文章目錄
- 一、演算法效率
- 💦 如何衡量一個演算法的好壞
- 💦 演算法的復雜度
- 二、時間復雜度
- 💦 什么是時間復雜度
- 💦 大O漸進表示法 (估算)
- 💦 常見的時間復雜度計算舉例
- 💦 常見的復雜度對比
- 💦 根據對時間復雜度的要求撰寫代碼
- 三、空間復雜度
- 💦什么是空間復雜度
- 💦 常見的空間復雜度計算舉例
一、演算法效率
💦 如何衡量一個演算法的好壞
🎗遞回代碼 ———— 斐波那契數列的代碼量十分簡潔,所以這個演算法是很優的?但其實使用遞回是非常戳的,你會發現遞回去計算第40位斐波那契數時都要跑半天,究其原因是內部產生大量重復的計算,那該如何去衡量演算法的優劣呢?
#define _CRT_SECURE_NO_WARNINGS
#include<stdio.h>
int Fib(int n)
{
if(n > 2)
return Fib(n - 1) + Fib(n - 2);
else
return 1;
}
int main()
{
int n = 0;
scanf("%d", &n);
int ret = Fib(n);
printf("第%d個斐波那契數是%d\n", n, ret);
return 0;
}
💦 演算法的復雜度
演算法在撰寫成可執行程式后,運行時需要耗費時間資源和空間(記憶體)資源,因此衡量一個演算法的好壞,一般是從時間和空間兩個維度來衡量的,即時間復雜度和空間復雜度,
時間復雜度主要衡量一個演算法的運行快慢,而空間復雜度主要衡量一個演算法運行所需要的額外空間,在計算機發展的早期,計算機的存盤容量很小,
所以對空間復雜度比較在乎,但是經過計算機行業的迅速發展,計算機的存盤容量已經達到了很高的程度,所以我們如今已經不需要再特別關注演算法的空間復雜度,
二、時間復雜度
💦 什么是時間復雜度
在計算機科學中,演算法的時間復雜度是一個函式,它描述了該演算法的運行時間,一個演算法執行所耗費的時間,從理論上說,是不能算出來的,只有你把你的程式放在機器上跑起來,才能知道,但是我們需要每個演算法都上機測驗嗎?是可以上機測驗,但是這很麻煩,所以才有了時間復雜度這個分析方式,
一個演算法所花費的時間與其中陳述句的執行次數成正比,所以演算法中的基本操作的執行次數,為演算法的時間復雜度,
即找到某潭訓本陳述句與問題規模N之間的數學運算式,就是算出了該演算法的時間復雜度,
🎗 計算fun1中++count陳述句總共執行了多少次
void Func1(int N)
{
int count = 0;
for (int i = 0; i < N ; ++ i)
{
for (int j = 0; j < N ; ++ j)
{
++count;
}
}
for (int k = 0; k < 2 * N ; ++ k)
{
++count;
}
int M = 10;
while (M--)
{
++count;
}
printf("%d\n", count);
}
📝 分析:
從上述代碼中可以看出Func1的時間復雜度函式為F(N) = N * N + 2 * N + 10
? N = 10????F(N) = 130
? N = 100??? F(N) = 10210
? N = 1000???F(N) = 1002010
💨 從上述就可以看出N越大,對結果的影響就越小,實際中我們計算時間復雜度時,我們其實并不一定要計算精確的執行次數,而只需要大概執行次數,那么這里我們使用大O的漸進表示法 (估算),
💦 大O漸進表示法 (估算)
大O符號 (Big O notation):用于描述函式漸近行為的數學符號
🎗推導大O階的方法:
1?? 用常數1取代運行時間中的所有加法常數
2?? 在修改后的運行次數函式中,只保留最高項
3?? 如果最高階項存在且系數不是1,則去除與這個項相乘的系數,得到的結果就是大O階
💨 對于上面的Func1函式,使用大O的漸近表示法后,時間復雜度為O(N^2)
? N = 10????F(N) = 100
? N = 100??? F(N) = 10000
? N = 1000???F(N) = 1000000
🎗另外有些演算法的時間復雜度存在最好,平均和最壞情況:
例如:在一個長度為N的陣列中查找一個資料X,最好的情況1次就找到;平均的情況N/2就找到;最壞的情況N次才找到
1?? 最壞情況:任意輸入規模的最大運行次數(上界)
2?? 平均情況:任意輸入規模的期望運行次數
3?? 最好情況:任意輸入規模的最小運行次數(下界)
💨 在實際中一般情況關注的是演算法的最壞運行情況,所以陣列中搜索資料時間復雜度為O(N)
💦 常見的時間復雜度計算舉例
🎗實體1:
void Func2(int N)
{
int count = 0;
for (int k = 0; k < 2 * N ; ++ k)
{
++count;
}
int M = 10;
while (M--)
{
++count;
}
printf("%d\n", count);
}
📝 分析:
Func2的時間復雜度函式為F(N) = (2N + 10)
使用大O漸近表示法:保留影響最大的一項、去掉系數則為O(N)
🎗實體2:
void Func3(int N, int M)
{
int count = 0;
for (int k = 0; k < M; ++ k)
{
++count;
}
for (int k = 0; k < N ; ++ k)
{
++count;
}
printf("%d\n", count);
}
📝 分析:
Func3的時間復雜度函式為F(N) = (M + N)
使用大O漸近表示法:不一定只有一個未知數,所以這里可以寫O(M + N)
也可以寫成如下:
? O(max(M, N)):取M和N的較大值
? O(M):如果能說明M遠大于N
? O(N):如果能說明N遠大于M
? O(N)/O(M):如果能說明M和N差不多大
🎗實體3:
void Func4(int N)
{
int count = 0;
for (int k = 0; k < 100; ++k)
{
++count;
}
printf("%d\n", count);
}
📝 分析:
Func4的時間復雜度函式為F(N) = (100)
使用大O漸近表示法:使用1代表常數,所以O(1)
🎗實體4:
void BubbleSort(int* a, int n)
{
assert(a);
for (size_t end = n; end > 0; --end)
{
int exchange = 0;
for (size_t i = 1; i < end; ++i)
{
if (a[i-1] > a[i])
{
Swap(&a[i-1], &a[i]);
exchange = 1;
}
}
if (exchange == 0)
break;
}
}
📝 分析:
這是冒泡排序的一個優化版本,在一趟排序的程序中如果沒有交換資料的話,它就會跳出回圈,所以它是有最好、平均、最壞的情況的
BubbleSort的時間復雜度函式為F(N) = (n + (n - 1) + (n - 2) … + 2 + 1)
所以你會發現這是一個等引數列,利用公式整合得:F(N) = (n + 1)* n / 2 -> F(N) = n^2 / 2 + n / 2
使用大O漸近表示法: (最壞情況):O(N^2) -> 這是我們要考慮的情況,顯然如果是最壞的情況,那我們就優化了個寂寞
??????????(平均情況):O(N^2) -> (n^2 / 2 + n / 2)/2
??????????(最好情況):O(N)
🎗實體4:
int BinarySearch(int* a, int n, int x)
{
assert(a);
int begin = 0;
int end = n-1;
while (begin < end)
{
int mid = begin + ((end-begin)>>1);
if (a[mid] < x)
begin = mid+1;
else if (a[mid] > x)
end = mid;
else
return mid;
}
return -1;
}
📝 分析:
BinarySearch依然存在最好、平均、最壞的情況:
BinarySearch的時間復雜度函式為F(N) = N / 2 / 2 / 2 … /2 = 1
使用大O漸近表示法:O(log?N)或O(logN) -> 因為底數不好打出來,有時候一般也這樣寫
1、N / 2
2、N / 2 / 2 -> N / 4:N / 2^2
3、N / 2 / 2 / 2 -> N / 8:N / 2^3
x、N / 2^x = 1 -> N = 2^x -> log?N = x
🎗實體5:
long long Fac(size_t N)
{
if(1 == N)
return 1;
return Fac(N-1)*N;
}
📝 分析:
Fac的時間復雜度為F(N) = (N)
使用大O漸近表示法:O(N)
🎗實體6:
long long Fib(size_t N)
{
if(N < 3)
return 1;
return Fib(N-1) + Fib(N-2);
}
📝 分析:
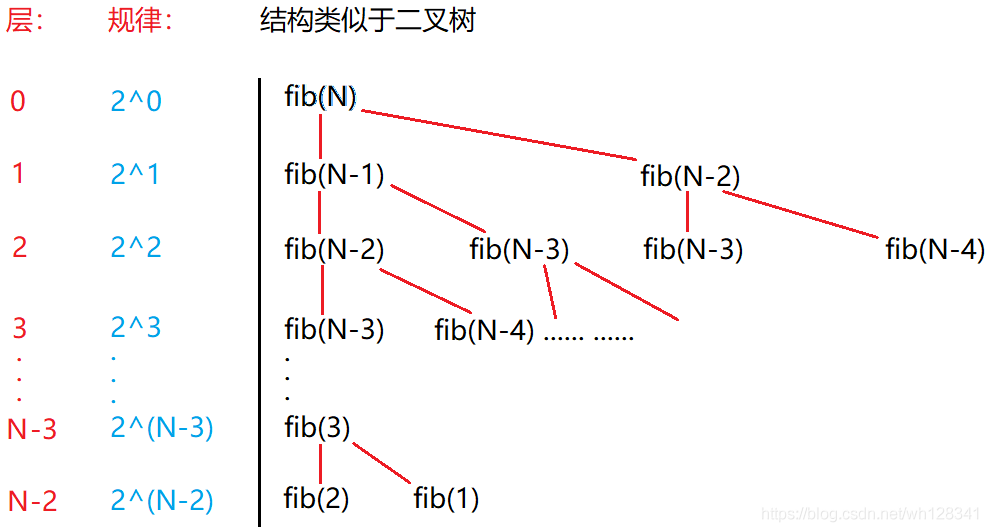
2^0 + 2^1 + 2^2 + 2^3 … +2^(N-3) + 2^(N-2)
使用大O漸近表示法:O(2^N)
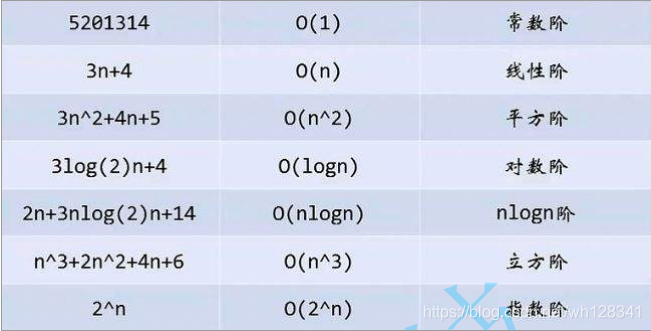
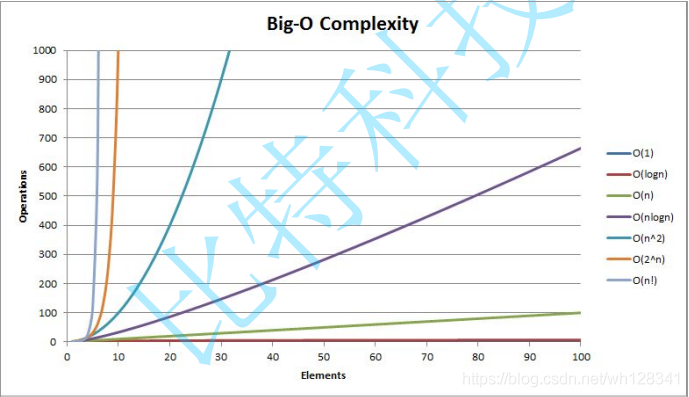
💦 常見的復雜度對比
💦 根據對時間復雜度的要求撰寫代碼
🎗實體1:消失的數字
📝 題述:陣列arr包含從0到n的所有整數,但其中缺了一個,撰寫代碼找出那個缺失的整數,時間復雜度限制為O(N)
💨 輸入描述:輸入0到n的整數,并少輸一個數
💨 輸出描述:輸出那個少輸的數
🔑 核心思想:
方法一:先排序,再依次判斷第1個數和之后的數相加是否等于第3個數,若不等,則它們的和就是缺失的數————冒泡排序時間復雜度O(N2),快速排序時間復雜度O(N*log?N)
方法二:求和,如果有n個數,則0+1+2…+n,最后整體再減去陣列中的值的累加就是缺失的數————時間復雜度O(N)
方法三:異或,使用0跟0—n之間的數異或,再跟數值中的值異或,異或的結果就是缺失的數
🎗 方法2
#define _CRT_SECURE_NO_WARNINGS
#include<stdio.h>
int FindNum1(int arr[], int n)
{
int i = 0;
//把n+1個數加起來,放在sum里
int sum = 0;
for (i = 0; i < n + 1; i++)
{
sum += i;
}
//再減去陣列里的數,結果就是缺失的數
for (i = 0; i < n; i++)
{
sum -= arr[i];
}
return sum;
}
int main()
{
int arr[20] = { 0 };
//規定輸入有n個數
int n = 3;
int i = 0;
for (i = 0; i < n; i++)
{
scanf("%d", &arr[i]);
}
int ret = FindNum1(arr, n);
printf("%d\n", ret);
return 0;
}
🎗 方法3
#define _CRT_SECURE_NO_WARNINGS
#include<stdio.h>
int FindNum2(int arr[], int n)
{
int i = 0;
//把n+1個數異或后,放在sum里
int sum = 0;
for (i = 0; i < n + 1; i++)
{
sum ^= i;
}
//再和陣列里的異或,剩下的就是缺失的數
for (i = 0; i < n; i++)
{
sum ^= arr[i];
}
return sum;
}
int main()
{
int arr[20] = { 0 };
//n個數
int n = 3;
int i = 0;
for (i = 0; i < n; i++)
{
scanf("%d", &arr[i]);
}
int ret = FindNum2(arr, n);
printf("%d\n", ret);
return 0;
}
🎗實體2:旋轉字串
📝 題述:給定一個陣列,將陣列中的元素向右移動 k 個位置,其中 k 是非負數,要求時間復雜度O(N)
💨 輸入描述:輸入n個字符,輸入要右移的k個位置
💨 輸出描述:輸出右移后的陣列
🔑 核心思想:
方法一:這是1個字符的旋轉,拷貝一份最右值,陣列中的值都向右挪劫1次,再把拷貝的內容放在開頭;在外面套一層回圈就可以旋轉k個字符了————時間復雜度O(N2)
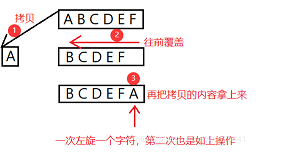
方法二:空間換時間————時間復雜度O(N)
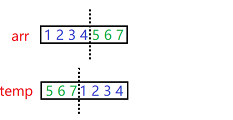
方法三:三步翻轉法————時間復雜度O(N)

🎗 方法2
#define _CRT_SECURE_NO_WARNINGS
#include<stdio.h>
#include<string.h>
#include<assert.h>
char* Rotate1(const char* arr, int len, int k, char* temp)
{
assert(arr && temp);
//拷貝一份新空間的首地址用于回傳
char* tem = temp;
//我們當前寫的這個代碼是不適用于旋轉的字符k大于目標陣列的arr,所以如果k大于arr時,我們需要看看k有幾個arr,并把它排除掉
k %= len;
int i = 0;
//先拷貝后半部分的字符
for (i = len - k; i < len; i++)
{
*temp = *(arr + i);
temp++;
}
//再拷貝前半部分的字符
for (i = 0; i < len - k; i++)
{
*temp = *(arr + i);
temp++;
}
return tem;
}
int main()
{
//temp為新的空間
char temp[20] = { 0 };
//arr存盤要旋轉的字串
char arr[20] = { 0 };
gets(arr);
//旋轉k個字符
int k = 0;
scanf("%d", &k);
char* ret = Rotate1(arr, strlen(arr), k, temp);
printf("%s\n", ret);
return 0;
}
🎗 方法3
#define _CRT_SECURE_NO_WARNINGS
#include<stdio.h>
#include<assert.h>
#include<string.h>
void reverse(char* left, char* right)
{
assert(left && right);
while (left < right)
{
char temp = *left;
*left = *right;
*right = temp;
left++;
right--;
}
}
void string_right_rotation(char* str, int k)
{
assert(str);
int len = strlen(str);
//我們當前寫的這個代碼是不適用于旋轉的字符k大于目標陣列的arr,所以如果k大于arr時,我們需要看看k有幾個arr,并把它排除掉
k %= len;
reverse(str, str + (len - k - 1));//第一部分
reverse(str + (len - k), str + len - 1);//第二部分
reverse(str, str + len - 1);//整體
}
int main()
{
//arr存盤要旋轉的字串
char arr[20] = { 0 };
gets(arr);
//旋轉k個字符
int k = 0;
scanf("%d", &k);
string_right_rotation(arr, k);
printf("%s\n", arr);
return 0;
}
三、空間復雜度
💦什么是空間復雜度
空間復雜度也是一個數學運算式,是對一個演算法在運行程序中臨時占用存盤空間大小的量度,
空間復雜度不是程式占用了多少bytes的空間,因為這個也沒太大意義,所以空間復雜度算的是變數的個數,空間復雜度計算規則基本跟時間復雜度類似,也使用大o漸進表示法,
注意:函式運行時所需要的堆疊空間(存盤引數、區域變數、一些暫存器資訊等)在編譯期間已經確定好了,因此空間復雜度主要通過函式在運行時候顯式申請的額外空間來確定,
💦 常見的空間復雜度計算舉例
相對簡單,過一下即可:
🎗實體1:
void BubbleSort(int* a, int n)
{
assert(a);
for (size_t end = n; end > 0; --end)
{
int exchange = 0;
for (size_t i = 1; i < end; ++i)
{
if (a[i-1] > a[i])
{
Swap(&a[i-1], &a[i]);
exchange = 1;
}
}
if (exchange == 0)
break;
}
}
📝 分析:
相比時間復雜度來說:時間是累計的,但空間不是累計的(可以重復利用)
BubbleSort的空間復雜度為F(N) = (3)
使用大O漸近表示法:O(1)
🎗實體2:
long long* Fibonacci(size_t n)
{
if(n==0)
return NULL;
long long * fibArray = (long long *)malloc((n+1) * sizeof(long long));
fibArray[0] = 0;
fibArray[1] = 1;
for (int i = 2; i <= n ; ++i)
{
fibArray[i] = fibArray[i - 1] + fibArray[i - 2];
}
return fibArray;
}
📝 分析:
使用大O漸近表示法:O(N)
🎗實體3:
long long Fac(size_t N)
{
if(N == 1)
return 1;
return Fac(N-1)*N;
}
📝 分析:
使用大O漸近表示法:O(N)
🎗實體1:
long long Fib(size_t N)
{
if(N < 3)
return 1;
return Fib(N-1) + Fib(N-2);
}
📝 分析:
使用大O漸近表示法:O(N)

轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/291237.html
標籤:其他
上一篇:剖析整型在記憶體中的存盤
下一篇:C語言之volatile關鍵字