容器型資料型別——字串
字串的定義
注意!!!:字串同元組一樣只能進行讀操作,不能進行寫操作
在Python程式中,如果我們把單個或多個字符用單引號或者雙引號包圍起來,就可以表示一個字串,字串中的字符可以是特殊符號、英文字母、中文字符、日文的平假名或片假名、希臘字母、Emoji字符等,
字串的運算
再次注意:字串和元組一樣也是不變的資料型別,只能讀操作不能寫操作
回圈遍歷字串每個字符
a = 'hello world'
#獲取字串的長度(空格也算)
print(len(a))
#回圈遍歷字串每個字符
for i in range(len(a)):#i表示下標
print(a)
for i in a: #i表示元素
print(i)
重復運算
a = 'hello world'
print(a * 5)
成員運算
a = 'hello world'
print('or' in a)
print('ko' in a)
比較運算
(比較字串的內容)比的是字符編碼的大小
a = 'hello world'
b = 'hello,world'
print(a == b)
print(a != b)
c = 'goodbye, world'
print(b>c)
d = 'hello, everybody'
print(b >=c)
print(ord('g'),ord('h'))
字串的索引和切片
字串的索引與切片與串列元組一樣
a = 'hello, world'
print(a[0],a[-len(a)])
print(a[len(a) - 1],a[-1])
print(a[a], a[-7])
print(a[2:5])
print(a[1:10:2])
print(a[::-1])
字串相關函式與操作
操作字串大小寫
-
upper()全變大寫 -
lower()全變小寫 -
capitalize()首字母大寫 -
title()每個單詞首字母大寫a = 'hello, world123' print(a.upper()) #變全大寫 print(a.lower()) #變全小寫 print(a.capitalize()) #首字母大寫 print(a.title()) #每個單詞首字母大寫 print(a) #可以看出前面操作對字串沒有改變
判斷字串性質
判斷字串的性質回傳的都是布林值
在以后的資料分析中我們查看資料的性質會用到此些函式
-
isdigit()判斷字串是不是數字 -
isalpha()判斷字串是不是字母 -
isalnum()判斷字串是不是字母和數字 -
isascii()判斷字串是不是ASCII碼 (python3.0以后才有此函式)b = 'abc123' print(b.isdigit())#判斷字串是不是數字 print(b.isalpha())#判斷字串是不是字母 print(b.isalnum())#判斷字串是不是字母和數字 print(b.isascii())#判斷字串是不是ASCII碼 python 3.7 以上版本 -
startswith()判斷字串是否以指定內容開頭 -
endswith()判斷字串是否以指定內容結尾c = '你好呀' print(c.startswith('你好'))#判斷字串是否以指定內容開頭 print(c.endswith('啊'))#判斷字串是否以指定內容結尾
查找有沒有子串
-
index()/rindex()從左開始查找 / 從右開始查找 -
find()/rfind()同上a = 'hO apple, i love apple.' #index --> 從左向右尋找指定的字串,可以指定從哪開始找,默認是0 #找到了回傳字串對應的索引(下標),找不到直接報錯(程式崩潰) print(a.index('apple')) print(a.index('apple',10)) print(a.rindex('apple'))#從右向左 #同上 但查找不到不會報錯 print(a.find('apple')) print(a.find('apple', 10)) print(a.rfind('apple')) print(a.find('banana')) print(a.rfind('banana'))
字串對齊操作
-
center()居中 -
rjust()右對齊 -
ljust()左對齊a = 'hello, world' print(a.center(80, '~')) # 居中80個字符 可以指定字符,默認空格,用~填充也可換其它 print(a.rjust(80, '=')) # 右對齊 print(a.ljust(80, '-')) # 左對齊 -
zfill()零填充(在左邊補0)b = '123' print(b.zfill(6)) # 零填充(在左邊補六個0)
字串的修剪操作
-
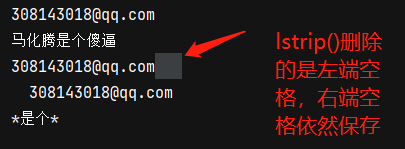
strip()修剪字串兩端空格 -
lstrip()修剪字串左端空格 -
rstrip()修剪字串右端空格 -
replace()將指定的字串替換為新的內容email = ' 308143018@qq.com ' content = ' 馬化騰是個傻逼 ' #修剪字串左右兩端空格 print(email.strip()) print(content.strip()) #修剪字串左端的空格 print(email.lstrip()) #修剪字串右端的空格 print(email.rstrip()) #將指定的字串替換為新的內容 print(content.strip().replace('馬化騰','*').replace('傻逼','*'))
字串的拆分與合并
-
split()用空格拆分字串得到一個串列 -
rsplit()從右向左進行字串拆分 -
print(' '.join(contents))將串列中的字串,用指定的字符連接起來content = 'You go your way, I will go mine.' content2 = content.replace(',','').replace(',','') # 用空格拆分字串得到一個串列 words = content2.split() print(words, len(words)) for word in words: print(word) # 用空格拆分字串,最多允許拆分三次 words = content2.split(' ', maxsplit=3) print(words, len(words)) #從右向左進行字串拆分,做多允許拆分三次 words = content2.rsplit(' ',maxsplit=3) print(words,len(words)) #用逗號拆分字串 items = content.split(',') for item in items: print(item) contents = [ '請不要相信我的美麗', '更不要相信我的愛情', '因為在涂滿油彩的面孔下', '有著一顆戲子的心' ] #將串列中的字串,用指定的字符連接起來 這里用的是空格 print(' '.join(contents))
字串的編碼與解碼
字串的編碼與解碼非常重要,在我們的以后資料提取與分析中有著重要的作用,
要點;
1.選者字符集(編碼)的時候,最佳的選擇(也是默認的)是UTF-8,
2.編碼和解碼的字符集要保持一致,否則就會出現亂碼現象,
3.不能用IOS-8856-1編碼保存中文,否則會出現編碼黑洞,中文變成?,
4.UTF-8是Unicode的一種實作方案,也一種變長的編碼,
最少1個位元組(英文和數字),最多4個位元組(Emoji),表示中文用3個位元組,
編碼,str(字串) --->encode() --->bytes(位元組串)
解碼:bytes(位元組串) --->decode() --->str(字串)
-
encode()編碼 -
decode()解碼# 字串的編碼和解碼(gbk《——gbk2312 《——ASCII) # 編碼(以后選UTF-8(萬國碼),變長的編碼方式,中文占3個字符) # .encode(編碼型別) # 默認UTF-8 # 解碼 # .decode(編碼型別) # 例子: a = '我愛你中國' print(a.encode('gbk')) b = b'\xce\xd2\xb0\xae\xc4\xe3\xd6\xd0\xb9\xfa' print(b.decode('gbk')) message = 'attack at dawn' # 生成字串轉換的對照表 table = str.maketrans( 'abcdefghijklmnopqrstuvwxyz', 'defghijklmnopqrstuvwxyzabc' ) # 通過字串的.translate()方法實作字串的轉譯 print(message.translate(table))
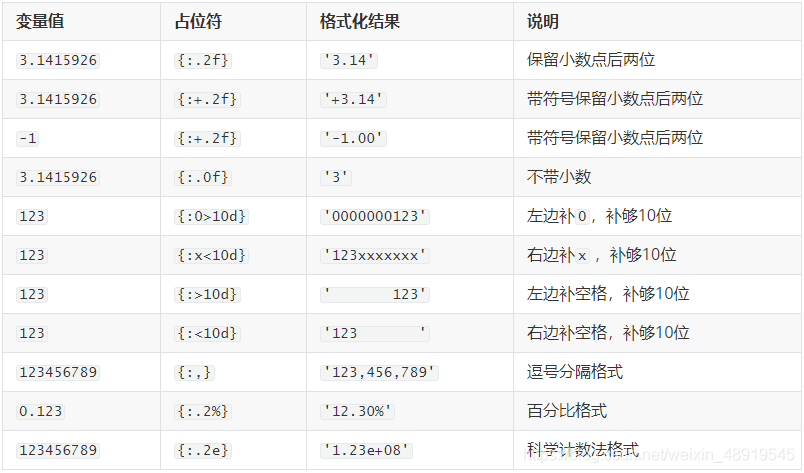
字串格式化操作
主要有三種
c = 1234
d = 345
print(f'{c}+{d}={c + d:.2f}')# python 3.6 以上才有的格式化字串的語法 :.2f 輸出結果保留兩位小數
#下面和上面的寫法等價的語法 建議使用這一種
print('%d + %d = %d' % (c, d, c + d))
print('{}+{}={}'.format(c, d, c + d))
print('{2}+{1}={0}'.format(c + d, d, c))#也可以加下標表示對應的位置
訓練
生成隨機驗證碼(數字由文字字母構成,長度為4)
方法一
import random
nums = [str(i) for i in range(10)]#把0~9轉換成字串串列
print(nums)
big_leteers = [chr(i) for i in range(65,91)]#把26個字母的ASCII碼轉換成字符
print(big_leteers)
small_letters = [chr(i) for i in range(97,123)]#小寫
all_letters = big_leteers + small_letters+nums#拼接
for _ in range(4):
selected_chars = random.choices(all_letters,k=4) #choices()隨機又放回抽樣 抽4次
print(''.join(selected_chars))#把串列內字串連接起來
print()
方法二
import random
import string #字串模塊
all_chars = string.ascii_letters +string.digits#把字母和數字拼接
for _ in range(4):
selected_chars = random.choices(all_chars,k=4)
print(''.join(selected_chars))
總結
知道如何表示和操作字串對程式員來說是非常重要的,因為我們需要處理文本資訊,Python中操作字串可以用拼接、切片等運算子,也可以使用字串型別的方法,
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/291085.html
標籤:其他
下一篇:演算法效率(時間與空間復雜度)