一、前情回顧
上次的文章中講到了BeautifulSoup模塊,可以用來決議和提取資料,那么,我們下面一起來嘗試爬取一些內容,比如五月天歌單
首先,我們需要知道爬取五月天的歌單需要選擇擁有五月天歌曲著作權的平臺去找,因此這里選擇了QQ音樂,但是爬取之前,我們應該先看一看QQ音樂的robots協議:1

可以看到,QQ音樂只是禁止了我們爬取playlist(播放串列)的資訊,因此我們可以放心爬取,接下來按流程進行爬取:
首先還是用谷歌瀏覽器打開網頁,右擊,點擊檢查并找到歌名對應的位置:
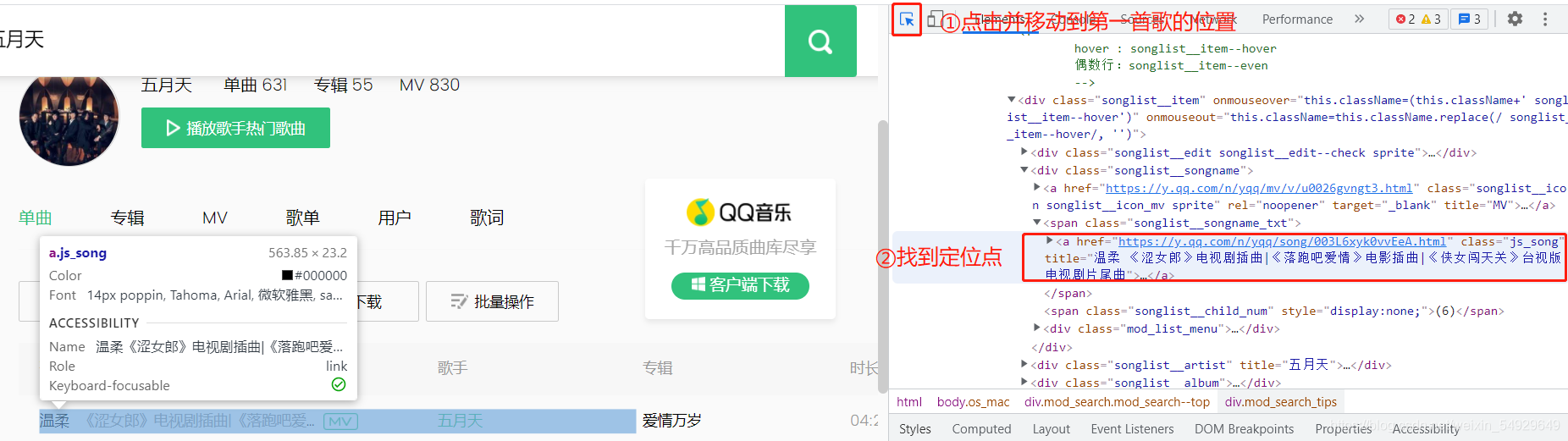
下面,我們就撰寫代碼實作爬取五月天的歌單:
import requests
from bs4 import BeautifulSoup as bs
headers = {'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.79 Safari/537.36'}
# 定義請求頭,模擬用戶訪問網頁,后面會具體講述
res=requests.get('https://y.qq.com/portal/search.html#page=1&searchid=1&remoteplace=txt.yqq.top&t=song&w=%E4%BA%94%E6%9C%88%E5%A4%A9',headers=headers,verify=False)
# 提取網頁資料
# verify=False功能為關閉網頁認證
music_message=bs(res.text,'html.parser')
# 決議提取到的資料
name=music_message.find_all('a',class_="js_song")
# 找到全部的歌曲名稱
for i in name:
# 逐一列印歌曲名稱
print(i)
雖然有一條警告,但是我們運行成功了,不過,什么都沒有顯示,為了檢查是不是我們書寫有問題,我們先查看一下提取到的資料:
import requests
from bs4 import BeautifulSoup as bs
headers = {'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.79 Safari/537.36'}
res=requests.get('https://y.qq.com/portal/search.html#page=1&searchid=1&remoteplace=txt.yqq.top&t=song&w=%E4%BA%94%E6%9C%88%E5%A4%A9',headers=headers,verify=False)
# verify=False功能為關閉網頁認證
music_message=bs(res.text,'html.parser')
print(music_message)
由于結果太長,這里不放了,可以看到的是,我們并沒有看到完整的網頁源代碼,并且這部分代碼中也沒有出現歌單,也就是之前介紹的方法不是用于這個場景下了,
二、網站的深度決議
之前已經提到過,網頁源代碼和我們怕渠道的內容不一致,我們只爬到了一部分源代碼,那么,下面就介紹沒有被爬到的源代碼,被隱藏到了什么地方
1.Network簡介
首先,我們觀察一下這里:

我們之前所看的都是這個Elements里的內容,但是接下來,我們需要點擊Network進行對隱藏的源代碼的找尋,首先點擊Network然后重繪頁面(Network 記錄的是實時網路請求,在網頁已經加載完成的情況下,不會顯示內容):
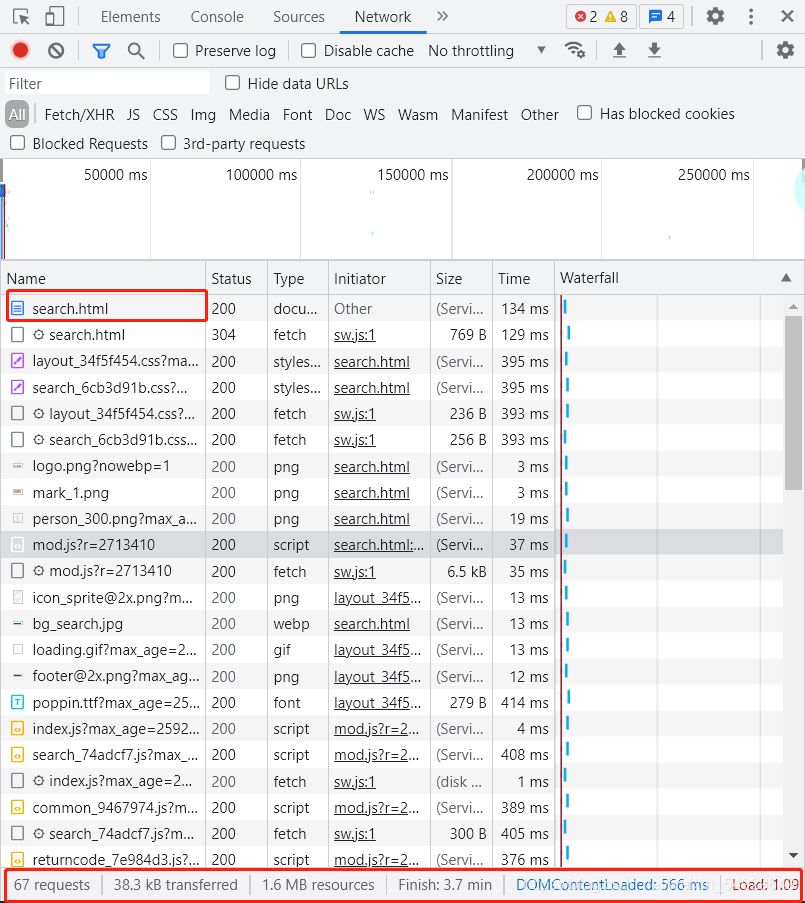
首先,Name欄第一個是html檔案,我們不妨點開看看:
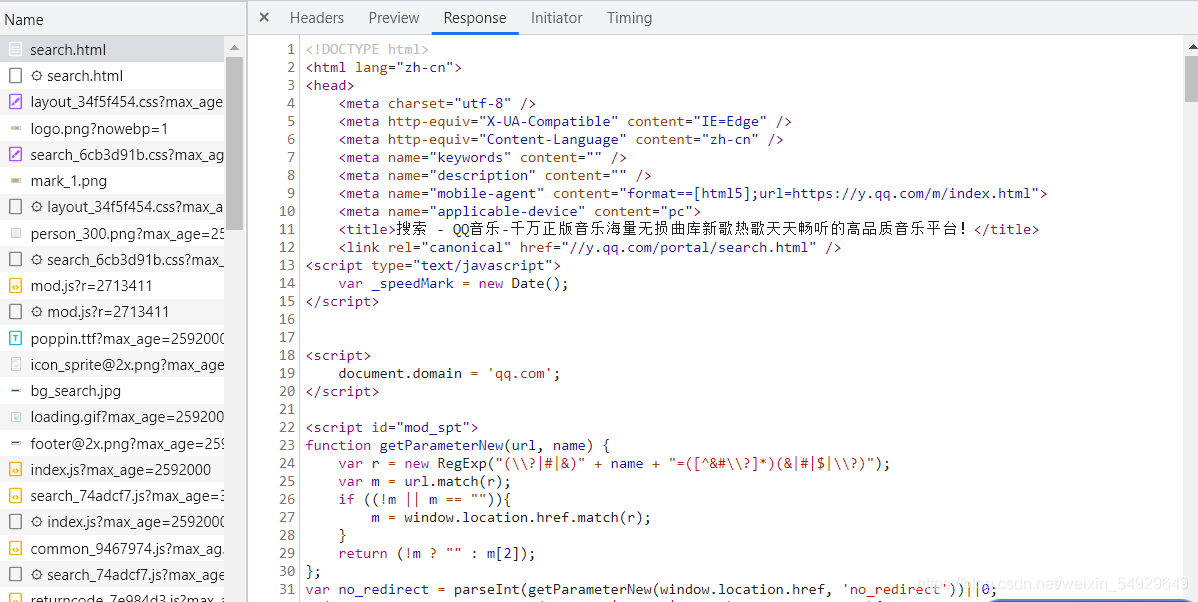
點開后選擇Responses進行觀察,細心的小伙伴也許已經發現了,這里面的內容和我們剛剛爬取的一致,事實上,我們剛剛的方法所爬取的內容就是這個檔案里的源代碼,上篇文章中選擇的網頁,源代碼全部都放在這個檔案里,而這次的網頁不同,這也就是為什么我們之前行之有效的方法在這里失靈的原因,
下面我們繼續觀察下面這一欄,這一欄記錄著請求數量,流量和時間的消耗,這正是瀏覽器作業的原理:它總是在向服務器發起請求,當這些請求完成,服務器就會回傳我們在 Elements 中看到的網頁源代碼,剛剛我們查看的html檔案只是這67個請求里第一個請求,一般來說,都是這種第 1 個請求先啟動了,其他的請求才會關聯啟動,一點點地將網頁給填充起來,我們也得到了一個方法:以后爬取內容之前先看看Network里面的第一個請求的內容,如果不包含我們想要的內容,之前的方法就不再適用了,
為了成功抓取到歌曲清單,我們就需要找到能讓服務器回傳歌名的那一個請求,然后針對這個請求應用requests庫,模擬這個請求,
那么如何找到這個被隱藏起來的請求呢?別急,下面我們一步步分析,先上圖:
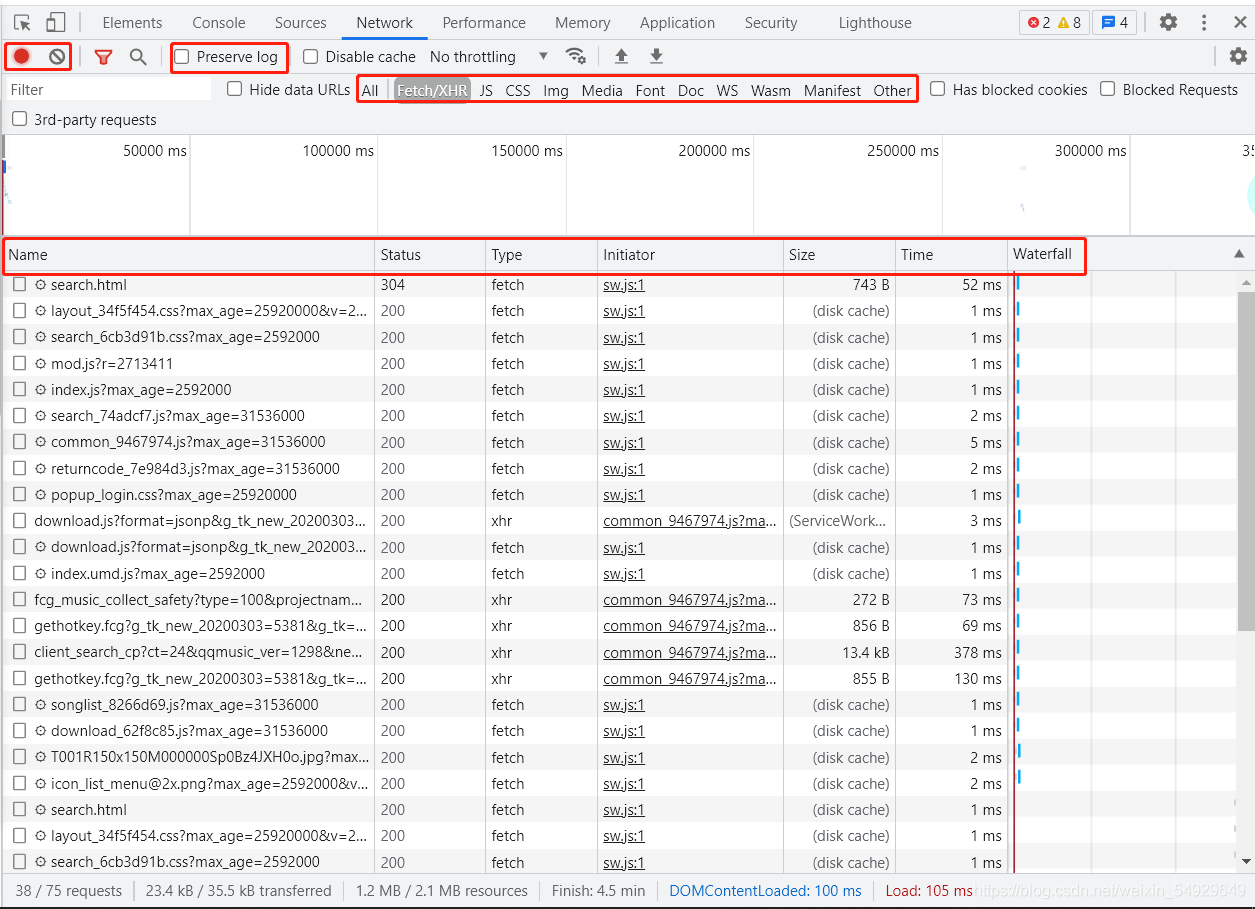
紅框圈起來的是我們需要重點了解的內容,左上角的紅圈是啟用 Network 監控(一般瀏覽器默認是打開),灰色圓圈是清空面板上的資訊,勾選框 Preserve log的作用是 “保留請求日志”,當我們需要爬取會發生跳轉的網頁時,要記得點亮它,否則當發生頁面跳轉的時候,記錄會被清空,下面一行,是對請求進行分類查看,我們對常用的標題進行介紹:
| 標題 | 功能 |
|---|---|
| ALL | 查看全部請求 |
| Fetch/XHR | 查看 XHR或Fetch,后面會重點介紹 |
| JS 和 CSS | 前端代碼,負責發起請求和頁面實作 |
| Img | 僅查看圖片 |
| Media | 僅查看媒體檔案 |
| Font | 文字字體 |
| Doc | Document的縮寫,第 1 個請求一般在這里,用于檢查想要爬取的內容是否在第一個請求里十分方便 |
| Other | 其他 |
| WS以及Manifest | 與網路編程有關,在此先不做介紹 |
下面的一行紅框是時間軸,可以僅作為了解:
| 標題 | 功能 |
|---|---|
| name | 名字 |
| status | 請求狀態代碼 |
| type | 請求型別,例如xhr |
| size | 資料大小 |
| time | 請求所花費時間 |
| waterfail | 描述每個請求的起止時間 |
對Network有了基本了解之后,便要開始尋找被隱藏起的源代碼咯~
2.XHR類請求
在 Network 中,有一類非常重要的請求叫做XHR(完整表述為XHR and Fetch),平時使用瀏覽器上網的時候,經常有這樣的情況:地址欄里的網址沒有發生變化,但網頁內容卻在不斷變化,這就叫做Ajax技術,應用這種技術可以在不改變網址的情況下更改網頁內容,省流又節約時間,這種技術在作業的時候,會創建一個 XHR(或是 Fetch)物件,然后利用 XHR 物件來實作服務器和瀏覽器之間傳輸資料,XHR與Fetch 并沒有本質區別,只是 Fetch 出現得比 XHR 晚一些,
對比前面的功能表,我們想要找的歌單不在網頁源代碼里,而且也不是圖片,不是媒體檔案,自然只會是在XHR里,也就是說,我們應該會在Fetch/XHR選項下找到包含歌曲清單的檔案,可以看到,這里一共包含了38個請求,那么如何去尋找歌單呢?最為簡單有效的方法就是遍歷,在遍歷之前,先給大家介紹一下這個表頭:
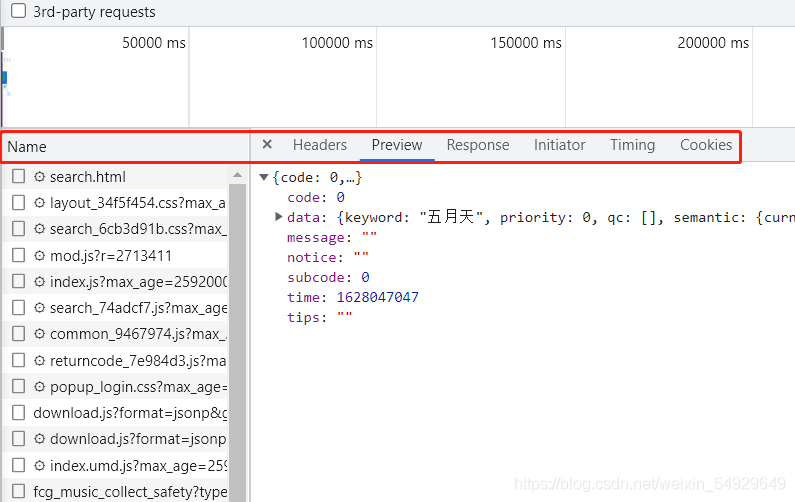
隨意點開一個請求,就會出現類似的界面,那么這個表頭都是什么意思,怎樣查看我們要找的內容是不是在對應請求下呢?老規矩,先總結,再上圖:
| 名稱 | 含義 |
|---|---|
| Headers | 請求資訊 |
| Preview | 預覽 |
| Response | 原始資訊 |
| Timing | 時間 |
這次,我們需要在Preview(預覽)里查看,依次點擊請求,我們發現了以下幾種樣式:
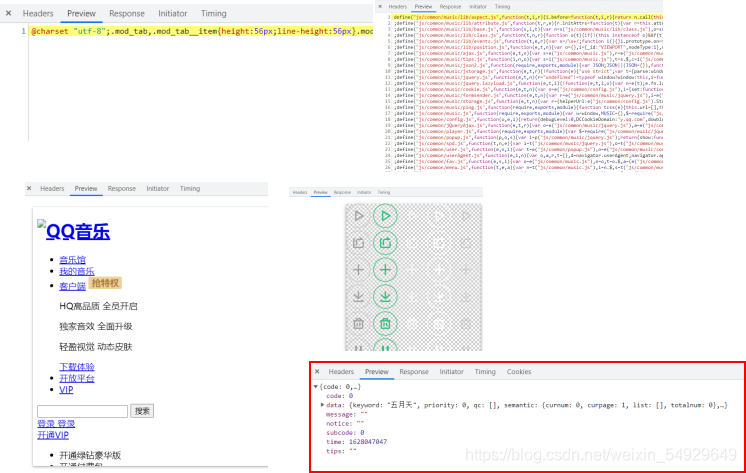
只有紅框圈起的內容樣式是我們想要的歌單的可能出處,至于為什么是這樣的格式,我們后文為大家介紹,先依次點擊小三角打開折疊的內容,尋找到歌名所在的請求:client_search(客戶端搜索),如果可以閱讀它們的名字,自然可以更快地找到對應的請求,
找到這個請求之后,可以點擊Headers(請求資訊)查看這個請求的詳細內容,比如:
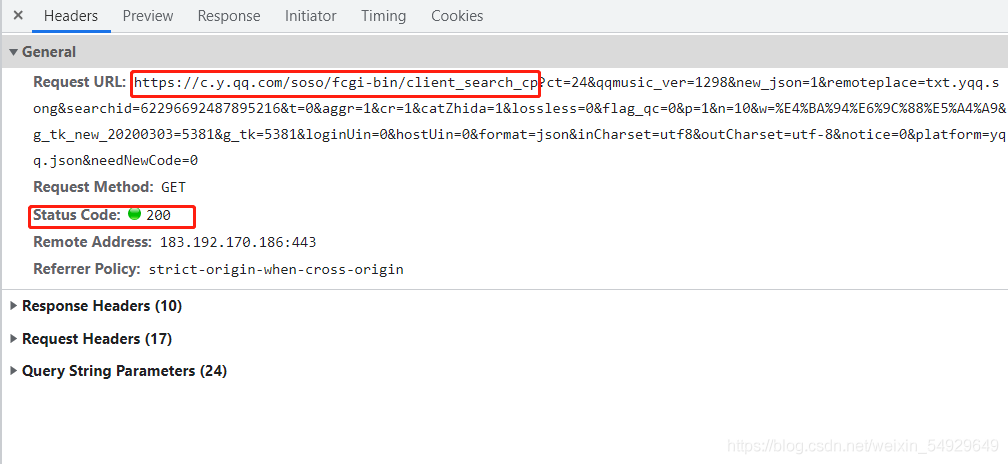
這里就提供了這個請求的網址和狀態碼,以及服務器的地址和埠、記錄請求的來源,注意一下這個網址,“?”(也或是#)會將網址分成兩個部,這兩部分分別代表什么后面會提到,現在我們將整個網址復制下來去瀏覽器打開看看:

這真是一個令人絕望的頁面,但是粗略看過去,這里面的漢字有歌曲名、專輯以及歌曲資訊,是我們想要的內容,所以硬著頭皮看看:這是一個串列和字典相互嵌套的結構,和我們在Response 里看到東西是一致的,原始資訊看不明朗,那我們就去預覽里看看:
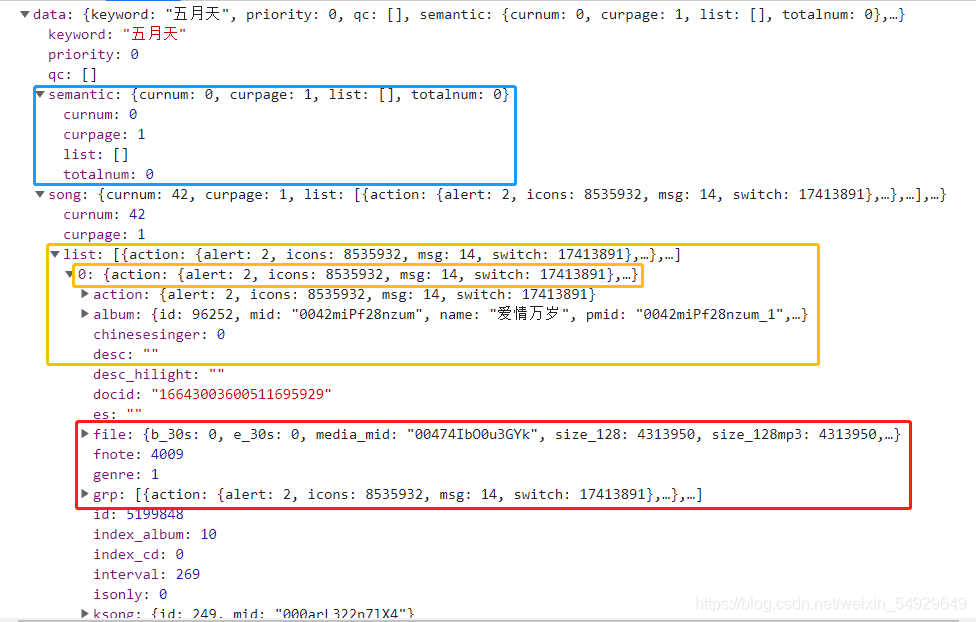
可以很清楚的看到內容分級,和我們的python語言一樣,針對字典元素而言,相同的縮進是同一級的元素,比如藍框里,semantic鍵對應一個字典,下面是縮進更多的鍵和值,代表這些內容屬于semantic對應的的值;黃色框里先是一個串列,而后更多縮進的一行是串列的0號位置元素是一個字典元素,而后的內容同籃框;紅色框file鍵對應的值是字典,fnote、genre鍵對應的值是數字,grp鍵對應的值是串列,但這三個鍵對應的縮進相同,因此就代表它們是字典內的同一級元素,
理解了這些資料分級,我們就可以用查找字典和數字元素的方法找到我們想要的歌曲清單了,首先找到第一首歌曲名所在的位置:
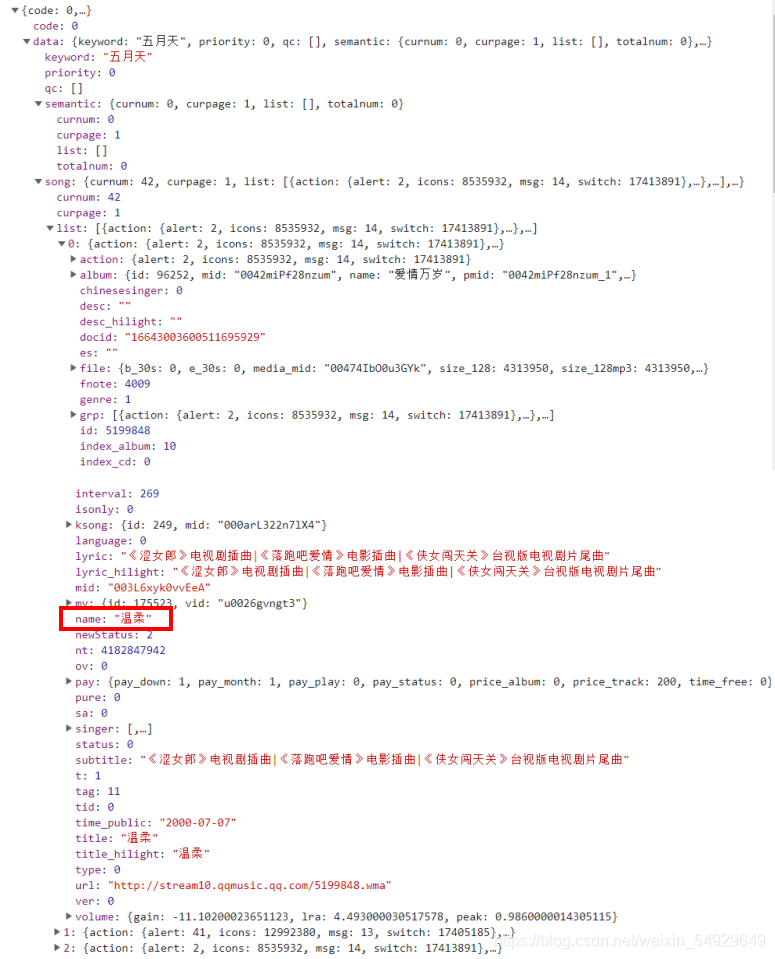
如圖,這里name鍵對應的值是我們想要的,想要讓代碼找到這里,就必須逐層找下去:首先找到data鍵對應的值,然后找到song鍵對應的值,緊接著找到list鍵對應的串列下標為0的元素,最后找到name鍵對應的元素,
下面,我們一起撰寫代碼:
import requests
from bs4 import BeautifulSoup as bs
headers = {'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.79 Safari/537.36'}
# 定義請求頭,模擬用戶訪問網頁,后面會具體講述
url='https://c.y.qq.com/soso/fcgi-bin/client_search_cp?ct=24&qqmusic_ver=1298&new_json=1&remoteplace=txt.yqq.song&searchid=62296692487895216&t=0&aggr=1&cr=1&catZhida=1&lossless=0&flag_qc=0&p=1&n=10&w=%E4%BA%94%E6%9C%88%E5%A4%A9&g_tk_new_20200303=5381&g_tk=5381&loginUin=0&hostUin=0&format=json&inCharset=utf8&outCharset=utf-8¬ice=0&platform=yqq.json&needNewCode=0'
res=requests.get(url=url,headers=headers,verify=False)
# 下載字典的資料
# verify=False功能為關閉網頁認證
# 注:其實我們可以寫成
# res=requests.get(url,headers,verify=False)
# 這種形式,但由于擔心初學者記不住引數的位置,
# 本文都以上文未屏蔽代碼的寫法書寫代碼
print(type(res))
# 檢查res的資料型別
music_message=bs(res.text,'html.parser')
# 決議資料
print(music_message)
# 輸出為:<class 'requests.models.Response'>
# {"code":0,"data":{"keyword":"五月天"...}...}
寫到這里,相信小伙伴們已經發現了這個尷尬的事情,我們之前決議的資料是網頁的源代碼,可以用find_all()函式等尋找想要的內容,而這里決議過的資料是一個字典,find_all()等函式不再能派上用場了,
3.json格式在爬蟲中的應用
想要解決剛剛的問題,我們必須了解一個新的概念——json,json可以這樣來理解:json 是用字串的樣式書寫的串列或陣列(也可以是串列和陣列的嵌套),舉個例子:
i='1,2,3,4'
# i是一個字串
i=[1,2,3,4]
# i是一個串列
i='[1,2,3,4]'
# i是用json格式寫的字串
這種特殊的寫法決定了,json 能夠有組織地存盤資訊,

一般來說,這三條占得越多,資料的結構越清晰;占得越少,資料的結構越混亂,之前學習過的 html,是通過標簽、屬性來實作分層和對應來使網頁的結構清晰,json 則是另一種組織資料的格式,長得和 Python 中的串列 / 字典非常相像,它和 html 一樣,常用來做網路資料傳輸,可是串列或字典,只有在python語言中才能被識別,所以直接將他們封裝起來會導致其他編程語言不能夠識別,因此,json格式就出現了,它用字串(文本)的方式上傳字典/串列,這樣就變成了所有的語言都可以識別的最樸素的資料型別了,也因此,json 資料就能實作,跨平臺,跨語言作業,
那么,又如何在json格式下找到想要的內容呢?首先,我們需要把它轉化回串列/字典型別,然后就可以應用字典的鍵,串列的下標來找內容了,
3.1決議json
我們可以在requests庫的官方檔案中,找到requests庫處理 json 資料的方法,將json決議之后,就可以按照對串列和字典的操作完成資料的讀取了:
import requests
headers = {'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.79 Safari/537.36'}
res=requests.get('https://c.y.qq.com/soso/fcgi-bin/client_search_cp?ct=24&qqmusic_ver=1298&new_json=1&remoteplace=txt.yqq.song&searchid=62296692487895216&t=0&aggr=1&cr=1&catZhida=1&lossless=0&flag_qc=0&p=1&n=10&w=%E4%BA%94%E6%9C%88%E5%A4%A9&g_tk_new_20200303=5381&g_tk=5381&loginUin=0&hostUin=0&format=json&inCharset=utf8&outCharset=utf-8¬ice=0&platform=yqq.json&needNewCode=0',headers=headers,verify=False)
# 以上內容和之前代碼類似
json_music = res.json()
print(type(json_music))
# 檢查決議后的資料型別
# 結果為:<class 'dict'>
可以看到,這樣決議之后資料型別已經變成了字典,那么之后的操作就類似于依據字典的鍵取字典的值了(不太懂的小伙伴點擊這里看看「字典的讀取」部分的內容):
# 將這段代碼附加在剛剛的代碼后面即可
first=json_music['data']
# 找到data鍵對應的子字典
second=first['song']
# 找到song鍵對應的子字典
list_music=second['list']
# 找到list鍵對應的串列
# 以上內容可以寫成:
# list_music=json_music['data']['song']['list']
for music in list_music:
# 依據下標對串列進行遍歷,并列印歌曲名
print(music['name'])
# 結果為:<class 'dict'>
# 溫柔
# 后來的我們
# 知足
# 突然好想你
# 擁抱
# 倔強
# 你不是真正的快樂
# 盛夏光年
# 干杯
# 離開地球表面
這樣,我們就成功的把歌名拿到了,不過還有一點點遺憾需要解決,那就是我們雖然已經學會了把json格式的資料轉化成串列/字典,但是我們還沒有介紹如何將字典/串列轉化為json的格式,
那么,讓我們簡單學習一下:
3.2dumps()與loads()
dumps()與loads()是json模塊下的兩個函式,其功能分別為:將字典/串列等型別編碼成json格式的字串和將json格式的字串解碼為字典等原有型別,
那么這兩個函式的書寫格式分別為:
import json
result=json.dumps(dic,ensure_ascii=False,indent=i)
下面來解釋引數的意義:dic代表一個要轉化成json型別的字典型別,當然也可以是其他型別,如字典、串列、字串,ensure_ascii=False的目的是讓轉化為json格式之后,列印result的結果依然是輸入的文字內容,而非其對應的二進制編碼,indent=i的目的是轉換為json格式后,以“ ,”為標志,進行換行并空出i個空格,下面我們舉個栗子:
# 匯入 json 模塊
import json
dic = {"title": "尋找歌單","name":"五月天"}
list_=["title", "尋找五月天","name","五月天"]
str_ = '"title":"尋找歌單","name":"五月天"'
dic = json.dumps(dic,ensure_ascii=False,indent=4)
list_1 = json.dumps(list_,ensure_ascii=False,indent=4)
str_ = json.dumps(str_,ensure_ascii=False,indent=4)
list_2 = json.dumps(list_,ensure_ascii=False)
list_3 = json.dumps(list_)
print(dic,type(dic),list_1,type(list_1),str_,type(str_),\
list_2,type(list_2),list_3,type(list_3),sep='\n')
結果為:

得到的這個結果除了印證了我們剛才的介紹之外,也可以發現,所有通過dumps轉化成json格式的資料,其型別最終都為< str>型別而并非< requests.models.Response>、< BeautifulSoup>型別,也就是說,接下來我們學習的loads()函式他能操作的型別也只是str,因此并不能應用在將網頁上下載來的XHR類請求的內容直接還原成字典等型別,
下面給大家介紹loads()函式,這個函式可以將json格式下的str型別的資料還原成字典等原有格式,該函式的書寫格式為:
import json
result = json.loads(str_)
引數str_代表一個str型別的資料,下面舉例說明:
import json
old_dic='''{
"title": "尋找歌單",
"name": "五月天"
}'''
dic = json.loads(old_dic)
print(dic,type(dic),sep='\n')
# 結果為:{'title': '尋找歌單', 'name': '五月天'}
# <class 'dict'>
那么關于json的應用就先給大家普及這么多了,如果小伙伴想要深入了解可以到以下網站去拜訪:
JSON 編碼和解碼器,dumps()與loads()的使用
4.什么是“帶引數請求資料”
學習這節之前,我們先提出一個問題:上面爬取到的只有十首歌曲的歌名,如果我們想要拿到五月天的全部歌單,該如何操作呢?
打開網站,滑動到網頁底部:

好像已經沒有正常渠道翻閱更多的歌曲內容了,而客戶端打開又沒辦法爬取,所以又要怎么做才能查找到其他的歌曲內容呢?
首先我們先換一個網站觀察,給大家推薦豆瓣的“選電影”:
這個網頁可以翻閱更多的電影,也就友好了很多,我們先照例嘗試尋找包含有電影名稱的XHR請求:
小提示:我們順便介紹一個尋找包含電影名稱的XHR請求的高效方法,觀察這個界面:
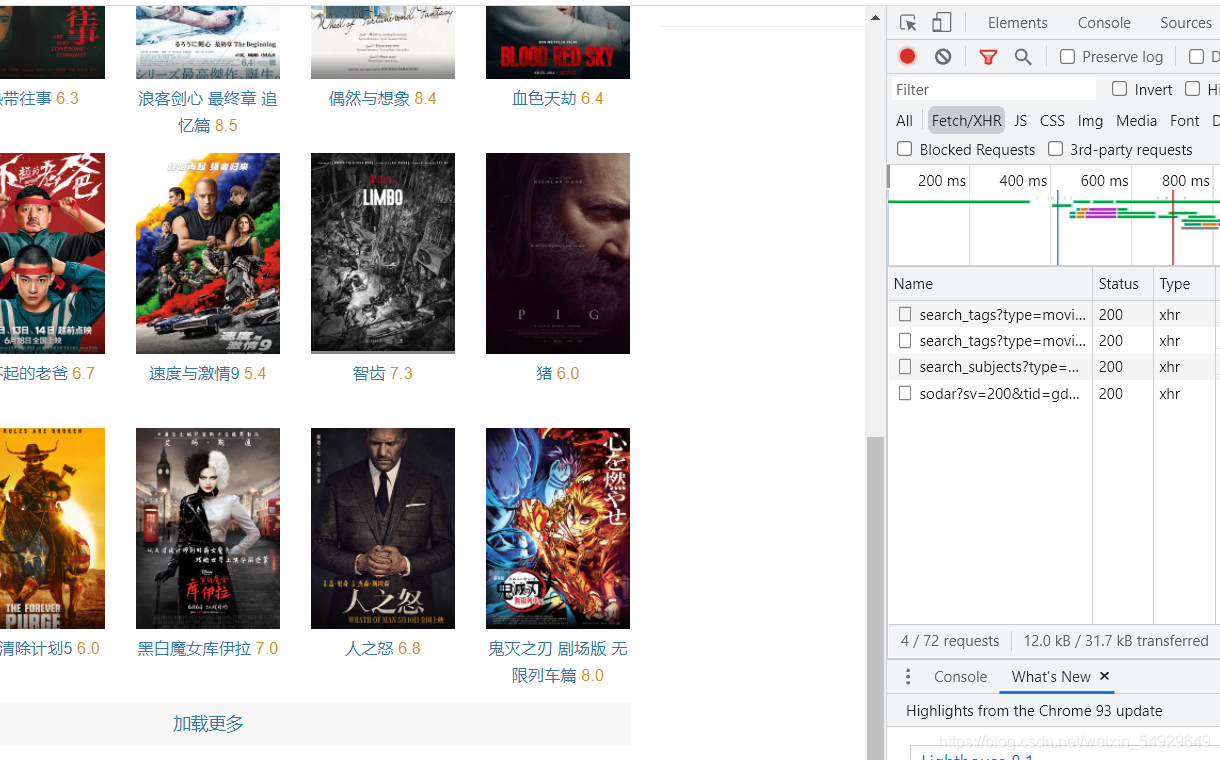
這里的Name欄有四個XHR請求,然后我們點擊加載更多按鈕:
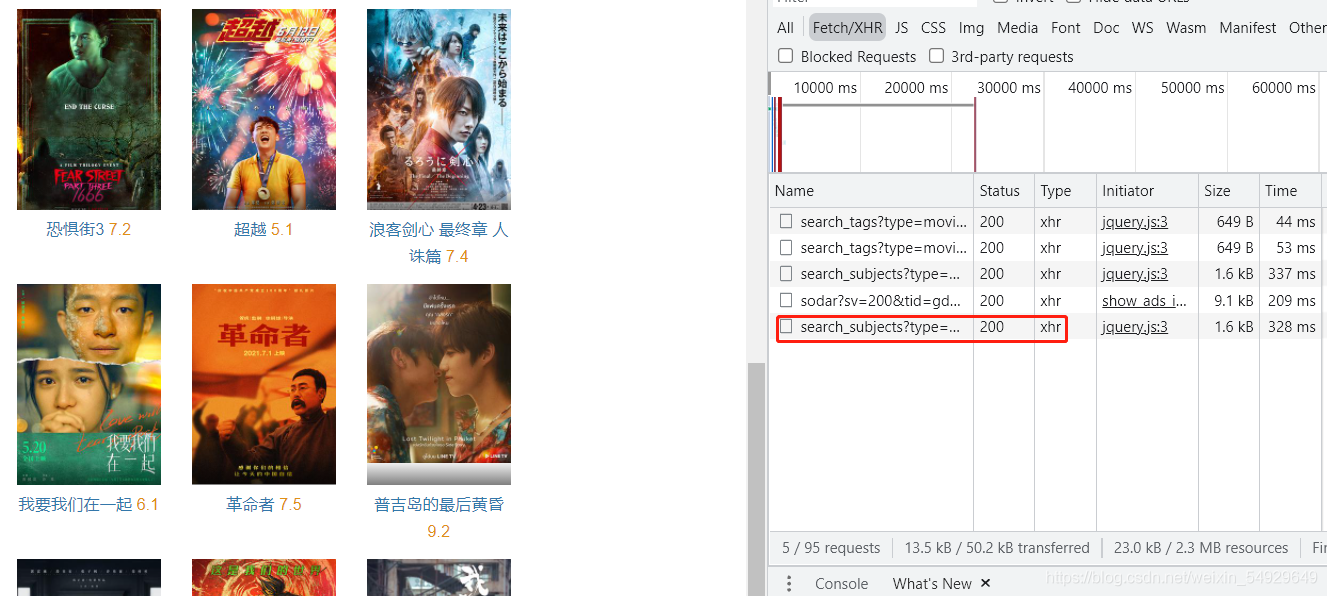
這里就出現了第五個請求了,這個請求里就包含了我們想找的電影資訊哦~可以先記住這個請求的名字,方便之后的操作,不僅如此,我們將滑鼠移動到可以點擊的部分,旁邊的Name欄都會有新的請求加載出來,這種方法非常好用的,
下面,我們開始嘗試爬取電影名稱:
import requests
headers = {'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.79 Safari/537.36'}
res=requests.get('https://movie.douban.com/j/search_subjects?type=movie&tag=%E7%83%AD%E9%97%A8&sort=recommend&page_limit=20&page_start=0',headers=headers,verify=False)
movies = res.json()
finds=movies['subjects']
for movie in finds:
# 依據下標對串列進行遍歷,并列印電影名
print(movie['title'])
和之前的代碼如出一轍,并且輸出結果也一樣,只包含了第一頁的所有電影:
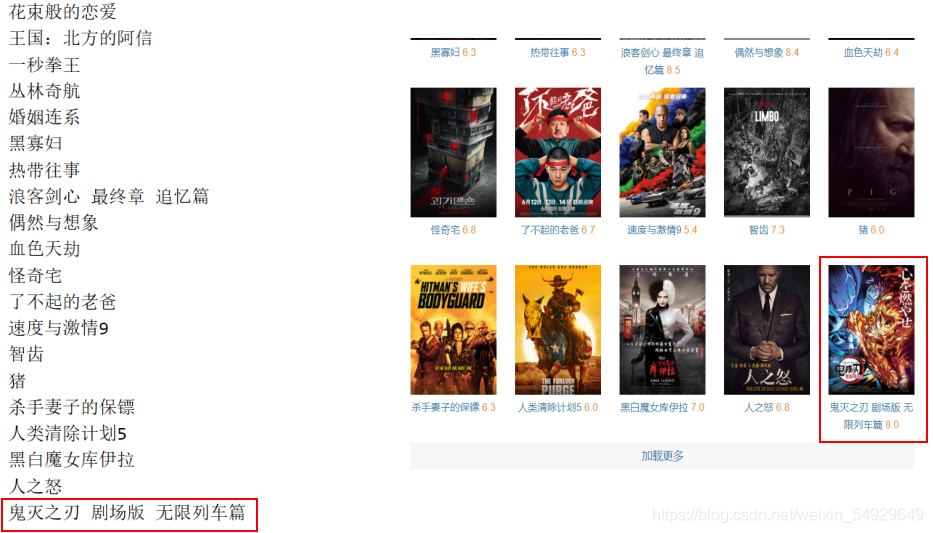
只有我們點擊加載更多,才能看到更多的影片內容,顯然,如果我們不斷的手動翻頁、找到新的請求、獲取新的網址、然后呼叫爬蟲爬取資訊,程序也很繁瑣,有沒有更簡單的方式呢?
這就要說到網頁的結構了,老規矩,先觀察:
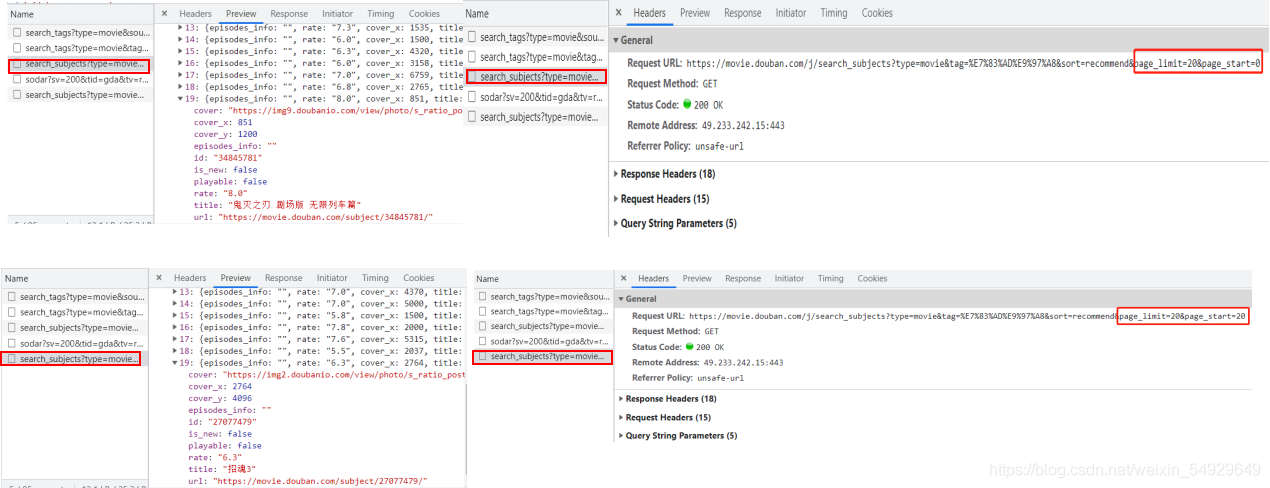
左側的圖片是點擊加載更多前后的包含影片名稱的XHR請求內容,右面是其對應的網址,大家仔細看發現什么不同了嗎?
下面,我們做一個關于這個網址的深度決議:
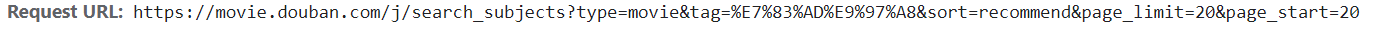
先看到這個網址,它是以“?”作為分隔,并且,大多數網站前半部分形如:https://xx.xx.xxx/xxx/xxx,這部分是我們所請求的地址,它會告訴服務器,我們想訪問哪里;而后半部分,多形如:xx=xx&xx=xxxxxx&xx=xx&……,這我們的請求所附帶的引數,它會告訴服務器,我們想要什么樣的資料,并且資料之間用“&”連接,
上述圖片中提到的不同就是page_start所對應的數字,這就為我們撰寫爬蟲提供了一個理論的可能,假如我們可以改變這個引數所對應的值,是不是就能實作自動翻頁了呢?這就涉及到帶引數請求資料了,
怎樣完成“帶引數請求資料”
上文提到,只要想辦法改掉page_start引數的值就好了,page_limit=20這個引數不難理解,代表了每加載一頁,就顯示20部電影,那么page_start引數應該也是以20為一個梯度,因此,對之前的代碼加以完善:
import requests
for i in range(3):
headers = {'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.79 Safari/537.36'}
res=requests.get('https://movie.douban.com/j/search_subjects?type=movie&tag=%E7%83%AD%E9%97%A8&sort=recommend&page_limit=20&page_start='\
+str(i*20),headers=headers,verify=False)
# i*20必須要轉換成字串形式才能正常運行
# 注:如果不用字串拼接的形式,Python會認為這是一段完整的字串,不會進行修改i的值并計算
movies = res.json()
finds=movies['subjects']
for movie in finds:
# 依據下標對串列進行遍歷,并列印電影名
print(movie['title'])
大家可以嘗試運行一下,這樣確實滿足了我們的需求,但是直接這樣修改連接引數還是比較麻煩,代碼也太長,不夠優雅,不要小看代碼簡介的威力,于大型專案來說,簡潔的代碼會很大程度的縮減維護的難度,
在解決這個問題之前,我們先觀察一下這個網址的特色:
首先,我們點擊Headers下General和Query String Parameters(以下簡稱QSP)前面的三角進行一個對比,不難發現,整個網址“?”后面的內容是:
type=movie&tag=%E7%83%AD%E9%97%A8&sort=recommend&page_limit=20&page_start=20
而QSP的內容是:

是不是前面的內容就是后面的內容用“&”連接起來的結果呢?也許會有小伙伴提出疑問,type對應的內容不一樣呀…
那請看下面這段代碼:
str_='熱門'
print(str_.encode('utf-8'))
# 輸出為:b'\xe7\x83\xad\xe9\x97\xa8'
這串東東也只是“熱門”的utf-8的編碼而已,
那么簡化代碼就可以從QSP入手,事實上,requests 模塊里的 requests.get() 提供了一個引數叫 params,可以讓我們用字典的形式,把引數傳進去:
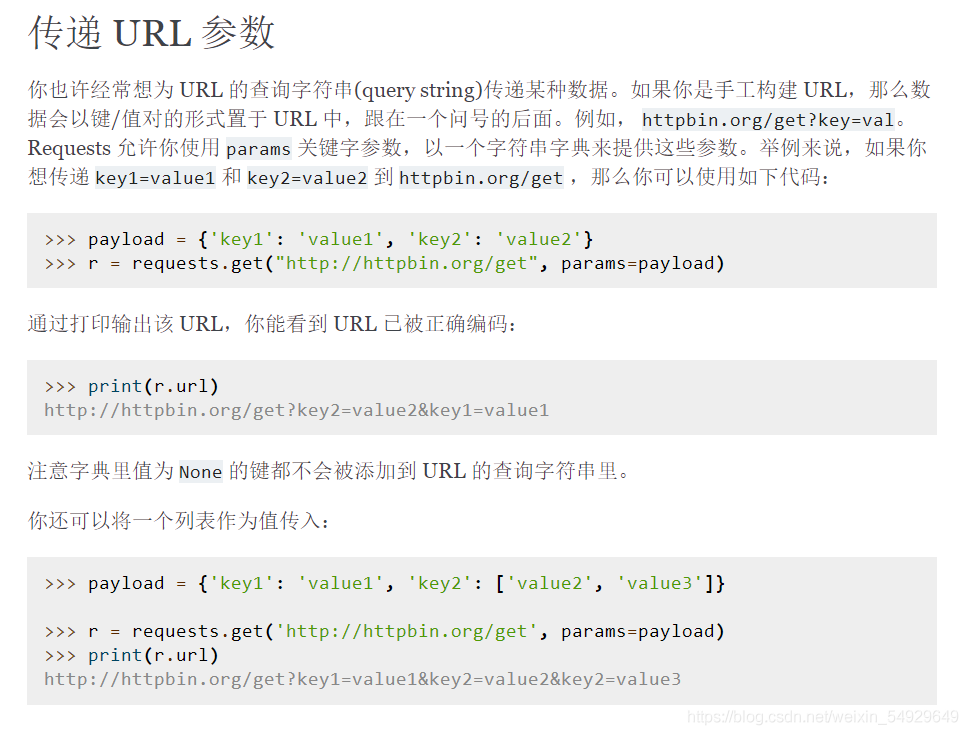
沒有看懂的小伙伴也沒有關系,下面我們一起來簡化代碼:
import requests
url='https://movie.douban.com/j/search_subjects'
# 標記請求地址
headers = {'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.79 Safari/537.36'}
for i in range(3):
p={'type': 'movie',
'tag': '熱門',
'sort': 'recommend',
'page_limit': '20',
'page_start': str(i*20)}
# 標記附帶引數
res=requests.get(url=url,params=p,headers=headers,verify=False)
movies = res.json()
finds=movies['subjects']
for movie in finds:
# 依據下標對串列進行遍歷,并列印電影名
print(movie['title'])
運行這段代碼,觀察結果:
這樣一來,我們就成功的爬取到了自己想要的全部內容了,其實,我們也可以通過改變page_limit這個引數改變每一頁顯示的電影數量,如果僅設定其為60,相當于現在一夜就能顯示之前三頁的內容,也就可以一口氣爬取原來三頁的內容,請大家自行嘗試,
說了這么多,還有一個疑問沒有解決,那就是這個headers是什么意思,我們先觀察一下Request Headers(請求頭):
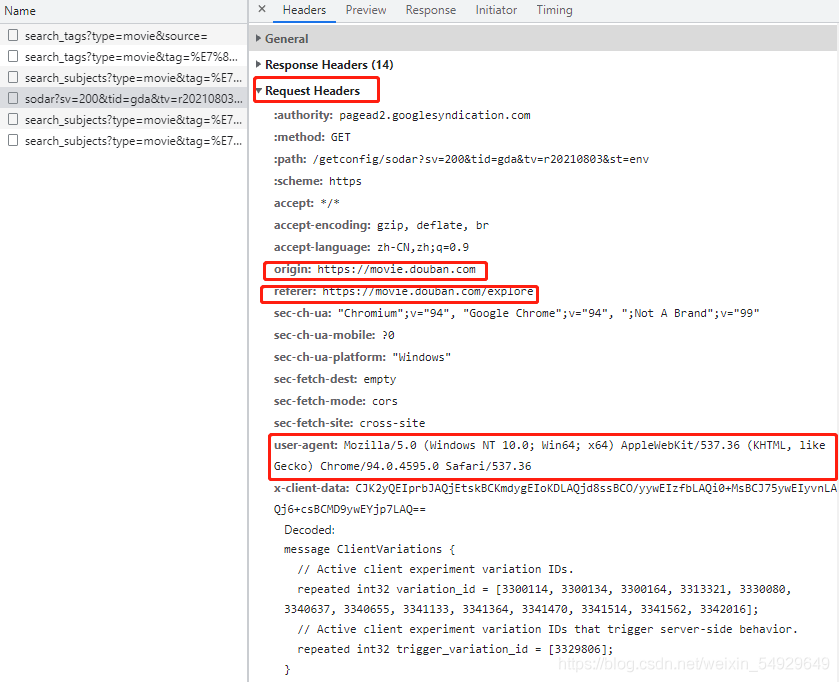
看看這里user-agent(用戶代理)的資訊,是不是也和我們代碼里的headers字典里的內容很像呀?其實,user-agent記錄的就是我的電腦系統資訊和瀏覽器(谷歌瀏覽器),在其之前,還有origin(源頭)和 referer(參考來源),記錄了這個請求最初的起源的頁面,referer會比origin攜帶的資訊更多些,我們也可以看看官方檔案:
如果不修改user-agent,當我們使用爬蟲爬取內容時,其會默認為python,這樣會被很多服務器識別出來,可能會造成無法爬取的結果,而對于爬取某些特定資訊,也要求你注明請求的來源,即 origin 或 referer 的內容,處理這些的方法也很簡單,只要將這些內容封裝到一個字典里就好了,例如:
import requests
url = 'https://pagead2.googlesyndication.com/getconfig/sodar'
headers = {
# 偽裝請求頭
'origin': 'https://movie.douban.com',
# 請求來源
'referer': 'https://movie.douban.com/explore',
# 請求來源
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4595.0 Safari/537.36'
# 標記請求從什么設備,什么瀏覽器上發出
}
p={...}
res=requests.get(url=url, params=p, headers=headers, verify=False)
...
三、再戰五月天
上面我們已經詳細決議了網站,現在,我們來繼續最開始的問題,怎么才能爬取五月天的全部歌名,當然,給大家的例子里,只爬取前三頁的資訊,學會的小伙伴可以自己嘗試,
首先看到“#”后面的資訊:page=1&searchid=1&remoteplace=txt.yqq.top&t=song&w=五月天
依照剛才講的內容,憑直覺這里好像改變page就能夠完成翻頁,但需要注意的是,一定要用谷歌瀏覽器打開,否則附帶引數可能會不太一樣:
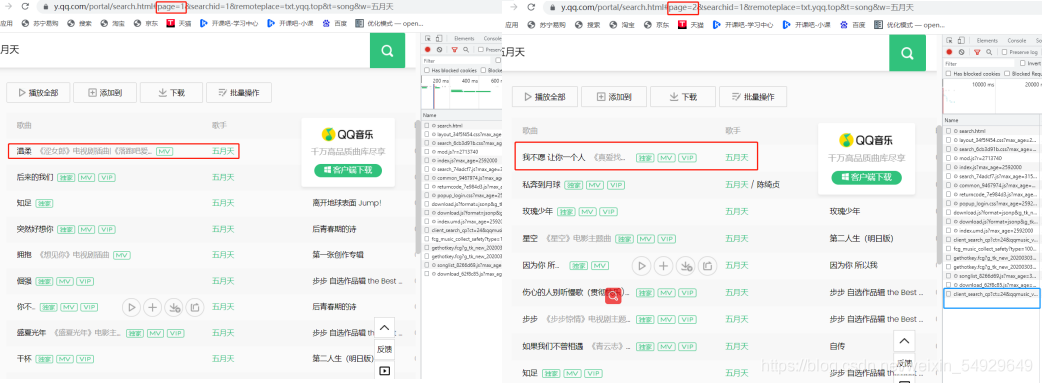
果然成功翻到了下一頁,并且還出現了個驚喜,藍色框圈出來了翻頁程序中多出的那個XHR請求,正是之前我們采用遍歷的方法尋找的包含歌單的請求,那這種方法尋找歌曲名豈不也是一個高效的方法~
回歸正題,既然改變page可以拿到下一頁的歌曲名,我們的代碼就可以著手了:
import requests
url = 'https://c.y.qq.com/soso/fcgi-bin/client_search_cp'
headers = {
'referer': 'https://y.qq.com/portal/search.html',
# 請求來源
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'
# 標記了請求從什么設備,什么瀏覽器上發出
}
for x in range(3):
params = {
'ct': '24',
'qqmusic_ver': '1298',
'new_json': '1',
'remoteplace': 'sizer.yqq.lyric_next',
'searchid': '94267071827046963',
'aggr': '1',
'cr': '1',
'catZhida': '1',
'lossless': '0',
'sem': '1',
't': '7',
'p': str(x + 1),
'n': '10',
'w': '五月天',
'g_tk': '1714057807',
'loginUin': '0',
'hostUin': '0',
'format': 'json',
'inCharset': 'utf8',
'outCharset': 'utf-8',
'notice': '0',
'platform': 'yqq.json',
'needNewCode': '0'
}
# 下載該網頁,賦值給 res
res = requests.get(url, params=params, headers=headers)
# 使用json來決議res.text
jsonres = res.json()
# 一層一層地取字典,獲取歌詞的串列
list_lyric = jsonres['data']['lyric']['list']
# list_lyric 是一個串列,lyric 是它里面的元素
for lyric in list_lyric:
# 以 content 為鍵,查找歌名
print(lyric['title'])
看看運行結果:

OK,滿足了,那么下面,我們再做一個嘗試,看看能不能爬取五月天歌曲的歌詞:
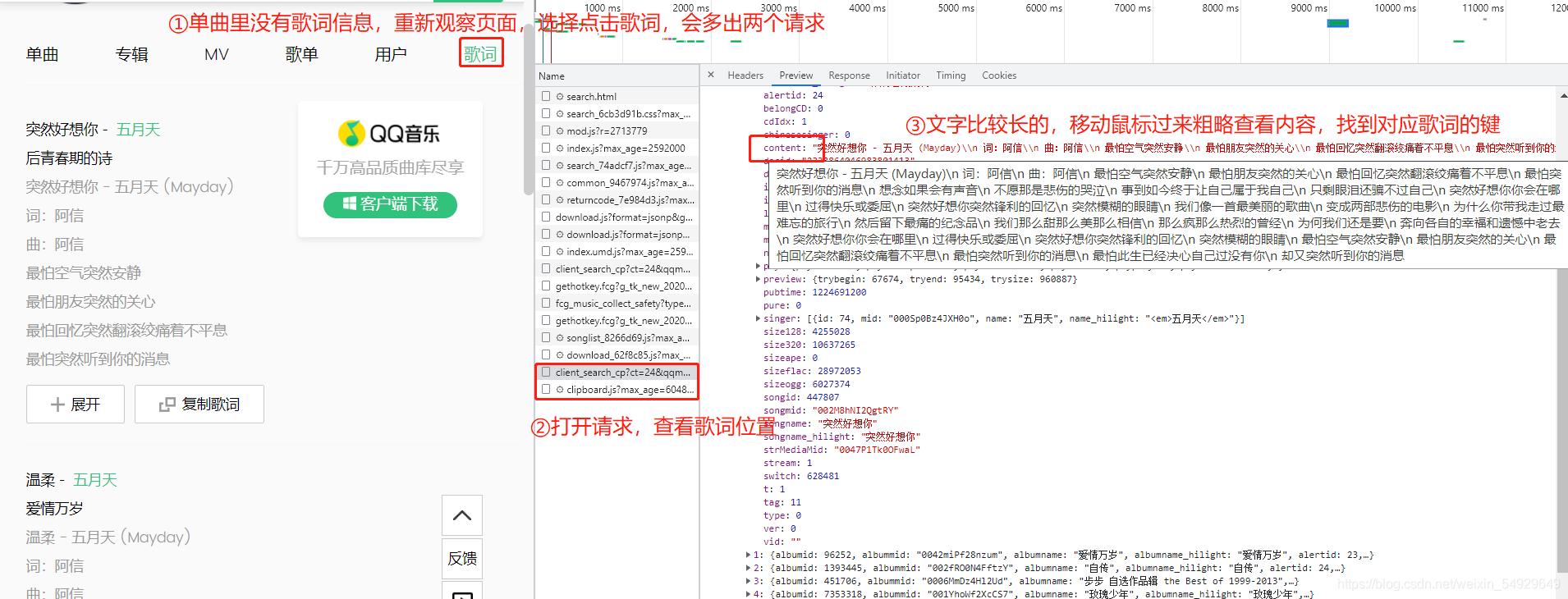
找到了歌詞的位置,我們可以進行爬取了:
import requests
url = 'https://c.y.qq.com/soso/fcgi-bin/client_search_cp'
headers = {
# 請求來源
'referer': 'https://y.qq.com/portal/search.html',
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
for x in range(3):
params = {
'ct': '24',
'qqmusic_ver': '1298',
'new_json': '1',
'remoteplace': 'sizer.yqq.lyric_next',
'searchid': '94267071827046963',
'aggr': '1',
'cr': '1',
'catZhida': '1',
'lossless': '0',
'sem': '1',
't': '7',
'p': str(x + 1),
'n': '10',
'w': '五月天',
'g_tk': '1714057807',
'loginUin': '0',
'hostUin': '0',
'format': 'json',
'inCharset': 'utf8',
'outCharset': 'utf-8',
'notice': '0',
'platform': 'yqq.json',
'needNewCode': '0'
}
# 下載該網頁,賦值給 res
res = requests.get(url, params=params, headers=headers)
# 使用 json 來決議 res.text
jsonres = res.json()
# 一層一層地取字典,獲取歌詞的串列
list_lyric = jsonres['data']['lyric']['list']
這部分的代碼和之前相似,不做過多介紹了(ps:本節后面的代碼也都需要拼接到這段后面),下面我們嘗試列印出來:
for lyric in list_lyric:
# 以 content 為鍵,查找歌詞
print(lyric['content'])
看看結果:

內容是正確了,但是太亂了,我們希望爬取的內容能夠正常換行,
1.split()方法
split()方法可以將字串進行切片,結果存放到一個陣列里,我們使用split()方法,最多有2個引數,使用方法如下:
# 假設str_是一個字串
str_.spilt('定義以某字符為切片點','替換數量')
# 沒有第一個引數則默認以空格或\n為切片點
# 將其洗掉并進行切片(如果二者都有都會洗掉)
# 沒有第二個引數,替換全部的內容
詳細的介紹大家可以參考Python split()方法,
知道了這種方法,我們對剛才的代碼修改一下:
for lyric in list_lyric:
# 以 content 為鍵,查找歌詞
con=lyric['content'].split()
for i in con:
print(i)
看看運行結果:

換行是對了,可是為什么還是有\n呢?那么我們插入print函式看看問題出在哪:
for lyric in list_lyric:
# 以 content 為鍵,查找歌詞
con=lyric['content'].split()
print(con)

看,我們剛剛看到的\n在字串中實際上是\n,想要得到我們預期的結果是必須要去掉\n,可見切片的方法還是比較麻煩的,
2.replace()方法
通過切片的方式,我們發現我們看到的\n實際上是\n,那么如果我們把這個字串中的\n替換成\n,那么所有的問題不就都解決了嗎~
下面我們就介紹一個可以替換內容的方法——replace():
res=str_.replace('需要被替換的內容','用于替換的內容')
# 假設str_是一個字串
那么通過這個方法是不是可以把\n替換成\n從而得到我們需要的結果呢?嘗試修改一下剛剛代碼:
for lyric in list_lyric:
# 以 content 為鍵,查找歌詞
print(lyric['content'].replace('\\n','\n'))
看看結果:

非常完美,這節的內容到此就結束了,希望大家學懂這兩個非常實用的方法,
四、存盤爬到的資料
之前的內容針對爬取網站有了更深入的介紹,相信大家已經能夠融會貫通,接下來我們處理爬取到的內容如何存盤的問題,
看過我之前內容的小伙伴應該熟悉讀寫以下兩種格式的檔案:.txt和.csv,實際上,這兩種格式都可以用記事本打開,.txt檔案是純文字的文本,而.csv是文字間以“ ,”隔開的文本,當然也可以用Excel打開,表格記憶體放以逗號連接的文字內容:
import csv
con=[['姓名','成績','年齡'],['張三',73,18],['李四',82,16],['王五',96,17],['趙六',68,19]]
with open("test.csv", 'w+', encoding='utf-8-sig',newline='') as test:
writer = csv.writer(test)
for i in con:
writer.writerow(i)
test.seek(0)
read = csv.reader(test)
for a in read:
print(a)
# 結果為:['姓名', '成績', '年齡']
# ['張三', '73', '18']
# ['李四', '82', '16']
# ['王五', '96', '17']
# ['趙六', '68', '19']
下面我們分別以記事本和和Excel檔案打開:

至于具體的操作大家可以參考我的博客編碼譯碼與檔案操作以及python的模塊呼叫,
這節的重點在于操作.xlsx檔案,這種檔案需要用Excel檔案打開,并且比.csv格式擁有更多的功能,也需要用到不同的模塊,操作.xlsx檔案則需要借助 openpyxl 模塊,這個模塊并非python自帶,所以需要我們自行安裝,安裝程序詳見爬蟲相關環境搭建,
學習.xlsx檔案的讀寫之前,先來了解一下這種格式檔案的基本結構,一個 Excel 檔案也稱為一個作業薄(workbook),每個作業薄里可以有多個作業表(wordsheet),當前打開的作業表又叫活動表:
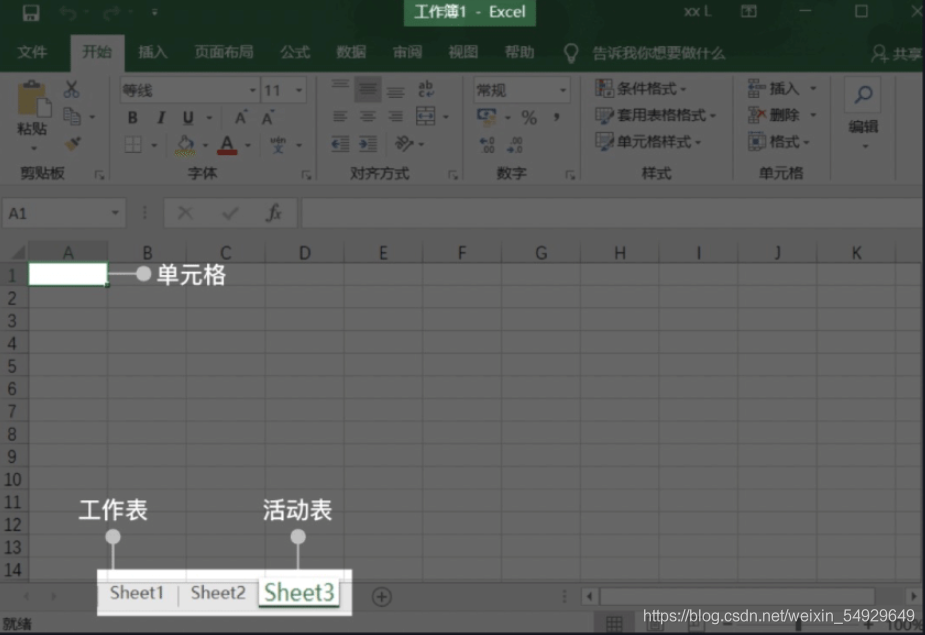
每個作業表里有行和列,通常我們會用列數+行數描述一個單元格(cell),如上圖中的A1,
清楚了基礎知識,我們來說一下.xlsx檔案的讀寫,.xlsx檔案的讀寫都明顯區別于.txt檔案和.csv檔案,我們先說先說寫入:
import openpyxl
wb= openpyxl.Workbook()
# 利用 openpyxl.Workbook() 函式創建新的 workbook(作業薄)物件,
# 即創建新的空的.xlsx檔案
sheet = wb.active
# wb.active 為獲取這個作業薄的活動表,通常是第一個作業簿
sheet.title = '練習檔案'
# 用 .title 給作業表重命名,
# 現在第一個作業表的名稱就會由原來默認的 “sheet1” 改為 "練習檔案"
sheet['A1'] = '單元格A1'
# 向單個單元格寫入資料,
# 寫入資料后指標會自動跳轉到下一行等待我們繼續寫入內容
score1 = ['math', 95]
# 創建串列,準備寫入
sheet.append(score1)
# 將剛剛的串列內容寫入新的一行
con=[['姓名','成績','年齡'],['張三',73,18],['李四',82,16]]
for i in con:
sheet.append(i)
# 繼續寫入二維串列
wb.save('test.xlsx')
# 保存修改的.xlsx檔案,并將其命名為“test”
wb.close()
# 關閉 Excel
那么穿插著代碼,我們已經學過了.xlsx檔案如何寫入了,接下來介紹如何讀取.xlsx檔案的內容,首先我們需要打開檔案,這個程序要用到 openpyxl 中的 load_workbook 方法:
wb=openpyxl.load_workbook('檔案名.xlsx')
這句代碼可以打開我們剛剛創建好的test.xlsx檔案,打開檔案之后我們才可以查看里面的內容,
緊接著我們需要打開作業表:
sheet = wb['作業表名稱']
打開練習檔案以后,我們就可以讀取里面的內容了,值得注意的一點是,這里的內容可以理解為以二維串列存盤的,但是我們可以直接以列+行的形式尋找到特定單元格內的元素,但是如果我們想要遍歷,依然需要兩個for回圈:
A1_value = sheet['想讀取的單元格'].value
# 查看單元格的內容
for con in sheet:
for i in con:
print(i,end=' ')
print()
# 遍歷整個作業表
我們把這些內容整理起來,查看一下剛剛新建的檔案吧:
from openpyxl import load_workbook
wb = load_workbook(filename='test.xlsx', read_only=True)
ws = wb['練習檔案']
A1_value = ws['A1'].value
print(A1_value)
print('--------------------')
for row in ws.rows:
for cell in row:
print(cell.value,end=' ')
print()
# Close the workbook after reading
wb.close()
# 結果為:單元格A1
# --------------------
# 單元格A1 None None
# math 95 None
# 姓名 成績 年齡
# 張三 73 18
# 李四 82 16
相信大家已經看懂了,只是這里介紹的方法是最簡單的一部分,如果想深入了解,大家可以查看官網進行學習,
接下來,我們實戰一下,來存盤另一位歌手——河圖的歌單和專輯資訊:
import requests
import openpyxl
con=[['歌曲名','專輯名']]
url = 'https://c.y.qq.com/soso/fcgi-bin/client_search_cp'
headers = {
'referer': 'https://y.qq.com/',
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'
}
for x in range(3):
params = {
'ct': '24',
'qqmusic_ver': '1298',
'new_json': '1',
'remoteplace': 'txt.yqq.song',
'searchid': '55102789769710202',
't': '0',
'aggr': '1',
'cr': '1',
'catZhida': '1',
'lossless': '0',
'flag_qc': '0',
'p': str(x + 1),
'n': '10',
'w': '河圖',
'g_tk_new_20200303': '5381',
'g_tk': '5381',
'loginUin': '0',
'hostUin': '0',
'format': 'json',
'inCharset': 'utf8',
'outCharset': 'utf-8',
'notice': '0',
'platform': 'yqq.json',
'needNewCode': '0',
}
res = requests.get(url, params=params, headers=headers)
jsonres = res.json()
list_lyric = jsonres['data']['song']['list']
# 以上代碼來自于上文
for lyric in list_lyric:
con.append([lyric['name'],lyric['album']['name']])
# 將歌曲名與專輯名存入二維串列
wb = openpyxl.Workbook()
# 利用 openpyxl.Workbook() 函式創建新的 workbook(作業薄)物件,
# 即創建新的空的.xlsx檔案
sheet = wb.active
# wb.active為獲取這個作業薄的活動表,通常是第一個作業簿
sheet.title = '河圖專欄'
# 將作業簿重新命名
for write in con:
sheet.append(write)
# 寫入歌曲資訊
wb.save('河圖.xlsx')
# 保存修改的.xlsx檔案,并將其命名為“河圖”
wb.close()
# 關閉 Excel
運行一下試試,看是否滿足我們的要求:
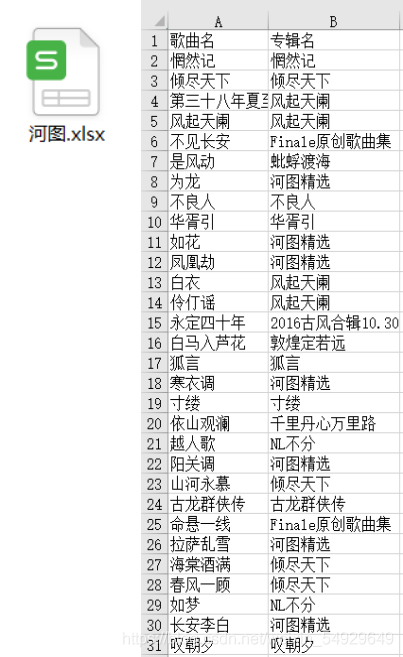
很棒!是不是像個自己點個贊呢~
這次的學習就到這里了,我是有理想的打工人,日后還會帶給大家更好的作品,期待和大家共同進步~
查看robots協議只需要在對應官網后面加入robots.txt即可, ??
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/292537.html
標籤:其他