int maxAreaOfIsland(vector<vector<int>>& grid) {
}
};
III、思路分析
- 對 g r i d grid grid 中的每個 1 抽象成一個節點,且都有一個唯一編號,兩個水平或者垂直方向相鄰且都為 1,則在這兩個節點之間連接一條無向邊,舉個例子:
- [ 1 0 0 1 1 1 0 1 0 1 1 1 ] \left[ \begin{matrix} 1 & 0 & 0 & 1 \\ 1 & 1 & 0 & 1 \\ 0 & 1 & 1 & 1 \end{matrix} \right] ???110?011?001?111????
- 先將每個 1 的位置都分配一個編號,假設行號為 i i i,列號為 j j j,則它的編號就是 i × 4 + j i \times 4 + j i×4+j,其中 4 4 4 代表總共有多少列,如下:
- [ 0 E E 3 4 5 E 7 E 9 10 11 ] \left[ \begin{matrix} 0 & E & E & 3 \\ 4 & 5 & E & 7 \\ E & 9 & 10 & 11 \end{matrix} \right] ???04E?E59?EE10?3711????
- E E E 的含義是 Empty 的意思,可以用一個額外的編號(不和其它現有編號沖突)表示,比如 -1,
- 所以,它其實應該是這樣一個圖:
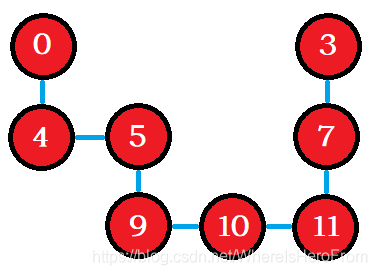
- 這樣,我們就可以轉換成用深度優先搜索來求連通塊問題了,
- 關于深度優先搜索的更深入內容,可以參考這篇文章:夜深人靜寫演算法(一)- 搜索入門,
IV、時間復雜度
- 由于有哈希陣列在,所以 g r i d grid grid 的每個元素最多被訪問一次,如果長 n n n 寬為 m m m 的 g r i d grid grid,時間復雜度為 O ( n m ) O(nm) O(nm),
V、原始碼詳解
const int dir[4][2] = { {0, 1}, {0, -1}, {1, 0}, {-1, 0} }; // (1)
int bHash[100][100]; // (2)
int n, m; // (3)
class Solution {
public:
void dfs(vector<vector<int>>& grid, int &count, int x, int y) { // (4)
if(x < 0 || y < 0 || x >= n || y >= m) {
return ; // (5)
}
if(!grid[x][y]) {
return ; // (6)
}
if(bHash[x][y]) {
return; // (7)
}
bHash[x][y] = 1;
++count;
for(int i = 0; i < 4; ++i) {
dfs(grid, count, x + dir[i][0], y + dir[i][1]); // (8)
}
}
int maxAreaOfIsland(vector<vector<int>>& grid) {
n = grid.size();
m = grid[0].size();
memset(bHash, 0, sizeof(bHash));
int count = 0, maxv = 0;
for(int i = 0; i < n; ++i) {
for(int j = 0; j < m; ++j) {
if(grid[i][j] && !bHash[i][j]) { // (9)
count = 0;
dfs(grid, count, i, j);
maxv = max(maxv, count); // (10)
}
}
}
}
return maxv;
}
};
- ( 1 ) (1) (1) 代表四個方向的全域向量;
- ( 2 ) (2) (2) 二維的哈希陣列,用來標記一個位置有沒有被訪問過;
- ( 3 ) (3) (3) 全域快取 g r i d grid grid 的寬 和 高;
-
(
4
)
(4)
(4) 用于對全域進行搜素的遞回函式,
grid作為參考傳參提高效率,count作為參考傳參是當全域變數來用的,x,y代表的是當前列舉到的 行 和 列, - ( 5 ) (5) (5) 如果遇到搜索到邊界的情況,終止搜索;
- ( 6 ) (6) (6) 如果遇到不是島嶼的情況,終止搜索;
-
(
7
)
(7)
(7) 如果遇到已經搜索過的島嶼,終止搜索;否則,標記
(x,y)被搜索過,且計數器count自增, - ( 8 ) (8) (8) 繼續列舉四方向的下一個位置;
-
(
9
)
(9)
(9)
grid的每個位置未被訪問過(!bHash[i][j])的島嶼(grid[i][j])都必須列舉到; -
(
10
)
(10)
(10) 取最大的連通塊,
max為系統庫函式;
VI、本題小知識
利用深度優先搜索,可以用來求圖的連通塊問題,
3、全排列列舉
I、例題描述
??給定一個 不含重復數字 的長度小于 7 的陣列 n u m s nums nums ,回傳其 所有可能的全排列,
??樣例輸入: n u m s = [ 1 , 2 , 3 ] nums = [1,2,3] nums=[1,2,3]
??樣例輸出: [ [ 1 , 2 , 3 ] , [ 1 , 3 , 2 ] , [ 2 , 1 , 3 ] , [ 2 , 3 , 1 ] , [ 3 , 1 , 2 ] , [ 3 , 2 , 1 ] ] [[1,2,3],[1,3,2],[2,1,3],[2,3,1],[3,1,2],[3,2,1]] [[1,2,3],[1,3,2],[2,1,3],[2,3,1],[3,1,2],[3,2,1]]
??原題出處: LeetCode 46. 全排列
II、基礎框架
- c++ 版本給出的基礎框架代碼如下:
class Solution {
public:
vector<vector<int>> permute(vector<int>& nums) {
}
};
- 定義一個函式
permute,函式的引數是一個vector,代表的是一個陣列; - 回傳值是
vector<vector<int>>可以理解成vector<T>,其中T代表vector的元素,并且這個元素是另一個vector<int>,當然,可以嵌套的實作三維陣列,甚至更高維的陣列,
III、思路分析
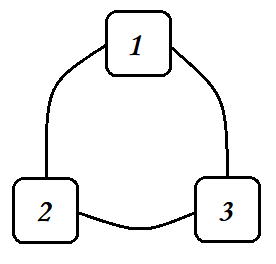
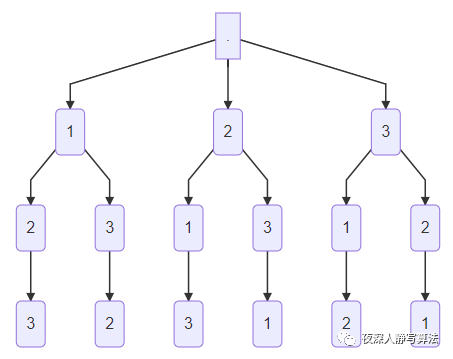
- 全排列的種數是 n ! n! n!,這是最典型的深搜問題,我們可以把 n n n 個數兩兩建立無向邊(即任意兩個結點之間都有邊,也就是一個 n n n 個結點的完全圖),然后對每個點作為起點,分別做一次深度優先搜索,當所有點都已經標記時,輸出當前的搜索路徑,就是其中一個排列;
- 這里需要注意的是,回溯的時候需要將原先標記的點的標記取消,否則只能輸出一個排列,
- 如下圖,代表的是3個數的圖表示:
- 3個數的全排列的深度優先搜索空間樹如下圖所示:
- 關于深度優先搜索的更深入內容,可以參考這篇文章:夜深人靜寫演算法(一)- 搜索入門,
IV、時間復雜度
- 由于每次訪問后會將標記過的節點標記回來,所以時間復雜度就是排列數,即 O ( n ! ) O(n!) O(n!),
V、原始碼詳解
class Solution {
int hash[6];
void dfs(int dep, int maxdep, vector<int>& nums, vector<vector<int>>& ans, vector<int>& st) { // (1)
if(dep == maxdep) {
ans.push_back( st ); // (2)
return ;
}
for(int i = 0; i < maxdep; ++i) {
if(!hash[i]) { // (3)
hash[i] = 1;
st.push_back( nums[i] );
dfs(dep + 1, maxdep, nums, ans, st); // (4)
st.pop_back(); // (5)
hash[i] = 0; // (6)
}
}
}
public:
vector<vector<int>> permute(vector<int>& nums) {
vector<vector<int>> ans;
memset(hash, 0, sizeof(hash));
vector<int> st;
dfs(0, nums.size(), nums, ans, st);
return ans;
}
};
-
(
1
)
(1)
(1)
dep代表本地遞回訪問第幾個節點,maxdep代表遞回的層數,vector<int>& nums則代表原始輸入陣列,vector<vector<int>>& ans代表結果陣列,vector<int>& st代表存盤當前搜索結果的堆疊; -
(
2
)
(2)
(2)
dep == maxdep代表一次全排列訪問,這時候得到一個可行解,放入結果陣列中; -
(
3
)
(3)
(3) 如果節點
i
i
i 未訪問,則將第
i
i
i 個節點的值塞入搜索結果堆疊,并且用
hash陣列標記已訪問; - ( 4 ) (4) (4) 繼續遞回呼叫下一層;
- ( 5 ) (5) (5) 將堆疊頂元素彈出,代表本次訪問的回溯;
- ( 6 ) (6) (6) 取消陣列標記;
VI、本題小知識
利用深度優先搜索,可以用來求全排列問題,
🚕十、簡單動態規劃
1、線性DP
1)遞推型
I、例題描述
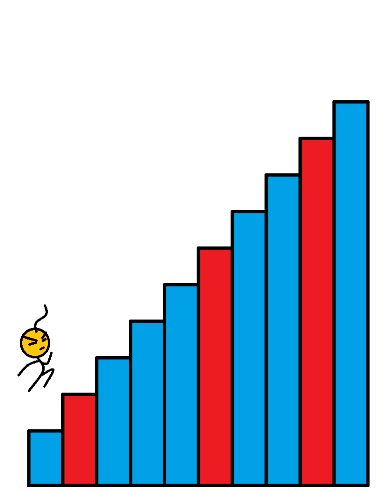
??陣列的每個下標作為一個階梯,第 i i i 個階梯對應著一個非負數的體力花費值 c o s t [ i ] cost[i] cost[i](下標從 0 開始),每當爬上一個階梯,都要花費對應的體力值,一旦支付了相應的體力值,就可以選擇 向上爬一個階梯 或者 爬兩個階梯,求找出達到樓層頂部的最低花費,在開始時,可以選擇從下標為 0 或 1 的元素作為初始階梯,
??樣例輸入: c o s t = [ 1 , 99 , 1 , 1 , 1 , 99 , 1 , 1 , 99 , 1 ] cost = [1, 99, 1, 1, 1, 99, 1, 1, 99, 1] cost=[1,99,1,1,1,99,1,1,99,1]
??樣例輸出: 6 6 6
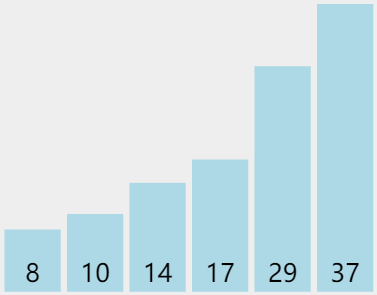
如圖所以,藍色的代表消耗為 1 的樓梯,紅色的代表消耗 99 的樓梯,
??原題出處: LeetCode 746. 使用最小花費爬樓梯
II、基礎框架
- c++ 版本給出的基礎框架代碼如下:
class Solution {
public:
int minCostClimbingStairs(vector<int>& cost) {
}
};
III、思路分析
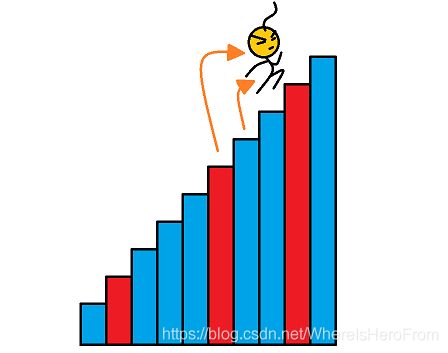
- 令走到第 i i i 層的最小消耗為 f [ i ] f[i] f[i]
- 假設當前的位置在 i i i 層樓梯,那么只可能從 i ? 1 i-1 i?1 層過來,或者 i ? 2 i-2 i?2 層過來;
- 如果從 i ? 1 i-1 i?1 層過來,則需要消耗體力值: f [ i ? 1 ] + c o s t [ i ? 1 ] f[i-1] + cost[i-1] f[i?1]+cost[i?1];
- 如果從 i ? 2 i-2 i?2 層過來,則需要消耗體力值: f [ i ? 2 ] + c o s t [ i ? 2 ] f[i-2] + cost[i-2] f[i?2]+cost[i?2];
- 起點可以在第 0 或者 第 1 層,于是有狀態轉移方程:
-
f
[
i
]
=
{
0
i
=
0
,
1
min
?
(
f
[
i
?
1
]
+
c
o
s
t
[
i
?
1
]
,
f
[
i
?
2
]
+
c
o
s
t
[
i
?
2
]
)
i
>
1
f[i] = \begin{cases} 0 & i=0,1\\ \min ( f[i-1] + cost[i-1], f[i-2] + cost[i-2] ) & i > 1\end{cases}
f[i]={0min(f[i?1]+cost[i?1],f[i?2]+cost[i?2])?i=0,1i>1?
IV、時間復雜度
- 狀態數: O ( n ) O(n) O(n)
- 狀態轉移: O ( 1 ) O(1) O(1)
- 時間復雜度: O ( n ) O(n) O(n)
V、原始碼詳解
class Solution {
int f[1100]; // (1)
public:
int minCostClimbingStairs(vector<int>& cost) {
f[0] = 0, f[1] = 0; // (2)
for(int i = 2; i <= cost.size(); ++i) {
f[i] = min(f[i-1] + cost[i-1], f[i-2] + cost[i-2]); // (3)
}
return f[cost.size()];
}
};
-
(
1
)
(1)
(1) 用
f[i]代表到達第 i i i 層的消耗的最小體力值, - ( 2 ) (2) (2) 初始化;
- ( 3 ) (3) (3) 狀態轉移;
VI、本題小知識
有沒有發現,這個問題和斐波那契數列很像,只不過斐波那契數列是求和,這里是求最小值,
2)最大子段和
I、例題描述
??給定一個整數陣列 n u m s nums nums ,找到一個具有最大和的連續子陣列(子陣列最少包含一個元素),回傳其最大和,
??樣例輸入: n u m s = [ ? 2 , 1 , ? 3 , 4 , ? 1 , 2 , 1 , ? 5 , ? 7 ] nums = [-2,1,-3,4,-1,2,1,-5,-7] nums=[?2,1,?3,4,?1,2,1,?5,?7]
??樣例輸出: 6 6 6, 即 [ 4 , ? 1 , 2 , 1 ] [4,-1,2,1] [4,?1,2,1],
??原題出處: LeetCode 53. 最大子序和
II、基礎框架
- c++ 版本給出的基礎框架代碼如下:
class Solution {
public:
int maxSubArray(vector<int>& nums) {
}
};
III、思路分析
由于要求的是連續的子陣列,所以對于第 i i i 個元素,狀態轉移一定是從 i ? 1 i-1 i?1 個元素轉移過來的,
- 基于這一點,可以令 f [ i ] f[i] f[i] 表示以 i i i 號元素結尾的最大值,
- 那么很自然,這個最大值必然包含 n u m s [ i ] nums[i] nums[i] 這個元素,那么要不要包含 n u m s [ i ? 1 ] , n u m s [ i ? 2 ] , n u m s [ i ? 3 ] , . . . , n u m s [ k ] nums[i-1],nums[i-2],nums[i-3],...,nums[k] nums[i?1],nums[i?2],nums[i?3],...,nums[k] 呢?其實就是看第 i ? 1 i-1 i?1 號元素結尾的最大值是否大于零,也就是:當 f [ i ? 1 ] ≤ 0 f[i-1] \le 0 f[i?1]≤0 時,則 前 i ? 1 i-1 i?1 個元素是沒必要包含進來的,所以就有狀態轉移方程:
- f [ i ] = { n u m s [ 0 ] i = 0 n u m s [ i ] f [ i ? 1 ] ≤ 0 n u m s [ i ] + f [ i ? 1 ] f [ i ? 1 ] > 0 f[i] = \begin{cases} nums[0] & i = 0 \\ nums[i] & f[i-1] \le 0 \\ nums[i] + f[i-1] & f[i-1] > 0\end{cases} f[i]=??????nums[0]nums[i]nums[i]+f[i?1]?i=0f[i?1]≤0f[i?1]>0?
- 一層回圈列舉后,取 m a x ( f [ i ] ) max(f[i]) max(f[i]) 就是答案了,
IV、時間復雜度
- 狀態數: O ( n ) O(n) O(n)
- 狀態轉移: O ( 1 ) O(1) O(1)
- 時間復雜度: O ( n ) O(n) O(n)
V、原始碼詳解
class Solution {
int f[30010];
public:
int maxSubArray(vector<int>& nums) {
int maxValue = nums[0];
f[0] = nums[0]; // (1)
for(int i = 1; i < nums.size(); ++i) {
f[i] = nums[i];
if(f[i-1] > 0) {
f[i] += f[i-1]; // (2)
}
maxValue = max(maxValue, f[i]); // (3)
}
return maxValue;
}
};
- ( 1 ) (1) (1) 初始值;
- ( 2 ) (2) (2) 狀態轉移;
- ( 3 ) (3) (3) 程序中取最大值;
VI、本題小知識
連續子陣列問題,可以考慮前一個元素已經計算出來的狀態進行下一個元素的求解,
3)最長遞增子序列
- 更多有關最長遞增子序列的內容,限于字數的關系的關系,不便再做展開,有興趣的讀者可以參考以下這篇文章:夜深人靜寫演算法(二十)- 最長單調子序列,
2、序列匹配問題
1)正則運算式匹配
I、例題描述
??給定一個 匹配字串 s (只包含小寫字母) 和一個 模式字串 p (包含小寫字母和兩種額外字符:
'.'和'*'),要求實作一個支持'.'和'*'的正則運算式匹配('*'前面保證有字符),
??'.'匹配任意單個字符
??'*'匹配零個或多個前面的那一個元素
??樣例輸入:s = "mississippi"、p = "mis*is*p*."
??樣例輸出:false,
??原題出處: LeetCode 10. 正則運算式匹配
II、基礎框架
- c++ 版本給出的基礎框架代碼如下:
class Solution {
public:
bool isMatch(string str, string pattern) {
}
};
str是匹配串;pattern是模式串;
III、思路分析
- 這是個經典的 串匹配 問題,可以按照 最長公共子序列 的思路去解決,
- 令 f ( i , j ) f(i, j) f(i,j) 代表的是 匹配串前綴 s[0:i] 和 模式串前綴 p[0:j] 是否有匹配,只有兩個值: 0 代表 不匹配, 1 代表 匹配,
于是,對模式串進行分情況討論:
??1)當 p[j] 為.時,代表 s[i] 為任意字符時,它都能夠匹配(沒毛病吧?沒毛病),所以問題就轉化成了求 匹配串前綴 s[0:i-1] 和 模式串前綴 p[0:j-1] 是否有匹配的問題,也就是這種情況下 f ( i , j ) = f ( i ? 1 , j ? 1 ) f(i, j) = f(i-1, j-1) f(i,j)=f(i?1,j?1),如圖1所示:
圖1
??2)當 p[j] 為*時,由于*前面保證有字符,所以拿到字符 p[j-1],分情況討論:
????2.a)如果 p[j-1] 為.時,可以匹配所有 s[0:i] 的后綴,這種情況下,只要 f ( k , j ? 2 ) f(k, j-2) f(k,j?2) 為 1, f ( i , j ) f(i, j) f(i,j) 就為 1;其中 k ∈ [ 0 , i ] k \in [0, i] k∈[0,i],如圖2所示:
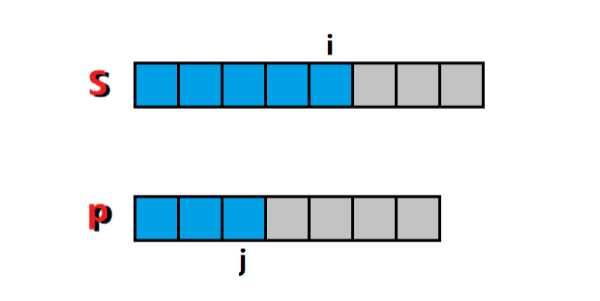
圖2
????2.b)如果 p[j-1] 非.時,只有當 s[0:i] 的后綴 字符全為 p[j-1] 時,才能去匹配 s[0:i] 的前綴,同樣轉化成 f ( k , j ? 2 ) f(k, j-2) f(k,j?2) 的子問題,如圖3所示:

圖3
??3)當 p[j] 為其他任意字符時,一旦 p[j] 和 s[i] 不匹配,就認為 f ( i , j ) = 0 f(i, j) = 0 f(i,j)=0,否則 f ( i , j ) = f ( i ? 1 , j ? 1 ) f(i, j) = f(i-1, j-1) f(i,j)=f(i?1,j?1),如圖4所示:
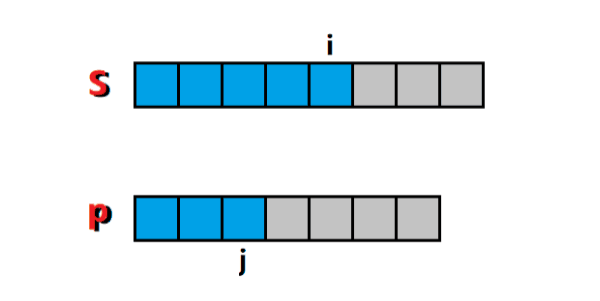
圖4
- 最后,這個問題可以采用記憶化搜索求解,并且需要考慮一些邊界條件,邊界條件可以參考代碼實作中的講解,
- 有關記憶化搜索的內容,可以參考以下這篇文章:夜深人靜寫演算法(二十六)- 記憶化搜索,
- 有關最長公共子序列的內容,可以參考以下這篇文章:夜深人靜寫演算法(二十一)- 最長公共子序列,
IV、時間復雜度
- 匹配串的長度為 n n n,模式串的長度為 m m m,
- 狀態數: O ( n m ) O(nm) O(nm)
- 狀態轉移: O ( n ) O(n) O(n)
- 時間復雜度: O ( n 2 m ) O(n^2m) O(n2m)
V、原始碼詳解
const int maxn = 110;
class Solution {
public:
int dfs(int dp[maxn][maxn], string& str, string& pattern, int sidx, int pidx) {
if(sidx == -1 && pidx == -1) // (1)
return 1;
if(pidx == -1) // (2)
return 0;
if(sidx == -2) { // (3)
return 0;
}
int &x = dp[sidx+1][pidx+1]; // (4)
if(x != -1)
return x; // (5)
x = 0; // (6)
if(pattern[pidx] == '.') {
x |= dfs(dp, str, pattern, sidx-1, pidx-1); // (7)
}else if(pattern[pidx] == '*') {
if(pidx == 0) {
x |= dfs(dp, str, pattern, sidx, pidx-1);
}else {
char c = pattern[pidx-1];
x |= dfs(dp, str, pattern, sidx, pidx-2); // (8)
for(int i = sidx; i >= 0; --i) {
if(c == '.' || c == str[i]) { // (9)
x |= dfs(dp, str, pattern, i - 1, pidx - 2);
}else {
break;
}
}
}
}else {
if(sidx >= 0 && pattern[pidx] == str[sidx]) // (10)
x |= dfs(dp, str, pattern, sidx-1, pidx-1);
else // (11)
x = 0;
}
return x;
}
bool isMatch(string str, string pattern) {
int dp[maxn][maxn];
int len = str.size();
int plen = pattern.size();
memset(dp, -1, sizeof(dp));
int ans = dfs(dp, str, pattern, len-1, plen-1);
return ans;
}
};
-
(
1
)
(1)
(1) 邊界情況1:空匹配串 和 空模式串 的匹配,直接回傳
1; -
(
2
)
(2)
(2) 邊界情況2:非空匹配串 和 空模式串 是無法匹配的,直接回傳
0; -
(
3
)
(3)
(3) 邊界情況3:空匹配串 和 非空模式串 也是無法匹配的,直接回傳
0; - ( 4 ) (4) (4) 記憶化的部分,避免 -1 陣列下標越界,采用 +1 偏移;
- ( 5 ) (5) (5) 利用記憶化,已經計算出結果的,則直接回傳;
- ( 6 ) (6) (6) 初始時,認為都不匹配;
-
(
7
)
(7)
(7)
.表示匹配任意單個字符,對應上文 1)的情況; -
(
8
)
(8)
(8) 讓
c*去匹配空串,剩下的進行匹配; -
(
9
)
(9)
(9) 只要模式字符是
.或者 匹配字符 和 模式字符 相等,都能夠進行下一步匹配;對應上文 2)的情況; - ( 10 ) (10) (10) 和 ( 11 ) (11) (11) 對應上文 3)的情況,
VI、本題小知識
??兩個串的模式匹配問題,可以采用動態規劃求解,實作方式可以采用記憶化搜索,更加好理解,這題對于求職來說較難,如果在面試的遇到,那表明你運氣不好哈(當然,不排除你是 ACM 大神!Good Luck!),
2)最長公共子序列
- 限于篇幅,有關最長公共子序列的問題,可以參考:夜深人靜寫演算法(二十一)- 最長公共子序列,
3)最短編輯距離
- 限于篇幅,有關最短編輯距離的問題,可以參考:夜深人靜寫演算法(二十二)- 最小編輯距離,
3、背包問題
- 背包相關的所有問題,可以參考:夜深人靜寫演算法(十九)- 背包總覽,
4、記憶化搜索
- 記憶化相關問題,可以參考:夜深人靜寫演算法(二十六)- 記憶化搜索,
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/290995.html
標籤:其他