前面講述完傳輸層,接下來從最常用的HTTP協議開始講應用層的協議
HTTP協議,幾乎是每個人上網用的第一個協議,同時也是很容易被人忽略的協議
比如看新聞的163網站http://www.163.com
http://www.163.com是個URL,叫作統一資源定位符,之所以叫統一,是因為它是有格式的
HTTP稱為協議,www.163.com是一個域名,表示互聯網上的一個位置,有的URL會有更詳細的位置標識,例如http://www.163.com/index.html
正是因為這個東西是統一的,所以當把這樣一個字串輸入到瀏覽?的框里時,瀏覽?才知道如何進行統一處理
一、HTTP請求的準備
瀏覽?會將www.163.com這個域名發送給DNS服務?,讓它決議為IP地址,有關DNS的程序其實非常復雜,DNS服務器將域名決議成為IP地址,那接下來是發送HTTP請求嗎?
不是的,HTTP是基于TCP協議的,當然是要先建立TCP連接,那怎么建立呢?這就需要TCP的三次握手
目前使用的HTTP協議大部分都是1.1,在1.1的協議中,默認是開啟了Keep-Alive的,這樣建立的TCP連接可以在多次請求中復用
TCP的三次握手和四次揮手還是很費時費力的,如果好不容易建立了連接,然后就做了一點兒事情就結束了,有點兒浪費人力和物力
二、HTTP請求的構建
建立了連接以后,瀏覽?就要發送HTTP的請求
請求的格式就像這樣
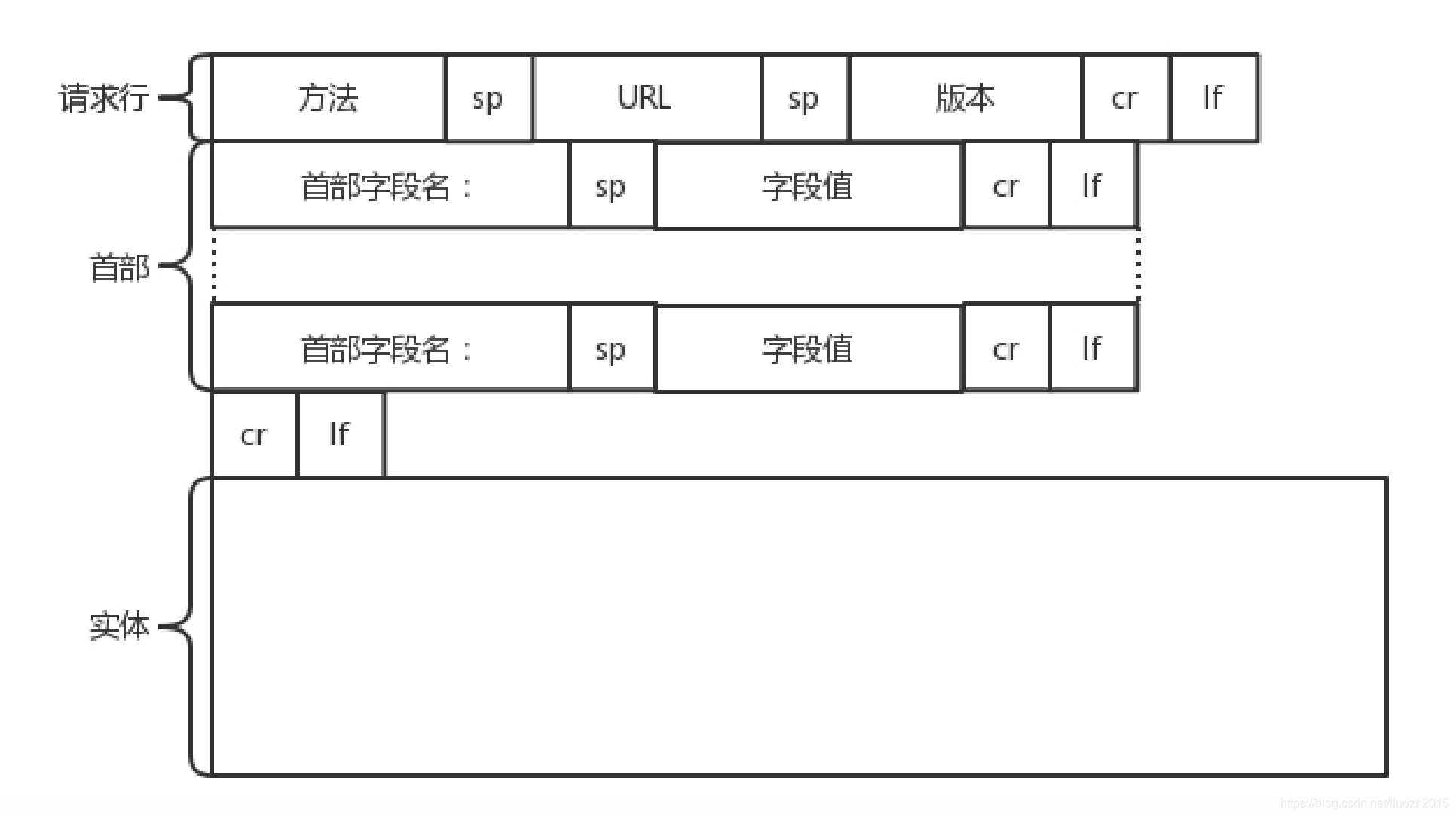
HTTP的報文大概分為三大部分,第一部分是請求行,第二部分是請求的首部,第三部分才是請求的正文物體
2.1 第一部分:請求行
在請求行中,URL就是http://www.163.com,版本為HTTP 1.1,接下來特別說一下幾種型別的方法
2.1.1 GET方法
對于訪問網頁來講,最常用的型別就是GET,GET就是去服務?獲取一些資源
對于訪問網頁來講,要獲取的資源往往是一個頁面,其實也有很多其他的格式,比如說回傳一個JSON字串,到底要回傳什么是由服務?端的實作決定的
例如,在云計算中如果服務?端要提供一個基于HTTP協議的API,獲取所有云主機的串列,這就會使用GET方法得到,回傳的可能是一個JSON字串,字串里面是一個串列,串列里面是云主機的資訊
2.1.2 POST方法
另外一種型別叫做POST,它需要主動告訴服務端一些資訊,而非獲取
要告訴服務端什么呢?一般會放在正文里面,正文可以有各種各樣的格式,常見的格式也是JSON
例如,在云計算中如果服務?端要提供一個基于HTTP協議的創建云主機的API,這就會用到POST方法,這個時候往往需要將要創建多大的云主機?多少CPU多少記憶體?多大硬碟?這些資訊放在JSON字串里面,通過POST的方法告訴服務?端
2.1.3 PUT方法
還有一種型別叫PUT,就是向指定資源位置上傳最新內容
但是,HTTP的服務?往往是不允許上傳檔案的,所以PUT和POST就都變成了要傳給服務?東西的方法
在實際使用程序中,這兩者還會有稍許的區別,POST往往是用來創建一個資源,而PUT往往是用來修改一個資源
例如,云主機已經創建好了,想對這個云主機打一個標簽,說明這個云主機是生產環境的,另外一個云主機是測驗環境的,那怎么修改這個標簽呢?往往就是用PUT方法
2.1.4 DELETE方法
再有一種常見的就是DELETE,顧名思義就是用來洗掉資源的
例如,要洗掉一個云主機,就會呼叫DELETE方法
2.2 第二部分:首部欄位
請求行下面就是首部欄位,首部是key value,通過冒號分隔,這里面往往保存了一些非常重要的欄位
2.2.1 Accept-Charset
Accept-Charset,表示客戶端可以接受的字符集,防止傳過來的是另外的字符集從而導致出現亂碼
2.2.2 Content-Type
Content-Type,指正文的格式,例如,進行POST的請求,如果正文是JSON, 那么應該將這個值設定為JSON
這里需要重點說一下的就是快取,為啥要使用快取呢?那是因為一個非常大的頁面有很多東西
例如,瀏覽一個商品的詳情,里面有這個商品的價格、庫存、展示圖片、使用手冊等等,商品的展示圖片會保持較長時間不變,而庫存會根據用戶購買的情況經常改變,如果圖片非常大,而庫存數非常小,如果每次要更新資料的時候都要重繪整個頁面,對于服務?的壓力就會很大
對于這種高并發場景下的系統,在真正的業務邏輯之前都需要有個接入層,將這些靜態資源的請求攔在最外面
這個架構的圖就像這樣
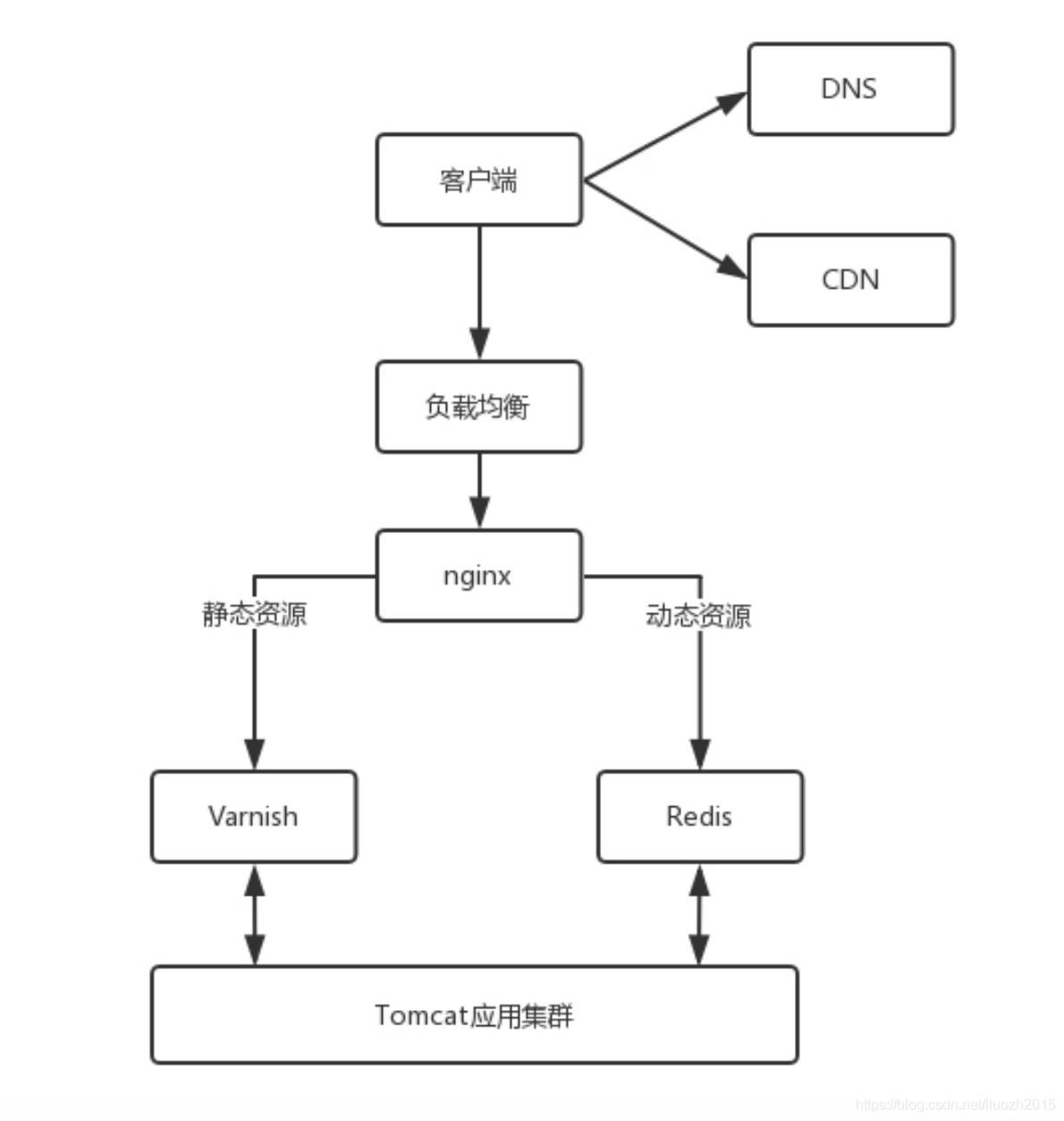
對于靜態資源,有Vanish快取層,當快取過期的時候,才會訪問真正的Tomcat應用集群
2.2.3 Cache-control
在HTTP頭里面,Cache-control是用來控制快取的
當客戶端發送的請求中包含max-age指令時,如果判定快取層中,資源的快取時間數值比指定時間的數值小,那么客戶端可以接受快取的資源,當指定max-age值為0,那么快取層通常需要將請求轉發給應用集群
2.2.4 If-Modified-Since
另外,If-Modified-Since也是一個關于快取的
如果服務?的資源在某個時間之后更新了,那么客戶端就應該下載最新的資源,如果沒有更新,服務端會回傳304 Not Modified的回應,那客戶端就不用下載,從而節省帶寬
到此為止,僅僅是拼湊起HTTP請求的報文格式,接下來瀏覽?會把它交給下一層傳輸層,怎么交給傳輸層呢?其實也無非是用Socket這些東西,只不過用的瀏覽?里,這些程式不需要自己寫,別人已經實作好了
三、HTTP請求的發送
3.1 HTTP層通過stream二進制流發送給TCP層
HTTP協議是基于TCP協議的,所以它使用面向連接的方式發送請求,通過stream二進制流的 方式傳給對方
3.2 TCP層封裝地址資訊交給IP層
當然,到了TCP層,它會把二進制流變成一個的報文段發送給服務?
在發送給每個報文段的時候,都需要對方有一個回應ACK,來保證報文可靠地到達了對方,如果沒有回應,那么TCP這一層會進行重新傳輸直到可以到達,同一個包有可能被傳了好多次,但是HTTP這一層不需要知道這一點,因為是TCP這一層在埋頭苦干
TCP層發送每一個報文的時候,都需要加上自己的地址(即源地址)和它想要去的地方(即目標地址),將這兩個資訊放到IP頭里面,交給IP層進行傳輸
3.3 IP層封裝MAC資訊發給MAC地址或網關
IP層需要查看目標地址和自己是否是在同一個局域網
如果是,就發送ARP協議來請求這個目標地址對應的MAC地址,然后將源MAC和目標MAC放入MAC頭,發送出去即可
如果不在同一個局域網,就需要發送到網關,還需要發送ARP協議來獲取網關的MAC地址,然后將源MAC和網關MAC放入MAC頭,發送出去
網關收到包發現MAC符合,取出目標IP地址,根據路由協議找到下一跳的路由?,獲取下一
跳路由?的MAC地址,將包發給下一跳路由?
這樣路由?一跳一跳終于到達目標的局域網,這時最后一跳的路由?能夠發現,目標地址就在自己的某一個出口的局域網上,于是,在這個局域網上發送ARP,獲得這個目標地址的MAC地址,將包發出去
3.4 目標的機?的處理
- 發現MAC地址符合,就將包收起來
- 發現IP地址符合,根據IP頭中協議項知道自己上一層是TCP協議
- 決議TCP的頭中的序列號,需要看一看這個序列包是不是想要的
- 如果序列包是需要的就放入快取中然后回傳一個ACK,如果不是就丟棄
3.5 服務端根據請求資訊處理
TCP頭里面還有埠號,HTTP的服務?正在監聽這個埠號,于是,目標機?自然知道是HTTP服務?這個行程想要這個包,于是將包發給HTTP服務?,HTTP服務?的行程看到原來這個請求是要訪問一個網頁,于是就把這個網頁發給客戶端
四、HTTP回傳的構建
HTTP的回傳報文也是有一定格式的,這也是基于HTTP 1.1
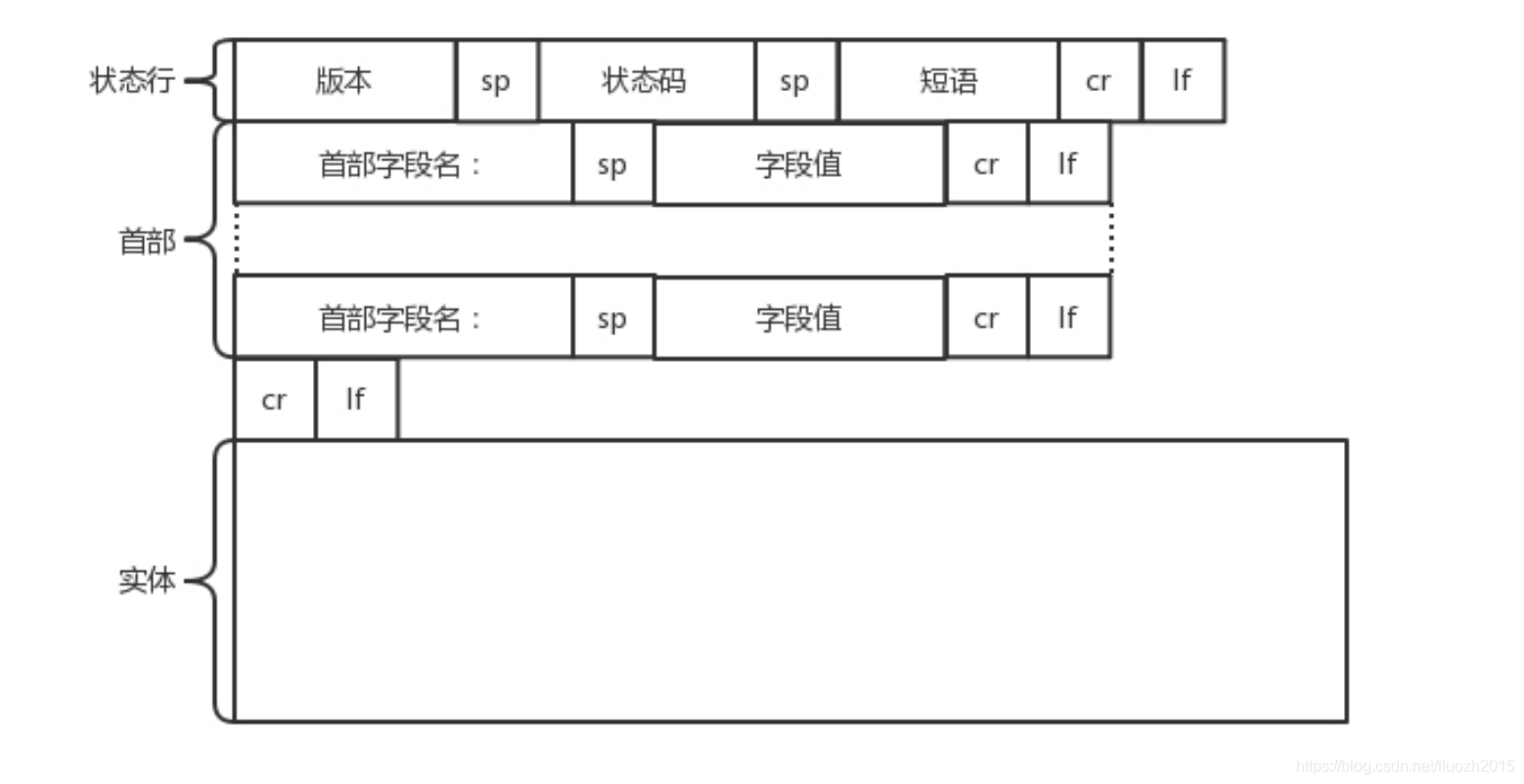
4.1 狀態行
- 狀態碼
反應HTTP請求的結果,200意味著大吉大利,而404是服務端無法回應這個請求
- 短語
大概說一下原因
4.2 首部
接下來是回傳首部的key value
4.2.1 Retry-After
Retry-After,表示告訴客戶端應該在多長時間以后再次嘗試一下,503錯誤是說服務暫時不再和這個值配合使用
4.2.2 Content-Type
在回傳的頭部里面也會有Content-Type,表示回傳的是HTML,還是JSON
4.3 回傳HTTP報文傳輸
4.3.1 TCP分小段并且保證可靠到達
構造好了回傳的HTTP報文,接下來就是把這個報文發送出去,還是交給Socket去發送,還是 交給TCP層,讓TCP層將回傳的HTML,也分成一個個小的段,并且保證每個段都可靠到達
4.3.2 IP層封裝MAC資訊并路由到對應MAC層
這些段加上TCP頭后會交給IP層,然后把剛才的發送程序反向走一遍,雖然兩次不一定走相同 的路徑,但是邏輯程序是一樣的,一直到達客戶端
4.3.3 客戶端發送給對應埠的行程處理
客戶端發現MAC地址符合、IP地址符合,于是就會交給TCP層,根據序列號看是不是自己要的報文段,如果是,則會根據TCP頭中的埠號發給相應的行程,這個行程就是瀏覽?,瀏覽?作為客戶端也在監聽某個埠
4.3.4 瀏覽器根據HTML渲染出網頁
當瀏覽?拿到了HTTP的報文,發現回傳200則一切正常,于是就從正文中將HTML拿出來,HTML是一個標準的網頁格式,瀏覽?只要根據這個格式就可以展示出一個絢麗多彩的網頁
這就是一個正常的HTTP請求和回傳的完整程序
五、HTTP 2.0
HTTP協議在不斷地進化程序中,在HTTP1.1基礎上便有了HTTP 2.0
5.1 HTTP 1.0存在的問題
HTTP 1.1在應用層以純文本的形式進行通信,每次通信都要帶完整的HTTP的頭,而且不考慮 pipeline模式的話,每次的程序總是像上面描述的那樣一去一回,這樣在實時性、并發性上都 存在問題
5.2 HTTP 2.0相對于1.0的優化
5.2.1 HTTP 2.0在兩端針對頭資訊建立索引表
為了解決這些問題,HTTP 2.0對HTTP的頭進行一定的壓縮,將原來每次都要攜帶的大量key value在兩端建立一個索引表,對相同的頭只發送索引表中的索引
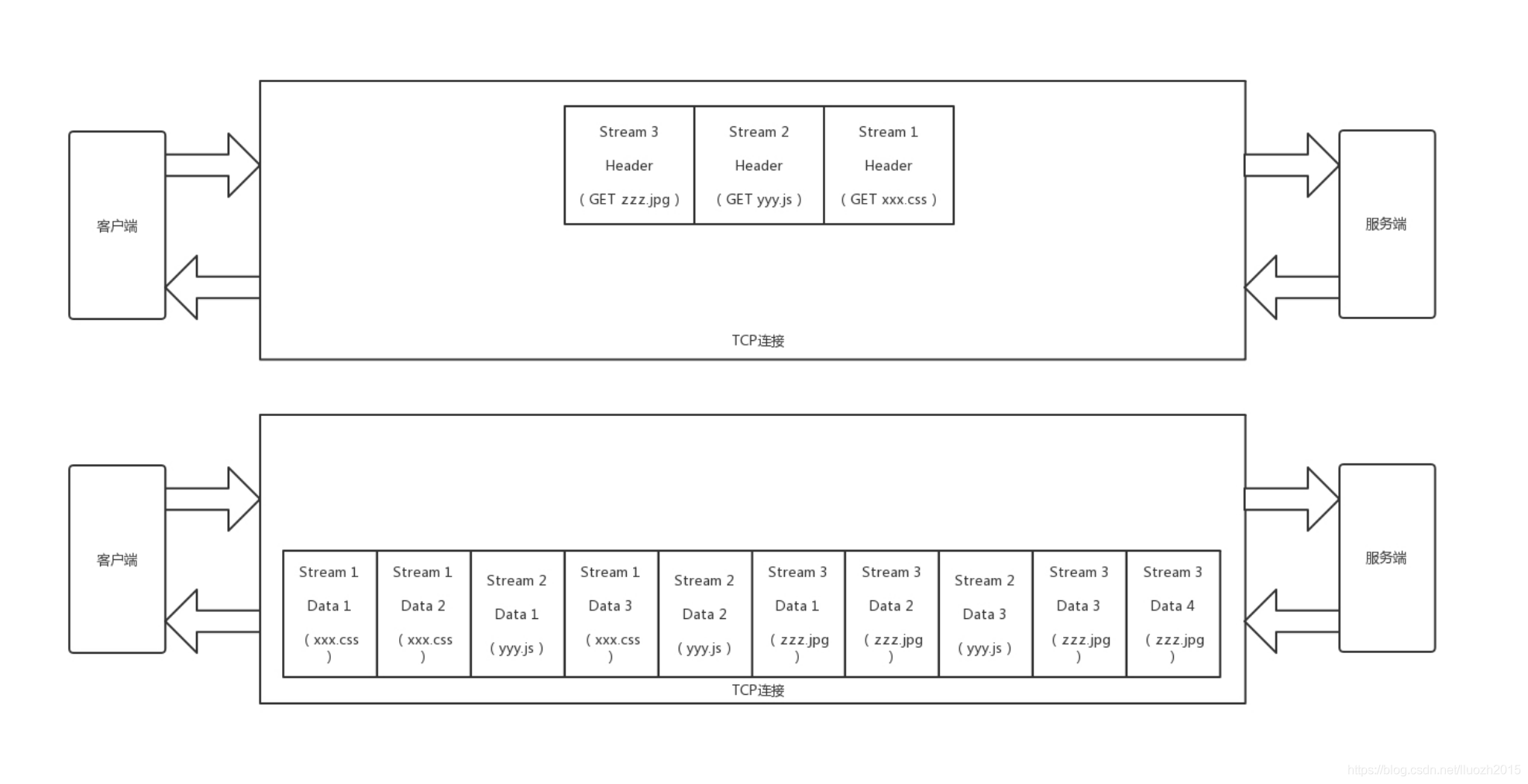
5.2.2 HTTP 2.0將一個連接切分成多個流
另外,HTTP 2.0協議將一個TCP的連接中,切分成多個流,每個流都有自己的ID,而且流可以是客戶端發往服務端,也可以是服務端發往客戶端,它其實只是一個虛擬的通道,并且流是有優先級的
5.2.3 HTTP 2.0將傳輸資訊分割成更小的訊息和幀
HTTP 2.0還將所有的傳輸資訊分割為更小的訊息和幀,并對它們采用二進制格式編碼,常見的幀有Header幀,用于傳輸Header內容,并且會開啟一個新的流,再就是Data幀,用來傳輸正文物體,多個Data幀屬于同一個流
5.3 HTTP 2.0資料流傳輸的方式
通過這兩種機制,HTTP 2.0的客戶端可以將多個請求分到不同的流中,然后將請求內容拆成幀,進行二進制傳輸,這些幀可以打散亂序發送, 然后根據每個幀首部的流識別符號重新組裝,并且可以根據優先級,決定優先處理哪個流的資料
5.4 栗子
來舉一個例子:
假設一個頁面要發送三個獨立的請求,一個獲取css,一個獲取js,一個獲取圖片jpg,如果使用HTTP 1.1就是串行的,但是如果使用HTTP 2.0就可以在一個連接里,客戶端和服務端都可以同時發送多個請求或回應,而且不用按照順序一對一對應
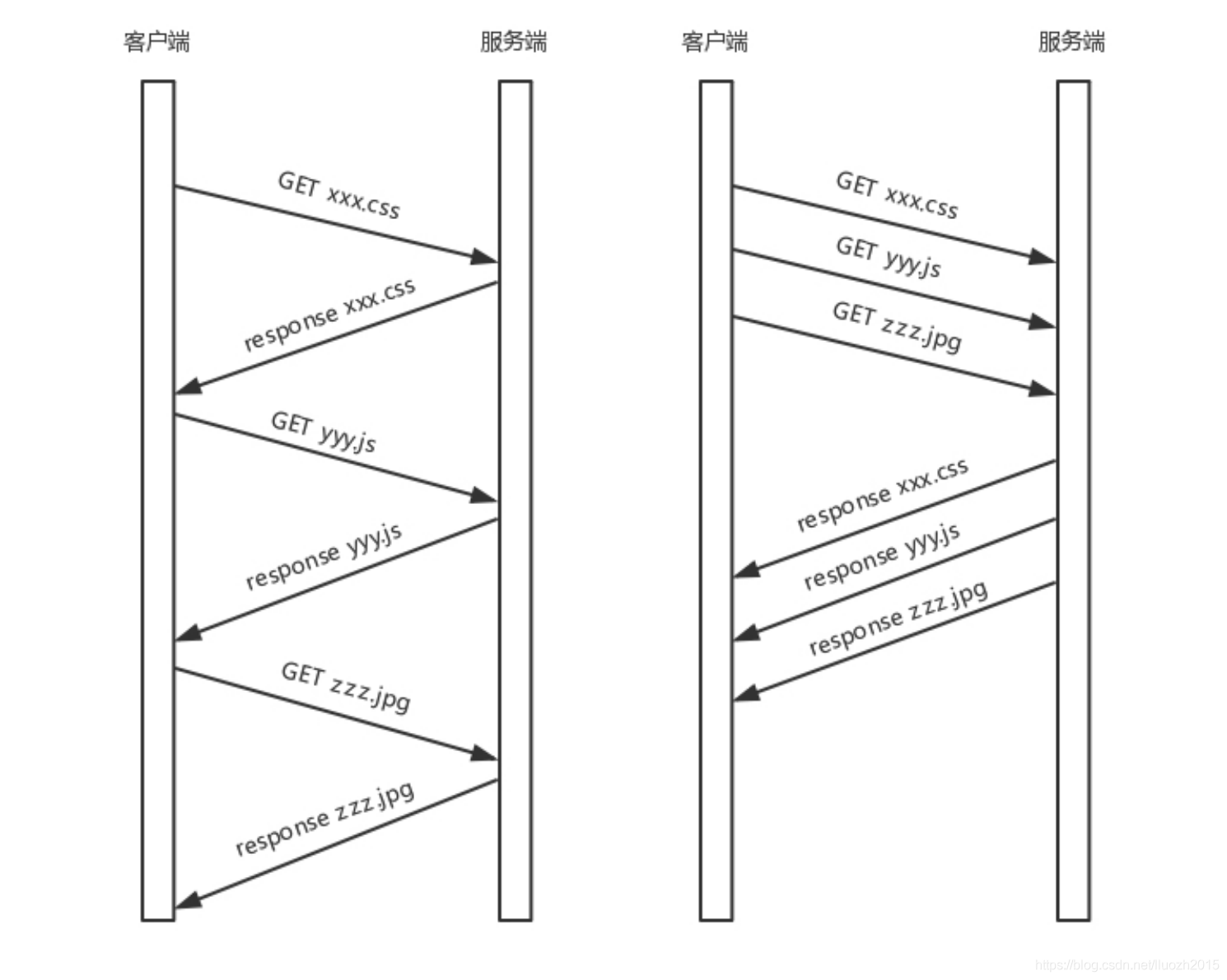
HTTP 2.0其實是將三個請求變成三個流,將資料分成幀,亂序發送到一個TCP連接中
5.5 HTTP 2.0的優勢
HTTP 2.0的優勢如下:
- 成功解決了HTTP 1.1的隊首阻塞問題
- 不需要通過HTTP 1.x的pipeline機制用多條TCP連接來實作并行請求與回應,減少了TCP連接數對服務?性能的影響
- 將頁面的多個資料css、js、 jpg等通過一個資料鏈接進行傳輸,能夠加快頁面組件的傳輸速度
六、QUIC協議的城會玩
HTTP 2.0雖然大大增加了并發性,但還是有問題的,因為HTTP 2.0也是基于TCP協議的,TCP協議在處理包時是有嚴格順序的
當其中一個資料包遇到問題,TCP連接需要等待這個包完成重傳之后才能繼續進行,雖然HTTP 2.0通過多個stream,使得邏輯上一個TCP連接上的并行內容進行多路資料的傳輸, 然而這中間并沒有關聯的資料,一前一后,前面stream 2的幀沒有收到,后面stream 1的幀也會因此阻塞
于是,就又到了從TCP切換到UDP,進行城會玩的時候了,這就是Google的QUIC協議,接下來看它是如何城會玩的
6.1 機制一:自定義連接機制
一條TCP連接是由四元組標識的,分別是源IP、源埠、目的IP、目的埠, 一旦一個元素發生變化時就需要斷開重連,重新連接,在移動互聯情況下,當手機信號不穩定或者在WIFI和移動網路切換時,都會導致重連,從而進行再次的三次握手,導致一定的時延
這在TCP是沒有辦法的,但是基于UDP就可以在QUIC自己的邏輯里面維護連接的機制,不再以四元組標識,而是以一個64位的亂數作為ID來標識,而且UDP是無連接的,所以當IP或者埠變化的時候,只要ID不變,就不需要重新建立連接
6.2 機制二:自定義重傳機制
TCP為了保證可靠性,通過使用序號和應答機制,來解決順序問題和丟包問題
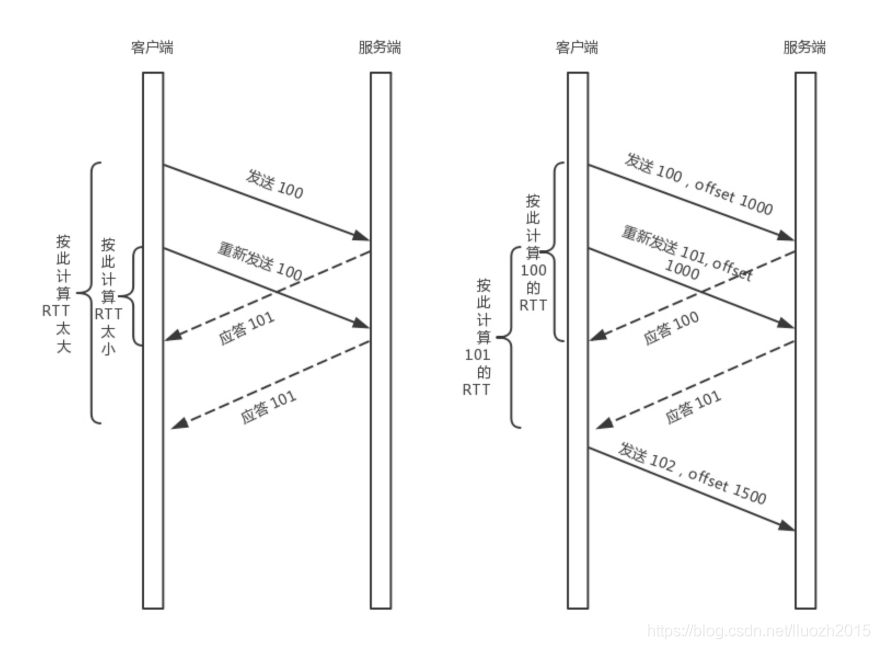
任何一個序號的包發過去,都要在一定的時間內得到應答,否則一旦超時就會重發這個序號的包,那怎么樣才算超時呢?TCP采用的自適應重傳演算法中的這個超時是通過采樣往返時間RTT不斷調整的
其實,在TCP里面超時的采樣存在不準確的問題
例如,發送一個包序號為100,發現沒有回傳,于是再發送一個100,過一陣回傳一個ACK101,這時客戶端知道這個包肯定收到 了,但是往返時間是多少呢?是ACK到達的時間減去后一個100發送的時間,還是減去前一個100發送的時間呢?事實是,第一種演算法把時間算短了,第二種演算法把時間算長了
QUIC也有個序列號,是遞增的,任何一個序列號的包只發送一次,下次就要加一了
例如, 發送一個包序號是100,發現沒有回傳,再次發送時序號就是101了,如果回傳的ACK 100,就是對第一個包的回應,如果回傳ACK 101就是對第二個包的回應,RTT計算相對準確
但是這里有一個問題,就是怎么知道包100和包101發送的是同樣的內容呢?QUIC定義了一個
offset概念,QUIC既然是面向連接的,也就像TCP一樣是一個資料流,發送的資料在這個資料流里面有個偏移量offset,可以通過offset查看資料發送到了哪里,這樣只要這個offset 的包沒有來就要重發,如果來了,按照offset拼接,還是能夠拼成一個流
6.3 機制三:無阻塞的多路復用
有了自定義的連接和重傳機制,就可以解決上面HTTP 2.0的多路復用問題
同HTTP 2.0一樣,同一條QUIC連接上可以創建多個stream來發送多個 HTTP 請求,但是,QUIC是基于UDP的,一個連接上的多個stream之間沒有依賴,這樣,假如stream2丟了一個UDP包,后面跟著stream3的一個UDP包,雖然stream2的那個包需要重傳,但是stream3的包無需等待,就可以發給用戶
6.4 機制四:自定義流量控制
TCP的流量控制是通過滑動視窗協議,QUIC的流量控制也是通過window_update,來告訴對端它可以接受的位元組數,但是QUIC的視窗是適應自己的多路復用機制的,不但在一個連接上控制視窗,還在一個連接中的每個stream控制視窗
在TCP協議中,接收端的視窗的起始點是下一個要接收并且ACK的包,即便后來的包都到了放在快取里面,視窗也不能右移,因為TCP的ACK機制是基于序列號的累計應答,一旦ACK了一個系列號就說明前面的都到了,所以只要前面的沒到,后面的到了也不能ACK,就會導致后面的到了也有可能超時重傳,浪費帶寬
QUIC的ACK是基于offset的,每個offset的包來了,進了快取就可以應答,應答后就不會重 發,中間的空擋會等待到來或者重發即可,而視窗的起始位置為當前收到的最大offset,從這 個offset到當前的stream所能容納的最大快取,是真正的視窗大小,顯然,這樣更加準確
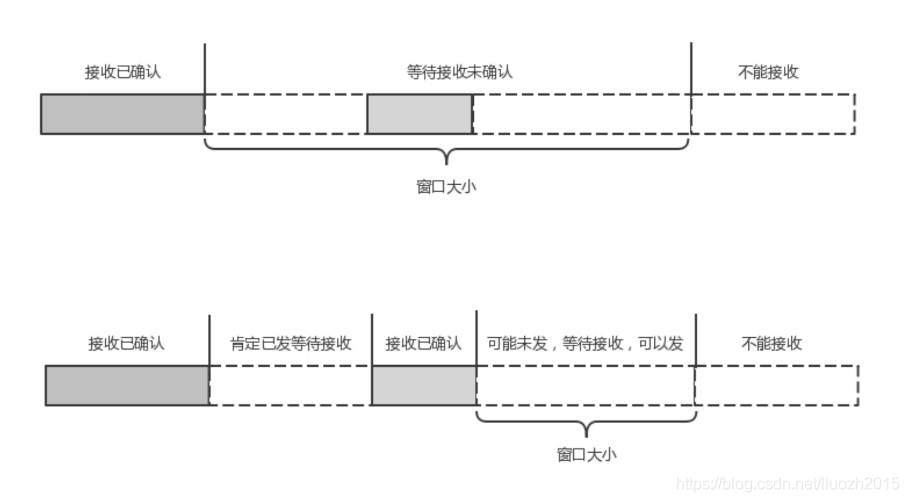
另外,還有整個連接的視窗,需要對于所有的stream的視窗做一個統計
七、小結
針對以上內容總結一下:
- HTTP協議雖然很常用,也很復雜,重點記住GET、POST、 PUT、DELETE這幾個方法, 以及重要的首部欄位
- HTTP 2.0通過頭壓縮、分幀、二進制編碼、多路復用等技術提升性能
- QUIC協議通過基于UDP自定義的類似TCP的連接、重試、多路復用、流量控制技術,進一步提升性能
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/292003.html
標籤:其他
上一篇:umi改為路由改為hash模式,Ant Design Pro Components的ProLayout 選單不出來了
下一篇:初識c語言2.0