導讀
篇幅較長,干貨十足,閱讀需要花點時間,全部手打出來的字,難免出現錯別字,敬請諒解,珍惜原創,轉載請注明出處,謝謝~!
學習之前,先附上一張知識腦圖,百度上找噠~~~


NoSql介紹與Redis介紹
什么是Redis?
Redis是用C語言開發的一個開源的高性能鍵值對(key-value)記憶體資料庫,
它提供五種資料型別來存盤值:字串型別、散列型別、串列型別、集合型別、有序型別,
它是一種NoSql資料庫,
什么是NoSql?
- NoSql,即Not-Only Sql(不僅僅是SQL),泛指非關系型的資料庫,
- 什么是關系型資料庫?資料結構是一種有行有列的資料庫,
- NoSql資料庫是為了解決高并發、高可用、高可擴展、大資料存盤問題而產生的資料庫解決方案,
- NoSql可以作為關系型資料庫的良好補充,但是不能替代關系型資料庫,
NoSql資料庫分類
鍵值(key-value)存盤資料庫
- 相關產品:Tokyo Cabinet/Tyrant、Redis、Voldemort、Berkeley Db等
- 典型應用:記憶體快取,主要用于處理大量資料的高訪問負載
- 資料模型:一系列鍵值對
- 優勢:快速查詢
- 劣勢:存盤的資料缺少結構化
列存盤資料庫
- 相關產品:Cassandra、Hbase、Riak
- 典型應用:分布式的檔案系統
- 資料模型:以列簇式存盤,將同一列資料存在一起
- 優勢:查找速度快,可擴展性強,更容易進行分布式擴展
- 劣勢:功能相對局限
檔案型資料庫
- 相關產品:CouchDB、MongoDB
- 典型應用:web應用(與key-value類似,value是結構化的)
- 資料模型:一系列鍵值對
- 優勢:資料結構要求不嚴格
- 劣勢
圖形(Graph)資料庫
- 相關資料庫:Neo4J、InfoGrid、Infinite、Graph
- 典型應用:社交網路
- 資料模型:圖結構
- 優勢:利用圖結構先關演算法
- 劣勢:需要對整個圖做計算才能得出結果,不容易做分布式的集群方案,
Redis歷史發展
2008年,意大利的一家創業公司Merzia推出了一款給予MySql的網站實時統計系統LLOOGG,然而沒過多久該公司的創始人Salvatore Sanfilippo便對MySql的性能感到失望,于是他決定親力為LLOOGG量身定做一個資料庫,并于2009年開發完成,這個資料庫就是Redis,
不過Salvatore Sanfilippo并不滿足只將Redis用于LLOOGG這一款產品,而是希望更多的人使用它,于是在同一年Salvatore Sanfilippo將Redis開源發布,
并開始和Redis的另一名主要的代碼貢獻者Pieter Noordhuis一起繼續著Redis的開發,直到今天,
Salvatore Sanfilippo自己也沒有想到,短短的幾年時間,Redis就擁有了龐大的用戶群體,Hacker News在2012年發布一份資料庫的使用請款調查,結果顯示有近12%的公司在使用Redis,國內如新浪微博、街旁網、知乎網、國外如GitHub、Stack、Overflow、Flickr等都是Redis的用戶,
VmWare公司從2010年開始贊助Redis的開發,Salvatore Sanfilippo和Pieter Noordhuis也分別在3月和5月加入VMware,全職開發Redis,
Redis的應用場景
- 記憶體資料庫(登錄資訊、購物車資訊、用戶瀏覽記錄等)
- 快取服務器(商品資料、廣告資料等等)(最多使用)
- 解決分布式集群架構中的Session分離問題(Session共享)
- 任務佇列,(秒殺、搶購、12306等等)
- 支持發布訂閱的訊息模式
- 應用排行榜
- 網站訪問統計
- 資料過期處理(可以精確到毫秒)
Redis安裝及配置
- 官網地址:https://redis.io/
- 中文官網地址:http://www.redis.cn
- 下載地址:http://download.redis.io/releases/
Linux環境下安裝Redis
注:將下載后的Redis拖進Linux需要安裝下,VMware Tools,參考鏈接
將下載后的Redis拖進linux
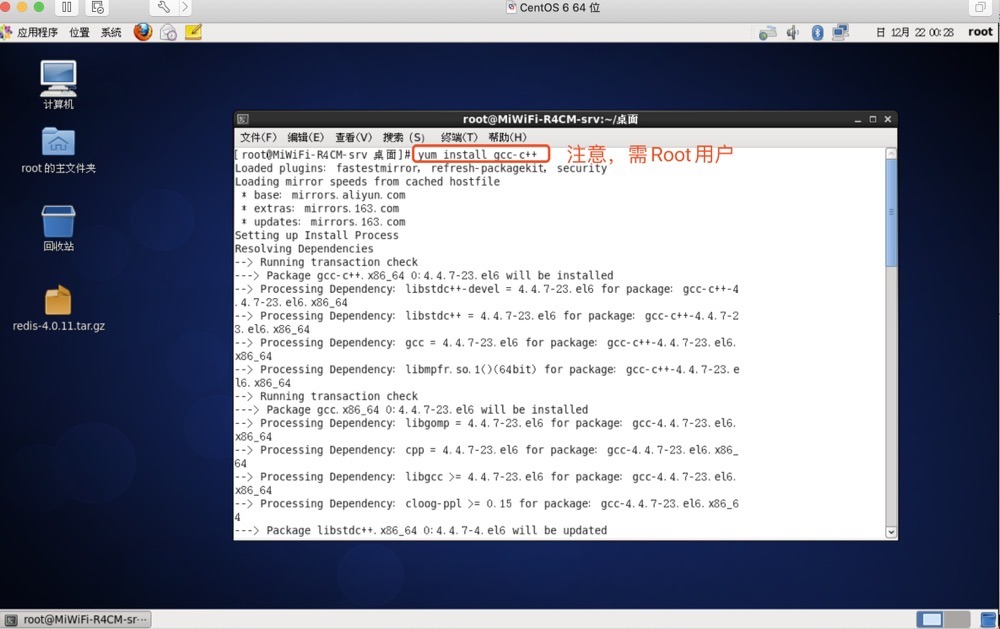
安裝C語言需要的GCC環境
yum install gcc-c++
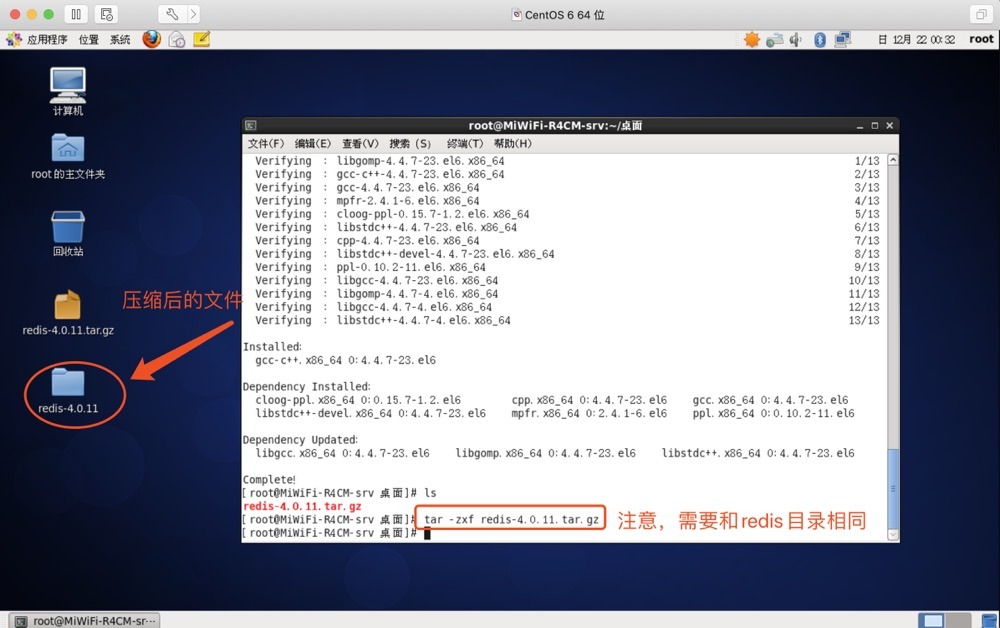
解壓Redis原始碼壓縮包
tar -zxf redis-4.0.11.tar.gz
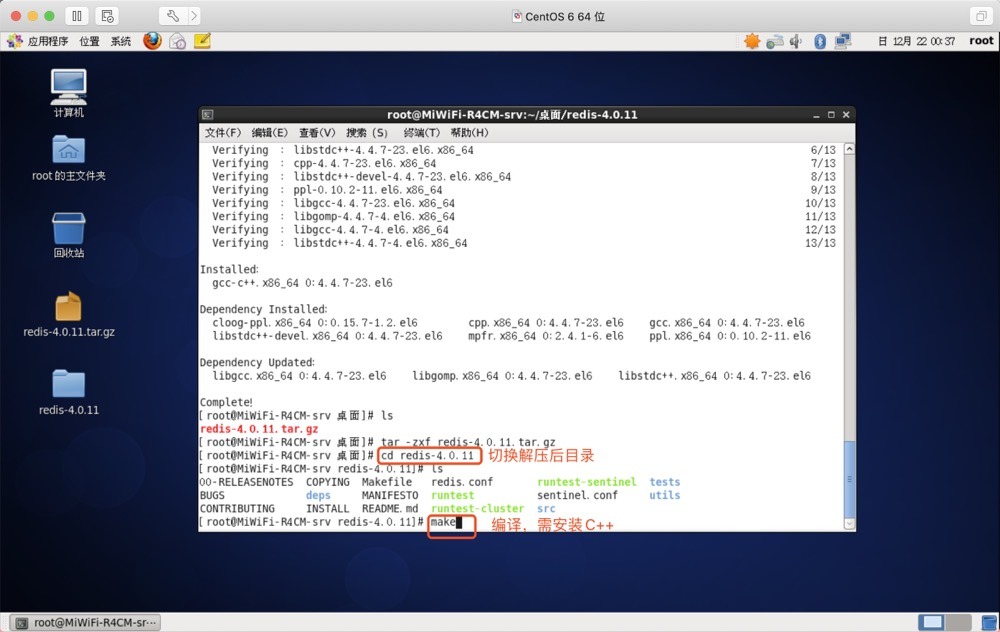
編譯Redis原始碼
make
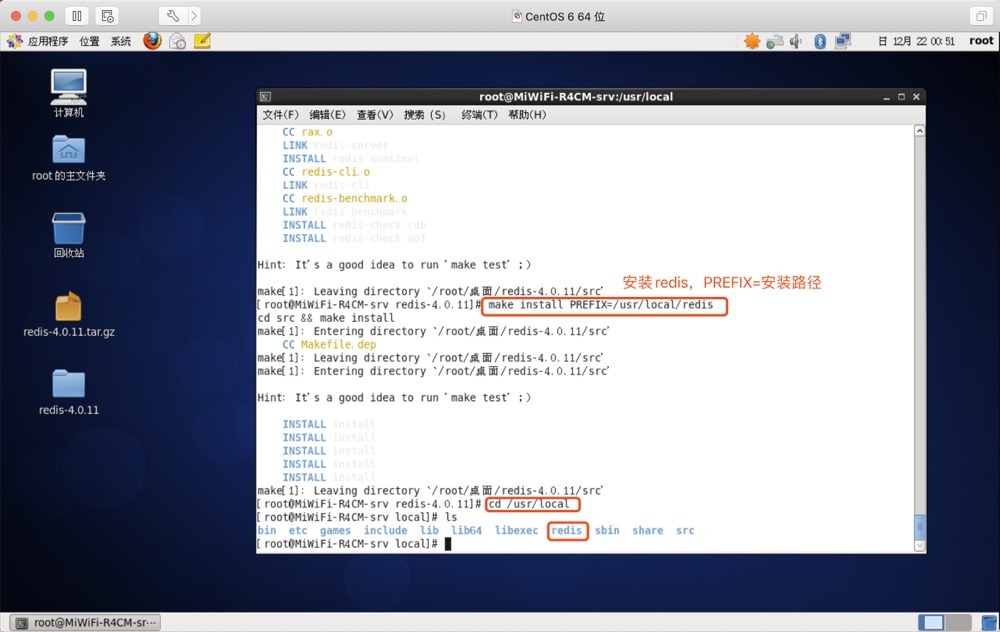
安裝Redis
make install PREFIX=/user/local/redis
格式:make install PREFIX=安裝目錄
Redis啟動
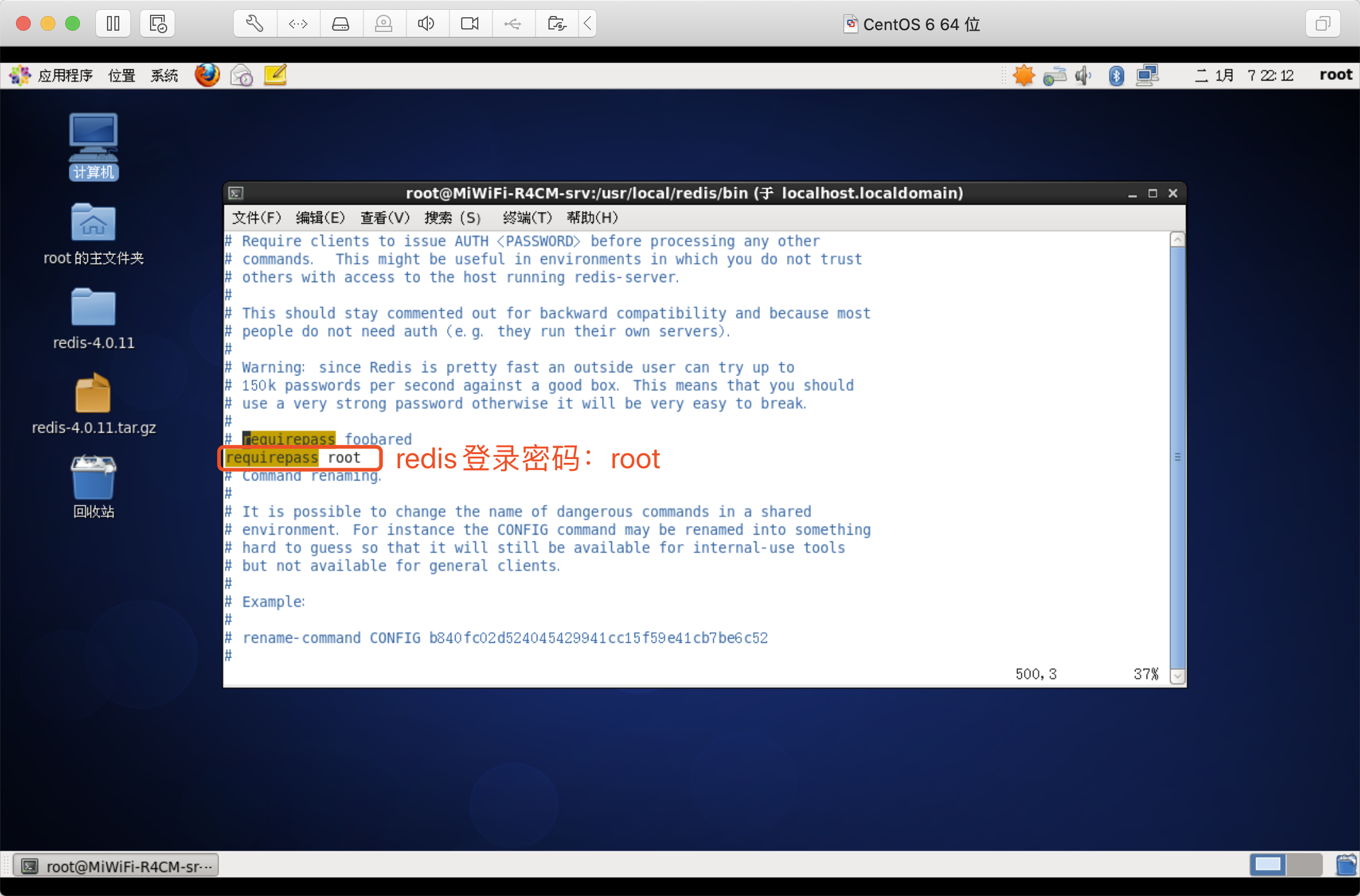
redis設定密碼
更改redis.conf配置
重啟服務
前端啟動
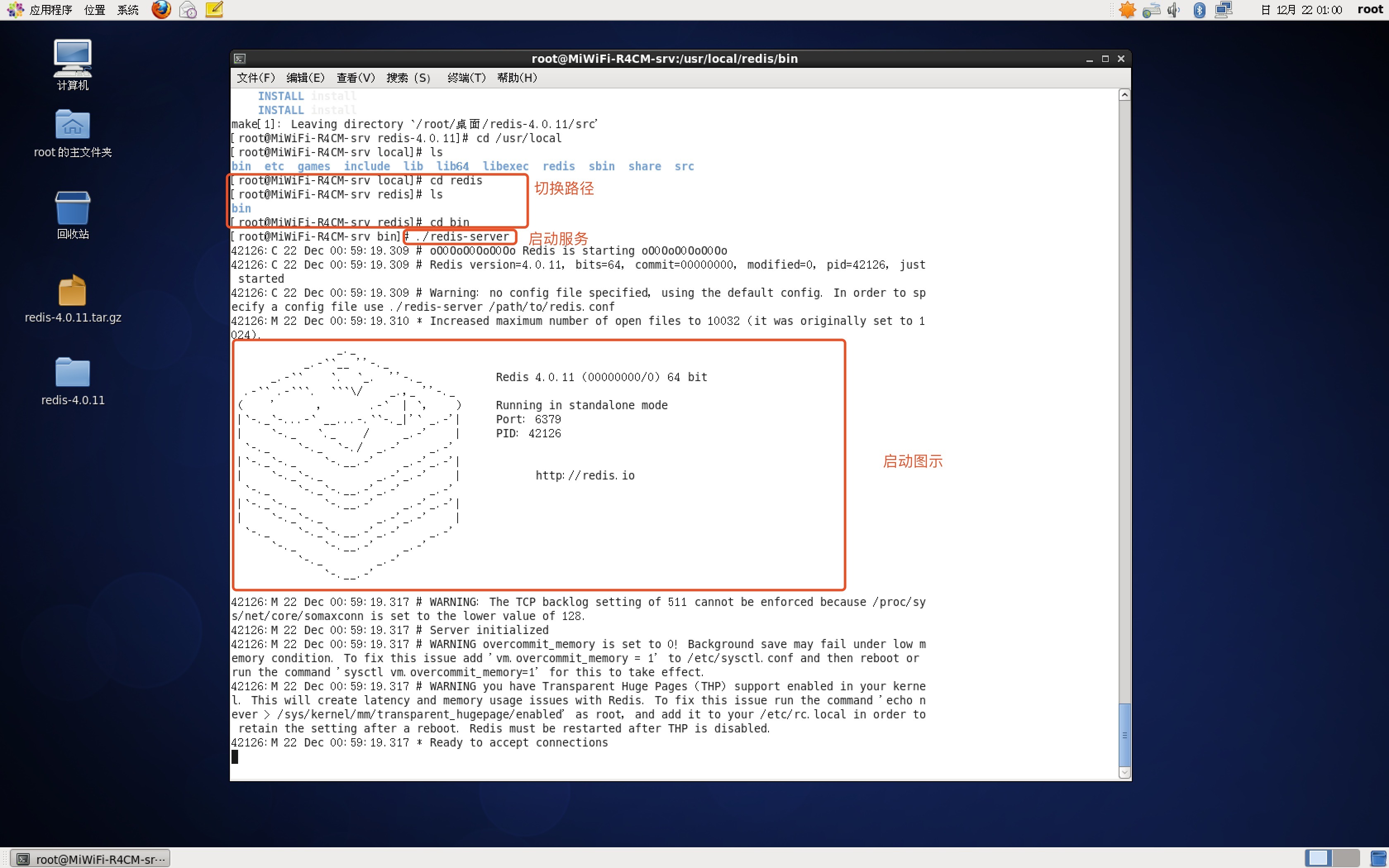
- 啟動命令:redis-server,直接運行bin/redis-server將以前端模式啟動,
關閉服務
ctrl+c
啟動缺點:客戶端視窗關閉,則redis-server程式結束,不推薦使用
后端啟動(守護行程啟動)
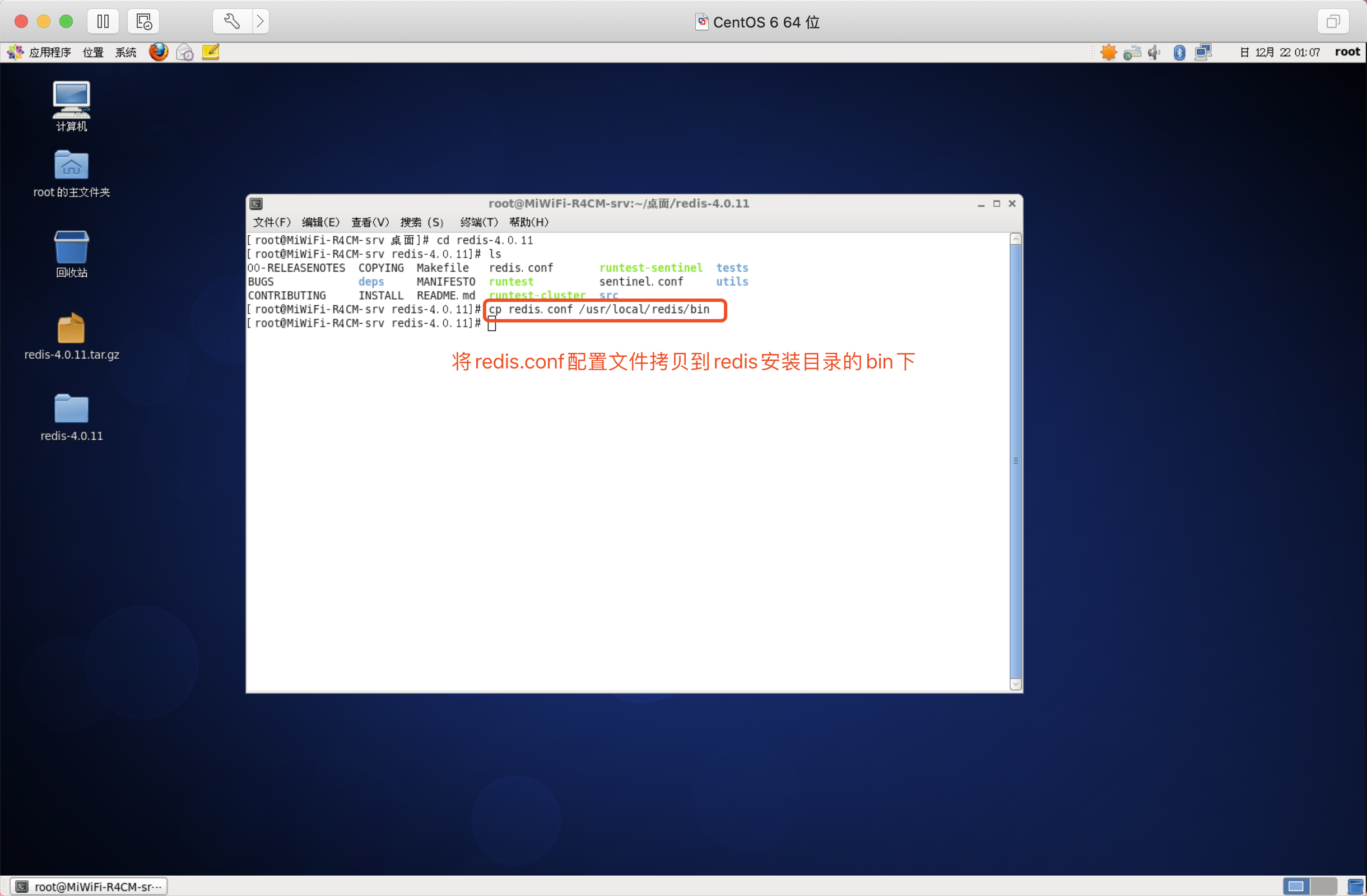
拷貝redis
cp redis.conf /usr/local/redis/bin
格式:cp 拷貝檔案夾 拷貝路徑
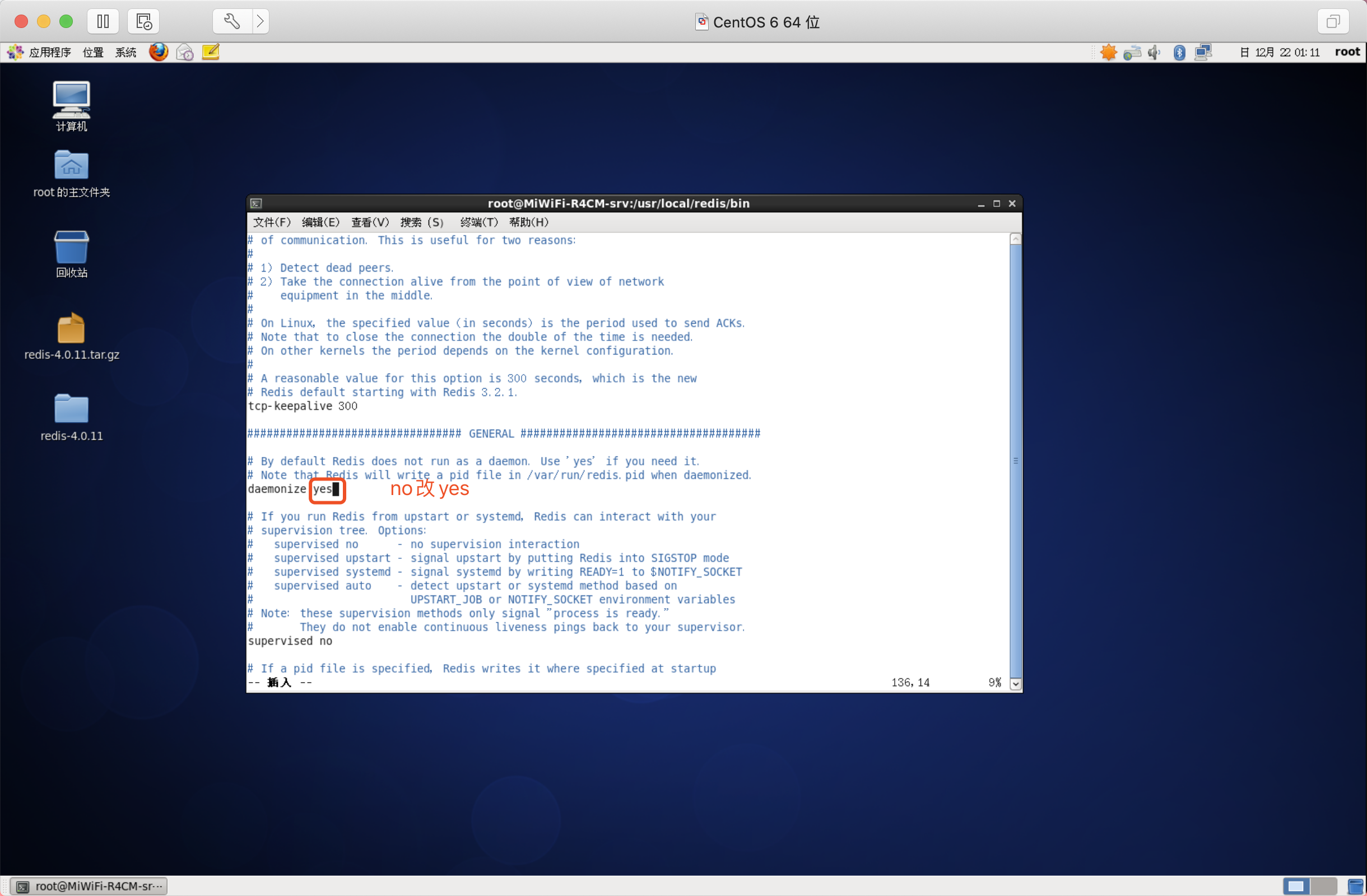
修改redis.conf,將daemonize由no改為yes
vim redis.conf
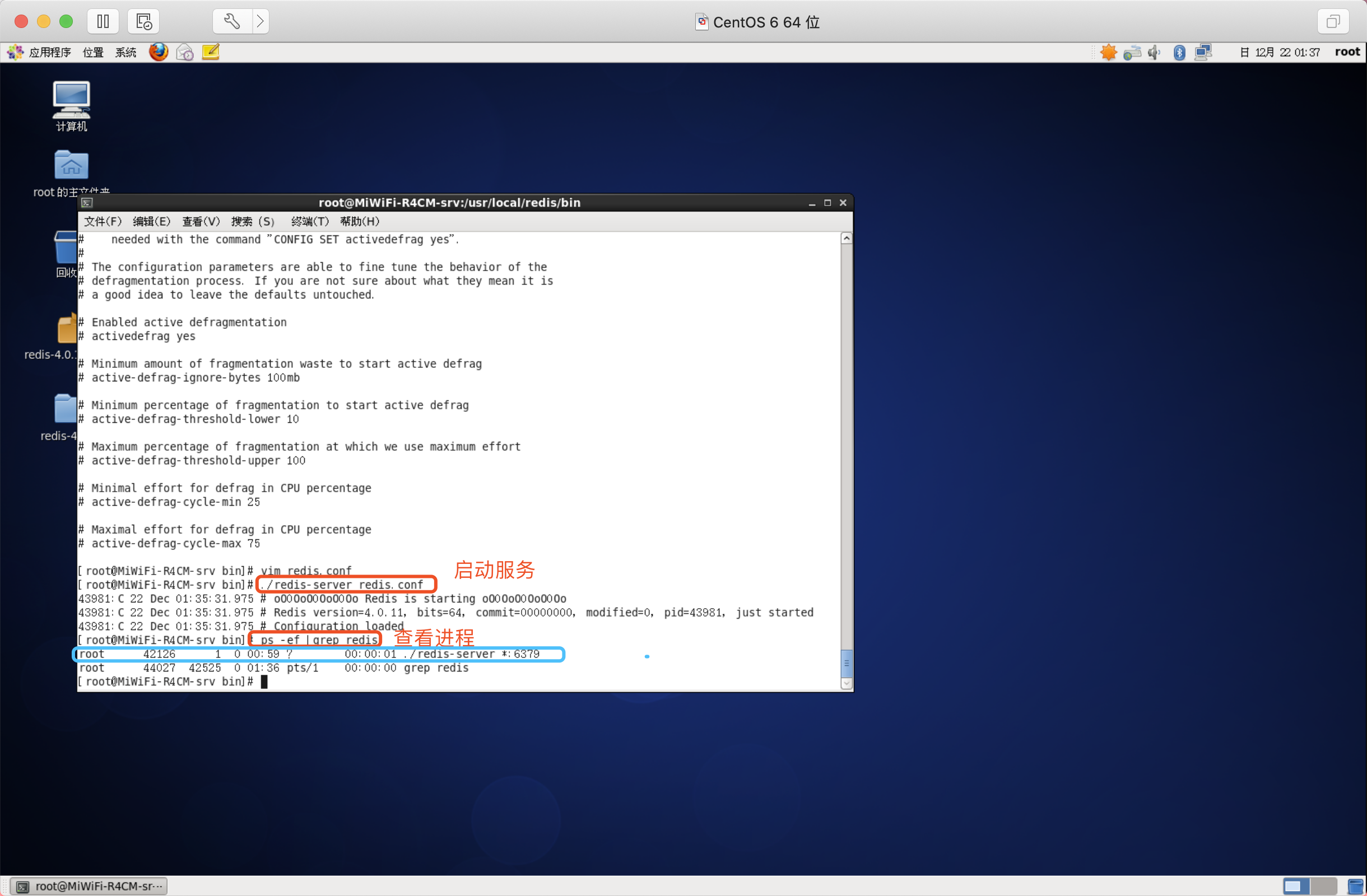
執行命令
./redis-server redis.conf
格式:啟動服務 指定組態檔
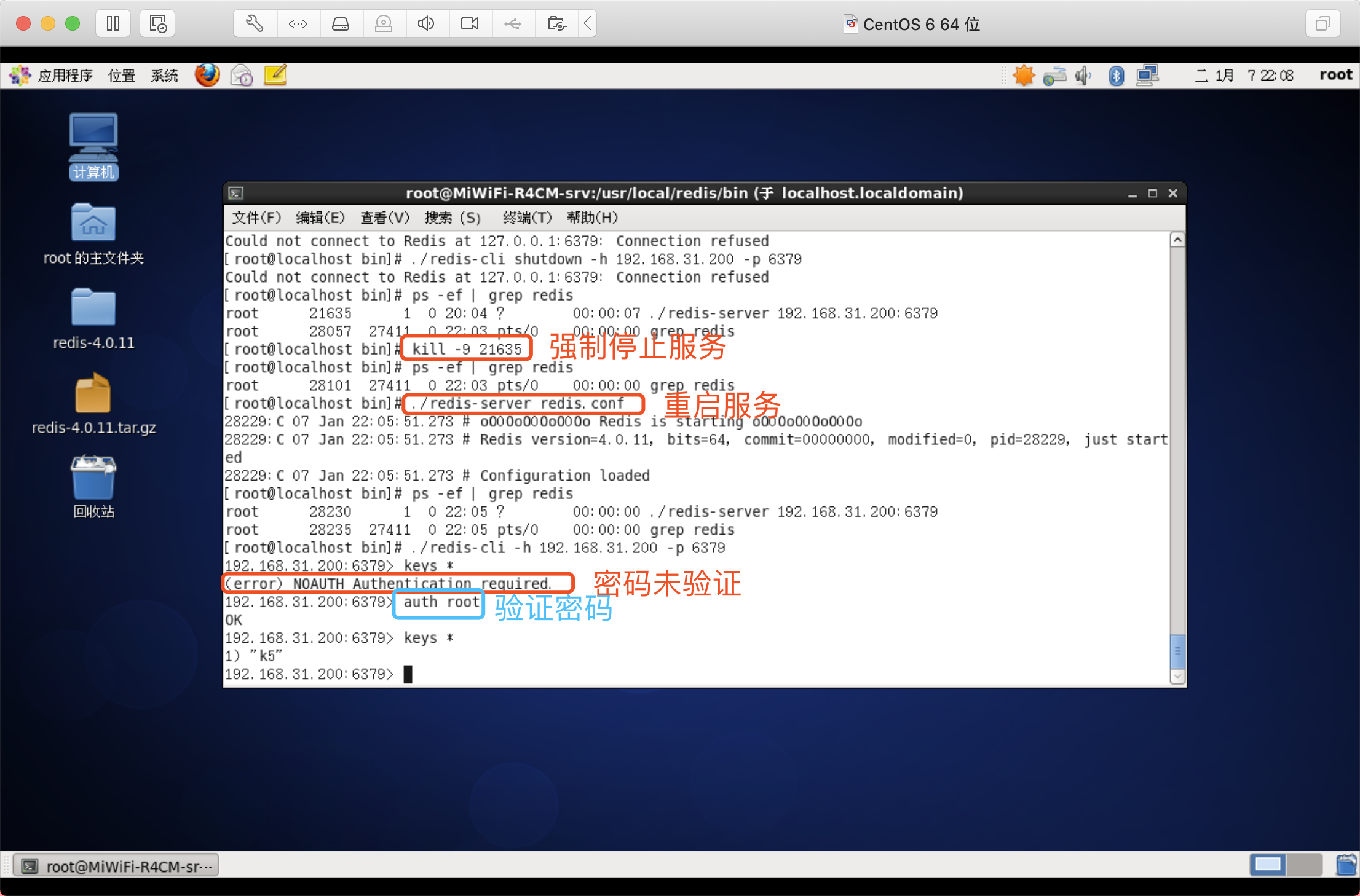
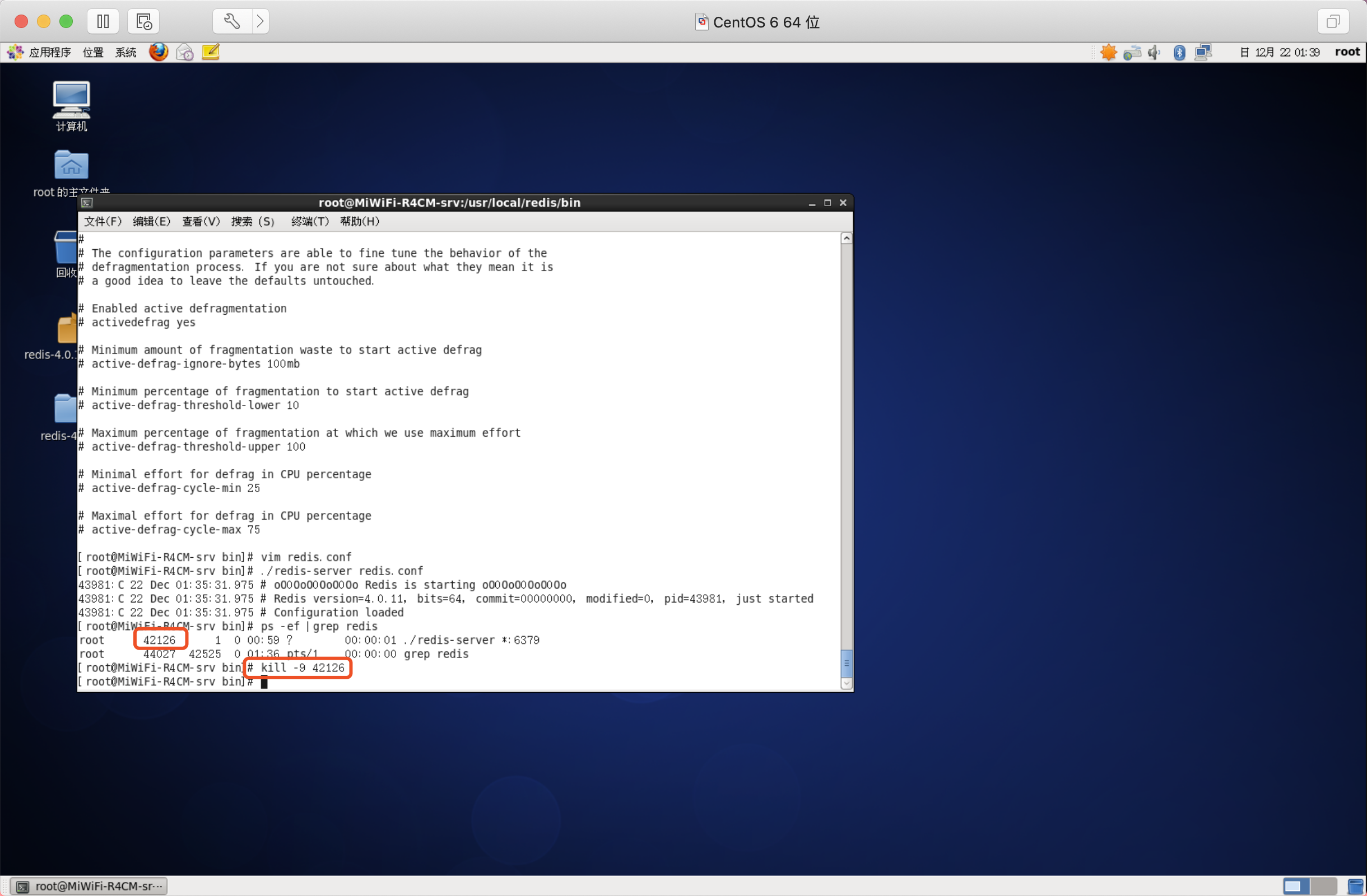
關閉服務(粗暴方式)
kill -9 42126
格式:kill -9 行程號
正常關閉
./redis-cli shutdown
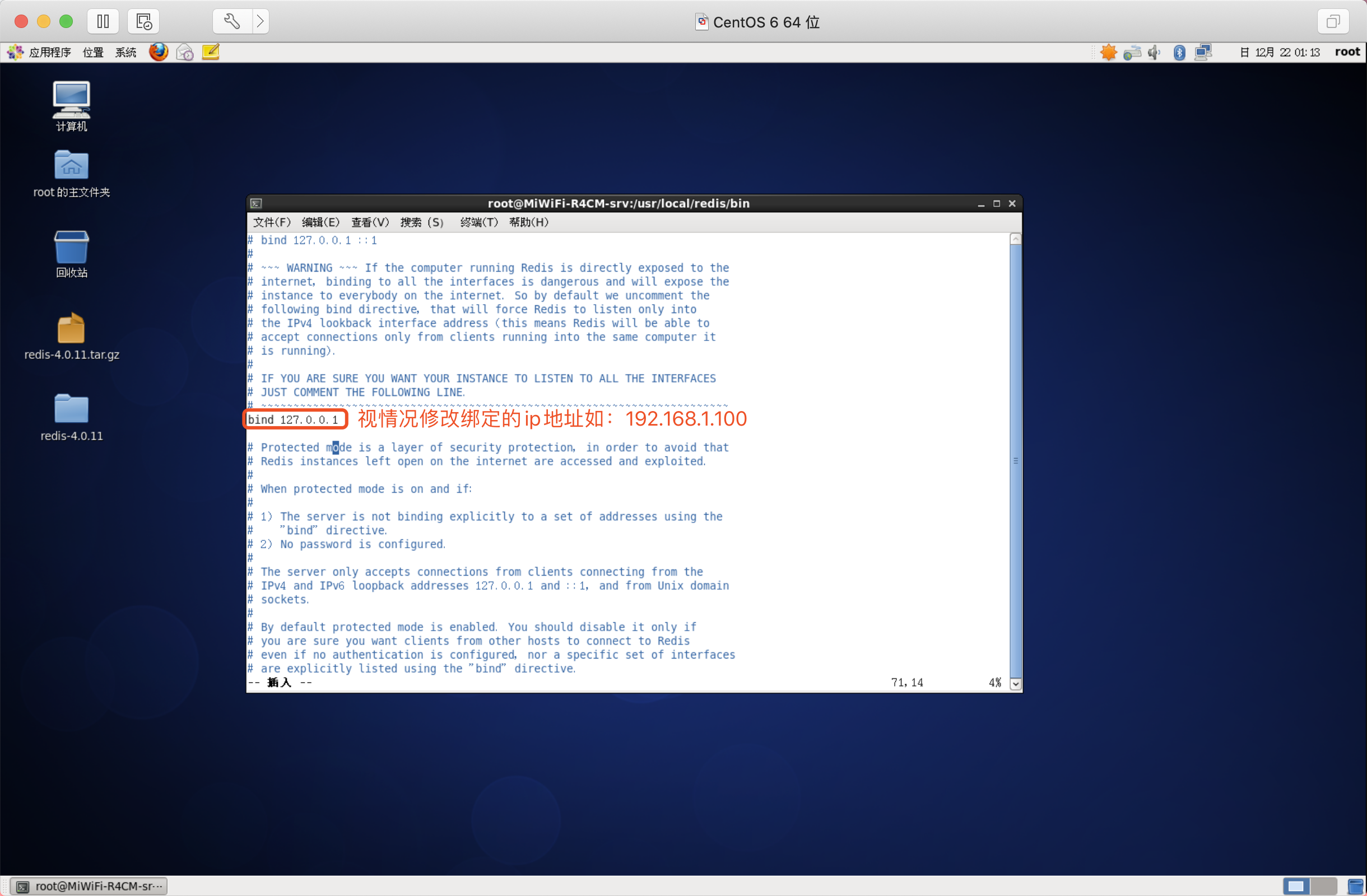
修改redis組態檔(解決IP系結問題)
# bind 127.0.0.1 系結的IP才能fangwenredis服務器,注釋掉該配置 protected-mode yes 是否開啟保護模式,由yes改為no
其他命令說明
redis-server :啟動redis服務 redis-cli :進入redis命令客戶端 redis-benchmark: 性能測驗的工具 redis-check-aof : aof檔案進行檢查的工具 redis-check-dump : rdb檔案進行檢查的工具 redis-sentinel : 啟動哨兵監控服務
Redis客戶端
自帶命令列客戶端
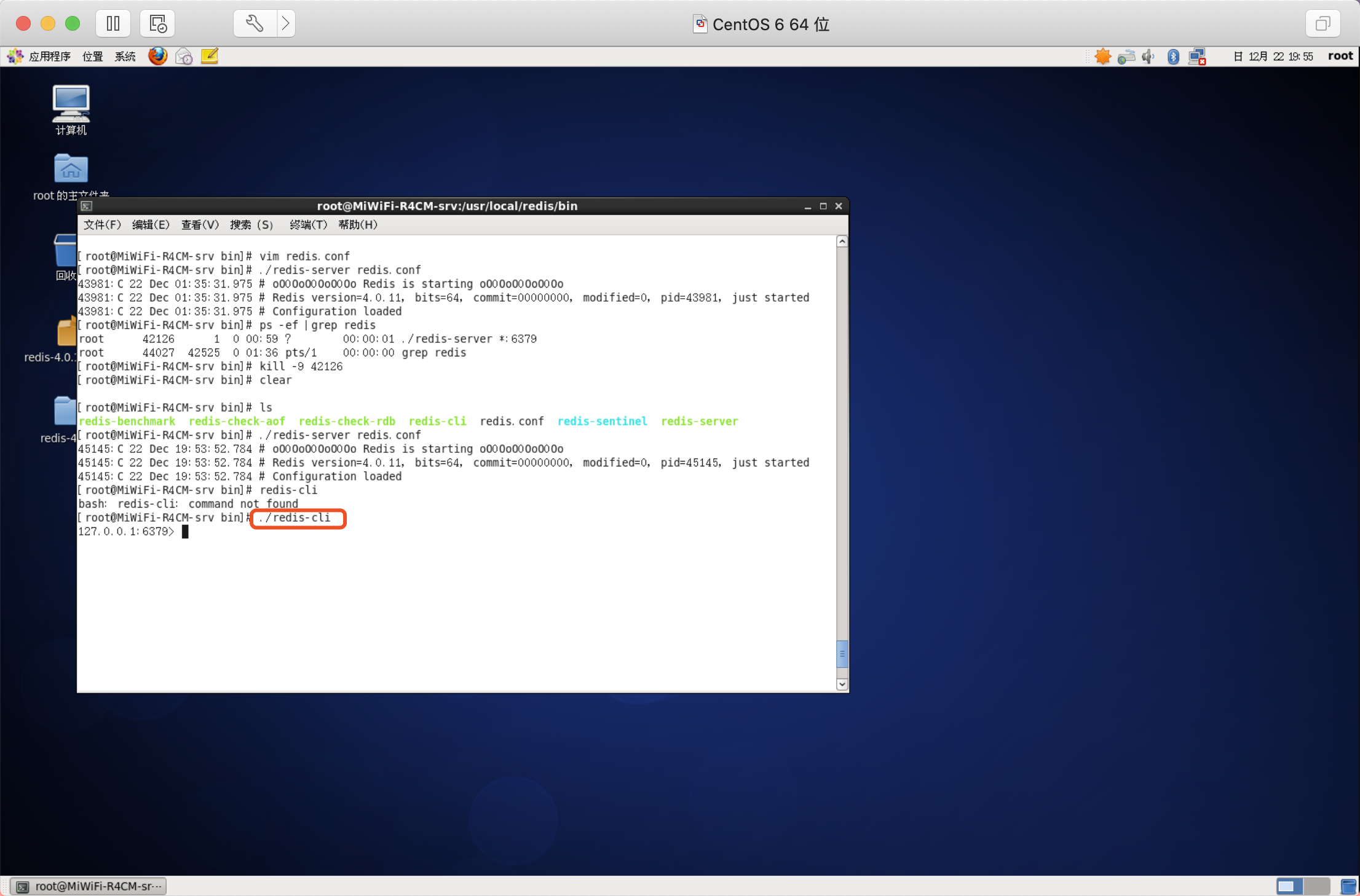
語法
./redis-cli -h 127.0.0.1 -p 6379
修改redis.conf組態檔(解決ip系結問題)
#bind 127.0.0.1 系結的ip才能訪問redis服務器,注釋掉該配置 protected-mode yes 是否開啟保護模式,由yes改為no
引數說明
- -h:redis服務器的ip地址
- -p:redis實體的埠號
默認方式
如果不制定主機和埠號也可以
./redis-cli 默認的主機地址是:127.0.0.1 默認的埠號是:6379
Redis資料型別
官網命令大全網址
http://www.redis.cn/commands.html
- String(字符型別)
- Hash(散列型別)
- List(串列型別)
- Set(集合型別)
- SortedSet(有序集合型別,簡稱zset)
注:命令不區分大小寫,而key是區分大小寫的,
String型別
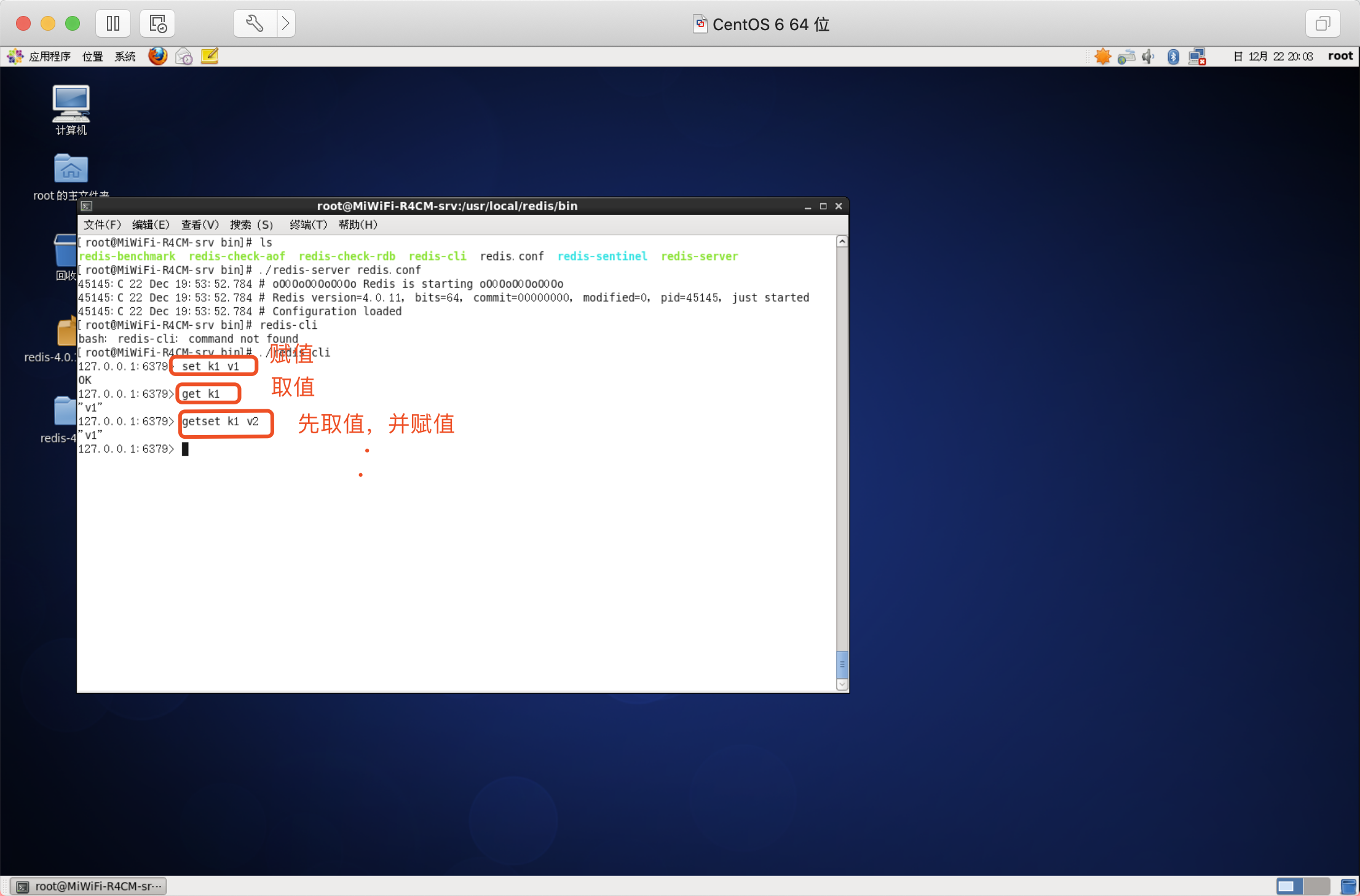
賦值
語法:SET key value
取值
語法:GET key
取值并賦值
語法:GETSET key value
演示
數值增減
前提條件:
- 當value為整數資料時,才能使用以下命令運算元值的增減,
- 數值增減都是原子操作,
遞增數字
語法:INCR key
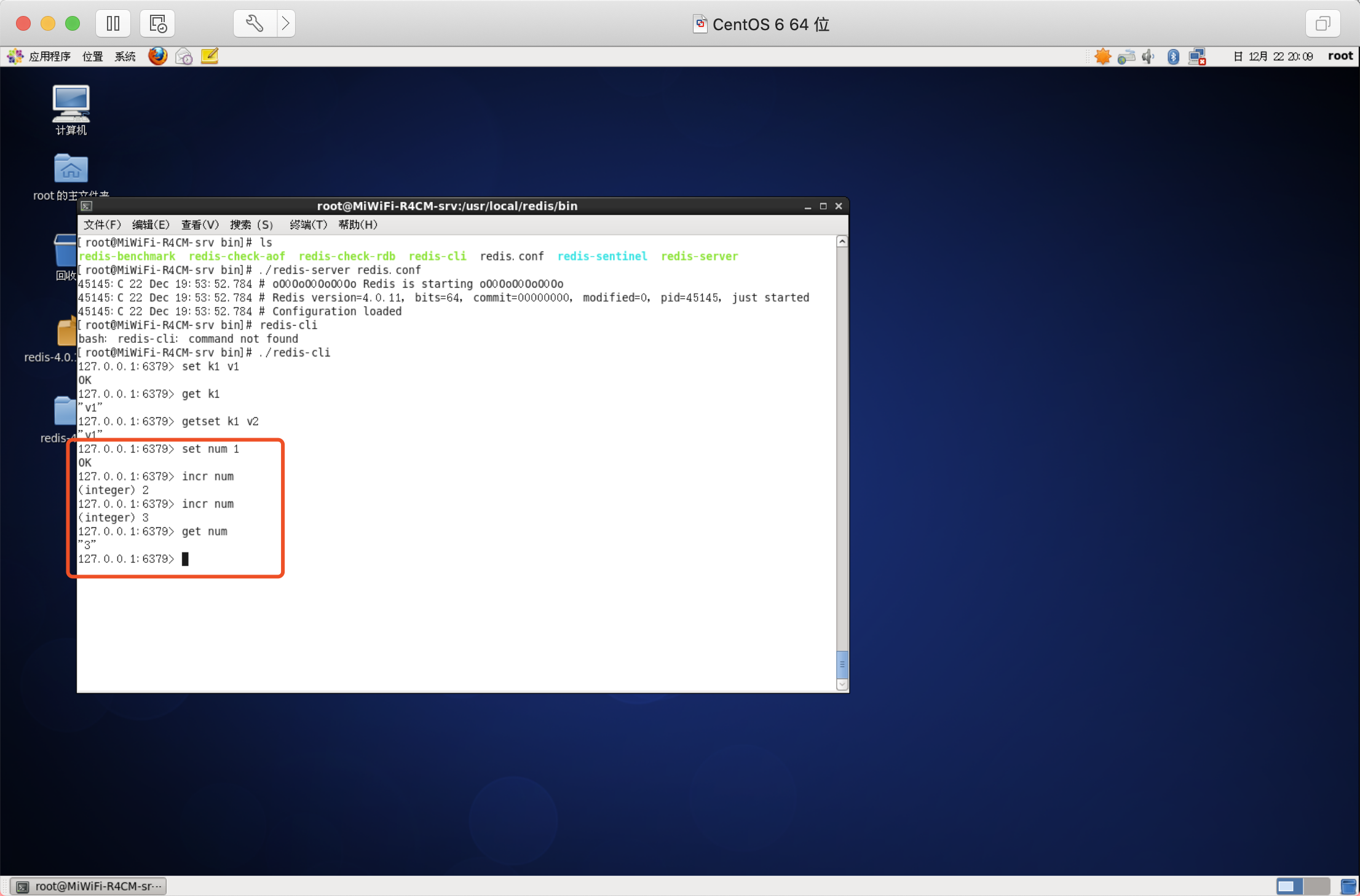
增加指定的整數
語法:INCRBY key increment
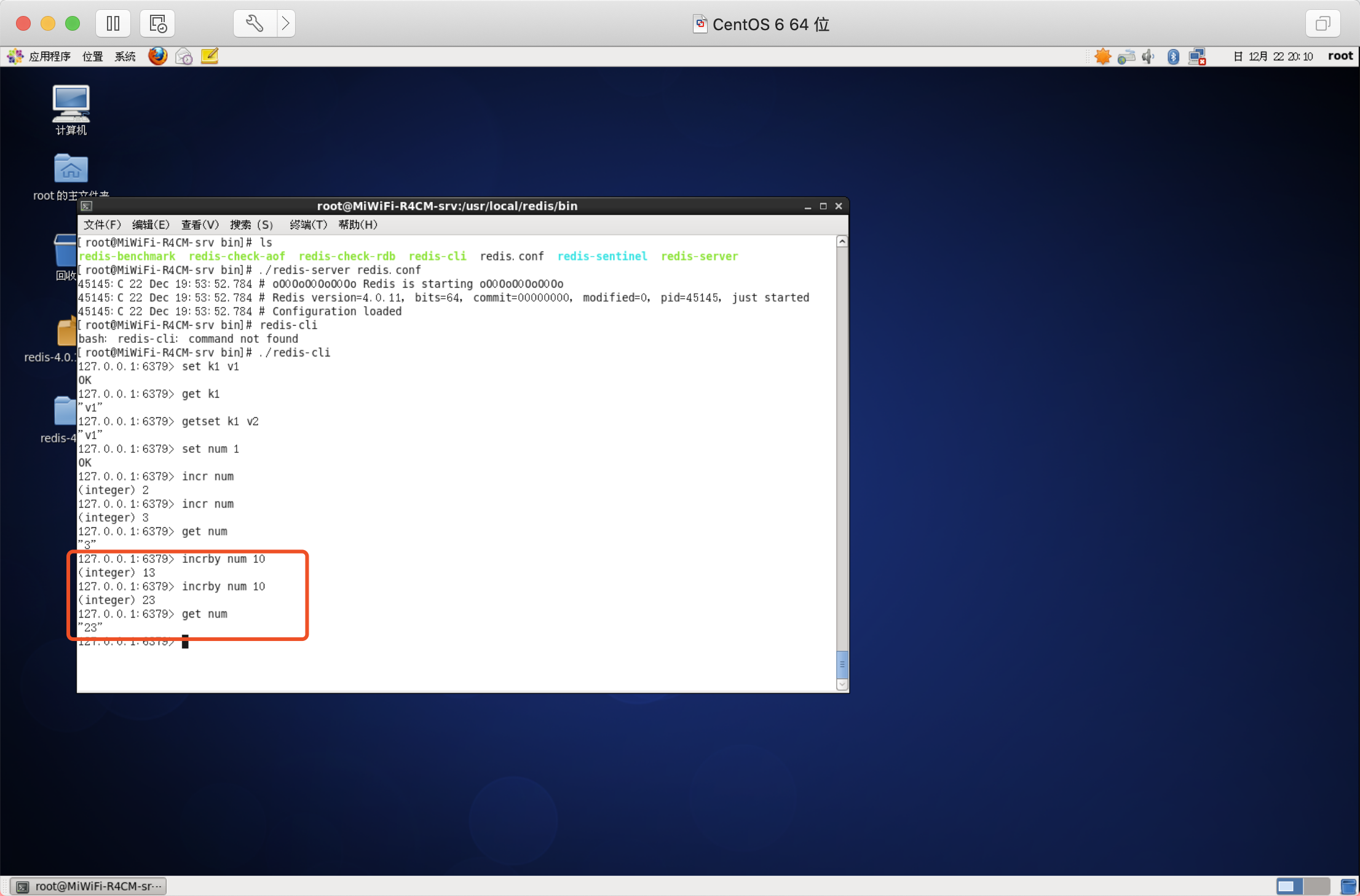
遞減數值
語法:DECR key
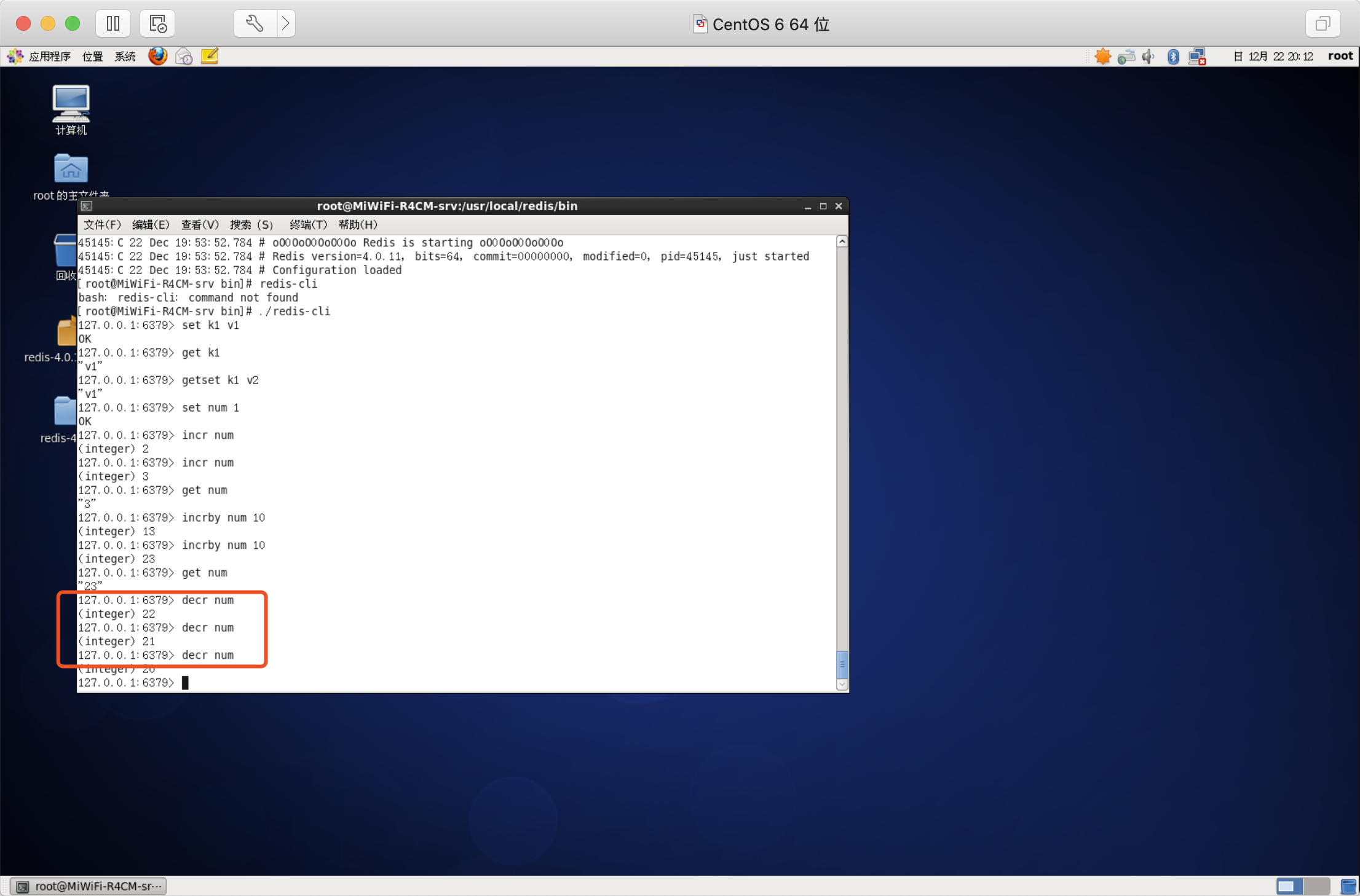
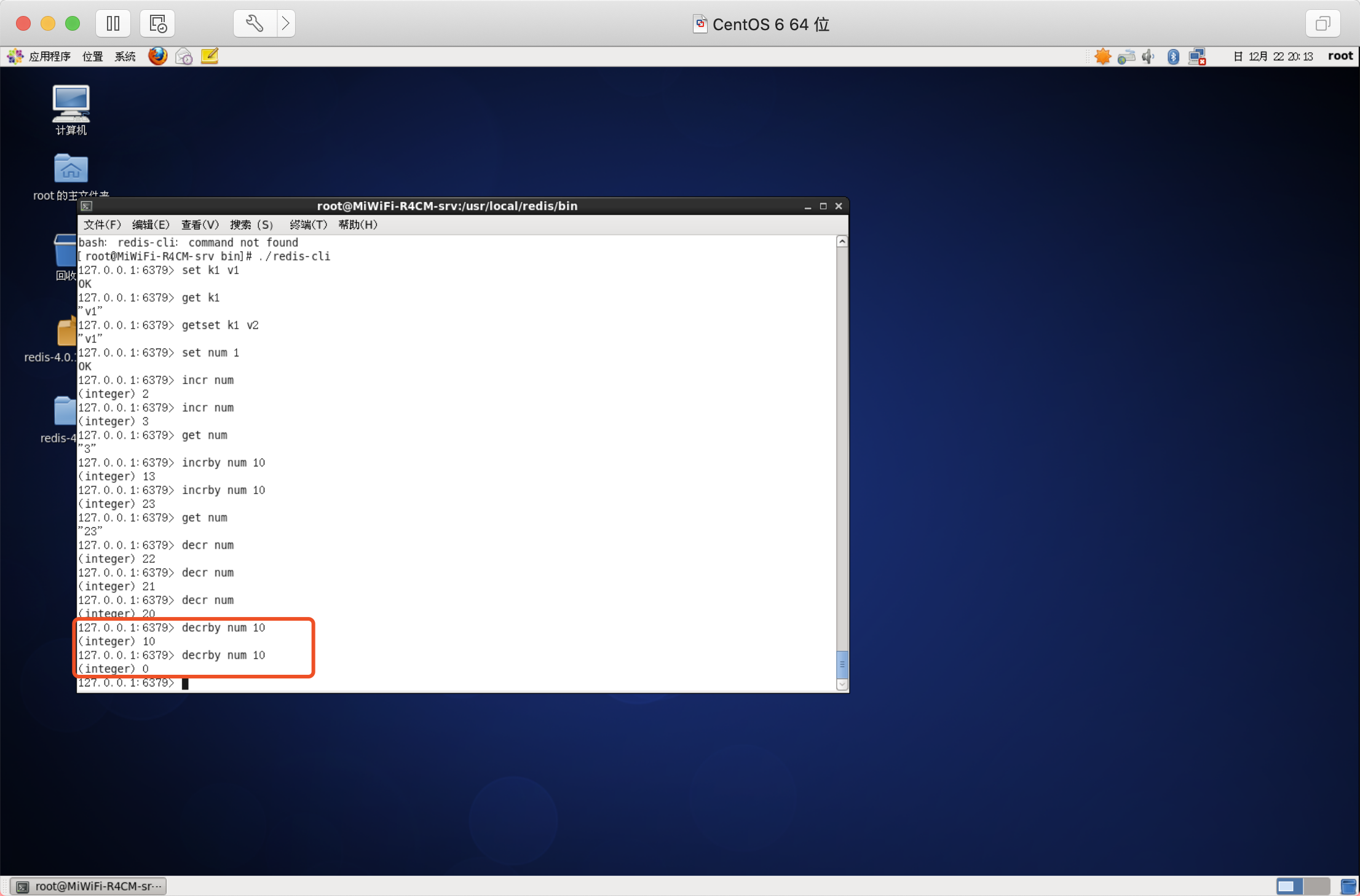
減少指定的整數
語法:DECRBY key decrement
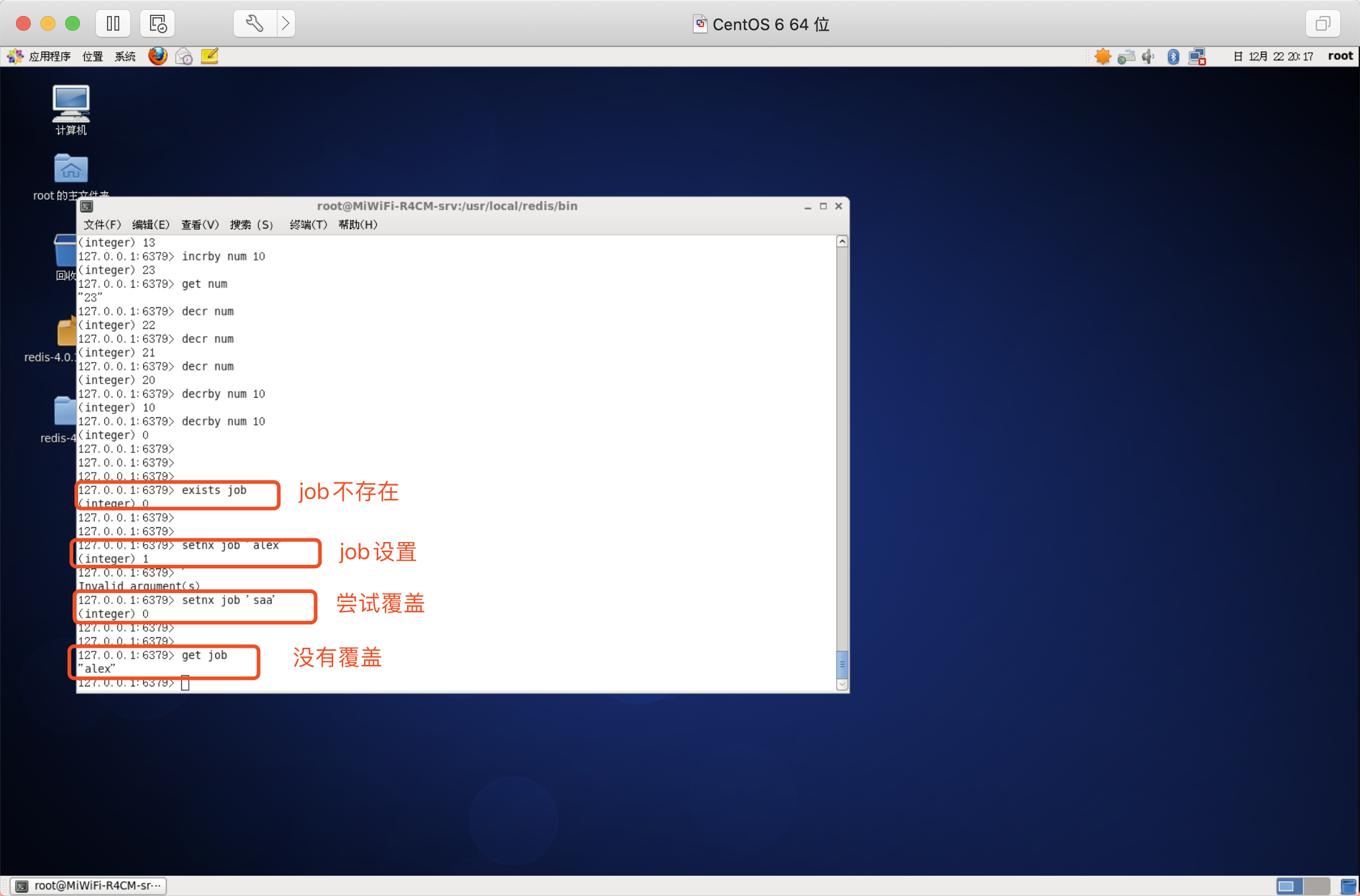
僅當不存在時賦值
注:該命令可以實作分布式鎖的功能,后續講解!!!!
語法:setnx key value
向尾部追加值
注:APPEND命令,向鍵值的末尾追加value,如果鍵不存在則該鍵的值設定為value,即相當于set key value,回傳值是追加后字串的總長度,
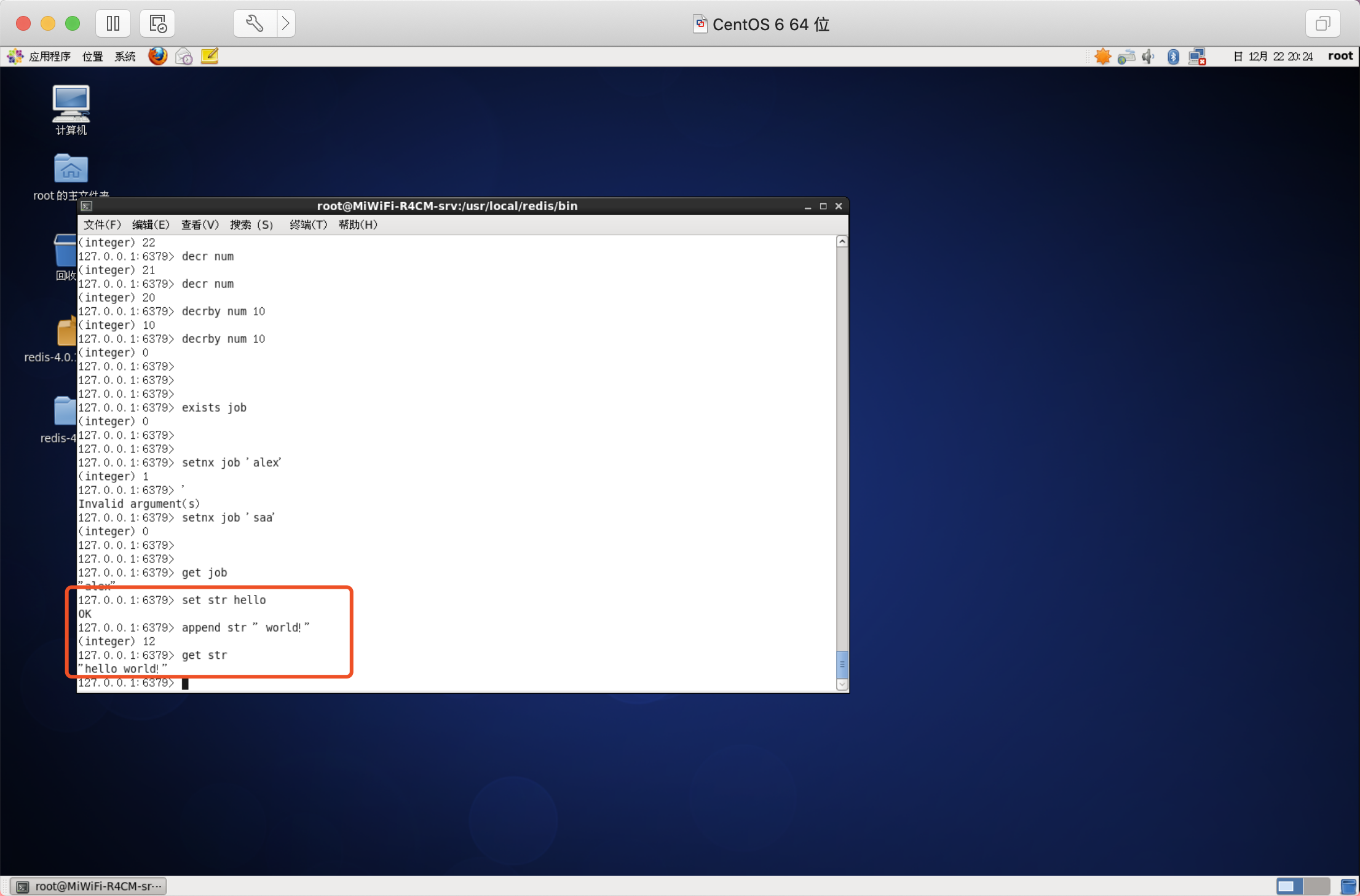
獲取字串長度
注:strlen命令,回傳鍵值的長度,如果鍵不存在則回傳0
語法:STRLEN key
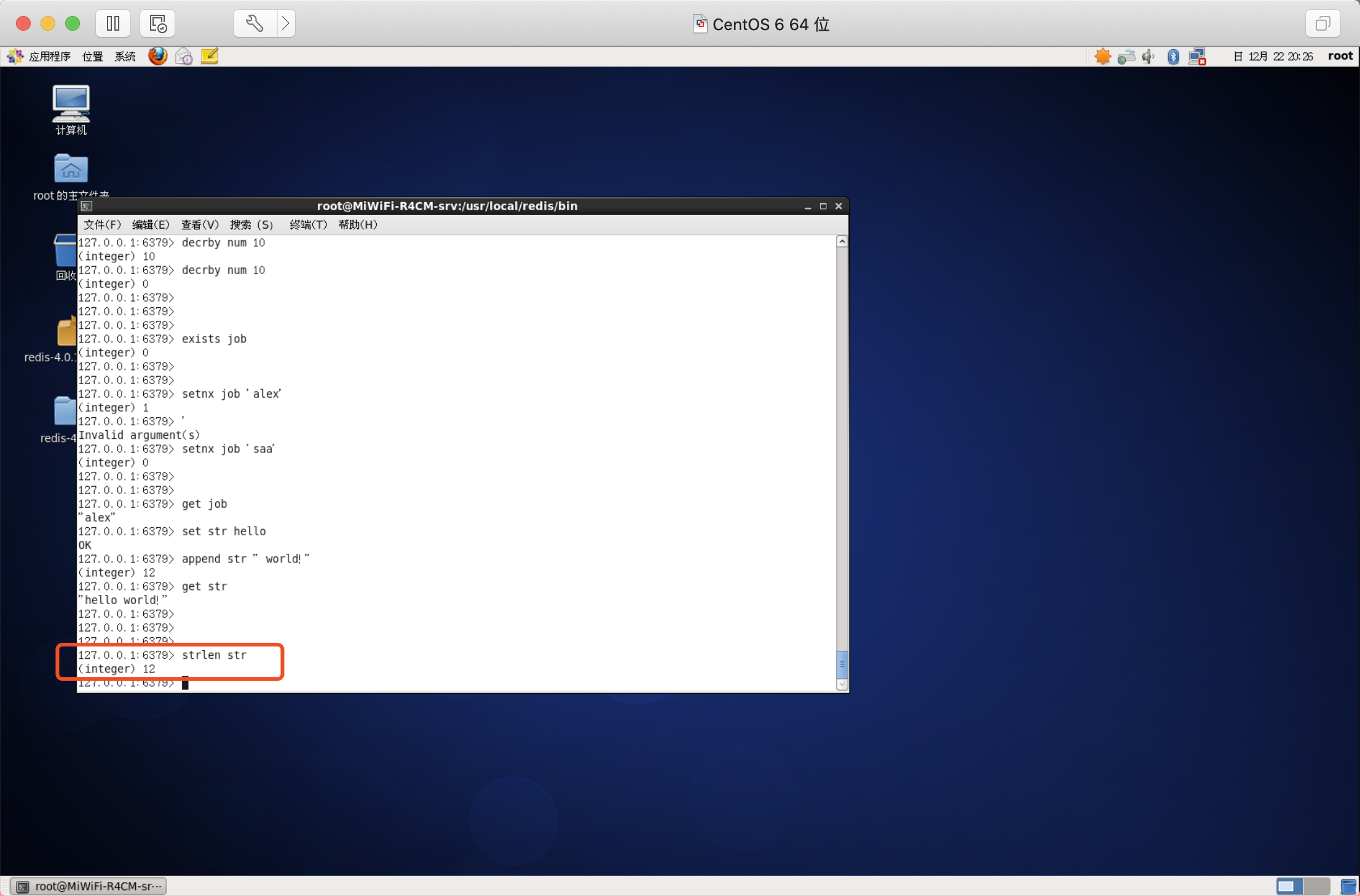
同時設定/獲取多個鍵值
語法:
- MSET key value [key value ....]
- MGET key [key ....]
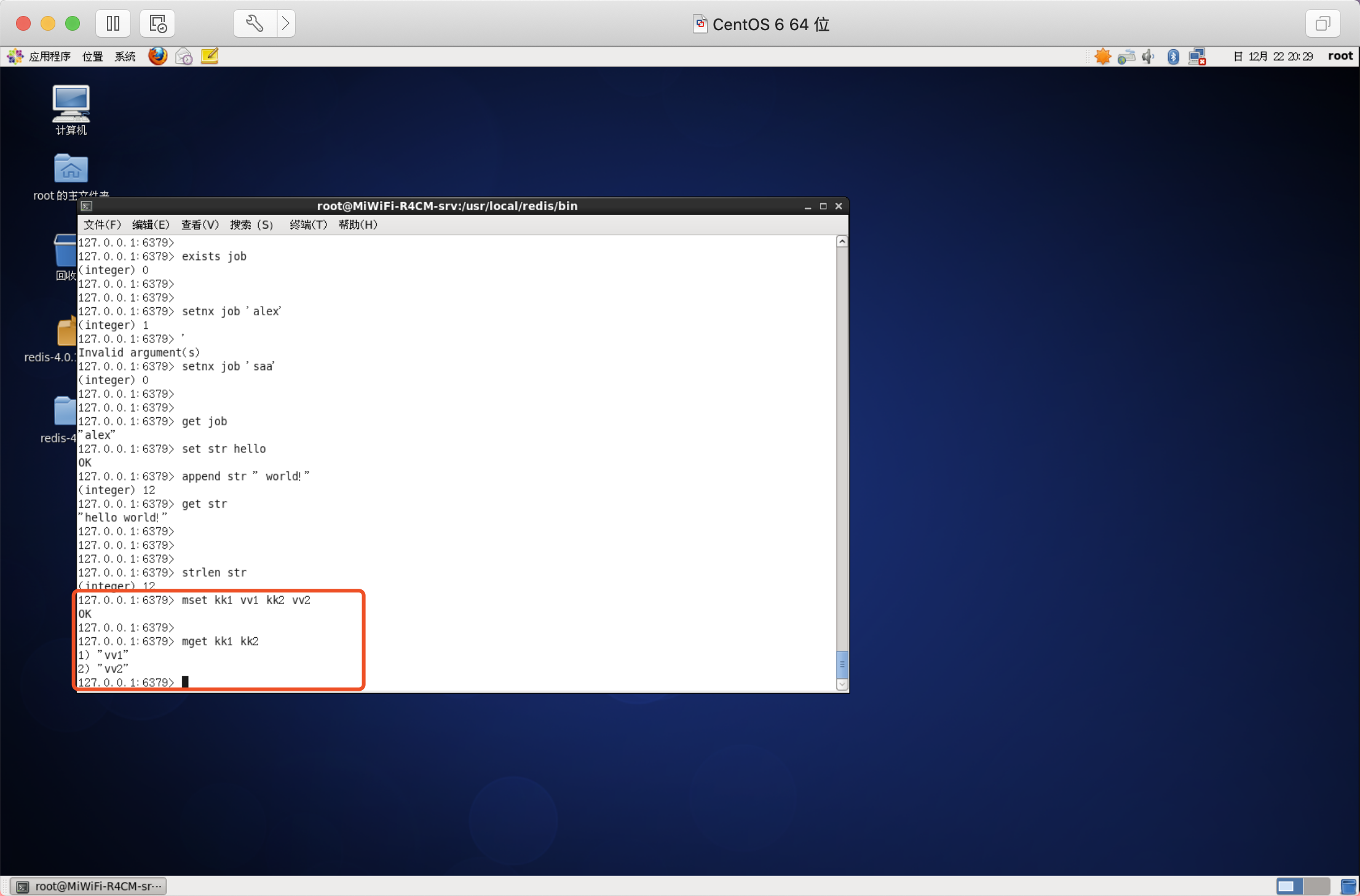
應用場景之自增主鍵
需求:商品編號、訂單號采用INCR命令生成,
設計:key明明要有一定的設計
實作:定義商品編號key:items:id
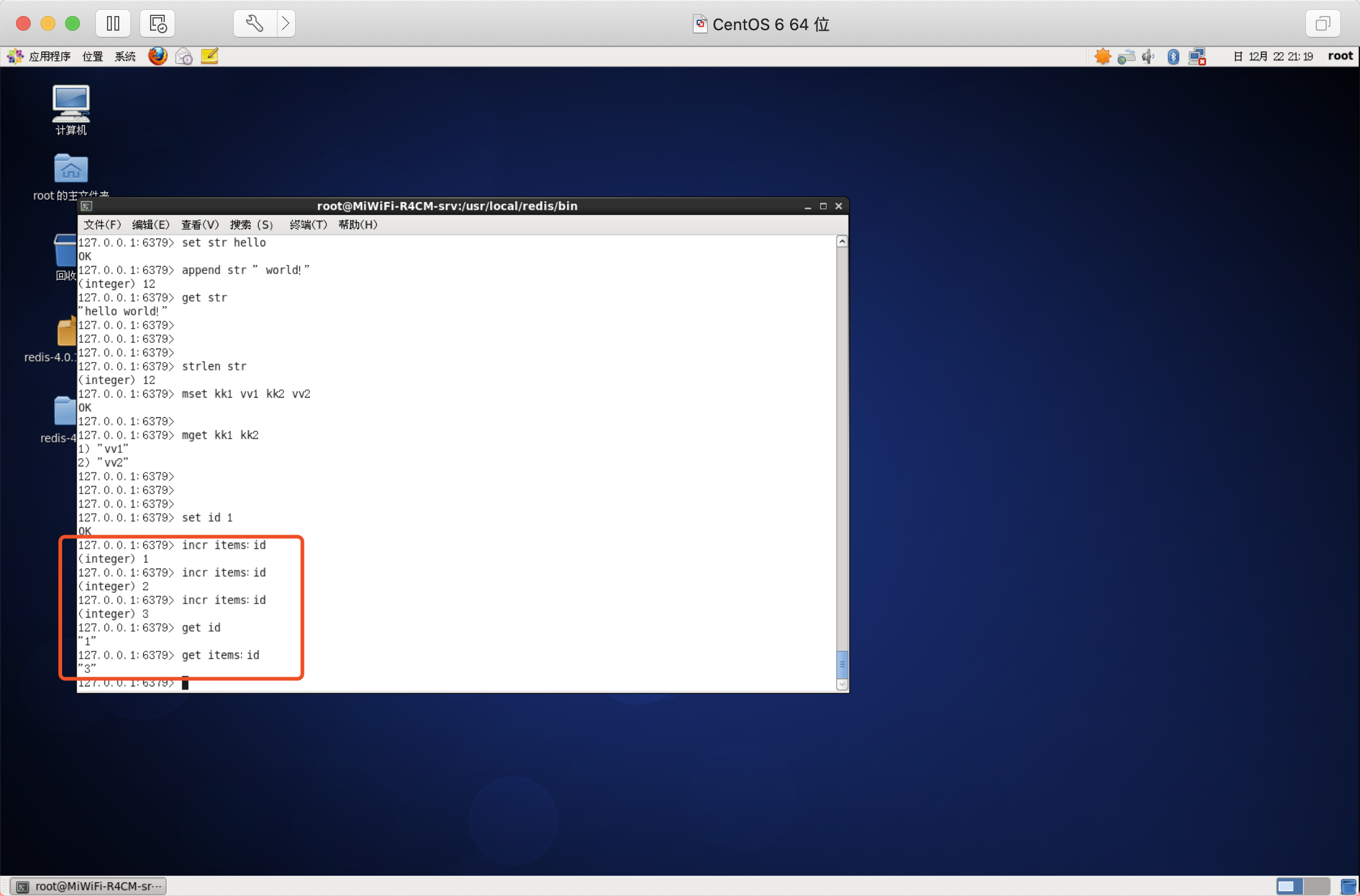
Hash型別
Hash叫散列型別,它提供了欄位和欄位值的映射,欄位值只能是字串型別,不支持散列型別、集合型別等其他型別,
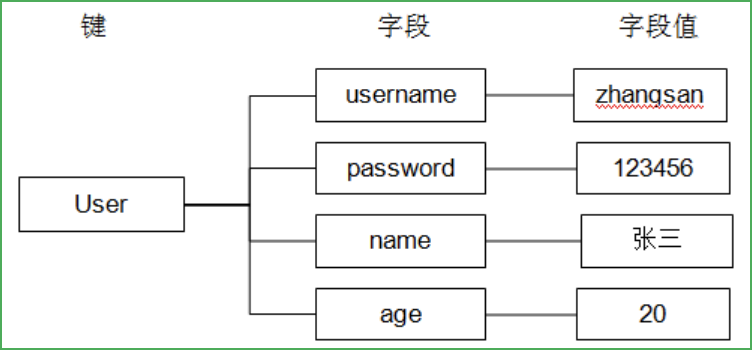
賦值
HSET命令不區分插入和更新操作,當執行插入操作時HSET命令回傳1,當執行更新操作時回傳0,
一次只能設定一個欄位值
語法:HSET key field value
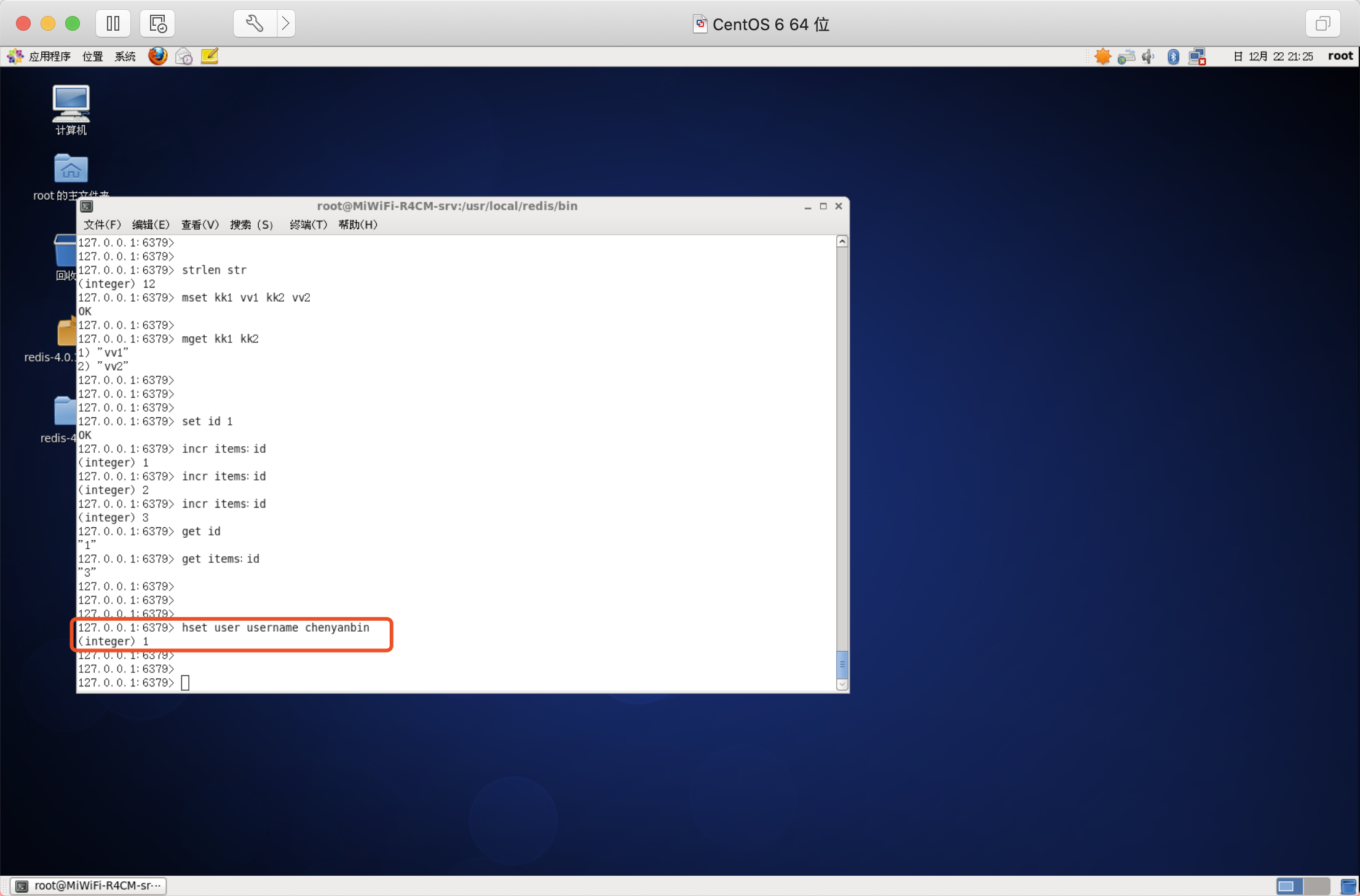
一次設定多個欄位值
語法:HMSET key field value [field value ...]
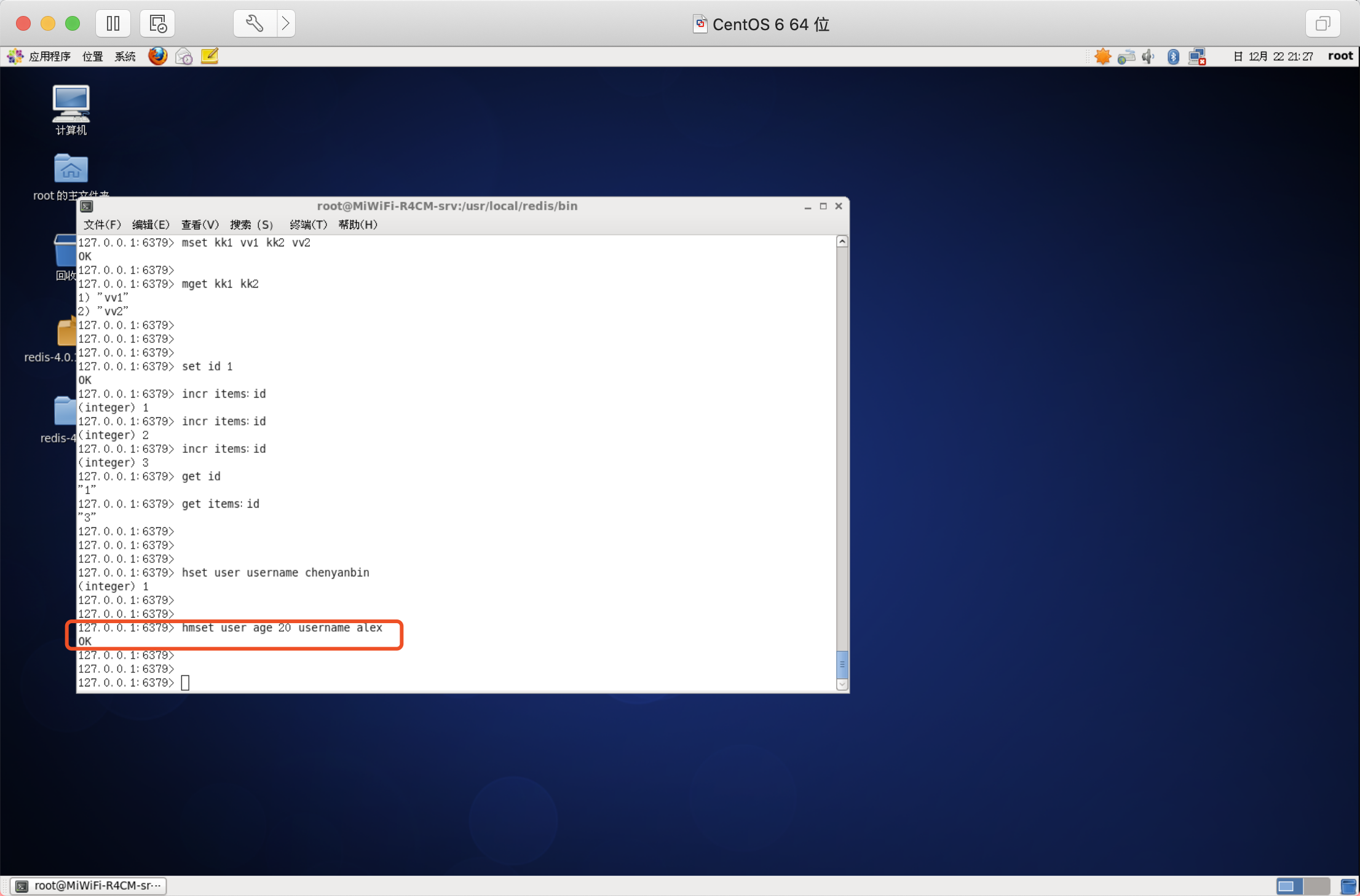
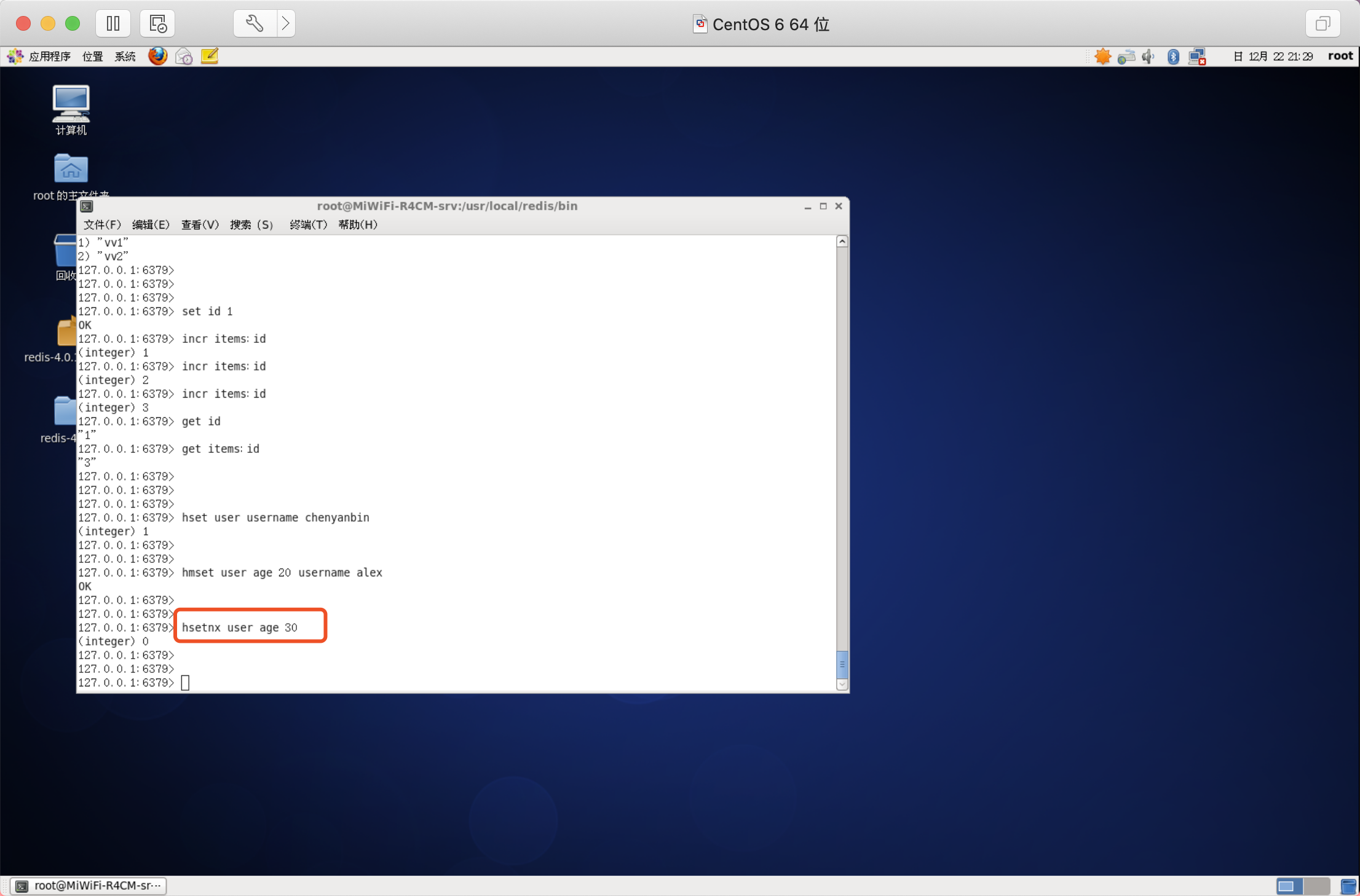
當欄位不存在時
類似HSET,區別在于如何欄位存在,該命令不執行任何操作
語法:HSETNX key field value
取值
一次只能獲取一個欄位值
語法:HGET key field
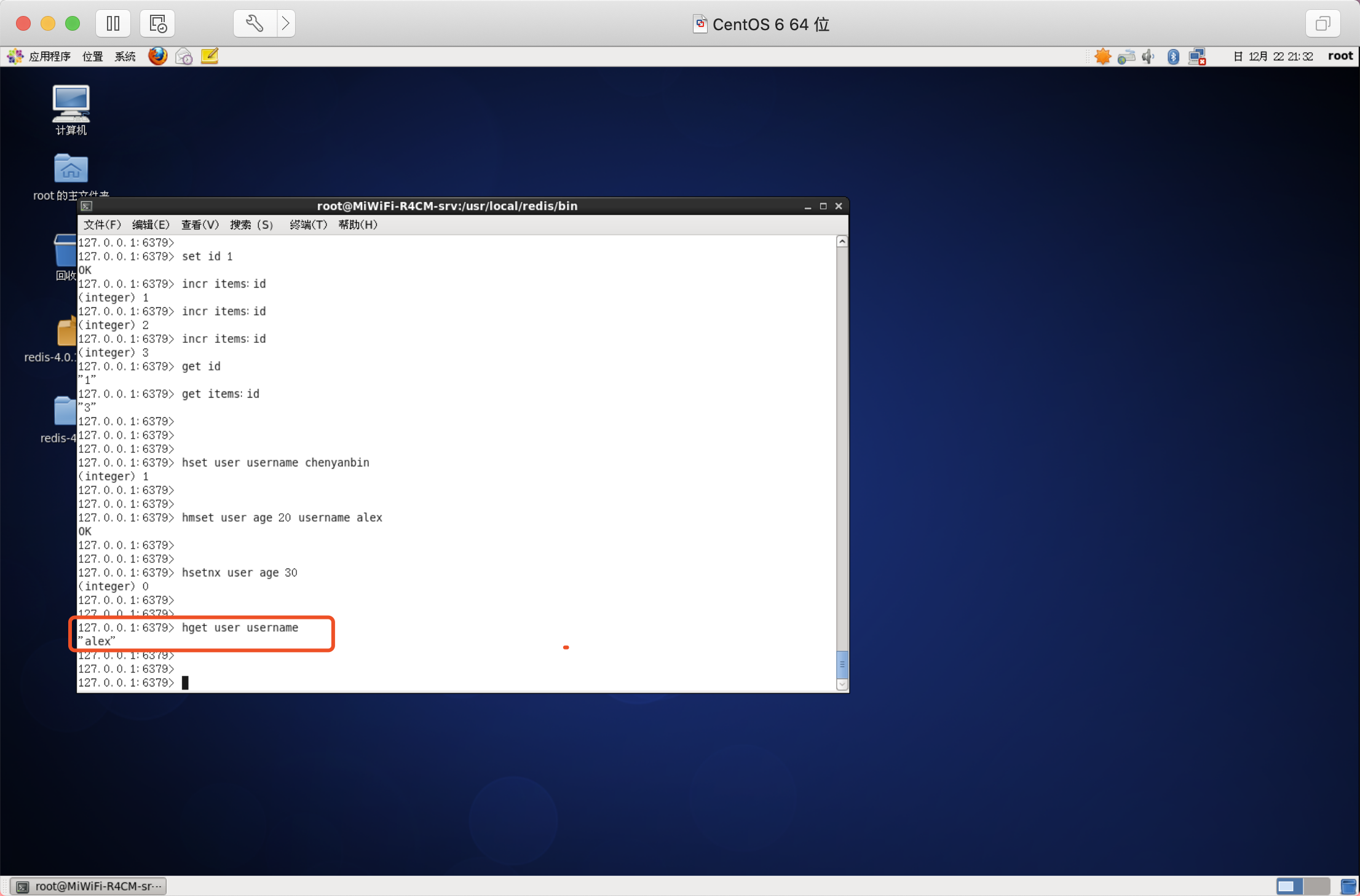
一次可以獲取多個欄位值
語法:HMGET key field [field ....]
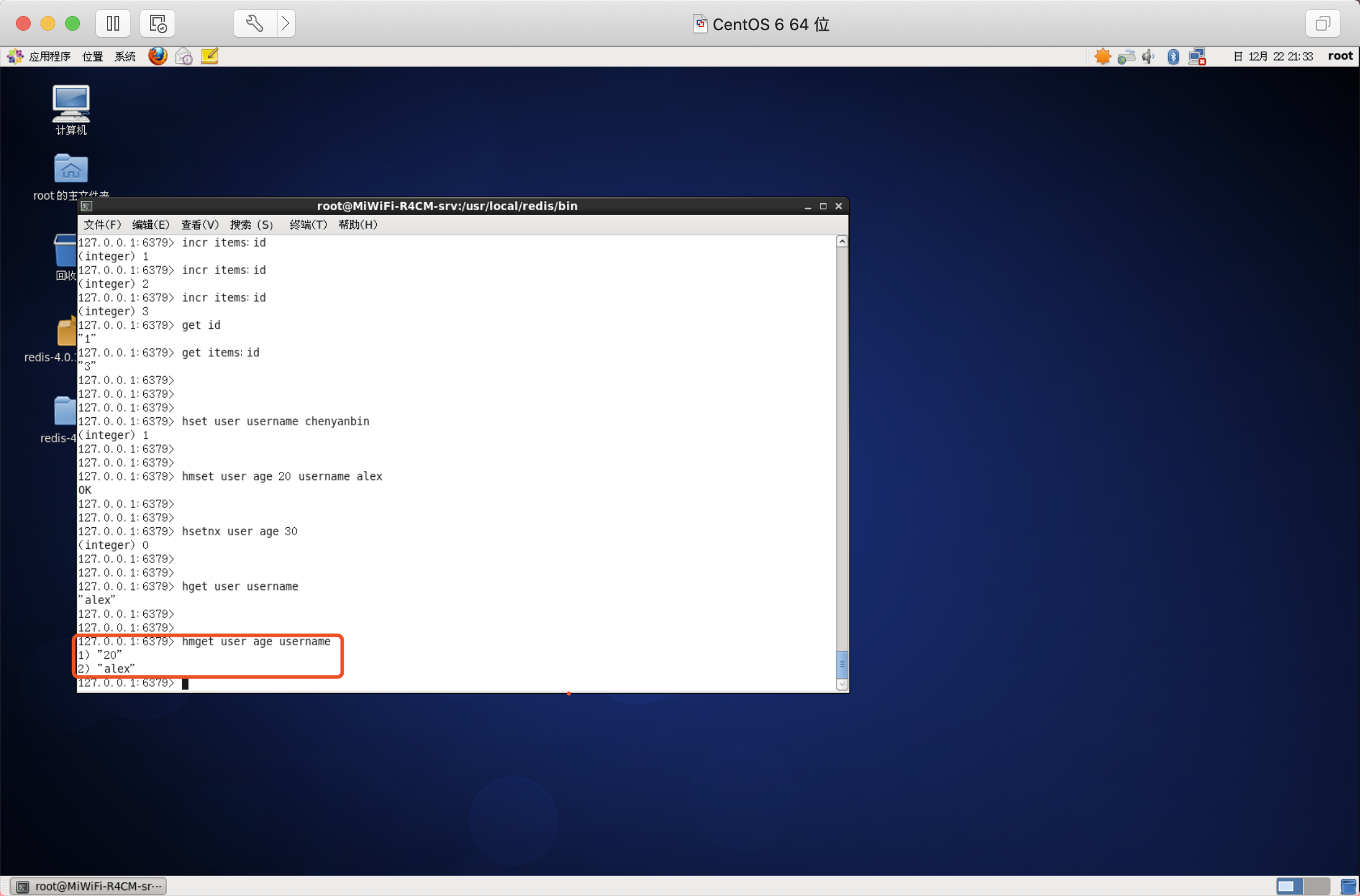
獲取所有欄位值
語法:HGETALL key
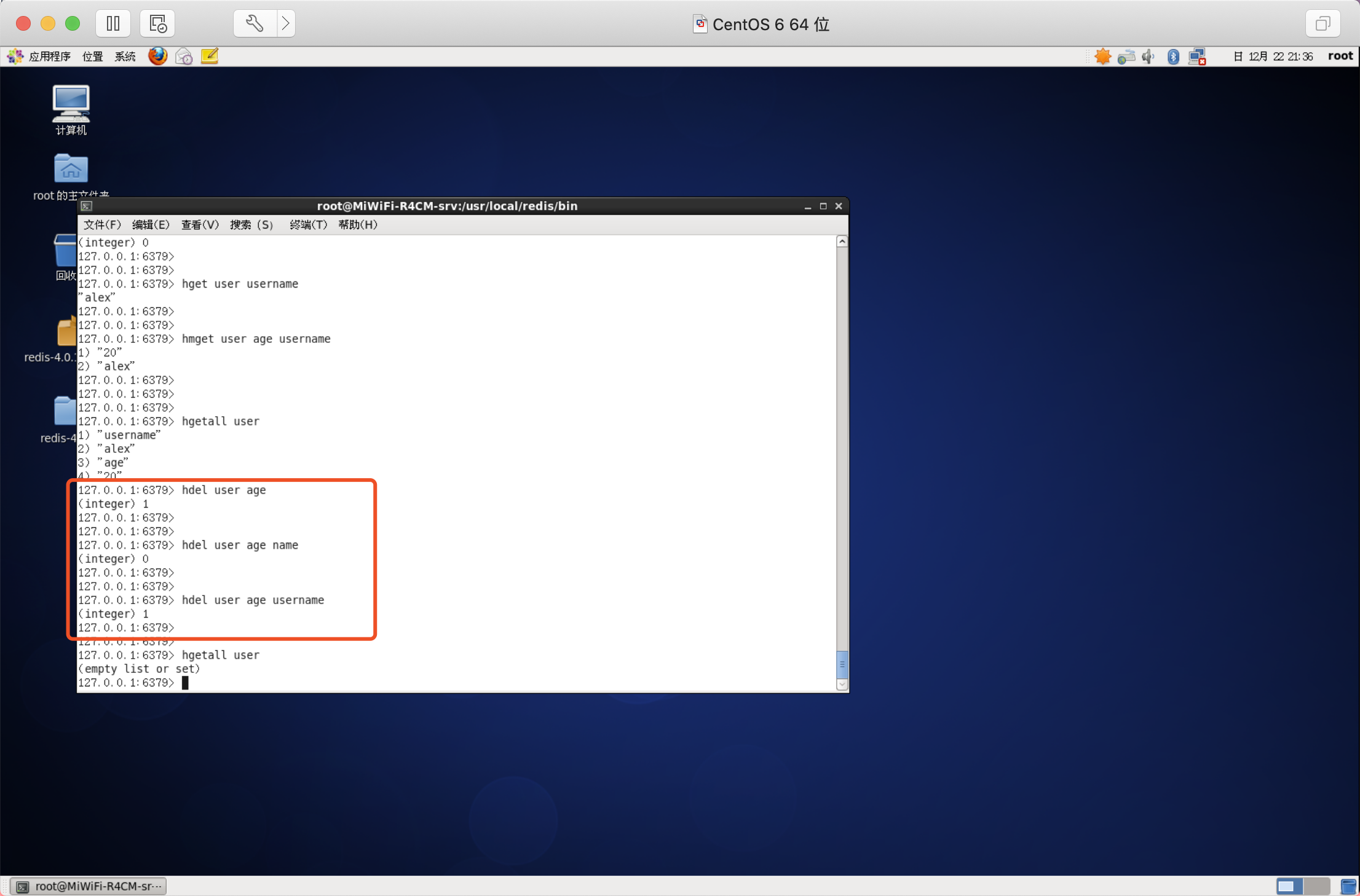
洗掉欄位
可以洗掉一個或多個欄位,回傳值是被洗掉的欄位個數
語法:HDEL key field [field ...]
增加數字
語法:HINCRBY key field increment
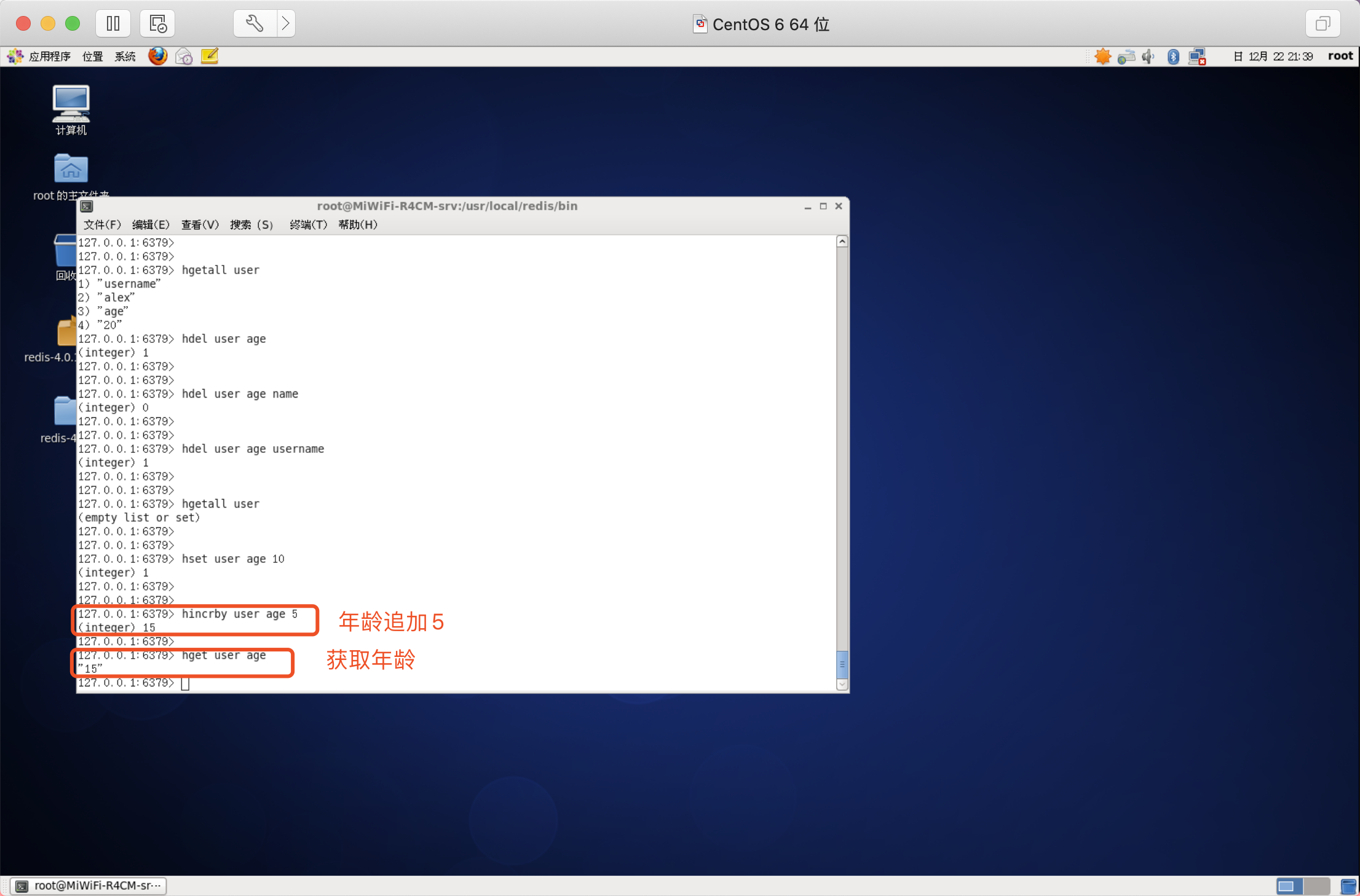
判斷欄位是否存在
語法:HEXISTS key field
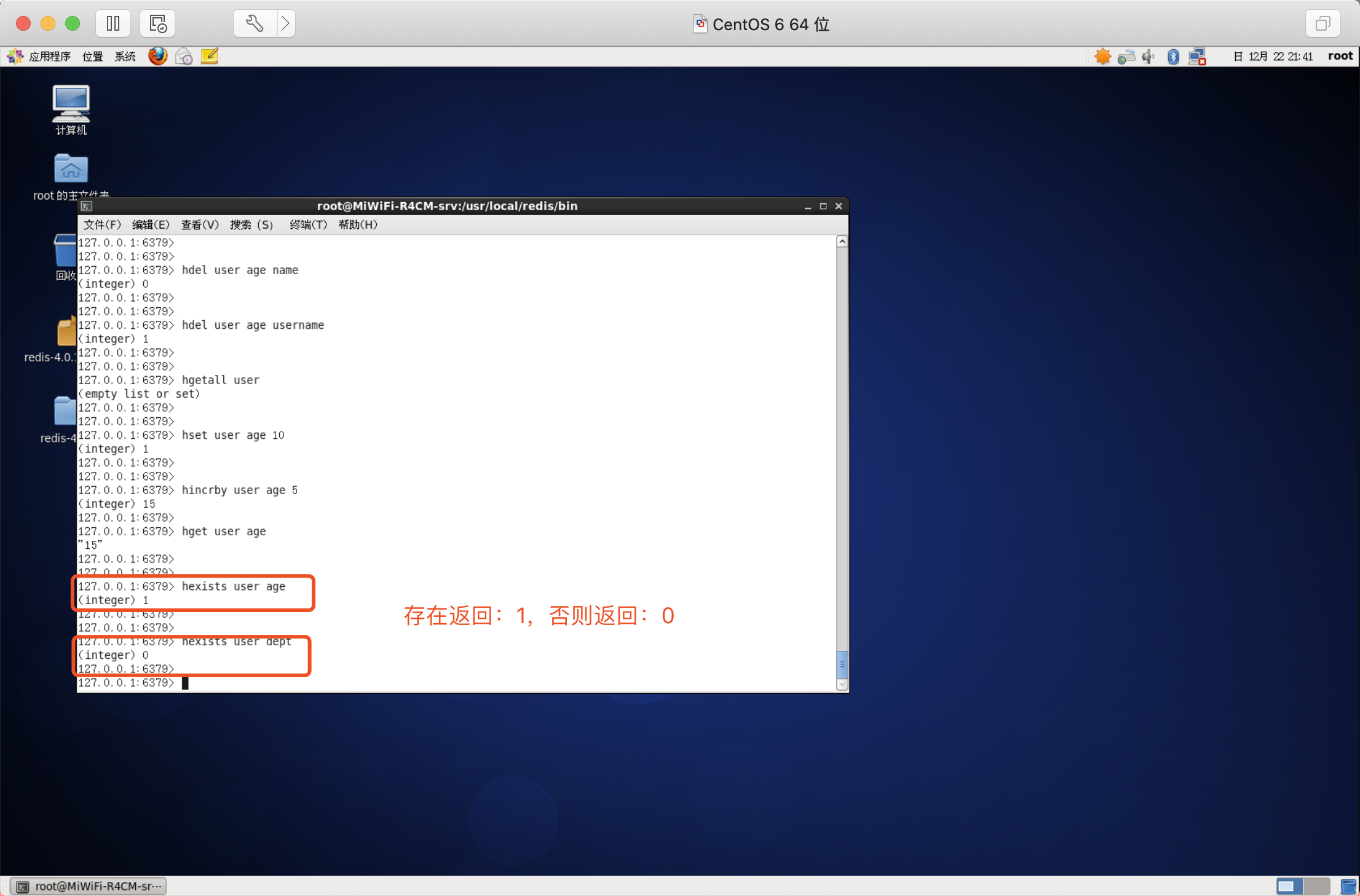
只獲取欄位名或欄位值
語法:
- HKEYS key
- HVALS key
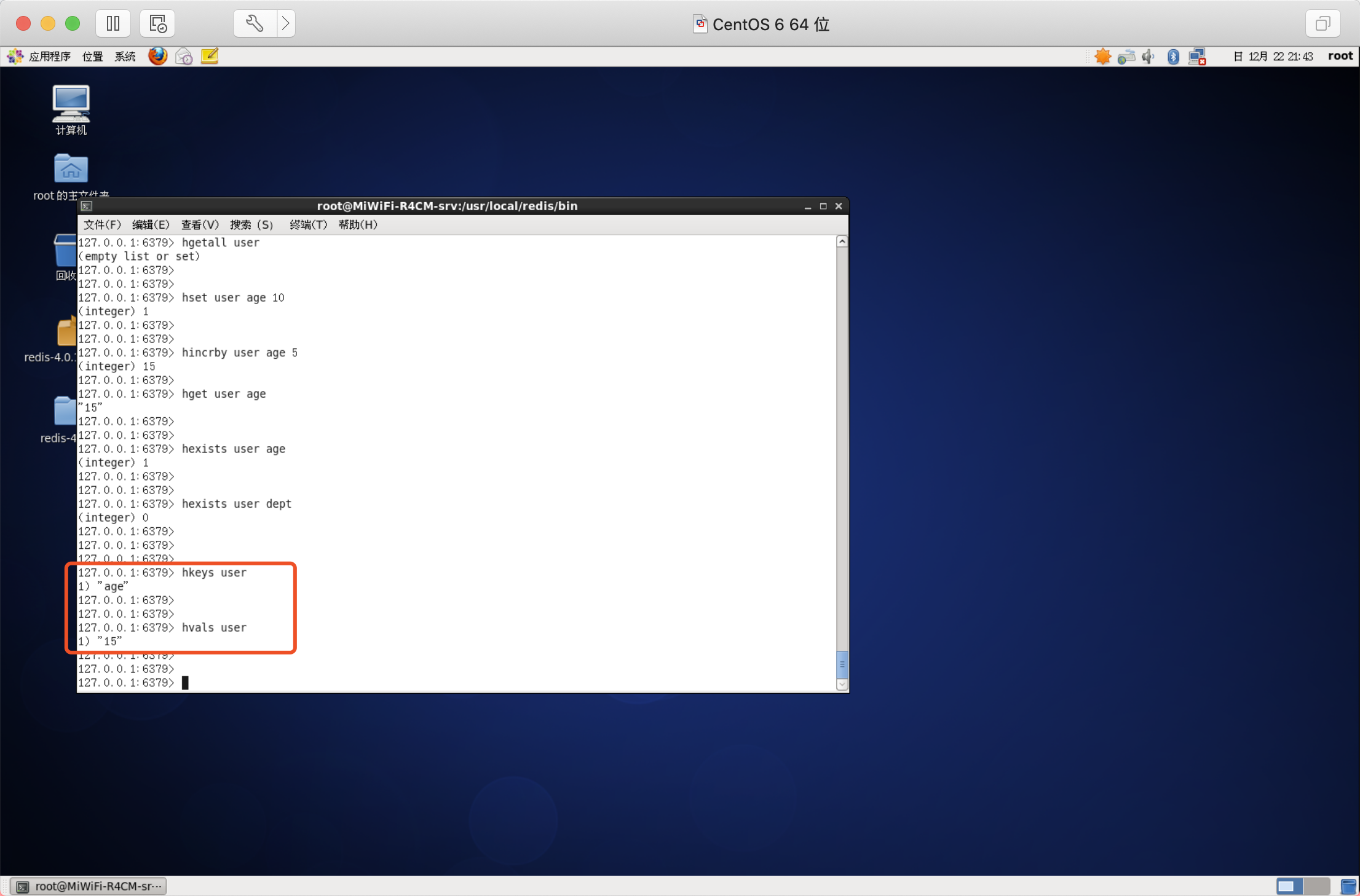
獲取欄位數量
語法:HLEN key
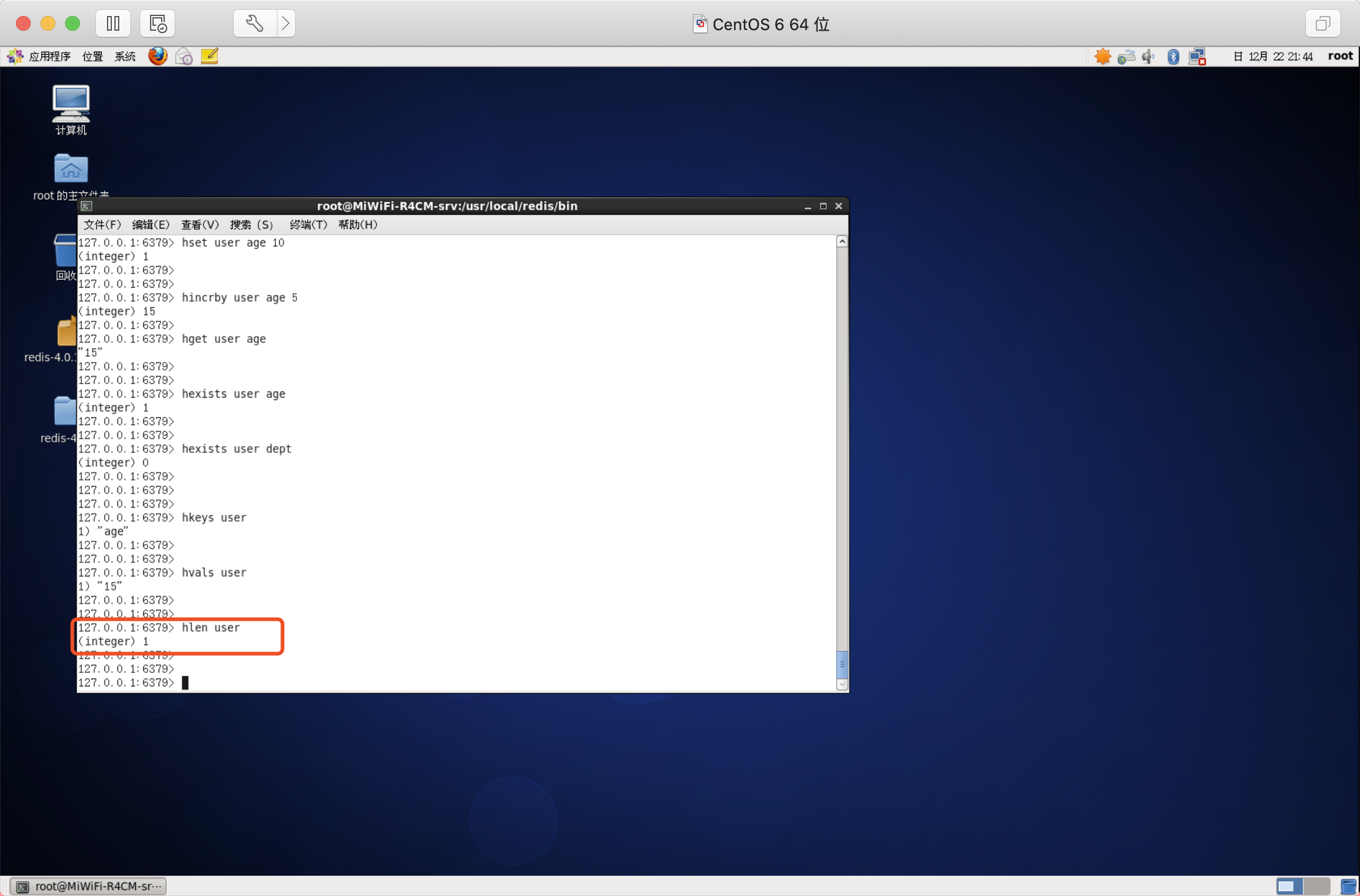
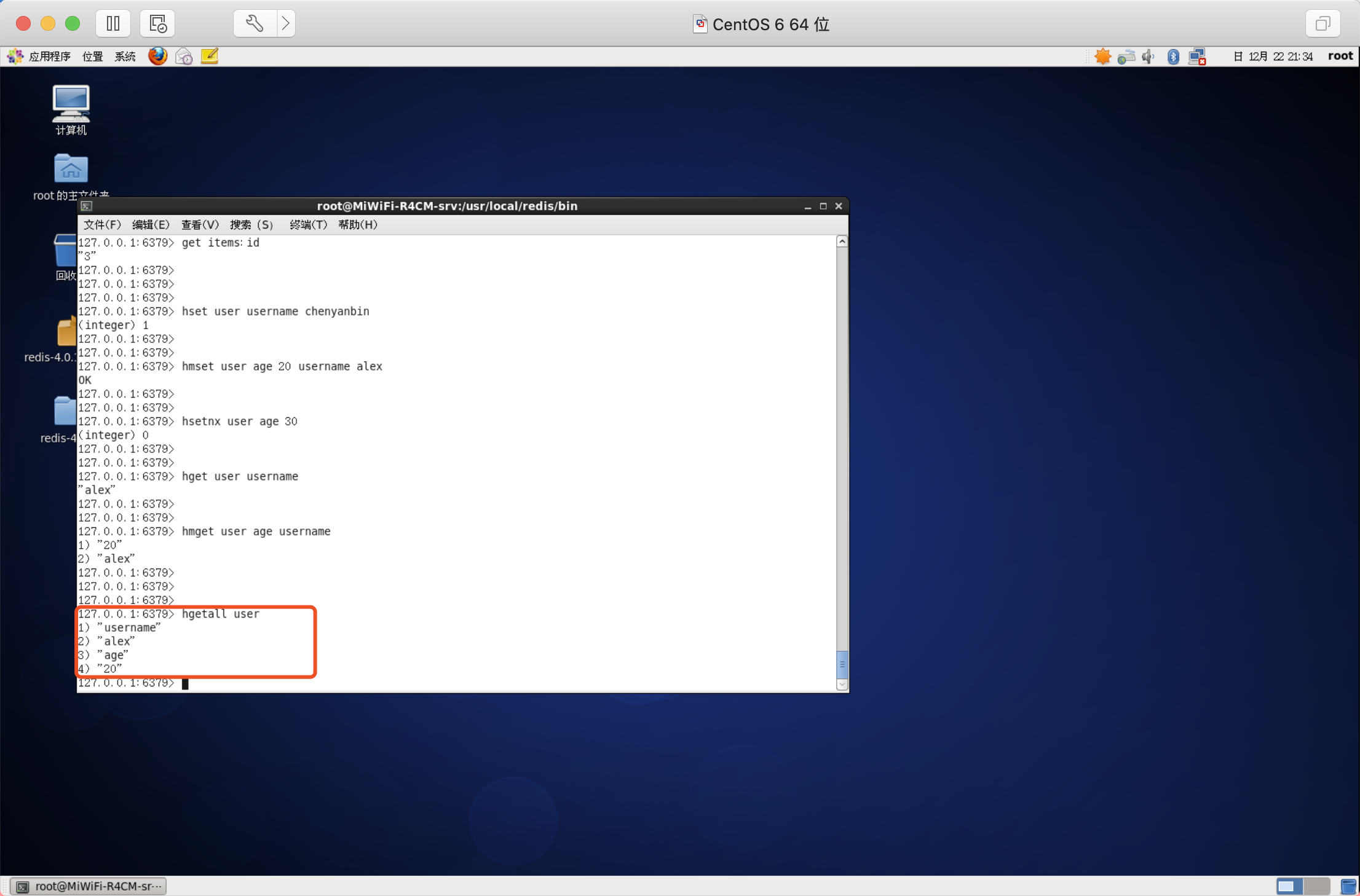
獲取所有欄位
作用:獲取hash的所有資訊,包括key和value
語法:hgetall key
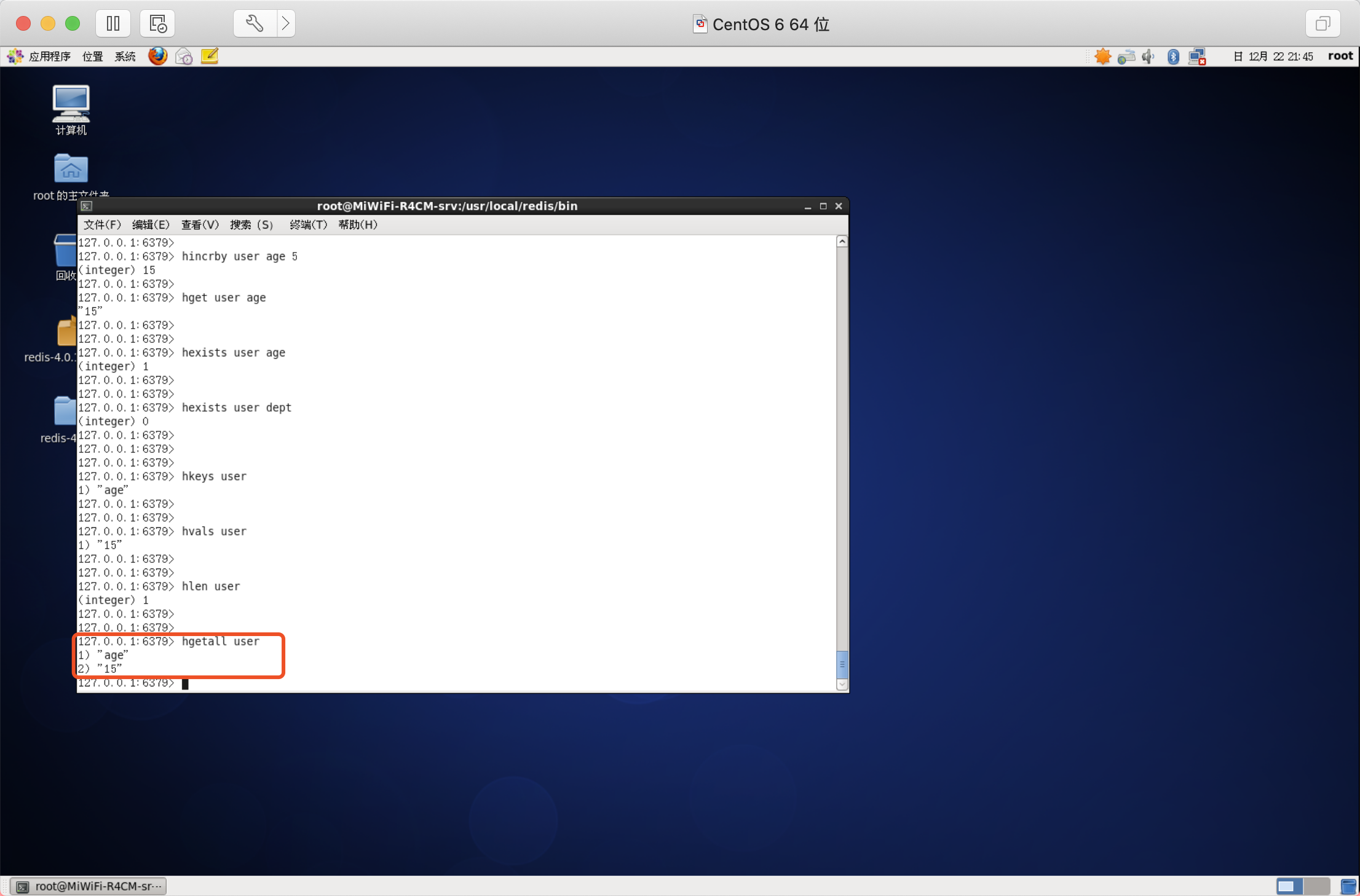
應用之存盤商品資訊
注意事項:存在哪些物件資料,特別是物件屬性經常發生增刪改操作的資料,
商品資訊欄位
【商品id,商品名稱,商品描述,商品庫存,商品好評】
定義商品資訊的key
商品id為1001的資訊在Redis中的key為:[items.1001]
示例
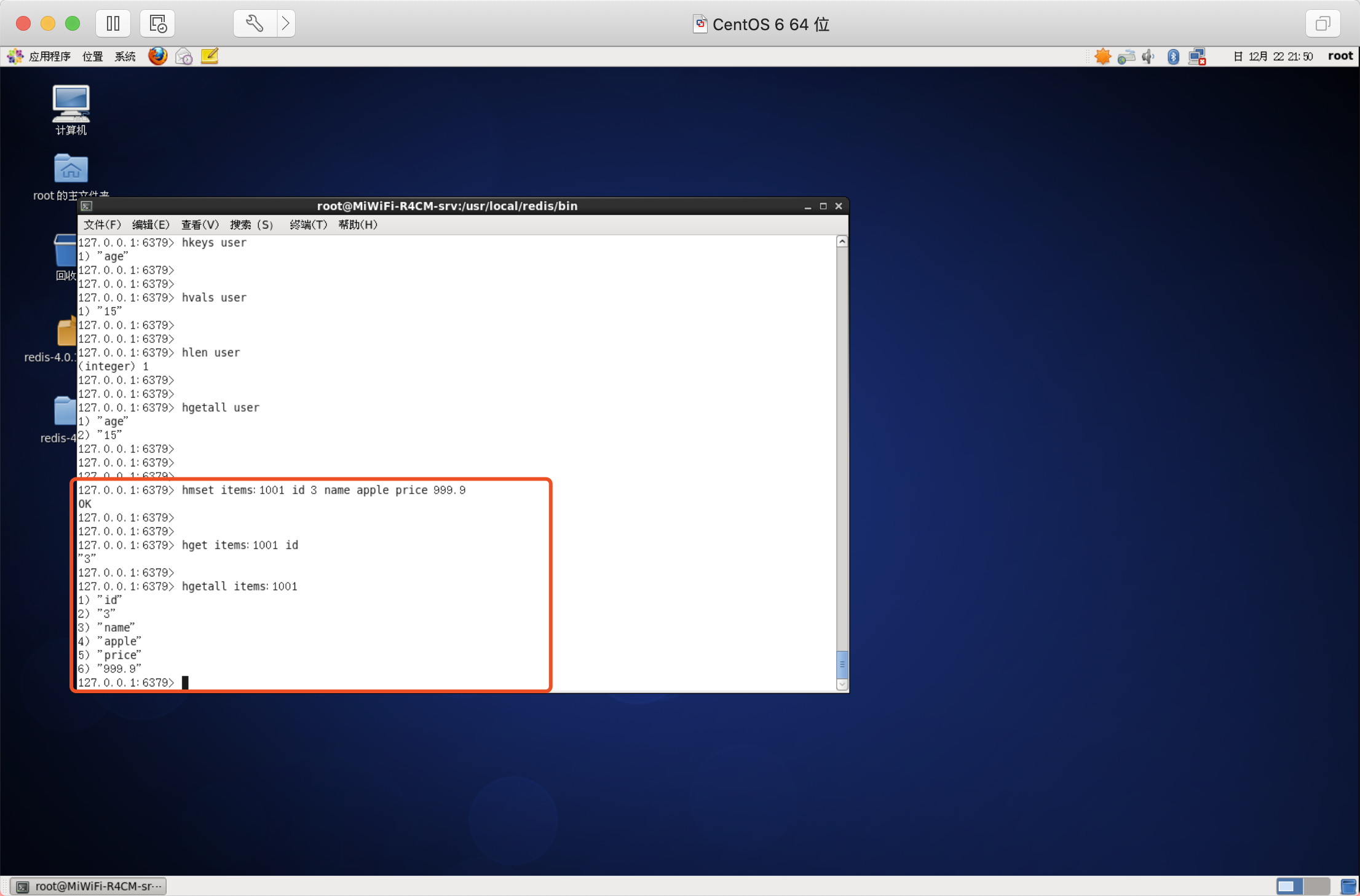
List型別
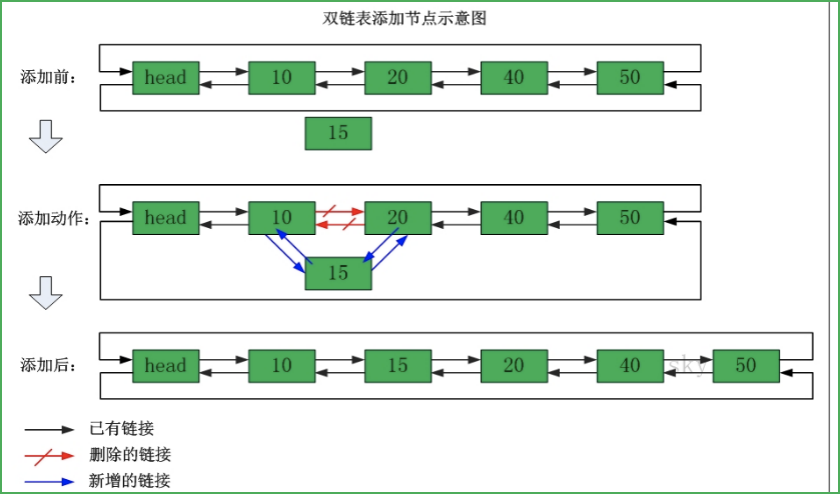
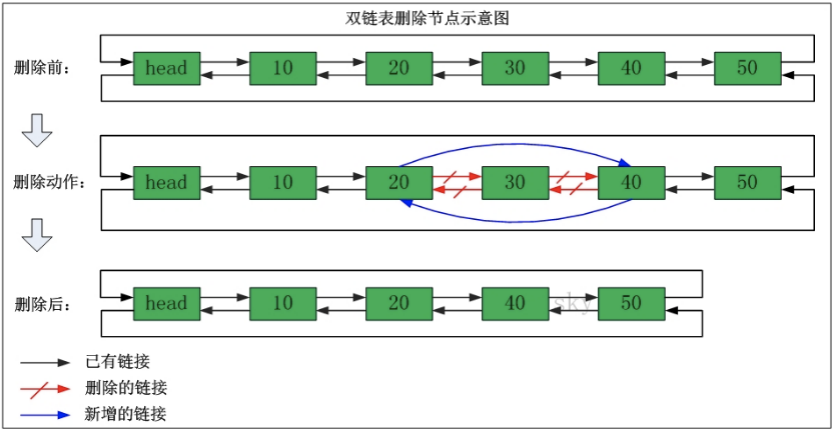
ArrayList使用陣列方式存盤資料,所以根據索引查詢資料速度快,而新增或者洗掉元素時需要涉及到位移操作,所以比較慢,
LinkedList使用雙向鏈表方式存盤資料,每個元素都記錄前后元素的指標,所以插入、洗掉資料時只是更改前后元素的指標即可,速度非常快,然后通過下標查詢元素時需要從頭開始索引,所以比較慢,但是如果查詢前幾個元素或后幾個元素速度比較快,
List介紹
Redis的串列型別(list)可以存盤一個有序的字串串列,常用的操作是向串列兩端添加元素,或者獲取串列的某一個片段,
串列型別內部是使用雙向鏈表(double linked list)實作的,所以向串列兩端添加元素的時間復雜度為0/1,獲取越接近兩端的元素速度就越快,意味著即使是一個有幾千萬個元素的串列,獲取頭部或尾部的10條記錄也是極快的,
向串列兩端添加元素
向串列左邊添加元素
語法:LPUSH key value [value ...]
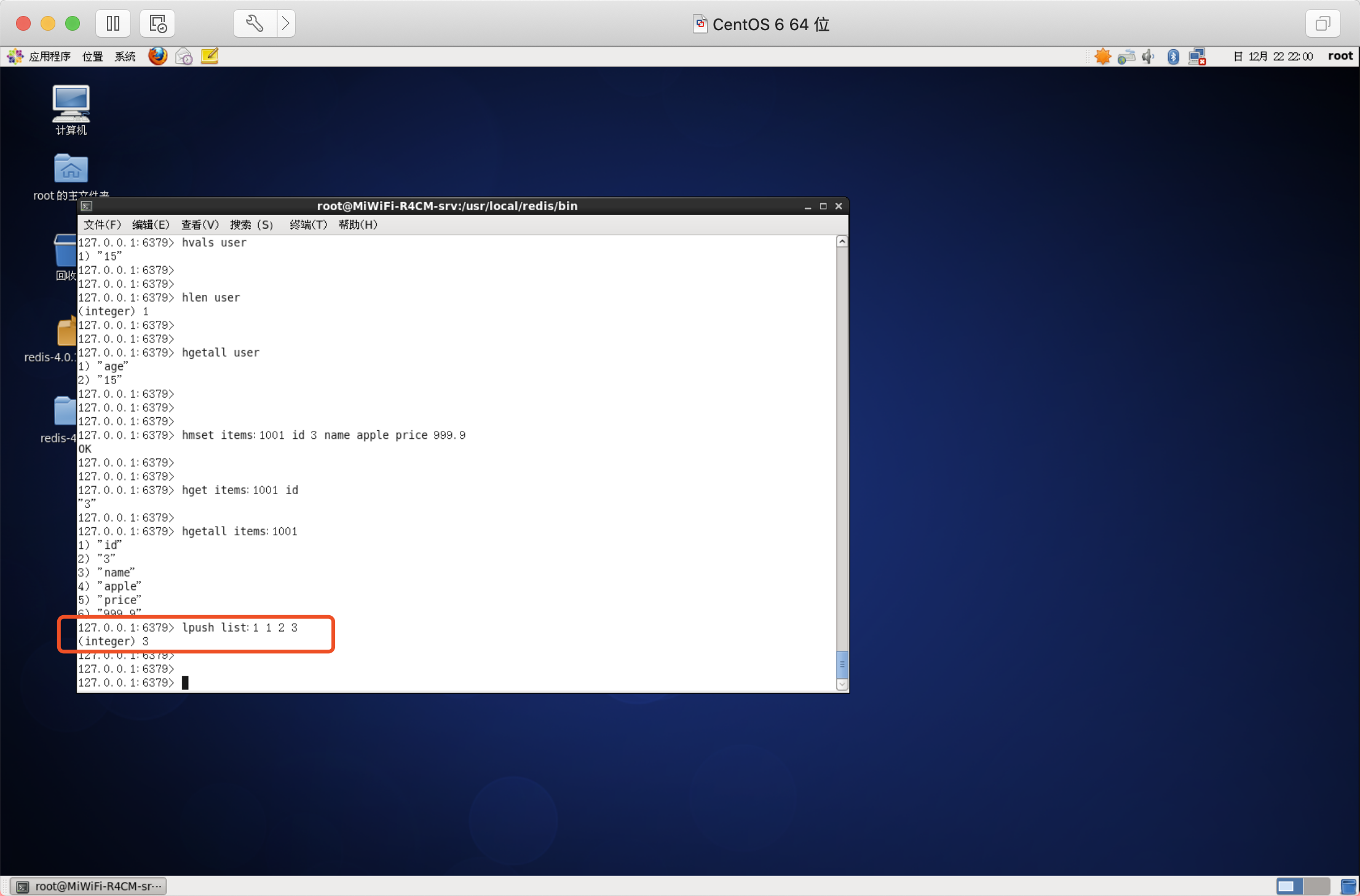
向串列右邊添加元素
語法:RPUSH key value [value ....]
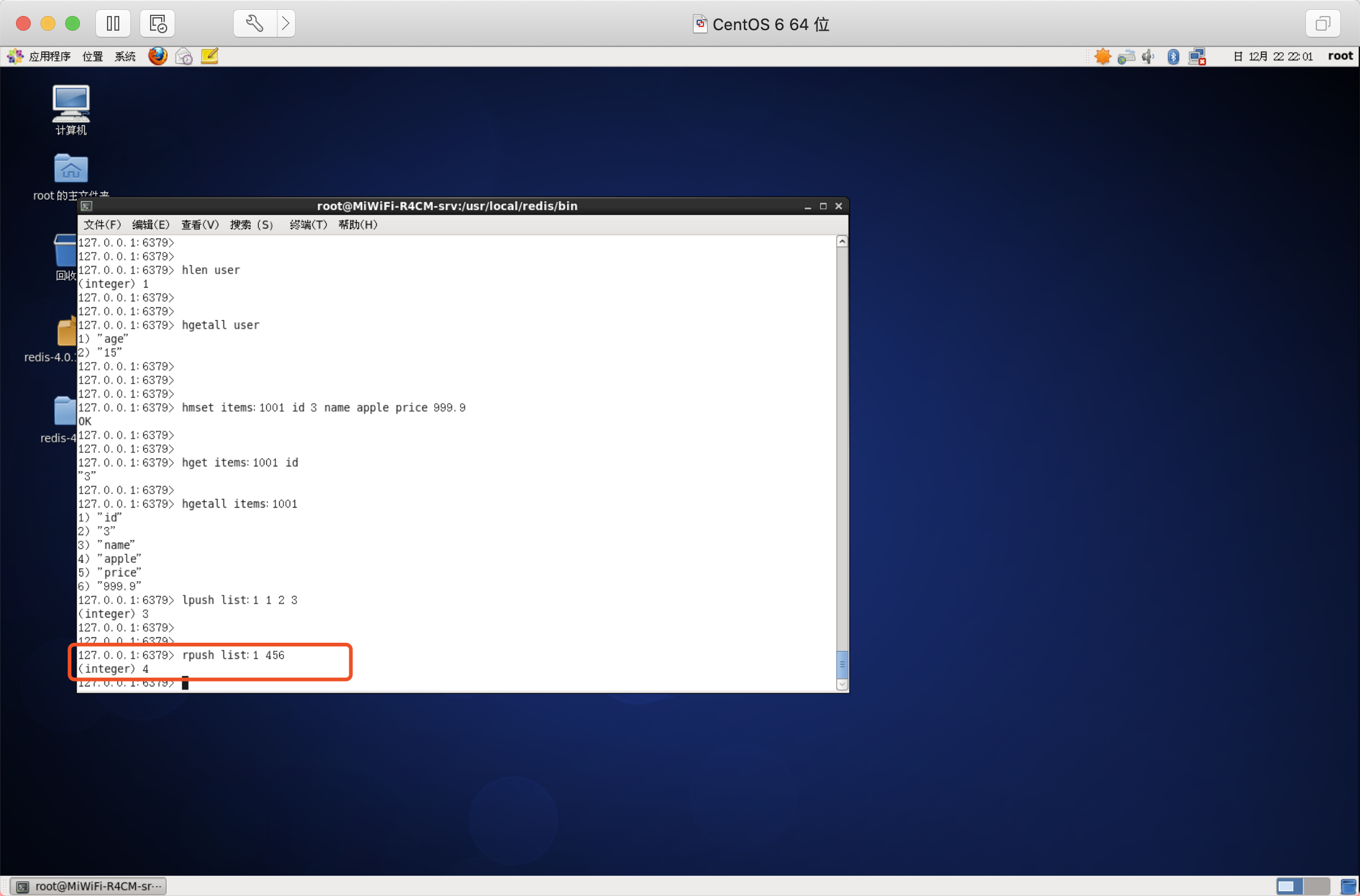
查看串列
語法:LRANGE key start stop
LRANGE命令是串列型別最常用的命令之一,獲取串列中的某一片段,將回傳start、stop之間的所有元素(包括兩端的元素),索引從0開始,索引可以是負數,“-1”代表最后一邊的一個元素
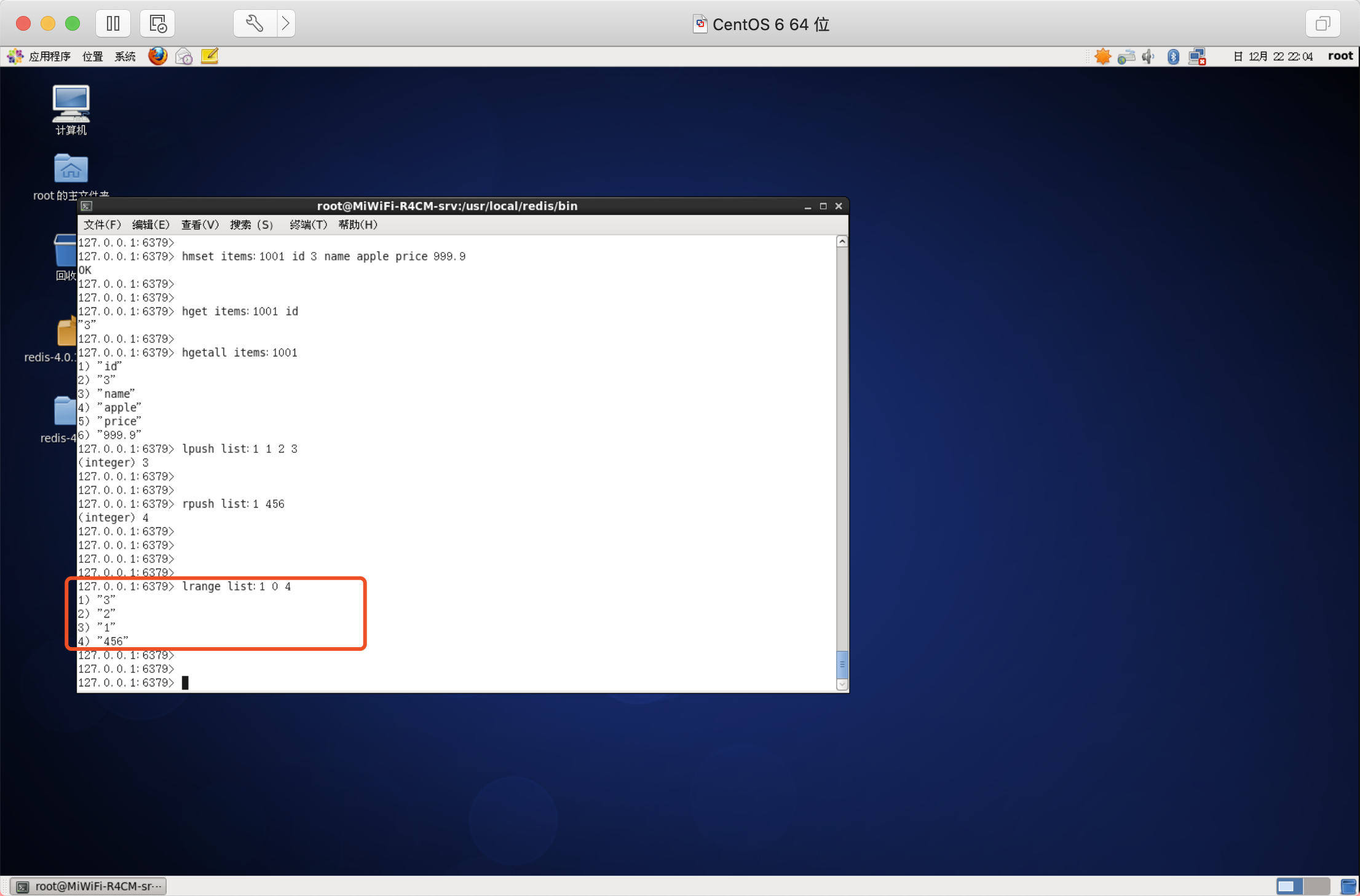
從串列兩端彈出元素
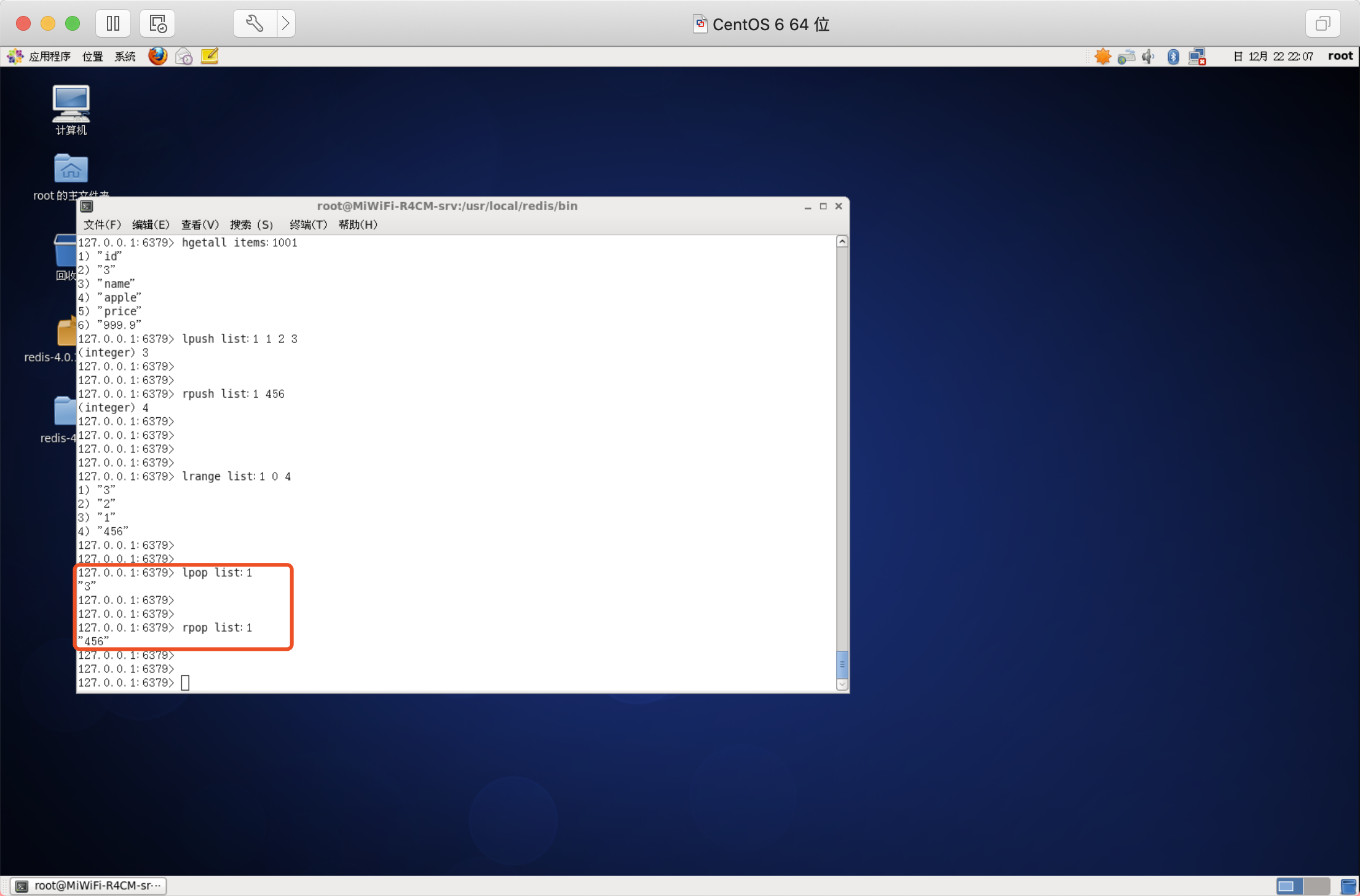
LPOP命令從串列左邊彈出一個元素,會分兩步完成:
- 將串列左邊的元素從串列中移除
- 回傳被移除的元素值
語法:
- LPOP key
- RPOP key
獲取串列中元素的個數
語法:LLEN key 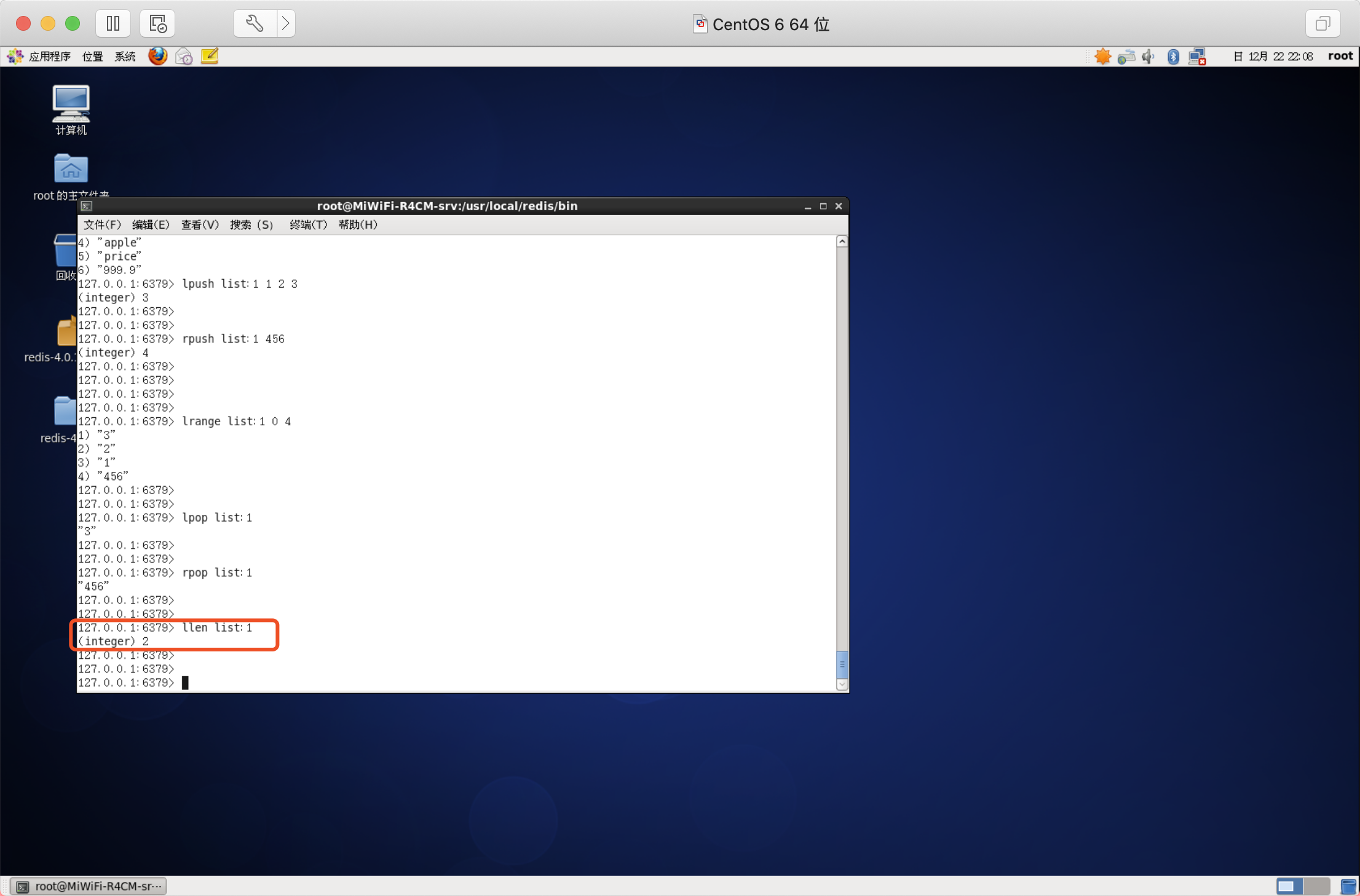
洗掉串列中指定個數的值
LREM命令會洗掉串列中前count個數為value的元素,回傳實際洗掉的元素個數,根據count值不同,該命令的執行方式會有所不同,
語法:LREM key count value
- 當count>0時,LREM會從串列左邊開始洗掉
- 當count<0時,LREM會從串列右邊開始洗掉
- 當count=0時,LREM會洗掉所有值為value的元素
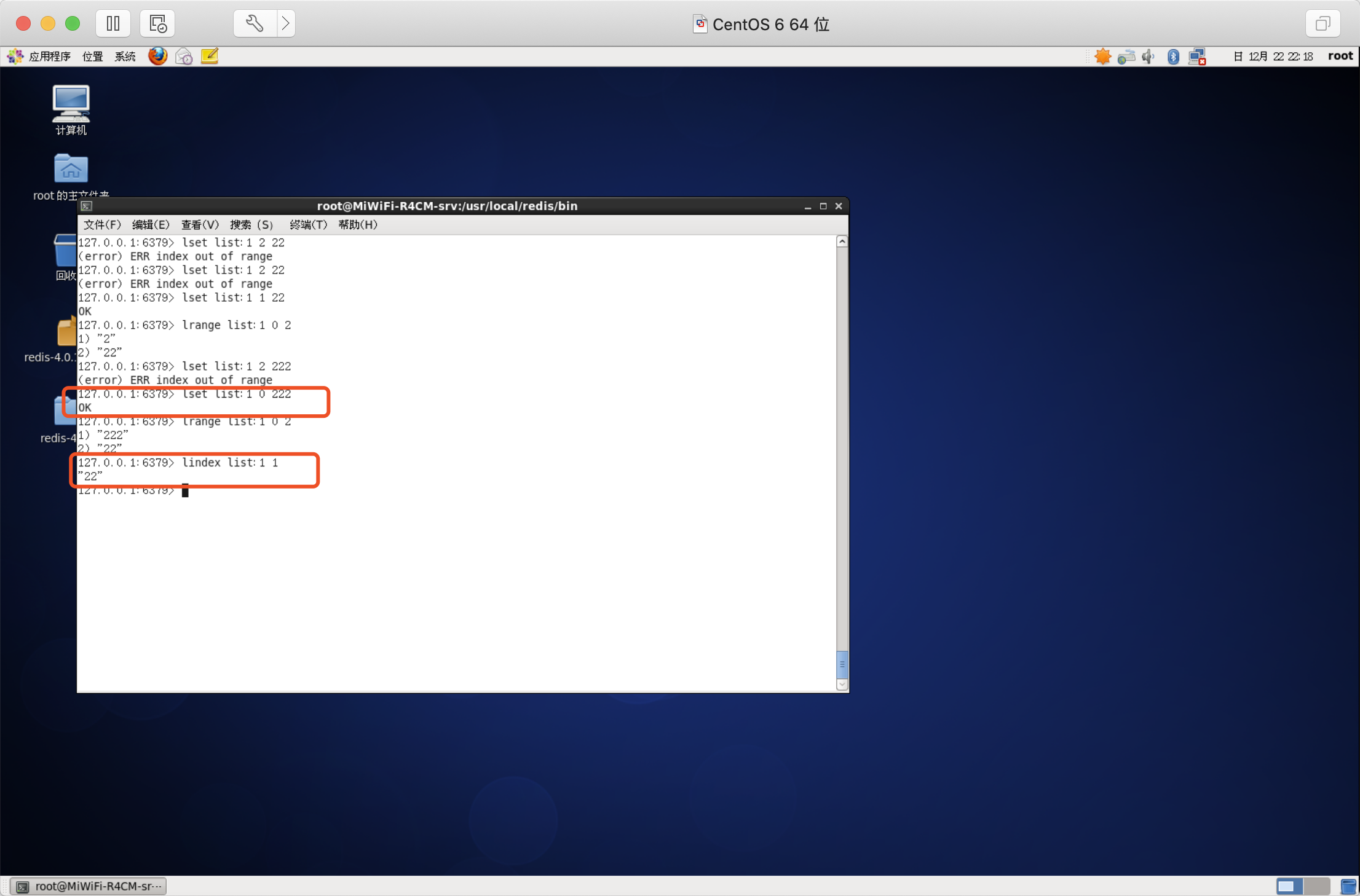
獲取/設定指定索引的元素值
獲取指定索引的元素值
語法:LINDEX key index
設定指定索引的元素值
語法:LSET key index value
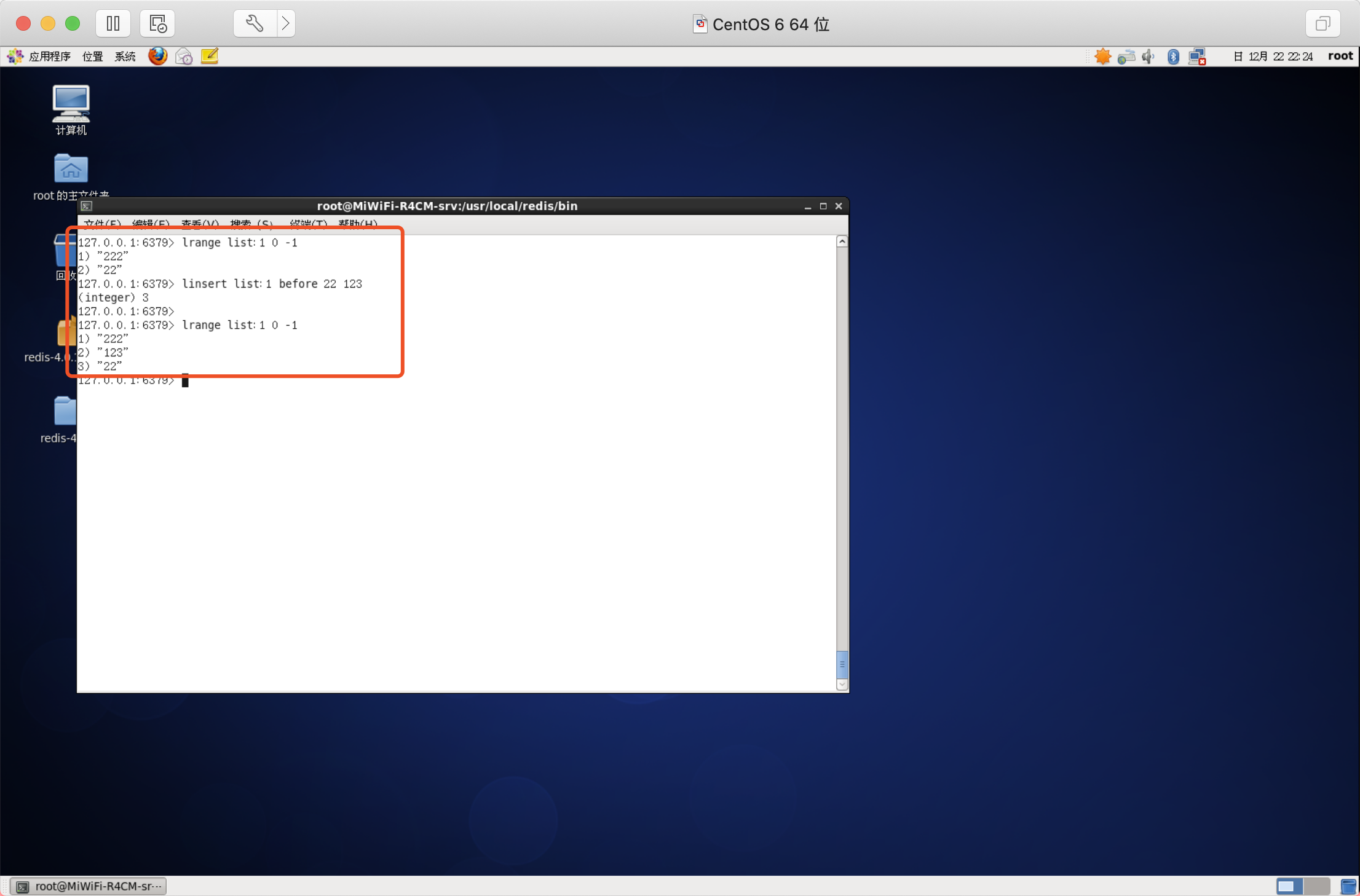
向串列中插入元素
該命令首先會在串列中從左到右查詢值為pivot的元素,然后根據第二個引數是BEFORE還是AFTER來決定將value插入到該元素的前面還是后面,
語法:LINSERT key BEFORE|AFTER pivot value
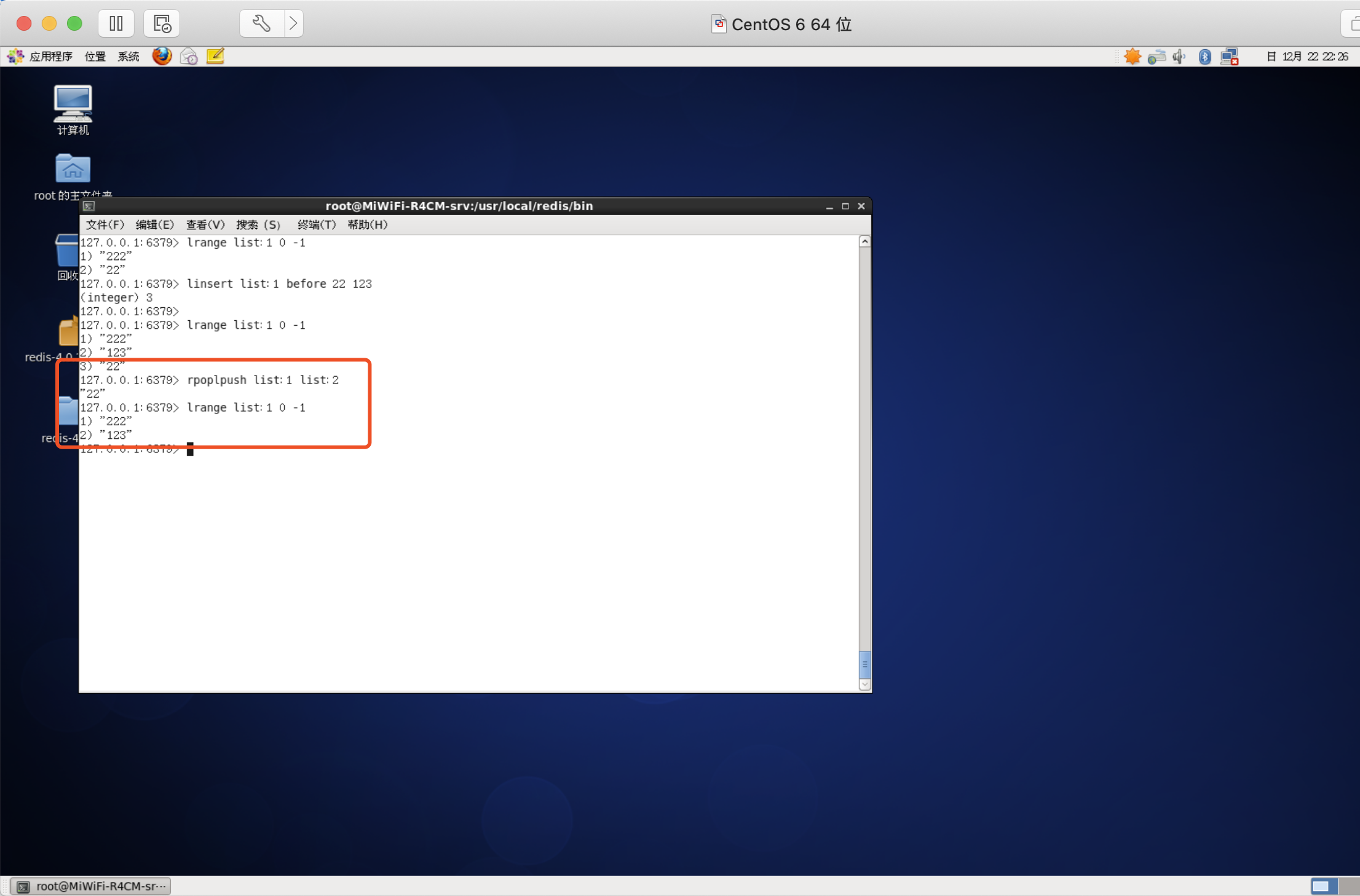
將元素從一個串列轉移到另一個串列中
語法:RPOPLPUSH source destination
應用之商品評論串列
需求1:用戶針對某一商品發布評論,一個商品會被不同的用戶進行評論,存盤商品評論時,要按時間順序排序,
需要2:用戶在前端頁面查詢該商品的評論,需要按照時間順序降序排序,
思路:
使用list存盤商品評論資訊,key是該商品的id,value是商品評論資訊商品編號為1001的商品評論key【items:comment:1001】 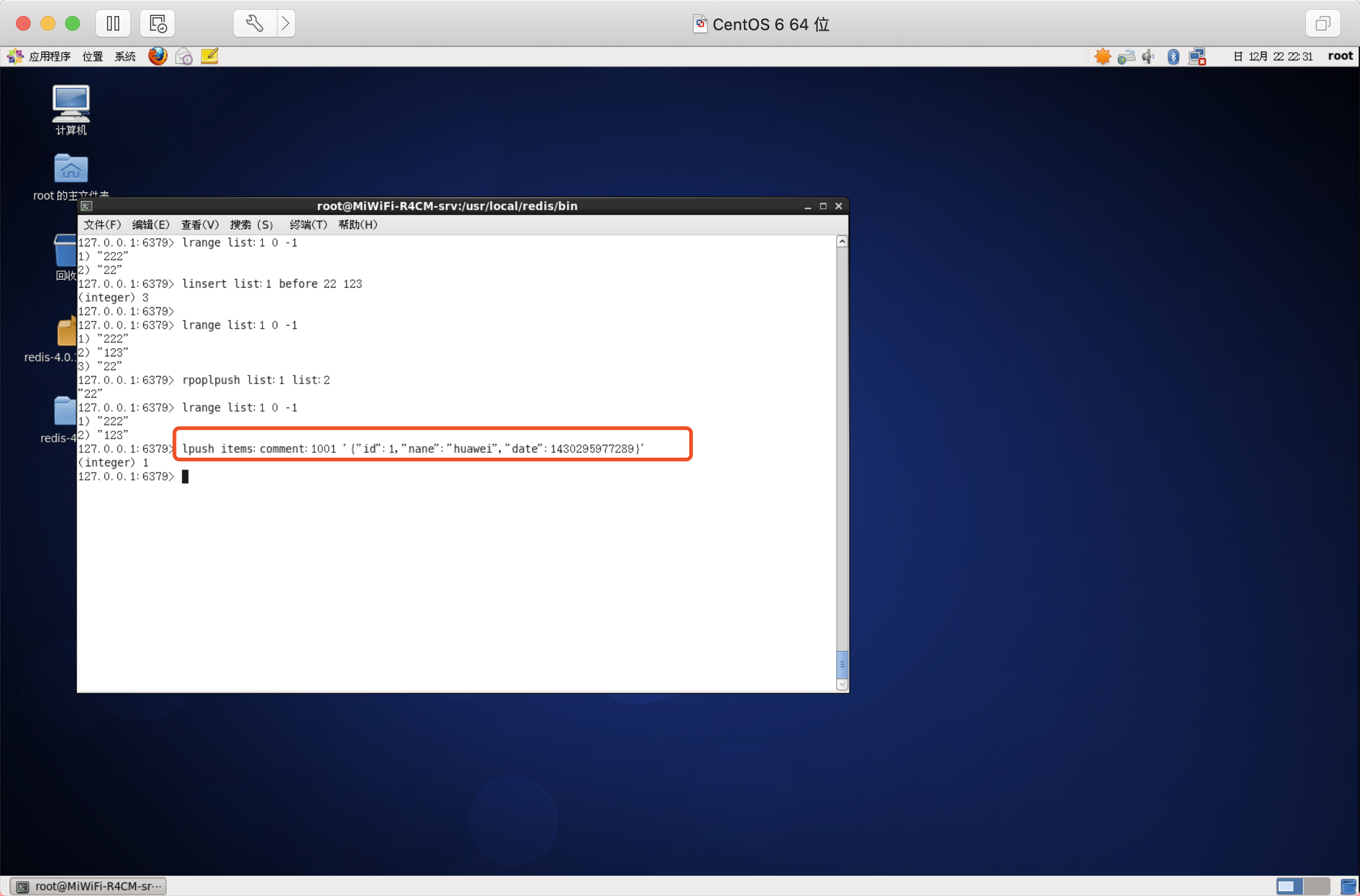
Set型別
set型別即集合型別,其中的資料時不重復且沒有順序,
集合型別和串列型別的對比:

集合型別的常用操作是向集合中加入或洗掉元素、判斷某個元素是否存在等,由于集合型別的Redis內部是使用值為空散列標實作,所有這些操作的時間復雜度都為0/1,
Redis還提供了多個集合之間的交集、并集、差集的運算,
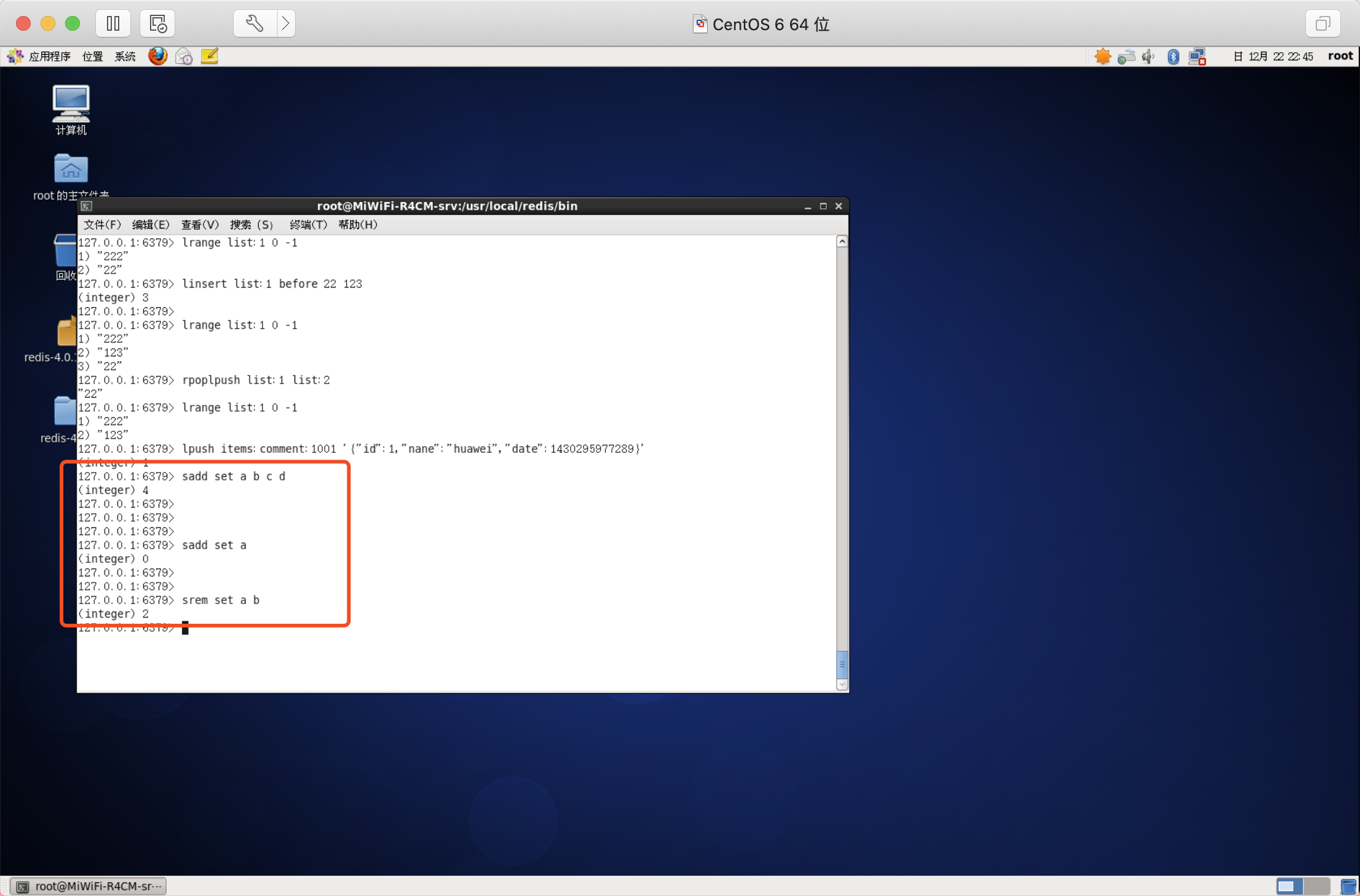
添加/洗掉元素
語法:SADD key member [member ...]
語法:SREM key member [member ...]
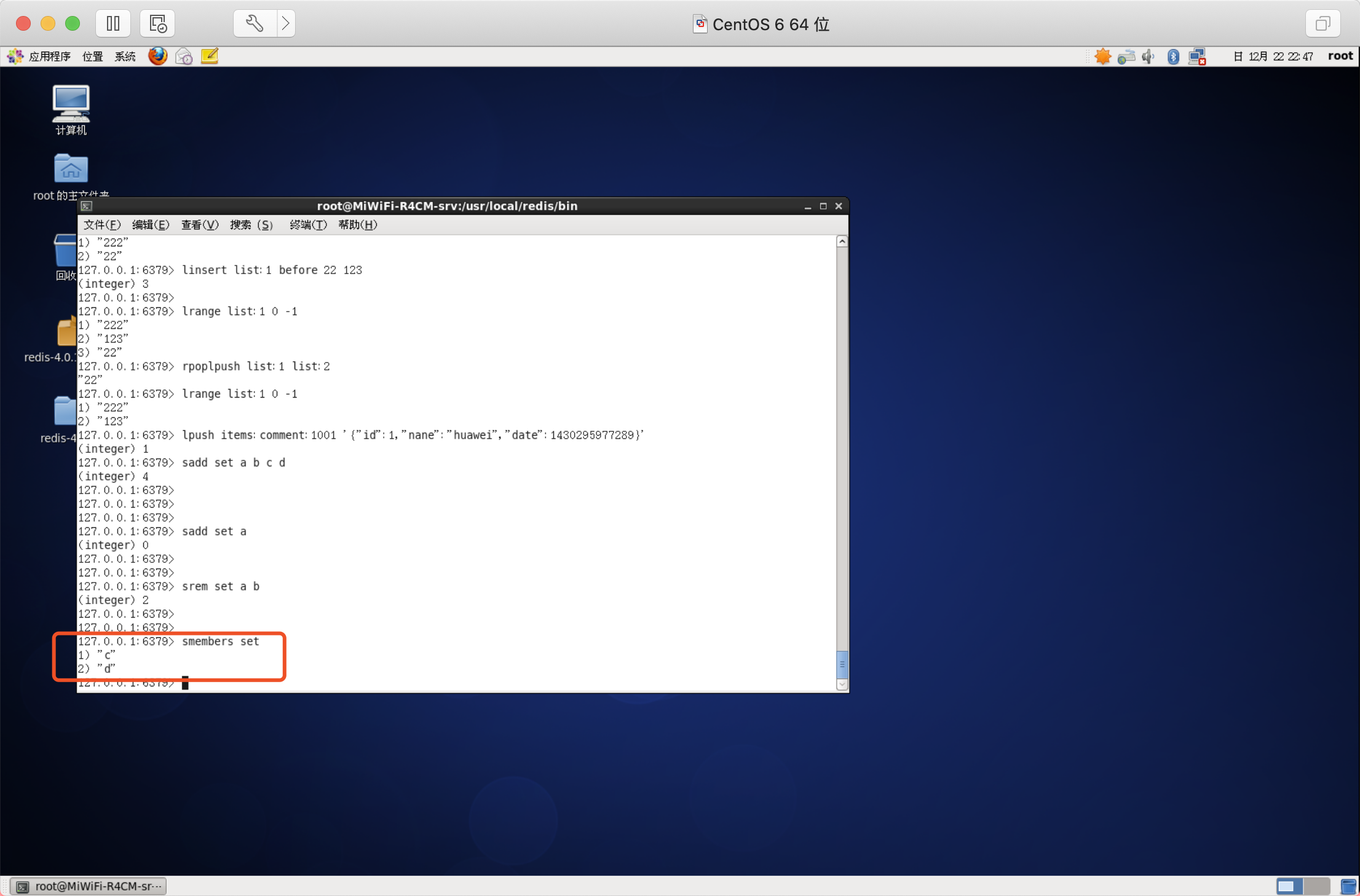
獲取集合中的所有元素
語法:SMEMBERS key
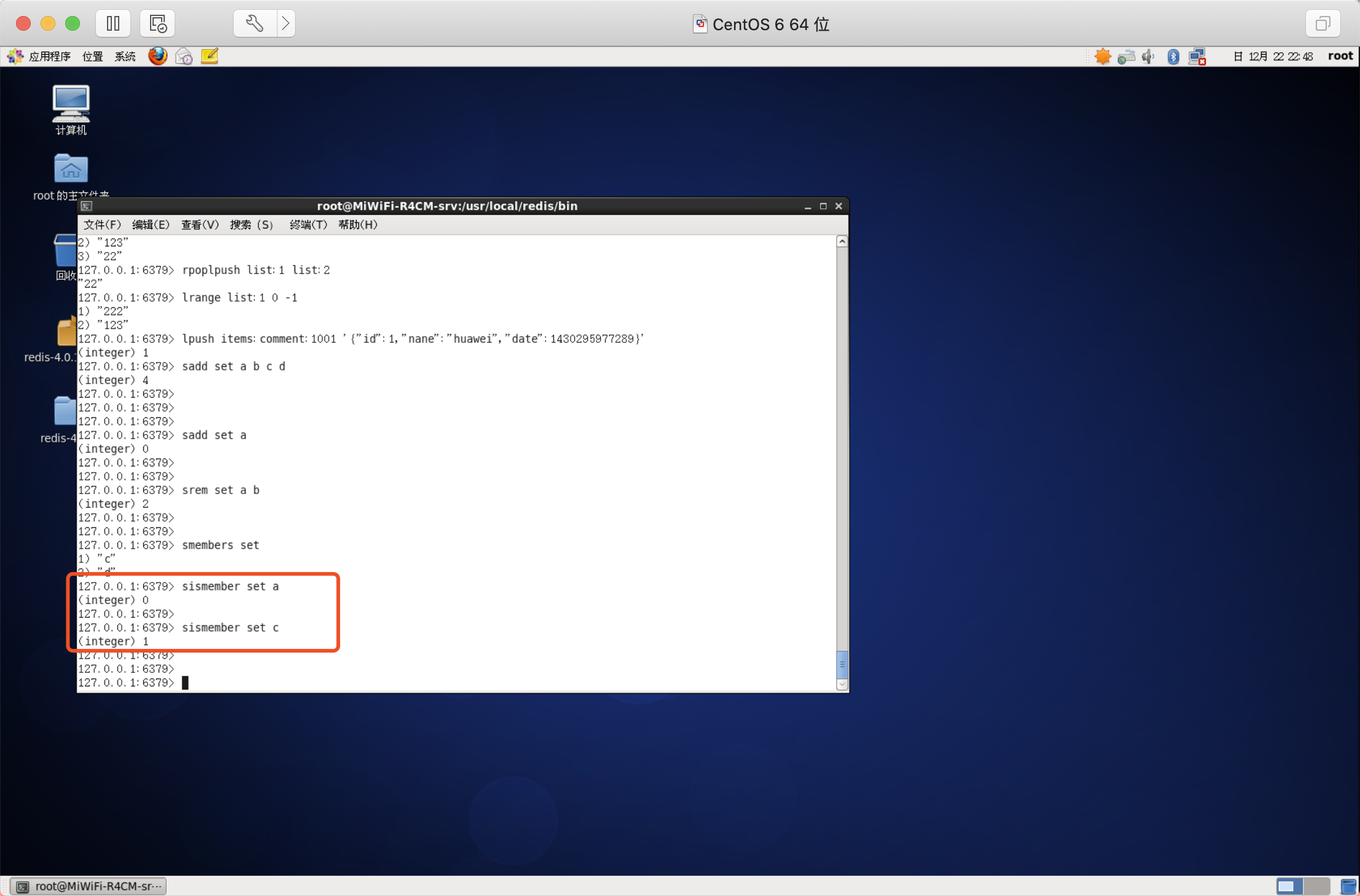
判斷元素是否在集合中
語法:SISMEMBER key member
集合運算命令
集合的差集運算 A-B
屬于A并且不屬于B的元素構成的集合
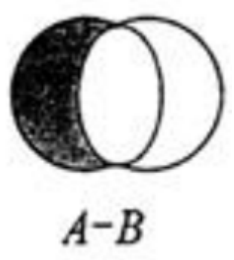
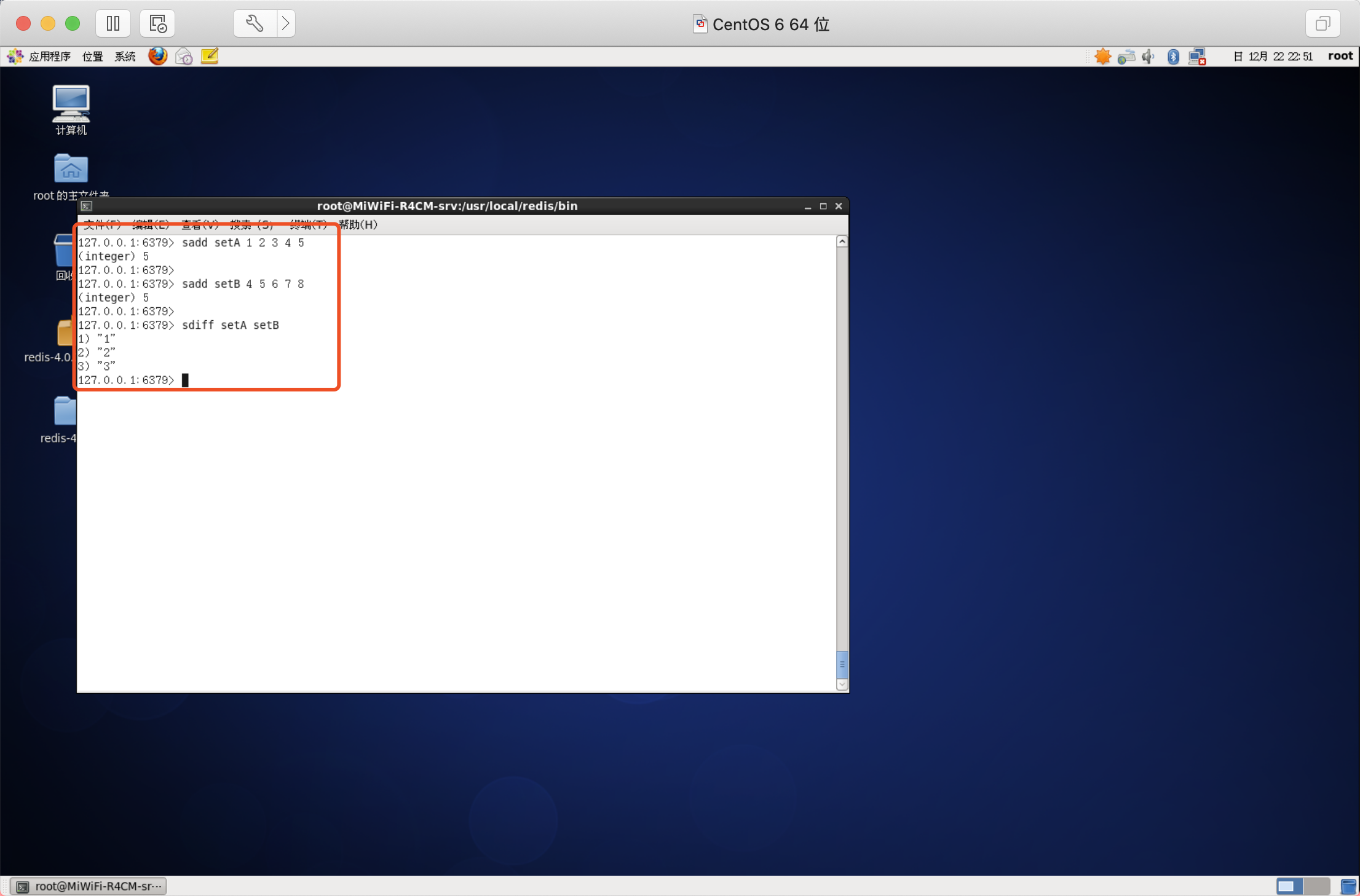
語法:SDIFF key [key ...]
集合的交集運算 A∩B
屬于A且屬于B的元素構成的集合,
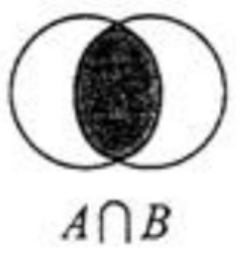
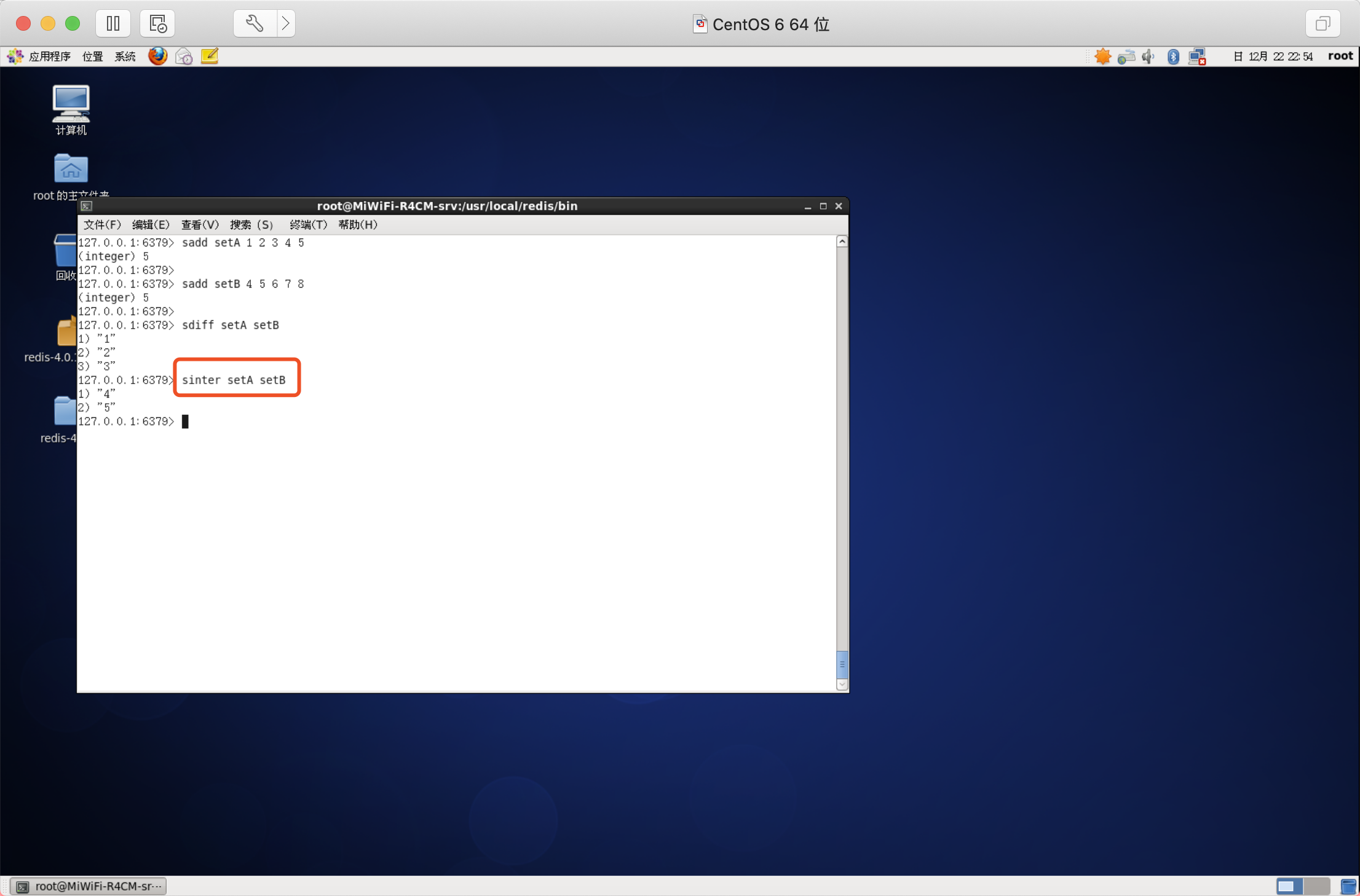
語法:SINTER key [key ...]
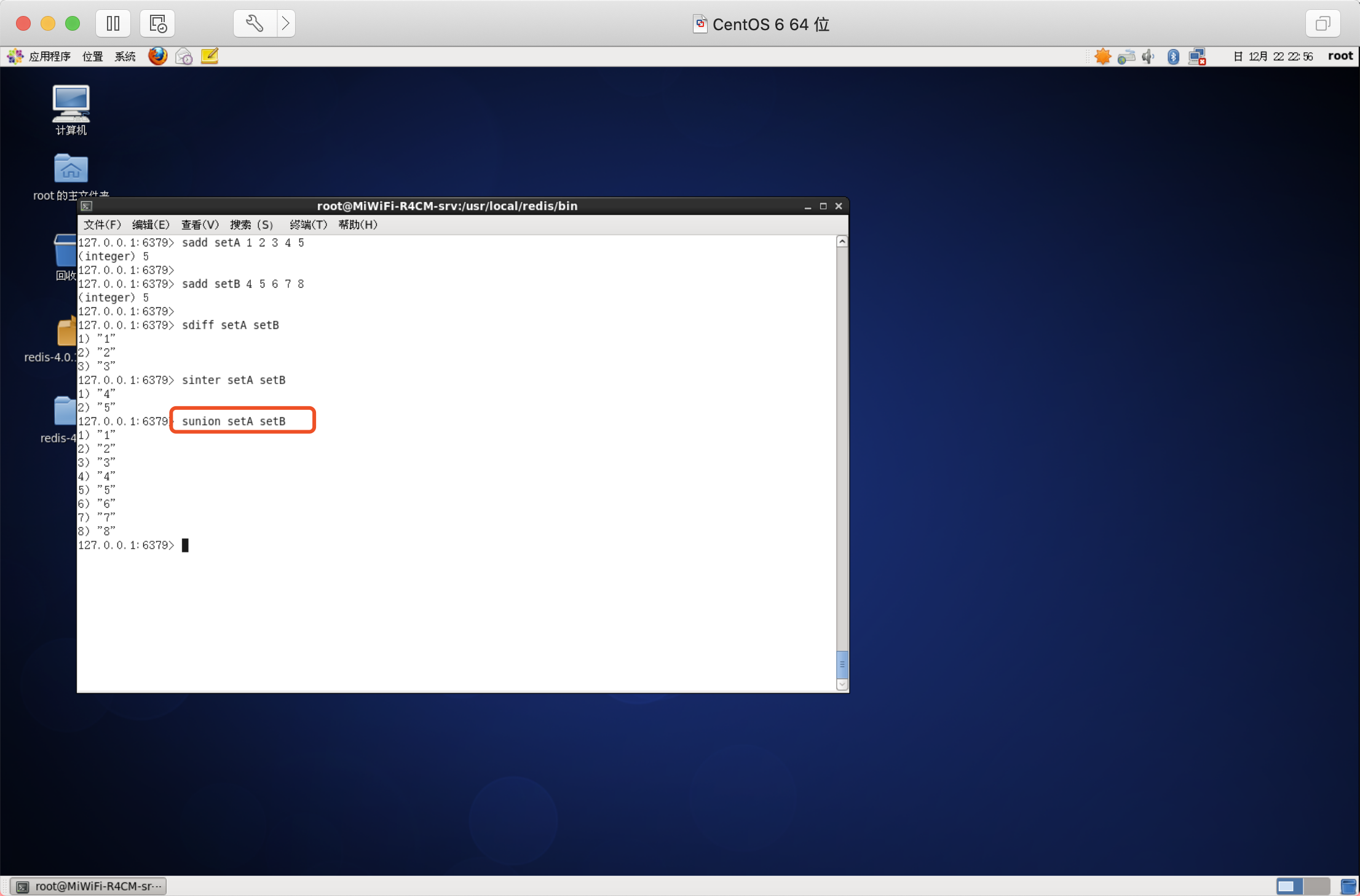
集合的并集運算 A ∪ B
屬于A或者屬于B的元素構成的集合

語法:SUNION key [key ...]
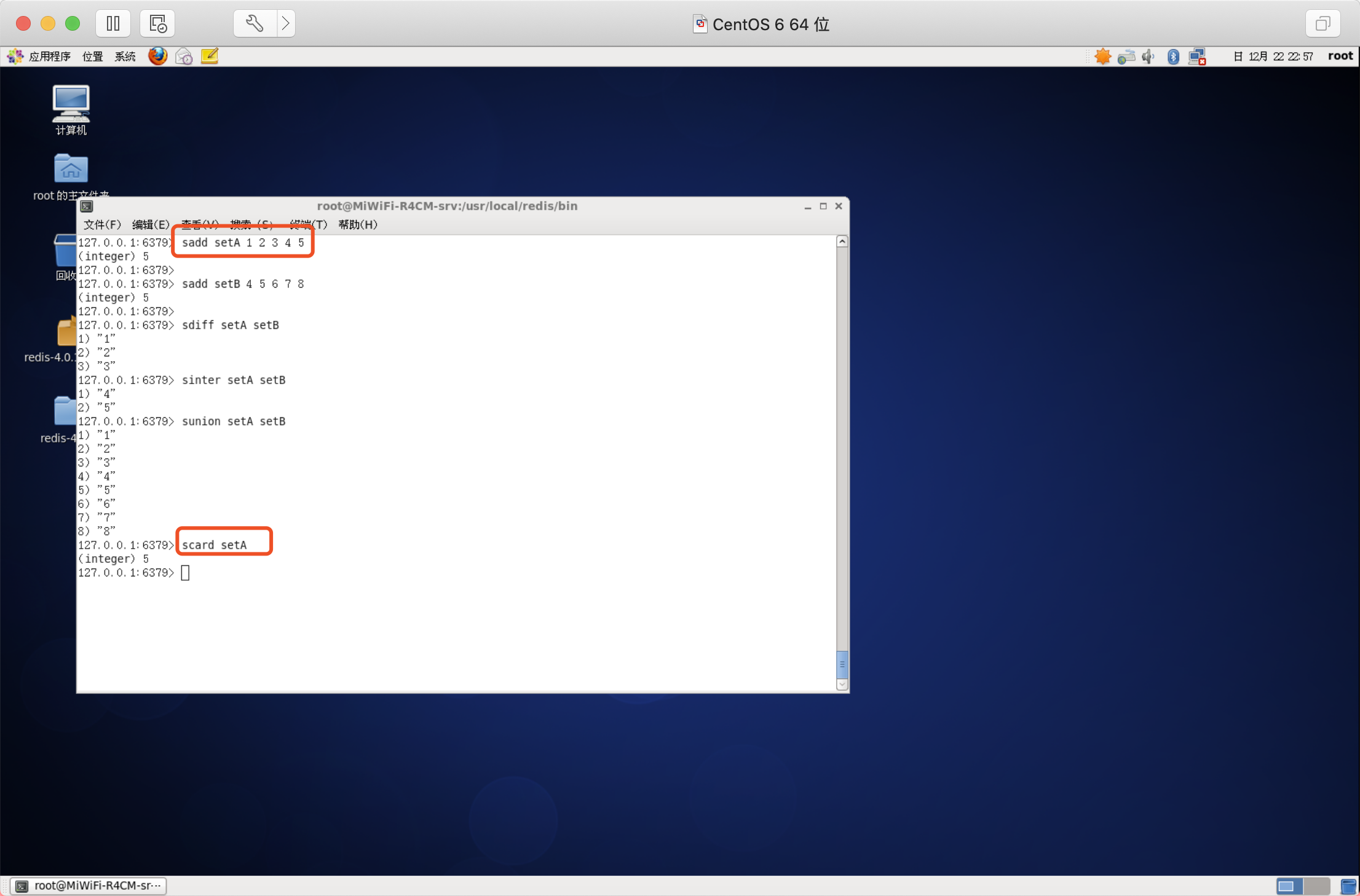
獲取集合中的元素個數
語法:SCARD key
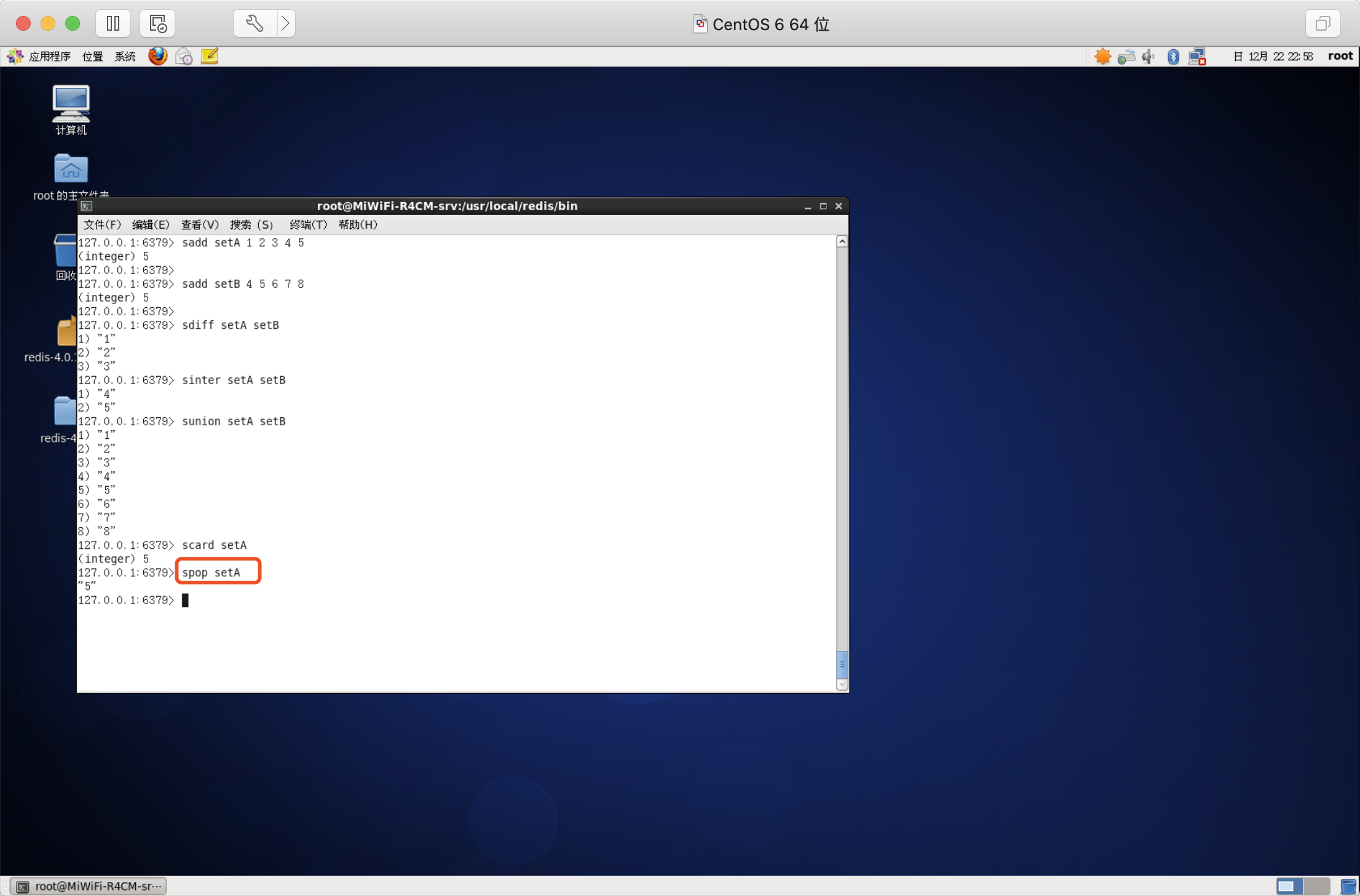
從集合中彈出一個元素
注意:集合是無序的,所有spop命令會從集合中隨機選擇一個元素彈出
語法:SPOP key
SortedSet型別zset
在集合型別的基礎上,有序集合為集合中的每個元素都關聯一個分數,這使得我們不僅可以完成插入、洗掉和判斷元素是否存在集合中,還能夠獲得最高或最低的前N個元素、獲取指定分數范圍內的元素等與分蘇有關的操作,
在某些方面有序集合和串列型別有些相似,
- 二者都是有序的,
- 二者都可以獲得某一范圍的元素
但是二者有著很大的區別:
- 串列型別是通過鏈表實作的,后去靠近兩端的資料速度極快,而當元素增多后,訪問中間資料的速度會變慢,
- 有序集合型別使用散列實作,所有即使讀取位于中間部分的資料也很快,
- 串列中不能簡單的調整某個元素的位置,但是有序集合可以(通過更改分數實作),
- 有序集合要比串列型別更耗記憶體,
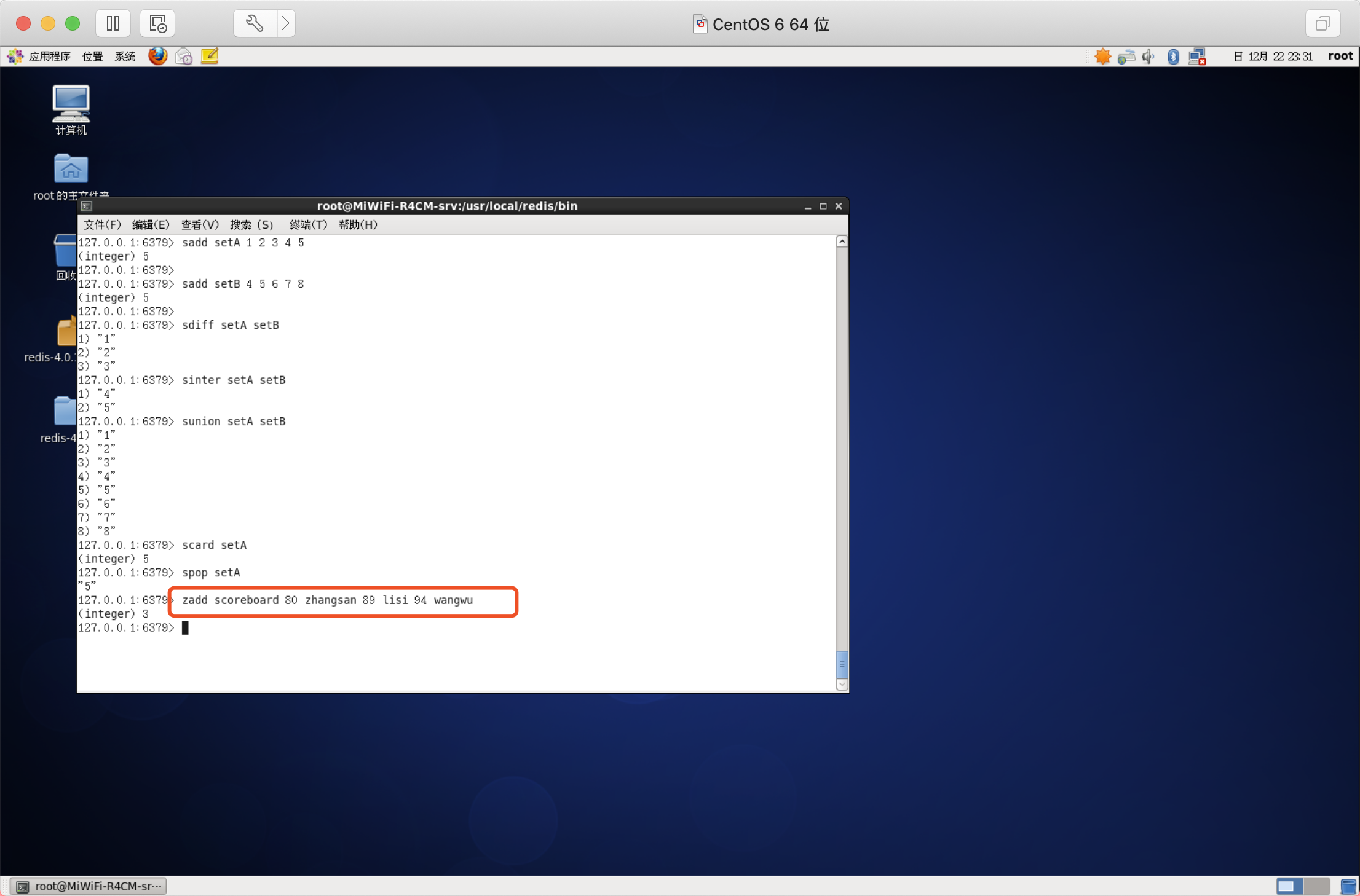
添加元素
向有序集合中加入一個元素和該元素的分數,如果該元素已經存在則會用新的分數替換原有的分數,回傳值是新加入到集合中的元素個數,不不含之前已經存在的元素,
語法:ZADD key score member [score member ...]
獲取排名在某個范圍的元素串列
按照元素分數從小到大的順序回傳索引從start到stop之間的所有元素(包含兩端的元素)
語法:ZRANGE key start stop [WITHSCORES]
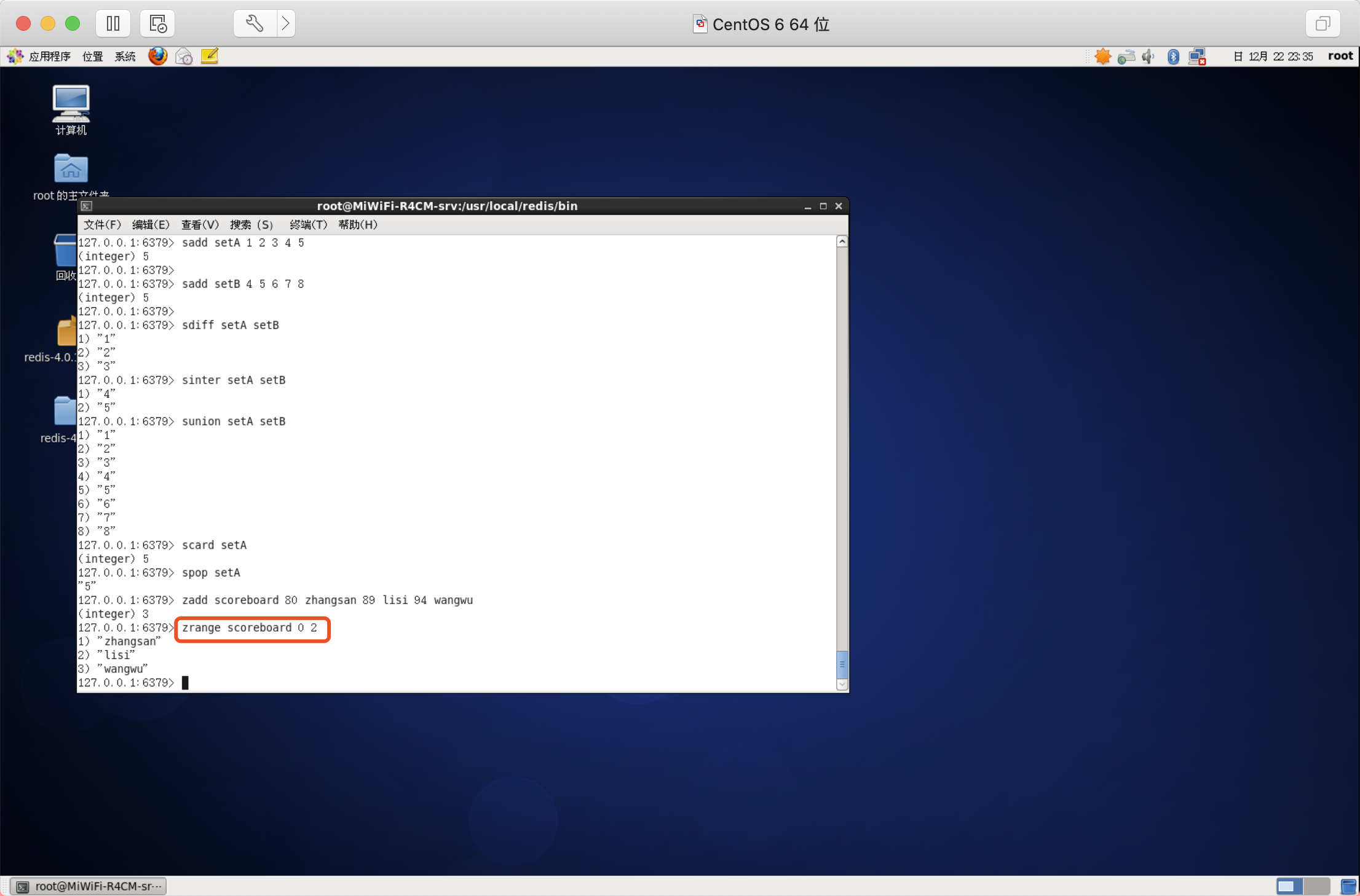
如果需要獲取元素的分數的可以在命令尾部加上WITHSCORES引數
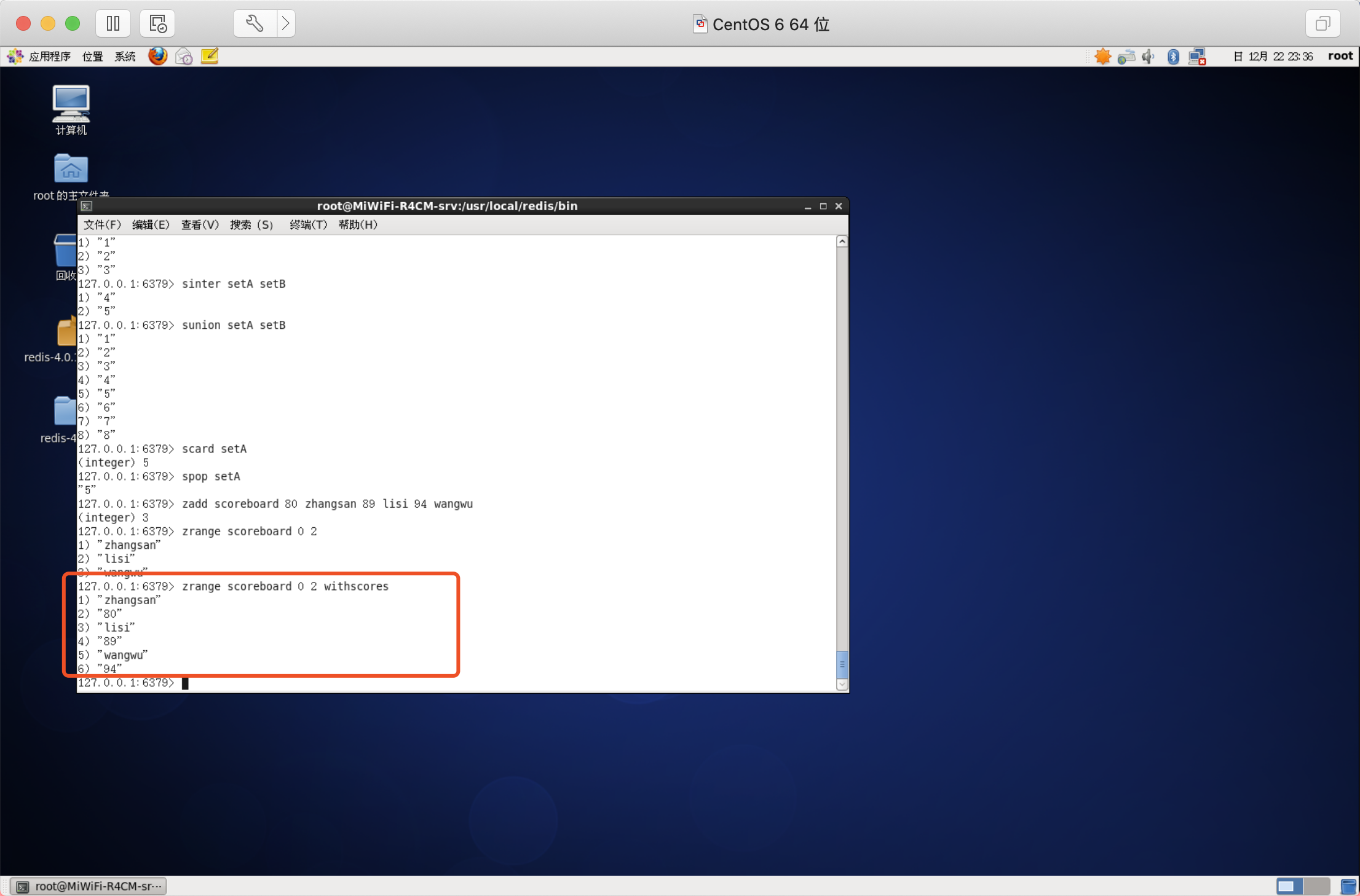 獲取元素的分數
獲取元素的分數
語法:ZSCORE key member
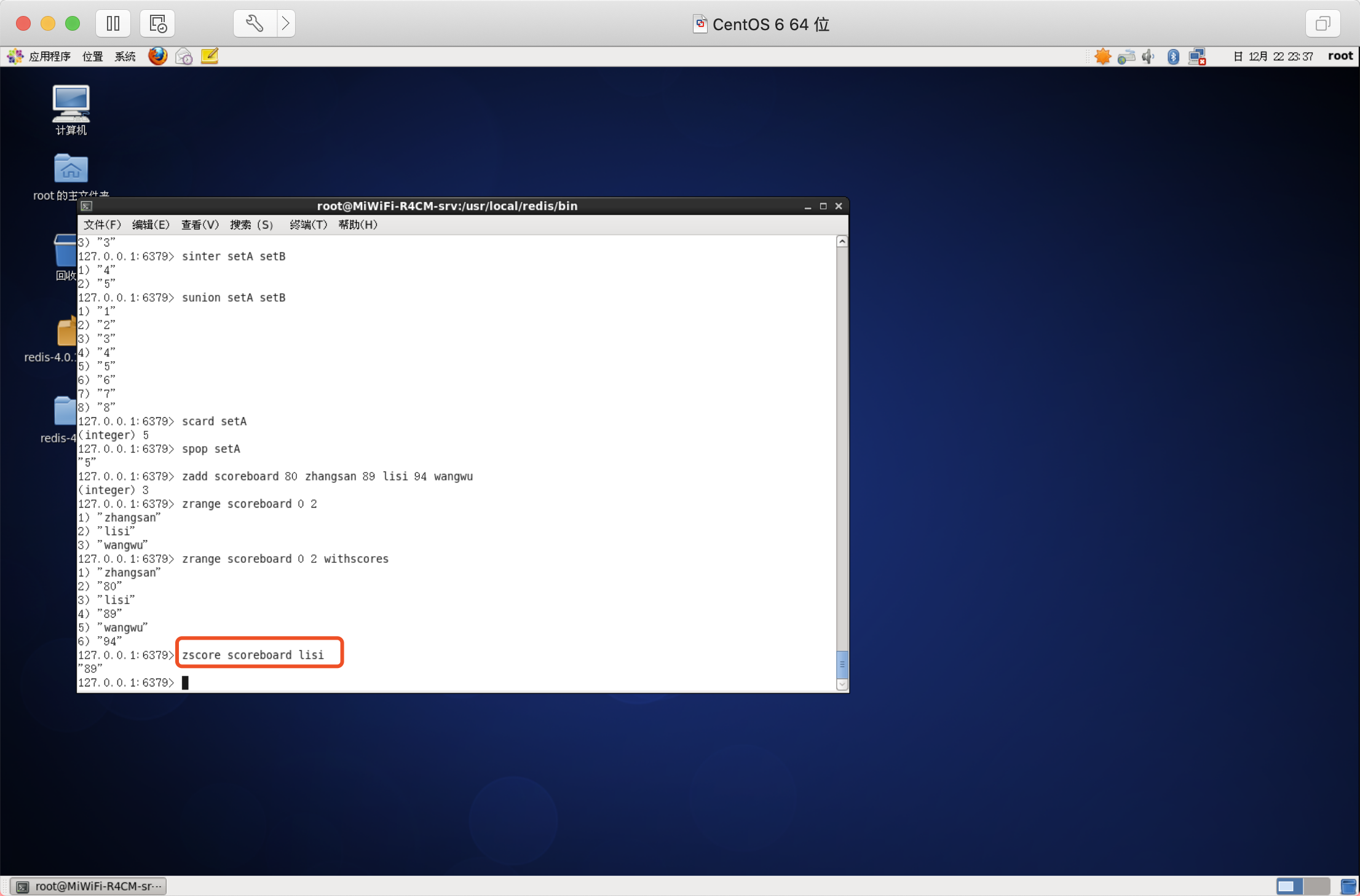
洗掉元素
移除有序集key中的一個或多個成員,不存在的成員將被忽略,
當key存在但不是有序集型別時,回傳錯誤,
語法:ZREM key member [member ...]
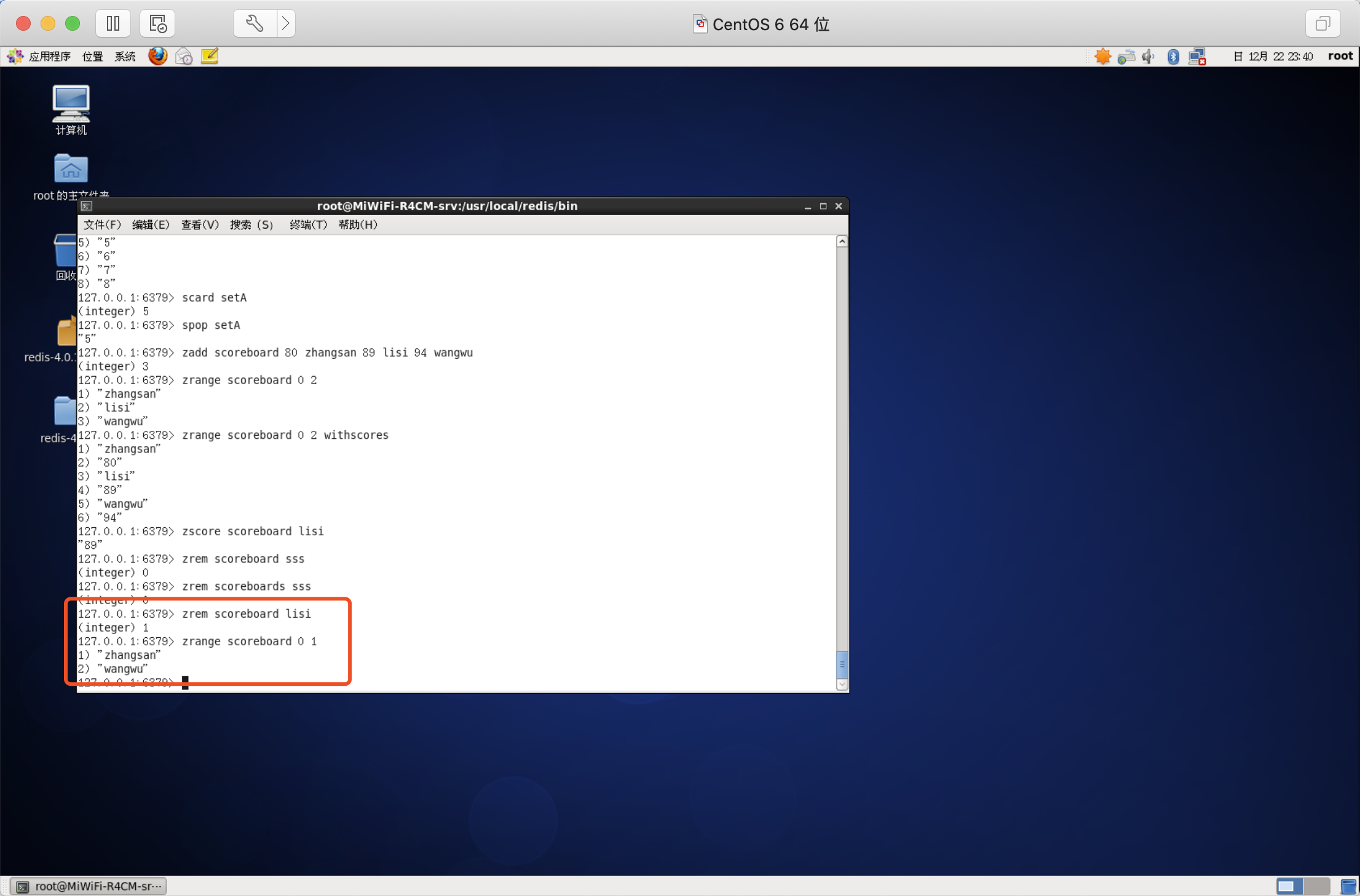
獲取指定分數范圍的元素
語法:ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT offset count]
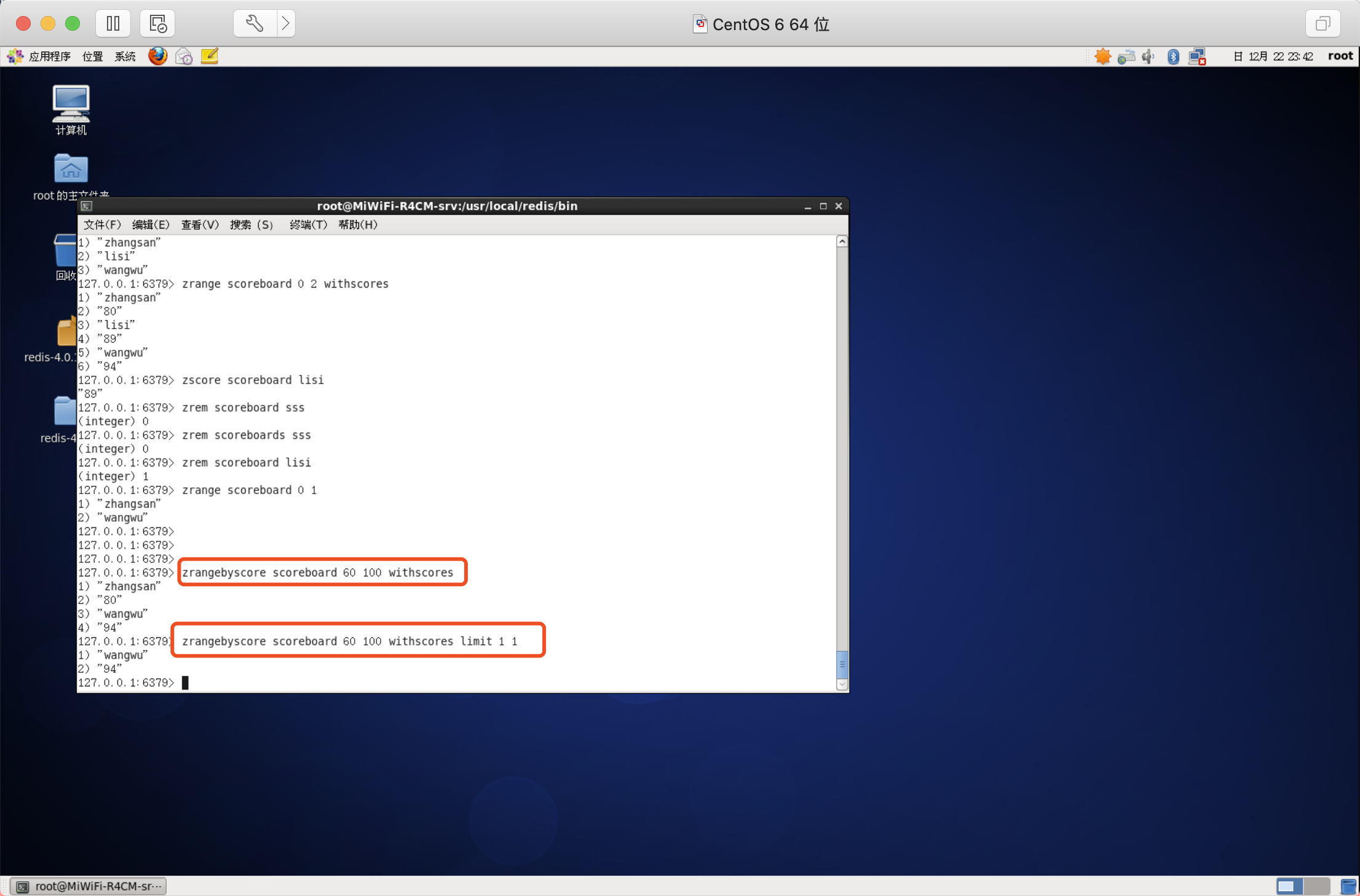
增加某個元素的分數
回傳值是更改后的分數
語法:ZINCRBY key increment member
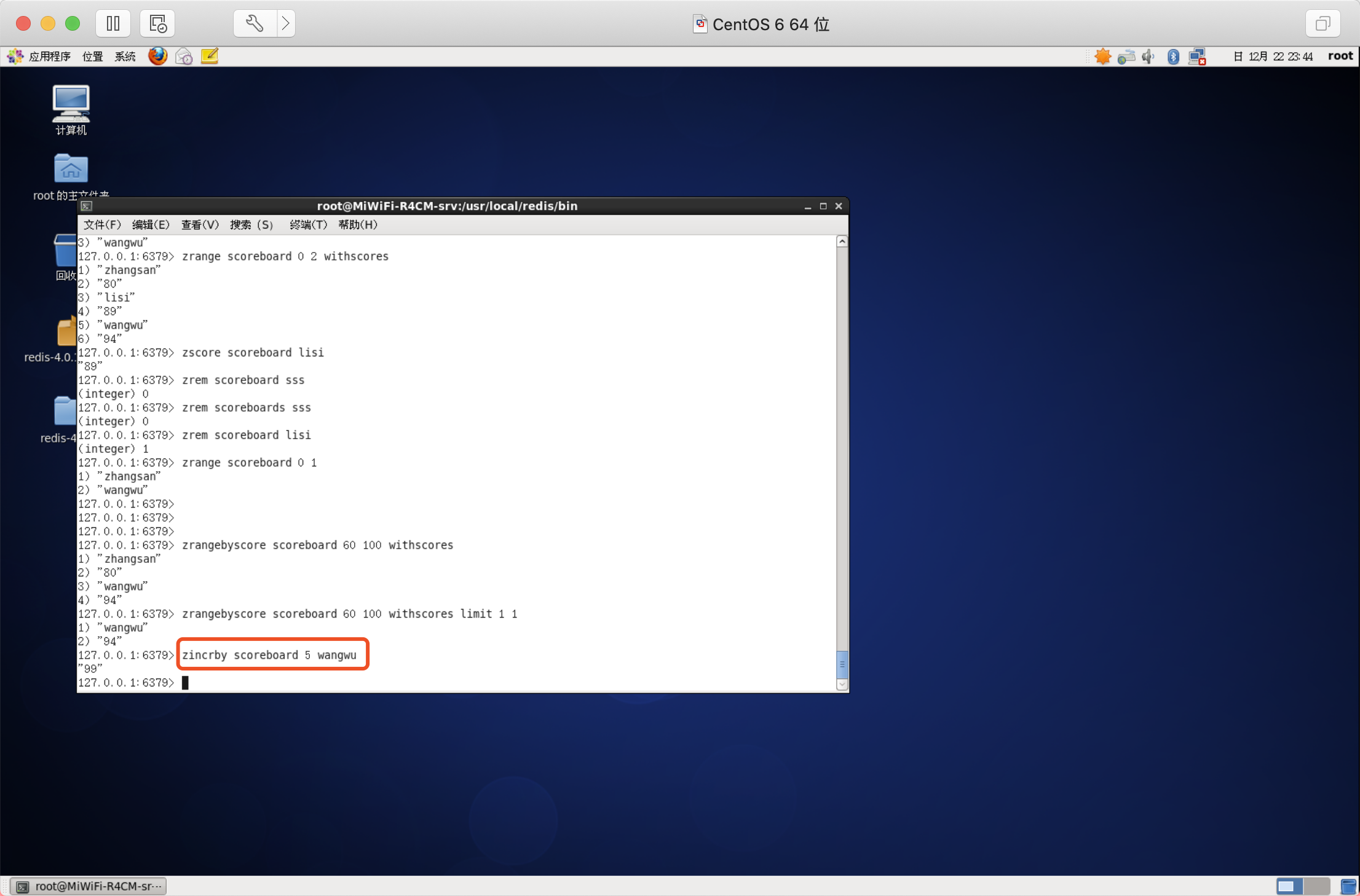
獲取集合中元素的數量
語法:ZCARD key
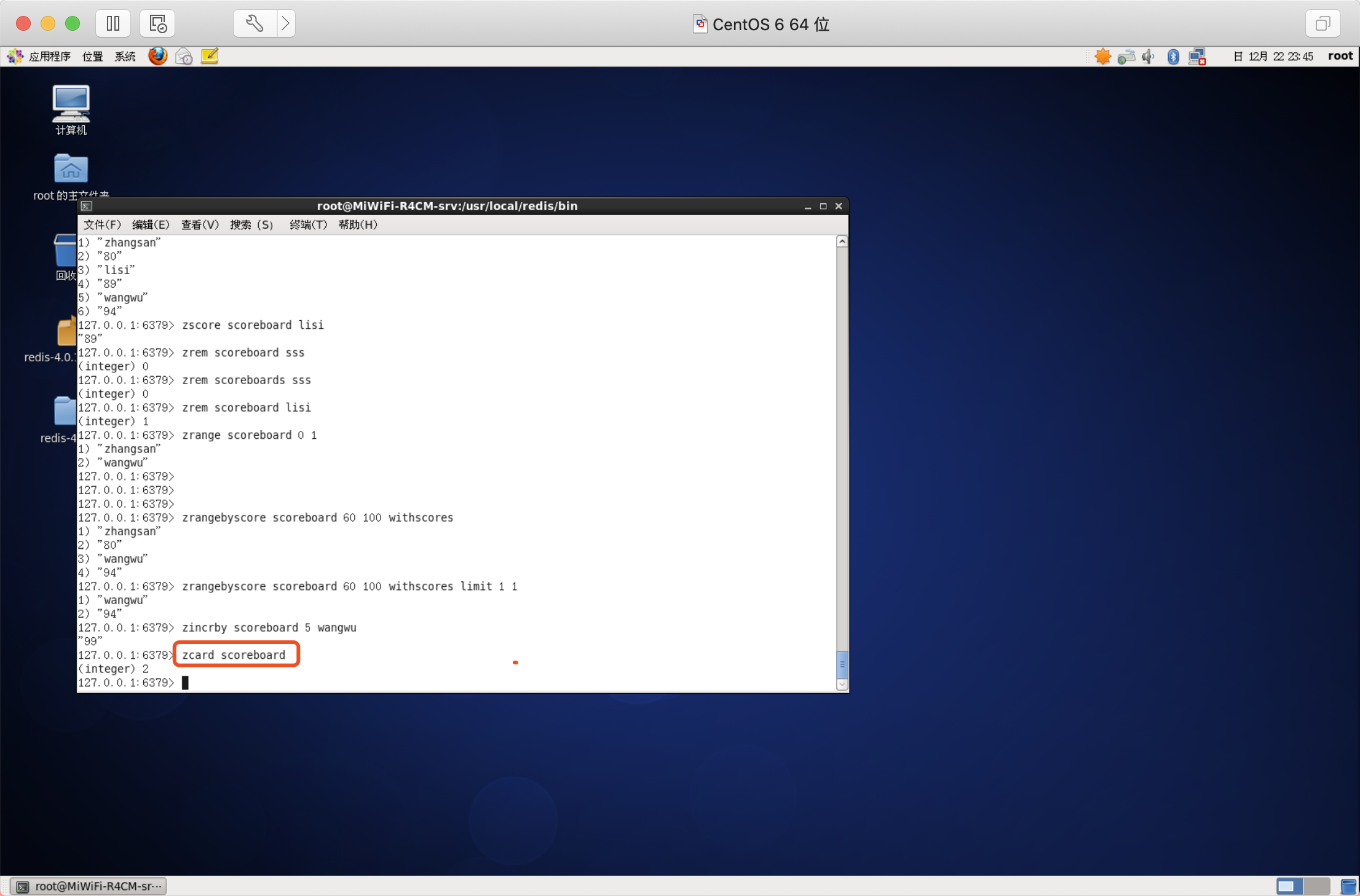
獲得指定分數范圍內的元素個數
語法:ZCOUNT key min max
按照排名范圍洗掉元素
語法:ZREMRANGEBYRANK key start stop
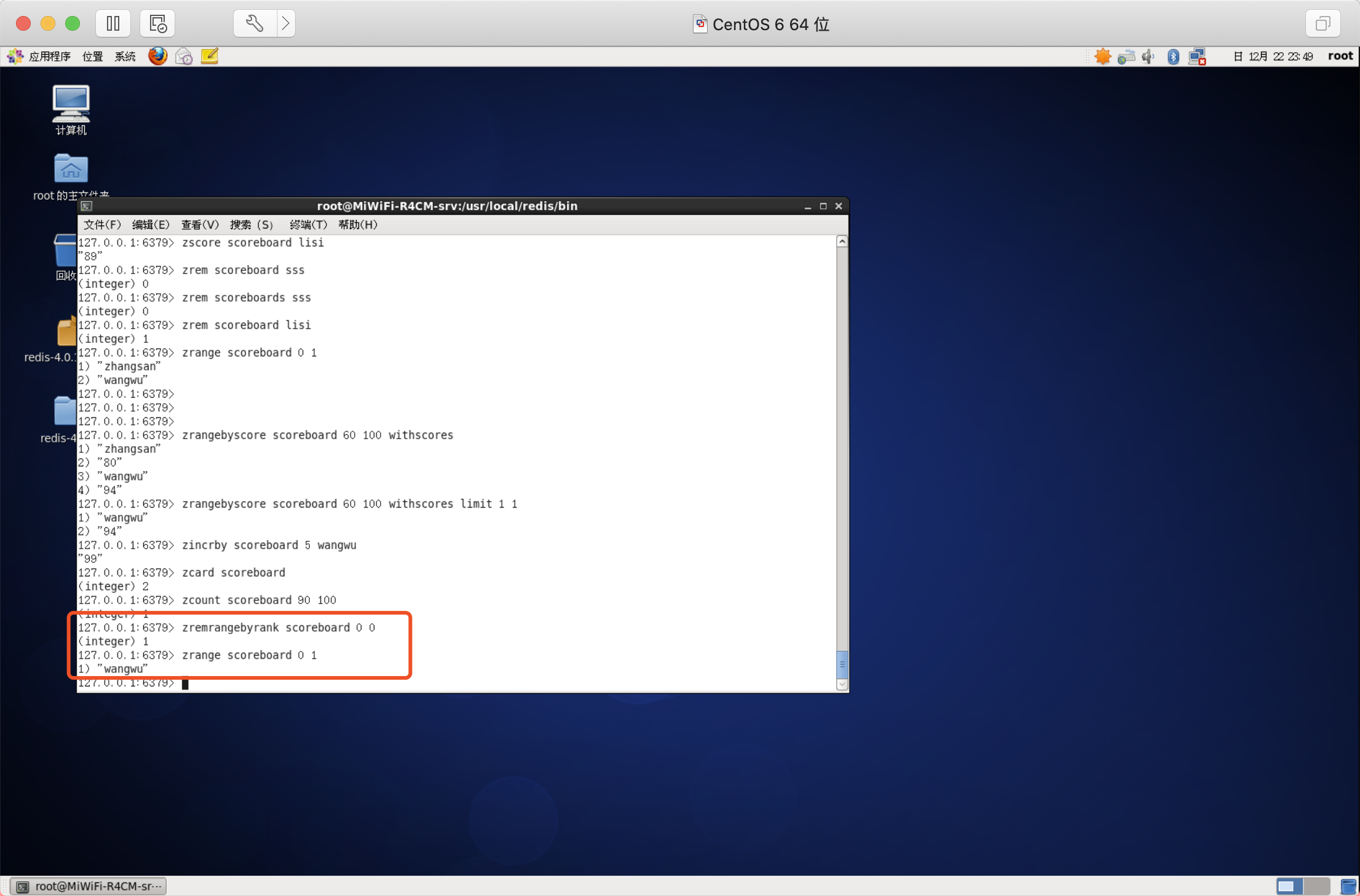
按照分數范圍洗掉元素
語法:ZREMRANGEBYSCORE key min max
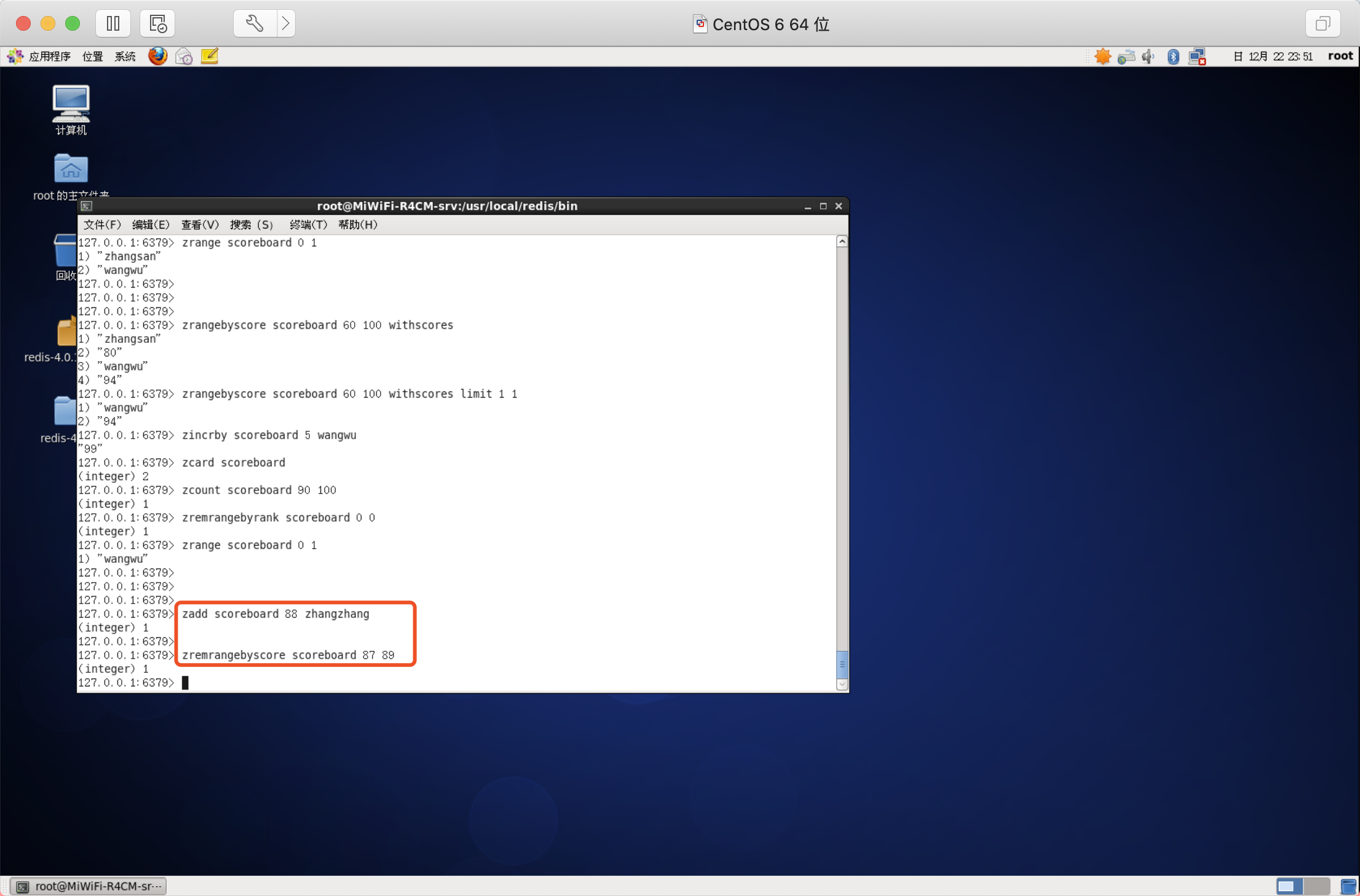
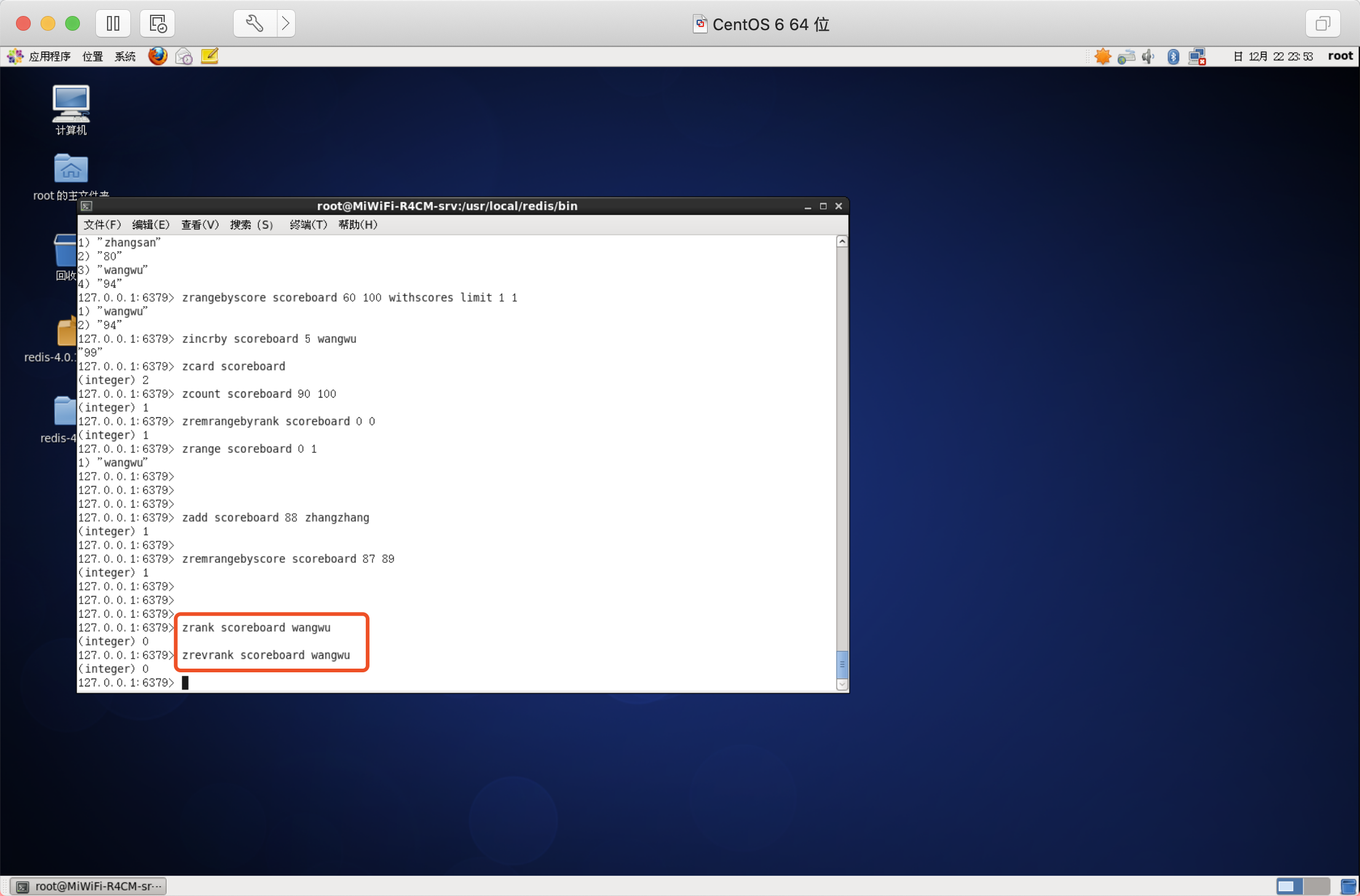
獲取元素的排名
從小到大
語法:ZRANK key member
從大到小
語法:ZREVRANK key member
應用之商品銷售排行榜
需求:根據商品銷售對商品進行排序顯示
思路:定義商品銷售排行榜(sorted set集合),key為items:sellsort,分數為商品小數量,
寫入商品銷售量:
>商品編號1001的銷量是9,商品編號1002的銷量是10
>商品編號1001銷量家1
>商品銷量前10名
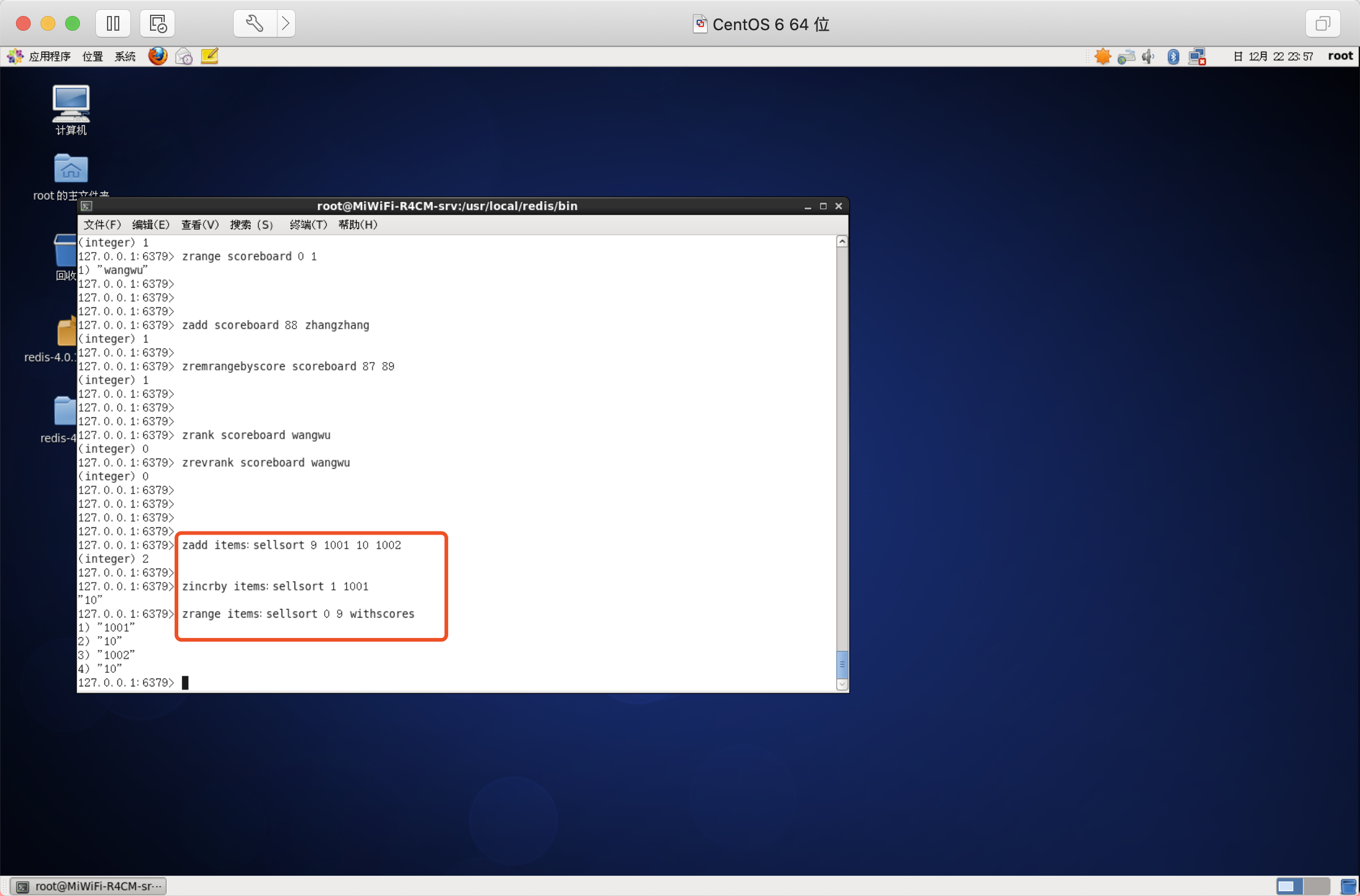
通用命令
keys
語法:keys pattern
del
語法:DEL key
exists
作用:確認一個key是否存在
語法:exists key
expire
Redis在實際使用程序中更多的用作快取,然后快取的資料一般都是需要設定生存時間的,即:到期后資料銷毀,
EXPIRE key seconds 設定key的生存時間(單位:秒)key在多少秒后會自動洗掉
TTL key 查看key生于的生存時間
PERSIST key 清除生存時間
PEXPIRE key milliseconds 生存時間設定單位為:毫秒
例子:
192.168.101.3:7002> set test 1 設定test的值為1
OK
192.168.101.3:7002> get test 獲取test的值
"1"
192.168.101.3:7002> EXPIRE test 5 設定test的生存時間為5秒
(integer) 1
192.168.101.3:7002> TTL test 查看test的生于生成時間還有1秒洗掉
(integer) 1
192.168.101.3:7002> TTL test
(integer) -2
192.168.101.3:7002> get test 獲取test的值,已經洗掉
(nil)
rename
作用:重命名key
語法:rename oldkey newkey
type
作用:顯示指定key的資料型別
語法:type key
Redis事務
事務介紹
- Redis的事務是通過MULTI,EXEC,DISCARD和WATCH這四個命令來完成,
- Redis的單個命令都是原子性的,所以這里確保事務性的物件是命令集合,
- Redis將命令集合序列化并確保處于一事務的命令集合連續且不被打斷的執行,
- Redis不支持回滾的操作,
相關命令
-
MULTI
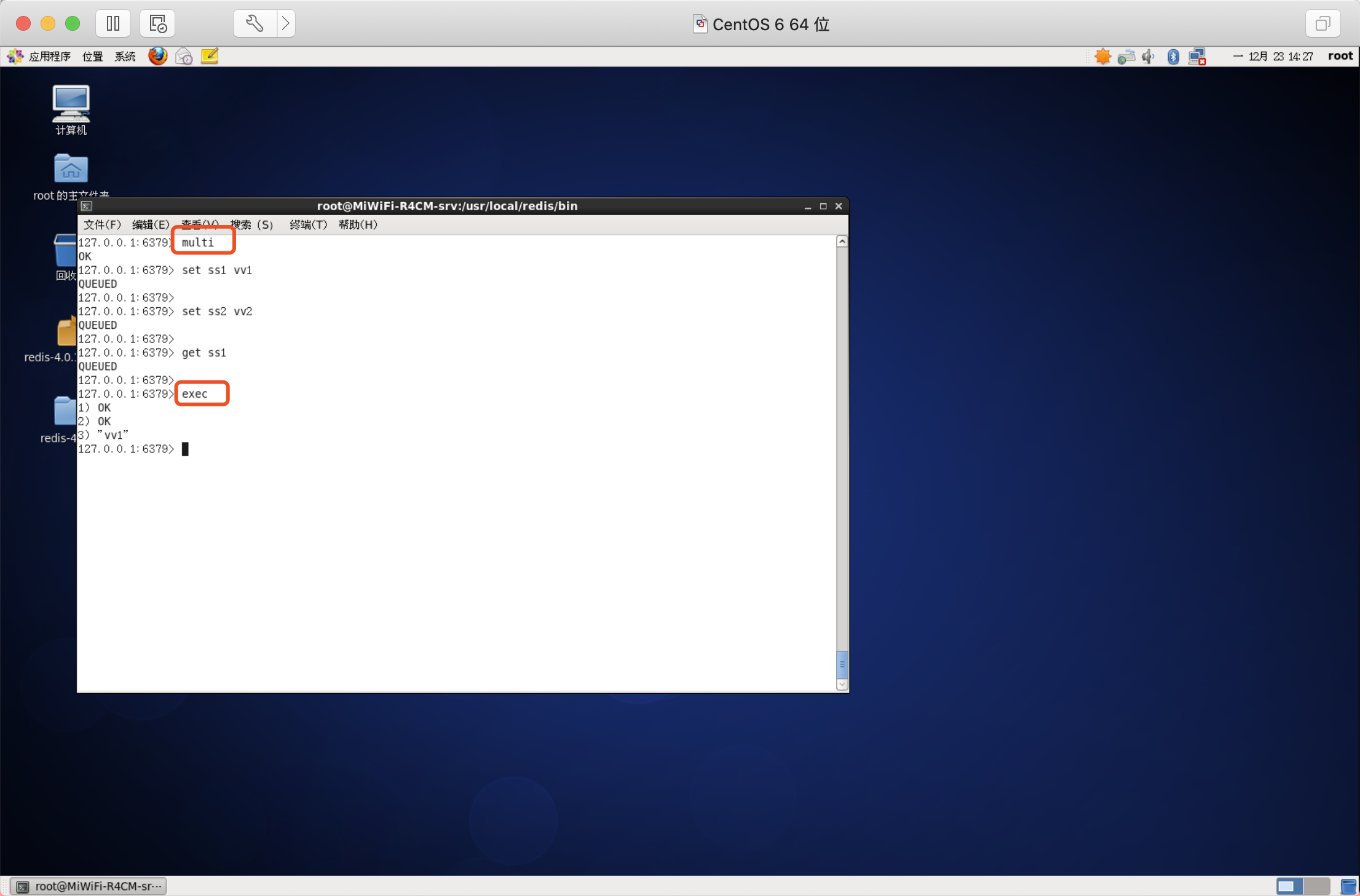
注:用于標記事務塊的開始,
Redis會將后續的命令逐個放入佇列中,然后使用EXEC命令原子化地執行這個命令序列,
語法:MULTI
-
EXEC
在一個事務中執行所有先前放入佇列的命令,然后恢復正常的連接狀態,
語法:EXEC
-
DISCARD
清楚所有先前在一個事務中放入佇列的命令,然后恢復正常的連接狀態,
語法:DISCARD
-
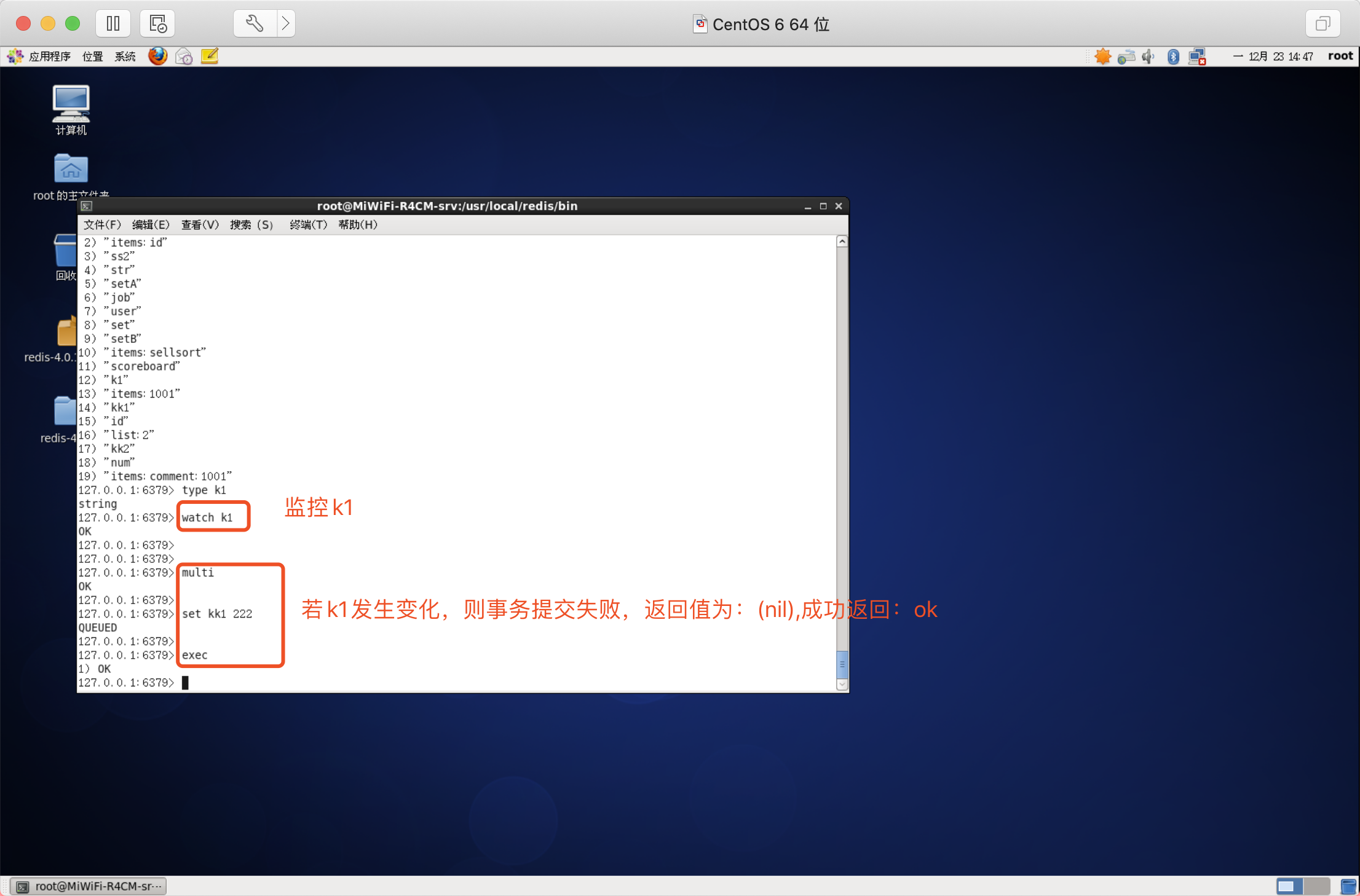
WATCH
當某個事務需要按條件執行時,就要使用這個命令將給定的鍵設定為受監控的狀態,
語法:WATCH key [key ....]
注:該命令可以實作redis的樂觀鎖
-
UNWATCH
清除所有先前為一個事務監控的鍵,
語法:UNWATCH
事務失敗處理
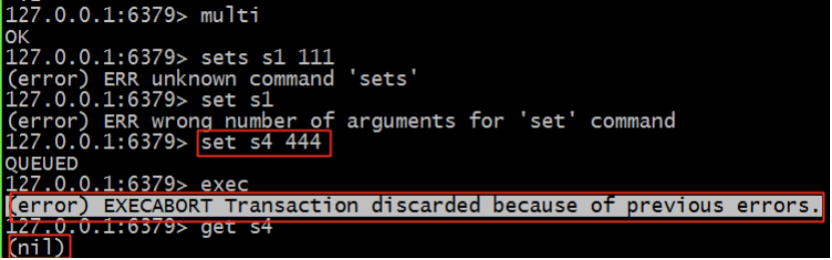
- Redis語法錯誤(編譯器錯誤)
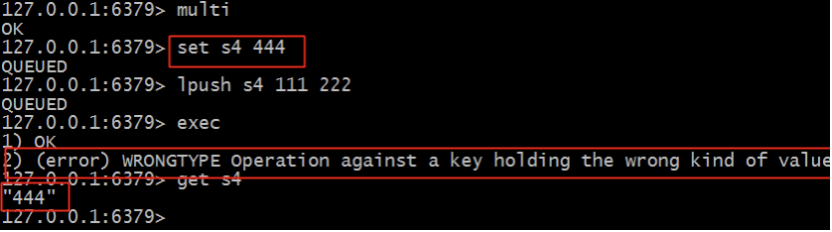
- Redis型別錯誤(運行期錯誤)
為什么redis不支持事務回滾?
- 大多數事務失敗是因為語法錯誤或者型別錯誤,這兩種錯誤,再開發階段都是可以避免的
- Redis為了性能方面就忽略了事務回滾
Redis實作分布式鎖
鎖的處理
單應用中使用鎖:單執行緒多執行緒
synchronize、Lock
分布式應用中使用鎖:多行程
分布式鎖的實作方式
- 資料庫的樂觀鎖
- 給予zookeeper的分布式鎖
- 給予redis的分布式鎖
分布式鎖的注意事項
- 互斥性:在任意時刻,只有一個客戶端能持有鎖
- 同一性:加鎖和解鎖必須是同一個客戶端,客戶端自己不能把別人加的鎖給解了,
- 避免死鎖:即使有一個客戶端在持有鎖的期間崩潰而沒有主動解鎖,也能保證后續其他客戶端能加鎖,
實作分布式鎖
獲取鎖
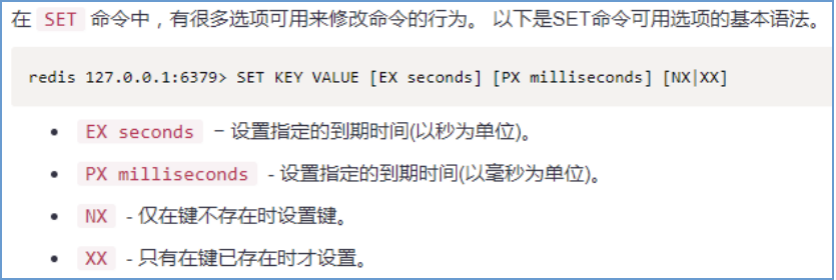
方式一(使用set命令實作)
方式二(使用setnx命令實作)
package com.cyb.redis.utils; import redis.clients.jedis.Jedis; import redis.clients.jedis.JedisPool; public class jedisUtils { private static String ip = "192.168.31.200"; private static int port = 6379; private static JedisPool pool; static { pool = new JedisPool(ip, port); } public static Jedis getJedis() { return pool.getResource(); } public static boolean getLock(String lockKey, String requestId, int timeout) { //獲取jedis物件,負責和遠程redis服務器進行連接 Jedis je=getJedis(); //引數3:NX和XX //引數4:EX和PX String result = je.set(lockKey, requestId, "NX", "EX", timeout); if (result=="ok") { return true; } return false; } public static synchronized boolean getLock2(String lockKey, String requestId, int timeout) { //獲取jedis物件,負責和遠程redis服務器進行連接 Jedis je=getJedis(); //引數3:NX和XX //引數4:EX和PX Long result = je.setnx(lockKey, requestId); if (result==1) { je.expire(lockKey, timeout); //設定有效期 return true; } return false; } }
釋放鎖
package com.cyb.redis.utils; import redis.clients.jedis.Jedis; import redis.clients.jedis.JedisPool; public class jedisUtils { private static String ip = "192.168.31.200"; private static int port = 6379; private static JedisPool pool; static { pool = new JedisPool(ip, port); } public static Jedis getJedis() { return pool.getResource(); } /** * 釋放分布式鎖 * @param lockKey * @param requestId */ public static void releaseLock(String lockKey, String requestId) { Jedis je=getJedis(); if (requestId.equals(je.get(lockKey))) { je.del(lockKey); } } }
Redis持久化方案
導讀
Redis是一個記憶體資料庫,為了保證資料的持久性,它提供了兩種持久化方案,
- RDB方式(默認)
- AOF方式
RDB方式
RDB是Redis默認采用的持久化方式,
RDB方式是通過快照(snapshotting)完成的,當符合一定條件時Redis會自動將記憶體中的資料進行快照并持久化到硬碟,
RDB觸發條件
- 符合自定義配置的快照規則
- 執行save或者bgsave命令
- 執行flushall命令
- 執行主從復制操作
在redis.conf中設定自定義快照規則
1、RDB持久化條件
格式:save <seconds> <changes>
示例:
save 900 1:表示15分鐘(900秒)內至少1個鍵更改則進行快照,
save 300 10:表示5分鐘(300秒)內至少10個鍵被更改則進行快照,
save 60 10000:表示1分鐘內至少10000個鍵被更改則進行快照,
2、配置dir指定rdb快照檔案的位置
# Note that you must specify a directory here, not a file name.
dir ./
3、配置dbfilename指定rdb快照檔案的名稱
# The filename where to dump the DB
dbfilename dump.rdb
說明
- Redis啟動后會讀取RDB快照檔案,將資料從硬碟載入到記憶體
- 根據資料量大小與結構和服務器性能不同,這個時間也不同,通常將記錄1千萬個字串型別鍵,大小為1GB的快照檔案載入到記憶體中需要花費20-30秒鐘,
快照的實作原理
快照程序
- redis使用fork函式復制一份當前行程的副本(子行程)
- 父行程繼續接受并處理客戶端發來的命令,而子行程開始將記憶體中的資料寫入到硬碟中的臨時檔案,
- 當子行程寫入完所有資料后會用該臨時檔案替換舊的RDB檔案,至此,一次快照操作完成,
注意
- redis在進行快照的程序中不會修改RDB檔案,只有快照結束后才會將舊的檔案替換成新的,也就是說任何時候RDB檔案都是完整的,
- 這就使得我們可以通過定時備份RDB檔案來實作redis資料庫的備份,RDB檔案是經過壓縮的二進制檔案,占用的空間會小于記憶體中的資料,更加利于傳輸,
RDB優缺點
缺點
使用RDB方式實作持久化,一旦redis例外退出,就會丟失最后一次快照以后更改的所有資料,這個時候我們就需要根據具體的應用場景,通過組合設定自動快照條件的方式將可能發生的資料損失控制在能夠接受范圍,如果資料相對來說比較重要,希望將損失降到最小,則可以使用AOF方式進行持久化
優點
RDB可以最大化redis的性能:父行程在保存RDB檔案時唯一要做的就是fork出一個字行程,然后這個子行程就會處理接下來的所有保存作業,父行程無需執行任何磁盤I/O操作,同時這個也是一個缺點,如果資料集比較大的時候,fork可能比較耗時,造成服務器在一段時間內停止處理客戶端的請求,
AOF方式
介紹
默認情況下Redis沒有開啟AOF(append only file)方式的持久化
開啟AOF持久化后每執行一潭訓更改Redis中的資料命令,Redis就會將該命令寫入硬碟中的AOF檔案,這一程序顯示會降低Redis的性能,但大部分下這個影響是能夠接受的,另外使用較快的硬碟可以提高AOF的性能,
配置redis.conf
設定appendonly引數為yes
appendonly yes
AOF檔案的保存位置和RDB檔案的位置相同,都是通過dir引數設定的
dir ./
默認的檔案名是appendonly.aof,可以通過appendfilename引數修改
appendfilename appendonly.aof
AOF重寫原理(優化AOF檔案)
- Redis可以在AOF檔案體積變得過大時,自動地后臺對AOF進行重寫
- 重寫后的新AOF檔案包含了恢復當前資料集所需的最小命令集合,
- 整個重寫操作是絕對安全的,因為Redis在創建新的AOF檔案的程序中,會繼續將命令追加到現有的AOF檔案里面,即使重寫程序中發生停機,現有的AOF檔案也不會丟失,而一旦新AOF檔案創建完畢,Redis就會從舊AOF檔案切換到新AOF檔案,并開始對新AOF檔案進行追加操作,
- AOF檔案有序地保存了對資料庫執行的所有寫入操作,這些寫入操作以Redis協議的格式保存,因此AOF檔案的內容非常容易被人讀懂,對檔案進行分析(parse)也很輕松,
引數說明
- #auto-aof-rewrite-percentage 100:表示當前aof檔案大小超過上次aof檔案大小的百分之多少的時候會進行重寫,如果之前沒有重寫過,以啟動時aof檔案大小為基準,
- #auto-aof-rewrite-min-size 64mb:表示限制允許重寫最小aof檔案大小,也就是檔案大小小于64mb的時候,不需要進行優化
同步磁盤資料
Redis每次更改資料的時候,aof機制都會將命令記錄到aof檔案,但是實際上由于作業系統的快取機制,資料并沒有實時寫入到硬碟,而是進入硬碟快取,再通過硬碟快取機制去重繪到保存檔案中,
引數說明
- appendfsync always:每次執行寫入都會進行同步,這個是最安全但是效率比較低
- appendfsync everysec:每一秒執行
- appendfsync no:不主動進行同步操作,由于作業系統去執行,這個是最快但是最不安全的方式
AOF檔案損壞以后如何修復
服務器可能在程式正在對AOF檔案進行寫入時停機,如果停機造成AOF檔案出錯(corrupt),那么Redis在重啟時會拒絕載入這個AOF檔案,從而確保資料的一致性不會被破壞,
當發生這種情況時,可以以以下方式來修復出錯的AOF檔案:
1、為現有的AOF檔案創建一個備份,
2、使用Redis附帶的redis-check-aof程式,對原來的AOF檔案進行修復,
3、重啟Redis服務器,等待服務器字啊如修復后的AOF檔案,并進行資料恢復,
如何選擇RDB和AOF
- 一般來說,如果對資料的安全性要求非常高的話,應該同時使用兩種持久化功能,
- 如果可以承受數分鐘以內的資料丟失,那么可以只使用RDB持久化,
- 有很多用戶都只使用AOF持久化,但并不推薦這種方式:因為定時生成RDB快照(snapshot)非常便于進行資料庫備份,并且RDB恢復資料集的速度也要比AOF恢復的速度要快,
- 兩種持久化策略可以同時使用,也可以使用其中一種,如果同時使用的話,那么Redis啟動時,會優先使用AOF檔案來還原資料,
Redis的主從復制
什么是主從復制
持久性保證了即使redis服務重啟也不會丟失資料,因為redis服務重啟后將硬碟上持久化的資料恢復到記憶體中,但是當redis服務器的硬碟損壞了可能導致資料丟失,不過通過redis的主從復制機制舊可以避免這種單點故障,如下圖:
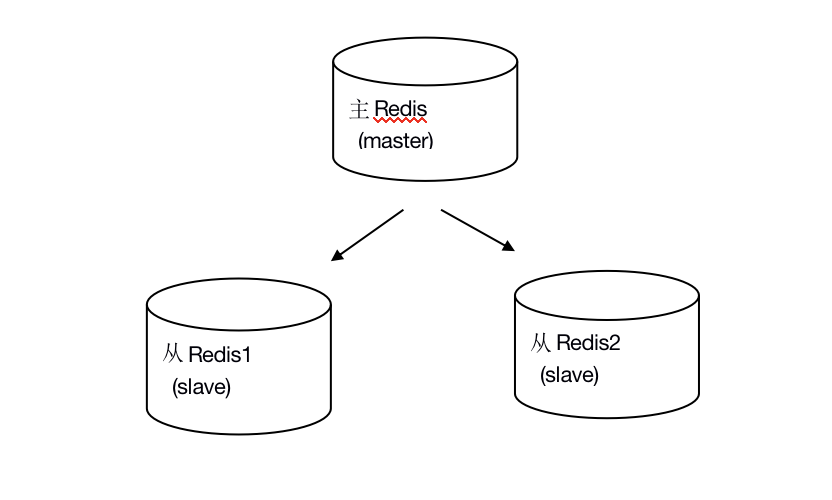
說明:
- 主redis中的資料有兩個副本(replication)即從redis1和從redis2,即使一臺redis服務器宕機其他兩臺redis服務也可以繼續提供服務,
- 主redis中的資料和從redis上的資料保持實時同步,當主redis寫入資料時通過主從復制機制會復制到兩個從redis服務上,
- 只有一個主redis,可以有多個從redis,
- 主從復制不會阻塞master,在同步資料時,master可以繼續處理client請求
- 一個redis可以即是主從,如下圖:
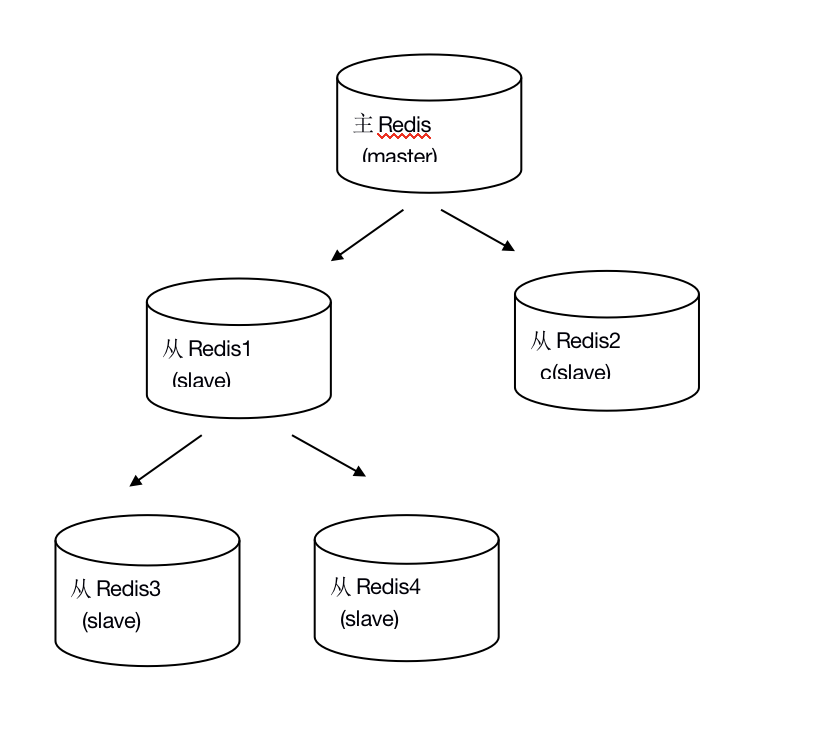
主從配置
主redis配置
無需特殊配置
從redis配置
修改從服務器上的redis.conf檔案
# slaveof <masterip> <masterport> slaveof 192.168.31.200 6379
上邊的配置說明當前【從服務器】對應的【主服務器】的ip是192.168.31.200,埠是6379.
實作原理
- slave第一次或者重連到master發送一個SYNC的命令,
- master收到SYNC的時候,會做兩件事
- 執行bgsave(rdb的快照檔案)
- master會把新收到的修改命令存入到緩沖區
缺點:沒有辦法對master進行動態選舉
Redis Sentinel哨兵機制
簡介
Sentinel(哨兵)行程是用于監控redis集群中Master主服務器作業的狀態,在Master主服務器發生故障的時候,可以實作Master和Slave服務器的切換,保證系統的高可用,其已經被集成在redis2.6+的版本中,Redis的哨兵模式到2.8版本之后就穩定了下來,
哨兵行程的作用
- 監控(Monitoring):哨兵(Sentinel)會不斷地檢查你的Master和Slave是否運作正常,
- 提醒(Notification):當被監控的某個Redis節點出現問題時,哨兵(Sentinel)可以通過API向管理員或者其他應用程式發送通知,
- 自動故障遷移(Automatic failover):當一個Master不能正常作業時,哨兵(Sentinel)會開始一次自動故障遷移操作,
- 它會將失效Master的其中一個Slave升級為新的Master,并讓失效Master的其他Slave改為復制新的Master;
- 當客戶端視圖連接失效的Master時,集群也會向客戶端回傳新Master的地址,使得集群可以使用現在的Master替換失效的Master,
- Master和Slave服務器切換后,Master的redis.conf、Slave的redis.conf和sentinel.conf的組態檔的內容都會發生相應的改變,即Master主服務器的redis.conf組態檔中會多一行Slave的配置,sentinel.conf的監控目標會隨之調換,
哨兵行程的作業方式
- 每個Sentinel(哨兵)行程以每秒鐘一次的頻率向整個集群中的Master主服務器,Slave從服務器以及其他Sentinel(哨兵)行程發送一個PING命令,
- 如果一個實體(instance)距離最后一次有效回復PING命令的時間超過down-after-milliseconds選項所指定的值,則這個實體會被Sentinel(哨兵)行程標記為主觀下線(SDOWN),
- 如果一個Master主服務器被標記為主觀下線(SDOWN),則正在監視這個Master主服務器的所有Sentinel(哨兵)行程要以每秒一次的頻率確認Master主服務器確實進入了主觀下線狀態,
- 當有足夠數量的Sentinel(哨兵)行程(大于等于組態檔指定的值)在指定的時間范圍內確認Master主服務器進入了主觀下線狀態(SDOWN),則Master主服務器會被標記為客觀下線(ODOWN),
- 在一般情況下,每個Sentinel(哨兵)行程會以每10秒一次的頻率向集群中的所有Master主服務器、Slave從服務器發送INFO命令,
- 當Master主服務器被Sentinel(哨兵)行程標記為客觀下線(ODOWN)時,Sentinel(哨兵)行程向下線的Master主服務器的所有Slave從服務器發送INFO命令的頻率會從10秒一次改為每秒一次,
- 若沒有足夠數量的Sentinel(哨兵)行程同意Master主服務器下線,Master主服務器的客觀下線狀態就會被移除,若Master主服務器重新向Sentinel(哨兵)行程發送PING命令回傳有效回復,Master主服務器的主觀下線狀態就會被移除,
實作
修改從機的sentinel.conf
sentinel monitor mymaster 192.168.127.129 6379 1
啟動哨兵服務器
./redis-sentinel sentinel.conf
Redis Cluster集群
redis-cluster架構圖
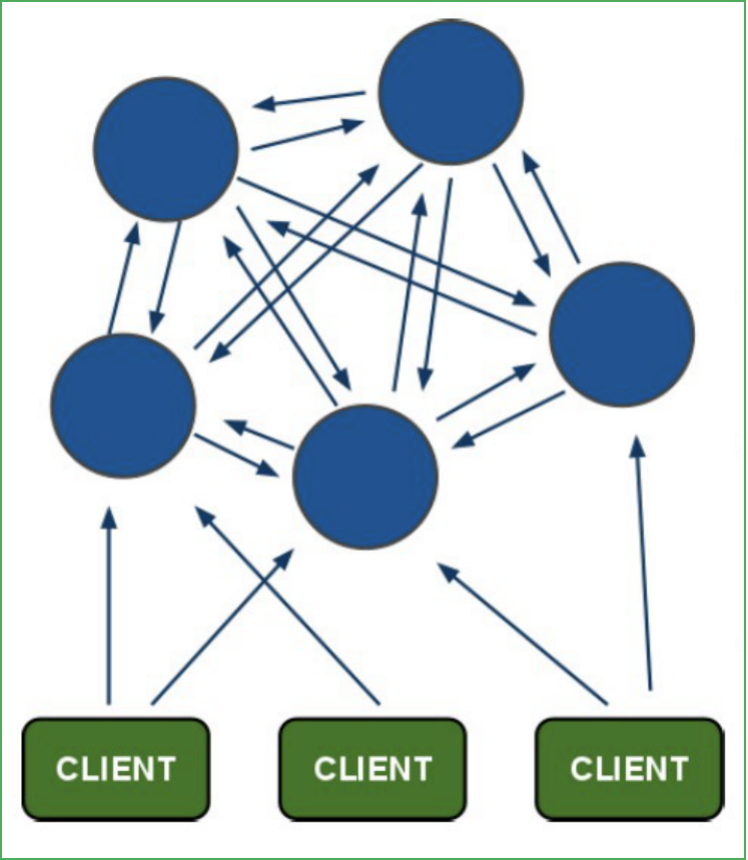
架構細節
- 所有的redis節點彼此互聯(PING-PING機制),內部使用二進制協議優化傳輸速度和帶寬,
- 節點的fail是通過集群中超過半數的節點檢測失效時才生效,
- 客戶端與redis節點直連,不需要中間proxy層,客戶端不需要連接集群所有節點,連接集群中任何一個可用節點即可,
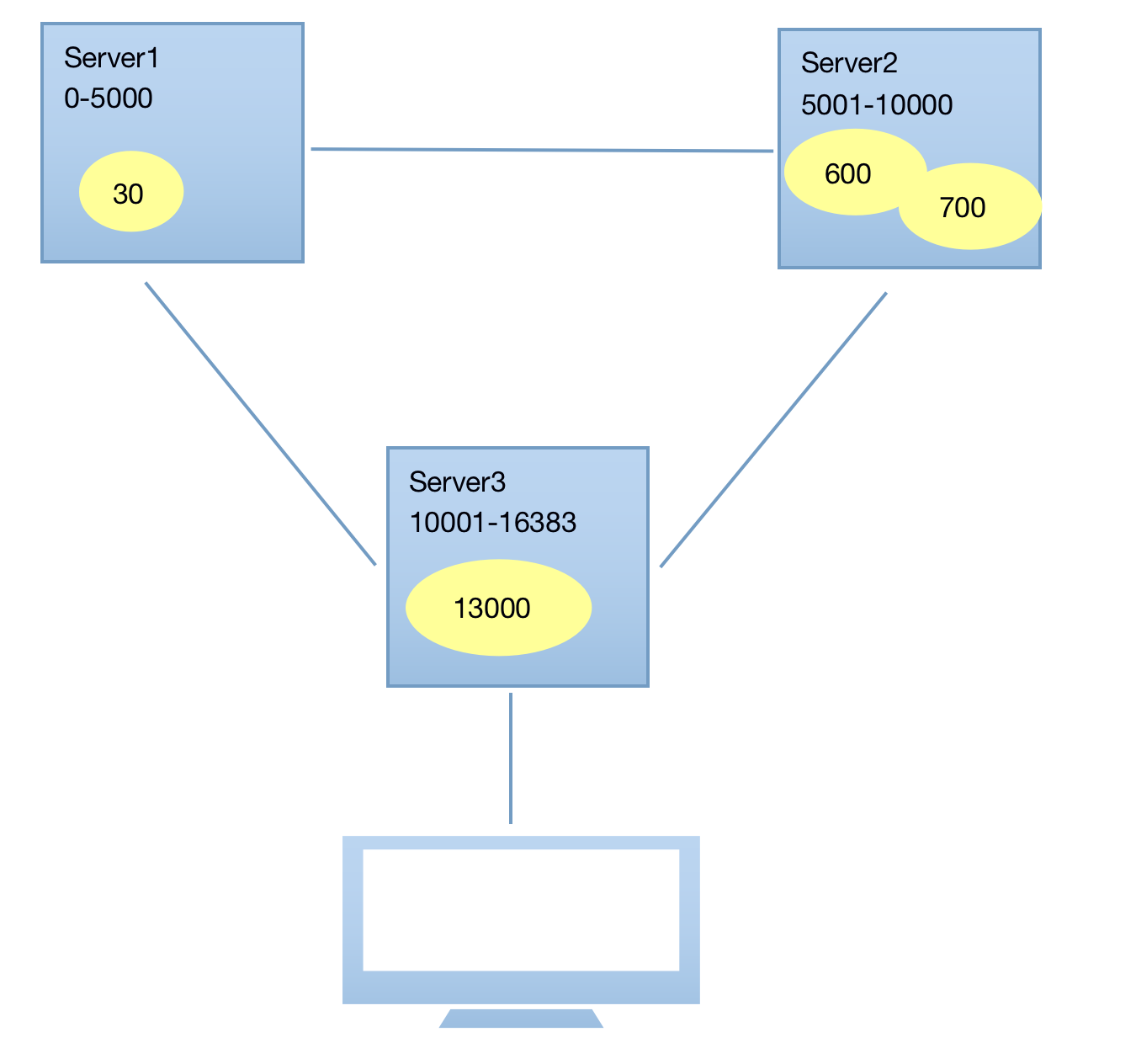
- redis-cluster把所有的物理節點映射到[0-16383]slot上,cluster負責維護node<->slot<->value
Redis集群中內置了16384個哈希槽,當需要在Redis集群中放置一個key-value時,redis先對key使用crc16演算法算出一個結果,然后把結果對16384求余數,這樣每個key都會對應一個編號在0-16384之間的哈希槽,redis會根據節點數量大致均等的將哈希槽映射到不同節點,
redis-cluster投票:容錯
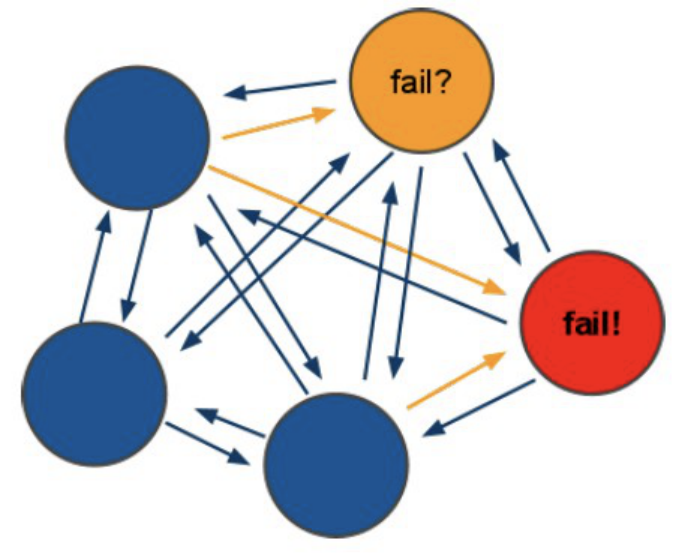
- 集群中所有master參與投票,如果半數以上master節點與其中一個master節點通信超過(cluster-node-timeout),認為該master節點掛掉,
- 什么時候整個集群不可用(cluster_state:fail)?
- 如果集群任意master掛掉,且當前master沒有slave,則集群進入fail狀態,也可以理解成集群的[0-16384]slot映射不完全時進入fail狀態,
- 如果集群超過半數以上master掛掉,無論是否有slave,集群進入fail狀態,
安裝Ruby環境
導讀
redis集群需要使用集群管理腳本redis-trib.rb,它的執行相應依賴ruby環境,
安裝
安裝ruby
yum install ruby
yum install rubygems
將redis-3.2.9.gen拖近Linux系統
安裝ruby和redis的介面程式redis-3.2.9.gem
gem install redis-3.2.9.gem
復制redis-3.2.9/src/redis-trib.rb 檔案到/usr/local/redis目錄
cp redis-3.2.9/src/redis-trib.rb /usr/local/redis/ -r
安裝Redis集群(RedisCluster)
Redis集群最少需要三臺主服務器,三臺從服務器,埠號分別為7001~7006,
創建7001實體,并編輯redis.conf檔案,修改port為7001,

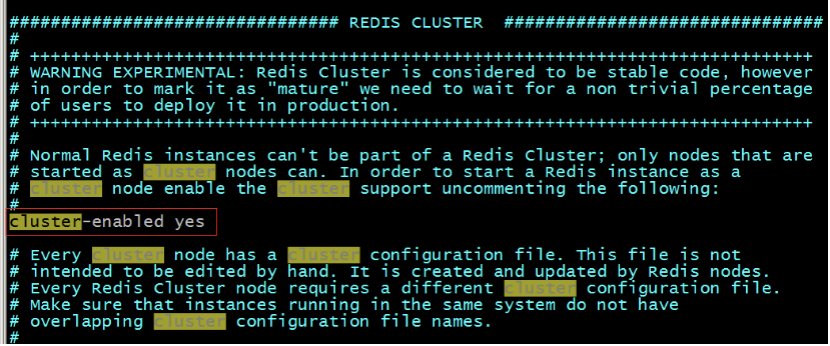
修改redis.conf組態檔,打開Cluster-enable yes
重復以上2個步驟,完成7002~7006實體的創建,注意埠修改
啟動所有的實體
創建Redis集群
./redis-trib.rb create --replicas 1 192.168.242.129:7001 192.168.242.129:7002 192.168.242.129:7003 192.168.242.129:7004 192.168.242.129:7005 192.168.242.129:7006
>>> Creating cluster
Connecting to node 192.168.242.129:7001: OK
Connecting to node 192.168.242.129:7002: OK
Connecting to node 192.168.242.129:7003: OK
Connecting to node 192.168.242.129:7004: OK
Connecting to node 192.168.242.129:7005: OK
Connecting to node 192.168.242.129:7006: OK
>>> Performing hash slots allocation on 6 nodes...
Using 3 masters:
192.168.242.129:7001
192.168.242.129:7002
192.168.242.129:7003
Adding replica 192.168.242.129:7004 to 192.168.242.129:7001
Adding replica 192.168.242.129:7005 to 192.168.242.129:7002
Adding replica 192.168.242.129:7006 to 192.168.242.129:7003
M: d8f6a0e3192c905f0aad411946f3ef9305350420 192.168.242.129:7001
slots:0-5460 (5461 slots) master
M: 7a12bc730ddc939c84a156f276c446c28acf798c 192.168.242.129:7002
slots:5461-10922 (5462 slots) master
M: 93f73d2424a796657948c660928b71edd3db881f 192.168.242.129:7003
slots:10923-16383 (5461 slots) master
S: f79802d3da6b58ef6f9f30c903db7b2f79664e61 192.168.242.129:7004
replicates d8f6a0e3192c905f0aad411946f3ef9305350420
S: 0bc78702413eb88eb6d7982833a6e040c6af05be 192.168.242.129:7005
replicates 7a12bc730ddc939c84a156f276c446c28acf798c
S: 4170a68ba6b7757e914056e2857bb84c5e10950e 192.168.242.129:7006
replicates 93f73d2424a796657948c660928b71edd3db881f
Can I set the above configuration? (type 'yes' to accept): yes
>>> Nodes configuration updated
>>> Assign a different config epoch to each node
>>> Sending CLUSTER MEET messages to join the cluster
Waiting for the cluster to join....
>>> Performing Cluster Check (using node 192.168.242.129:7001)
M: d8f6a0e3192c905f0aad411946f3ef9305350420 192.168.242.129:7001
slots:0-5460 (5461 slots) master
M: 7a12bc730ddc939c84a156f276c446c28acf798c 192.168.242.129:7002
slots:5461-10922 (5462 slots) master
M: 93f73d2424a796657948c660928b71edd3db881f 192.168.242.129:7003
slots:10923-16383 (5461 slots) master
M: f79802d3da6b58ef6f9f30c903db7b2f79664e61 192.168.242.129:7004
slots: (0 slots) master
replicates d8f6a0e3192c905f0aad411946f3ef9305350420
M: 0bc78702413eb88eb6d7982833a6e040c6af05be 192.168.242.129:7005
slots: (0 slots) master
replicates 7a12bc730ddc939c84a156f276c446c28acf798c
M: 4170a68ba6b7757e914056e2857bb84c5e10950e 192.168.242.129:7006
slots: (0 slots) master
replicates 93f73d2424a796657948c660928b71edd3db881f
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
[root@localhost-0723 redis]#
命令客戶端連接集群
命令:
./redis-cli -h 127.0.0.1 -p 7001 -c
注:-c表示是以redis集群方式進行連接
./redis-cli -p 7006 -c
127.0.0.1:7006> set key1 123
-> Redirected to slot [9189] located at 127.0.0.1:7002
OK
127.0.0.1:7002>
查看集群的命令
查看集群狀態
127.0.0.1:7003> cluster info
cluster_state:ok
cluster_slots_assigned:16384
cluster_slots_ok:16384
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:6
cluster_size:3
cluster_current_epoch:6
cluster_my_epoch:3
cluster_stats_messages_sent:926
cluster_stats_messages_received:926
查看集群中的節點
127.0.0.1:7003> cluster nodes
7a12bc730ddc939c84a156f276c446c28acf798c 127.0.0.1:7002 master - 0 1443601739754 2 connected 5461-10922
93f73d2424a796657948c660928b71edd3db881f 127.0.0.1:7003 myself,master - 0 0 3 connected 10923-16383
d8f6a0e3192c905f0aad411946f3ef9305350420 127.0.0.1:7001 master - 0 1443601741267 1 connected 0-5460
4170a68ba6b7757e914056e2857bb84c5e10950e 127.0.0.1:7006 slave 93f73d2424a796657948c660928b71edd3db881f 0 1443601739250 6 connected
f79802d3da6b58ef6f9f30c903db7b2f79664e61 127.0.0.1:7004 slave d8f6a0e3192c905f0aad411946f3ef9305350420 0 1443601742277 4 connected
0bc78702413eb88eb6d7982833a6e040c6af05be 127.0.0.1:7005 slave 7a12bc730ddc939c84a156f276c446c28acf798c 0 1443601740259 5 connected
127.0.0.1:7003>
維護節點
集群創建完成后可以繼續向集群中添加節點,
添加主節點
添加7007節點作為新節點
命令:./redis-trib.rb add-node 127.0.0.1:7007 127.0.0.1:7001
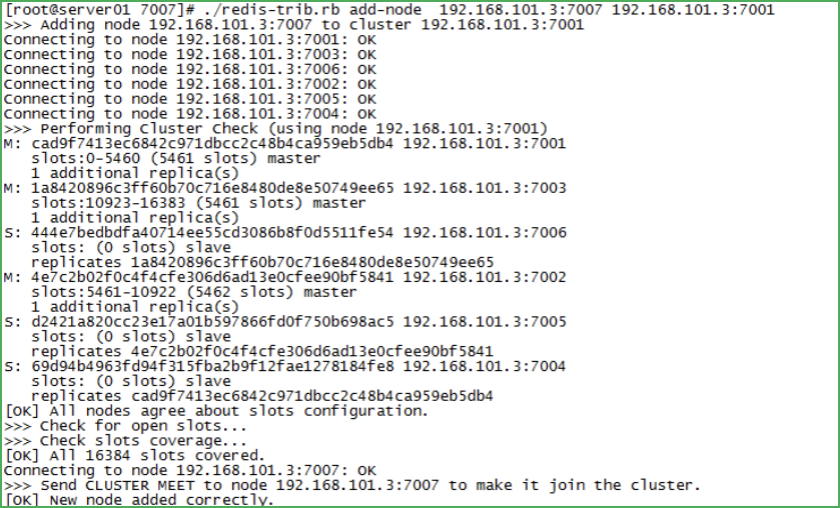
查看集群節點發現7007已加到集群中

hash槽重新分配
添加完主節點需要對主節點進行hash槽分配,這樣該主節才可以存盤資料,
查看集群中槽占用情況
redis集群有16384個槽,集群中的每個節點分配自己槽,通過查看集群節點可以看到槽占用情況,

給剛添加的7007節點分配槽
第一步:連上集群(連接集群中任意一個可用節點都行)
./redis-trib.rb reshard 192.168.101.3:7001
第二步:輸入要分配的槽數量
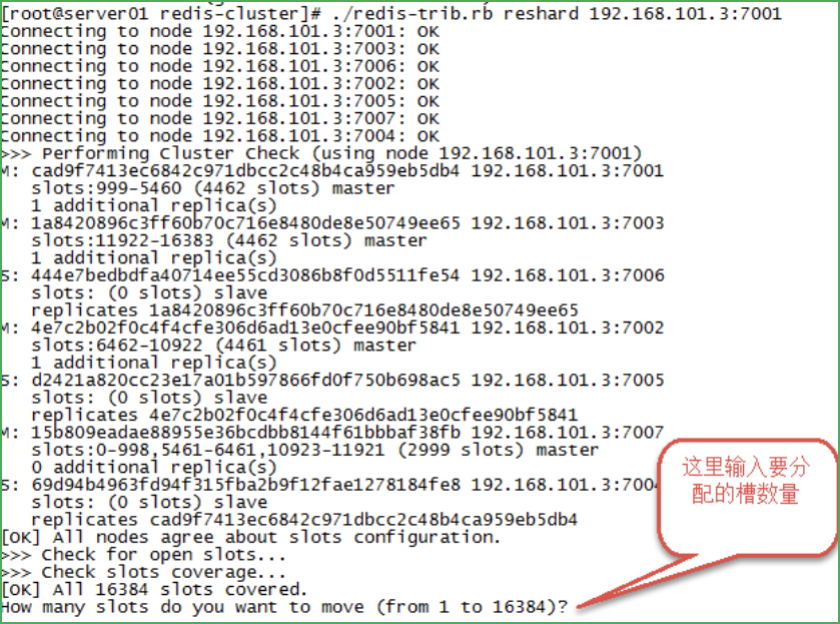
輸入500,表示要分配500個槽
第三步:輸入接收槽的節點id
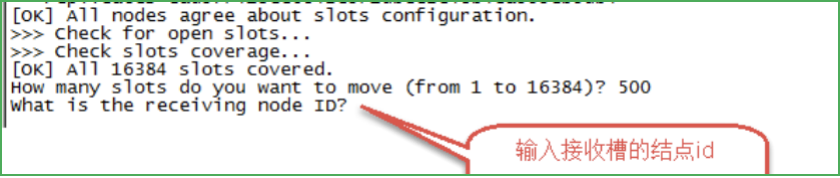
輸入:15b809eadae88955e36bcdbb8144f61bbbaf38fb
ps:這里準備給7007分配槽,通過cluster node查看7007節點id為:
15b809eadae88955e36bcdbb8144f61bbbaf38fb
第四步:輸入源節點id
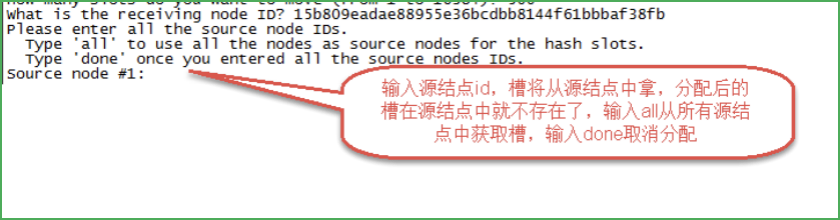
輸入:all
第五步:輸入yes開始移動槽到目標節點id

輸入:yes
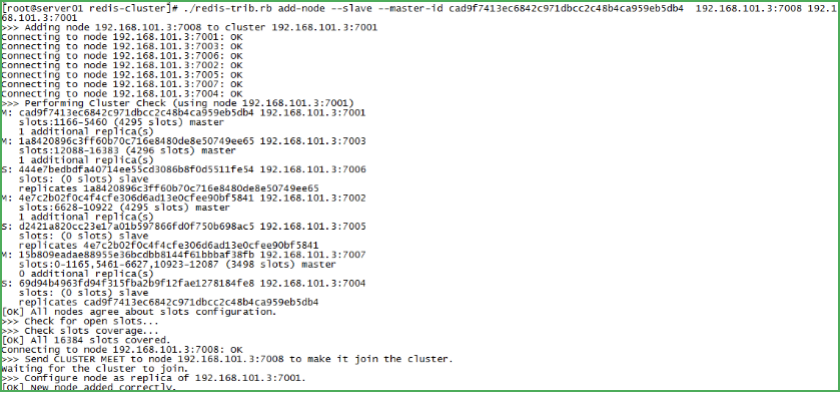
添加從節點
添加7008從節點,將7008作為7007的從節點
命令:
./redis-trib.rb add-node --slave --master-id 主節點id 新節點的ip和埠 舊節點ip和埠
執行如下命令:
./redis-trib.rb add-node --slave --master-id cad9f7413ec6842c971dbcc2c48b4ca959eb5db4 192.168.101.3:7008 192.168.101.3:7001
cad9f7413ec6842c971dbcc2c48b4ca959eb5db4 是7007結點的id,可通過cluster nodes查看,
nodes查看
注意:如果原來該節點在集群中的配置資訊已經生成到cluster-config-file指定的組態檔中(如果cluster-config-file沒有指定則默認為nodes.conf),這時可能會報錯
[ERR] Node XXXXXX is not empty. Either the node already knows other nodes (check with CLUSTER NODES) or contains some key in database 0
解決辦法是洗掉生成的組態檔nodes.conf,洗掉后再執行./redis-trib.rb add-node指令
查看集群中的節點,剛添加7008為7007的從節點

洗掉節點
命令:
./redis-trib.rb del-node 127.0.0.1:7005 4b45eb75c8b428fbd77ab979b85080146a9bc017
洗掉已經占用hash槽的節點會失敗,報錯如下
[ERR] Node 127.0.0.1:7005 is not empty! Reshard data away and try again.
需要將該節點占用的hash槽分配出去
Jedis連接集群
創建JedisCluster類連接Redis集群
@Test public void testJedisCluster() throws Exception { //創建一連接,JedisCluster物件,在系統中是單例存在 Set<HostAndPort> nodes = new HashSet<>(); nodes.add(new HostAndPort("192.168.242.129", 7001)); nodes.add(new HostAndPort("192.168.242.129", 7002)); nodes.add(new HostAndPort("192.168.242.129", 7003)); nodes.add(new HostAndPort("192.168.242.129", 7004)); nodes.add(new HostAndPort("192.168.242.129", 7005)); nodes.add(new HostAndPort("192.168.242.129", 7006)); JedisCluster cluster = new JedisCluster(nodes); //執行JedisCluster物件中的方法,方法和redis一一對應, cluster.set("cluster-test", "my jedis cluster test"); String result = cluster.get("cluster-test"); System.out.println(result); //程式結束時需要關閉JedisCluster物件 cluster.close(); }
使用Spring
配置applicationContext.xml
<!-- 連接池配置 --> <bean id="jedisPoolConfig" class="redis.clients.jedis.JedisPoolConfig"> <!-- 最大連接數 --> <property name="maxTotal" value="30" /> <!-- 最大空閑連接數 --> <property name="maxIdle" value="10" /> <!-- 每次釋放連接的最大數目 --> <property name="numTestsPerEvictionRun" value="1024" /> <!-- 釋放連接的掃描間隔(毫秒) --> <property name="timeBetweenEvictionRunsMillis" value="30000" /> <!-- 連接最小空閑時間 --> <property name="minEvictableIdleTimeMillis" value="1800000" /> <!-- 連接空閑多久后釋放, 當空閑時間>該值 且 空閑連接>最大空閑連接數 時直接釋放 --> <property name="softMinEvictableIdleTimeMillis" value="10000" /> <!-- 獲取連接時的最大等待毫秒數,小于零:阻塞不確定的時間,默認-1 --> <property name="maxWaitMillis" value="1500" /> <!-- 在獲取連接的時候檢查有效性, 默認false --> <property name="testOnBorrow" value="true" /> <!-- 在空閑時檢查有效性, 默認false --> <property name="testWhileIdle" value="true" /> <!-- 連接耗盡時是否阻塞, false報例外,ture阻塞直到超時, 默認true --> <property name="blockWhenExhausted" value="false" /> </bean> <!-- redis集群 --> <bean id="jedisCluster" class="redis.clients.jedis.JedisCluster"> <constructor-arg index="0"> <set> <bean class="redis.clients.jedis.HostAndPort"> <constructor-arg index="0" value="192.168.101.3"></constructor-arg> <constructor-arg index="1" value="7001"></constructor-arg> </bean> <bean class="redis.clients.jedis.HostAndPort"> <constructor-arg index="0" value="192.168.101.3"></constructor-arg> <constructor-arg index="1" value="7002"></constructor-arg> </bean> <bean class="redis.clients.jedis.HostAndPort"> <constructor-arg index="0" value="192.168.101.3"></constructor-arg> <constructor-arg index="1" value="7003"></constructor-arg> </bean> <bean class="redis.clients.jedis.HostAndPort"> <constructor-arg index="0" value="192.168.101.3"></constructor-arg> <constructor-arg index="1" value="7004"></constructor-arg> </bean> <bean class="redis.clients.jedis.HostAndPort"> <constructor-arg index="0" value="192.168.101.3"></constructor-arg> <constructor-arg index="1" value="7005"></constructor-arg> </bean> <bean class="redis.clients.jedis.HostAndPort"> <constructor-arg index="0" value="192.168.101.3"></constructor-arg> <constructor-arg index="1" value="7006"></constructor-arg> </bean> </set> </constructor-arg> <constructor-arg index="1" ref="jedisPoolConfig"></constructor-arg> </bean>
測驗代碼
private ApplicationContext applicationContext; @Before public void init() { applicationContext = new ClassPathXmlApplicationContext( "classpath:applicationContext.xml"); } // redis集群 @Test public void testJedisCluster() { JedisCluster jedisCluster = (JedisCluster) applicationContext .getBean("jedisCluster"); jedisCluster.set("name", "zhangsan"); String value = jedisCluster.get("name"); System.out.println(value); }
快取穿透、快取擊穿、快取雪崩
快取資料步驟
- 查詢快取,如果沒有資料,則查詢資料庫
- 查詢資料庫,如果資料不為空,將結果寫入快取
快取穿透
什么叫快取穿透?
一般的快取系統,都是按照key去快取查詢,如果不存在對應的value,就應該去后端系統查詢,如果key對應的value是一定不存在的,并且對key并發請求量很大,就會對后端系統造成很大的壓力,這就叫做快取穿透,
如何解決?
- 對查詢結果為空的情況也進行快取,快取時間設定短一點,或者該key對應的資料insert了之后清楚快取,
- 對一定不存在的key進行過濾,可以把所有的可能存在的key放到一個大的Bitmap中,查詢時通過該Bitmap過濾,(布隆運算式)
快取雪崩
什么叫快取雪崩?
當快取服務器重啟或者大量快取集合中某一個時間段失效,這樣在失效的時候,也會給后端系統帶來很大壓力,
如何解決?
- 在快取失效后,通過加鎖或者佇列來控制讀資料庫寫快取的執行緒數量,比如對某個key只允許一個執行緒查詢資料和寫快取,其他執行緒等待,
- 不同的key,設定不同的過期時間,讓快取失效的時間點盡量均勻,
- 做二級快取,A1為原始快取,A3為拷貝快取,A1失效時,可以訪問A2,A1快取失效時間設定為短期,A2設定為長期,
快取擊穿
什么叫快取擊穿?
對于一些設定了過期時間的key,如果這些key可能會在某些時間點被超高并發地訪問,是一種非常“熱點”的資料,這個時候,需要考慮一個問題:“快取”被擊穿的問題,這個和快取雪崩的區別在于這里針對某一key快取,前者則是很多key,
快取在某個時間點過期的時候,恰好在這個時間點對這個key有大量的并發請求過來,這些請求發現快取過期一般都會從后端DB加載資料并回設到快取,這個時候大并發的請求可能會瞬間把后端DB壓垮,
如何解決?
使用redis的setnx互斥鎖先進行判斷,這樣其他執行緒就處于等待狀態,保證不會有大并發操作去操作資料庫,
if(redis.setnx()==1){
//查資料庫
//加入執行緒
}
快取淘汰策略
- 當 Redis 記憶體超出物理記憶體限制時,記憶體的資料會開始和磁盤產生頻繁的交換 (swap),交換會讓 Redis 的性能急劇下降,對于訪問量比較頻繁的 Redis 來說,這樣龜速的存取效率基本上等于不可用,
- 在生產環境中我們是不允許 Redis 出現交換行為的,為了限制最大使用記憶體,Redis 提供了配置引數 maxmemory 來限制記憶體超出期望大小,
- 當實際記憶體超出 maxmemory 時,Redis 提供了幾種可選策略 (maxmemory-policy) 來讓用戶自己決定該如何騰出新的空間以繼續提供讀寫服務,
策略
noeviction:當記憶體不足以容納新寫入資料時,新寫入操作會報錯,
allkeys-lru:當記憶體不足以容納新寫入資料時,在鍵空間中,移除最近最少使用的key,
allkeys-random:當記憶體不足以容納新寫入資料時,在鍵空間中,隨機移除某個key,
volatile-lru:當記憶體不足以容納新寫入資料時,在設定了過期時間的鍵空間中,移除最近最少使用的key,
volatile-random:當記憶體不足以容納新寫入資料時,在設定了過期時間的鍵空間中,隨機移除某個key,
volatile-ttl:當記憶體不足以容納新寫入資料時,在設定了過期時間的鍵空間中,有更早過期時間的key優先移除,
使用
修改redis.conf的maxmemory,設定最大使用記憶體:
maxmemory 1024000
修改redis.conf的maxmemory-policy,設定redis快取淘汰機制:
maxmemory-policy noeviction
SpringBoot整合Redis、Mybatis(附原始碼)
點我直達
Redis高級專案實戰,分布式鎖詳講(附原始碼)
點我直達
Redis實戰秒殺(附原始碼)
點我直達
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/29288.html
標籤:架構設計