前言
YOLO是一種目標檢測方法,它的輸入是整張圖片,輸出是n個物體的檢測資訊,可以識別出圖中的物體的類別和位置,YOLOv4是在YOLOv3的基礎上增加了很多實用的技巧,使得速度與精度都有較大提升,v4版本設計思路如下:
輸入端:在模型訓練階段,使用了Mosaic資料增強、cmBN跨小批量標準化、SAT自對抗訓練;
BackBone層:也稱主干網路,使用CSPDarknet53網路提取特征;同時使用Mish激活函式、Dropblock正則化;CSP 跨階段部分連接,
Neck中間層:這是在BackBone與最后的Head輸出層之間插入的一些層,Yolov4中添加了SPP模塊、FPN+PAN結構;也支持“多尺度特征檢測”,三種輸出特征圖分為19*19、38*38、76*76,對應檢測大物體、中等物體、小物體,
Head輸出層:輸出層的錨框機制與YOLOv3相同,其中通過聚類提取先驗框尺度,并約束預測邊框的位置,主要改進的是訓練時的損失函式CIOU_Loss,以及預測框篩選的DIOU_nms,
論文地址:YOLOv4: Optimal Speed and Accuracy of Object Detection
Pytorch-YOLOv4 開源代碼:https://github.com/Tianxiaomo/pytorch-YOLOv4
Tensorflow 2-YOLOv4 開源代碼:https://github.com/hunglc007/tensorflow-yolov4-tflite
目錄
一、網路結構
1.1 輸入輸出映射
1.2整體網路結構
1.3 基礎組件CBM
1.4 基礎組件CBL
1.5 基礎組件Res unit
1.6 基礎組件CSPX
1.7 基礎組件 SPP
二、輸入端
2.1 Mosaic資料增強
2.2 cmBN跨小批量標準化
2.3 SAT自對抗訓練
三、BackBone層
3.1 CSPDarknet53
3.2 Mish激活函式
3.3 Dropblock正則化
四、Neck中間層
4.1 SPP模塊
4.2 PAN結構
5、Head輸出層
5.1 多尺度特征檢測
5.2 輸出維度含義
5.3 DIOU_nms損失函式
5.4 CIOU_Loss損失函式
六、模型效果
七、參考文獻
一、網路結構
1.1 輸入輸出映射
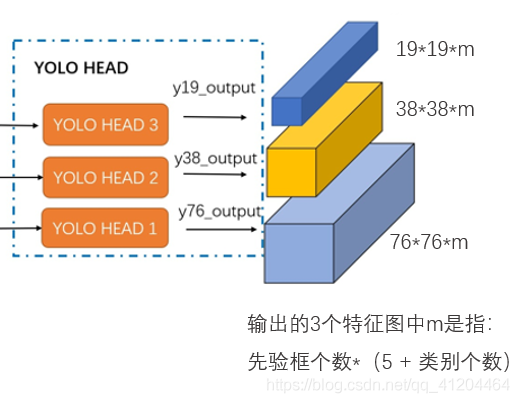
輸入一張608*608的影像,CSPDarknet-53 網路后得到了 3 個分支,這些分支在經過SSP+PAN結構最終得到了三個尺寸不一的 feature map,形狀分別為 [19, 19, m]、[38, 38, m] 和 [76, 76, m],
輸出的3個特征圖中的m是指: 先驗框個數*(5 + 類別個數)
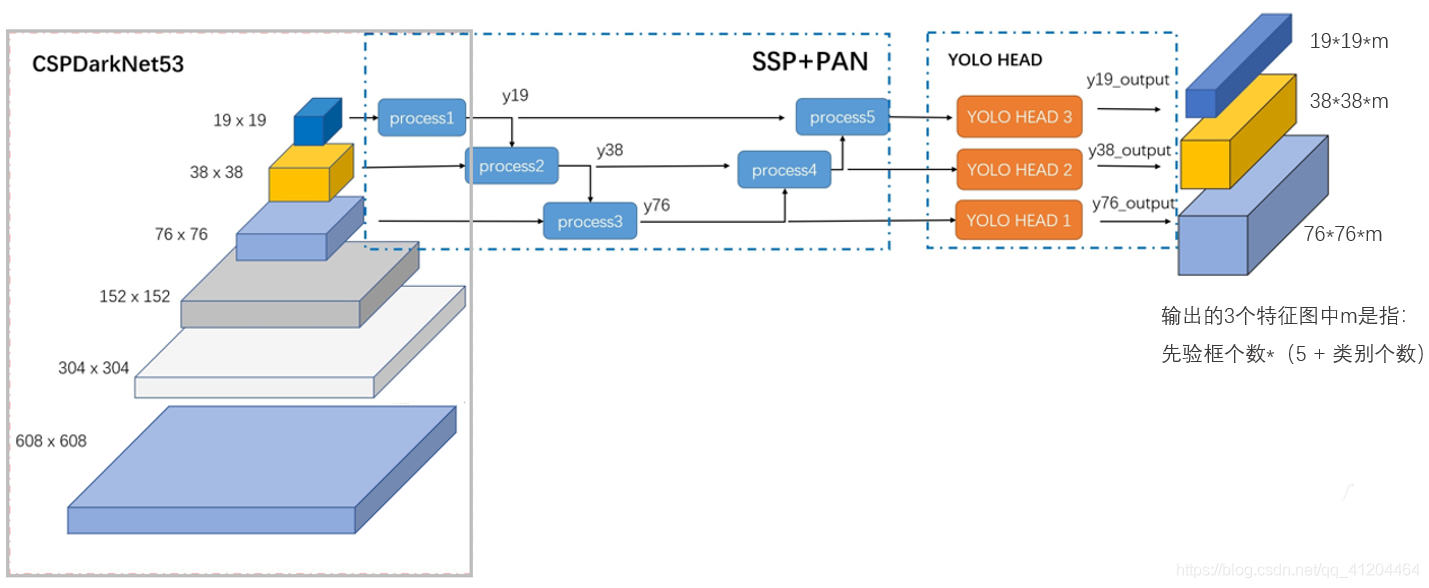
1.2整體網路結構
整體網路可以分為4部分組成,分別是輸入端、BackBone主干網路、Neck連接結構、Prediction Head輸出然后預測, 先看一下整體的網路結構:
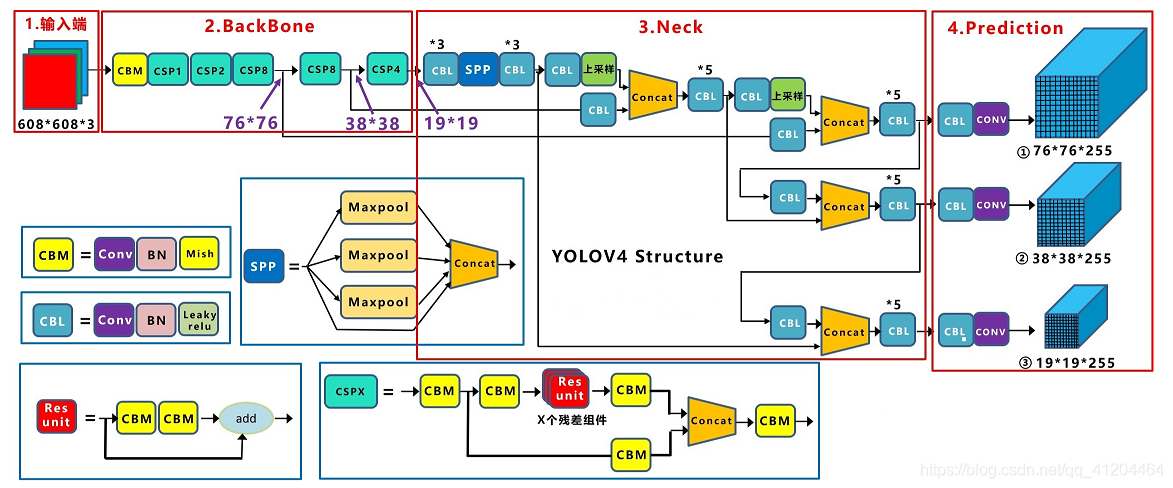
- 輸入端,輸入608*608的影像,進行影像預處理;其中Mosaic資料增強,提升模型的訓練速度和網路的精度;cmBN及SAT自對抗訓練來提升網路的泛化性能,
- BackBone主干網路,用于提取影像特征;v4版本使用CSPDarknet53作為主干網路,使用Mish激活函式代替原始的RELU激活函式;增加了Dropblock正則化來進一步提升模型的泛化能力,降低過擬合風險 ,
- Neck連接結構,用于連接BackBone主干網路 和 Head輸出層,通過設計“Neck連接結構”可以提升特征的多樣性及魯棒性,使用SPP結構,融合不同尺度大小的特征圖,解決不同尺寸的特征圖如何進入全連接層,對任意尺寸的特征圖直接進行固定尺寸的池化,來得到固定數量的特征,使用PAN結構,代替FPN進行引數聚合以適用于不同level的目標檢測,
- Head輸出層,用來完成目標檢測結果的輸出,用CIOU_Loss來代替Smooth L1 Loss函式,并利用DIOU_nms來代替傳統的NMS操作,從而進一步提升演算法的檢測精度,
基礎組件,包括CBM、CBL、Res unit、CSPX、SPP,
1.3 基礎組件CBM
CBM,由Conv+BN+Mish激活函陣列成,
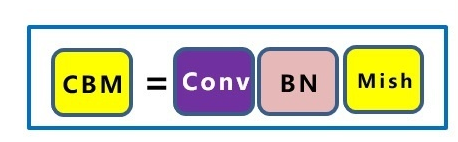
Conv 是卷積層,用來提取特征;
BN,batch normalization 批歸一化:
網路中的位置:在“該層網路輸出后”和“激活函式之前”增加一個BN層,
批歸一化的處理:對該層網路輸出的特征量分別進行歸一化處理,分別使每個特征的資料分布變換為均值0,方差1,特征值數范圍控制在[0,1]之間,
批歸一化的效果:有助于解決反向傳播程序中的梯度消失和梯度爆炸問題,降低對一些超引數(比如學習率、網路引數的大小范圍、激活函式的選擇)的敏感性,并且每個batch分別進行歸一化的時候,起到了一定的正則化效果,從而能夠獲得更好的收斂速度和收斂效果,
Mish,是一種激活函式,Mish與ReLU、Swish非常相似,但Mish可以在不同資料集的許多深度網路中勝過它們,Mish公式:
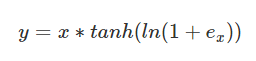
Mish是一個平滑的曲線,平滑的激活函式允許更好的資訊深入神經網路,從而得到更好的準確性和泛化;在負值的時候并不是完全截斷,允許比較小的負梯度流入,
看看Mish、ReLU、SoftPlus 和 Swish 激活函式的圖:
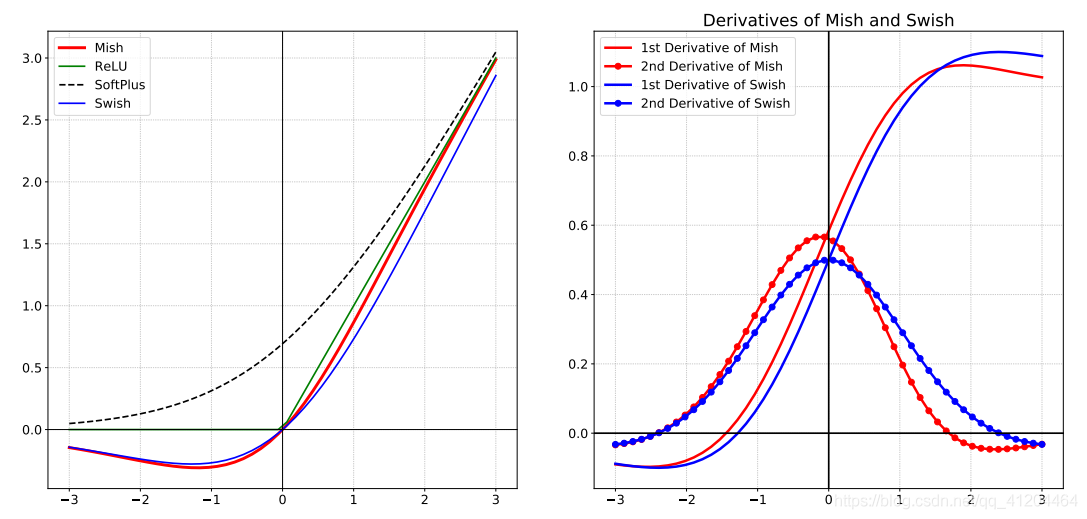
Mish論文地址: https://arxiv.org/pdf/1908.08681.pdf
1.4 基礎組件CBL
CBL,由Conv+BN+Leaky_relu激活函陣列成,
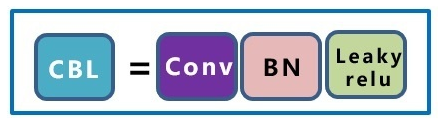
Conv、BN 上面介紹過了,這里主要介紹Leaky_relu激活函式, 公式:
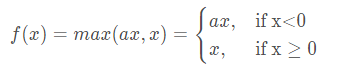
其中a通常會設為0.01,
Leaky_relu與ReLU很相似,僅在輸入小于0的部分有差別,ReLU輸入小于0的部分值都為0,而Leaky_relu輸入小于0的部分,值為負,且有微小的梯度,看看ReLU、Leaky_relu激活函式的圖:
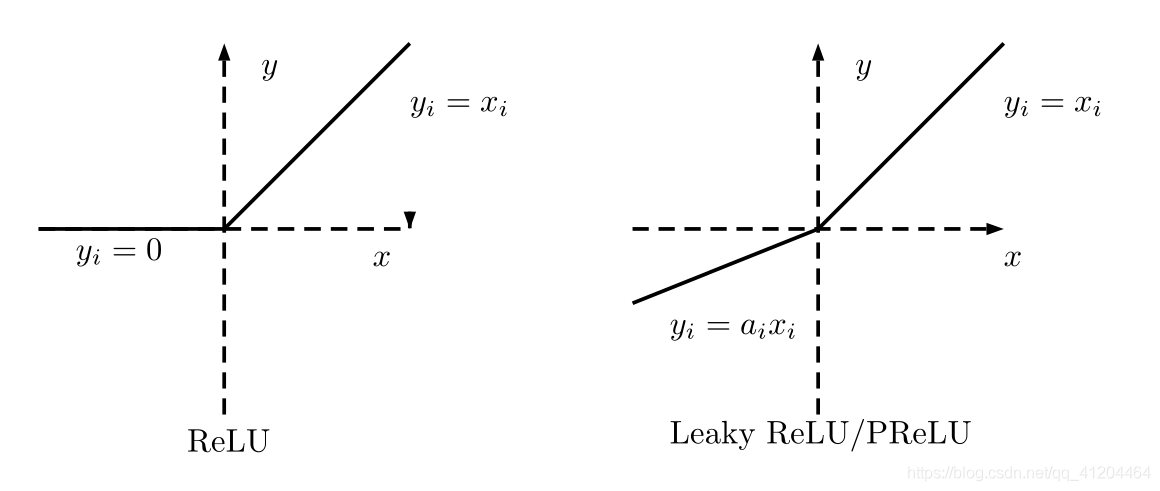
Leaky_relu 優點:在反向傳播程序中,其輸入小于零的部分,也可以計算得到梯度(而不是像ReLU一樣值為0),這樣就避免了上述梯度方向鋸齒問題,
1.5 基礎組件Res unit
Res unit,借鑒ResNet網路中的殘差結構,用來構建深層網路,CBM是殘差模塊中的子模塊,
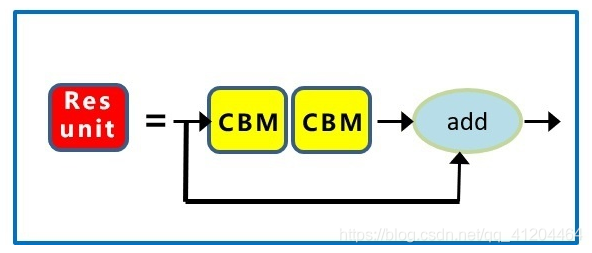
這里主要介紹一下殘差結構,
ResNets殘差結構解決深度神經網路的“退化”問題,其中退化”指的是,給網路疊加更多的層后,網路深度在增加,性能卻快速下降的情況,隨著網路深度增加,會出現梯度消失或 梯度爆炸,梯度消失會導致梯度變為 0 ;梯度爆炸會導致梯度太大,
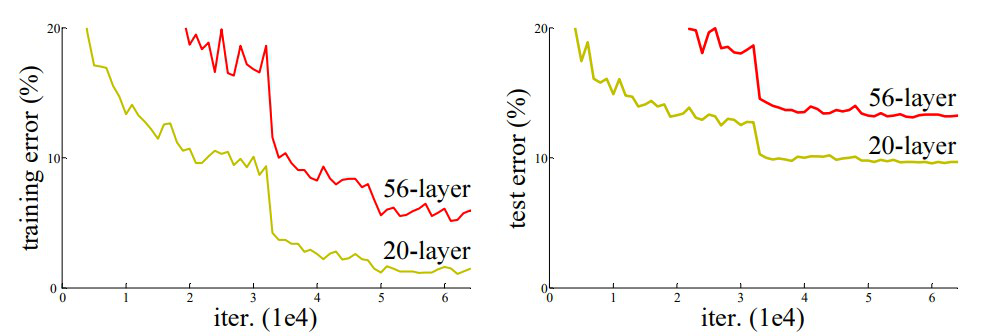
在上圖中,我們可以觀察到 56 層 CNN 在訓練和測驗資料集上的錯誤率都高于 20 層 CNN 架構,如果這是過度擬合的結果,那么56層CNN應該中具有更低的“訓練錯誤”,但它也有更高的訓練誤差,在對錯誤率進行更多分析后,ResNet作者得出結論,這是由梯度消失/爆炸引起的,
微軟研究院的研究人員于 2015 年提出的 ResNet 引入了一種名為 Residual Network 的新架構,
殘差塊:
為了解決梯度消失/爆炸的問題,該架構引入了殘差網路的概念,在這個網路中,我們使用一種稱為跳過連接的技術,跳過連接,從幾層跳過訓練,并直接連接到輸出,
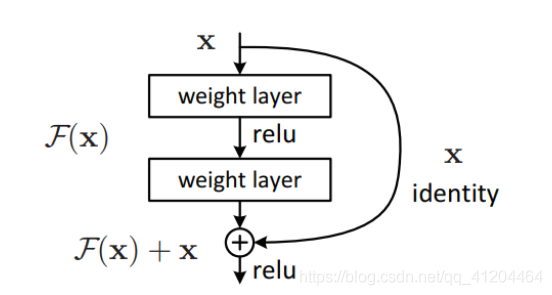
添加這種型別的跳過連接的好處是,如果任何層損害了架構的性能,那么它將被正則化跳過,因此,這導致訓練非常深的神經網路,而不會出現梯度消失/爆炸引起的問題,
其中輸出H(x),H(x) = F(x) + x,x是輸入資訊,F(x)是輸入資訊經過一些層的特征提取得出的結果,
該結構是讓網路擬合殘差映射,F(x) = H(x) – x,
1.6 基礎組件CSPX
CSPX,借鑒CSPNet網路結構,由卷積層和X個Res unint模塊Concate組成而成,
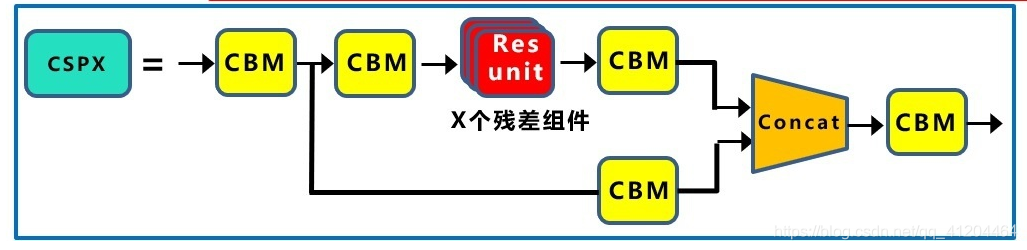
首先介紹一下Concate 結構,然后介紹CSPNet網路結構,
Concate,用于將特征聯合;是通道數的合并,也就是說描述影像本身的特征增加了,而每一特征下的資訊是沒有增加,
1.7 基礎組件 SPP
SPP,采用1×1、5×5、9×9和13×13的最大池化方式,進行多尺度特征融合,
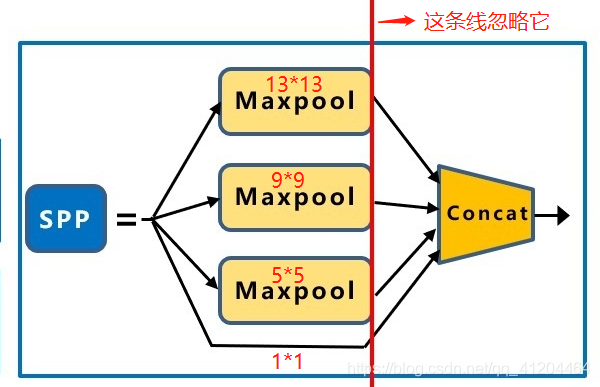
SPP結構,能融合不同尺度大小的特征圖;用來解決不同尺寸的特征圖如何進入全連接層,對任意尺寸的特征圖直接進行固定尺寸的池化,來得到固定數量的特征,
然后將每個池化得到的特征合起來即得到固定長度的特征個數(特征圖的維度是固定的),接著就可以輸入到全連接層中進行訓練網路了,SPP能增加感受野,
二、輸入端
輸入端:在模型訓練階段,使用了Mosaic資料增強、cmBN跨小批量標準化、SAT自對抗訓練;
2.1 Mosaic資料增強
Mosaic 是一種資料增強方法,將 4 張訓練影像組合成1張進行訓練,

作用:增強了對正常背景(context)之外的物件的檢測,每個 mini-batch 包含大量的影像,使用Mosaic后:是原來 mini-batch 所包含影像數量的 4 倍,因此,減少了估計均值和方差的時需要大mini-batch的要求,
2.2 cmBN跨小批量標準化
BN是僅僅使用“當前迭代時刻的資訊”進行歸一化,而CBN在計算當前時刻統計量時候會考慮“前k個時刻”統計量,從而實作擴大batch size操作,同時作者指出CBN操作不會引入比較大的記憶體開銷,訓練速度不會影響很多,但是訓練時候會慢一些,
CmBN是CBN的改進版本,其把大batch內部的4個mini batch當做一個整體,對外隔離,CBN在第t時刻,也會考慮前3個時刻的統計量進行匯合,而CmBN操作不會,不再滑動cross,其僅僅在mini batch內部進行匯合操作,保持BN一個batch更新一次可訓練引數,
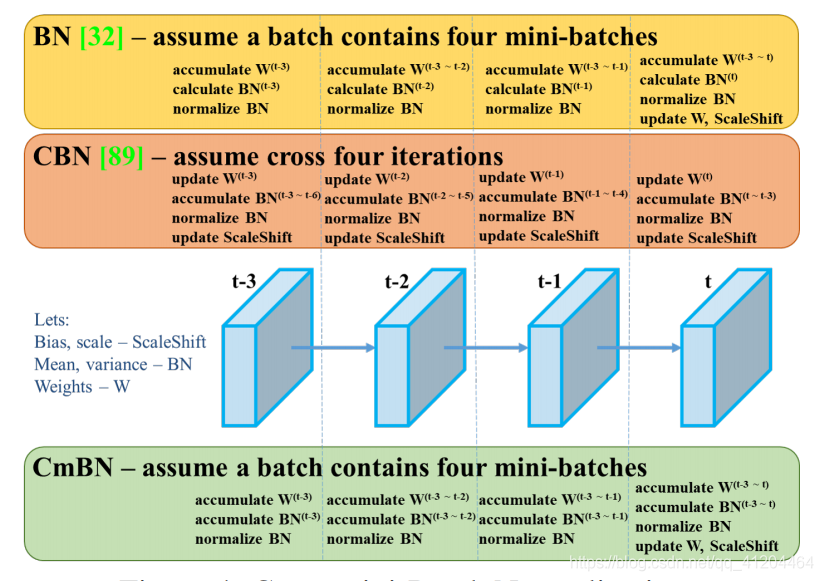
BN:無論每個batch被分割為多少個mini batch,其演算法就是在每個mini batch前向傳播后統計當前的BN資料(即每個神經元的期望和方差)并進行歸一化,BN資料與其他mini batch的資料無關,
CBN:每次迭代中的BN資料是其之前n次資料與當前資料的和(對非當前batch統計的資料進行了補償再參與計算),用該累加值對當前的batch進行歸一化,好處在于每個batch可以設定較小的size,
CmBN:只在每個Batch內部使用CBN的方法,個人理解如果每個Batch被分割為一個mini batch,則其效果與BN一致;若分割為多個mini batch,則與CBN類似,只是把mini batch當作batch進行計算,其區別在于權重更新時間點不同,同一個batch內權重引數一樣,因此計算不需要進行補償,
2.3 SAT自對抗訓練
SAT,全稱Self-Adversarial Training,可以理解為自對抗訓練;為一種新型資料增強方式,在第一階段,神經網路改變原始影像而不是網路權值,通過這種方式,神經網路對其自身進行一種對抗式的攻擊,改變原始影像,制造影像上沒有目標的假象,在第二階段,訓練神經網路對修改后的影像進行正常的目標檢測,
SAT論文:https://export.arxiv.org/pdf/1703.08603
使用對抗生成可以改善學習的決策邊界中的薄榷訓節,提高模型的魯棒性,因此這種資料增強方式被越來越多的物件檢測框架運用,
三、BackBone層
BackBone層也稱主干網路,使用CSPDarknet53網路提取特征;同時使用Mish激活函式、Dropblock正則化;CSP 跨階段部分連接,
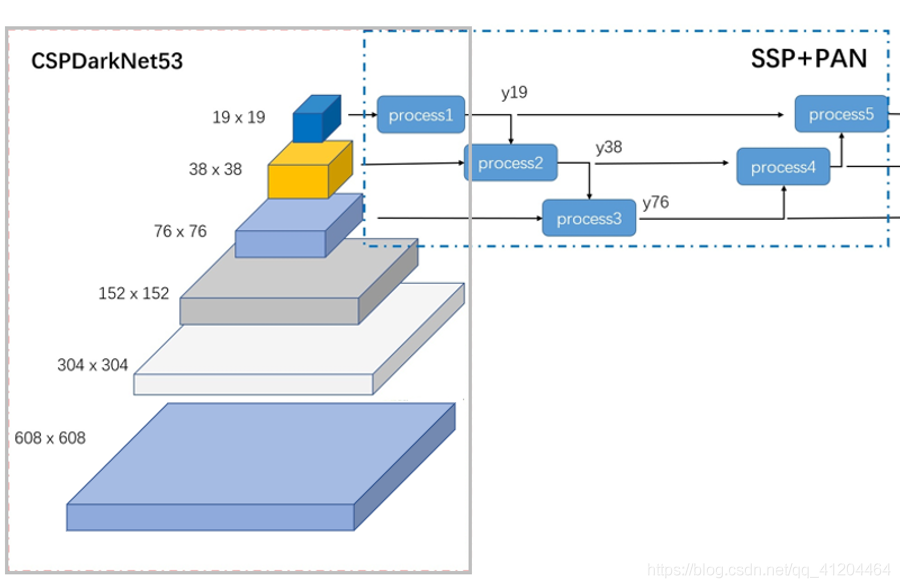
3.1 CSPDarknet53
CSPDarknet53是基于Darknet53,借鑒CSPNet,進行了一些改進,使得模型既保證了推理速度和準確率,又減小了模型尺寸,
首先介紹一下CSPNet,全稱是Cross Stage Partial Networks,也就是“跨階段區域網路”,
CSPNet解決了一些大型卷積神經網路框架Backbone中網路優化的“梯度資訊重復問題”,它是將梯度的變化從頭到尾地集成到特征圖中,因此減少了模型的引數量,
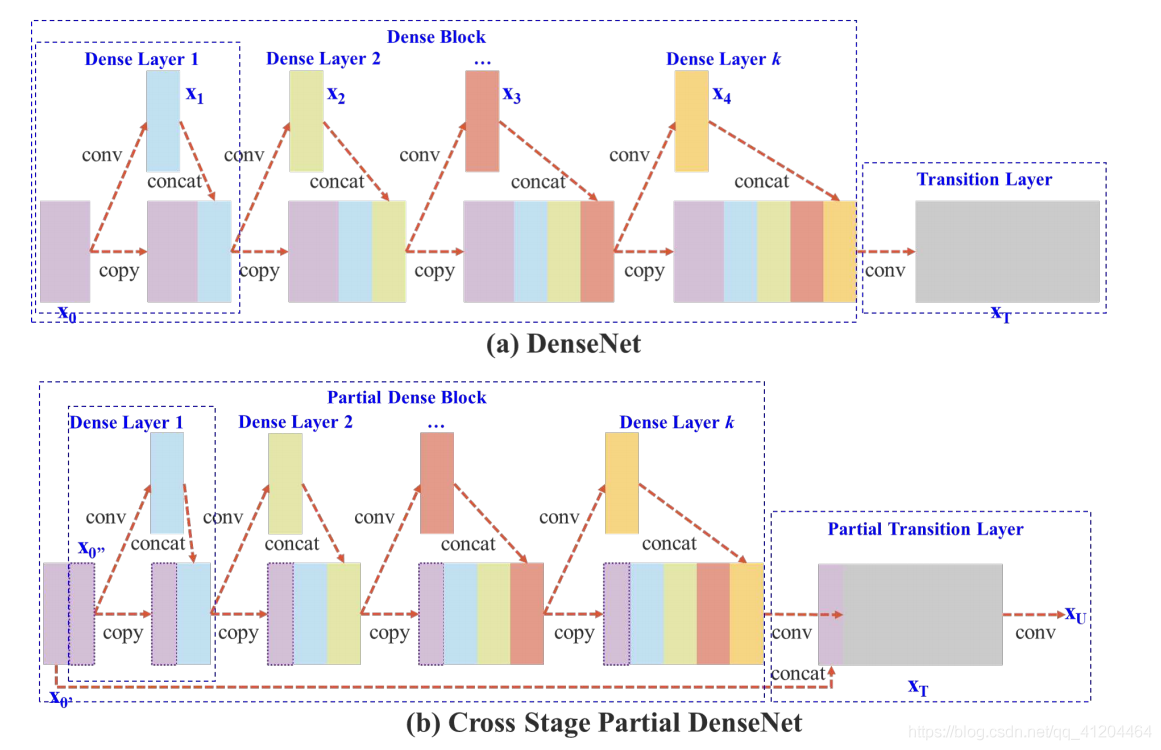
CSPNet實際上是基于Densnet的思想,“復制基礎層的特征映射圖”,通過dense block發送副本到下一個階段,從而將基礎層的特征映射圖分離出來,這樣可以有效緩解梯度消失問題(通過非常深的網路很難去反推丟失信號) ,支持特征傳播,鼓勵網路重用特征,從而減少網路引數數量,
CSPNet 主要從網路結構設計的角度解決推理中“計算量大”的問題,CSPNet 的作者認為推理計算過高的問題是由于“網路優化中的梯度資訊重復”導致的, 因此采用CSP先將基礎層的特征映射劃分為兩部分,然后通過“跨階段層次結構”將它們合并,在減少了計算量的同時可以保證準確率,CSP 連接如下圖所示:
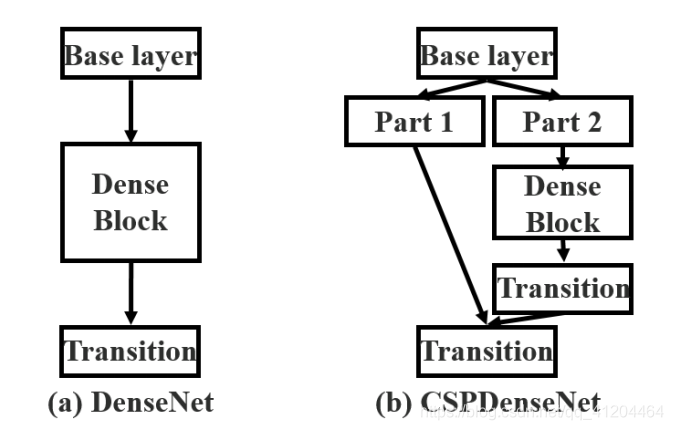
不同型別的特征融合策略: (a) 單路徑 DenseNet;(b) 提出的 CSPDenseNet:轉換 → 串聯 → 轉換,
CSPNet論文地址:CSPNet: A New Backbone that can Enhance Learning Capability of CNN
檢測效果好需要以下幾點:
- 更大的網路輸入解析度——用于檢測小目標
- 更深的網路層——能夠覆寫更大面積的感受野
- 更多的引數——更好的檢測同一影像內不同size的目標
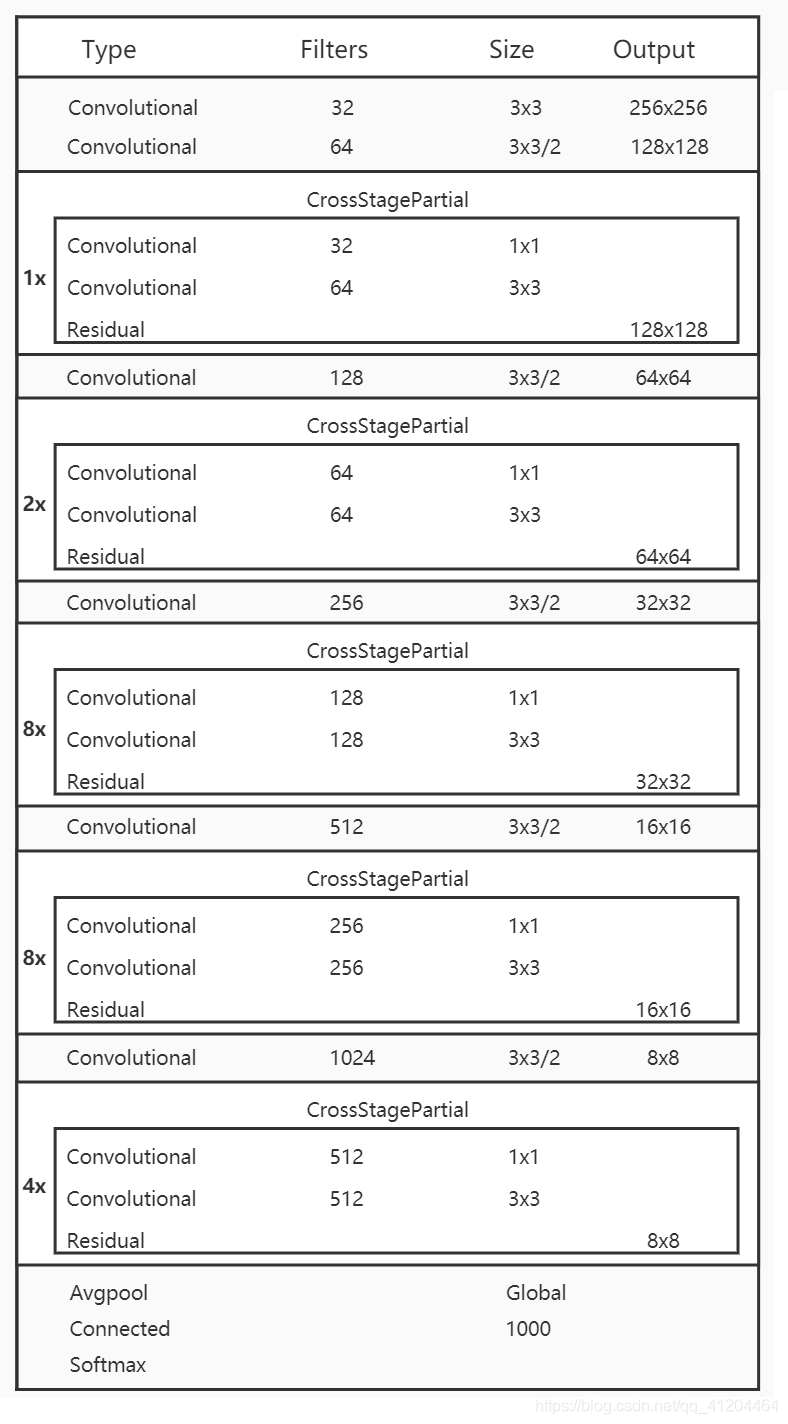
YOLOv4中,選擇了具有CSP的darknet53,而是沒有選擇在imagenet 影像分類上跑分更高的CSPResNext50;因為在目標檢測領域的精度來說,CSPDarknet53是要強于 CSPResNext50,
CSPDarknet53 結構就如下圖:
3.2 Mish激活函式
Mish,是一種激活函式,Mish與ReLU、Swish非常相似,但Mish可以在不同資料集的許多深度網路中勝過它們,Mish公式:
Mish是一個平滑的曲線,平滑的激活函式允許更好的資訊深入神經網路,從而得到更好的準確性和泛化;在負值的時候并不是完全截斷,允許比較小的負梯度流入,
看看Mish、ReLU、SoftPlus 和 Swish 激活函式的圖:
Mish論文地址: https://arxiv.org/pdf/1908.08681.pdf
3.3 Dropblock正則化
正則化技術有助于避免過擬合,對于正則化,已經提出了幾種方法,如L1和L2正則化、Dropout、Early Stopping和資料增強,YOLOv4用了DropBlock正則化的方法,
DropBlock,一種解決模型過擬合的正則化方法,它的作用與Dropout基本相同,Dropout的主要思路是隨機的使網路中的一些神經元失活,從而形成一個新的網路,Dropout是隨機丟棄特征的,它被證明是全連接網路的有效策略,但在特征空間相關的卷積層中效果不佳,
為什么Dropout應用在全連接網路的有效,應用在卷積層中效果不佳呢?
由于卷積層通常是三層結構,即卷積+激活+池化層,池化層本身就是對相鄰單元起作用,因而卷積層對于這種隨機丟棄并不敏感,除此之外,即使是隨機丟棄,卷積層仍然可以從相鄰的激活單元學習到相同的資訊,
DropBlock是“塊的相鄰相關區域中”丟棄特征,即:對整個區域區域進行失活(連續的幾個位置),如下圖:中間的是Dropout處理效果;右邊的是DropBlock處理效果,
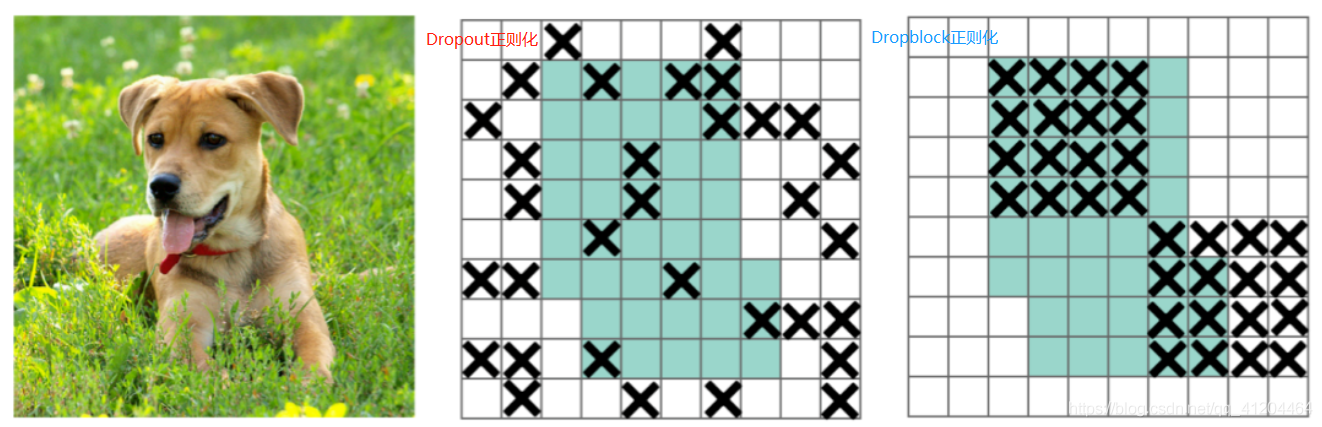
這樣既可以實作生成更簡單模型的目的,又可以在每次訓練迭代中引入學習部分網路權值的概念,對權值矩陣進行補償,從而減少過擬合,
DropBlock論文: https://arxiv.org/pdf/1810.12890.pdf
四、Neck中間層
Neck中間層:這是在BackBone與最后的Head輸出層之間插入的一些層,Yolov4中添加了SPP模塊、FPN+PAN結構,
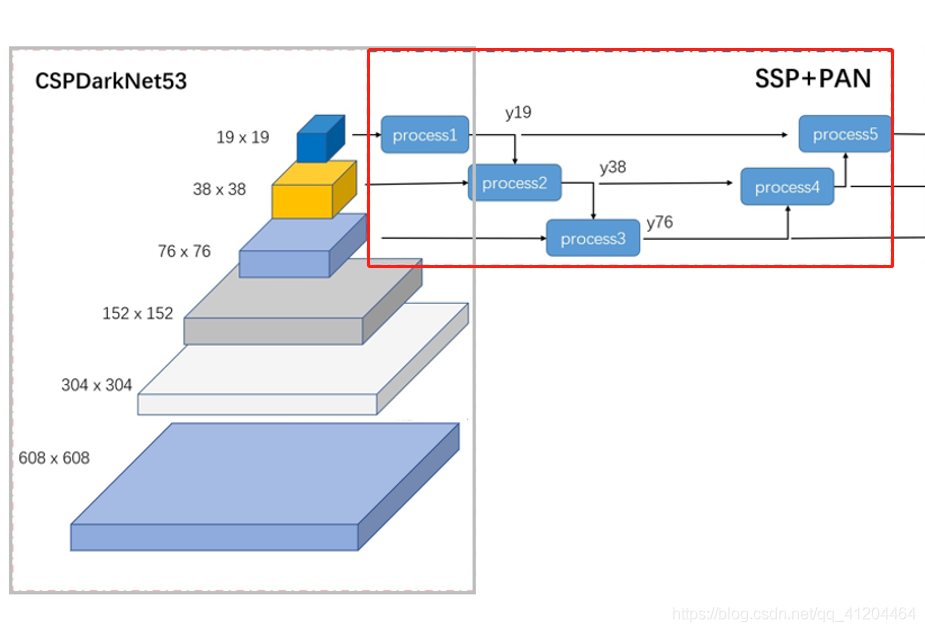
4.1 SPP模塊
SPP,采用1×1、5×5、9×9和13×13的最大池化方式,進行多尺度特征融合,
SPP結構,能融合不同尺度大小的特征圖;用來解決不同尺寸的特征圖如何進入全連接層,對任意尺寸的特征圖直接進行固定尺寸的池化,來得到固定數量的特征,
然后將每個池化得到的特征合起來即得到固定長度的特征個數(特征圖的維度是固定的),接著就可以輸入到全連接層中進行訓練網路了,SPP能增加感受野,
4.2 PAN結構
PANet,全稱Path Aggregation Network;主要用來融合不同尺寸特征圖的特征資訊,
下面首先介紹早期深度學習中的結構、DenseNet結構、FPN結構,最后介紹PAN結構,
在早期深度學習中,模型設計相對簡單,每一層從前一層獲取輸入,淺層提取區域紋理和模式資訊,建立后續層所需的語意資訊,然而,當我們向右移動時,微調預測結果時所需的區域資訊可能會丟失,
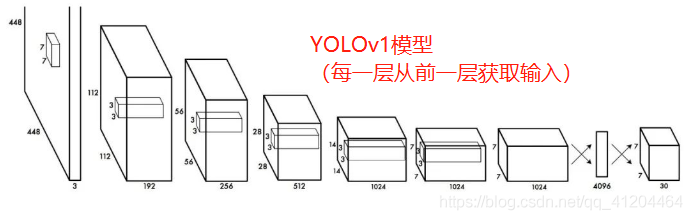
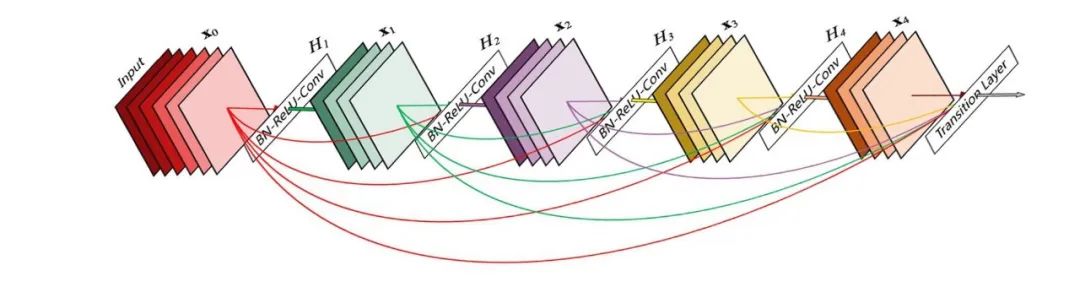
在后來的深度學習發展中,層之間的互相連接變得越來越復雜,在DenseNet,它走到了極致,每一層都與之前的所有層相連,
后面發展到FPN,其全名是Feature Pyramid Networks,中文稱為特征金字塔網路;FPN的預測是在不同特征層獨立進行的,即:同時利用低層特征高解析度和高層特征的高語意資訊,通過融合這些不同層的特征達到預測的效果,
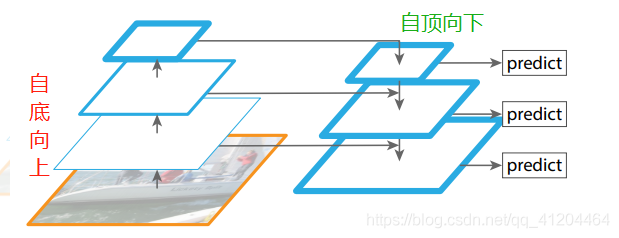
作者認為足夠低層高分辨的特征對于檢測小物體是很有幫助的,
自底向上的程序也稱為下采樣,feature map尺寸在逐漸減小,同時提取到的特征語意資訊逐漸豐富,在下采樣程序中,feature map的大小在經過某些層后會改變,而在經過其他一些層的時候不會改變,作者將不改變feature map大小的層歸為一個stage,因此每次抽取的特征都是每個stage的最后一個層輸出,這樣就能構成特征金字塔,
自頂向下的程序也稱為上采樣(upsampling)進行,而橫向連接則是將上采樣的結果和自底向上生成的相同大小的feature map進行融合(merge),其中,1*1的卷積核減少卷積核的個數,也就是減少feature map的個數,并不改變feature map的尺寸大小,
可以看看這篇文章:FPN 用于目標檢測的特征金字塔網路
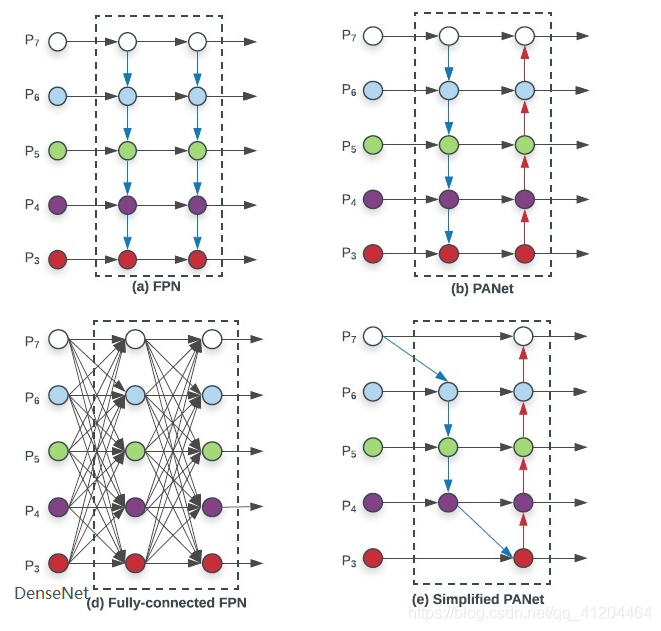
接著發展到了PAN,其全稱Path Aggregation Network;主要用來融合不同尺寸特征圖的特征資訊,先看看下圖:FPN是(a)中網路結構,在此基礎上增加了自底向上的路徑(b),使低層資訊更容易傳播到頂層,
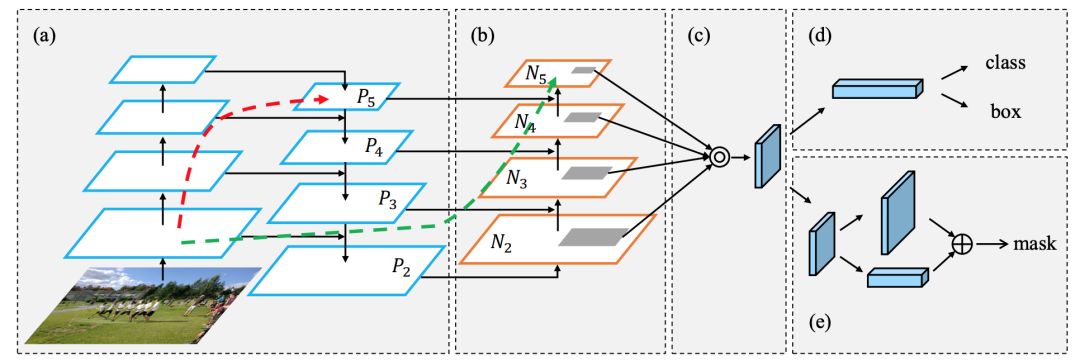
在FPN中,區域空間資訊在紅色箭頭處向上傳遞,雖然圖中沒有清楚地顯示,但紅色的路徑經過了大約100多個層,PAN引入了 short-cut 路徑(綠色通道),只需要大約10層去頂部的N?層,這種short-circuit 的概念使得最上層可以獲得精確的區域資訊,
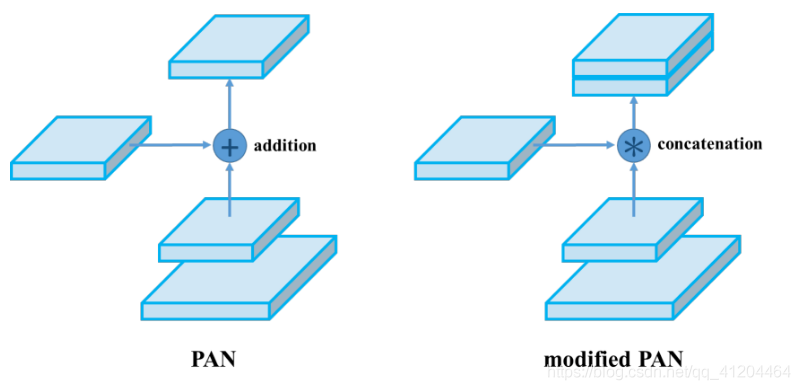
PANet論文中融合的時候使用的方法是Addition,YOLOv4演算法將融合的方法由加法改為Concatenation,即features maps是連接在一起的,如下圖:
Neck連接結構小結:
5、Head輸出層
Head輸出層:輸出層的錨框機制與YOLOv3相同,其中通過聚類提取先驗框尺度,并約束預測邊框的位置,主要改進的是訓練時的損失函式CIOU_Loss,以及預測框篩選的DIOU_nms,
5.1 多尺度特征檢測
模型輸出3種尺度的張量,19*19*255、38*38*255、72*72*255,這里體現了多尺度特征檢測的特點,為什么要輸出3種尺度的張量呢?
低層高分辨的特征 對于檢測小物體是很有幫助的,低層高分辨的特征 對應76*76;(相對于輸出608*608影像,做了8倍下采樣,感受野較小)
高層抽象的特征 適合檢測大物體,高層抽象的特征 對應19*19;(相對于輸出608*608影像,做了32倍下采樣,感受野較大)
38*38 適合檢測一般大小的物體,感受野中等大小,
5.2 輸出維度含義
模型輸出3種尺度的張量,19*19*255、38*38*255、72*72*255,為什么都是輸出255維的呢?
一個網格的維度 = 先驗框數量 *( 坐標x、坐標y、寬度、高度、置信度 + 類別 )
即:255= 3 * (5 + 80)
先驗框數量 在每個尺度的特征圖的每個網格設定3個先驗框,即:每種尺度的輸出張量,都有互不相同的3個先驗框Anchor Boxes;13*13 用來檢測大物體,使用3個尺寸較大的先驗框;52*52 用來檢測小物體,使用3個尺寸較小的先驗框;26*26 用來檢測一般大小物體,使用3個尺寸中等的先驗框,這里一共有9個不同大小的先驗框,
先驗框維度 先驗框中心坐標x、y;框的寬、高;這4個維度用來表達先驗框的位置資訊;還是框的置信度,是表示框內包含物體的概率,一共5維,
類別 如果用COCO資料集訓練,一共有80種物體,
5.3 DIOU_nms損失函式
IOU Loss:考慮檢測框和目標框重疊面積,
GIOU Loss:在IOU的基礎上,解決邊界框不重合時的問題,
DIOU Loss:在IOU的基礎上,考慮邊界框中心距離的資訊,
詳細原理參考:https://blog.csdn.net/qq_37099552/article/details/104464878
https://zhuanlan.zhihu.com/p/104236411
5.4 CIOU_Loss損失函式
CIOU Loss:在DIOU的基礎上,考慮邊界框寬高比的尺度資訊,
六、模型效果
YOLOv4與其他模型對比:
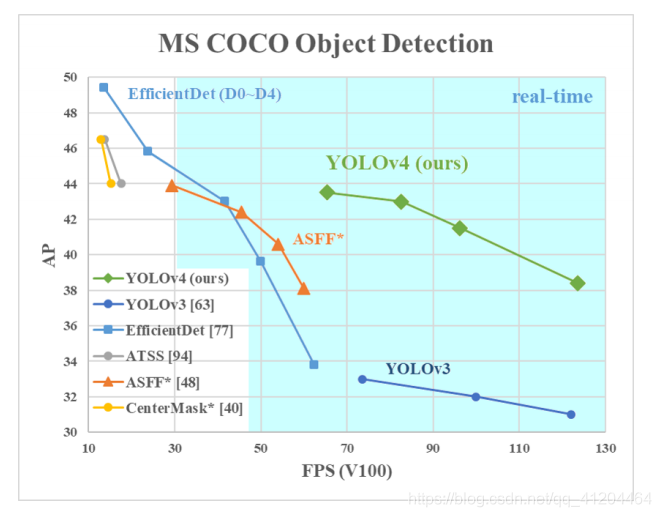
詳細對比參考直接看論文:YOLOv4: Optimal Speed and Accuracy of Object Detection
七、參考文獻
[1] https://cloud.tencent.com/developer/article/1748630
[2] https://zhuanlan.zhihu.com/p/161439809
[3] https://blog.csdn.net/WZZ18191171661/article/details/113765995
[4] YOLOv4: Optimal Speed and Accuracy of Object Detection
[5] Mish論文 https://arxiv.org/pdf/1908.08681.pdf
[6] DropBlock論文: https://arxiv.org/pdf/1810.12890.pdf
[7] FPN 用于目標檢測的特征金字塔網路
Pytorch-YOLOv4 開源代碼:https://github.com/Tianxiaomo/pytorch-YOLOv4
Tensorflow 2-YOLOv4 開源代碼:https://github.com/hunglc007/tensorflow-yolov4-tflite
本篇文章只供參考學習,謝謝,
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/294276.html
標籤:其他