聊聊 “吳牙簽” 背后的搜索引擎技術
大家好,我是魚皮,今天分享點有趣的技術知識,
前兩天,我想上網買包牙簽,于是就打開了某度搜索,
結果讓我懵逼,我搜到的第一條內容竟然不是拿來剔牙的工具,而是搜出了一位明星,江湖美譽 “吳牙簽”,
原來是最近的一個大瓜,你看這個簽它又細又扎 🎵 ~

在吃瓜的同時,問題來了:為什么搜索牙簽時,最先搜出來的不是傳統牙簽而是老吳呢?
作為一名程式員,有必要給大家科普一下互聯網 搜索引擎 的作業原理,看看它是怎么幫助我們從數億個網站中精準地把這根牙簽找出來的!
搜索引擎作業原理
內容參考百度官方的搜索引擎作業原理介紹
先放一張官方的搜索引擎作業流程圖:
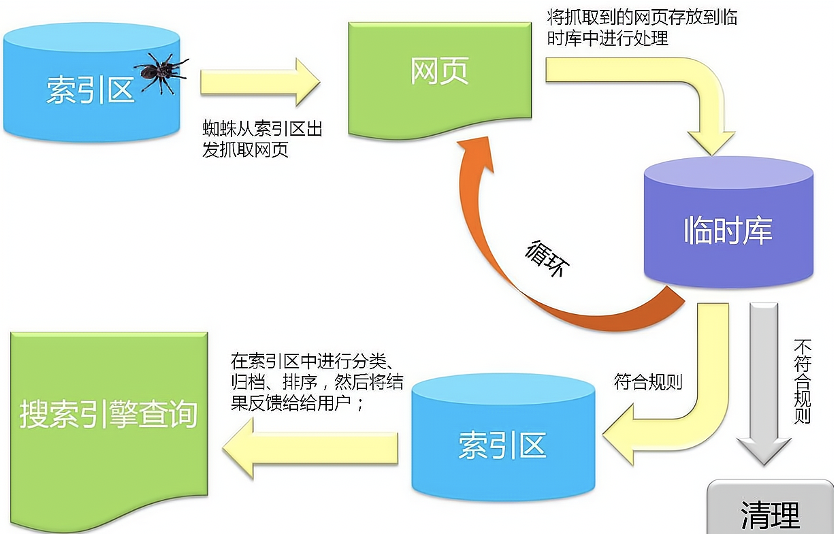
看不懂沒關系,下面用實際的例子帶大家理解,
資料抓取
用戶搜索網站的內容歸根結底是來自于存盤網站的資料庫的,因此,搜索引擎做的第一件事肯定是先把各個網站的資料抓到手,
當然,資料的抓取不可能全部交給人工負責,更多的是讓機器(程式)自動抓取,通常,我們把負責資料抓取的工具人叫做 spider ,即網頁蜘蛛,
每個搜索引擎都有自己的蜘蛛,各家的蜘蛛行為也不同,但基本原理是類似的,
整個互聯網就是一張大蜘蛛網,網頁中又嵌套著網頁,網頁蜘蛛就順著網爬(類似有向圖),從入口開始,通過頁面上的超鏈接關系,不斷發現新的網址并抓取,目標是盡最大可能抓取到更多有價值網頁,
比如有位作者寫了一篇 “吳牙簽” 相關的文章,發到了某個寫作平臺,網頁蜘蛛就能順著這個寫作平臺將這篇文章抓到自己的網頁資料庫中,
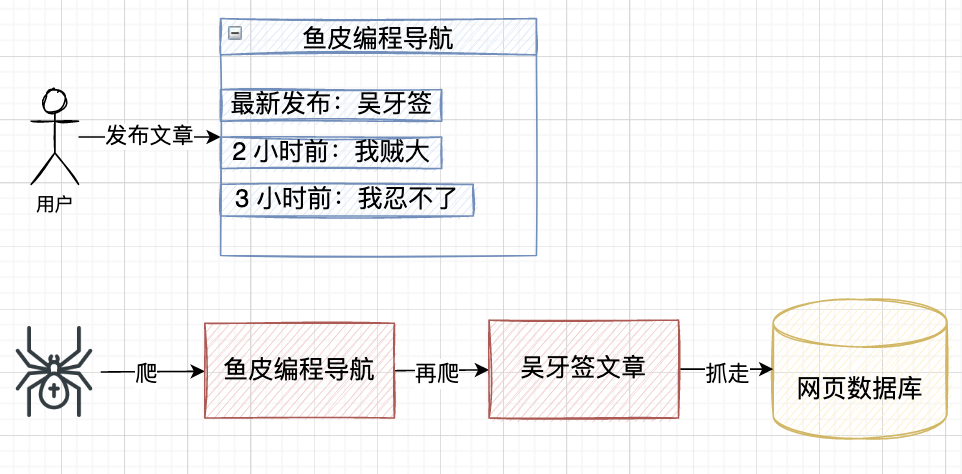
聽起來好像還挺簡單的,但對于億級資料量的搜索引擎,需要有很多額外的考慮,
需關注的問題
首先是 重復和失效 問題,對于類似百度這樣的大型 spider 系統,因為隨時都存在網頁被修改、洗掉、失效或出現新的超鏈接的可能,因此,不是把網站抓取過來就完事了,而是要維護一個網址庫和頁面庫,保證庫內網頁的真實有效、不冗余,
還有其他問題比如:
- 如何保證抓取網站的質量?應拒絕垃圾廣告、不良資訊網站,
- 如何保證抓取友好性?應控制蜘蛛抓取的頻率和深度,別蜘蛛太重把整個網搞破了,
- 如何使抓取的覆寫度更大?抓取一些原本抓不到的資料孤島,
當然,問題遠遠不止這些,設計搜索引擎的抓取系統還是很復雜的,協議、演算法、策略、原則、例外處理都要納入考慮,以下是百度官方提供的抓取系統基本框架圖,展示了抓取系統的宏觀作業流程:
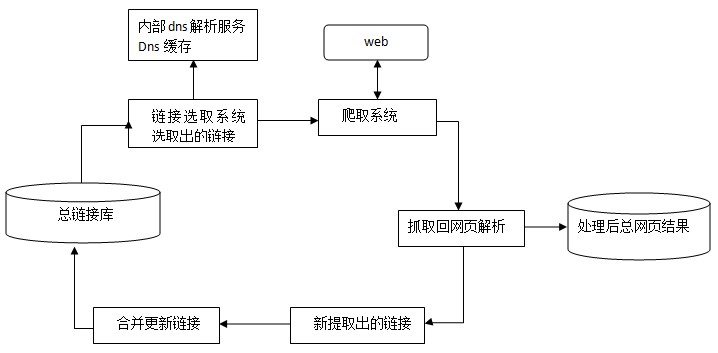
抓取配額
假如我們做了一個網站,肯定希望其他同學能搜到對吧,那么最關鍵的一點就是先讓蜘蛛抓到你、并且多抓你,
通常,資料抓取系統會綜合評估站點來確定抓取次數和頻率,
像百度搜索引擎主要是根據 4 個指標來確定:
- 網站更新頻率:更新越頻繁的網站,蜘蛛抓取頻率越高
- 網站更新質量:內容質量越高的網站,蜘蛛抓取的越多
- 連通度:蜘蛛要能順利抵達該網站,且能正常訪問
- 站點評價:運用演算法對站點進行一個打分,也會影響收錄度
資料處理
在蜘蛛抓取到網頁,并存入網頁資料庫后,并不能把這一大坨網頁資料直接拿來用,
比如我要搜索 “老吳牙簽”,網頁資料庫中可能存盤了數以億計個網站,而且網站中又有那么多牙簽,我怎么知道哪根是老吳的?

雖然慢慢搜肯定能搜出結果,但別忘了用戶可等不起!現在大家對網站的要求很高,幾秒鐘沒搜出來大家可能就會懷疑網路了,因此搜索引擎必須要面臨的挑戰是:如何提高搜索網頁的效率?最好是在毫秒級完成,
為了實作這點,搜索引擎首先會對亂七八糟的網頁資料進行 頁面分析 ,將原始頁面的不同部分進行識別并標記,比如幾個影響搜索的關鍵欄位:網頁的 title(標題)、keywords(關鍵詞)、description(摘要)等,
<html>
<title>老吳賣牙簽</title>
<meta name="keywords" content="娛樂,生活,很大">
<meta name="description" content="老吳賣牙簽">
</html>
提取出這些資訊后,僅通過傳統的關系型資料庫和順序搜索演算法是無法滿足毫秒級查詢的,那不妨換個思路,既然用戶都是根據關鍵詞搜索,那如果事先知道這些關鍵詞存在于哪些頁面中,不就能直接找到了么?即對內容進行 分詞 ,建立 倒排索引 ,
分詞就是把一句話拆分成多個單詞,英文分詞比較簡單,就根據空格來就行,但中文分詞就麻煩了,傳統分詞方法是建立一個詞典,然后線性匹配,但這種方法成本大、且精度不高,現在基本都是 NLP(自然語言處理)、AI 分詞了,包括了切詞、同義詞轉換、同義詞替換等等,
以對頁面標題分詞為例,比如有兩個網頁,第一個網頁的標題是 “老吳賣牙簽”,其實會被分詞為 “老吳”、“賣”、“牙簽”,第二個網頁的標題是 “老吳牙簽很大”,會被分詞為 “老吳”、“牙簽”、“很大”,
分詞后,要根據分詞結果建立 倒排索引 ,
如果說 正向索引 就像書的目錄,幫助我們根據頁碼找到對應章節;那倒排索引則像是打小抄,事先記錄好題目答案所在的頁碼,再根據頁碼快速找到題目答案,
對上面的兩個網頁建立正向索引:
| 網頁 id | 標題 | 內容 |
|---|---|---|
| 1 | 老吳賣牙簽 | xxx |
| 2 | 老吳牙簽很大 | xxx |
建立倒排索引:
| 索引 id | 索引文本 | 存在于網頁 id |
|---|---|---|
| 1 | 老吳 | 1, 2 |
| 2 | 賣 | 1 |
| 3 | 牙簽 | 1, 2 |
| 4 | 很大 | 2 |
建立并存盤倒排索引后,如果用戶搜索關鍵詞 “很大”,只需要從倒排索引表中找到索引文本等于 “很大” 的那一行,取出包含該詞的網頁 id,就可以再根據網頁 id 去正向索引中找到網頁全部資訊了,
資料檢索
光有倒排索引還不能支持用戶快速搜索,在最后的資料檢索環節也有大學問,
比如為什么搜索 “老吳不是牙簽”,卻能搜出 “吳牙簽” 呢?
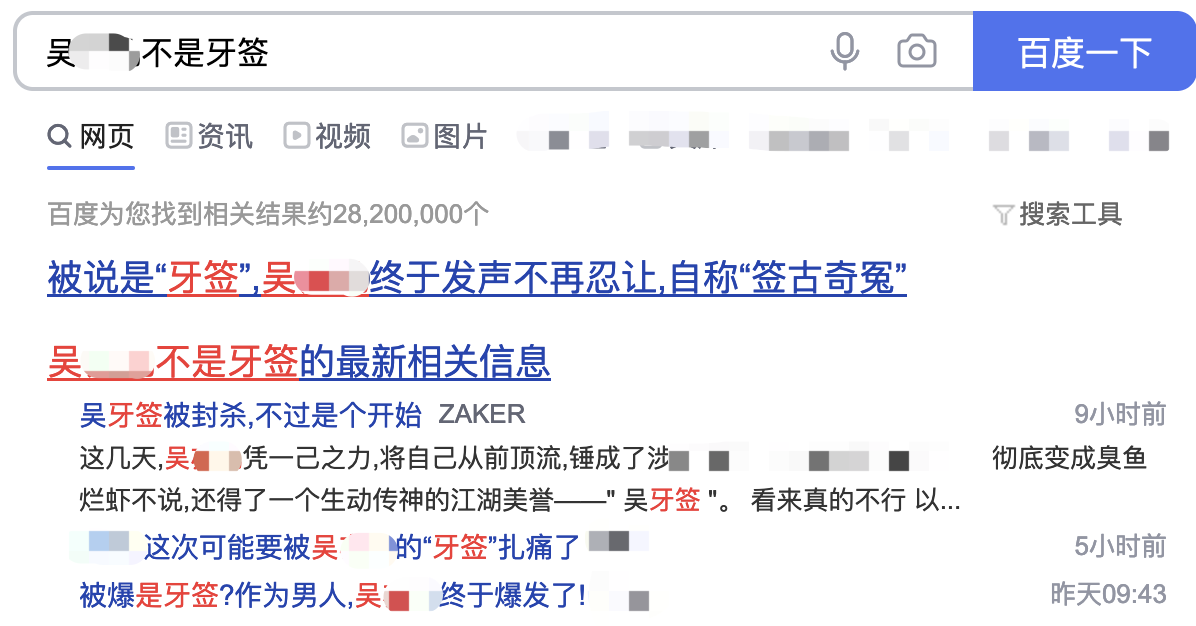
明明前者沒有包含后者對吧,我們常用的 like、正則之類的字串匹配演算法是查詢不到結果的,
下面講講搜索引擎的做法,
先放一張幾年前由百度搜索官方提供的資料檢索流程圖,大致思路是沒問題的,但有些步驟的細節可能早已天差地別,
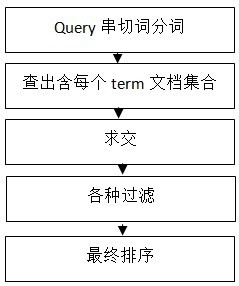
1. 分詞
先像建立倒排索引一樣,對用戶輸入的查詢文本進行分詞,比如搜索 “老吳不是牙簽”,可能的分詞為:“老吳”、“不是”、“牙簽”,
2. 查詢倒排索引
分別對這 3 個關鍵詞,從事先建立好的倒排索引中查出包含網頁的集合:
| 關鍵詞 | 包含該關鍵詞的網頁 |
|---|---|
| 老吳 | 網頁 1、網頁 2 |
| 不是 | 網頁 3 |
| 牙簽 | 網頁 1、網頁 2 |
然后將上述查詢出的網頁取交集(及所有關鍵詞都必須包含該網頁,查詢要求更嚴格)或并集(包含任一關鍵詞即可),作為候選集合,
此處為了得到更多的結果,取并集作為候選集合,結果為:網頁 1、網頁 2、網頁 3,
3. 相關性評價
其實就是給候選集合中的網頁打分,根據上一步的索引查詢結果,來計算用戶的搜索和網頁實際內容到底有多像,
一種很常見的打分演算法是 TF-IDF ,是搜索引擎技術 Elasticsearch 和 Lucene 最主流的打分機制,在 Elasticsearch 中,將該打分演算法結合向量空間模型、協調因子、詞語權重提升等,組成了 實用評分函式,提高搜索的有效性,
TF 是 詞頻 ,就是關鍵詞在網頁中出現的頻度是多少,頻度越高,權重越高,出現 5 次 “牙簽” 關鍵詞的網頁在該詞的權重顯然比只出現 1 次要高,
公式如下:
// 該詞在檔案中出現次數的平方根
tf(t in d) = √frequency
IDF 是 逆向檔案頻率 ,即關鍵詞在集合所有網頁中出現的頻率是多少,物以稀為貴,越冷門的詞,權重反而越高,
上面的例子中顯然 “不是” 這個詞最稀有,所以 “網頁 3” 在這個詞的分數會更高,
公式如下:
// 索引中檔案數量除以所有包含該詞的檔案數,然后求其對數
idf(t) = 1 + log ( numDocs / (docFreq + 1))
此外,還有一個因素是 norm(欄位長度歸一值),假設同一個網頁的標題和內容都包含了 “牙簽”,而標題很短,內容很長,那么在標題中出現 “牙簽” 會有更高的權重,
// 欄位中詞數平方根的倒數
norm(d) = 1 / √numTerms
用戶搜索文本中的 每一個 關鍵詞都要結合這些因素進行打分,最后再結合每個詞的權重將分數進行累加,計算出每個候選網頁的最終得分,
最終公式如下:

有興趣的朋友可以閱讀《Elasticsearch:權威指南》的相關度評分章節,
地址:https://www.elastic.co/guide/cn/elasticsearch/guide/current/scoring-theory.html
在上面的例子中,計算分數后,得到的集合如下:
| 網頁 | 標題 | 分數 |
|---|---|---|
| 網頁 1 | 老吳賣牙簽 | 0.9 |
| 網頁 2 | 老吳牙簽很大 | 0.8 |
| 網頁 3 | 不是吧 | 0.7 |
網頁 1 比網頁 2 雖然都匹配到了兩個關鍵詞,但前者更短,所以分數略高一籌,
4. 過濾
上面的步驟只是計算了候選網頁的得分,但并不是這些網頁都能被搜出來,還要經過各種過濾,比如過濾掉死鏈(失效網站)、重復資料、各種 “你懂的” 網站等,

5. 排序
經過上面的步驟,我們最后得到了 3 個網頁,但到底該把哪個網頁放到第一位呢?
回到開頭的問題:為什么搜索牙簽時,最先搜出來的不是傳統牙簽而是老吳呢?
這個問題取決于 最終排序 ,現在一般都使用機器學習演算法,結合一些資訊,比如上面提到的相關度、網站的質量、熱度、時效性等等,將最能滿足用戶需求的結果排序在最前,
而老吳是近期的爆款內容,在熱度、時效性、搜索相關度上都很有優勢,而且不排除有人工或推廣來動態操作權重的可能,
相信講到這里,大家也都能理解為什么搜索牙簽時, “吳牙簽” 被頂到首頁了吧~

搜索引擎優化
那假如說你做了一個網站,肯定希望不僅其他用戶能搜到,而且是要在第一條對吧,
要做到這點,首先要讓蜘蛛抓到你的網頁,還要重點研究搜索結果的排序機制,這些內容結合起來,就是我們常說的 SEO(搜索引擎優化),
這一塊學問很大,我自己的編程導航網站目前也做到了各搜索引擎的 排名第一 ,送給大家一些 SEO 視頻教程吧,在我的博客回復 seo 即可,
我的博客
后面我會再結合實際具體講講我做 SEO 的小技巧,
以上就是本期分享,我是魚皮,歡迎閱讀 我從 0 自學進入騰訊的編程學習、求職、考證、寫書經歷,不再迷茫!
我學計算機的四年,共勉!
點贊 還是要求一下的,祝大家都能心想事成、發大財、行大運,

轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/291088.html
標籤:其他
上一篇:兩萬字長文-設計模式總結