一、背景
- 線上存在業務,需要每天定時整理某個表A未處理的資料,并寫入另外一張表B;
- 每天查詢出不存在B表中且未處理過的A表資料;
- A表中的資料主鍵放入B表中,未設定B表對應索引;
- 資料量初始值大概在幾千條;
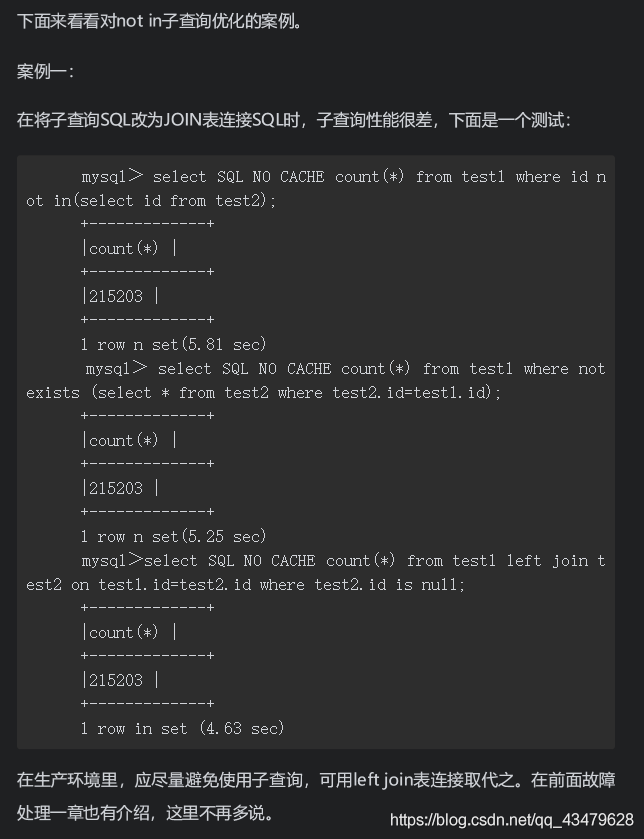
- 根據網上書籍介紹及多數網友介紹,left join 優于 not exists 優于 not in,not in不走索引,所以最終選擇left join完成該業務;
- 資料量大約在10萬條資料時,已經無法查詢出任何資料;
二、測驗環境
- mysql版本 5.7.30
- 資料庫建表sql
create table test_a( id int(11) primary key, user_name varchar(11) ) create table test_b( id int(11), user_name varchar(11) ) - test_a存在主鍵索引,test_b表無索引
- 插入資料存盤程序sql
CREATE DEFINER=`root`@`%` PROCEDURE `NewProc`() BEGIN #Routine body goes here... declare id int(11); DECLARE i int(11) DEFAULT 0; DECLARE user_name varchar(11); while i <= 1000000 do set i = i + 1; set id = i; set user_name = CONCAT('test',i); insert into test_a VALUES (id, user_name); set i = i + 1; set id = i; set user_name = CONCAT('test',i); insert into test_b VALUES (id, user_name); end while; END - 保證test_a和test_b各存在id互不相等500001條資料
三、測驗結果
left join
-
測驗sql
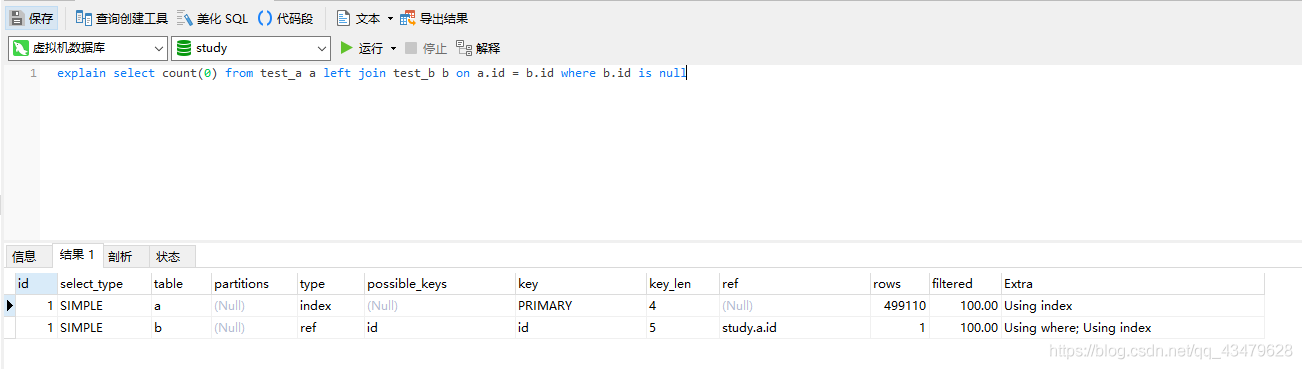
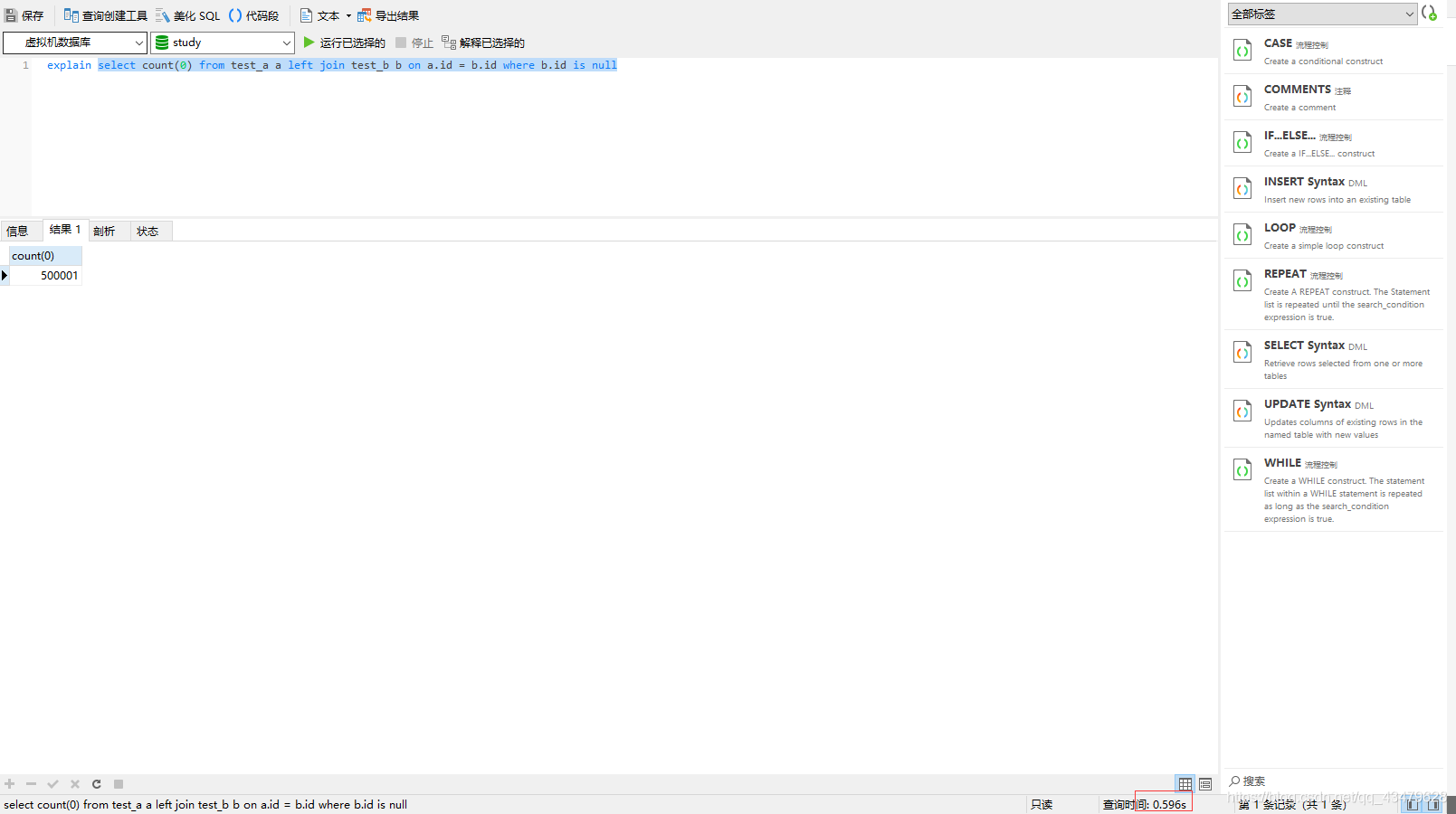
select count(0) from test_a a left join test_b b on a.id = b.id where b.id is null1.1 測驗sql分析
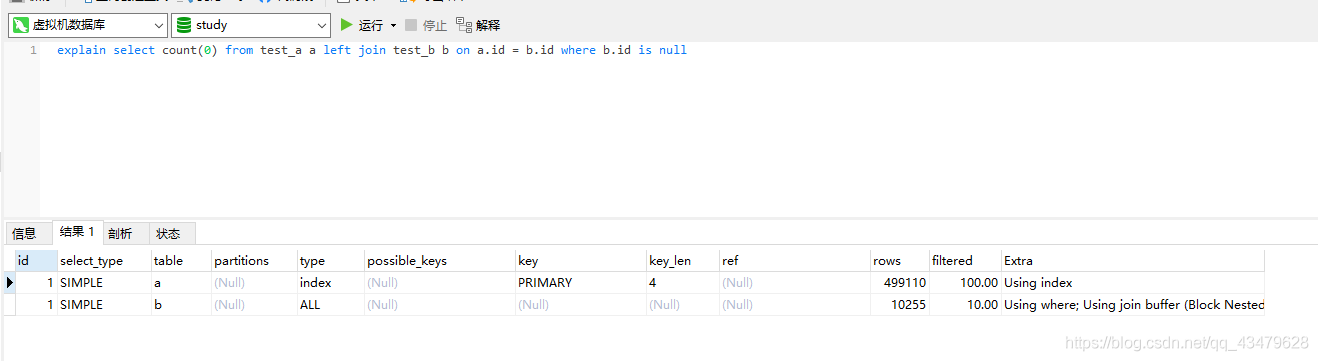
1.2 測驗結果
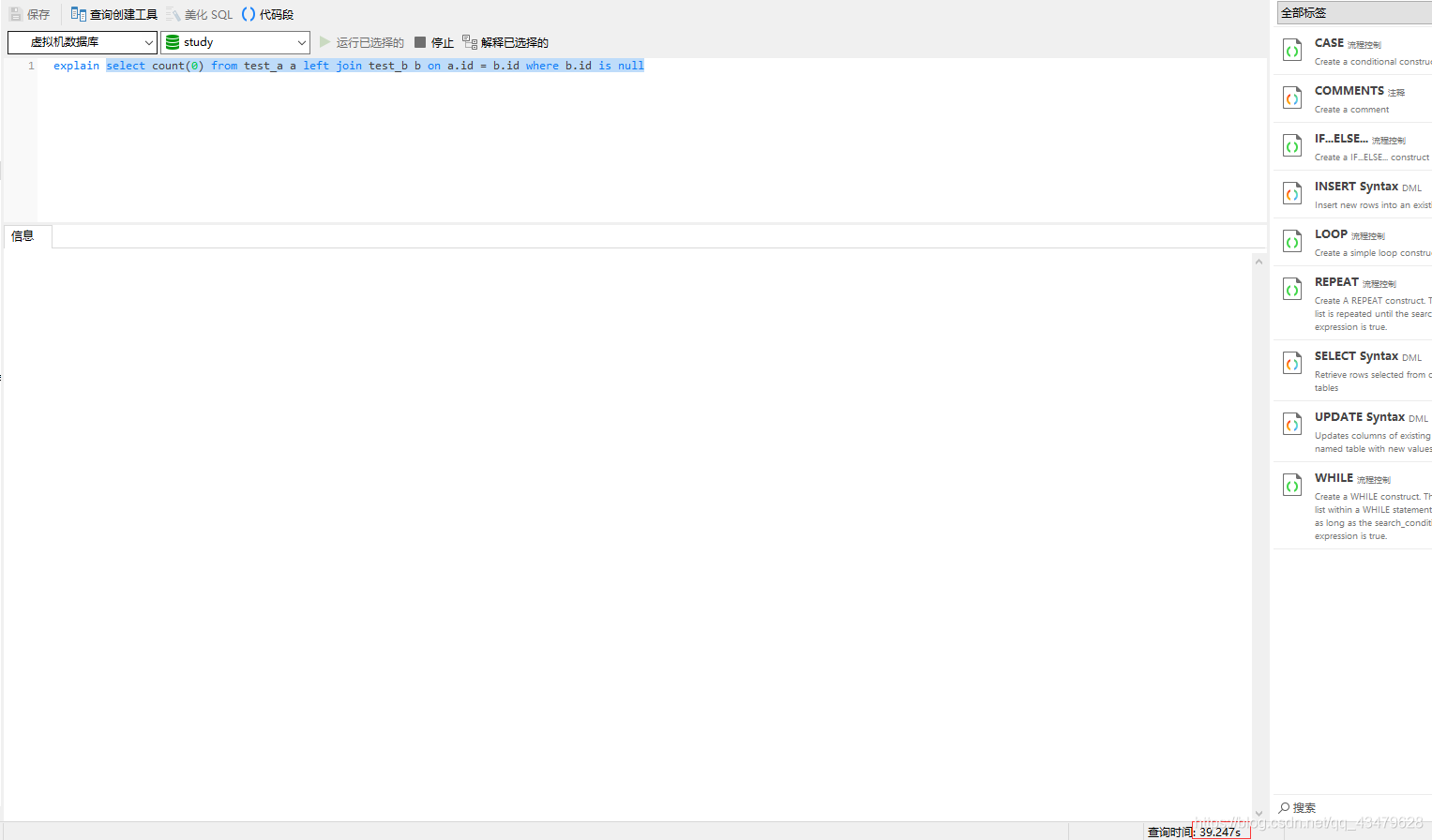
無結果,資料查詢時間過長無回應
not exists
- 測驗sql
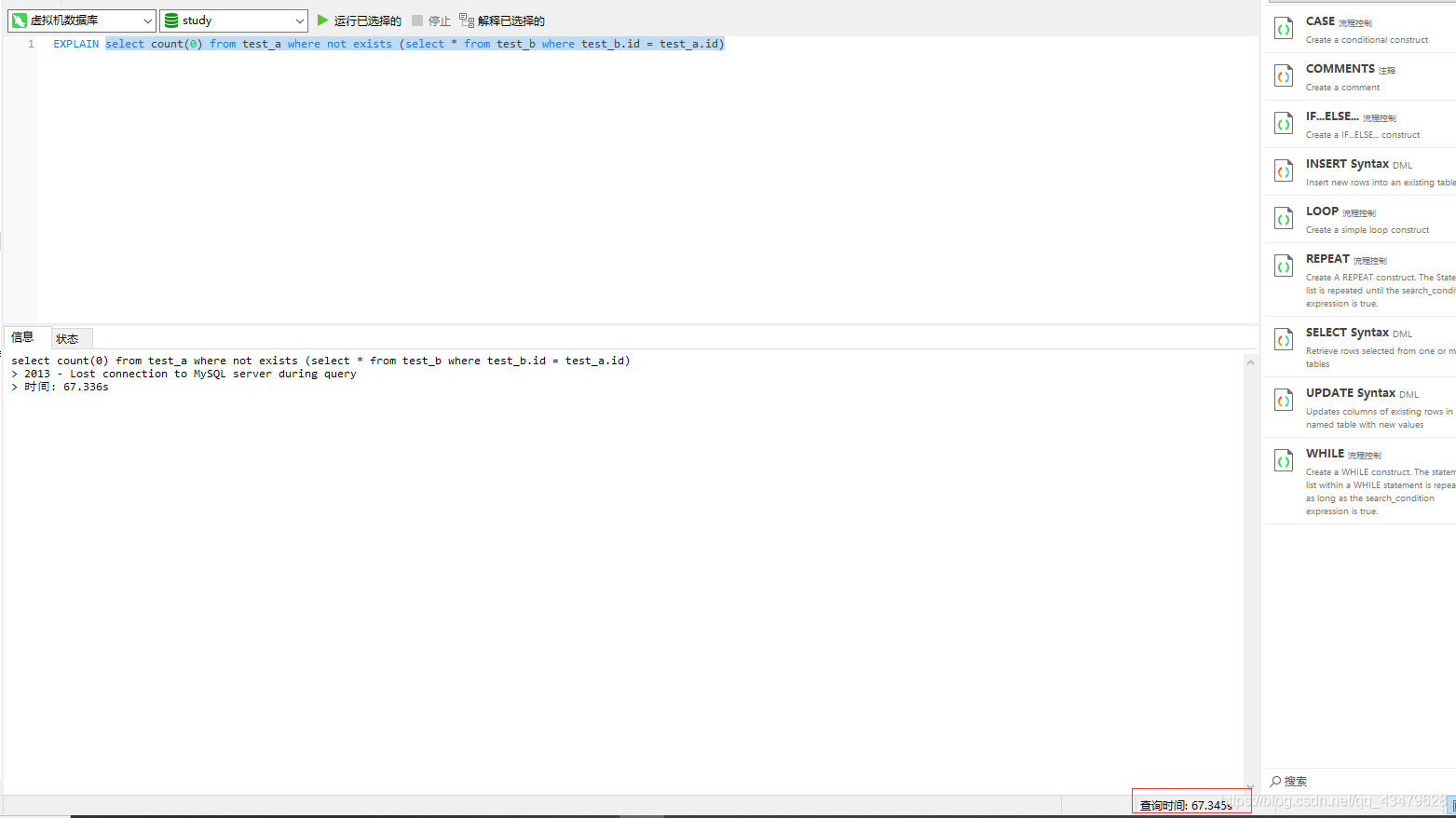
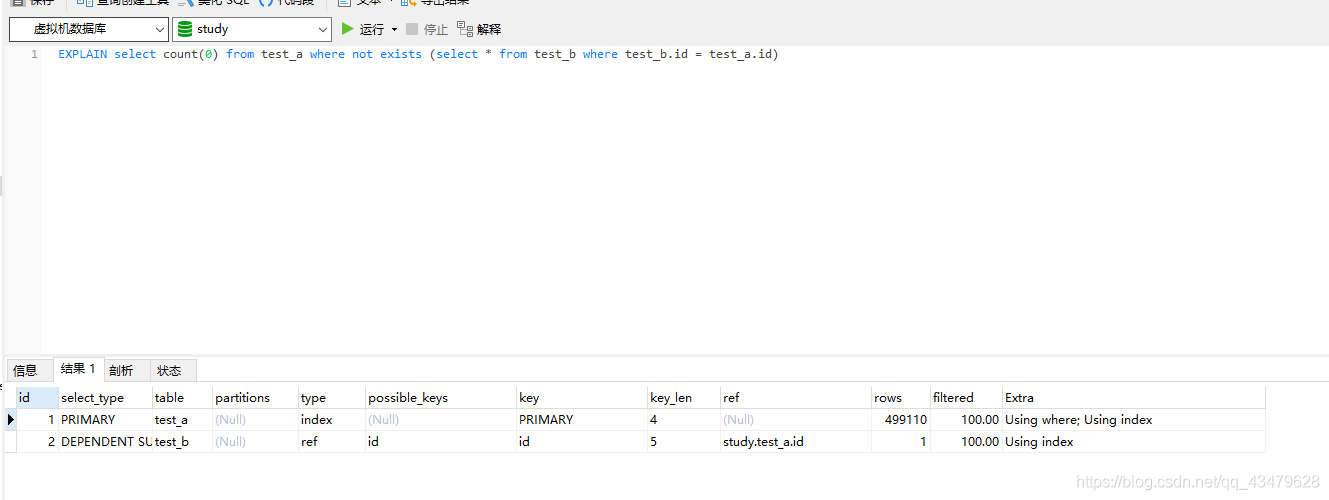
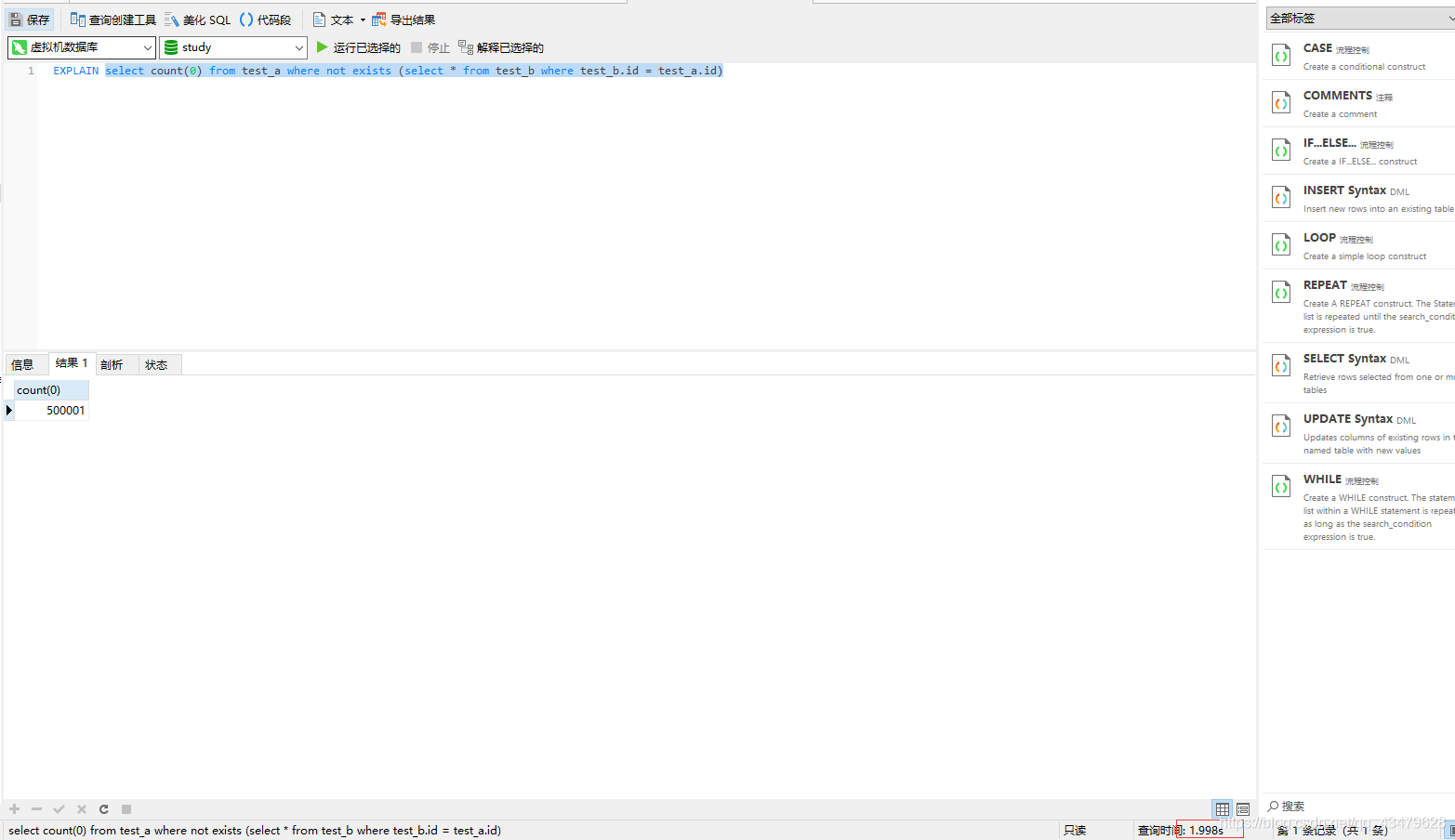
2.1 測驗sql分析EXPLAIN select count(0) from test_a where not exists (select * from test_b where test_b.id = test_a.id)
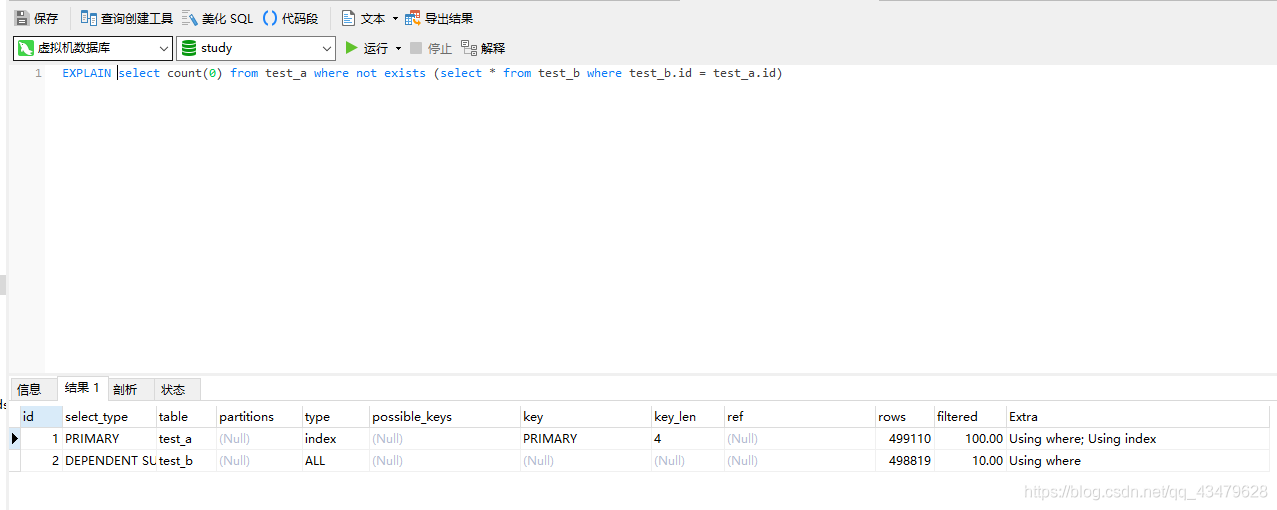
2.2 測驗結果
無結果,資料查詢時間過長無回應
not in
- 測驗sql
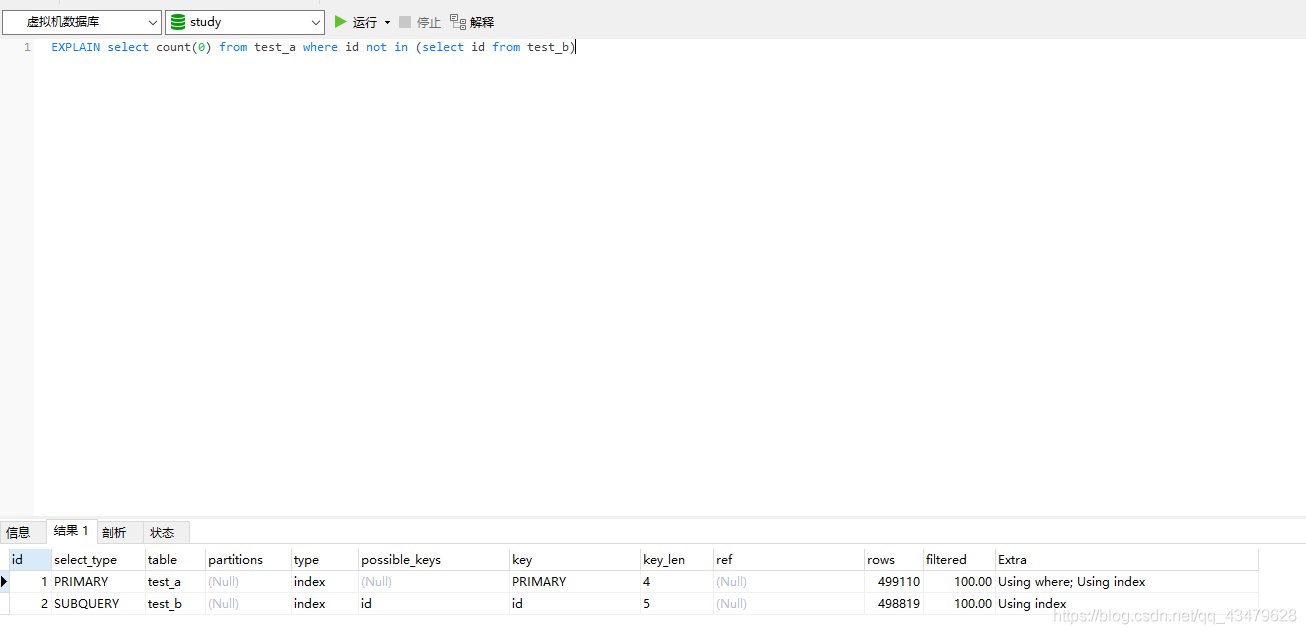
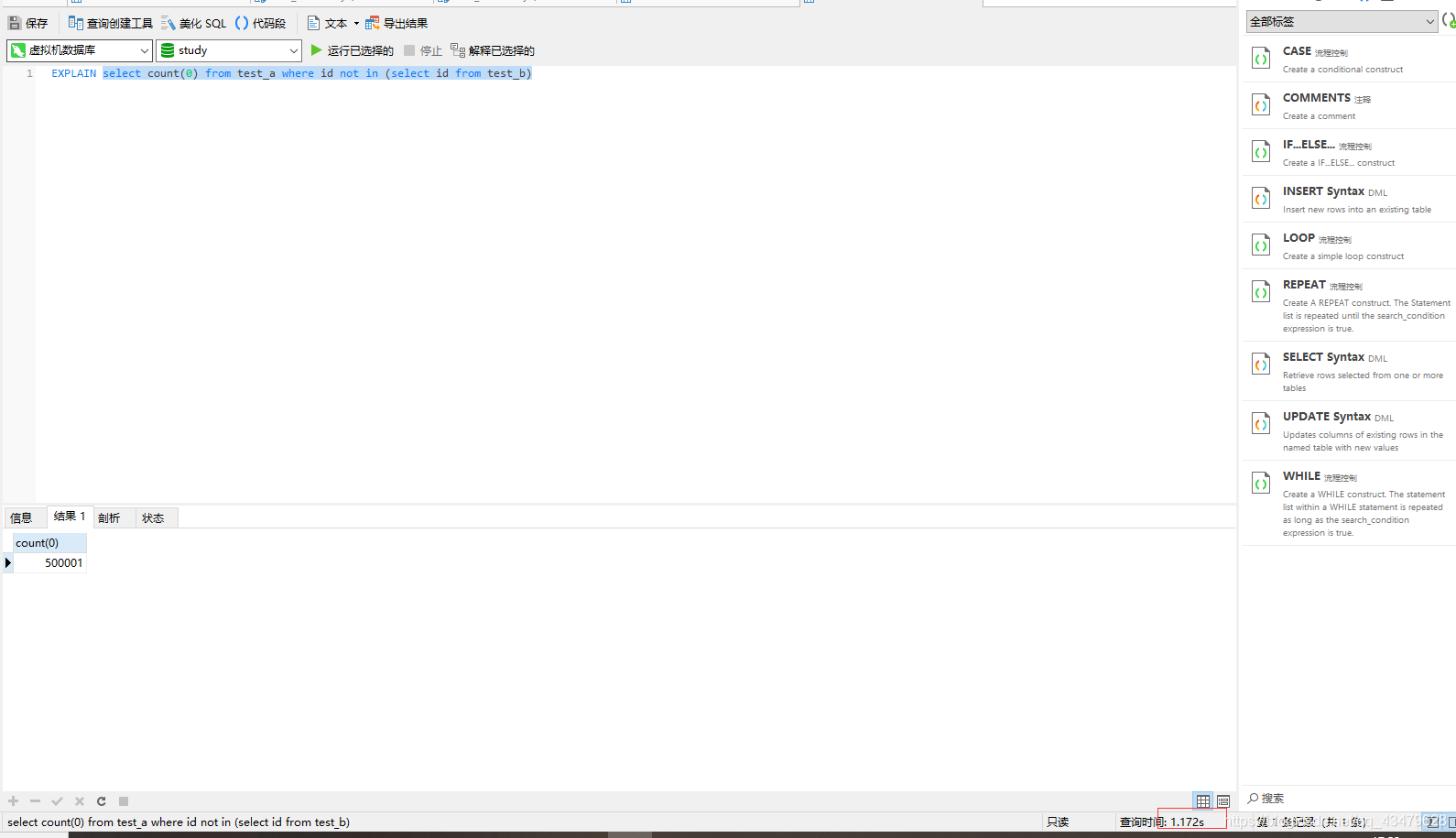
3.1 測驗sql分析EXPLAIN select count(0) from test_a where id not in (select id from test_b)
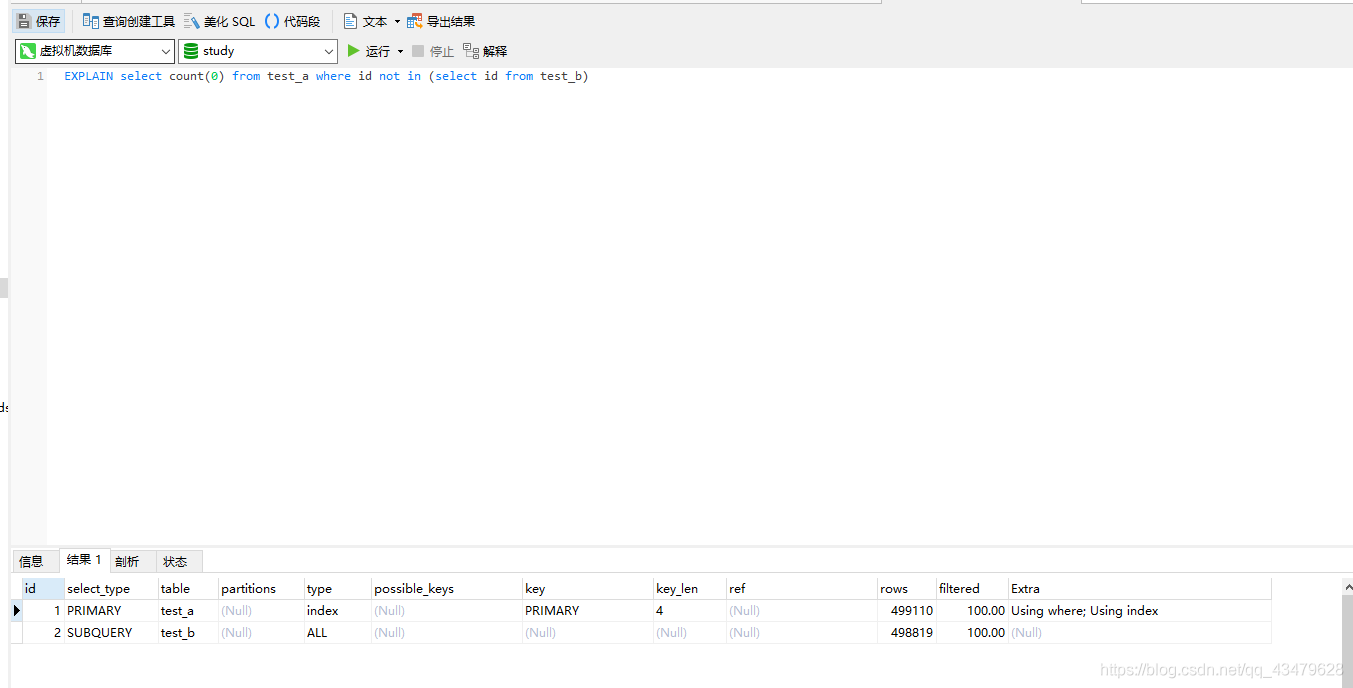
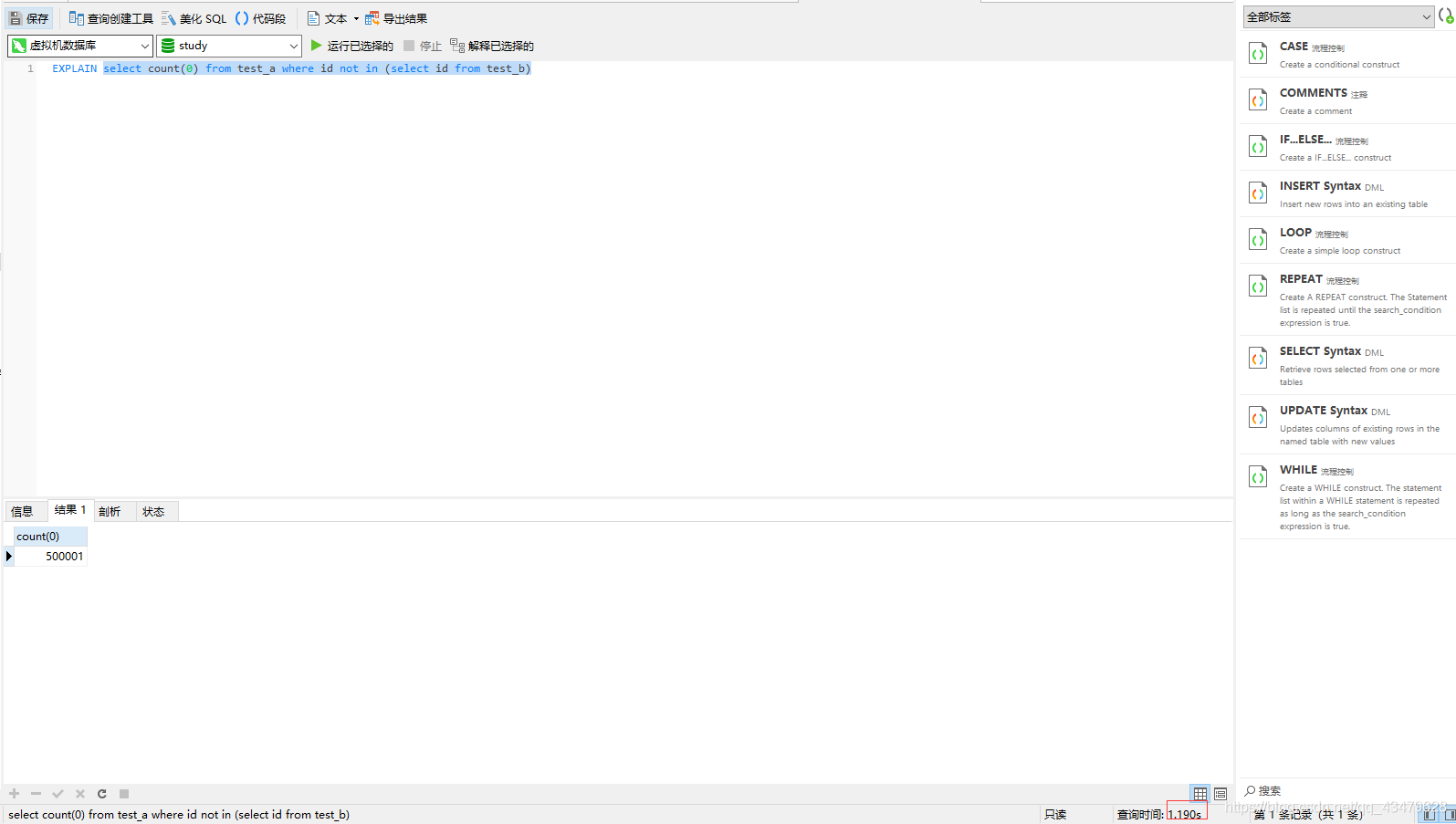
3.2 測驗結果
唯一一個出資料的,1.190s
四、優化處理
- 增加test_b 的id索引
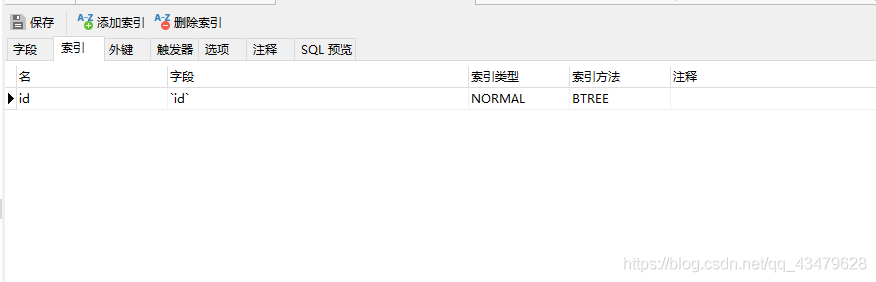
- 查看對應結果
2.1 left join , 0.596s
2.2 not exists , 1.998s
2.3 not in , 1.172s
五、結果分析
- 使用left join, not exists優化not in 陳述句時,必須在存在索引的情況下使用,否則有可能長時間查詢無結果;
- left join在有索引的情況下對于此類情況優化最明顯;
- not exists不一定速度快過not in,exists的原理是先查詢exists前面表回傳的資料,根據資料結果,作為條件與exists后面的查詢進行對比(查詢一條,對比一條),如果滿足后面的條件,則回傳真,然后回傳資料,否則回傳假,無資料,not exists則與之相反,所以not exists快過not in的前提是exists前面的陳述句對應的表查詢回傳的資料量必須小于后面的表查詢回傳的資料量;
- not in還是會走索引,至于是否與mysql版本有關,暫時不做論證;
- 使用Left join,exists優化 in陳述句時,必須要小心是否能觸發索引,否則得不償失,
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/292915.html
標籤:其他
上一篇:低配服務器福音,標星37K+Star開源專案Gogs秒搭Git服務
下一篇:Android架構設計——MVC