文章目錄
- 指標
- 指標定義
- 記憶體劃分
- 指標與指標變數
- 總結
- 指標大小
- 指標型別
- 指標解參考方面
- 指標±正數方面
- 總結
- 野指標
- 野指標定義
- 野指標成因
- 如何規避野指標
- 指標運算
- 指標`+` `-`整數
- 指標`-`指標
- 指標關系運算
- 指標和陣列
- 二級指標
- 型別中“*”的含義
- 多級指標解參考操作
- 指標陣列
- 指標陣列定義
- 指標陣列使用
指標
這次的指標(Pointer),比初識C語言里的指標更深入一點,但也不是全部內容,因為后面的進階部分還會講到,
指標定義
記憶體劃分
記憶體是一塊很大的空間,由一個個小的占一位元組的記憶體單元組成,每一個記憶體單元對應系結著一個地址,即對記憶體單元的編號,像是身份證號一樣,通過地址我們就可以唯一確定地找到一塊記憶體單元,如:

指標與指標變數
地址直接指向了存盤在記憶體的另一個值,由于能通過地址找到所需的變數單元,地址指向了唯一確定的記憶體單元,故將地址形象化稱為指標,
現在我們定義了一個整型變數a,在記憶體中給他分配了4個位元組,由此我們也能看出定義變數的本質就是在記憶體中分配空間,變數a的第一個位元組的地址為0x0012ff40,它就代表變數a的地址,

那什么是指標變數呢?現在我們去定義一個“指標”指向一個變數a,
我們用&a把變數a的地址取出來,再放到變數pa中,由于變數pa中存的是地址,所以用型別int *去定義變數pa,
int * pa = &a;
這樣變數pa也是真實存在于記憶體中的一個變數,其中存盤的是地址編號,這樣的變數叫指標變數,
總結
- 指標即地址,地址即指標,
- 指標變數是存放地址的變數,其中的內容都被當作地址處理,
指標變數經常被人們簡稱為指標,我們要去從語境中區分他人說的是指標還是指標變數,
指標大小
- 一個記憶體單元有多大?
- 地址是如何進行編號?
首先我們分析一下,記憶體單元的大小為什么是一個位元組,
對于32位機器,即32根地址線,每一個地址線在尋址時產生的電信號(正電/負電)轉化為數字信號 ,正點就是1,負電就是0,更通俗來說,通電即為1,沒通電就是0,
那么32根地址線有多少種01組合呢,高中的排列知識就可以說明共有 2 32 2^{32} 232 種01序列,即從32個全0到32個全1,
00000000 00000000 00000000 00000000
00000000 00000000 00000000 00000001
… …
11111111 11111111 11111111 11111110
11111111 11111111 11111111 11111111
當然64位機器,就有 2 64 2^{64} 264 種排列組合,
既然我們32位機器上,有 2 32 2^{32} 232 種排列組合,
每一個二進制序列就是一個記憶體單元的編號,那么就有 2 32 2^{32} 232 個記憶體單元可供使用,轉化為十進制就是 4 , 294 , 967 , 296 4,294,967,296 4,294,967,296,
如果每個記憶體單元是1bit大小的話,那么除以8就有 536 , 870 , 912 536,870,912 536,870,912個byte,就有 524 , 288 524,288 524,288個kb,再除以1024就是我們熟悉的 512 512 512個MB,約含半個GB,這樣的話一個
char型別的變數就需要8個地址,是不是太浪費了?如果每個記憶體單元是1個byte的話,轉化到最后正好是4個GB,這就正好了,最早期的時候只有1個或者2個GB,
指標變數用來存盤地址,一個地址就是32個位元位,那么正好需要4個位元組,所以無論是什么型別,指標變數的大小都是4個位元組,
當然,32位機器指標的大小為4個位元組,64位機器下指標大小為8個位元組,
指標型別
int a = 10;
int * pa = &a;
*代表pa是指標int代表pa所指向的變數型別為int
變數有不同的型別,很明顯指標變數也有不同的型別,可是依據前面的推導,不管什么型別的指標變數,32位平臺下大小都是4個位元組,那指標的型別有什么作用呢?體現在兩個方面,一是指標解參考,二是指標加減整數,
指標解參考方面
int a = 0x11223344;
int* pa = &a;
*pa = 0;
我們先創建一個變數a,并用指標變數pa指向它,然后再對pa解參考把a置為0,我們可以從記憶體中看到:
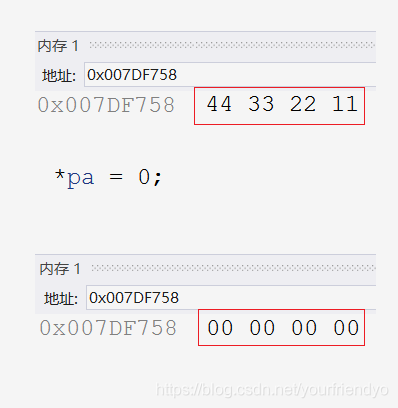
這個結果大家都能猜到,那么接下來我們對指標變數的型別稍作修改,把int * pa改成char * pa,

這樣的話,區別就有了,
int*的指標訪問并修改了4個位元組的內容,而char*的指標只修改了1個位元組的內容,
指標±正數方面
現在我們再用不同型別的指標分別指向同一個變數,對其+1,如:
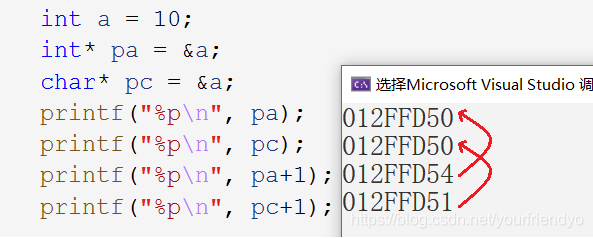
可以看到
int*型的指標+1向后跳過了4個位元組,char*型的指標+1向后跳過了1個位元組,
總結
指標型別決定了:
- 指標解參考操作時能夠訪問的位元組(記憶體大小),
- 指標
±整數時能跳過幾個位元組(步長),
這樣的話,我們用不同型別的指標,就可以實作跳過不同的位元組,繼而更細致的訪問變數內容,如:
int arr[10] = { 0 };
//1.
int* pa = arr;
//2.
char * pa = arr;
for (int i = 0; i < 10; i++)
{
*(pa + i) = 1;
}
兩種不同的指標,帶來不同的效果,如圖所示:
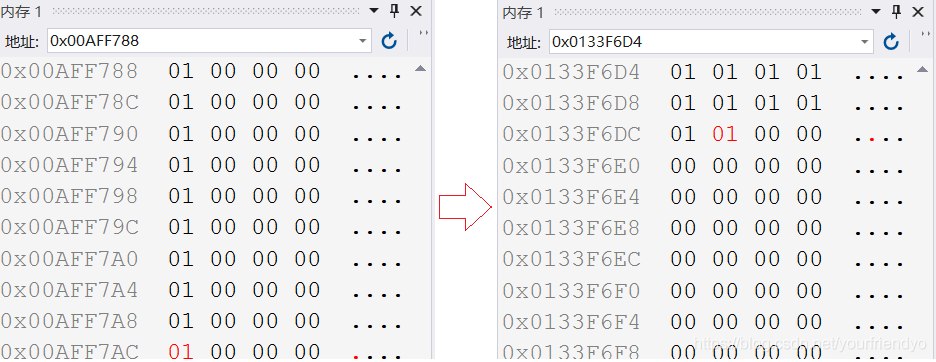
第一種是一個整型一個整型訪問陣列元素,第二個是一個字符一個字符地訪問陣列,如:

野指標
野指標定義
指向不明確的位置(隨機的,不正確的,無明確限制的)的指標是野指標,
不正確的位置:指向了沒有分配的記憶體空間,造成越界訪問,
野指標成因
-
指標未初始化
int* p;//未初始化 *p = 20; -
指標越界訪問
int arr[10] = { 0 }; int* p = arr; for (int i = 0; i <= 10; i++)//越界訪問 { *(p + i) = i; }
越界可以,但不能越界訪問^_^,
-
例題
int* test(){ int a = 10; return &a; } int main(){ int* p = test(); printf("%d\n", *p);//野指標越界訪問 return 0; }
這里的
a是test函式中定義的,出了作用域就會被銷毀,所以我們這里列印*p就屬于越界訪問,但我們這執行程式仍能發現結果是10,這是為什么呢?
原因是
a變數所占的空間回收后作業系統還未將其銷毀,編譯器對其作一次保留,而且傳參先行于呼叫,所以再呼叫printf函式之前就*p就已經替換為10,
- 我們稍作修改,在列印
*p的前面再呼叫一次printf函式,如:int* test(){ int a = 10; return &a; } int main(){ int* p = test(); printf("hehe\n"); printf("%d\n", *p); return 0; }
這次呼叫
printf函式,使得原來分配給a的空間被覆寫,又分配給了printf函式,堆疊區的使用習慣就是壓堆疊彈堆疊(如果不了解的話可以去看看堆疊區空間的開辟和銷毀),
-
那如果我們把列印
printf("%d\n", *p);改為賦值陳述句*p = 20;的話,如:int* test(){ int a = 10; return &a; } int main(){ int* p = test(); *p = 20;//訪問非法記憶體 return 0; }
編譯器就直接檢測出這塊空間是非法記憶體,就會直接報錯,
- 指標指向空間已釋放
從上面的例子也可以看出,指標p指向test函式原先占有的已被釋放的記憶體空間,這也是一件非常危險的事情,必然會成為野指標,動態記憶體開辟的地方也會將指向動態開辟的記憶體的指標free掉,這也是防止其成為野指標,
如何規避野指標
-
明確指標初始化,確定指向
int* p = &a; int* p =NULL;//不知道該指向何處時,置為空NULL -
謹防指標越界
-
指標指向空間釋后,立即置為
NULL -
避免函式回傳區域變數地址
-
檢查指標有效性
空指標不可解參考,
if(p != NULL){
*p=20;//檢驗不為空指標,再使用
}
或者直接用
assert斷言函式,assert(p)判斷指標p是否為空指標,如有誤回傳錯誤資訊,
指標運算
當然指標的解參考操作也算是指標的運算,但我們這里僅考慮一下三類,畢竟指標解參考是基本運算,
指標加減整數所得還是指標,就像日期加天數后還是日期,而指標減指標所得為元素個數,就像日期減日期為天數,從這個例子也可以看出來指標加指標是沒有意義的,
指標+ -整數
float values[N_VALUE];
float* vp = values;
for (vp = &values[0]; vp < &values[N_VALUE];)
{
*vp++=0;
}
上述代碼,依靠指向陣列的指標回圈遍歷置零,
-
回圈體內,
vp先++后*,盡管++的優先級比*要高,但是后置++是先使用再++,所以仿佛是對指標先解參考再
++的, -
float型別指標的加一,跳過一個float型別的長度,故跳到下一個元素,不論指標是什么型別,指標
++,都是跳過一個型別的長度, -
當
vp指向陣列最后一個元素其后的地址,不滿足條件,結束回圈,該地址雖不屬于陣列,但僅是用所判斷大小的條件(地址有高低),沒有訪問該地址的內容,所以不算越界訪問,
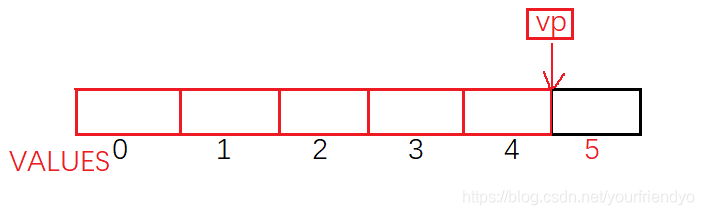
本例子涉及到了兩個指標的運算:指標加減整數,也就是指標++,指標的關系運算,指標相互比大小作判斷條件,
指標加整數即指標向后跳整數個型別大小的位元組,再來看看指標減整數,

如圖所示,指標p-1就是指標p向前跳一個型別的大小,
指標加減整數即指標向后或向前跳過整數個型別大小的位元組,
指標-指標
指標可以減去指標,代表兩個地址之間的”差距“,那可以用指標加上指標嗎?相當于兩個地址相加是沒有意義的,
int arr[] = { 1,2,3,4,5,6,7,8,9,10 };
printf("%d\n", &arr[9] - &arr[0]);
這題答案是什么?是36還是9?
答案是9,語法規定指標-指標,得到的是兩地址之間的元素個數(下標相減),
當然兩地址間的元素個數,也可以理解為所占位元組大小除以型別大小,
那要是在不同的陣列中運算呢?如:
int arr[] = { 1,2,3,4,5,6,7,8,9,10 };
char ch[] = { '1','2','3' };
printf("%d\n", &arr[9] - &ch[0]);
編譯器不會報錯,因為沒有語法錯誤,但是所得到的數字即元素的個數,該元素是int型別還是char型別的呢?所以這數字根本就是沒有意義的,
所以我們得到指標相減運算的前提:是兩指標指向同一塊空間,如同一個陣列,
-
指標
-指標的前提:是兩指標指向同一塊空間, -
指標
-指標,得到的數字的絕對值是兩地址之間的元素個數,
應用:實作strlen函式
int my_strlen(const char* s){
char* begin = s;//標記開頭
while(*s++);//s先++再判斷是否為\0
return s - begin - 1;//指標相減
}
指標關系運算
將指標加減整數代碼例子拿過來稍作修改,
//1.
for(vp = &values[N_VALUE];vp > &values[0];){
*--vp = 0;
}
把陣列后面的空間,也想象成陣列內容根據陣列下標拿取是可以的,畢竟陣列在記憶體中是連續存放的,從后往前遍歷,先
--再解參考,就不會造成陣列越界訪問,我們再稍作修改:
//2.
for(vp = &values[N_VALUE-1];vp >= &values[0];vp--){
*vp = 0;
}
最后一次遍歷時,指標指向
values[0]前面的一塊地址,當然再回來判斷時不滿足條件,就退出回圈,
但是我們要盡量選擇第一種方法,因為C語言標準規定:允許指向陣列的指標,與指向陣列最后元素之后的記憶體位置進行比較,但不允許與首元素之前的位置進行比較,如圖:
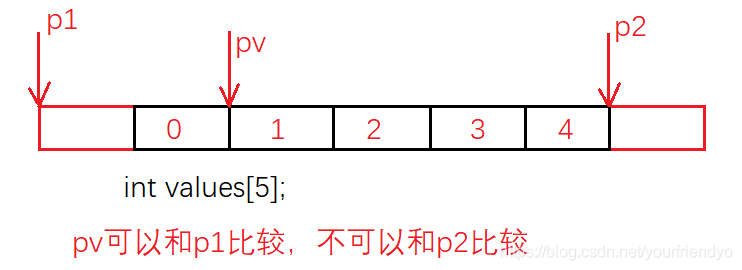
原因是編譯器可能會在陣列前的位置存盤和陣列有關的資訊,如陣列元素個數等,這樣可能會影響到程式的運行,
指標也是地址,地址是編號是數字,就可以進行比較大小,指標的關系運算就是比較大小,
指標和陣列
指標和陣列之間有什么區別,有什么聯系嗎?
-
陣列是一個相同型別元素的集合,其中元素存放在連續的空間中,陣列的大小取決于元素型別和元素個數,
-
指標存盤地址,是一個變數,指標的大小固定為4 (32bit) / 8 (64bit),
int arr[10] = { 0 };
printf("%p\n", arr);//0x0012ff40
printf("%p\n", &arr[0]);//0x0012ff40
由此可得:陣列名就是陣列首元素的地址,
ps:以下兩種情況陣列名代表整個陣列,除該兩種情況外,陣列名都代表首元素地址,
sizeof(arr)&arr
陣列名可以作為地址,存放在指標變數中,我們就可以通過指標訪問陣列,
事實上,陣列作函式形參時,都是降級優化為指標的,一整個陣列是傳不過去的,不過這也是后話了,
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
int* p = arr;
for (int i = 0; i < sz; i++)
{
printf("&arr[%d] = %p <===> p+%d = %p\n", i, &arr[i], i, p + i);
}

也就是說,p+i其實就是陣列arr下標為i的地址,本質上二者就是一回事,
二級指標
顧名思義,二級指標就是用來存放一級指標的地址的,通過二級指標也可以訪問到一級指標,
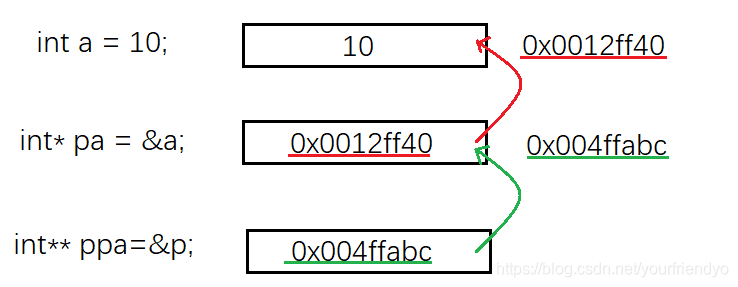
首先創建了一個變數
a,存了10,所以它的型別為int,變數的地址為0x0012ff40,然后取出a的地址,再創建了一個新的變數
pa,并把&a存了進去,所以它的型別為int*(一級指標),變數的地址為0x004ffabc,最后又創建了一個新的變數
ppa,把&p存了進去,所以它的型別為int**(二級指標),
通過ppa里p的地址,可以找到p,通過p里a的地址,也可以找到a,
型別中“*”的含義

灰框中的*代表變數是一個指標變數,
- 一級指標
p前面的int表示p指向的物件a是int型的, - 二級指標
pp前面的int*表示pp指向的物件p的型別是int*型的, - 三級指標
ppp前面的int**表示ppp指向的物件pp的型別是int**型的,
多級指標解參考操作
*p = 1;
* *pp = 2;
* * *ppp = 3;
如上述代碼所示,我們一級一級分析,
- 對一級指標
p解參考*p,找到a, - 對二級指標
pp解參考*pp,找到p,再解參考**pp,找到a, - 對三級指標
ppp解參考*ppp找到pp,再解參考**ppp,找到p,再解一次參考***ppp,找到a,
所以可以看出,有多少級指標,就要解多少次參考,
指標陣列
指標陣列定義
在回答何為指標陣列前,我們先來看何為整型陣列,何為字符陣列,
int arr[10] = {0};
//整型陣列 - 存放整型變數的陣列
char ch[10] = {'0'};
//字符陣列 - 存放字符變數的陣列
通過類比整型陣列和字符陣列,可以得到指標陣列就是存放指標變數的陣列,
陣列名前的型別
int和char表示,陣列元素的型別是int或者char,所以指標陣列名前的型別名就是int*或者是char*,如:
//整型指標陣列
int* parr[10];
//字符型指標陣列
char* pch[5];
對于整型指標陣列,每個元素都是整型變數的地址,對于字符型指標陣列,每個元素都是字符型變數的地址,由此也可以看出,指標陣列的大小,僅取決于陣列元素個數,

指標陣列使用
int arr[] = { 10,20,30 };
int* parr[5] = {NULL};
//輸入
for (int i = 0; i < 3; i++)
{
parr[i] = &arr[i];
}
//輸出1.
for (int i = 0; i < 3 ; i++)
{
printf("%d ", *parr[i]);
}
//輸出2.
for (int i = 0; i < 3; i++)
{
printf("%d ", **(parr+i));
}
- 切記要么初始化要么指定大小,指標陣列記得內容初始化為空指標,
- 指標陣列遍歷陣列元素列印時,記得要解參考,用陣列名
+i遍歷陣列元素時,就要解兩層參考,
目前對應指標陣列就理解到這個層次,后續還會學習指標的進階,
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/292781.html
標籤:其他