本篇文章是解讀頂會論文的第一篇,為了追求閱讀效率,省略了本人認為不影響理解的內容,并非論文的全部中文翻譯,主要包括文章的核心內容和方法,想要看包含文獻綜述等完整論文內容的小伙伴可以自己閱讀英文原文哦~
文章標題《Understanding the Effects of the Neighbourhood Built Environment on Public Health with Open Data》

本文發表于2019年CCF-A類頂會WWW,由劍橋大學的學者提出,是關于因果推斷,社會科學和計量經濟學的論文,屬于交叉學科研究方向,關于CV,NLP,RecSys等方向的頂會論文解讀已有不少大佬總結,關注計量經濟學和社會科學方面的頂會論文相對較少,這篇論文比較有意思,因此簡要介紹幫助大家快速了解文章核心,
廢話不多說,我們開始吧≡ω≡
1. 文章背景
在公共政策以及社會科學的領域中,研究社區環境對居民健康的影響是一個較為典型的、有價值的方向,傳統的研究方法以社會調研為主,其時間和空間跨度是有限的,這會導致時間和空間上的粗粒度資料(如面板資料),且大規模的社會調研會導致較高的人力物力成本,通常來說是效率很低的做法,基于此,本文利用開放資料(如OSM等專案提供的資料),在較細的時空粒度以及因果關系框架的基礎上,提出了一種將鄰里社區特征對居民健康的影響聯系起來的方法,具體而言,作者使用因果推斷等方法,研究了三年內倫敦600多個區域的運動場所對抗抑郁藥處方流行率的影響,將其作為一個典型案例來證明社區環境對居民健康的影響,這種方法有很多好處,看到后面你就知道了╰( ̄▽ ̄)╭,
2. 研究方法
先介紹總體方法:文章關注的是社區環境的具體特征,如某些特定服務的存在(體育設施)對人口健康的outcome(如抗抑郁藥處方)的影響,這里的社區環境特征被稱為treatment,這里采取了因果推理的觀點(假設你已經了解因果推理相關概念),文章想找到對于社區環境施加體育設施這種treatment會給人口健康結果帶來的因果效應,簡單來說就是,我們需要評估,當體育設施這個具體特征改變的時候,它對于人口健康結果(如抗抑郁藥處方)有什么樣的影響,
2.1 研究單位
在因果推理中,實驗物件叫做unit,可以是一個或者多個,在本文中可以看作是施加了treatment的研究單位,即不同的neighbourhoods,具體就是倫敦的625個行政選區(ward),在一年開始時,每個區域都被視為施加了特定單位量的treatment,
2.2 Matching
在介紹matching方法之前,我們要了解一個基礎的因果推理方法叫做隨機對照實驗(RCT,randomized controlled trials),如果應用這種方法,本文的做法理論上應該是隨機選擇一半的區域(ward),將沒有施加treatment的區域集合作為對照組(control group),剩下的作為實驗組(treatment group),但是顯而易見這種方法是非常拉垮的,畢竟我們不能隨心所欲地控制在哪個區域去施加treatment,
雖然RCT的方法是不可取的,但它背后的思想非常有價值,它確保了除treatment變數的所有影響outcome的變數都是平衡的,這意味著兩組物件的實驗結果在treatment status上是可比的,因為treatment是唯一的區別所在,
那么問題來了——怎樣找到一個alternative method來實作RCT的思想呢?

本文采用的是因果推理中的匹配演算法(Matching Procedure),這里要介紹一個概念叫混雜變數(confounder),它是影響treatment或outcome(包括同時影響)的變數(類似于計量經濟學中的協變數),我們構建對照組和實驗組時需使confounders平衡,而treatment的分配隨機,匹配的程序可以概括如下:對每個對照組的unit,在實驗組中找到confounders都相同的unit作為一個match,即精確匹配(Exact Matching),(你問為什么要這么做?——請查閱因果推理相關資料,這里不做贅述)然而想要找到精確匹配并不是always possible,因此我們退而求其次,對于每個對照組的unit,在實驗組中找到confounders變數平均值差異最小的unit就行了,
2.3 Propensity Score
大致了解了匹配的思路后,我們需要解決兩個問題:1.怎樣最小化match中confounders的差異?2.怎樣最大化match中treatment的dose值?(dose為文中體育設施的單位量)
對于第一個問題,解決方法是使用一個指標來量化match中confounders之間的差異,這個指標就是傾向評分(propensity score);對于第二個問題,文章將0-1二分的treament變數改為multiple treatment levels,
3. 論文圖示
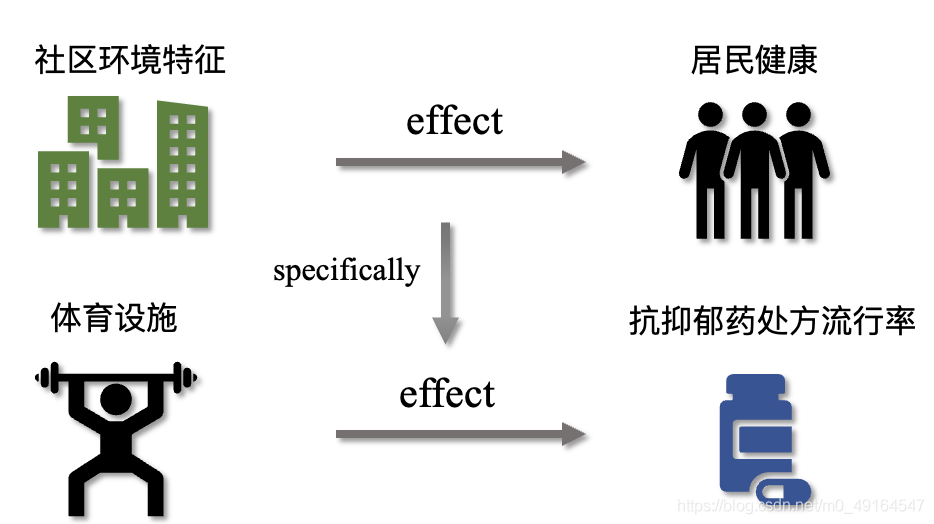
4. Matching with Binary Treatment
為了后續更好地說明multiple treatment的情況,這里先介紹二分匹配,最常用的一種匹配方法是最近鄰匹配法(nearest neighbor matching),其匹配程序可以概括如下:設為配對的units集合,
???????為confounders集合,
???????為單一confounder,優化的目的是最小化配對units的距離(distance):
![]()
其中,代表unit
的第
個confounder,
該優化問題可看作一個圖匹配問題(gragh matching problem),給定一個二分圖,在
???????的一個子圖
中,
的邊集中任意兩條邊都不依附于同一個頂點,則稱
是一個匹配,若一個圖的某個匹配中,圖的所有頂點都是匹配點,則稱該匹配為完美匹配,一個圖的所有匹配中,所含匹配邊數最大的匹配稱為最大匹配,使所有邊權和最小的最大匹配叫做最優加權圖匹配,在本文中,每個confounder都有不同的權重,因此可以看作是尋找最優加權圖匹配的問題,
5. Matching with Multiple Treatment Levels
假設代表施加treatment的等級,我們先前的討論是基于
???????的取值僅為0或1的情況,然而對于本文的特定情況,我們必須考慮將其擴展到有許多可能的treatment level的情況,在這種存在multiple treatment levels的情況下,基于傾向評分的匹配仍然需要平衡觀察到的混雜變數confounders,即滿足下列條件:
,其中
表示每個unit屬于treatment的傾向性(預測概率),
表示confounders,
為傾向評分,
傾向評分的估計是一個典型的建模問題,方法有許多種,最常見的就是線性回歸模型,也有學者使用機器學習模型,如 LR + LightGBM,由于我們的因變數treatment是多分類的情況,本文使用的模型是ordered logistic model:
![]()
其中, 為施加treatment的dose值,可取值
,注意:在此處,給定confounders的treatment level分布僅取決于
,估計傾向評分就等于估計
,這里可使用最大似然法進行該引數的估計,表示為
,
上述的作業主要是為了使confounders平衡,除此之外還需要使配對units的treatment level差異最大化,假設unit 和 unit
的距離為
,目標為最小化該距離:
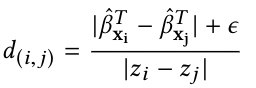
其中,為一個極小正數, 為防止出現confounders完全相同的配對units,該問題是一個最優非二分匹配問題,我們現在可以構建一個圖,每個頂點代表一個unit,邊連接到其他unit,邊上的權重為
,使用Edmonds演算法(Edmonds' non-bipartite matching algorithm)可以在多項式時間內解決在非二分圖中尋找最大匹配的問題,我們可以使用Edmonds演算法得到一個最佳匹配M,并用
和
分別表示outcome和treatment,然后通過以下公式計算平均因果效應(Average Treatment Effect,簡稱 ATE):
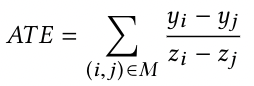
6. 資料集和變數
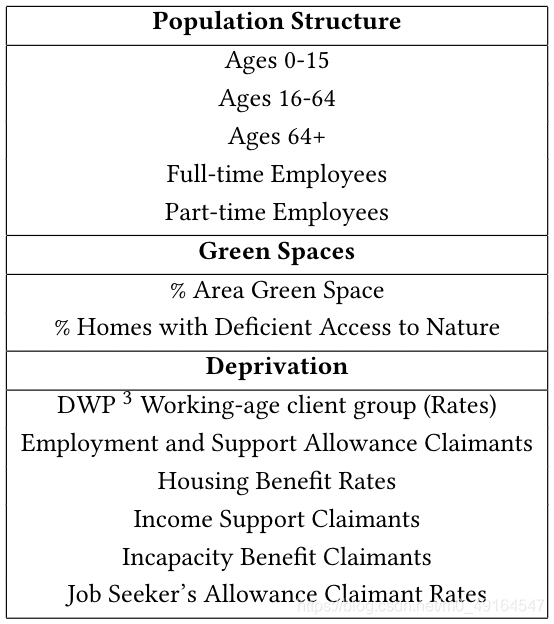
6.1 Confounding Variables
混雜變數可分為三類,首先是人口結構,倫敦和許多發達城市一樣,是一個商業活躍的地區,城市的不同部分吸引著生活在不同階段的人們,這里將人口分為0-15歲(兒童)、16-64歲(作業年齡)和64歲以上(退休)的人群,其次,一個地區全職和兼職員工的數量有助于我們確定該地區是住宅區還是商業區,這會影響體育設施和抗抑郁藥處方的數量,
第二是綠地的可用性,盡管倫敦是地球上最具綠色的首都之一,但在綠地的可用性方面還是有很大差異,人口統計資料集通過兩個值來描述這個特征,即% area that is green space和% homes with deficient access to nature,接觸大自然不僅與心理健康相關,而且也決定了可用的體育場地的型別,
最后,confounders還包括一些貧困措施(Deprivation),如表所示:
6.2 The Treatment Effect
用體育設施代表treatment,包括一系列體育相關的場館,如下表所示,涉及到的場館及其頻率用詞云表示,本文的treatment level為1,2,3,4四個等級,

7. ATE結果
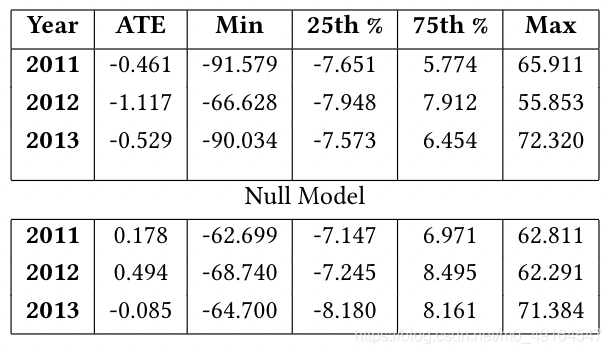
確定了資料集和變數后,使用前面提到的方法計算因果效應,這里的units是在倫敦的單位區域(ward)內,單位個人(per person)抗抑郁藥處方的變化和單位(per dosage)運動場地,從實驗結果可以看到2011~2013三年的ATE都是負數,這表明了treatment對outcome有負面的影響,如果我們將其與在null model上match的treatment效應分布進行比較(每個ward的運動場地計數是隨機的),如圖所示,這也表明存在負方向的影響,
8. 評估因果效應的可靠性
由于我們沒有可比較的“真實”效應,因此在這種情況下,匹配演算法的有效性使用三個指標進行評估:dose差異、confounders平衡性、匹配程式在生成資料集上的性能,
8.1 Dose Difference
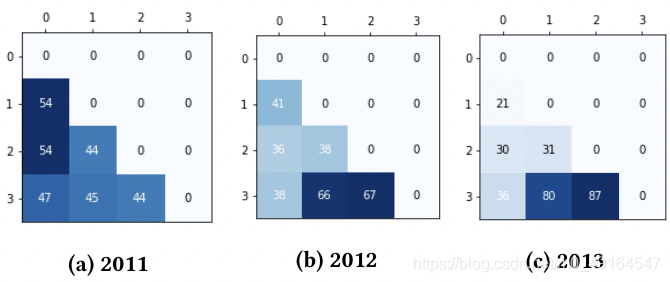
下圖顯示了三年內每對配對units的dose分布,行表示該對中treatment水平較高的unit,串列示treatment水平較低的unit,深色表示該dose水平的配對數量更多,
8.2 Confounder Balance
下表顯示了配對的high dose unit 和 low dose unit之間confounders的平均值,
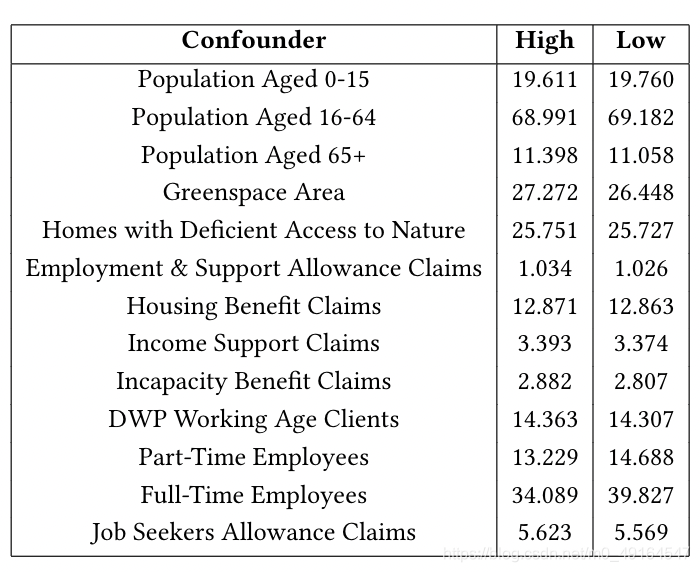
在這里可以看到,大多數confounders在兩組之間成功地平衡了,例外情況可能是標準化的全職和兼職員工比率,其差異分別超過5%和1.4%,文中深入探討了這兩個變數非平衡性產生的原因,大致是由于倫敦三大商業區的因素,由于其特殊性,不能簡單地當作誤差處理,否則會導致其他confounders的非平衡性增加,
8.3 匹配生成資料
假設需要生成個units,
,每個unit都具有
個confounders(這里具體為13個),表示為
,首先,我們使用截斷正態分布(truncated normal distribution)建模,先為所有units生成confounders的值,然后使用指數分布(exponential distribution)建模生成每個unit的treatment值,即
,最后,仍然使用截斷正態分布建模,生成每個unit的outcome值,即
(具體公式請參考原文),下圖為標準化后的生成資料和真實資料分布對比圖:
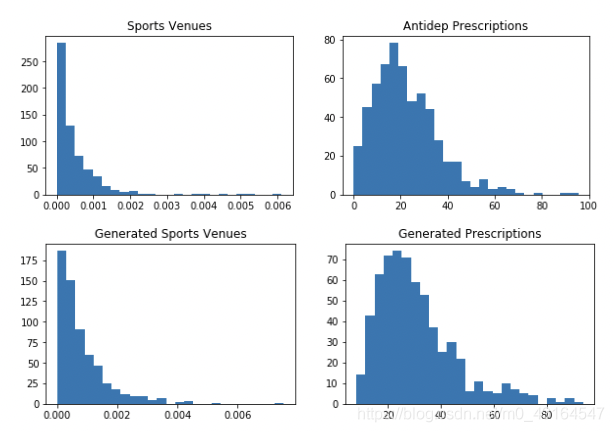
在生成資料集上運行與真實資料集相同的匹配演算法,文中共生成6250個units,每批625個,具有不同的混雜因素集,設定四個ATE真值,倒推出資料,使用匹配演算法計算四次求ATE值,根據匹配演算法計算的treatment effects如表所示:
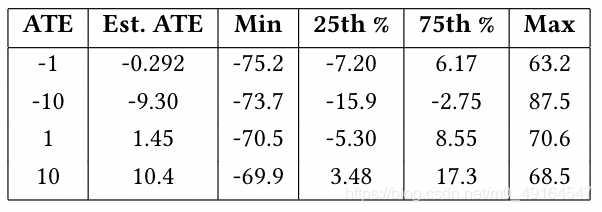
表中第一列是作者設定的真實ATE值,在這里,我們可以看到與真實的treatment effects類似的結果,若設定較大的ATE值,該匹配演算法能夠達到更好的估計效果,如果真實的ATE值較小,則因果推斷的效應不太準確,這說明了我們應該如何解釋從實際資料中獲得的結果,由于前面在真實資料集上計算出的對于outcome的因果效應很小,我們應該更傾向于保守的解釋(可以看出論文是非常嚴謹的),
9 后續討論
文章后續討論了confounder的選取及其影響,以及一些可能的誤差來源以及假設問題,綜上,文章通過研究體育場館的可用性在多大程度上對倫敦周邊地區抗抑郁藥處方起著因果作用,為解決社會和公共政策問題提供了一個資料驅動的方法,

ok,本文的介紹到此結束,學經濟學的朋友們應該感覺特別輕松,關于省略的部分推薦大家閱讀英文原文:https://dl.acm.org/doi/10.1145/3308558.3313701,有相關問題也歡迎感興趣的朋友和我探討,
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/292397.html
標籤:其他
上一篇:一文徹底搞懂SLAM技術