文章目錄
- 環境準備
- 安裝kubeadm
- 配置kubeadm
- 搭建K8S集群
- 安裝主節點
- 配置slave節點
- 配置網路
- 運行第一個容器
環境準備
這里準備三臺Ubuntu Server X64 18.04 虛擬 機,如下
192.168.90.31 4核2G 40G硬碟 Kubernetes server1 Master
192.168.90.32 4核2G 40G硬碟 Kubernetes server2 Slave1
192.168.90.33 4核2G 40G硬碟 Kubernetes server3 Slave2
安裝程序中可以使用阿里云的鏡像庫
http://mirrors.aliyun.com/ubuntu
安裝ubuntu 的程序記得修改硬碟空間(如果新建虛擬機后有調整磁盤空間那么這里會有未分配的空間,調整這里的值未最大即可)
固定ip
找到并修改如下檔案,修改保存后 執行 sudo netplan apply 使生效
eric@server1:~$ cat /etc/netplan/00-installer-config.yaml
# This is the network config written by 'subiquity'
network:
ethernets:
ens33:
dhcp4: false
addresses: [192.168.90.31/24]
gateway4: 192.168.90.1
nameservers:
addresses: [8.8.8.8]
version: 2
優化配置
關閉交換空間:sudo swapoff -a
避免開機啟動交換空間:注釋 /etc/fstab 中的 swap
關閉防火墻:ufw disable
安裝docker
# 更新軟體源
sudo apt-get update
# 安裝所需依賴
sudo apt-get -y install apt-transport-https ca-certificates curl software-properties-common
# 安裝 GPG 證書
curl -fsSL http://mirrors.aliyun.com/docker-ce/linux/ubuntu/gpg | sudo apt-key add -
# 新增軟體源資訊
sudo add-apt-repository "deb [arch=amd64] http://mirrors.aliyun.com/docker-ce/linux/ubuntu $(lsb_release -cs) stable"
# 再次更新軟體源
sudo apt-get -y update
# 安裝 Docker CE 版
sudo apt-get -y install docker-ce
docker version 驗證docker安裝成功
eric@server1:/etc$ docker version
Client: Docker Engine - Community
Version: 20.10.8
API version: 1.41
Go version: go1.16.6
Git commit: 3967b7d
配置docker鏡像加速器
eric@server1:/etc$ cat /etc/docker/daemon.json
{
"registry-mirrors": [
"https://registry.docker-cn.com"
]
}
重啟docker docker info驗證加速器是否生效
eric@server1:/etc$ sudo systemctl restart docker
eric@server1:/etc$ sudo docker info
......
Insecure Registries:
127.0.0.0/8
Registry Mirrors:
https://registry.docker-cn.com/
Live Restore Enabled: false
......
修改主機名
hostnamectl set-hostname server1
安裝kubeadm
kubeadm 是 kubernetes 的集群安裝工具,能夠快速安裝 kubernetes 集群,
配置軟體源
# 安裝系統工具
apt-get update && apt-get install -y apt-transport-https
# 安裝 GPG 證書
curl https://mirrors.aliyun.com/kubernetes/apt/doc/apt-key.gpg | apt-key add -
# 寫入軟體源;注意:我們用系統代號為 bionic,但目前阿里云不支持,所以沿用 16.04 的 xenial
cat << EOF >/etc/apt/sources.list.d/kubernetes.list
> deb https://mirrors.aliyun.com/kubernetes/apt/ kubernetes-xenial main
> EOF
安裝 kubeadm,kubelet,kubectl
kubeadm:用于初始化 Kubernetes 集群
kubectl:Kubernetes 的命令列工具,主要作用是部署和管理應用,查看各種資源,創建,洗掉和更新組件
kubelet:主要負責啟動 Pod 和容器
安裝時指定版本 避免 版本太新找不到鏡像
apt-get update
apt-get install -y kubelet=1.14.10-00 kubeadm=1.14.10-00 kubectl=1.14.10-00
通過日志可以看到安裝的版本
Setting up kubelet (1.14.10-00) ...
Created symlink /etc/systemd/system/multi-user.target.wants/kubelet.service → /lib/systemd/system/kubelet.service.
Setting up kubectl (1.14.10-00) ...
Setting up kubeadm (1.14.10-00) ...
配置kubeadm
安裝 kubernetes 主要是安裝它的各個鏡像,而 kubeadm 已經為我們集成好了運行 kubernetes 所需的基本鏡像,但由于國內的網路原因,在搭建環境時,無法拉取到這些鏡像,此時我們只需要修改為阿里云提供的鏡像服務即可解決該問題,
生成并修改組態檔如下:
root@server1:/etc# kubeadm config print init-defaults --kubeconfig ClusterConfiguration > kubeadm.yml
root@server1:/etc# vi kubeadm.yml
root@server1:~# cat kubeadm.yml
apiVersion: kubeadm.k8s.io/v1beta1
bootstrapTokens:
- groups:
- system:bootstrappers:kubeadm:default-node-token
token: abcdef.0123456789abcdef
ttl: 24h0m0s
usages:
- signing
- authentication
kind: InitConfiguration
localAPIEndpoint:
advertiseAddress: 192.168.90.31 ---master ip
bindPort: 6443
nodeRegistration:
criSocket: /var/run/dockershim.sock
name: server1
taints:
- effect: NoSchedule
key: node-role.kubernetes.io/master
---
apiServer:
timeoutForControlPlane: 4m0s
apiVersion: kubeadm.k8s.io/v1beta1
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controlPlaneEndpoint: ""
controllerManager: {}
dns:
type: CoreDNS
etcd:
local:
dataDir: /var/lib/etcd
imageRepository: registry.aliyuncs.com/google_containers --鏡像庫地址
kind: ClusterConfiguration
kubernetesVersion: v1.14.10 --kubeadm 版本
networking:
dnsDomain: cluster.local
podSubnet: "192.168.0.0/16" --ip段
serviceSubnet: 10.96.0.0/12
scheduler: {}
---
--開啟 IPVS 模式
apiVersion: kubeproxy.config.k8s.io/v1alpha1
kind: KubeProxyConfiguration
featureGates:
SupportIPVSProxyMode: true
mode: ipvs
root@server1:~# kubeadm config images list --config kubeadm.yml --查看所需鏡像
registry.aliyuncs.com/google_containers/kube-apiserver:v1.14.10
registry.aliyuncs.com/google_containers/kube-controller-manager:v1.14.10
registry.aliyuncs.com/google_containers/kube-scheduler:v1.14.10
registry.aliyuncs.com/google_containers/kube-proxy:v1.14.10
registry.aliyuncs.com/google_containers/pause:3.1
registry.aliyuncs.com/google_containers/etcd:3.3.10
registry.aliyuncs.com/google_containers/coredns:1.3.1
root@server1:~# kubeadm config images pull --config kubeadm.yml --下載鏡像
[config/images] Pulled registry.aliyuncs.com/google_containers/kube-apiserver:v1.14.10
[config/images] Pulled registry.aliyuncs.com/google_containers/kube-controller-manager:v1.14.10
[config/images] Pulled registry.aliyuncs.com/google_containers/kube-scheduler:v1.14.10
[config/images] Pulled registry.aliyuncs.com/google_containers/kube-proxy:v1.14.10
[config/images] Pulled registry.aliyuncs.com/google_containers/pause:3.1
[config/images] Pulled registry.aliyuncs.com/google_containers/etcd:3.3.10
[config/images] Pulled registry.aliyuncs.com/google_containers/coredns:1.3.1
......
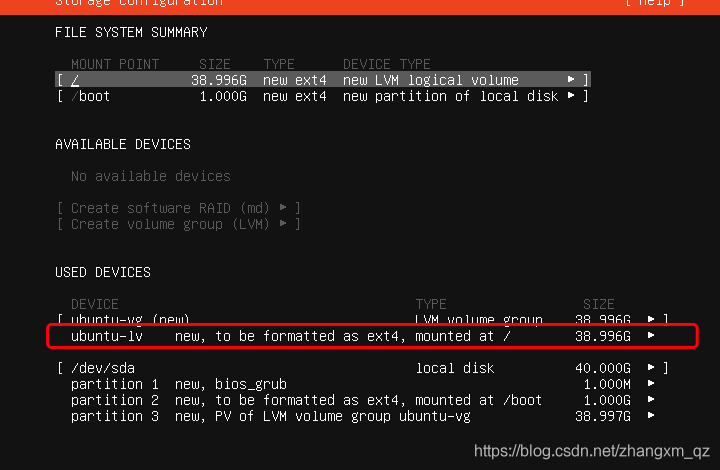
這部分工準備作業做完 后,需要克隆兩臺虛擬機作為從節點,并按照規劃修改ip、主機名
搭建K8S集群
安裝主節點
執行以下命令初始化主節點,該命令指定了初始化時需要使用的組態檔,其中添加 --experimental-upload-certs 引數可以在后續執行加入節點時自動分發證書檔案,追加的 tee kubeadm-init.log 用以輸出日志,
(要使用上文中創建的組態檔來執行該命令)
root@server1:~# kubeadm init --config=kubeadm.yml --experimental-upload-certs | tee kubeadm-init.log
......
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.90.31:6443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:ea5361c0f2876b215d177cd7dab7679ac47bcc85d709edd6522ff72363be4a61
注意:如果安裝 kubernetes 版本和下載的鏡像版本不統一則會出現 timed out waiting for the condition 錯誤,中途失敗或是想修改配置可以使用 kubeadm reset 命令重置配置,再做初始化操作即可,
按照輸出結果進行配置(按照日志提示 使用非root用戶執行如下命令)
mkdir -p $HOME/.kube
cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
# 非 ROOT 用戶執行
chown $(id -u):$(id -g) $HOME/.kube/config
驗證(出現如下輸出證明配置成功)
eric@server1:~$ kubectl get node
NAME STATUS ROLES AGE VERSION
server1 NotReady master 2d3h v1.14.10
kubeadm init 的執行程序
init:指定版本進行初始化操作
preflight:初始化前的檢查和下載所需要的 Docker 鏡像檔案
kubelet-start:生成 kubelet 的組態檔 var/lib/kubelet/config.yaml,沒有這個檔案 kubelet 無法啟動,所以初始化之前的 kubelet 實際上啟動不會成功
certificates:生成 Kubernetes 使用的證書,存放在 /etc/kubernetes/pki 目錄中
kubeconfig:生成 KubeConfig 檔案,存放在 /etc/kubernetes 目錄中,組件之間通信需要使用對應檔案
control-plane:使用 /etc/kubernetes/manifest 目錄下的 YAML 檔案,安裝 Master 組件
etcd:使用 /etc/kubernetes/manifest/etcd.yaml 安裝 Etcd 服務
wait-control-plane:等待 control-plan 部署的 Master 組件啟動
apiclient:檢查 Master 組件服務狀態,
uploadconfig:更新配置
kubelet:使用 configMap 配置 kubelet
patchnode:更新 CNI 資訊到 Node 上,通過注釋的方式記錄
mark-control-plane:為當前節點打標簽,打了角色 Master,和不可調度標簽,這樣默認就不會使用 Master 節點來運行 Pod
bootstrap-token:生成 token 記錄下來,后邊使用 kubeadm join 往集群中添加節點時會用到
addons:安裝附加組件 CoreDNS 和 kube-proxy
配置slave節點
將 slave 節點加入到集群中很簡單,只需要在 slave 服務器上安裝 kubeadm,kubectl,kubelet 三個工具,然后使用 kubeadm join 命令加入即可,我們的兩臺從節點已經安裝了必備的鏡像和 kubeadm,kubectl,kubelet 三個工具 ,因此直接執行kubeadm join 命令,執行join命令需要兩個引數,token 和 discovery-token-ca-cert-hash
token
- 可以通過安裝 master 時的日志查看 token 資訊
- 可以通過 kubeadm token list 命令列印出 token 資訊
- 如果 token 過期,可以使用 kubeadm token create 命令創建新的 token
discovery-token-ca-cert-hash
- 可以通過安裝 master 時的日志查看 sha256 資訊
- 可以通過 openssl x509 -pubkey -in /etc/kubernetes/pki/ca.crt | openssl rsa -pubin -outform der 2>/dev/null | openssl dgst -sha256 -hex | sed ‘s/^.* //’ 命令查看 sha256 資訊
我們到master節點執行生成一個新token如下:
eric@server1:~$ kubeadm token create
9srgjm.6xkcpoiczll8id0i
在master節點查看 discovery-token-ca-cert-hash 如下:
eric@server1:~$ openssl x509 -pubkey -in /etc/kubernetes/pki/ca.crt | openssl rsa -pubin -outform der 2>/dev/null | openssl dgst -sha256 -hex | sed 's/^.* //'
ea5361c0f2876b215d177cd7dab7679ac47bcc85d709edd6522ff72363be4a61
根據上述引數 分別在兩臺從節點執行如下命令 進行注冊
eric@server3:~$ sudo kubeadm join 192.168.90.31:6443 --token 9srgjm.6xkcpoiczll8id0i --discovery-token-ca-cert-hash sha256:ea5361c0f2876b215d177cd7dab7679ac47bcc85d709edd6522ff72363be4a61
[sudo] password for eric:
[preflight] Running pre-flight checks
[WARNING IsDockerSystemdCheck]: detected "cgroupfs" as the Docker cgroup driver. The recommended driver is "systemd". Please follow the guide at https://kubernetes.io/docs/setup/cri/
[WARNING SystemVerification]: this Docker version is not on the list of validated versions: 20.10.8. Latest validated version: 18.09
[preflight] Reading configuration from the cluster...
[preflight] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -oyaml'
[WARNING RequiredIPVSKernelModulesAvailable]:
The IPVS proxier may not be used because the following required kernel modules are not loaded: [ip_vs_wrr ip_vs_sh ip_vs ip_vs_rr]
or no builtin kernel IPVS support was found: map[ip_vs:{} ip_vs_rr:{} ip_vs_sh:{} ip_vs_wrr:{} nf_conntrack_ipv4:{}].
However, these modules may be loaded automatically by kube-proxy if they are available on your system.
To verify IPVS support:
Run "lsmod | grep 'ip_vs|nf_conntrack'" and verify each of the above modules are listed.
If they are not listed, you can use the following methods to load them:
1. For each missing module run 'modprobe $modulename' (e.g., 'modprobe ip_vs', 'modprobe ip_vs_rr', ...)
2. If 'modprobe $modulename' returns an error, you will need to install the missing module support for your kernel.
[kubelet-start] Downloading configuration for the kubelet from the "kubelet-config-1.14" ConfigMap in the kube-system namespace
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Activating the kubelet service
[kubelet-start] Waiting for the kubelet to perform the TLS Bootstrap...
This node has joined the cluster:
* Certificate signing request was sent to apiserver and a response was received.
* The Kubelet was informed of the new secure connection details.
Run 'kubectl get nodes' on the control-plane to see this node join the cluster.
主節點驗證 ,可以看到兩個從節點注冊成功
eric@server1:~$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
server1 NotReady master 2d3h v1.14.10
server2 NotReady <none> 2m21s v1.14.10
server3 NotReady <none> 83s v1.14.10
如果 slave 節點加入 master 時配置有問題可以在 slave 節點上使用 kubeadm reset 重置配置再使用 kubeadm join 命令重新加入即可,希望在 master 節點洗掉 node ,可以使用 kubeadm delete nodes 洗掉
查看pod狀態,coredns尚未運行,需要安裝網路插件
eric@server1:~$ kubectl get pod -n kube-system -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
coredns-7b7df549dd-htqc5 0/1 Pending 0 2d3h <none> <none> <none> <none>
coredns-7b7df549dd-smmfh 0/1 Pending 0 2d3h <none> <none> <none> <none>
etcd-server1 1/1 Running 0 2d3h 192.168.90.31 server1 <none> <none>
kube-apiserver-server1 1/1 Running 1 2d3h 192.168.90.31 server1 <none> <none>
kube-controller-manager-server1 1/1 Running 1 2d3h 192.168.90.31 server1 <none> <none>
kube-proxy-hsnwk 1/1 Running 0 3m14s 192.168.90.33 server3 <none> <none>
kube-proxy-r8cq8 1/1 Running 0 2d3h 192.168.90.31 server1 <none> <none>
kube-proxy-xvp28 1/1 Running 0 4m12s 192.168.90.32 server2 <none> <none>
kube-scheduler-server1 1/1 Running 1 2d3h 192.168.90.31 server1 <none> <none>
配置網路
容器網路是容器選擇連接到其他容器、主機和外部網路的機制,容器的 runtime 提供了各種網路模式,每種模式都會產生不同的體驗,例如,Docker 默認情況下可以為容器配置以下網路:
- none: 將容器添加到一個容器專門的網路堆疊中,沒有對外連接,
- host: 將容器添加到主機的網路堆疊中,沒有隔離, default
- bridge: 默認網路模式,每個容器可以通過 IP 地址相互連接,
- 自定義網橋: 用戶定義的網橋,具有更多的靈活性、隔離性和其他便利功能
CNI
CNI(Container Network Interface) 是一個標準的,通用的介面,在Docker,Kubernetes,Mesos平臺中, 容器網路解決方案 有 flannel,calico,weave等,平臺只要提供一個標準的介面協議,方案提供者根據介面為滿足該協議介面的容器平臺提供網路服務功能,CNI 就是這個標準介面協議,
K8S中的CNI插件
CNI 約定了基本的規則,在配置或銷毀容器時動態配置合適的網路和資源,插件實作配置和管理 IP 地址,通常提供 IP 管理、容器的 IP 分配、以及多主機連接相關的功能,容器運行時會呼叫網路插件,在容器啟動時分配 IP 地址并配置網路,在洗掉容器時再次呼叫它清理這些資源,協調器決定了容器應該加入哪個網路以及它需要呼叫哪個插件,然后,插件會將介面添加到容器網路命名空間中,它會在主機上進行更改,包括將 veth 的其他部分連接到網橋,再之后,它會通過呼叫單獨的 IPAM(IP地址管理)插件來分配 IP 地址并設定路由,
在 Kubernetes 中,kubelet 可以在適當的時間呼叫它找到的插件,為通過 kubelet 啟動的 pod進行自動的網路配置,Kubernetes 中可選的 CNI 插件包括:Flannel、Calico、Canal、Weave
為什么選Calico
Calico 為容器和虛擬機提供了安全的網路連接解決方案,并經過了大規模生產驗證(在公有云和跨數千個集群節點中),可與 Kubernetes,OpenShift,Docker,Mesos,DC / OS 和 OpenStack 集成,
Calico 還提供網路安全規則的動態實施,使用 Calico 的簡單策略語言,您可以實作對容器,虛擬機作業負載和裸機主機端點之間通信的細粒度控制,
安裝calico
主節點執行如下命令
kubectl apply -f https://docs.projectcalico.org/v3.7/manifests/calico.yaml
configmap/calico-config created
customresourcedefinition.apiextensions.k8s.io/felixconfigurations.crd.projectcalico.org created
customresourcedefinition.apiextensions.k8s.io/ipamblocks.crd.projectcalico.org created
customresourcedefinition.apiextensions.k8s.io/blockaffinities.crd.projectcalico.org created
customresourcedefinition.apiextensions.k8s.io/ipamhandles.crd.projectcalico.org created
customresourcedefinition.apiextensions.k8s.io/ipamconfigs.crd.projectcalico.org created
customresourcedefinition.apiextensions.k8s.io/bgppeers.crd.projectcalico.org created
customresourcedefinition.apiextensions.k8s.io/bgpconfigurations.crd.projectcalico.org created
customresourcedefinition.apiextensions.k8s.io/ippools.crd.projectcalico.org created
customresourcedefinition.apiextensions.k8s.io/hostendpoints.crd.projectcalico.org created
customresourcedefinition.apiextensions.k8s.io/clusterinformations.crd.projectcalico.org created
customresourcedefinition.apiextensions.k8s.io/globalnetworkpolicies.crd.projectcalico.org created
customresourcedefinition.apiextensions.k8s.io/globalnetworksets.crd.projectcalico.org created
customresourcedefinition.apiextensions.k8s.io/networkpolicies.crd.projectcalico.org created
customresourcedefinition.apiextensions.k8s.io/networksets.crd.projectcalico.org created
clusterrole.rbac.authorization.k8s.io/calico-kube-controllers created
clusterrolebinding.rbac.authorization.k8s.io/calico-kube-controllers created
clusterrole.rbac.authorization.k8s.io/calico-node created
clusterrolebinding.rbac.authorization.k8s.io/calico-node created
daemonset.extensions/calico-node created
serviceaccount/calico-node created
deployment.extensions/calico-kube-controllers created
serviceaccount/calico-kube-controllers created
確認是否安裝成功,執行如下命令 需要等待 所有狀態未 running 可能需要等待 3-5分鐘
watch kubectl get pods --all-namespaces
Every 2.0s: kubectl get pods --all-namespaces server1: Mon Aug 9 13:56:02 2021
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system calico-kube-controllers-f6ff9cbbb-btnxp 0/1 Running 2 3m12s
kube-system calico-node-7jp5d 1/1 Running 0 3m12s
kube-system calico-node-hktzm 1/1 Running 0 3m12s
kube-system calico-node-z8bpj 1/1 Running 0 3m12s
kube-system coredns-7b7df549dd-htqc5 0/1 Running 1 2d4h
kube-system coredns-7b7df549dd-smmfh 0/1 Running 1 2d4h
kube-system etcd-server1 1/1 Running 0 2d4h
kube-system kube-apiserver-server1 1/1 Running 1 2d4h
kube-system kube-controller-manager-server1 1/1 Running 1 2d4h
kube-system kube-proxy-hsnwk 1/1 Running 0 27m
kube-system kube-proxy-r8cq8 1/1 Running 0 2d4h
kube-system kube-proxy-xvp28 1/1 Running 0 28m
kube-system kube-scheduler-server1 1/1 Running 1 2d4h
至此基本環境已部署完畢
在使用 watch kubectl get pods --all-namespaces 命令觀察 Pods 狀態時如果出現 ImagePullBackOff 無法 Running 的情況,請嘗試使用如下步驟處理:
Master 中洗掉 Nodes:kubectl delete nodes
Slave 中重置配置:kubeadm reset
Slave 重啟計算機:reboot
Slave 重新加入集群:kubeadm join
運行第一個容器
檢查集群狀態
eric@server1:~$ kubectl get cs --檢查組件運行狀態
NAME STATUS MESSAGE ERROR
scheduler Healthy ok --調度服務 作用是將pod調度到node
controller-manager Healthy ok --自動化修復服務 作用:Node宕機后自動修復
etcd-0 Healthy {“health”:“true”} --服務注冊與發現
eric@server1:~$ kubectl cluster-info
Kubernetes master is running at https://192.168.90.31:6443 --主節點狀態
KubeDNS is running at https://192.168.90.31:6443/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy --dns服務
To further debug and diagnose cluster problems, use ‘kubectl cluster-info dump’.
eric@server1:~$ kubectl get nodes --節點狀態
NAME STATUS ROLES AGE VERSION
server1 Ready master 2d4h v1.14.10
server2 Ready 34m v1.14.10
server3 Ready 33m v1.14.10
運行一個ngxin實體
#使用 kubectl 命令創建兩個監聽 80 埠的 Nginx Pod
eric@server1:~$ kubectl run nginx --image=nginx --replicas=2 --port=80
kubectl run --generator=deployment/apps.v1 is DEPRECATED and will be removed in a future version. Use kubectl run --generator=run-pod/v1 or kubectl create instead.
deployment.apps/nginx created
eric@server1:~$ kubectl get pods --查看pod狀態 從初始化到運行 需要一定的時間
NAME READY STATUS RESTARTS AGE
nginx-755464dd6c-kdlp2 1/1 Running 0 94s
nginx-755464dd6c-r6gf4 1/1 Running 0 94s
eric@server1:~$ kubectl get deployment --查看已部署的服務
NAME READY UP-TO-DATE AVAILABLE AGE
nginx 2/2 2 2 111s
eric@server1:~$ kubectl expose deployment nginx --port=80 --type=LoadBalancer --映射服務讓用戶可以訪問
service/nginx exposed
eric@server1:~$ kubectl get services --查看已發布的服務
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 2d4h
nginx LoadBalancer 10.96.91.244 <pending> 80:31480/TCP 11s ---可以看到 80埠映射到了 31480 埠
訪問服務
通過master 地址的31480 埠訪問nginx
http://192.168.141.130:31480/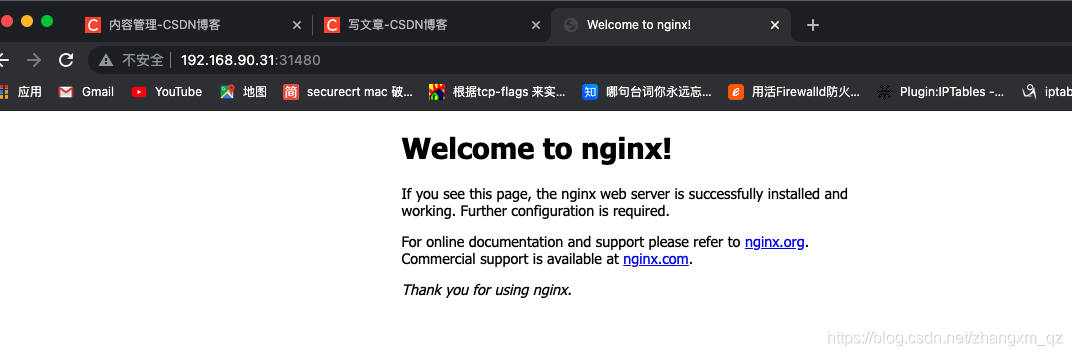
洗掉服務
eric@server1:~$ kubectl delete deployment nginx
deployment.extensions "nginx" deleted
eric@server1:~$ kubectl delete service nginx
service "nginx" deleted
eric@server1:~$
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/293139.html
標籤:其他
上一篇:shell腳本——日常巡檢腳本