文章目錄
- 一、冒泡排序
- 1.1.時間空間復雜度分析
- 二、快速排序
- 2.1.快排的遞回實作
- 2.1.1.挖坑法
- 2.1.2.左右指標法
- 2.1.3.前后指標法
- 2.2.快排的非遞回實作
- 2.2.1.挖坑法
- 2.2.2.左右指標法
- 2.2.3.前后指標法
- 2.2.4.用堆疊實作非遞回
- 2.3.快排的優化
- 2.3.1三數取中
- 2.3.2.小區間優化
- 2.4.時間空間復雜度分析
一、冒泡排序
冒泡排序應該是最簡單也是最容易理解的一種排序演算法,它的邏輯是每趟將最大的數移到陣列的最右邊:
我之前寫過冒泡排序的詳細說明,鏈接如下:冒泡排序
代碼實作:
//交換函式
void Swap(int* a, int* b)
{
int tmp = *a;
*a = *b;
*b = tmp;
}
void BubbleSort(int* a, int n)
{
int i,j;
for (i = 0; i < n - 1; i++)//趟數
{
int exchange = 0;//如果沒有發生排序說明已經有序,exchange為0
for (j = 0; j < n - i - 1; j++)//交換的次數
{
if (a[j] > a[j + 1])//交換兩個元素
{
Swap(&a[j], &a[j + 1]);
exchange = 1;//第一趟發生了排序
}
}
if (exchange == 0)//如果沒發生排序直接跳出回圈
{
break;
}
}
}
1.1.時間空間復雜度分析
最好的情況:排序前的陣列已經是有序的,則只需要進行n-1次比較即可,沒有資料交換,時間復雜度為O(N),
最壞的情況:排序前陣列,則需要比較并交換n-1+n-2+…3+2+1次,也就是n(n-1)/2次 時間復雜度為O(N2),
時間復雜度是最壞的情況,O(N2)
空間復雜度是O(1).
二、快速排序
快排的性能在所有排序演算法里面是最好的,資料規模越大快速排序的性能越優,快排在極端情況下會退化成 O(N2)的演算法,因此假如在提前得知處理資料可能會出現極端情況的前提下,可以選擇使用較為穩定的歸并排序,
快速排序演算法通過多次比較和交換來實作排序,其排序流程如下:
- 首先設定一個分界值,通過該分界值將陣列分成左右兩部分,
- 將大于或等于分界值的資料集中到陣列右邊,小于分界值的資料集中到陣列的左邊,此時,左邊部分中各元素都小于或等于分界值,而右邊部分中各元素都大于或等于分界值,
- 然后,左邊和右邊的資料可以獨立排序,對于左側的陣列資料,又可以取一個分界值,將該部分資料分成左右兩部分,同樣在左邊放置較小值,右邊放置較大值,右側的陣列資料也可以做類似處理,
- 重復上述程序,可以看出,這是一個遞回定義,通過遞回將左側部分排好序后,再遞回排好右側部分的順序,當左、右兩個部分各資料排序完成后,整個陣列的排序也就完成了,
快速排序的比較和交換方式可以通過遞回和非遞回的形式完成,每種形式又可以通過三種方式完成:
2.1.快排的遞回實作
2.1.1.挖坑法
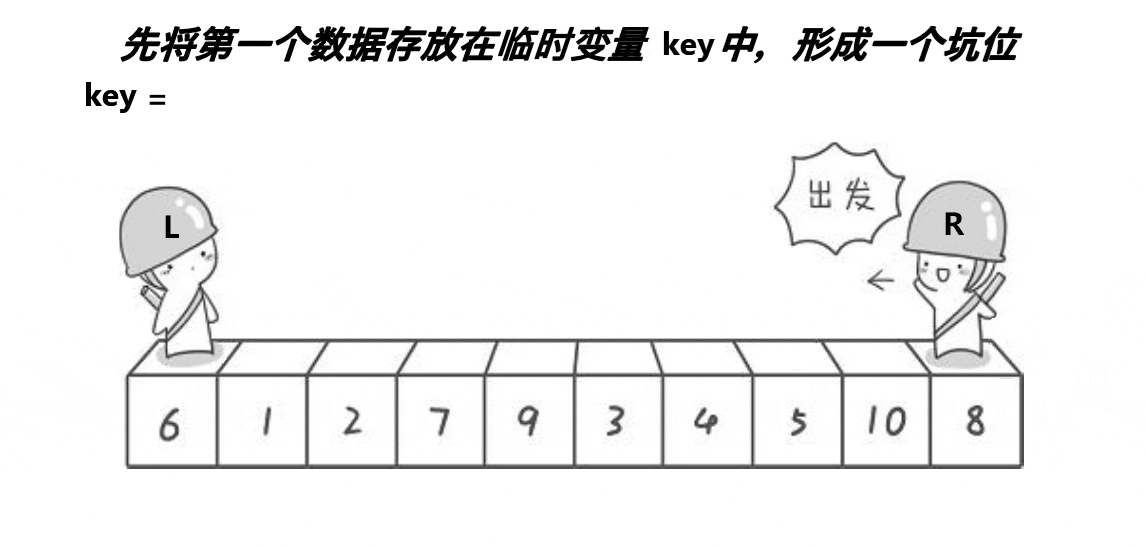
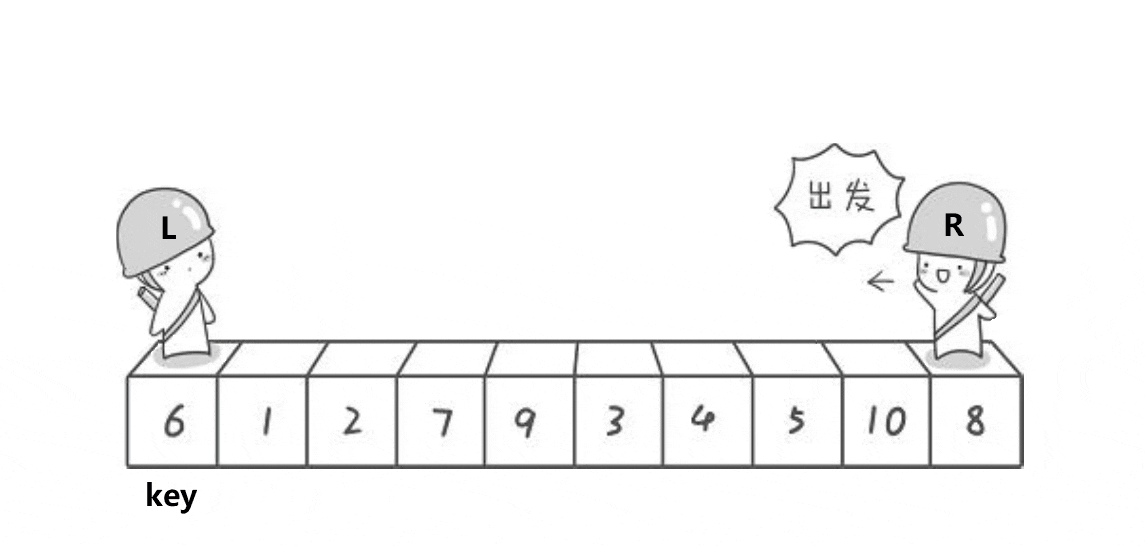
挖坑法的實作思路是:
- 選一個數為關鍵字,同時這個數的下標為坑位pivot,同時定義begin和end,begin左向右走,end從右向左走,(若在最左邊挖坑,則需要end先走;若在最右邊挖坑,則需要begin先走),這里選擇最左邊為坑位,
- 在走的程序中,若end遇到小于key的數,則將該數放入坑位,并在此處形成一個坑位,這時begin再向后走,若遇到大于key的數,則將其放入之前坑位,自己又形成一個坑位,
- 如此回圈下去,直到最終begin和right相遇,這時將key放入坑位,一趟排序就完成,
- 最終key左邊都比它小,右邊都比它大:
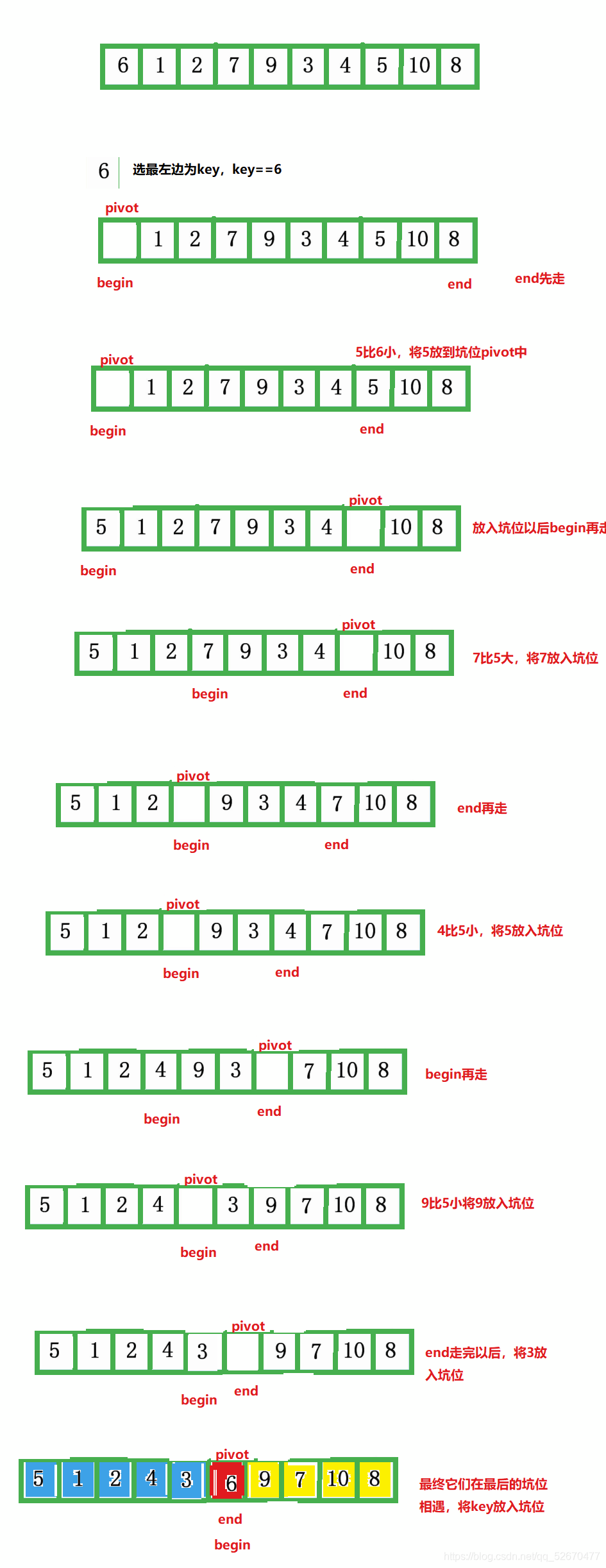
這樣一趟排序讓6的左邊都是比它小的數,右邊都是比它大的數,如果再將6的左區間和右區間用相同的方法遞回下去,則可以實作最終的排序,
代碼實作:
//挖坑法
void QuickSort1(int* a, int left, int right)//left是陣列a的左下標,right是右下標
{
if (left >= right)//當只有一個資料或是序列不存在時,不需要進行操作
{
return;
}
int begin = left, end = right;//確定begin和end的位置
int pivot = begin;//選最左邊左邊為坑
int key = a[begin];//選最左邊的元素為key
while (begin < end)//begin和end相遇時停止
{
//右邊找小,放到左邊
while (begin < end && a[end] >= key)//遇到大于等于key的元素就繼續向右走
{
end--;
}
//小的放到坑位,自己形成新的坑位
a[pivot] = a[end];
pivot = end;
//左邊找大,自己形成新的坑
while (begin < end && a[begin] <= key)//遇到比小于等于key的元素就繼續往左走
{
begin++;
}
//大的放到坑位,自己形成新的坑位
a[pivot] = a[begin];
pivot = begin;
}
a[pivot] = key;//begin和right相遇后跳出回圈,將key放入相遇的坑位
QuickSort1(a, left,pivot-1);//遞回左區間
QuickSort1(a, pivot+1,right);//遞回右區間
}
2.1.2.左右指標法
左右指標法和挖坑法差不多,唯一的區別在于左右指標法是交換兩個數,挖坑法是將數放入坑里:
- 選出一個key,一般是陣列最左邊或是最右邊的數,
- 定義一個begin和一個end,begin從左向右走,end從右向左走,(如果選擇最左邊的資料作為key,則需要end先走;若選擇最右邊的資料作為key,則需要left先走),
- 以最左邊的數為key舉例,在走的程序中,若end遇到小于key的數,則停下,begin開始走,直到L遇到一個大于key的數時,將end和begin的內容交換,end再次開始走,如此進行下去,直到end和begin最終相遇,此時交換key和相遇位置的值,
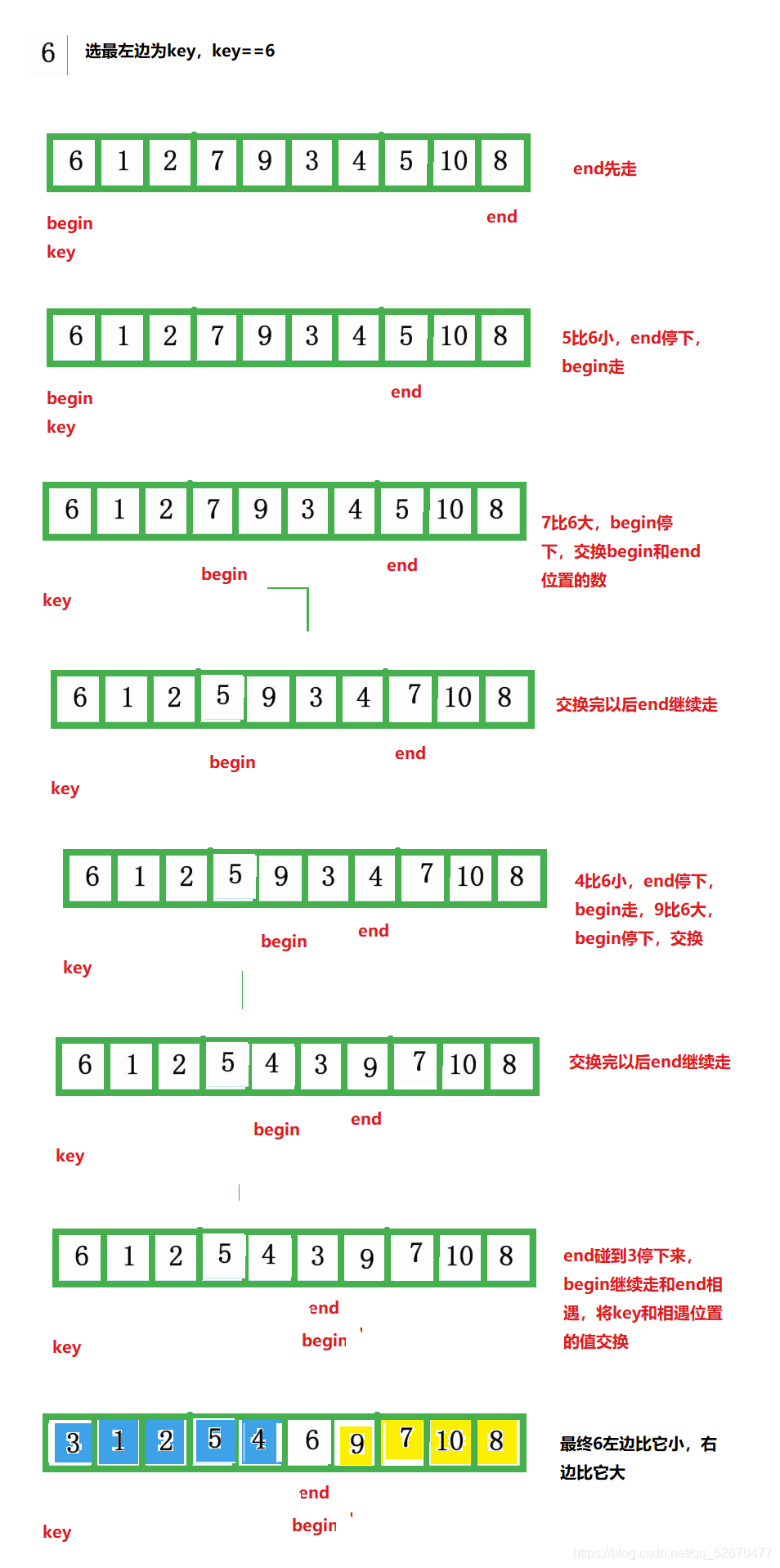
另外,這種方法和挖坑法排完一趟后數的順序是不一樣的,
再將6的左區間和右區間用相同的方法遞回下去,則可以實作最終的排序,
//左右指標快排
void QuickSort2(int* a, int left, int right)
{
if (left >= right)//當只有一個資料或是序列不存在時,不需要進行操作
{
return;
}
int begin = left, end = right;//確定begin和end的位置
int key = begin;//key為最左邊的元素
while (begin < end)
{
//找小
while (begin < end && a[end] >= a[key])
{
end--;
}
//找大
while (begin < end && a[begin] <= a[key])
{
begin++;
}
Swap(&a[begin], &a[end]);//交換
}
Swap(&a[begin], &a[key]);//相遇時和key交換
QuickSort1(a, left, begin - 1);//key的左序列進遞回
QuickSort1(a, begin + 1, right);//key的右序列進行遞回
}
2.1.3.前后指標法
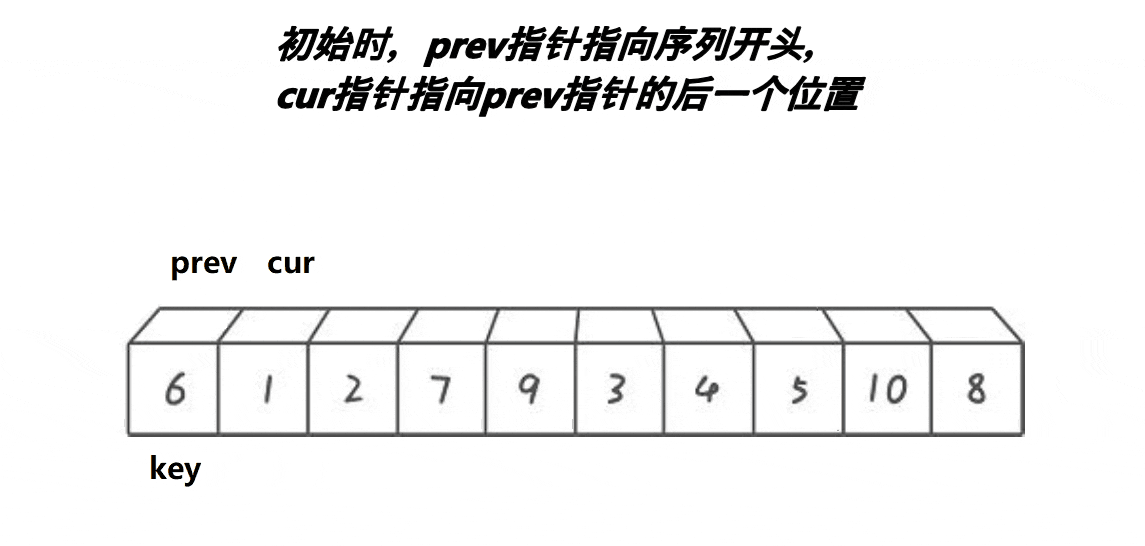
前后指標法的步驟:
- 選出一個key,一般是最左邊,
- prev指標指向序列開頭,cur指標指向prev+1的位置,
- cur一直往右走,如果cur指向的內容小于key,則prev先向右移動一位,然后交換prev和cur指標指向的內容;若cur指向的內容大于key,則不交換,如此進行下去,直到cur指標越界,此時將key和prev指標指向的內容交換,即完成一次排序,
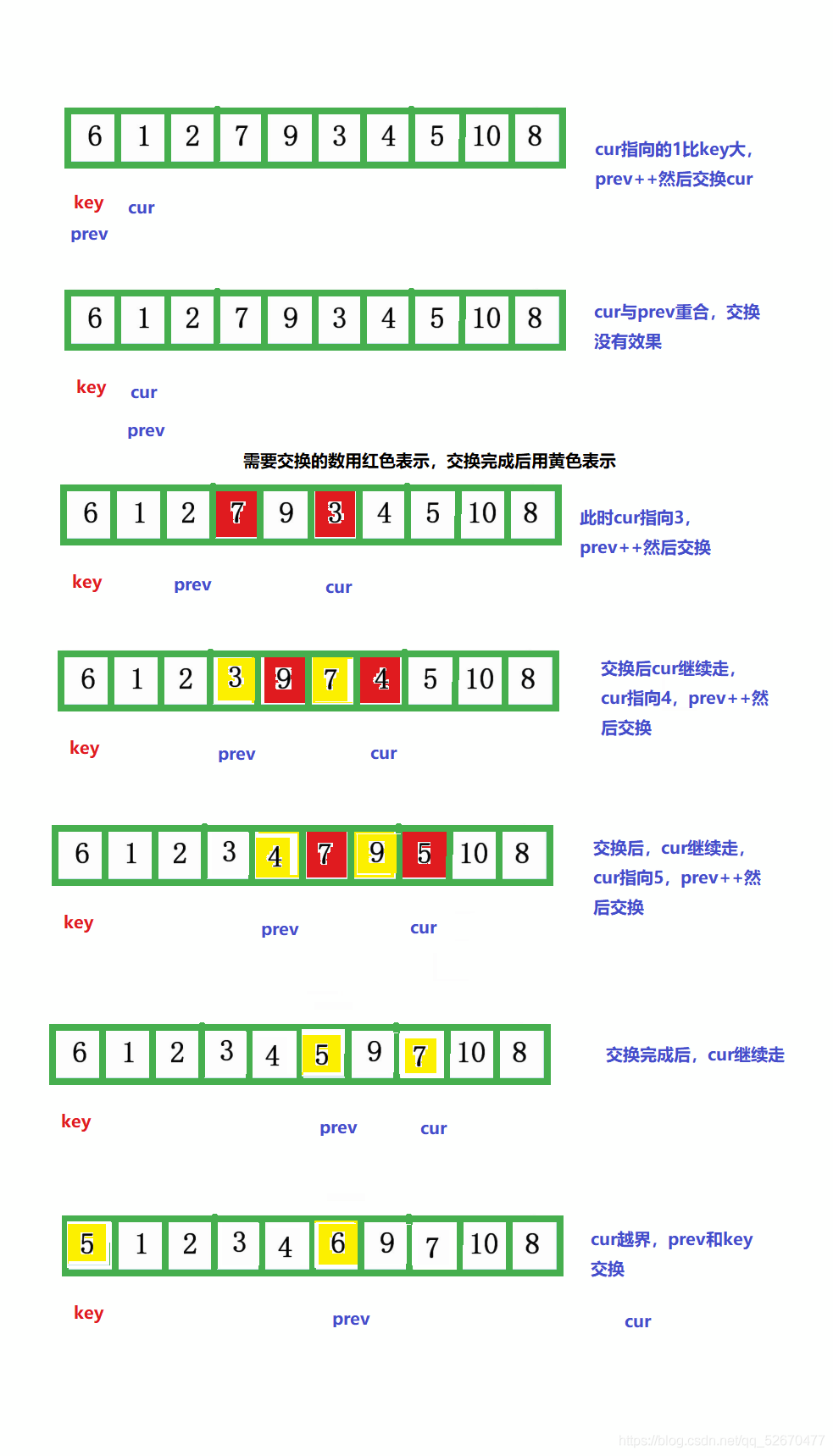
再將6的左區間和右區間用相同的方法遞回下去,則可以實作最終的排序,
//前后指標快排
int QuickSort3(int* a, int left, int right)
{
if (left >= right)//當只有一個資料或是序列不存在時,不需要進行操作
{
return;
}
int key = left;
int prev = left, cur = left + 1;
while (cur <= right)//當cur>right也就是越界時,跳出回圈
{
if (a[cur] < a[key] && prev++ != cur)
{
Swap(&a[prev], &a[cur]);//交換
}
cur++;
}
Swap(&a[key], &a[prev]);//交換key和prev指標指向的內容
QuickSort3(a, left, prev - 1);//key的左序列進行遞回
QuickSort3(a, prev + 1, right);//key的右序列進行遞回
}
2.2.快排的非遞回實作
如果使用非遞回實作,也就意味著我們需要使用額外的操作來起到遞回的效果,一般來說可以用回圈或者堆疊模擬遞回的程序,這里只能使用堆疊來實作,
既然要用非遞回,那么我們原來的遞回函式就要修改成非遞回只能排一趟了,但具體的思路沒有變,只是多了一個回傳值:
2.2.1.挖坑法
//挖坑法
int PartSort1(int* a, int left, int right)
{
if (left >= right)//當只有一個資料或是序列不存在時,不需要進行操作
{
return;
}
int begin = left, end = right;
int pivot = begin;
int key = a[begin];
while (begin < end)
{
//右邊找小,放到左邊
while (begin < end && a[end] >= key)
{
end--;
}
//小的放到坑位,自己形成新的坑位
a[pivot] = a[end];
pivot = end;
//左邊找大,自己形成新的坑
while (begin < end && a[begin] <= key)
{
begin++;
}
a[pivot] = a[begin];
pivot = begin;
}
a[pivot] = key;
return pivot;//回傳key的下標位置
}
2.2.2.左右指標法
//左右指標法
int PartSort2(int* a, int left, int right)
{
int begin = left, end = right;
int key = begin;
while (begin < end)
{
//找小
while (begin < end && a[end] >= a[key])
{
end--;
}
//找大
while (begin < end && a[begin]<= a[key])
{
begin++;
}
Swap(&a[begin], &a[end]);
}
Swap(&a[begin], &a[key]);
return key;//回傳key的下標位置
}
2.2.3.前后指標法
//前后指標法
int PartSort3(int* a, int left, int right)
{
int index = GetMidIndex(a, left, right);
Swap(&a[left], &a[index]);
int key = left;
int prev = left, cur = left + 1;
while (cur <= right)
{
if (a[cur] < a[key]&&prev++!=cur)
{
prev++;
Swap(&a[prev], &a[cur]);
}
cur++;
}
Swap(&a[key], &a[prev]);
return prev;
}
2.2.4.用堆疊實作非遞回
利用堆疊先進后出的特點,用堆疊實作非遞回的思路:
- 一開始將陣列的最后一個元素的下標和第一個元素的下標入堆疊,
- 當堆疊不為空時,讀取堆疊中的元素,一次讀取元素:一個記為left,另一個記為right,這兩個元素是排序的左右下標,然后呼叫快排的單趟排序,排完后獲得了key的下標,然后判斷key的左序列和右序列是否還需要排序,若還需要排序,就將相應序列的L和R入堆疊;序列只有一個元素或是不存在則不需要排序,就不需要將該序列的資訊入堆疊,
- 反復執行步驟2.直到堆疊為空為止,
在這里需要用到堆疊的函式,在之前的文章中有線性表之堆疊和佇列
void QuickSortNonR(int* a, int n)
{
ST st;//創建一個堆疊
StackInit(&st);//初始化堆疊
//堆疊里的區間就是需要被單趟分割排序的
StackPush(&st, n - 1);//將最后一個元素下標入堆疊
StackPush(&st, 0);//將第一個元素下標入堆疊
while (!StackEmpty(&st))//堆疊不為空則執行回圈
{
int left = StackTop(&st);//獲取左邊第一個元素的下標
StackPop(&st);//彈出左邊第一個元素的下標
int right = StackTop(&st);//獲取右邊第一個元素
StackPop(&st);//彈出右邊第一個元素的下標
int keyIndex = PartSort1(a, left, right);//快排并獲取回傳的key的位置
//這一次快排以后,陣列的區間如下:
//[left,keyIndex-1]keyIndex[keyIndex+1,right]
//接下來只需要將左右區間的left,right壓堆疊即可
if (keyIndex + 1 < right)
//如果keyIndex + 1 >= right說明右區間沒有元素,不用入堆疊
{
StackPush(&st, right);//右區間的最后一個元素入堆疊
StackPush(&st, keyIndex + 1);//右區間第一個元素入堆疊
}
if (left < keyIndex - 1)
//如果left > keyIndex - 1說明左區間沒有元素,不用入堆疊
{
StackPush(&st, keyIndex - 1);//左區間最后一個元素入堆疊
StackPush(&st, left);//左區間第一個元素入堆疊
}
}
StackDestory(&st);//銷毀堆疊
}
注意入堆疊和出堆疊的順序不要弄錯,如果是先取left后取right,則應該先入right,后入left,
2.3.快排的優化
2.3.1三數取中
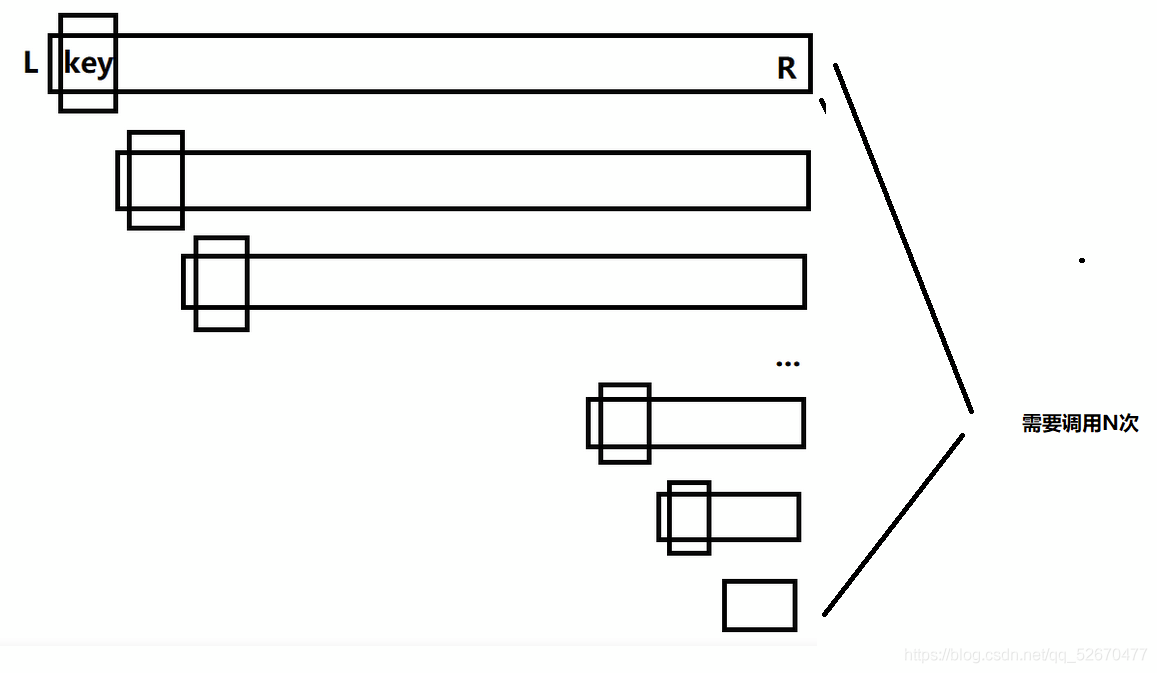
理想情況下,對于一個大小為N的陣列,每次遞回的左右區間中的元素個數如果都相同,那么只需要呼叫log2N次即可,
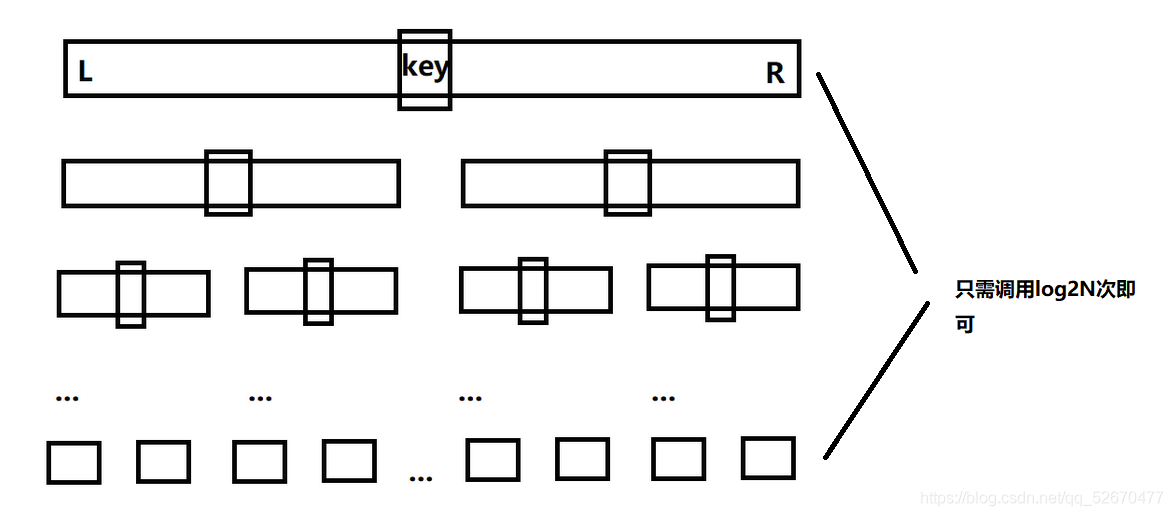
但是當陣列有序或者接近有序時,我們若是依然每次都選取最左邊作為key,這就會導致左邊區間根本就沒有數,右邊區間的數是除了key剩下的數,這樣就必須呼叫N次遞回了,那么快速排序的效率就會非常低,
三數取中的意思是取陣列左邊,中間,右邊三個數中不是最大也不是最小的那個數,然后回傳下標,接著交換這個數和最左邊的數即可:
//三數取中
int GetMidIndex(int* a, int left, int right)
{
int mid = (left + right) / 2;//陣列中間元素的下標
if (a[left] < a[mid])
{
if (a[mid] < a[right])
{
return mid;
}
else if (a[left] > a[right])
{
return left;
}
else
{
return right;
}
}
else
{
if (a[mid] > a[right])
{
return mid;
}
else if (a[left] < a[right])
{
return left;
}
else
{
return right;
}
}
}
取中以后只需要在快排函式的最前面交換這個數和最左邊的數:
int index = GetMidIndex(a, left, right);
Swap(&a[left], &a[index]);
通過三數取中后,遞回后的key就不會在靠近中間的位置,減少了呼叫次數,提高了效率,
2.3.2.小區間優化
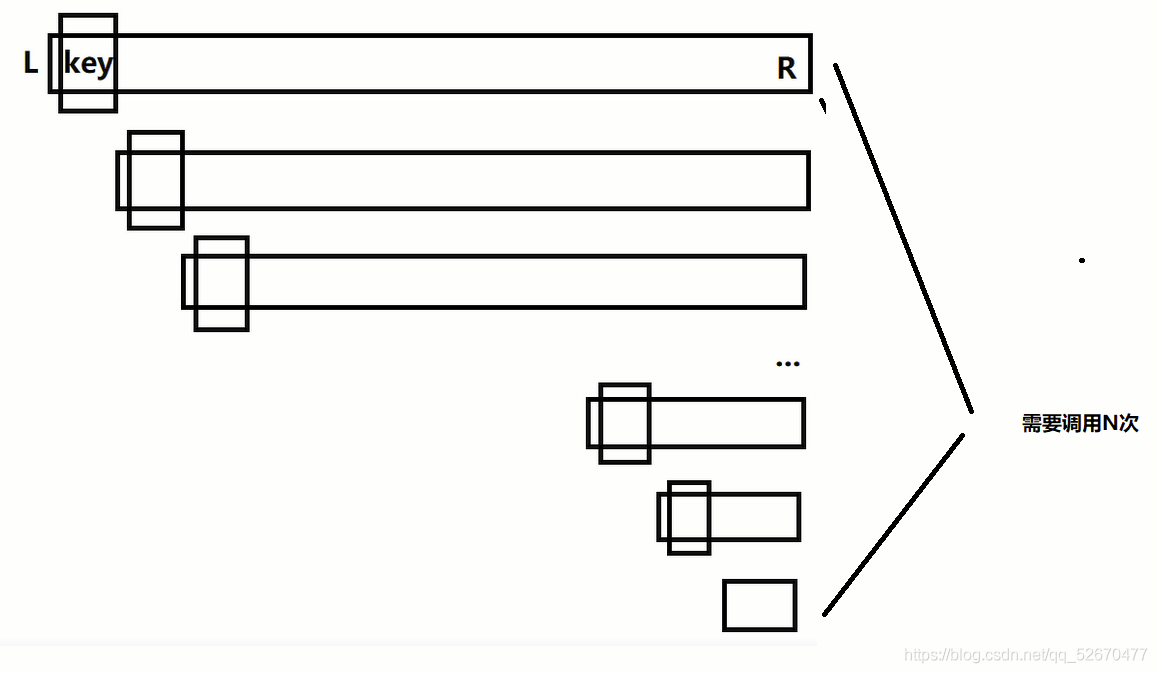
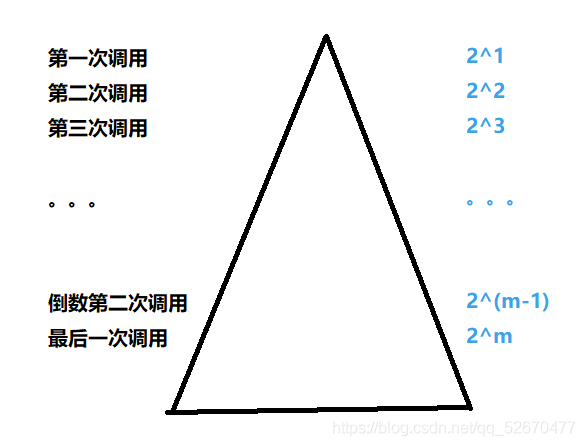
通過這張圖不難看出來,當劃分的左右子區間的元素個數很小的時候(一般為十幾個),需要呼叫的次數會非常多,這時候使用別的排序演算法比如直接插入排序比快速排序更加的高效,
//小區間優化的快速排序
void QuickSort(int* a, int left,int right)
{
if (left >= right)
{
return;
}
int keyIndex = PartSort1(a, left, right);
//排序完成以后,從坑位分成三部分
//[left,pivot-1] pivot [pivot+1,right]
if (keyIndex - 1 - left > 10)//如果區間范圍小于10,則不遞回
{
QuickSort(a, left, keyIndex - 1);
}
else
{
InsertSort(a + left, keyIndex - 1 - left + 1);//使用直接插入排序
//a + left是左區間的起始下標,keyIndex - 1 - left + 1是左區間元素個數
}
if (right - (keyIndex + 1)>10)//如果區間范圍小于10,則不遞回
{
QuickSort(a, keyIndex + 1, right);
}
else
{
InsertSort(a + keyIndex +1, right-(keyIndex +1)+1);//使用直接插入排序
//a + keyIndex +1是右區間的起始下標,right-(keyIndex +1)+1是右區間元素個數
}
}
2.4.時間空間復雜度分析
如果沒有優化:每次呼叫都會遍歷一次傳入的陣列,所以呼叫一次的時間復雜度是O(N),而最好的情況就是key每次都是中間的位置,這樣只需要呼叫log2N次,而最壞的情況需要呼叫N次,所以最好的時間復雜度是 O(Nlog2N),最壞的時間復雜度是O(N2),
優化后,key一般都會在靠近中間的位置,所以優化后的時間復雜度一般為O(Nlog2N)
每次遞回呼叫都會開辟空間,所以空間復雜度最好的情況是O(Nlog2N),最壞的是O(N2),
平均來看:
時間復雜度為O(NlogN)
空間復雜度為O(NlogN)
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/293223.html
標籤:其他