COX生存分析-從基本概念到引數求解
- cox生存分析
- cox的基本概念
- 刪失資料
- COX基本概念
- 用kaplan-Meier method法估計生存函式
- 結論
- 舉例
- 證明
- 指數分布
- 模型擬合檢驗
- cox風險比例模型(Cox Proportional Hazards Model)
- 基本定義
- 引數求解
- 舉例
cox生存分析
第一次寫分享,希望自己的作業對正在學習COX的你所有幫助,很多地方可能理解不到位,大家可以幫忙指正~互相學習
cox的基本概念
刪失資料
在全面了解COX模型之前,我們要先知道,什么叫做刪失資料(censored data)
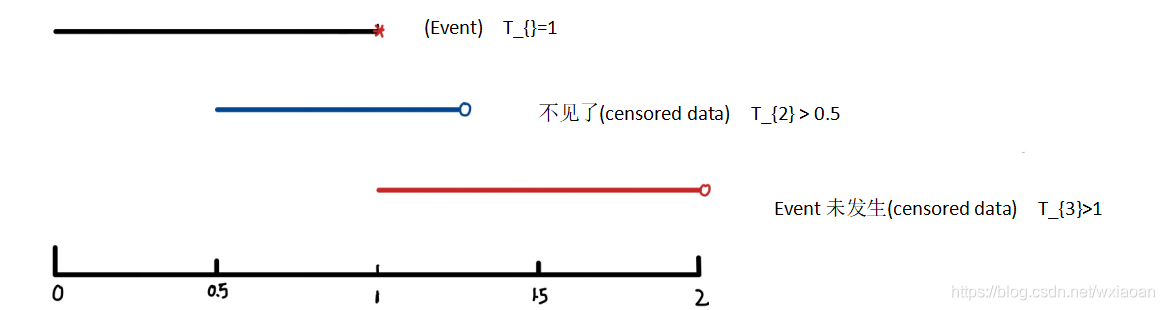
1)event是什么?
在醫學中,我們經常會將死亡看做一個event發生,因此很多資料都會以死亡作為例子,但是很多同學可能不是應用在醫學領域,因此我們這里使用事件發生作為感興趣的,客戶違約可以看做一個"event"、發生某種疾病也是一個"event"…
2)刪失資料是什么?
刪失資料(censored data)和缺失資料(missing data) 有本質的區別,在上圖里,我們整個觀測期為2,
1.看第一個個體,該個體在時刻1的時候發生event,這時候我們就認為第一個個體在1時刻event發生,記作
T
1
=
1
T_{1}=1
T1?=1,
2.看第二個個體,在1.5這個時刻,該個體不見了,這種情況我們就認為發生了刪失,記作
T
2
>
1.5
T_{2}>1.5
T2?>1.5,
3.看第三個個體,該個體在整個觀測期都沒有發生event,這種情況我們就認為發生了刪失,記作
T
3
>
2
T_{3}>2
T3?>2,
COX基本概念
T:受試者的生存時間
S(T): 生存函式
S
(
T
)
=
P
(
T
>
t
)
=
∫
t
∞
f
(
x
)
d
x
=
1
?
F
(
t
)
S(T)=P(T>t)=\int_{t}^{\infty} f(x) d x=1-F(t)
S(T)=P(T>t)=∫t∞?f(x)dx=1?F(t)
h(t): 風險函式,即這個人在t時刻瞬時死亡率
h
(
t
)
=
lim
?
d
t
→
0
P
(
T
<
t
+
d
t
∣
T
>
t
)
d
t
=
lim
?
d
t
→
0
P
(
t
<
T
<
t
+
d
t
)
P
(
T
>
t
)
d
t
=
lim
?
d
t
→
0
P
(
t
<
T
<
t
+
d
t
)
S
(
t
)
d
t
=
積分中值定理
f
(
t
)
S
(
t
)
h(t)=\lim _{d t \rightarrow 0} \frac{P(T<t+d t \mid T>t)}{d t}=\lim _{d t \rightarrow 0} \frac{P(t<T<t+d t)}{P(T>t) d t}=\lim _{d t \rightarrow 0} \frac{P(t<T<t+d t)}{S(t) d t} \stackrel{\text { 積分中值定理 }}{=} \frac{f(t)}{S(t)}
h(t)=limdt→0?dtP(T<t+dt∣T>t)?=limdt→0?P(T>t)dtP(t<T<t+dt)?=limdt→0?S(t)dtP(t<T<t+dt)?= 積分中值定理 S(t)f(t)?
H(t):
H
(
t
)
=
∫
0
t
h
(
x
)
d
x
H(t)=\int_{0}^{t} h(x) d x
H(t)=∫0t?h(x)dx
我們的目的是得到出S(T)、h(t)、H(t),實際上求出三個中的一個,其他的也相應可以得到:
h
(
t
)
=
f
(
t
)
S
(
t
)
=
?
S
′
(
t
)
S
(
t
)
?
H
(
t
)
=
?
ln
?
S
(
t
)
?
S
(
t
)
=
e
?
H
(
t
)
=
e
?
∫
0
t
h
(
x
)
d
x
\mathrm{h}(\mathrm{t})=\frac{\mathrm{f}(t)}{S(t)}=\frac{-S^{\prime}(t)}{S(\mathrm{t})} \Rightarrow H(t)=-\ln S(t) \Rightarrow S(t)=e^{-H(t)}=e^{-\int_{0}^{t} h(x) d x}
h(t)=S(t)f(t)?=S(t)?S′(t)??H(t)=?lnS(t)?S(t)=e?H(t)=e?∫0t?h(x)dx
用kaplan-Meier method法估計生存函式
結論
假設現在的資料集有k個不同的生存時間,
t
1
<
t
2
…
<
t
k
\mathrm{t}_{1}<\mathrm{t}_{2} \ldots<\mathrm{t}_{k}
t1?<t2?…<tk? ,
n
i
:
\mathrm{n}_{i}:
ni?: 在
t
i
t_{i}
ti? 時刻,
n
i
\mathrm{n}_{i}
ni? 個受試者處于風險之中(event未發生, 且不是刪失資料)
d
i
:
t
i
\mathrm{d}_{i}: t_{i}
di?:ti? 時刻發生event的人
那么有S(t)的估計值:
S
(
t
^
)
=
∏
i
:
t
i
≤
t
(
1
?
d
i
n
i
)
\hat{S(t})=\prod_{i: t_{i} \leq t}\left(1-\frac{\mathrm{d}_{i}}{n_{i}}\right)
S(t^?)=i:ti?≤t∏?(1?ni?di??)
舉例
舉個例子:
一家生物技術公司進行了一項為期 2 年的臨床試驗,測驗了新型心臟瓣膜的功效, 記錄了 10 名植入心臟瓣膜的患者的存活時間(以月為單位), 觀察旁邊的加號“+表示觀察被刪失, 資料是
24
+
,
16
+
,
8
,
19
,
10
,
8
+
,
5
,
17
,
20
,
10
24+, \quad 16+, \quad 8, \quad 19, \quad 10,8+, 5, \quad 17, \quad 20, \quad 10
24+,16+,8,19,10,8+,5,17,20,10
因此,有八個不同的生存時間,按升序給出:
5
,
8
,
10
,
16
,
17
,
19
,
20
,
24
\begin{array}{llllllll} 5, & 8, & 10, & 16, & 17, & 19, & 20, & 24 \end{array}
5,?8,?10,?16,?17,?19,?20,?24?
那么其生存函式可以通過如下的估計給出:
時刻
處于風險之中
死亡
刪失資料
生存率
估計量
t
i
n
i
d
i
at Time
t
i
(
1
?
d
i
n
i
)
S
^
(
t
)
,
t
i
<
t
<
t
i
+
1
0
10
0
0
1
?
0
=
1.00
1.00
5
10
1
0
1
?
1
10
=
0.90
(
1.00
)
(
0.90
)
=
0.90
8
9
1
1
1
?
1
9
=
0.89
(
0.90
)
(
0.89
)
=
0.80
10
7
2
0
1
?
2
7
=
0.71
(
0.80
)
(
0.71
)
=
0.57
16
5
0
1
1
?
0
=
1.00
(
0.57
)
(
1.00
)
=
0.57
17
4
1
0
1
?
1
4
=
0.75
(
0.57
)
(
0.75
)
=
0.43
19
3
1
0
1
?
1
3
=
0.67
(
0.43
)
(
0.67
)
=
0.29
20
2
1
0
1
?
1
2
=
0.50
(
0.29
)
(
0.50
)
=
0.15
24
1
0
1
1
?
0
=
1.00
(
0.15
)
(
1.00
)
=
0.15
\begin{array}{rrrcrc} \hline \text { 時刻 } & \text {處于風險之中 } & \text {死亡} & \text { 刪失資料 } & \text { 生存率 } & \text { 估計量 } \\ t_{i} & n_{i} & d_{i} & \text { at Time } t_{i} & \left(1-\frac{d_{i}}{n_{i}}\right) & \hat{S}(t), t_{i}<t<t_{i+1} \\ \hline 0 & 10 & 0 & 0 & 1-0=1.00 & 1.00 \\ 5 & 10 & 1 & 0 & 1-\frac{1}{10}=0.90 & (1.00)(0.90)=0.90 \\ 8 & 9 & 1 & 1 & 1-\frac{1}{9}=0.89 & (0.90)(0.89)=0.80 \\ 10 & 7 & 2 & 0 & 1-\frac{2}{7}=0.71 & (0.80)(0.71)=0.57 \\ 16 & 5 & 0 & 1 & 1-0=1.00 & (0.57)(1.00)=0.57 \\ 17 & 4 & 1 & 0 & 1-\frac{1}{4}=0.75 & (0.57)(0.75)=0.43 \\ 19 & 3 & 1 & 0 & 1-\frac{1}{3}=0.67 & (0.43)(0.67)=0.29 \\ 20 & 2 & 1 & 0 & 1-\frac{1}{2}=0.50 & (0.29)(0.50)=0.15 \\ 24 & 1 & 0 & 1 & 1-0=1.00 & (0.15)(1.00)=0.15 \\ \hline \end{array}
時刻 ti?058101617192024?處于風險之中 ni?10109754321?死亡di?011201110? 刪失資料 at Time ti?001010001? 生存率 (1?ni?di??)1?0=1.001?101?=0.901?91?=0.891?72?=0.711?0=1.001?41?=0.751?31?=0.671?21?=0.501?0=1.00? 估計量 S^(t),ti?<t<ti+1?1.00(1.00)(0.90)=0.90(0.90)(0.89)=0.80(0.80)(0.71)=0.57(0.57)(1.00)=0.57(0.57)(0.75)=0.43(0.43)(0.67)=0.29(0.29)(0.50)=0.15(0.15)(1.00)=0.15??
跟著這個例子算一遍,你就知道
S
(
t
^
)
=
∏
i
:
t
i
≤
t
(
1
?
d
i
n
i
)
\hat{S(t})=\prod_{i: t_{i} \leq t}\left(1-\frac{\mathrm{d}_{i}}{n_{i}}\right)
S(t^?)=∏i:ti?≤t?(1?ni?di??) 是怎么算的,
證明
下面對
S
(
t
^
)
=
∏
i
:
t
i
≤
t
(
1
?
d
i
n
i
)
\hat{S(t})=\prod_{i: t_{i} \leq t}\left(1-\frac{\mathrm{d}_{i}}{n_{i}}\right)
S(t^?)=∏i:ti?≤t?(1?ni?di??) 進行證明:
S
(
t
i
)
=
P
(
T
>
t
i
)
=
P
(
T
>
t
i
∣
T
>
t
i
?
1
)
P
(
T
>
t
i
?
1
)
=
P
(
T
>
t
i
∣
T
>
t
i
?
1
)
S
(
t
i
?
1
)
,
S\left(t_{i}\right)=P\left(T>t_{i}\right)=P\left(T>t_{i} \mid T>t_{i-1}\right) P\left(T>t_{i-1}\right)=P\left(T>t_{i} \mid T>t_{i-1}\right) S\left(t_{i-1}\right), \quad
S(ti?)=P(T>ti?)=P(T>ti?∣T>ti?1?)P(T>ti?1?)=P(T>ti?∣T>ti?1?)S(ti?1?), 令
P
(
T
>
t
i
∣
T
>
t
i
?
1
)
=
π
i
P\left(T>t_{i} \mid T>t_{i-1}\right)=\pi_{\mathrm{i}}
P(T>ti?∣T>ti?1?)=πi?
?
S
(
t
i
)
=
∏
j
=
1
i
π
j
\Rightarrow S\left(t_{i}\right)=\prod_{j=1}^{i} \pi_{j}
?S(ti?)=∏j=1i?πj?
假設時間
t
i
t_{\mathrm{i}}
ti? 時,有
d
i
d_{\mathrm{i}}
di? 個受試者以
1
?
π
i
1-\pi_{\mathrm{i}}
1?πi? 的概率死亡,
n
i
?
d
i
n_{i}-d_{i}
ni??di? 個人以
π
i
\pi_{\mathrm{i}}
πi? 的概率生存
L
(
π
1
,
…
,
π
k
)
=
∏
i
=
1
k
(
1
?
π
i
)
d
i
π
i
n
i
?
d
i
ln
?
L
(
π
1
,
…
,
π
k
)
=
∑
i
=
1
k
d
i
ln
?
(
1
?
π
i
)
+
(
n
i
?
d
i
)
ln
?
π
i
?
ln
?
L
?
π
i
=
0
?
π
^
i
=
1
?
d
i
n
i
所以,
S
(
t
^
i
)
=
∏
j
=
1
i
π
^
j
=
∏
j
=
1
i
(
1
?
d
i
n
i
)
\begin{gathered} L\left(\pi_{1}, \ldots, \pi_{\mathrm{k}}\right)=\prod_{i=1}^{k}\left(1-\pi_{\mathrm{i}}\right)^{d_{\mathrm{i}}} \pi_{\mathrm{i}}^{n_{i}-d_{i}} \\ \ln L\left(\pi_{1}, \ldots, \pi_{\mathrm{k}}\right)=\sum_{i=1}^{k} d_{i} \ln \left(1-\pi_{\mathrm{i}}\right)+\left(n_{i}-d_{i}\right) \ln \pi_{\mathrm{i}} \\ \frac{\partial \ln L}{\partial \pi_{\mathrm{i}}}=0 \Rightarrow \hat{\pi}_{\mathrm{i}}=1-\frac{d_{i}}{n_{i}} \\ \text { 所以, } \left.S \hat{(t}_{i}\right)=\prod_{j=1}^{i} \hat{\pi}_{\mathrm{j}}=\prod_{j=1}^{i}\left(1-\frac{d_{i}}{n_{i}}\right) \end{gathered}
L(π1?,…,πk?)=i=1∏k?(1?πi?)di?πini??di??lnL(π1?,…,πk?)=i=1∑k?di?ln(1?πi?)+(ni??di?)lnπi??πi??lnL?=0?π^i?=1?ni?di?? 所以, S(t^?i?)=j=1∏i?π^j?=j=1∏i?(1?ni?di??)?
指數分布
可以看到K-M法是一個非參的方法,當我們假設生存函式是指數分布或者weibull分布時,就是一個引數模型,我們以指數分布為例:
假設現有
n
n
n 對資料
(
t
i
,
δ
i
)
\left(t_{i}, \delta_{i}\right)
(ti?,δi?); 其中
t
i
t_{i}
ti? 為生存時間;
δ
i
\delta_{i}
δi? 為是否發生刪失:
δ
i
=
1
\delta_{i}=1
δi?=1 代表沒有發生刪失,
δ
i
=
0
\delta_{i}=0
δi?=0 代表發生刪失
T
i
T_{\mathrm{i}}
Ti? : 第
i
i
i 個人的生存時間(我們對這個興趣, 我們的關鍵是求
T
i
T_{\mathrm{i}}
Ti? 的分布)
C
i
C_{\mathrm{i}}
Ci? : 第
i
i
i 個人刪失發生的時間(我們對這個不感興趣)
T
i
:
T_{\mathrm{i}}:
Ti?: pdf
[
f
i
(
t
)
]
,
cdf
?
[
F
i
(
t
)
]
\left[f_{i}(t)\right], \operatorname{cdf}\left[F_{i}(t)\right]
[fi?(t)],cdf[Fi?(t)]
C
i
:
pdf
?
[
g
i
(
t
)
]
,
cdf
?
[
G
i
(
t
)
]
C_{i}: \operatorname{pdf}\left[g_{i}(t)\right], \operatorname{cdf}\left[G_{\mathrm{i}}(t)\right]
Ci?:pdf[gi?(t)],cdf[Gi?(t)]
T
i
⊥
C
i
T_{\mathrm{i}} \perp C_{i}
Ti?⊥Ci?
觀測到的生存時間:
min
?
(
T
i
,
C
i
)
\min \left(T_{\mathrm{i}}, C_{\mathrm{i}}\right)
min(Ti?,Ci?)
現在第
i
i
i 個人觀測到的生存時間為
t
i
,
δ
i
=
1
t_{\mathrm{i}}, \delta_{\mathrm{i}}=1
ti?,δi?=1,則此時
c
o
n
t
r
i
b
u
t
i
o
n
c o n t r i b u t i o n
contribution 為:
lim
?
d
t
→
0
P
(
min
?
(
T
i
,
C
i
)
∈
(
t
i
,
t
i
+
d
t
)
,
δ
i
=
1
)
d
t
=
lim
?
d
t
→
0
P
(
T
i
∈
(
t
i
,
t
i
+
d
t
)
,
C
i
>
t
i
)
d
t
=
f
i
(
t
)
(
1
?
G
i
(
t
)
)
\lim _{\mathrm{dt} \rightarrow 0} \frac{P\left(\min \left(T_{\mathrm{i}}, C_{\mathrm{i}}\right) \in\left(t_{\mathrm{i}}, t_{\mathrm{i}}+\mathrm{dt}\right), \delta_{\mathrm{i}}=1\right)}{d t}=\lim _{\mathrm{dt} \rightarrow 0} \frac{P\left(T_{\mathrm{i}} \in\left(t_{\mathrm{i}}, t_{\mathrm{i}}+\mathrm{dt}\right), C_{i}>t_{i}\right)}{d t}=\mathrm{f}_{i}(t)\left(1-G_{i}(t)\right)
limdt→0?dtP(min(Ti?,Ci?)∈(ti?,ti?+dt),δi?=1)?=limdt→0?dtP(Ti?∈(ti?,ti?+dt),Ci?>ti?)?=fi?(t)(1?Gi?(t))
現在第
i
i
i 個人觀測到的生存時間為
t
i
,
δ
i
=
0
t_{\mathrm{i}}, \delta_{\mathrm{i}}=0
ti?,δi?=0,則此時 contribution為:
lim
?
d
t
→
0
P
(
min
?
(
T
i
,
C
i
)
∈
(
t
i
,
t
i
+
d
t
)
,
δ
i
=
0
)
d
t
=
lim
?
d
t
→
0
P
(
C
i
∈
(
t
i
,
t
i
+
d
t
)
,
T
i
>
t
i
)
d
t
=
T
i
⊥
C
i
g
i
(
t
)
(
1
?
F
i
(
t
)
)
\lim _{\mathrm{dt} \rightarrow 0} \frac{P\left(\min \left(T_{\mathrm{i}}, C_{\mathrm{i}}\right) \in\left(t_{\mathrm{i}}, t_{\mathrm{i}}+\mathrm{dt}\right), \delta_{\mathrm{i}}=0\right)}{d t}=\lim _{\mathrm{dt} \rightarrow 0} \frac{P\left(C_{\mathrm{i}} \in\left(t_{\mathrm{i}}, t_{\mathrm{i}}+\mathrm{dt}\right), T_{i}>t_{i}\right)}{d t} \stackrel{T_{i} \perp C_{i}}{=} \mathrm{g}_{i}(t)\left(1-F_{i}(t)\right)
limdt→0?dtP(min(Ti?,Ci?)∈(ti?,ti?+dt),δi?=0)?=limdt→0?dtP(Ci?∈(ti?,ti?+dt),Ti?>ti?)?=Ti?⊥Ci?gi?(t)(1?Fi?(t))
則似然函式
L
=
∏
i
=
1
n
[
f
i
(
t
i
)
(
1
?
G
i
(
t
i
)
)
]
δ
i
[
g
i
(
t
i
)
(
1
?
F
i
(
t
i
)
)
]
1
?
δ
i
L=\prod_{\mathrm{i}=1}^{n}\left[\mathrm{f}_{i}\left(t_{i}\right)\left(1-G_{i}\left(t_{i}\right)\right)\right]^{\delta_{i}}\left[\mathrm{~g}_{i}\left(t_{i}\right)\left(1-F_{i}\left(t_{i}\right)\right)\right]^{1-\delta_{i}}
L=∏i=1n?[fi?(ti?)(1?Gi?(ti?))]δi?[ gi?(ti?)(1?Fi?(ti?))]1?δi?
=
∏
i
=
1
n
(
1
?
G
i
(
t
)
)
δ
i
g
i
(
t
)
1
?
δ
i
∏
i
=
1
n
f
i
(
t
i
)
δ
i
[
(
1
?
F
i
(
t
)
]
1
?
δ
i
=\prod_{\mathrm{i}=1}^{n}\left(1-G_{i}(t)\right)^{\delta_{i}} \mathrm{~g}_{i}(t)^{1-\delta_{i}} \prod_{\mathrm{i}=1}^{n} \mathrm{f}_{i}\left(t_{i}\right)^{\delta_{i}}\left[\left(1-F_{i}(t)\right]^{1-\delta_{i}}\right.
=∏i=1n?(1?Gi?(t))δi? gi?(t)1?δi?∏i=1n?fi?(ti?)δi?[(1?Fi?(t)]1?δi?
?
L
∝
∏
i
=
1
n
f
i
(
t
i
)
δ
i
[
1
?
F
i
(
t
)
]
1
?
δ
i
\Rightarrow \mathrm{L} \propto \prod_{\mathrm{i}=1}^{n} \mathrm{f}_{i}\left(t_{i}\right)^{\delta_{i}}\left[1-F_{i}(t)\right]^{1-\delta_{i}}
?L∝∏i=1n?fi?(ti?)δi?[1?Fi?(t)]1?δi?
?
ln
?
L
∝
∑
i
=
1
n
δ
i
ln
?
f
i
(
t
i
)
+
∑
i
=
1
n
(
1
?
δ
i
)
ln
?
[
1
?
F
i
(
t
)
]
\Rightarrow \ln L \propto \sum_{i=1}^{n} \delta_{i} \ln \mathrm{f}_{i}\left(t_{i}\right)+\sum_{i=1}^{n}\left(1-\delta_{i}\right) \ln \left[1-F_{i}(t)\right]
?lnL∝∑i=1n?δi?lnfi?(ti?)+∑i=1n?(1?δi?)ln[1?Fi?(t)]
以指數分布為例,
f
(
t
)
=
λ
e
?
λ
t
,
F
(
t
)
=
1
?
e
?
λ
t
\mathrm{f}(\mathrm{t})=\lambda \mathrm{e}^{-\lambda t}, F(t)=1-\mathrm{e}^{-\lambda t}
f(t)=λe?λt,F(t)=1?e?λt, 帶入上式我們有
ln
?
L
(
λ
)
∝
∑
i
=
1
n
δ
i
(
ln
?
λ
?
λ
t
i
)
+
∑
i
=
1
n
(
1
?
δ
i
)
[
?
λ
t
i
]
=
ln
?
λ
∑
i
=
1
n
δ
i
?
λ
∑
i
=
1
n
t
i
\ln L(\lambda) \propto \sum_{i=1}^{n} \delta_{i}\left(\ln \lambda-\lambda t_{i}\right)+\sum_{i=1}^{n}\left(1-\delta_{i}\right)\left[-\lambda t_{i}\right]=\ln \lambda \sum_{i=1}^{n} \delta_{i}-\lambda \sum_{i=1}^{n} t_{i}
lnL(λ)∝∑i=1n?δi?(lnλ?λti?)+∑i=1n?(1?δi?)[?λti?]=lnλ∑i=1n?δi??λ∑i=1n?ti?
?
ln
?
L
(
λ
)
?
λ
=
0
?
λ
^
=
∑
i
=
1
n
δ
i
∑
i
=
1
n
t
i
=
e
v
e
n
t
事件的總和
觀測時間總和
\frac{\partial \ln L(\lambda)}{\partial \lambda}=0 \Rightarrow \hat{\lambda}=\frac{\sum_{i=1}^{n} \delta_{i}}{\sum_{i=1}^{n} t_{i}}=\frac{e v e n t \text { 事件的總和 }}{\text { 觀測時間總和 }}
?λ?lnL(λ)?=0?λ^=∑i=1n?ti?∑i=1n?δi??= 觀測時間總和 event 事件的總和 ?
?
\Rightarrow
? 帶入指數分布, 則有
S
^
(
t
)
=
exp
?
{
?
λ
^
t
}
\hat{S}(t)=\exp \{-\hat{\lambda} t\}
S^(t)=exp{?λ^t}; weibull分布同理
模型擬合檢驗
假如我們對指數分布和 weibull 分布都進行建模,那哪個模型是更合適的呢?我們這里就引入似然比 檢驗
H
0
:
t
~
指數分布
v
s
H
1
:
t
~
weibull 分布
H_{0}: \mathrm{t} \sim \text { 指數分布 } vs H_{1}: \mathrm{t} \sim \text { weibull 分布}
H0?:t~ 指數分布 vsH1?:t~ weibull 分布
相應的似然函式為:
ln
?
L
(
β
1
,
…
,
β
m
)
、
ln
?
L
(
β
1
,
…
,
β
m
,
σ
)
\ln L\left(\beta_{1}, \ldots, \beta_{m}\right) 、 \quad \ln L\left(\beta_{1}, \ldots, \beta_{m}, \sigma\right)
lnL(β1?,…,βm?)、lnL(β1?,…,βm?,σ)
由似然比檢驗有:
H
0
下
H_{0}下
H0?下,
?
2
[
ln
?
L
(
β
1
,
…
,
β
m
)
?
ln
?
L
(
β
1
,
…
,
β
m
,
σ
)
]
~
漸進
χ
2
(
1
)
-2\left[\ln L\left(\beta_{1}, \ldots, \beta_{m}\right)-\ln L\left(\beta_{1}, \ldots, \beta_{m}, \sigma\right)\right]\underset{\text { 漸進 }} \sim \chi^{2}(1)
?2[lnL(β1?,…,βm?)?lnL(β1?,…,βm?,σ)] 漸進 ~?χ2(1)
cox風險比例模型(Cox Proportional Hazards Model)
基本定義
cox風險比例模型中,我們是對風險函式進行設定
h
(
t
,
x
1
,
…
,
x
m
,
β
1
,
.
.
,
β
m
)
=
h
0
(
t
)
exp
?
{
β
1
x
1
+
…
+
β
m
x
m
}
h\left(t, x_{1}, \ldots, x_{m}, \beta_{1}, . ., \beta_{m}\right)=h_{0}(t) \exp \left\{\beta_{1} x_{1}+\ldots+\beta_{m} x_{m}\right\}
h(t,x1?,…,xm?,β1?,..,βm?)=h0?(t)exp{β1?x1?+…+βm?xm?}
h
0
(
t
)
:
h_{0}(t):
h0?(t): baseline hazard function
cox
?
\operatorname{cox}
cox 基本模型中有
h
(
t
)
=
f
(
t
)
S
(
t
)
h(t)=\frac{f(t)}{S(t)}
h(t)=S(t)f(t)?
兩個人在同一時刻的風險比
h
(
t
,
x
i
1
,
…
,
x
i
m
,
β
1
,
…
,
β
m
)
h
(
t
,
x
j
1
,
…
,
x
j
m
,
β
1
,
…
,
β
m
)
=
exp
?
{
β
1
(
x
i
1
?
x
j
1
)
+
…
+
β
m
(
x
i
m
?
x
j
m
)
}
;
\frac{\mathrm{h}\left(t, x_{i 1}, \ldots, x_{i m}, \beta_{1}, \ldots, \beta_{m}\right)}{h\left(t, x_{j 1}, \ldots, x_{j m}, \beta_{1}, \ldots, \beta_{m}\right)}=\exp \left\{\beta_{1}\left(x_{i 1}-x_{j 1}\right)+\ldots+\beta_{m}\left(x_{i m}-x_{j m}\right)\right\} ;
h(t,xj1?,…,xjm?,β1?,…,βm?)h(t,xi1?,…,xim?,β1?,…,βm?)?=exp{β1?(xi1??xj1?)+…+βm?(xim??xjm?)}; 與
t
t
t 無關
因此在實際應用中,也可以基于此判斷使用
cox
?
\operatorname{cox}
cox 風險比例模型是否合理
引數求解
現在我們只需要估計出
β
\beta
β, 即可求出
cox
?
\operatorname{cox}
cox 風險比例模型,
這里我們使用偏似然估計對
β
\beta
β 估計
第一步求似然:
-
前面我們已經得到似然函式 L ∝ ∏ i = 1 n f i ( t i ) δ i [ 1 ? F i ( t ) ] 1 ? δ i \mathrm{L} \propto \prod_{\mathrm{i}=1}^{n} \mathrm{f}_{i}\left(t_{i}\right)^{\delta_{i}}\left[1-F_{i}(t)\right]^{1-\delta_{i}} L∝∏i=1n?fi?(ti?)δi?[1?Fi?(t)]1?δi?
-
因此有:
∏ i = 1 n ( f i ( t i ) ) δ i ( 1 ? F i ( t i ) ) 1 ? δ i = ∏ i = 1 n ( f i ( t i ) ) δ i ( S i ( t i ) ) 1 ? δ i = ∏ i = 1 n ( h i ( t i ) S i ( t i ) ) δ i ( S i ( t i ) ) 1 ? δ i = ∏ i = 1 n ( h i ( t i ) ) δ i S i ( t i ) = ∏ i = 1 n [ h i ( t i ) ∑ j ∈ R ( t i ) h j ( t i ) ] δ i × [ ∑ j ∈ R ( t i ) h j ( t i ) ] δ i S i ( t i ) = ∏ i = 1 n [ exp ? { β 1 x i 1 + ? + β m x i m } ∑ j ∈ R ( t i ) exp ? { β 1 x j 1 + ? + β m x j m } ] δ i × ∏ i = 1 n [ ∑ j ∈ R ( t i ) h j ( t i ) ] δ i S i ( t i ) \begin{aligned} &\prod_{i=1}^{n}\left(f_{i}\left(t_{i}\right)\right)^{\delta_{i}}\left(1-F_{i}\left(t_{i}\right)\right)^{1-\delta_{i}}=\prod_{i=1}^{n}\left(f_{i}\left(t_{i}\right)\right)^{\delta_{i}}\left(S_{i}\left(t_{i}\right)\right)^{1-\delta_{i}} \\ &=\prod_{i=1}^{n}\left(h_{i}\left(t_{i}\right) S_{i}\left(t_{i}\right)\right)^{\delta_{i}}\left(S_{i}\left(t_{i}\right)\right)^{1-\delta_{i}} \quad\\ &=\prod_{i=1}^{n}\left(h_{i}\left(t_{i}\right)\right)^{\delta_{i}} S_{i}\left(t_{i}\right)=\prod_{i=1}^{n}\left[\frac{h_{i}\left(t_{i}\right)}{\sum_{j \in R\left(t_{i}\right)} h_{j}\left(t_{i}\right)}\right]^{\delta_{i}} \times\left[\sum_{j \in R\left(t_{i}\right)} h_{j}\left(t_{i}\right)\right]^{\delta_{i}} S_{i}\left(t_{i}\right) \\ &=\prod_{i=1}^{n}\left[\frac{\exp \left\{\beta_{1} x_{i 1}+\cdots+\beta_{m} x_{i m}\right\}}{\sum_{j \in R\left(t_{i}\right)} \exp \left\{\beta_{1} x_{j 1}+\cdots+\beta_{m} x_{j m}\right\}}\right]^{\delta_{i}} \times \prod_{i=1}^{n}\left[\sum_{j \in R\left(t_{i}\right)} h_{j}\left(t_{i}\right)\right]^{\delta_{i}} S_{i}\left(t_{i}\right) \end{aligned} ?i=1∏n?(fi?(ti?))δi?(1?Fi?(ti?))1?δi?=i=1∏n?(fi?(ti?))δi?(Si?(ti?))1?δi?=i=1∏n?(hi?(ti?)Si?(ti?))δi?(Si?(ti?))1?δi?=i=1∏n?(hi?(ti?))δi?Si?(ti?)=i=1∏n?[∑j∈R(ti?)?hj?(ti?)hi?(ti?)?]δi?×???j∈R(ti?)∑?hj?(ti?)???δi?Si?(ti?)=i=1∏n?[∑j∈R(ti?)?exp{β1?xj1?+?+βm?xjm?}exp{β1?xi1?+?+βm?xim?}?]δi?×i=1∏n????j∈R(ti?)∑?hj?(ti?)???δi?Si?(ti?)? -
右邊的進行拋棄,左邊的就是我們求出來的似然函式,即似然函式為:
L p ( β 1 , … , β m ) = ∏ i = 1 n [ exp ? { β 1 x i 1 + ? + β m x i m } ∑ j ∈ R ( t i ) exp ? { β 1 x j 1 + ? + β m x j m } ] δ i L_{p}\left(\beta_{1}, \ldots, \beta_{m}\right)=\prod_{i=1}^{n}\left[\frac{\exp \left\{\beta_{1} x_{i 1}+\cdots+\beta_{m} x_{i m}\right\}}{\sum_{j \in R\left(t_{i}\right)} \exp \left\{\beta_{1} x_{j 1}+\cdots+\beta_{m} x_{j m}\right\}}\right]^{\delta_{i}} Lp?(β1?,…,βm?)=∏i=1n?[∑j∈R(ti?)?exp{β1?xj1?+?+βm?xjm?}exp{β1?xi1?+?+βm?xim?}?]δi? -
這里我們使用偏極大似然對引數 β \beta β 進行求導( partial-likelihood estimation method):
ln ? L p ( β 1 , … , β m ) = ∑ i = 1 n δ i ( β 1 x i 1 + ? + β m x i m ) ? ∑ i = 1 n δ i ln ? ( ∑ j ∈ R ( t i ) exp ? { β 1 x j 1 + ? + β m x j m } ) ? ln ? L p ( β ^ 1 , … , β ^ m ) ? β k = ∑ i = 1 n δ i x i k ? ∑ i = 1 n δ i ∑ j ∈ R ( t i ) x j k exp ? { β ^ 1 x j 1 + ? + β ^ m x j m } ∑ j ∈ R ( t i ) exp ? { β ^ 1 x j 1 + ? + β ^ m x j m } = 0 , k = 1 , … , m . \begin{aligned} \ln L_{p}\left(\beta_{1}, \ldots, \beta_{m}\right) &=\sum_{i=1}^{n} \delta_{i}\left(\beta_{1} x_{i 1}+\cdots+\beta_{m} x_{i m}\right) -\sum_{i=1}^{n} \delta_{i} \ln \left(\sum_{j \in R\left(t_{i}\right)} \exp \left\{\beta_{1} x_{j 1}+\cdots+\beta_{m} x_{j m}\right\}\right) \\ \frac{\partial \ln L_{p}\left(\hat{\beta}_{1}, \ldots, \hat{\beta}_{m}\right)}{\partial \beta_{k}} &=\sum_{i=1}^{n} \delta_{i} x_{i k} -\sum_{i=1}^{n} \delta_{i} \frac{\sum_{j \in R\left(t_{i}\right)} x_{j k} \exp \left\{\hat{\beta}_{1} x_{j 1}+\cdots+\hat{\beta}_{m} x_{j m}\right\}}{\sum_{j \in R\left(t_{i}\right)} \exp \left\{\hat{\beta}_{1} x_{j 1}+\cdots+\hat{\beta}_{m} x_{j m}\right\}} \\ &=0, \quad k=1, \ldots, m . \end{aligned} lnLp?(β1?,…,βm?)?βk??lnLp?(β^?1?,…,β^?m?)??=i=1∑n?δi?(β1?xi1?+?+βm?xim?)?i=1∑n?δi?ln???j∈R(ti?)∑?exp{β1?xj1?+?+βm?xjm?}???=i=1∑n?δi?xik??i=1∑n?δi?∑j∈R(ti?)?exp{β^?1?xj1?+?+β^?m?xjm?}∑j∈R(ti?)?xjk?exp{β^?1?xj1?+?+β^?m?xjm?}?=0,k=1,…,m.?
舉例
假設有 5 個受試者的生存時間
t
1
,
t
1
,
t
2
+
,
t
3
t_{1}, t_{1}, t_{2}+, t_{3}
t1?,t1?,t2?+,t3?, and
t
4
+
t_{4}+
t4?+,注意到有兩個不同的死亡時間
t
1
t_{1}
t1? and
t
3
t_{3}
t3?. 令
r
j
=
exp
?
{
β
1
x
j
1
+
?
+
β
m
x
j
m
}
,
j
=
1
,
…
,
5
r_{j}=\exp \left\{\beta_{1} x_{j 1}+\cdots+\beta_{m} x_{j m}\right\}, j=1, \ldots, 5
rj?=exp{β1?xj1?+?+βm?xjm?},j=1,…,5, 為第
j
j
j 個受試者的相關風險. 那么Breslow近似的似然函式是
L
p
(
β
1
,
…
,
β
m
)
=
r
1
r
2
(
r
1
+
r
2
+
r
3
+
r
4
+
r
5
)
2
r
4
(
r
4
+
r
5
)
L_{p}\left(\beta_{1}, \ldots, \beta_{m}\right)=\frac{r_{1} r_{2}}{\left(r_{1}+r_{2}+r_{3}+r_{4}+r_{5}\right)^{2}} \frac{r_{4}}{\left(r_{4}+r_{5}\right)}
Lp?(β1?,…,βm?)=(r1?+r2?+r3?+r4?+r5?)2r1?r2??(r4?+r5?)r4??
則回歸系數
β
^
1
,
…
,
β
^
m
\hat{\beta}_{1}, \ldots, \hat{\beta}_{m}
β^?1?,…,β^?m?的估計值滿足以下方程:
?
ln
?
L
p
(
β
^
1
,
…
,
β
^
m
)
?
β
q
=
∑
i
=
1
k
∑
l
∈
D
(
t
i
)
x
l
q
?
∑
i
=
1
k
d
i
∑
j
∈
R
(
t
i
)
x
j
q
exp
?
{
β
^
1
x
j
1
+
?
+
β
^
m
x
j
m
}
∑
j
∈
R
(
t
i
)
exp
?
{
β
^
1
x
j
1
+
?
+
β
^
m
x
j
m
}
=
0
,
q
=
1
,
…
,
m
\begin{aligned} \frac{\partial \ln L_{p}\left(\hat{\beta}_{1}, \ldots, \hat{\beta}_{m}\right)}{\partial \beta_{q}} &=\sum_{i=1}^{k} \sum_{l \in D\left(t_{i}\right)} x_{l q} \\ &-\sum_{i=1}^{k} d_{i} \frac{\sum_{j \in R\left(t_{i}\right)} x_{j q} \exp \left\{\hat{\beta}_{1} x_{j 1}+\cdots+\hat{\beta}_{m} x_{j m}\right\}}{\sum_{j \in R\left(t_{i}\right)} \exp \left\{\hat{\beta}_{1} x_{j 1}+\cdots+\hat{\beta}_{m} x_{j m}\right\}} \\ &=0, q=1, \ldots, m \end{aligned}
?βq??lnLp?(β^?1?,…,β^?m?)??=i=1∑k?l∈D(ti?)∑?xlq??i=1∑k?di?∑j∈R(ti?)?exp{β^?1?xj1?+?+β^?m?xjm?}∑j∈R(ti?)?xjq?exp{β^?1?xj1?+?+β^?m?xjm?}?=0,q=1,…,m?
現在我們已經求出了引數
β
\beta
β ,但是我們還沒有求出基線風險函式
h
0
(
t
)
h_{0}(t)
h0?(t) (baseline hazard function),下面對基線風險函式進行求解:
令
π
i
=
P
(
T
>
t
i
∣
T
>
t
i
?
1
)
\pi_{\mathrm{i}}=P\left(T>t_{i} \mid T>t_{i-1}\right)
πi?=P(T>ti?∣T>ti?1?)
L
(
π
1
,
…
,
π
n
,
β
1
,
…
,
β
m
)
=
∏
i
=
1
n
∏
j
∈
D
(
t
i
)
(
1
?
π
i
r
j
)
∏
j
∈
R
(
t
i
)
\
D
(
t
i
)
π
i
r
j
L\left(\pi_{1}, \ldots, \pi_{n}, \beta_{1}, \ldots, \beta_{m}\right)=\prod_{i=1}^{n} \prod_{j \in D\left(t_{i}\right)}\left(1-\pi_{i}^{r_{j}}\right) \prod_{j \in R\left(t_{i}\right) \backslash D\left(t_{i}\right)} \pi_{i}^{r_{j}}
L(π1?,…,πn?,β1?,…,βm?)=i=1∏n?j∈D(ti?)∏?(1?πirj??)j∈R(ti?)\D(ti?)∏?πirj??
相應地,其對數似然函式為
ln
?
L
(
π
1
,
…
,
π
n
,
β
1
,
…
,
β
m
)
=
∑
i
=
1
n
[
∑
j
∈
D
(
t
i
)
ln
?
(
1
?
π
i
r
j
)
+
∑
j
∈
R
(
t
i
)
\
D
(
t
i
)
r
j
ln
?
π
i
]
\ln L\left(\pi_{1}, \ldots, \pi_{n}, \beta_{1}, \ldots, \beta_{m}\right)=\sum_{i=1}^{n}\left[\sum_{j \in D\left(t_{i}\right)} \ln \left(1-\pi_{i}^{r_{j}}\right)+\sum_{j \in R\left(t_{i}\right) \backslash D\left(t_{i}\right)} r_{j} \ln \pi_{i}\right]
lnL(π1?,…,πn?,β1?,…,βm?)=i=1∑n????j∈D(ti?)∑?ln(1?πirj??)+j∈R(ti?)\D(ti?)∑?rj?lnπi????
對
π
i
\pi_{i}
πi? 進行求導:
∑
j
∈
D
(
t
i
)
r
^
j
1
?
π
^
i
r
^
j
=
∑
j
∈
R
(
t
i
)
r
^
j
,
i
=
1
,
…
,
n
\sum_{j \in D\left(t_{i}\right)} \frac{\hat{r}_{j}}{1-\hat{\pi}_{i}^{\hat{r}_{j}}}=\sum_{j \in R\left(t_{i}\right)} \hat{r}_{j}, \quad i=1, \ldots, n
j∈D(ti?)∑?1?π^ir^j??r^j??=j∈R(ti?)∑?r^j?,i=1,…,n
這里
r
^
j
=
exp
?
{
β
^
1
x
j
1
+
?
+
β
^
m
x
j
m
}
\hat{r}_{j}=\exp \left\{\hat{\beta}_{1} x_{j 1}+\cdots+\hat{\beta}_{m} x_{j m}\right\}
r^j?=exp{β^?1?xj1?+?+β^?m?xjm?},
π
^
i
=
(
1
?
r
^
j
′
(
i
)
∑
j
∈
R
(
t
i
)
r
^
j
)
1
/
r
^
j
′
(
i
)
,
i
=
1
,
…
,
n
\hat{\pi}_{i}=\left(1-\frac{\hat{r}_{j^{\prime}(i)}}{\sum_{j \in R\left(t_{i}\right)} \hat{r}_{j}}\right)^{1 / \hat{r}_{j^{\prime}(i)}}, \quad i=1, \ldots, n
π^i?=(1?∑j∈R(ti?)?r^j?r^j′(i)??)1/r^j′(i)?,i=1,…,n
看到這里你應該就明白了,為什么COX風險比例模型是半引數模型,
參考文獻及教學視頻:
[1]: Clinical Statistics: Introducing Clinical Trials, Survival Analysis, and Longitudinal Data Analysis
[2]: https://www.bilibili.com/video/BV1L5411j78B/spm_id_from=333.788.recommend_more_video.0
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/293665.html
標籤:其他