回文鏈表
- Part I、回文結構
- 1、 生活中的回文
- 2、解讀“回文”
- Part II、 回文鏈表
- 第一想法
- 思考+進階
- 詳解
- Part III、總結也很重要
Part I、回文結構
1、 生活中的回文
處處飛花飛處處;潺潺碧水碧潺潺,
處處紅花紅處處;重重綠樹綠重重,
這兩句對聯兒您或許不熟悉,但是看起來、讀起來都格外地有意思,為什么呢?因為無論是正著讀,抑或是倒著讀,都是一樣的效果,不信?您在回去讀讀看,經典的回文還有一個近乎人人皆知的:上海自來水來自海上,
是不是很神奇?其實,回文不僅存在于文學,數學里也可以見到回文的影子,比如12321就是個回文數字,
生活中的回文還多的是,不過這并不是我們今天談論的重點,且往下看,
2、解讀“回文”
看了這么多例子,不難發現,回文結構最特殊的點在于它的前后對稱性,這種前后對稱性具體體現在:第一個對應倒數第一個,第二個對應倒數第二個,依次類推,
在編程中,我們接觸的最早的應該就是回文字串的判斷——
給定一個字串,讓你判斷它是否是回文結構,很簡單,我們只需要頭尾兩個指標,然后判斷它們指向的字符相不相等就可以了,
int left = 0, right = strlen(str);
while(left < right)
{
if(str[left] != str[right])
break;
left++;
right--;
}
是不是很easy?
而這一切的簡單都來源于字符陣列的隨機存盤性,我們可以很輕易地訪問陣列的任意一個成員,但是這放在鏈表中就行不通了,因為鏈表不支持隨機讀取,怎么辦呢?
Part II、 回文鏈表
我們先來看看回文鏈表長啥樣:

回文是指鏈表的資料具有前后對稱性,但是可惜的是,對于這種單向鏈表,我們沒辦法從最后一個結點開始往前遍歷,
第一想法
既然鏈表不能隨機讀取,那我就讓它變得能隨機讀取不就好了?怎么做呢?把它的每一個資料單獨拿出來存放在一個陣列中,前后同時遍歷,這樣不就可以了嗎?
bool isPalindrome(struct ListNode* head)
{
struct ListNode* cur = head;//用來遍歷鏈表
int len = 0;//記錄鏈表長度
while(cur)
{
len++;
cur = cur->next;
}//遍歷鏈表,確定鏈表長度,便于開辟陣列
int* p = (int*)malloc(len*sizeof(int));
int i = 0;
cur = head;
while(cur)
{
p[i++] = cur->val;
cur = cur->next;
}
int left = 0, right = len - 1;
while(left < right)
{
if(p[left] != p[right])
{
free(p);
return false;
}
left++;
right--;
}
free(p);
return true;
}
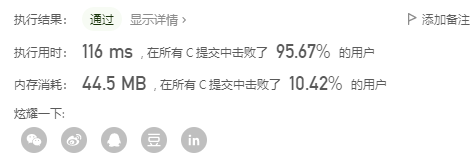
我們放到LeetCode上跑一下代碼后發現,速度還是很棒的,但是記憶體消耗上還是不盡人意,原因也很簡單:為了存放鏈表的資料,我們需要額外開辟一個陣列,這就帶來了O(n)的空間復雜度,
有沒有更好的方法呢?
思考+進階
鏈表不能隨機讀取確實是個問題,有沒有什么方法可以避開這個缺陷呢?
我們設想一個場景:如果我們有一張左右圖案對稱的紙,那么把它進行一個對折,它們是不是就能完美重合了?

我們把回文結構看成一張左右圖案對稱的紙,對它進行對折操作,而所謂的對折,其實就是以中間作為分界點,讓回文結構的右邊翻轉一下,跟左邊進行一 一 比較,那么顯然,它們是完全相同的兩個子結構,
如果放在鏈表中呢?我們就是以鏈表的中間節點為分界點,然后將鏈表的后半部分進行翻轉,得到兩個子鏈表——原鏈表的前一半和原鏈表后一半的翻轉,然后將這兩個子鏈表進行比較,
如果看過本系列前面的文章或者有刷題經驗,這其中有兩個關鍵字想必大家可能注意到了:1、中間結點
2、鏈表的翻轉
由于篇幅關系,有關找中間節點的函式和翻轉的函式我就不再贅述了,詳細內容可以看一下下面兩篇:鏈表的中間節點問題&反轉單鏈表
詳解
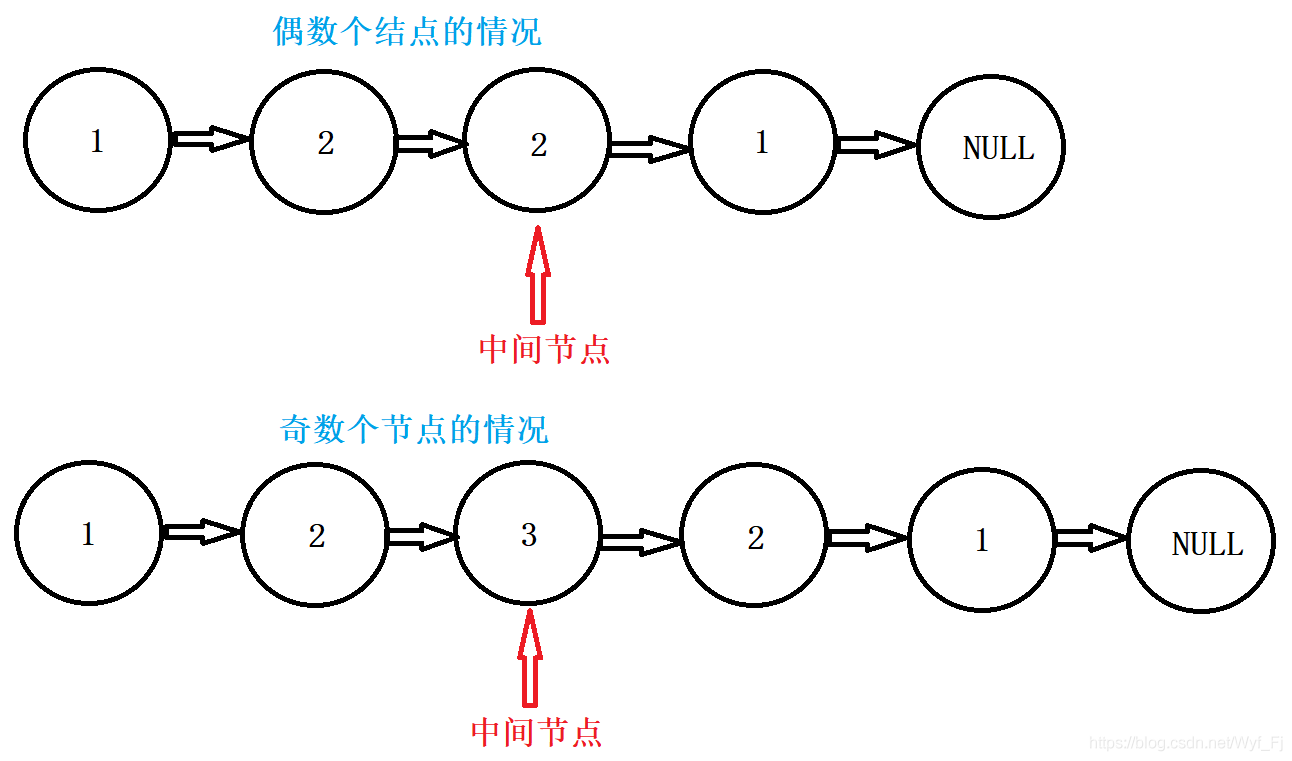
對于鏈表的中間節點,我們采取快慢指標的方法,如果有兩個中間節點(偶數個結點的情況),那么我們選擇回傳第二個中間節點,于是我們可以得到下面這幅圖:
而找中間節點的操作也相對easy:
struct ListNode* fast = head, * slow = head;
while (fast && fast->next)
{
slow = slow->next;
fast = fast->next->next;
}//找到中間節點使鏈表分割
我愿將其稱為:一步兩步解法(一步兩步似爪牙~)
中間節點的詳解在這里!!!不明白的可以看看哦
然后,我們將從中間節點開始往后的這部分鏈表進行整體翻轉,就會得到——
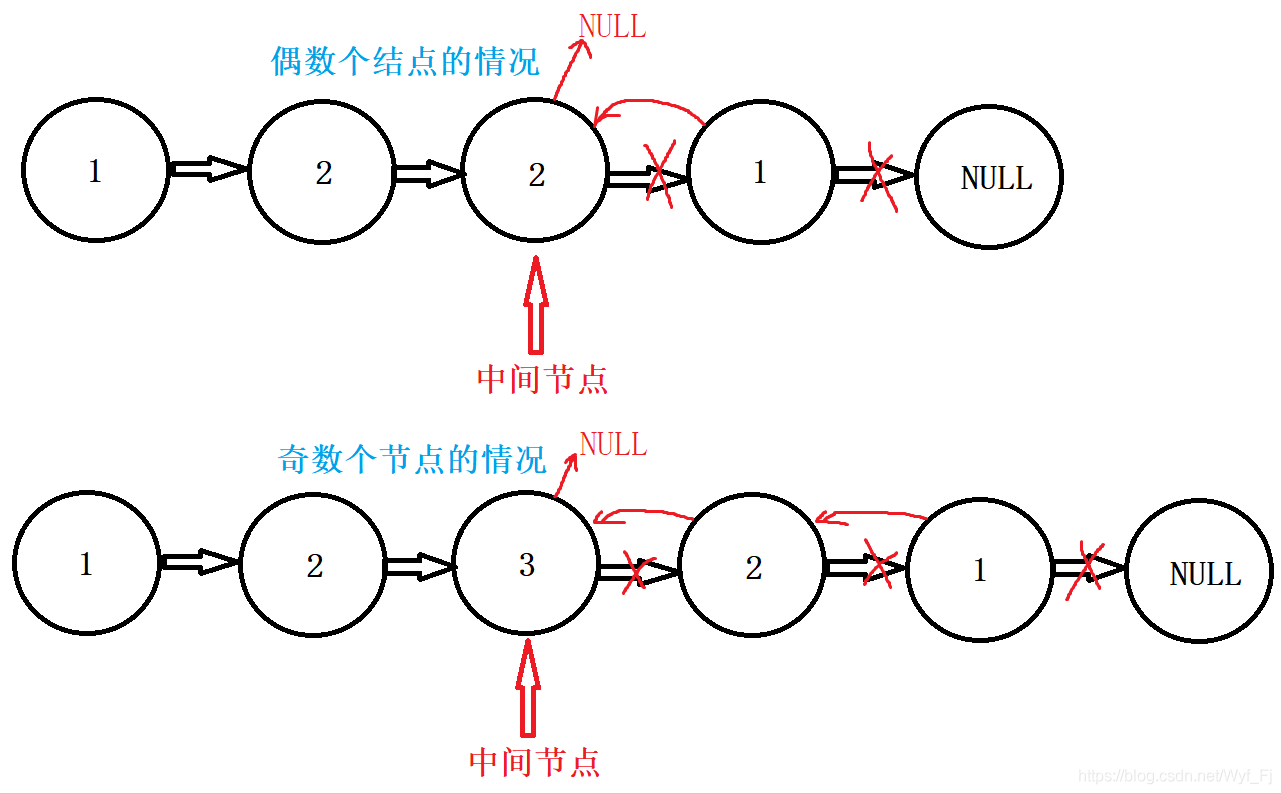
由于我們是將中間節點作為后半個子鏈表的頭,進行翻轉,于是原來的頭變成了現在的尾,
翻轉鏈表的代碼:
struct ListNode* reverseList(struct ListNode* head)
{
struct ListNode* cur = head, * newhead = NULL;
while (cur)
{
//頭插到新鏈表
struct ListNode* next = cur->next;
cur->next = newhead;
newhead = cur;
cur = next;
}
return newhead;
}
翻轉鏈表的詳解在這里!!!戳一戳
然后我們要做的就是進行兩個子鏈表的遍歷和比較,
bool isPalindrome(struct ListNode* head)
{
struct ListNode* fast = head, * slow = head;
struct ListNode* p1 = head, * p2 = NULL;
while (fast && fast->next)
{
slow = slow->next;
fast = fast->next->next;
}//找到中間節點使鏈表分割
p2 = reverseList(slow);//翻轉后半個鏈表
while(p2)
{
if(p1->val != p2->val)
{
return false;
}
p1 = p1->next;
p2 = p2->next;
}
return true;
}
注意,這里遍歷的控制條件要仔細分析一下:
對于偶數個結點的情況,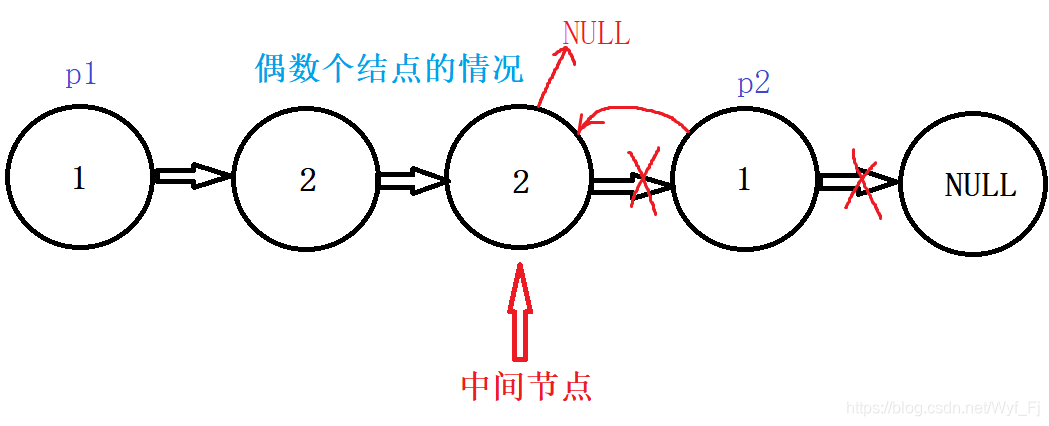
可以看到,前半個子鏈表是1->2->2->NULL,后半個翻轉后的子鏈表是:1->2>NULL,很明顯,這兩個鏈表是不一樣的,但我們我們可以選擇再設定一個prev指標記錄中間節點的前一個節點,然后讓它的next指向NULL,此時p1鏈表就變成了1->2->NULL,不過也沒必要,因為當我們的p2走到NULL時,p1也就走到了本應停下的位置:
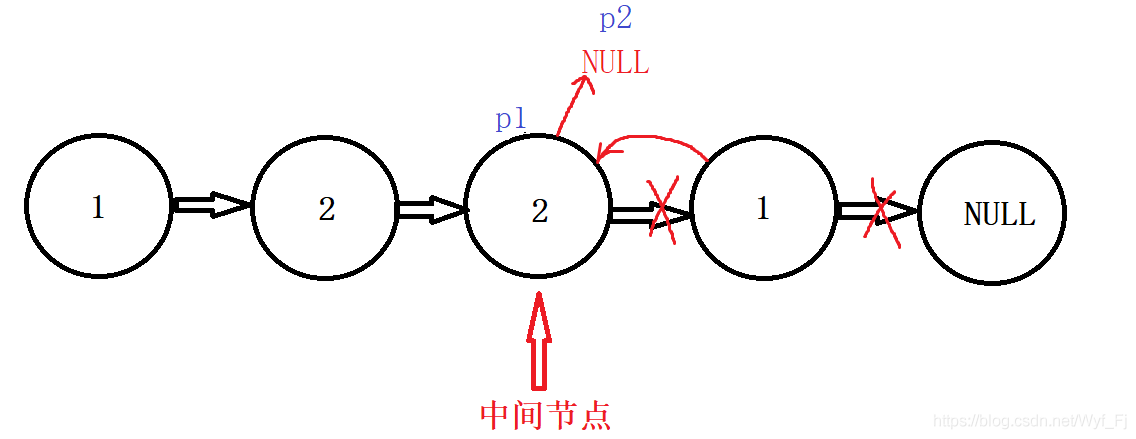
換句話說,p1、p2兩個鏈表的節點數都應該是原鏈表的一半,但這個時候p1比p2多了一個結點,沒關系,p2走到尾的時候p1也停下來就好咯,因此我們把p2!=NULL作為while的條件,
接下來看奇數個結點的情況:
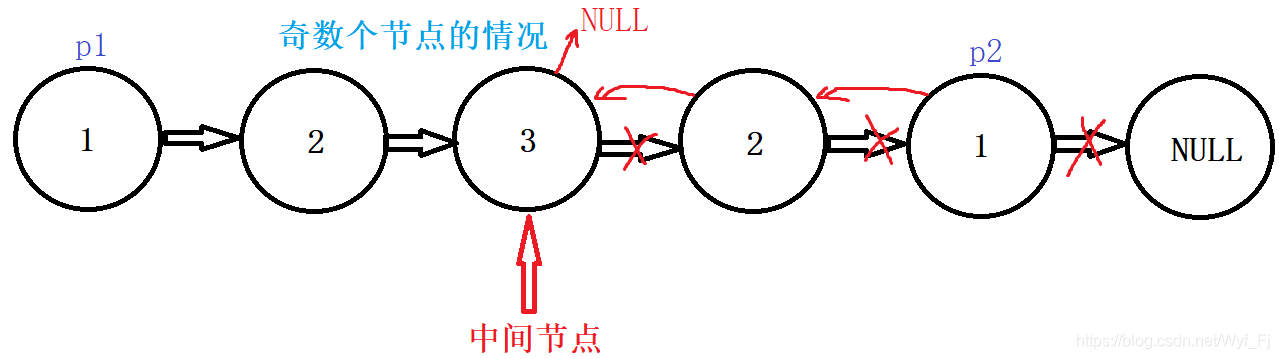
p1和p2都是1->2->3>NULL,那么遍歷的條件可以是p1!=NULL,也可以是p2!=NULL,
所以,兩種情況合并一下,就把p2!=NULL作為判斷條件了!
Part III、總結也很重要
對于回文鏈表,我們用最樸實的想法實作了第一種解法,而受益于折紙思想,我們又完成了第二種找中間+翻轉查重合的方法,
可能一開始我們想不到這些,但是隨著時間的積累,很多優質的解法都會刻入你的DNA!
最后,我們先把代碼匯總一下:
struct ListNode* reverseList(struct ListNode* head)
{
struct ListNode* cur = head, * newhead = NULL;
while (cur)
{
//頭插到新鏈表
struct ListNode* next = cur->next;
cur->next = newhead;
newhead = cur;
cur = next;
}
return newhead;
}
bool isPalindrome(struct ListNode* head)
{
struct ListNode* fast = head, * slow = head;
struct ListNode* p1 = head, * p2 = NULL;
while (fast && fast->next)
{
slow = slow->next;
fast = fast->next->next;
}//找到中間節點使鏈表分割
p2 = reverseList(slow);
while(p2)
{
if(p1->val != p2->val)
{
return false;
}
p1 = p1->next;
p2 = p2->next;
}
return true;
}
歡迎關注博主,定期分享各種題解!讓我們共同進步!
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/292769.html
標籤:其他
上一篇:詳解c語言函式堆疊幀的創建和銷毀