
目錄
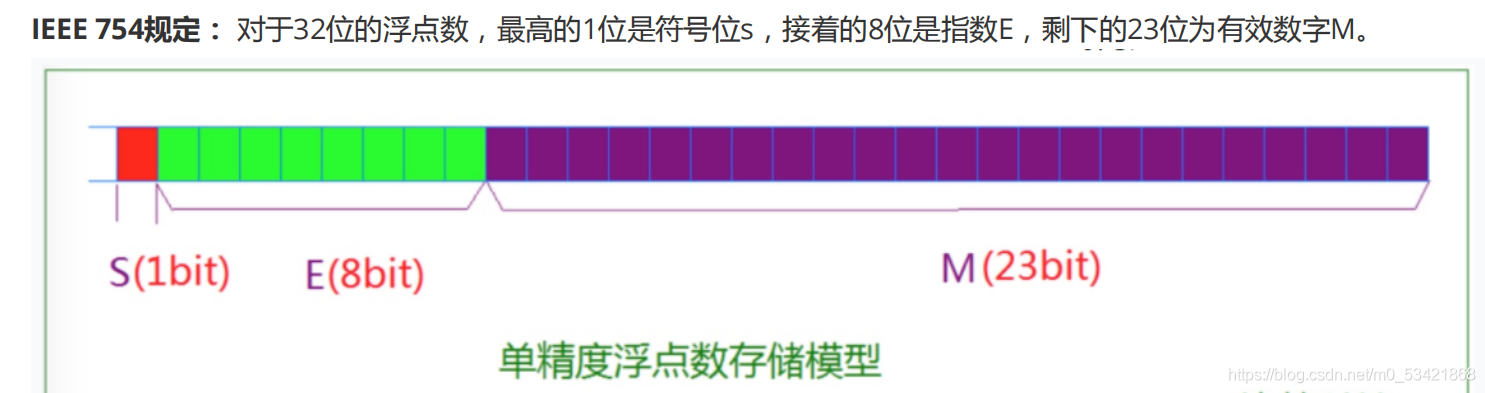
- 一、基本資料型別介紹
- 1.1型別的意義:
- 1、使用這個型別開辟記憶體空間的大小(大小決定了使用范圍)
- 2、如何看待記憶體空間的視角
- 1.2型別的基本歸類:
- 1.2.1關于char型別有符號和無符號型別的區別
- 1.3浮點數家族:
- 1.4構造型別:
- 陣列
- 1.5指標型別
- 1.6空型別:
- 二、整形在記憶體中的存盤
- 1.1流程圖
- 1.2概念總結
- 1.3實踐總結
- 1.4大小端
- 科普知識:為什么會有大端小端呢
- 1.5大小端總結:
- 1.6判斷機器是否是大小端
- 三、練習
- 浮點型在記憶體中的存盤
- 常見的浮點數:
- 浮點數的存
- 浮點數的取
- 回到之前的那個問題
一、基本資料型別介紹

1.1型別的意義:
1、使用這個型別開辟記憶體空間的大小(大小決定了使用范圍)
假設我們在記憶體中定義了兩個變數,A變數是int型別,B變數是char型別,我們都知道int型別是4位元組所以他在記憶體中占4個位元組的空間,float型別是4位元組,所以他在記憶體中占用4位元組的空間
2、如何看待記憶體空間的視角
型別就決定了定義變數時他們的大小變數A是四位元組,變數B也是四位元組,站在int型的角度他的存取都是整數,所以他是根據整數的形式存取的,而站在float型別的角度,他存放的是實數,所以他的存取方式是按實數的方式存取的,不同的資料型別就決定了他們在記憶體中存取方式是如何的,
1.2型別的基本歸類:

注意:在這里是把char型別劃分到整形家族里面去的,為什么char型別要劃分到整形家族呢?是因為char是用ASCII碼來表示的,而ASCII碼值又都是十進制的整形
在這里首先了解一下char型別
int main()
{
signed short int a = 0;//有符號短整型
unsigned short b = 0;//無符號短整型
char a;//有符號?還是無符號
return 0;
}
char a是有符號的還是無符號的問題,取決的是編譯器
1.2.1關于char型別有符號和無符號型別的區別
int main()
{
unsigned char c1 = 255;
signed char c2 = 255;
printf("%d\n",c1);//255
printf("%d\n",c2); //-1
return 0;
}

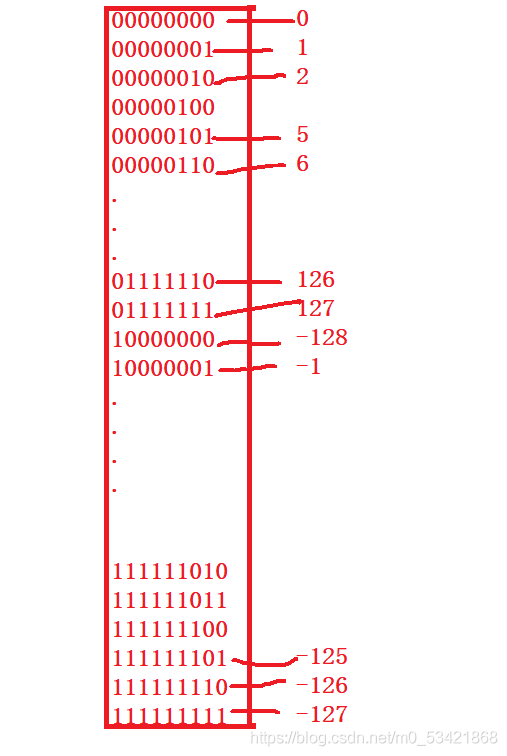
char型別是占1位元組的8個位元位,如果他是無符號型別呢,那么他的符號位也是有效位,而取值范圍可以到255,再對比一下有符號char型別(signed
char),首先255對應的二進制序列是11111111(8個1)

最終其實是得到的二進制序列是對應十進制的-1,而他的最高位代表的是符號位-1表示負數,0表示正數
再來羅列他的取值范圍

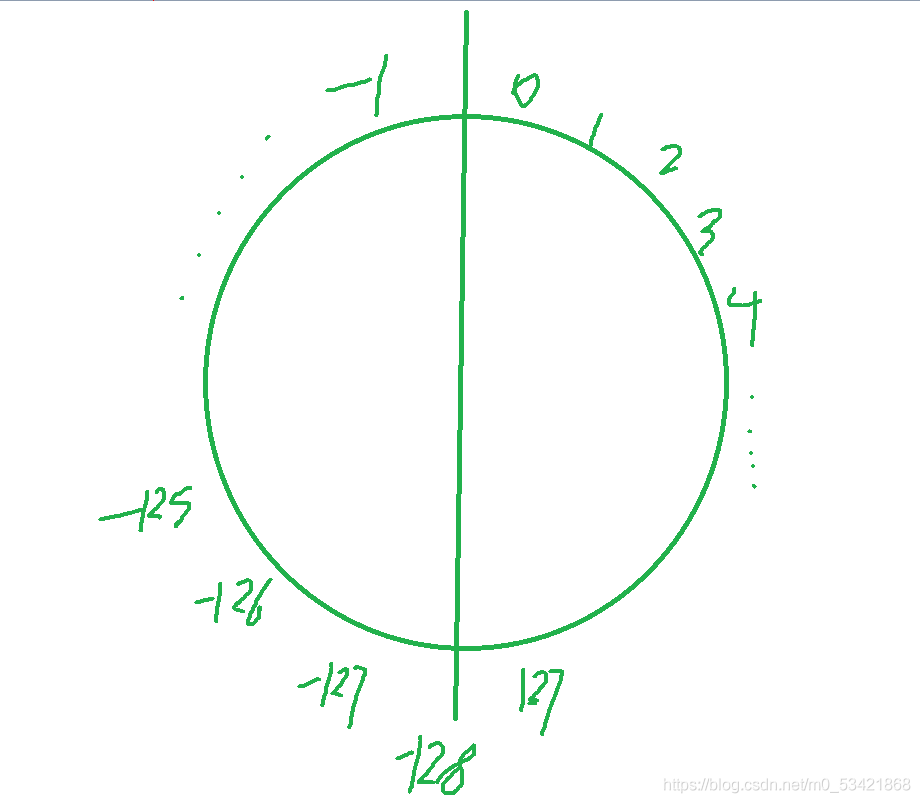
因為這里寫的是 signed char所以他的最高位為0的化表示的是一個正數,那么他的源、反、補都是一樣的而第一個二進制序串列示的是0,再看他的最后一個二進制序列,因為signed char的最高位是1表示的是負數,那么就需要對他的補碼-1取反得到原始碼,那么就會是-1,而-127又是通過下面的計算程序的到的原始碼對應的二進制序列因為是有符號的所以他的最高位表示的是符號位,而剩下的7位才是它的有效位,而中間的10000000表示的是-128
那如果是無符號的char那么它的二進制序列對應的每一位就都是有效位,所以它的最大范圍是0 ~ 255,既然我們知道了char型別的取值范圍怎么運算的規則,是不是就可以知道其他資料型別的取值范圍了?這里就不再繼續了

總結:
1、signed char的取值范圍是 0 ~ 127 | -128 ~ -1
2、unsigned char的取值范圍是0 ~ 255
short == signed short
long == signed long
int == signed int
而關于short - int - long這3中資料型別都是有符號的,這是C語言標準規定的,而如果想定義一個無符號整形就需要在前面加unsigned
1.3浮點數家族:

關于浮點型在后面的存盤方式再詳細介紹,這里簡單了解兩點
1、float型別稱為單精度,占4位元組空間 ,數值范圍為3.4E-38到3.4E+38, 有效數字6 ~ 7位
2、double型別稱為雙精度,占8位元組空間,數值范圍為1.7E-308到1.7E+308, 有效數字15 ~ 16位
1.4構造型別:
構造型別也成為自定義型別

陣列
陣列是有型別的,陣列的型別取決于陣列的元素型別和陣列的元素個數
int main()
{
int arr[10] = {0};
int a = 0;
printf("%d\n",sizeof(int));//4 求出int型別所占位元組
printf("%d\n",sizeof(a));//4 求出變數a所占位元組
printf("%d\n",sizeof(arr));//40 求出整個陣列所占位元組
printf("%d\n",sizeof(int [10]));//40 求出陣列型別所占位元組
//int arr1[5];
return 0;
}
那么 int arr1[5]; 是不是陣列型別呢?答案是的,因為陣列也是自定義型別,陣列元素個數和陣列元素型別決定了陣列是什么型別
1.5指標型別

1.6空型別:

void引數串列宣告
void func(void)//表示不需要傳遞引數
{
printf("hehe\n");
}
int main()
{
func(100);
return 0;
}
雖然程式不報錯,但是顯示了一條警告,這也是不太好的,如果指定不需要引數,那么就不傳引數,否則就不需要指定void

二、整形在記憶體中的存盤
我們之前講過一個變數的創建是要在記憶體中開辟空間的,空間的大小是根據不同的型別而決定的
那接下來我們談談資料在所開辟記憶體中到底是如何存盤的
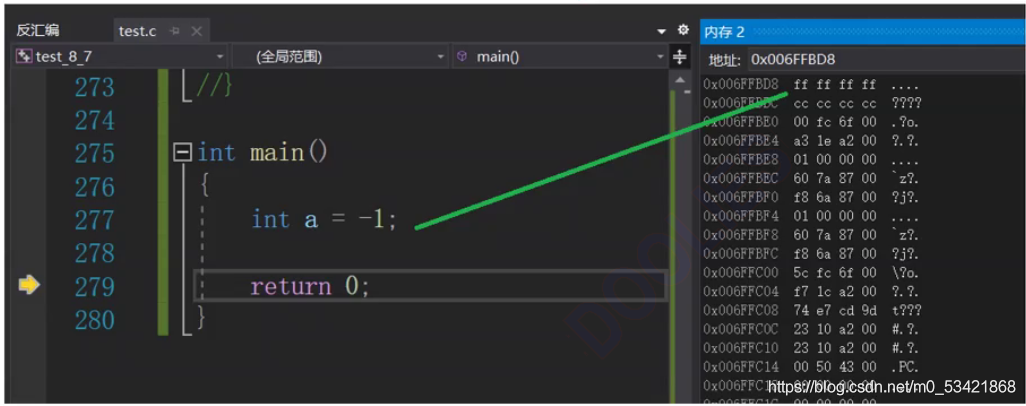
我們知道為 a 分配四個位元組的空間, 那如何存盤?
下來了解下面的概念:

1.1流程圖
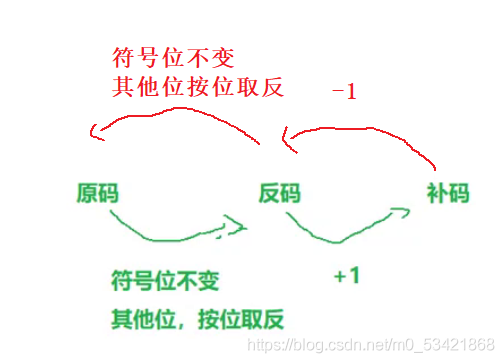
1.2概念總結
正數的原、反、補碼都相同,
對于整數來說:資料存放記憶體中其實存放的是補碼,
在計算機系統中,數值一律用補碼來表示和存盤,原因在于,使用補碼,可以將符號位和數值域統一處理; 同
時,加法和減法也可以統一處理(CPU只有加法器)此外,補碼與原碼相互轉換,其運算程序是相同的,不需 要額外的硬體電路,為什么需要使用補碼計算呢?假如使用原碼計算的話
很明顯這個結果不是想要的,那么是不是就說明了使用原碼不合適呢
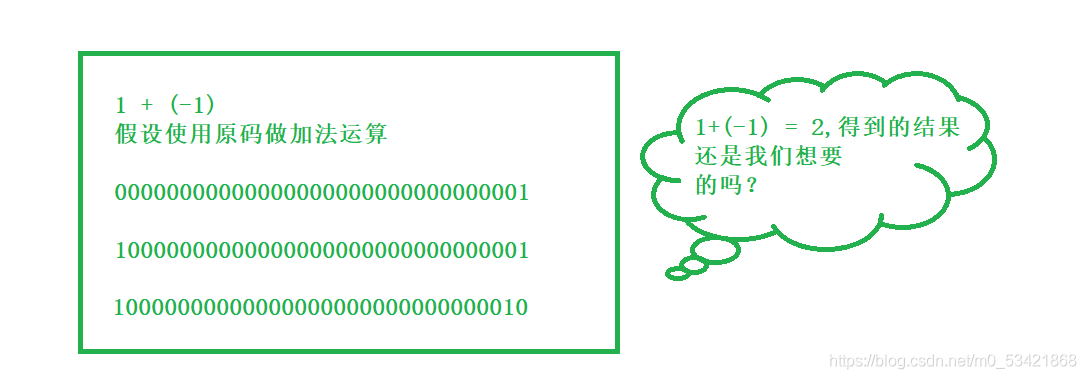
緊接著再使用補碼的方式去計算,這里注意正數的原、反、補都是一樣的,但是是不是就說明了正數是按照原碼的方式去存盤的呢?不是的,雖然正數的原、反、補一樣,但是在記憶體中的存盤方式卻不是一樣

但是一個整形只能存放32位,多出來的一位是不是就得截斷啊 實際上存的還是數值0,使用補碼的方式計算,在這里既處理了符號位又處理了有效數值位
1.3實踐總結
數值一律用補碼來表示和存盤,原因在于,使用補碼,可以將符號位和數值域統一處理
1.4大小端

科普知識:為什么會有大端小端呢
**
為什么會有大小端模式之分呢?這是因為在計算機系統中,我們是以位元組為單位的,每個地址單元都對應著一
個位元組,一個位元組為8bit,但是在C語言中除了8bit的char之外,還有16bit的short型,32bit的long型(要看具
體的編譯器),另外,對于位數大于8位的處理器,例如16位或者32位的處理器,由于暫存器寬度大于一個字
節,那么必然存在著一個如果將多個位元組安排的問題,因此就導致了大端存盤模式和小端存盤模式, 例如一個 16bit 的 short 型 x
,在記憶體中的地址為 0x0010 , x 的值為 0x1122 ,那么 0x11 為高位元組, 0x22 為低位元組,對于大端模式,就將
0x11 放在低地址中,即 0x0010 中, 0x22 放在高地址中,即 0x0011 中,小 端模式,剛好相反,我們常用的 X86
結構是小端模式,而 KEIL C51 則為大端模式,很多的ARM,DSP都為小
端模式,有些ARM處理器還可以由硬體來選擇是大端模式還是小端模式,
**
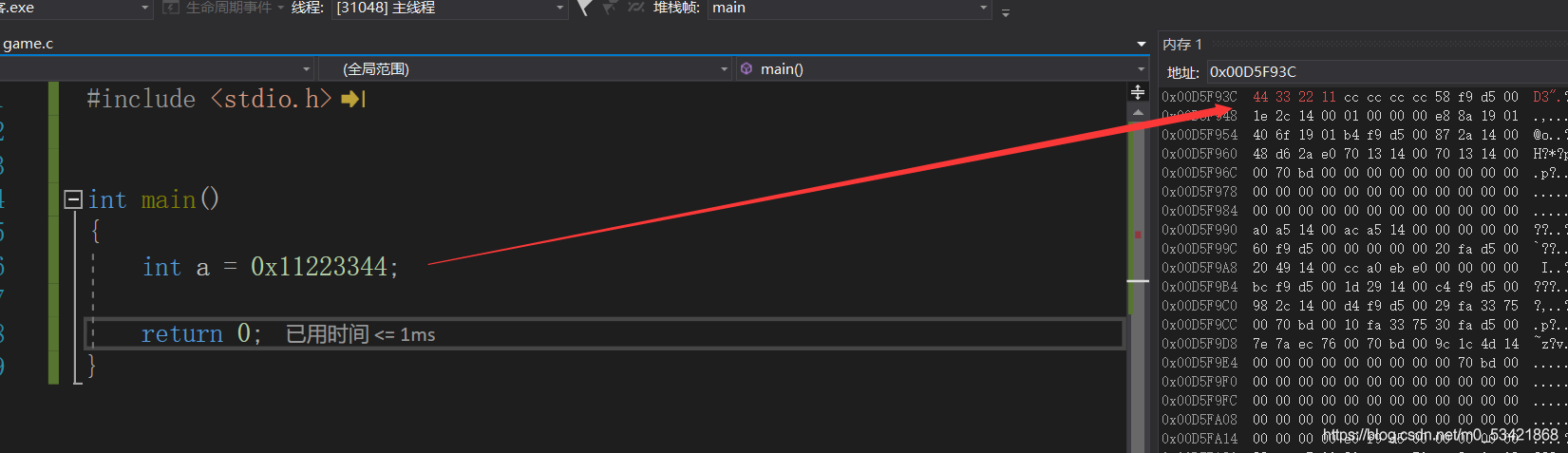
其實資料在記憶體中是以低地址存放在低地址處,高地址存放在高地址處
為什么要這么說呢?首先我們可以看出的是這兩個箭頭指向的是不同的兩個地址,而這兩個地址中間恰好是差四個位元組 44 33 22 11這塊記憶體空間被0x00D5F93C標識著,那么往后推演,是不是就能用0x00D5F93C表示44這個位元組的記憶體,0x00D5F93D表示33這個位元組的記憶體,0x00D5F93E表示22這個位元組的記憶體,0x00D5F940表示11這個位元組的記憶體,在這個推演的程序就能看到地址是逐漸遞增的,并且低地址處的空間被低地址處指向,而高地址處空間被高地址處指向
以上就是小端存盤

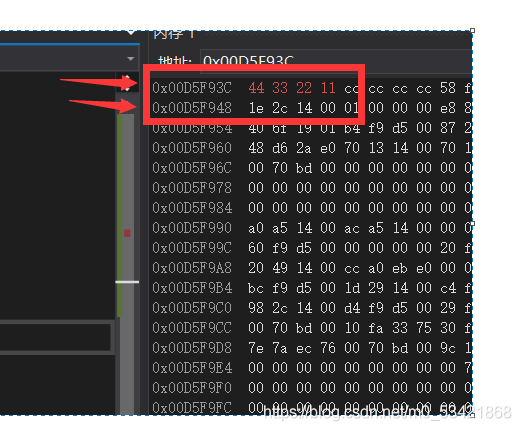
而大端存盤呢恰好與小端存盤相反
高地址處存放低地址,低地址處存放高地址
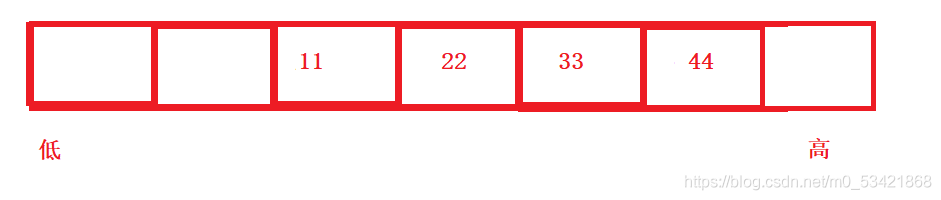
1.5大小端總結:
1、大端位元組序存盤(大端存盤)模式,是指資料的低位保存在記憶體的高地址中,而資料的高位,保存在記憶體的低地址中;
2、小端位元組序存盤(小端存盤)模式,是指資料的低位保存在記憶體的低地址中,而資料的高位,,保存在記憶體的高地址中,
補充:
位元組序:在記憶體中以位元組存盤的順序
1.6判斷機器是否是大小端


解題思路:想要判斷機器是大端還是小端,就得先知道它的第一個位元組存放的內容是什么,如果存放的是高地址處的內容,那么他就是大端,但是如果存放的是低地址處的內容那么就是小端
此刻編譯器采用的是小端存盤,而若想把這第一個位元組給挑出來,就需要使用指標變數訪問記憶體,在這里變數a是占4個位元組的空間的,變數a是以4個位元組角度看待這塊記憶體的,若想只挑出第一個位元組的內容,最合適的就是char了,操作記憶體當然得使用指標了,那么char*就最合適不過了
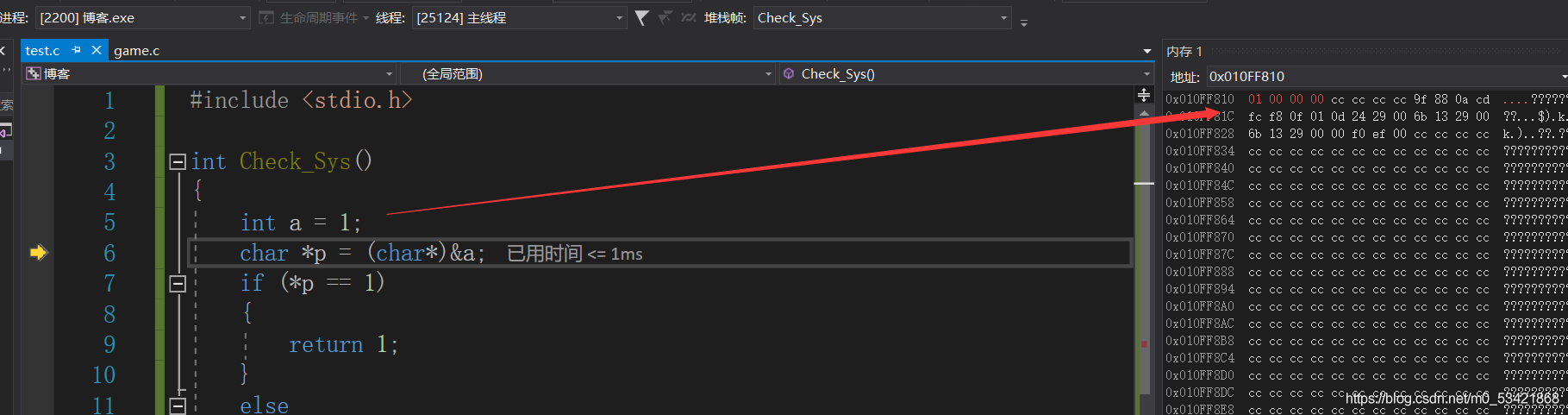
方案一:
#include <stdio.h>
int Check_Sys()
{
int a = 1;
char *p = (char*)&a;//指標指向記憶體中的第一個位元組處地址
if (*p == 1)
{
return 1;
}
else
{
return 0;
}
}
int main()
{
int ret = Check_Sys();
if (ret)
{
printf("小端\n");
}
else
{
printf("大端\n");
}
return 0;
}
方案二:
#include <stdio.h>
int Check_Sys()
{
int a = 1;
char *p = (char*)&a;
return *p;//回傳指標所指向的內容
}
int main()
{
int ret = Check_Sys();
if (ret)
{
printf("小端\n");
}
else
{
printf("大端\n");
}
return 0;
}
方案三:
#include <stdio.h>
int Check_Sys()
{
int a = 1;
return *((char*)&a);//對指標解參考,回傳指標所指向的內容
}
int main()
{
int ret = Check_Sys();
if (ret)
{
printf("小端\n");
}
else
{
printf("大端\n");
}
return 0;
}
三、練習
//輸出什么?
#include <stdio.h>
int main()
{
char a= -1;
signed char b=-1;
unsigned char c=-1;
printf("a=%d,b=%d,c=%d",a,b,c);
return 0;
}
答案是-1,-1,255
解題思路:首先我們得知道-1在記憶體中存放的是補碼,那么需要對-1的原碼取反+1得到補碼,再將-1存放到a這個變數里,而變數a是一個字符型別,char型別占8個位元位所以會只保留低位的二進制序列,這個時候就會發生截斷會只保留二進制序列低位的8個位元位
而在列印的時候會整形提升,如果是有符號的char型別,在高位就會補符號位這里的符號位是1,再對32個全1通過計算得出它的原碼,而原碼就是變數a的值
有了這個例子那么signed char也是有符號的資料型別,就不再解釋
再來看看unsigned char,為什么變數c = -1最終列印出來的值會是255呢?
同樣的道理先求出-1的補碼,因為是無符號型別,所以它的最高位代表的并不是正負,它的32個1全都是有效數字,但是由于而變數c是一個字符型別,char型別占8個位元位所以會只保留低位的二進制序列,這個時候就會發生截斷會只保留二進制序列低位的8個位元位
在列印的時候會發生整形提升,因為是無符號型別所以在整形提升的時候高位補0,而最終列印的結果就是255




#include <stdio.h>
int main()
{
char a = -128;
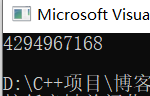
printf("%u\n",a);
return 0; }
同樣的道理還是先求出變數a 的補碼,經過一系列計算后-128的補碼
在高位被截斷的時候,變數a中存放的還是低位的8個位元位10000000
而在整形提升的時候,由于char是有符號型別,所以會在高位補符號位,得到后的補碼就是11111111111111111111111110000000,當以無符號整型列印的時候就是通過它的補碼方式表現的

#include <stdio.h>
int main()
{
char a = 128;
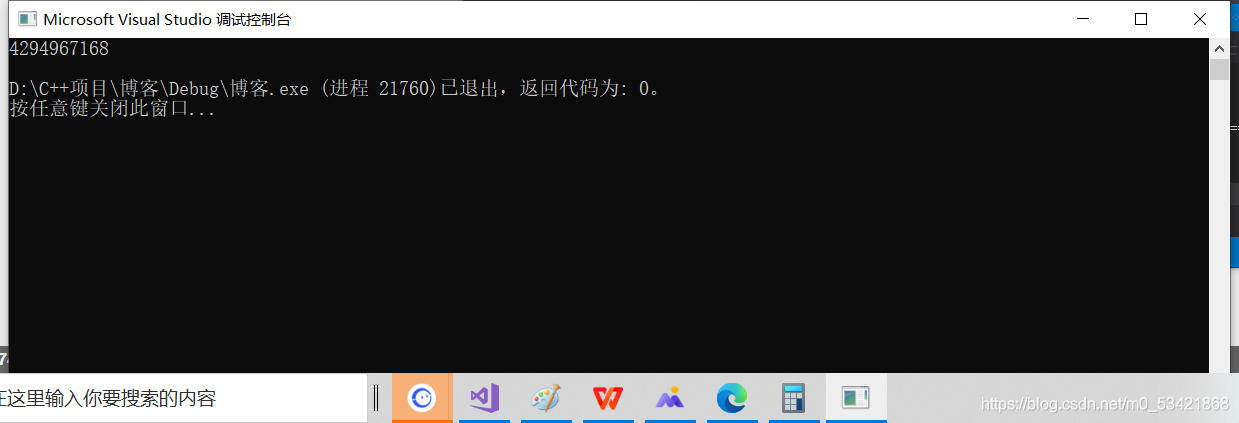
printf("%u\n",a);
return 0; }
在這里我們可以觀察到-128的和正128的低8位都是相同的,10000000,所以在被截斷后存放在變數a中的補碼也是一樣的,再通過整形提升,由于是char型別的所以會在高位補符號位 1,再將結果列印
我們可以看到沒啥區別

int i= -20;
unsigned int j = 10;
printf("%d\n", i+j);
//按照補碼的形式進行運算,最后格式化成為有符號整數
再看看這個代碼
答案是-10,以下就是計算程序

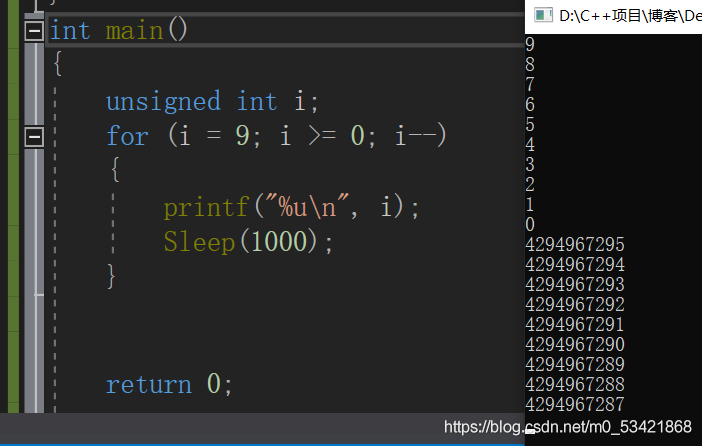
unsigned int i;
for(i = 9; i >= 0; i--) {
printf("%u\n",i);
}
這個結果會是什么呢
死回圈吧!
我們可以看到先是列印了9 ~0然后進入了死回圈,會什么呢,在變數i–后i變數的值等于0時,再減減不就等于-1了嗎而-1在記憶體中的補碼是32個全1,所以范圍很大,但是你覺到如果列印到0的時候是不是條件還滿足,i–,i的值又成了-1,于是又進入了下一個死回圈
int main()
{
char a[1000];
int i;
for(i=0; i<1000; i++)
{
a[i] = -1-i;
}
printf("%d",strlen(a));
return 0;
}
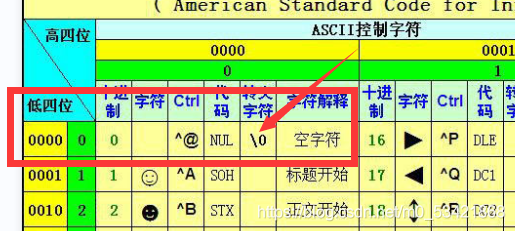
答案是255從-1開始的話它的第255位就是 00000000這個二進制序列,而這個值表示的是’\0‘,所在在strlen遇到它的時候就會結束計數,第0位表示的就是斜杠零
#include <stdio.h>
unsigned char i = 0;
int main()
{
for(i = 0;i<=255;i++)
{
printf("hello world\n");
}
return 0;
}
這個代碼的結果又是什么呢?
還是死回圈吧!變數i從0開始一直遞增直到記憶體中的補碼變成了11111111,再++的話是不是就會溢位了,最終只保留它的低8位,結果還是0,這時候條件還是滿足,有一次回圈,那么不就進入了死回圈嗎

浮點型在記憶體中的存盤
常見的浮點數:
3.14159
1E10
浮點數家族包括: float、double、long double 型別, 浮點數表示的范圍:float.h中定義 浮點數存盤的例子:
int main()
{
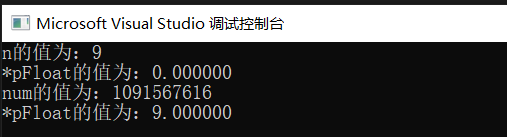
int n = 9;
float *pFloat = (float *)&n;
printf("n的值為:%d\n",n);
printf("*pFloat的值為:%f\n",*pFloat);
*pFloat = 9.0;
printf("num的值為:%d\n",n);
printf("*pFloat的值為:%f\n",*pFloat);
return 0; }
你能知道這個代碼列印的結果是什么嗎
先了解知識理論再回頭來看
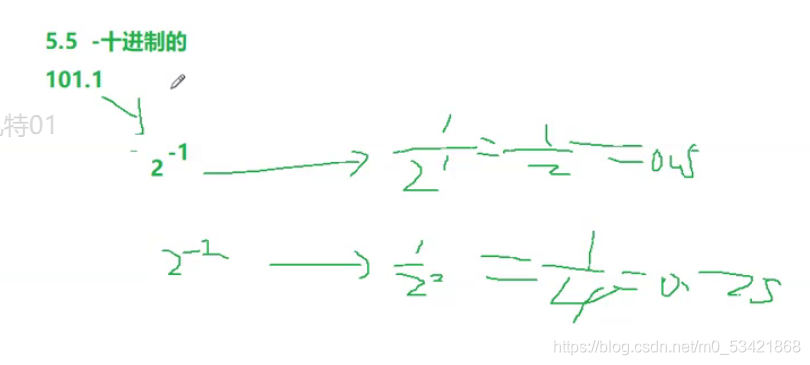
小數點的后一位表示的是2的負1次方,后兩位表示2的負2次方,101.1寫成科學計數法就是1.011 * 2^2,當我們換算到這個公式里頭來就是
(-1)^0 * 1.011 * 2^2 這里的
S = 0
M = 1.011
E = 2
------------如果是9.0呢
(-1)^0 * 1.001 * 2^3
S = 0
M = 1.011
E = 3



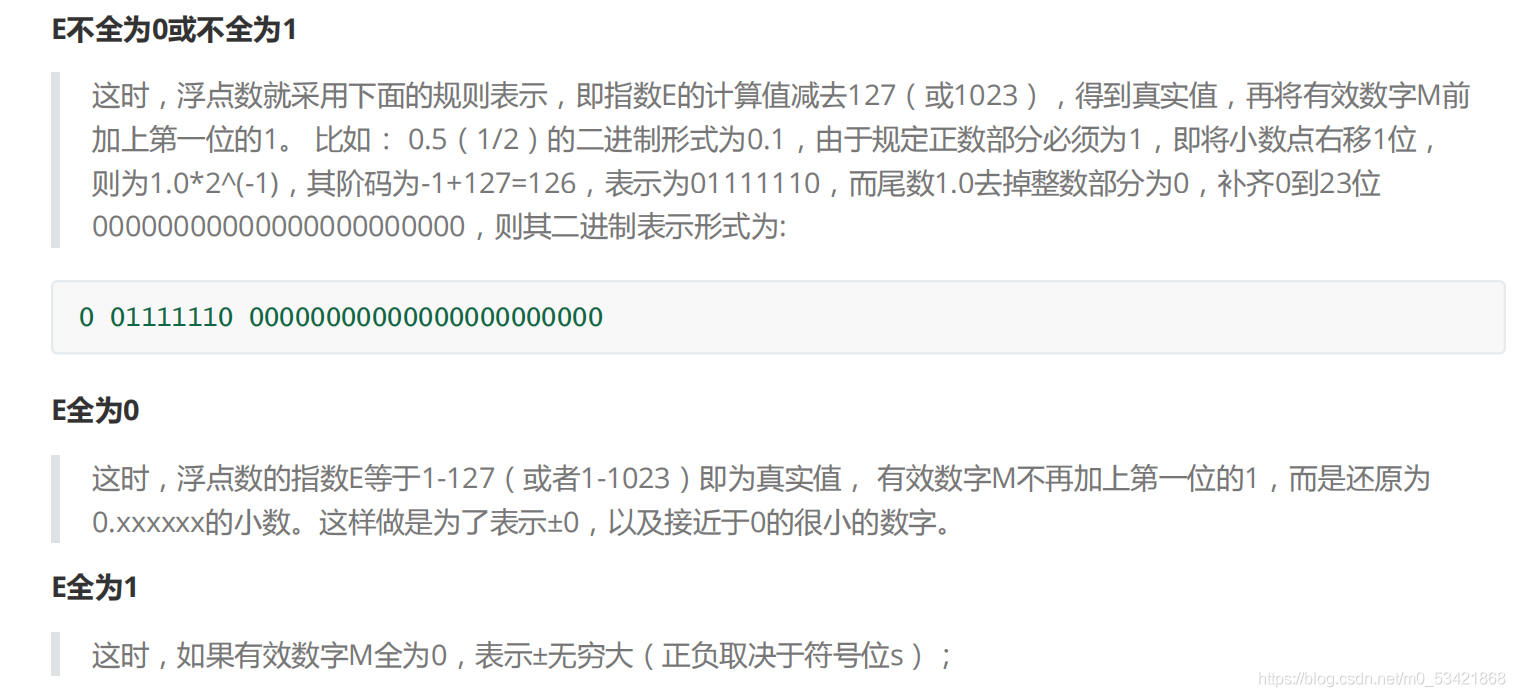
總結:
1、如果是float型別,這個中間數是127,比如,2^10的E 是10,所以保存成32位浮點數時,必須保存成10+127=137,即10001001,
2、如果是double型別,這個中間數是1023,比如,2^10的E 是10,所以保存成32位浮點數時,必須保存成10+1023=1033,即010000001001,
浮點數的存
下一個話題浮點數以二進制的形式在記憶體中存盤,
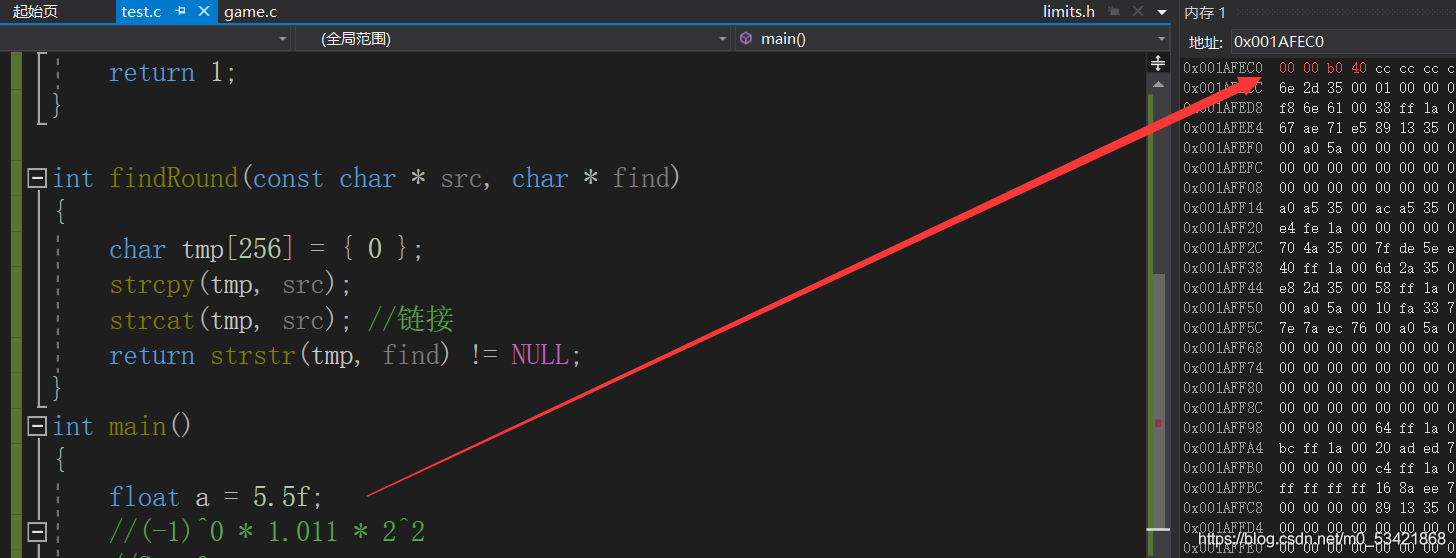
int main()
{
float a = 5.5f;
//(-1)^0 * 1.011 * 2^2
//S = 0
//M = 1.011
//E = 2
//因為是浮點型中間數是127,而E又是2
//E = 2 + 127 = 129
//對應的二進制序列:01000000 10110000 00000000 00000000
//對應的十六進制序列:40 B0 00 00
return 0;
}
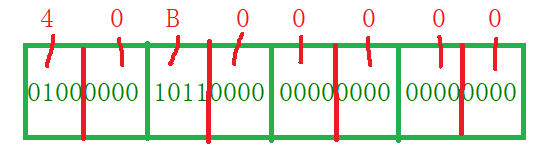
對應的二進制序列記憶體塊
把這32位二進制序列轉換成16進制就是 40 B0 00 00
由于使用的是VS2017編譯器采用的是小端存盤,所以低地址處存放的是二進制序列低位的資料,而高地址處的是二進制序列高位的資料

浮點數的取
然后,指數E從記憶體中取出還可以再分成三種情況:
回到之前的那個問題
int main()
{
int n = 9;
float *pFloat = (float *)&n;
printf("n的值為:%d\n",n);
printf("*pFloat的值為:%f\n",*pFloat);
*pFloat = 9.0;
printf("num的值為:%d\n",n);
printf("*pFloat的值為:%f\n",*pFloat);
return 0; }
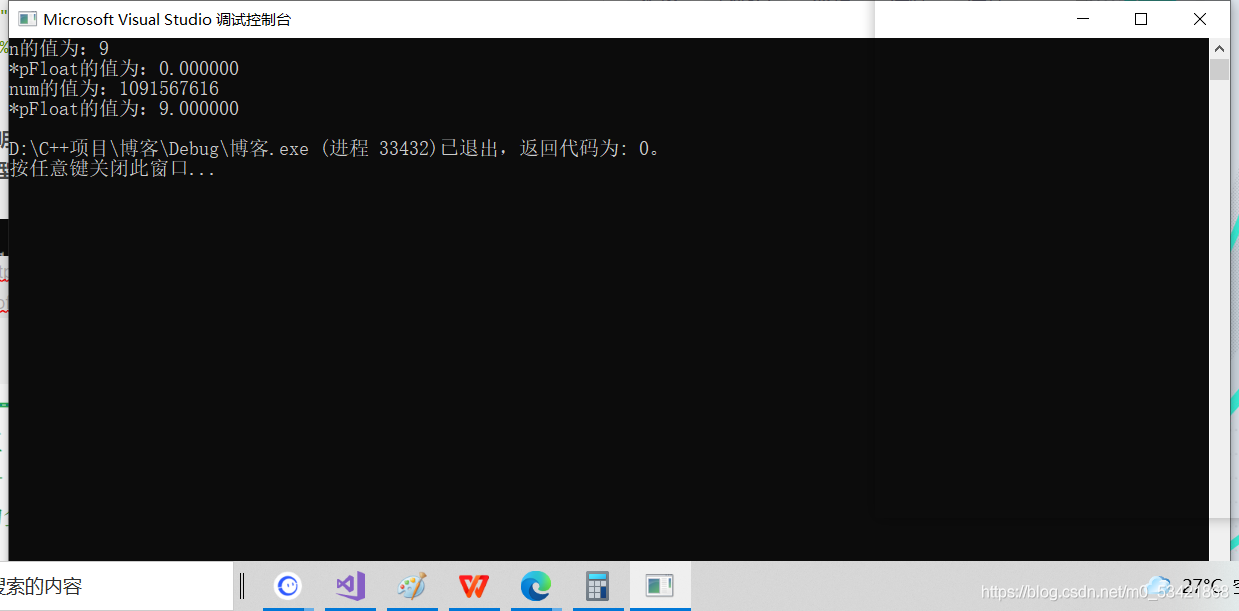
當我們把以上的知識弄明白之后,對于這個問題只要把它的二進制序列求出來,再截取它的6有效位數(因為浮點型的有效位數是6位有效數字) 所以會截取0.000000


決議這兩句代碼的意義
*pFloat = 9.0;
printf(“num的值為:%d\n”,n);
所以它的二進制序列是== 01000001000100000000000000000000==當以%d的形式列印,而他的最高為0所以是正數,而正數的原、反、補相同所以列印的結果是
以上講解就到這里,謝謝大家



轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/293392.html
標籤:其他
上一篇:IDEA最常用的快捷鍵和下載之后必要的設定【附動圖教程】
下一篇:從零開始C++系列 c++ 入門