實用模塊及網頁知識拓展
- 一、模擬網站登錄
- 1.cookie及其用法
- 2.session及其用法
- 3.cookies的存取及呼叫
- 二、用程式指揮瀏覽器
- 1.初識selenium
- 2.selenium的使用
- 3.決議網站,提取資料
- 4.文本輸入與模擬點擊
- 三、讓爬蟲學會定時匯報
- 1.schedule的使用方法
- 2.schedule的實戰應用
- i.爬取明天的天氣資訊
- ii.使用QQ郵箱發送郵件
- iii.設定定時資訊
- iv.代碼整合
一、模擬網站登錄
我們已經學會了如何在Network中提取xhr類請求內的資料,接下來要處理更多復雜的問題,首先,在之前的學習中,我們始終沒有涉及到登錄行為,而登錄實際上,很多網站需要登錄才能訪問到我們所需要的資訊,這一節,我們來解決如何登錄的問題,
準備好練習網站,我們開始這次的學習,我們先手動登錄網站,看看登陸之后的樣子,賬號為kaikeba,密碼為kaikeba888,
點擊登錄并滑動至網頁底部:
這里有評價頁面,那么這節我們就以在練習網站發表評論為例,講述如何用python完成登錄以及發表評論,
首先,要用爬蟲工程師的思維思考問題,打開登錄網站之后就要右擊檢查:
這里記得要勾選preserve log(持續顯示請求記錄,防止請求記錄被重繪),然后我們進行登錄,并記錄新增的請求,登陸之后看到請求的變化:
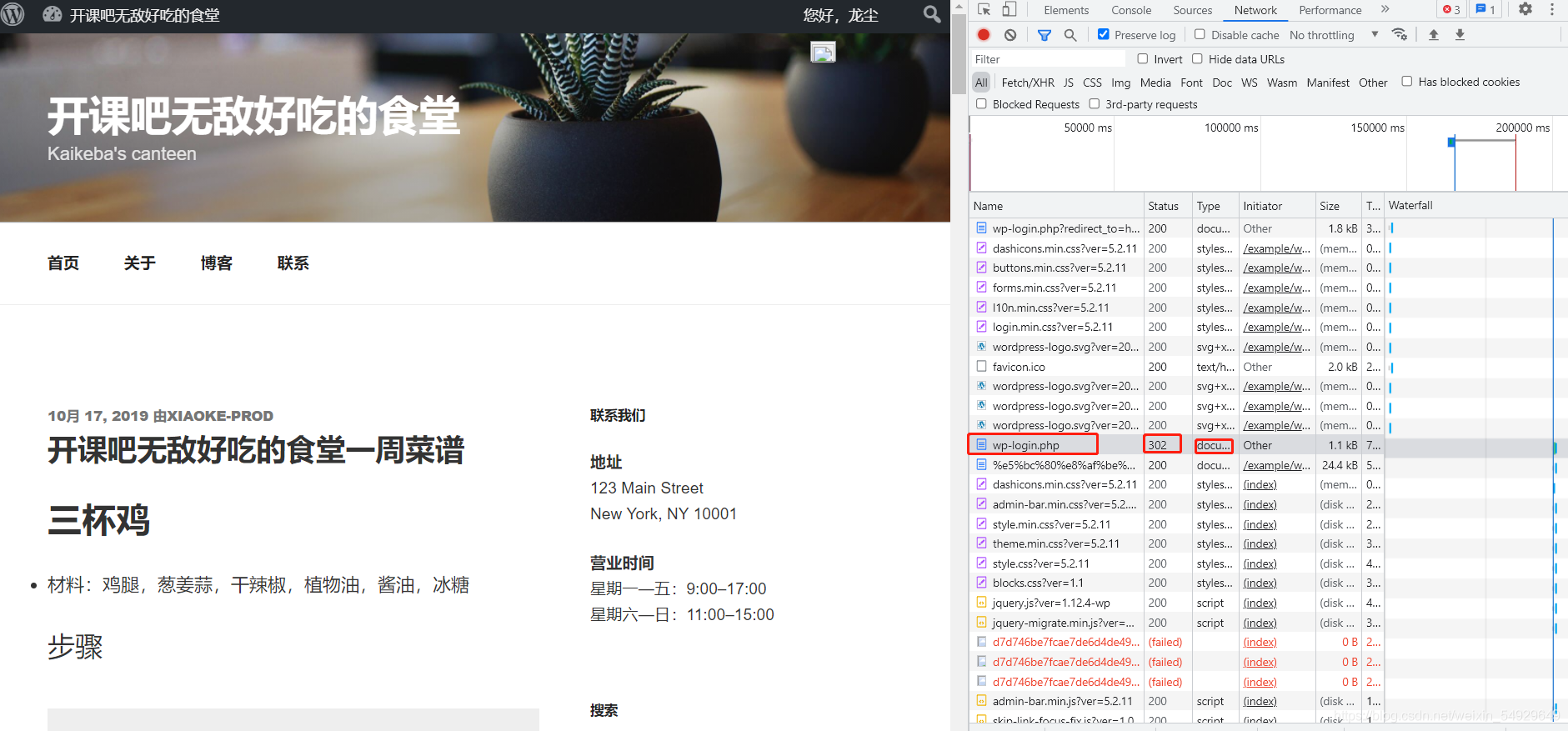
相信大家已經發現了wp-login.php請求1,因為我們可以看到它的狀態碼是302(目標暫時性轉移),而之前我們爬取請求內容的狀態碼都是200,
ps:可以試試雙擊這個請求,看有什么事情發生,
接下來我們查看一下這個請求的headers:

這里的url很短,并沒有出現“#”或“?”來連接附帶引數,并且請求方式也不是之前我們學到的“GET”,而是“POST”,
實際上,POST和GET一樣,都可以帶引數,但是POST不會在url里面顯示出來,這也正是使用POST請求方式的原因,畢竟直接將賬號和密碼暴露在url里很不安全,當然,這兩者的區別更在于get請求會應用于獲取網頁資料,比如我們之前學的 requests.get();而post 請求則應用于向網頁提交資料,比如提交表單型別資料(如賬號密碼),
get 和 post 是兩種最常用的請求方式,除此之外,還有其他型別的請求方式,如 head, options 等,但由于這些都不是很常用,這里就不做介紹了,
get 和 post 這兩種請求方式解釋清楚了,就讓我們繼續往下看:
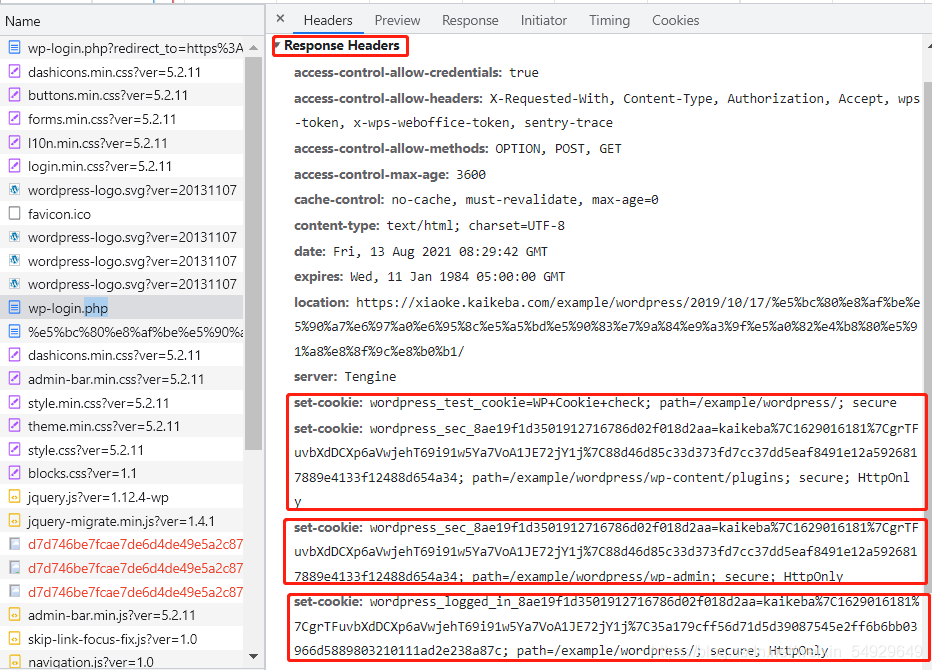
之前我們已經介紹過了headers里的許多引數,只有 response headers還沒有詳細介紹,正如requests headers存盤的是瀏覽器的請求資訊,response headers存盤的是服務器的回應資訊,下面就到了第一個重點內容:cookie,
1.cookie及其用法
cookie其實隨處可見,當我們需要經常性登錄一個網站又不想每次都輸入賬號密碼時,通常會選擇“記住密碼”標識的選項:
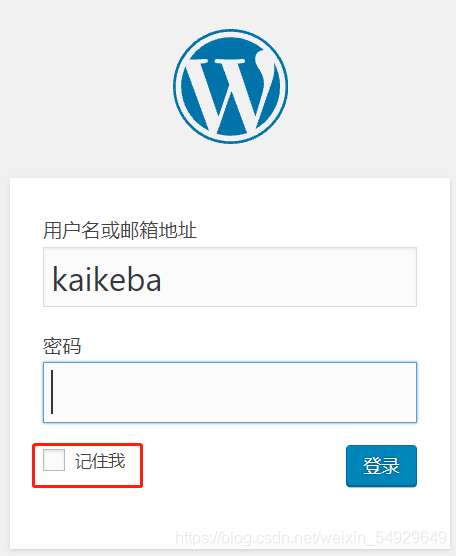
勾選之后,就可以很長時間不用再次輸入密碼或者會直接自動登錄了,這就是cookie在起作用,
如果我們登錄kaikeba賬號并勾選“記住我”,服務器就會生成一個cookie和這個賬號系結,接著會告訴瀏覽器,讓瀏覽器把這個cookie存盤到本地電腦,下一次瀏覽器帶著cookie訪問時,服務器可以直接識別,不需要再次輸入賬號和密碼,
當然,cookie也有時效性,如果長時間未使用或本地存盤的cookie丟失,亦或賬號資訊有所變動,網頁還是需要重新登錄,這就是原來的cookie失效了,
下面我們繼續查看Form Data:
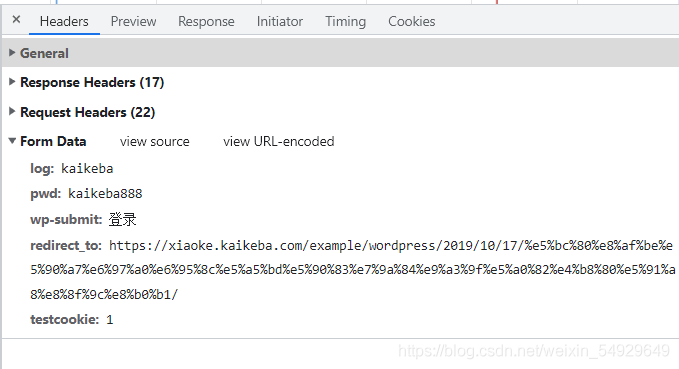
log和pwd 顯然是我們的賬號和密碼,wp-submit是登錄的按鈕,redirect_to 后面帶的鏈接是我們登錄后會跳轉到的頁面網址,但是testcookie暫時還看不出是什么,
既然關于登錄的
引數已經都找到了,我們就先嘗試一下向服務器發起登錄請求:
import requests
url='https://xiaoke.kaikeba.com/example/wordpress/wp-login.php'
headers = {
'User-Agent':
'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.120 Safari/537.36'
}
data={
'log': 'kaikeba',
'pwd': 'kaikeba888',
'wp-submit': '登錄',
'redirect_to': 'https://xiaoke.kaikeba.com/example/wordpress/2019/10/17/%e5%bc%80%e8%af%be%e5%90%a7%e6%97%a0%e6%95%8c%e5%a5%bd%e5%90%83%e7%9a%84%e9%a3%9f%e5%a0%82%e4%b8%80%e5%91%a8%e8%8f%9c%e8%b0%b1/',
'testcookie': '1'
}
log_in=requests.post(url,headers=headers,data=data)
# .post()和.get()方法的用法很類似,參考get()的用法寫代碼即可
print(log_in.status_code)
# 結果為:200
看到這個狀態碼,意味著服務器接收到并回應了登錄請求,我們已經登錄成功,接下來我們就開始研究怎么進行評論,
我們要利用程式來發表評論,就要先來發表一次評論,觀察請求欄會有什么變化,首先清空請求欄,然后發表一條評論觀察:
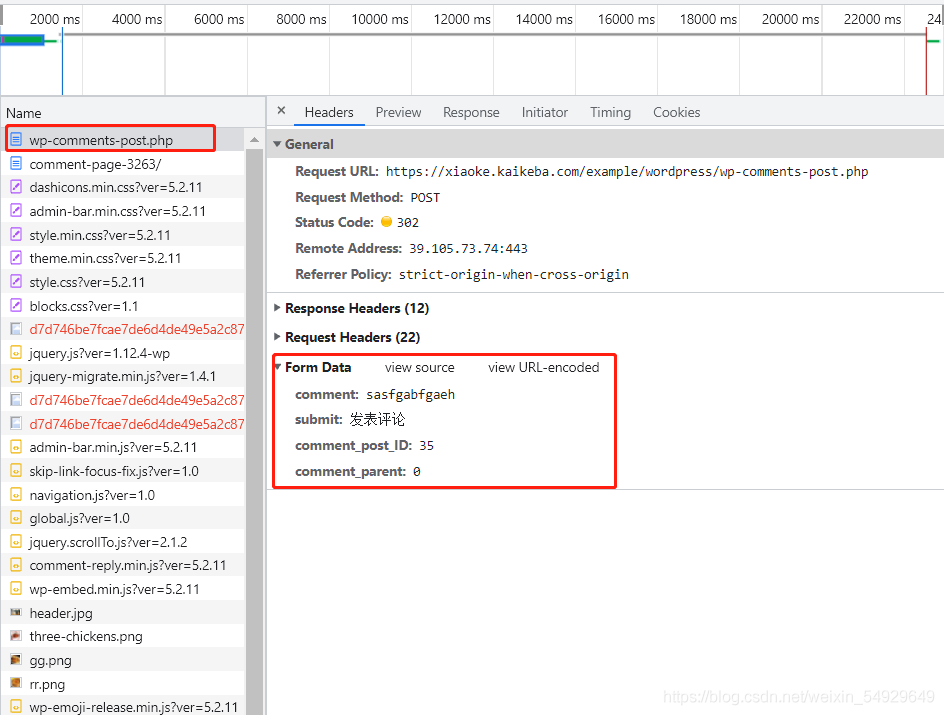
重新加載出來的請求里,wp-comments-post.php的Form Data的內容已經更新出我們剛剛發表評論的內容了,comment的內容對應我們剛剛發表的評論內容,submit對應發表評論按鈕,另外兩個引數看不太懂,不過也沒關系,它們都是和評論有關的引數,所以直接照抄就好,
細看之下還會發現,wp-comments-post.php的資料并沒有藏在 XHR 中,而是放在了Other 里,但常規情況下,大部分網站都會把這樣的資料存盤在 XHR 里,比如知乎的回答,
現在我們回憶一下發表評論的程序:首先得登錄,其次得提取和呼叫登錄的 cookie,然后還需要評論的引數,才能發起評論的請求,
現在,我們就只差提取和呼叫登錄的 cookie了,而cookie是每個requests物件的屬性,可以使用requests物件.cookie的方式查到:
import requests
url='https://xiaoke.kaikeba.com/example/wordpress/wp-login.php'
headers = {
'User-Agent':
'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.120 Safari/537.36'
}
data={
'log': 'kaikeba',
'pwd': 'kaikeba888',
'wp-submit': '登錄',
'redirect_to': 'https://xiaoke.kaikeba.com/example/wordpress/2019/10/17/%e5%bc%80%e8%af%be%e5%90%a7%e6%97%a0%e6%95%8c%e5%a5%bd%e5%90%83%e7%9a%84%e9%a3%9f%e5%a0%82%e4%b8%80%e5%91%a8%e8%8f%9c%e8%b0%b1/',
'testcookie': '1'
}
log_in=requests.post(url,headers=headers,data=data)
# 以下是新增代碼
cookie = log_in.cookies
# 提取 cookie 的方法:呼叫 requests 物件(log_in)的cookie屬性獲得登錄的cookie并保存
url_comment = 'https://xiaoke.kaikeba.com/example/wordpress/wp-comments-post.php'
# 我們想要評論的文章網址
data_comment = {
'comment': input('請輸入你想要發表的評論:'),
'submit': '發表評論',
'comment_post_ID': '35',
'comment_parent': '0'
}
# 把有關評論的引數封裝成字典
comment = requests.post(url_comment,headers=headers,data=data_comment,cookies=cookie)
# 用 requests.post 發起發表評論的請求,放入引數:文章網址、headers、評論引數、cookie 引數,賦值給 comment
# 呼叫 cookie 的方法就是在post請求中傳入cookies = cookie的引數
print(comment.status_code)
# 列印出 comment 的狀態碼,若狀態碼等于 200,則證明我們評論成功
運行這段代碼,我們可以輸入“下面我們嘗試發表評論”,觀察運行結果:
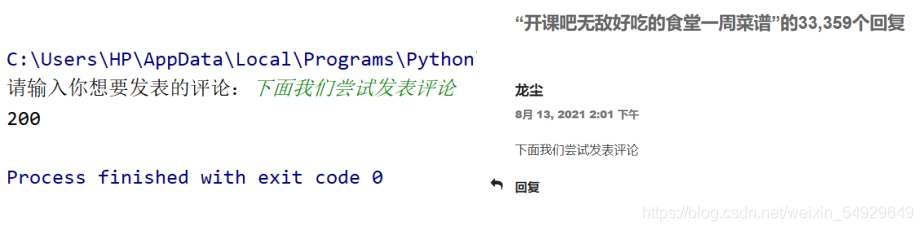
到這里我們已經成功發表了評論,但是專案并沒有結束,這個代碼還有優化空間,
注:這個網站不能發送重復的評論,大家練習的時候記得換評論內容
2.session及其用法
session,中文意會話,所謂會話,可以理解為我們用瀏覽器上網,到關閉瀏覽器的這一程序,
我們這里要學習的session,實際作用是幫助我們記錄會話程序中,服務器用來記錄特定用戶會話的資訊,舉個例子,如果沒有 session,可能會出現這樣搞笑的情況:淘寶購物車添加了很多商品,但在想要結算時,卻發現購物車空無一物,因為服務器根本沒有幫你記錄你想買的商品,
session和cookie的關系十分密切,因為cookie中存盤著session的編碼資訊,session中又存盤了cookie的資訊,
以訪問購物網頁為例,當瀏覽器第一次訪問時,服務器會回傳set cookie的欄位給瀏覽器,瀏覽器會把cookie保存到本地;等瀏覽器第二次訪問這個購物網頁時,就會帶著 cookie 去請求,而cookie里帶有session的編碼資訊,服務器立馬就能辨認出這個用戶,同時回傳和這個用戶相關的特定編碼的 session,盡管存放在本地的cookie會有很多種可能失效,但是服務器里存盤的cookie會一直保存session的編碼資訊,無論是更改密碼,還是長時間未登陸等情況,都幾乎不會丟失,
正因如此,我們每次重新登錄購物網站后,即使cookie存盤的內容(如密碼)有所變化,只要session的編碼資訊沒變,都還是可以找到保存在購物車中的商品,
session介紹完了,下面就來說如何優化代碼,由于cookie和session的關系密切,我們來查查可不可以通過創建一個 session 來處理 cookie:
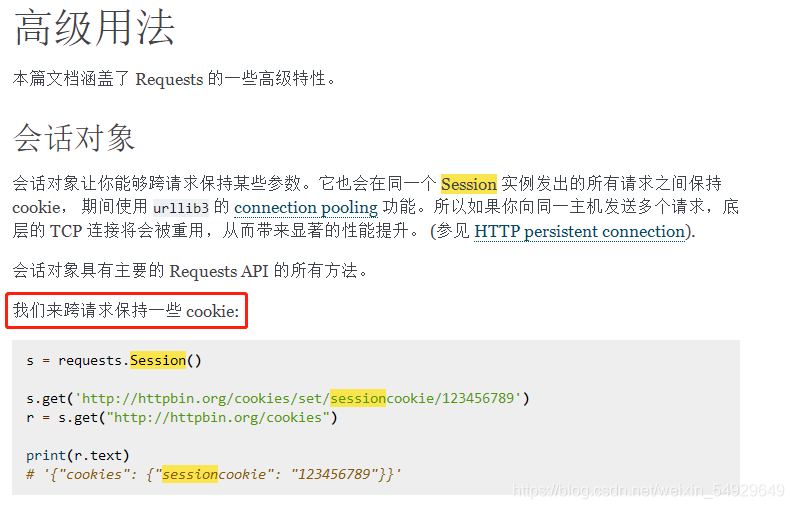
在 requests 的高級用法里,真有這樣的方法~那么下面我們就實戰一下:
import requests
session = requests.session()
# 用 requests.session()創建session 物件,它可以幫幫我們自動保持了cookie
url_login='https://xiaoke.kaikeba.com/example/wordpress/wp-login.php'
# 登陸頁面網址
headers = {
'User-Agent':
'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.120 Safari/537.36'
}
data_login = {
# 用input函式實作輸入賬號,可以登錄不同賬號
'log': input('請輸入賬號:'),
'pwd': input('請輸入密碼:'),
'wp-submit': '登錄',
'redirect_to':'https://xiaoke.kaikeba.com/example/wordpress/2019/10/17/%e5%bc%80%e8%af%be%e5%90%a7%e6%97%a0%e6%95%8c%e5%a5%bd%e5%90%83%e7%9a%84%e9%a3%9f%e5%a0%82%e4%b8%80%e5%91%a8%e8%8f%9c%e8%b0%b1/',
'testcookie': '1'
}
# Form Data資訊
session.post(url_login, headers=headers, data=data_login)
# 在創建的session下用post發起登錄請求,放入引數:請求登錄的網址、請求頭和登錄引數,
# session.post和requests.post用法一樣,只是不再需要手動傳參cookie
url_comment='https://xiaoke.kaikeba.com/example/wordpress/wp-comments-post.php'
# 把我們想要評論的文章網址賦值給 url_comment
data_comment = {
# 把有關評論的引數封裝成字典
'comment': input('請輸入你想要發表的評論:'),
'submit': '發表評論',
'comment_post_ID': '35',
'comment_parent': '0'
}
# 在創建的 session 下用 post 發起評論請求,放入引數:文章網址,請求頭和評論引數,并賦值給 comment
comment=session.post(url_comment, headers=headers, data=data_comment)
# 列印 comment
print(comment)
請大家自己運行,可以看到程式會列印出我們評論的內容的,這也說明呼叫.post()方法會回傳我們評論的內容,
這段代碼可以自己提取cookie,也就意味著不需要先登錄獲取cookies再登錄進行評論,可以只登錄一次就完成評論,是不是簡單了一些?但還不夠理想,我們能不能將cookie存在指定位置,然后每次直接自動登錄,發表評論呢?
3.cookies的存取及呼叫
①cookies的存盤
下面我們就來探討如何把cookie保存到指定位置,完成第一次登錄后,每一次都進行自動登錄,
我們先來看看cookie的內容和型別:
import requests
url='https://xiaoke.kaikeba.com/example/wordpress/wp-login.php'
headers = {
'User-Agent':
'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.120 Safari/537.36'
}
data={
'log': 'kaikeba',
'pwd': 'kaikeba888',
'wp-submit': '登錄',
'redirect_to': 'https://xiaoke.kaikeba.com/example/wordpress/2019/10/17/%e5%bc%80%e8%af%be%e5%90%a7%e6%97%a0%e6%95%8c%e5%a5%bd%e5%90%83%e7%9a%84%e9%a3%9f%e5%a0%82%e4%b8%80%e5%91%a8%e8%8f%9c%e8%b0%b1/',
'testcookie': '1'
}
log_in=requests.post(url,headers=headers,data=data)
cookie=log_in.cookies
print(cookie)
print(type(cookie))
cookie的內容我們看不懂,只是覺得有點像字典,這沒有什么影響,但是這個型別有點令人頭疼,我們可以將str型別的資料寫入.txt檔案,但這里的資料型別卻是 ‘requests.cookies.RequestsCookieJar’,
如何保存這種型別的資料,相信大家已經回想起之前我們學過的json模塊了,或許我們可以先把 cookie 轉成字典,然后再通過 json 模塊轉成字串,
當然我們想要使用資料的時候還需要先把字串轉化成字典,然后再轉化為’RequestsCookieJar’型別,有json模塊,字典和str型別的相互轉化好說,但是怎么完成’RequestsCookieJar’型別與字典型別的雙向轉化呢?

這個方法引發了博主的一些思考,我們看代碼:
import requests
import json
session=requests.session()
url='https://xiaoke.kaikeba.com/example/wordpress/wp-login.php'
headers = {
'User-Agent':
'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.120 Safari/537.36'
}
data = {
'log': 'kaikeba',
'pwd':'kaikeba888',
'wp-submit': '登錄',
'redirect_to':
'https://xiaoke.kaikeba.com/example/wordpress/2019/10/17/%e5%bc%80%e8%af%be%e5%90%a7%e6%97%a0%e6%95%8c%e5%a5%bd%e5%90%83%e7%9a%84%e9%a3%9f%e5%a0%82%e4%b8%80%e5%91%a8%e8%8f%9c%e8%b0%b1/',
'testcookie': '1'
}
session.post(url, headers=headers, data=data)
cookie_dict=requests.utils.dict_from_cookiejar(session.cookies)
# 把 cookie 轉化成字典
print(type(cookie_dict))
# 查看cookie_dict型別
cookie_str = json.dumps(cookie_dict)
# 呼叫 json 模塊的 dumps 函式,把 cookie 從字典再轉成字串
print(type(cookie_str))
# 查看cookie_str是否轉化成了str型別
with open('cookie.txt', 'w+') as f:
f.write(cookie_str)
# 把已經轉成字串的cookie寫入檔案
f.seek(0)
# 移動檔案指標,查看內容
print(f.read())
運行一下,和剛才的結果對比,cookie的文字內容沒有變化但是型別已經成功地由’RequestsCookieJar’轉化為字典,進而轉化為str并被保存起來了,
②cookies的讀取
接下來我們研究這個程序的逆程序,剛剛將cookies轉化為字典型別的方法是:
dict_=requests.utils.dict_from_cookiejar()
# 從cookiejar轉化為dict
那么將字典轉化成cookies原有格式的方法也比較類似:
cookies=requests.utils.cookiejar_from_dict()
# 從dict轉化為cookiejar
接下來,我們將剛保存的txt檔案打開并將資料還原成RequestsCookieJar型別:
import requests
import json
with open('cookie.txt','r') as f:
con=f.read()
cookies_dict=json.loads(con)
# 將con內容由字串轉化為字典型別
print(type(cookies_dict))
# 查看轉換是否成功
cookies_jar=requests.utils.cookiejar_from_dict(cookies_dict)
print(cookies_jar,'\n',type(cookies_jar))
# 輸出為:<class 'dict'>
# <RequestsCookieJar[<Cookie ... for />, <Cookie .. for />, <Cookie.. for />]>
# <class 'requests.cookies.RequestsCookieJar'>
經過檢查,輸出的內容和其型別和我們最初直接從網頁上獲取的一致,我們成功完成了cookies的存取,
③cookies的呼叫
之前我們已經可以存盤和讀取cookies了,下面我們學著使用存盤的cookies登錄網頁發表評論,撰寫代碼之前,我們先梳理一下代碼執行的程序:
(i)嘗試讀取cookies并登錄網站,成功則執行(iii),讀取到的cookies過期或沒有讀取到cookies執行(ii)
(ii)進入登錄頁面進行登錄并存盤cookies
(iii)發表評論
下面撰寫代碼:
import requests,json
session=requests.session()
headers = {
'User-Agent':
'Mozilla/5.0 (Windows NT 6.1; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.120 Safari/537.36'
}
def cookies_read():
# 封裝函式用以讀取cookies
with open('cookie.txt', 'r') as f:
con=f.read()
cookies_dict=json.loads(con)
return(requests.utils.cookiejar_from_dict(cookies_dict))
def sign_in():
# 沒有讀取到cookies或cookies已過期
url='https://xiaoke.kaikeba.com/example/wordpress/wp-login.php'
data_login = {
'log': input('請輸入你的賬號:'),
'pwd': input('請輸入你的密碼:'),
# 設定成可以手動輸入登錄資訊
'wp-submit': '登錄',
'redirect_to':
'https://xiaoke.kaikeba.com/example/wordpress/2019/10/17/%e5%bc%80%e8%af%be%e5%90%a7%e6%97%a0%e6%95%8c%e5%a5%bd%e5%90%83%e7%9a%84%e9%a3%9f%e5%a0%82%e4%b8%80%e5%91%a8%e8%8f%9c%e8%b0%b1/',
'testcookie': '1'
}
session.post(url, headers=headers, data=data_login)
# 嘗試登錄并評論
# cookie存盤
cookie_dict=requests.utils.dict_from_cookiejar(session.cookies)
# 轉化為字典
cookie_str = json.dumps(cookie_dict)
# 轉化為json字串
with open('cookie.txt', 'w') as f:
f.write(cookie_str)
# 已經登錄成功,進行評論的發表
def write_message():
url_comment = 'https://xiaoke.kaikeba.com/example/wordpress/wp-comments-post.php'
# 記錄評論所需要的網址
data_comment = {
'comment': input('請輸入你要發表的評論:'),
'submit': '發表評論',
'comment_post_ID': '35',
'comment_parent': '0'
}
return (session.post(url_comment, headers=headers, data=data_comment))
# 進行評論并回傳評論內容
# 主函式
try: # 獲取cookies
session.cookies = cookies_read()
except :
sign_in()
session.cookies = cookies_read()
comment=write_message()
if comment.status_code == 200:
print('成功啦!')
else: # 防止之前存盤的cookies過期
print('存盤的cookies過期,需要重新登錄!')
sign_in()
session.cookies = cookies_read()
comment = write_message()
這段代碼需要進行三次測驗,首先直接運行,看能否發表評論;然后更改cookie.txt檔案內容(注意要保證字典的完整性,不能只洗掉某一個鍵或值等,否則會報錯)再運行,運行之后觀察cookie.txt檔案內容是否和修改之前一樣;然后洗掉這個檔案再運行一次,三次都成功運行則代碼沒有問題,當然,想要清楚地看到代碼運行程序的小伙伴可以使用debug進行單步運行:
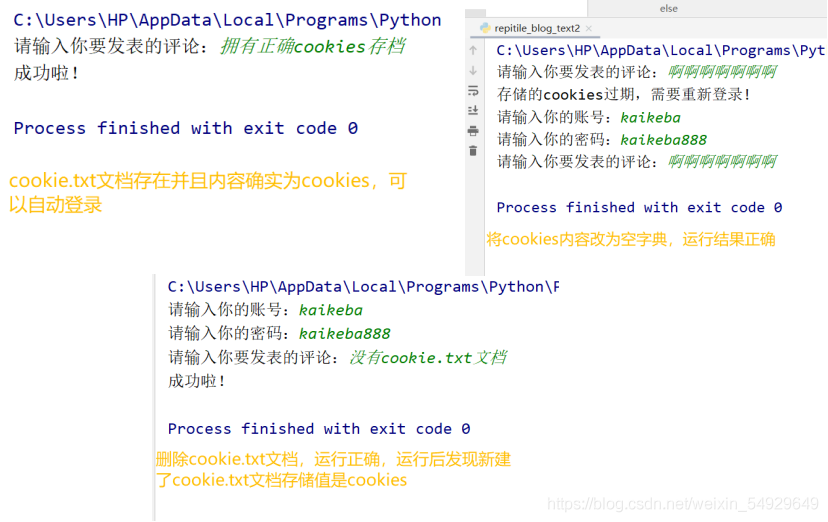
這個樣子說明我們已經運行成功了,這才是我們優化代碼的最終版,
我們已經發過的評論就不能再發了,小伙伴們練習的時候記得換評論內容,
二、用程式指揮瀏覽器
上一節我們已經介紹了網頁登錄,但是有些網站的登錄驗證碼很難破解,還有的網站對URL的加密邏輯很復雜,像之前爬過的五月天歌曲串列,URL的引數變數比較難找,通常這樣的情況下,想要攻破反爬技識訓有些難度,下面我們就來介紹一款新的武器:
1.初識selenium
selenium是一個強大的 Python 庫,使用selenium后可以看到瀏覽器自動打開、輸入、點擊等操作,很像我們在操作瀏覽器,
我們撰寫的程式遇到驗證碼很復雜的網站時,selenium 可以使用延時函式暫停運行,進而讓人工介入,手動輸入驗證碼,然后把剩下的操作交給程式去完成,
同時,對于那些互動復雜、加密復雜的網站,requests.get()函式爬取不到全部的網頁代碼,只能在Network里尋找對應請求,歸根結底,這是因為沒有真正打開網站的時候,很多請求是不會由瀏覽器向服務器發起,但selenium可以真正的打開一個網站,向服務器發出并完成所有請求后,將它們一起組成開發者工具的Elements中所展示的樣子,也因此使用selenium爬取網站的內容時不必尋找請求源,而是可以直接在Elements中爬取內容,爬動態網頁如爬靜態網頁2一樣簡單,
當然,selenium也有自己的缺點,由于要真實地運行本地瀏覽器,打開瀏覽器以及等待網渲染完成需要一些時間,selenium的作業不可避免地犧牲了爬取速度和更多資源,不過,肯定還是要比手動的操作快很多,
2.selenium的使用
以上說了很多文字內容,多少有些難以理解,因此我們接下來一起學習selenium的使用,那么,和其它所有Python庫一樣,需要安裝selenium,當然只有標準庫還不夠,我們想要讓代碼操作瀏覽器還需要安裝驅動,
安裝完成之后,先運行一下下面的代碼,體會一下selenium的神奇之處:
from selenium import webdriver
import time
driver = webdriver.Chrome()
driver.get('https://xiaoke.kaikeba.com/example/X-Man/')
time.sleep(2)
teacher = driver.find_element_by_id('teacher')
teacher.send_keys('1')
assistant = driver.find_element_by_name('assist')
assistant.send_keys('2')
time.sleep(2)
button = driver.find_element_by_tag_name('button')
time.sleep(1)
button.click()
time.sleep(5)
driver.close()
首先我們看到的是【你好,X戰警】幾個大字,一秒之后,它會自動跳轉到一個新的頁面,請你輸入最喜歡的老師和助教,點擊提交之后,就能看到一個關于爬蟲的課程表,仔細看會發現,在這個程序中,網頁URL一直沒有變化,可見這是個動態網頁,
代碼運行完之后,我們手動登錄剛剛的網站,執行一下同樣的操作試試看,
下面我們開始代碼的講解:
from selenium import webdriver
# 從 selenium 庫中呼叫 webdriver 模塊
driver = webdriver.Chrome()
# 設定引擎為 Chrome,真實地打開一個 Chrome 瀏覽器
driver 是實體化的瀏覽器,后面也會經常出現,因為我們要控制這個實體化的瀏覽器為我們做一些事情,
driver.get('https://xiaoke.kaikeba.com/example/X-Man/')
# 打開網頁
time.sleep(3)
# 延時,讓計算機加載全部請求,這個時間可以依據計算機性能的不同而自行設定
driver.close()
# 關閉瀏覽器
driver.get(URL) 是 webdriver 的一個方法可以打開指定的網頁,使用的瀏覽器,就是剛剛實體化的瀏覽器,這個網頁被打開后,網頁的全部資料就會加載到瀏覽器中,也就都可以被我們獲取到了,driver.close() 是關閉瀏覽器驅動,每次打開瀏覽器后都需要關閉,否則會占用系統記憶體,當然,打開的瀏覽器也可以手動關閉,不過瀏覽器關閉之后代碼就不能獲取網頁的資訊了,因此想要手動關閉的小伙伴一定要記得在代碼運行完后進行關閉,
3.決議網站,提取資料
與BeautifulSoup庫類似,selenium 庫同樣也具備決議資料、提取資料的能力,他們的底層原理一致,只是一些細節和語法上有所出入,首先明顯的一個不同就是selenium所決議提取的,是Elements中的所有資料,而BeautifulSoup所決議的則只是Network中第 0 個請求的回應,
下面就讓我們通過使用 selenium 來提取【你好,X戰警】網頁中,
from selenium import webdriver
import time
driver=webdriver.Chrome()
driver.get('https://xiaoke.kaikeba.com/example/X-Man/')
time.sleep(3)
label=driver.find_element_by_tag_name('label')
# 呼叫wbdriver的專有查找方法
print(label.text)
print(type(label))
driver.close()
# 運行結果:提示:(小K老師)
# <class 'selenium.webdriver.remote.webelement.WebElement'>
從這個結果中可以看出想要提取到的label標簽名對應的第一個元素的文字內容,其實不難發現,決議代碼是由driver實體打開網頁時自動完成的,提取資料則是driver實體的一個方法:.find_element_by_tag_name(),
當然,webdriver自帶的查找方法有很多,并不只局限于依據標簽提取內容,還有非常直截了當的方法:
| 方法 | 作用 |
|---|---|
| found_element_by_id() | 通過元素id查找 |
| found_element_by_class_name() | 通過元素class查找 |
| found_element_by_tag_name() | 通過元素標簽名查找 |
| found_element_by_name() | 通過元素內容查找 |
| found_element_by_partial_link_text() | 通過文本的內容查找標簽中含有的超鏈接 |
| found_element_by_link_text() | 通過文本的部分內容查找標簽中含有的超鏈接 |
下面我們進行舉例說明:
# driver為實體化的瀏覽器,已經使用.get()方法打開需要提取內容的網站
# find_element_by_tag_name:通過元素的名稱選擇
# 如: <h1>你好,X戰警</h1>
driver.find_element_by_tag_name('h1')
# find_element_by_class_name:通過元素的 class 屬性選擇
# 如: <h1 class="title">你好,X戰警</h1>
driver.find_element_by_class_name('title')
# find_element_by_id:通過元素的 id 選擇
# 如 :<h1 id="title">你好,X戰警</h1>
driver.find_element_by_id('title')
# find_element_by_name:通過元素的 name 屬性選擇
# 如 <h1 name="hello">你好,X戰警</h1>
driver.find_element_by_name('hello')
# find_element_by_link_text:通過鏈接文本獲取超鏈接
# 如 <a href="spidermen.html">你好,X戰警</a>
driver.find_element_by_link_text('你好,X戰警')
# find_element_by_partial_link_text:通過鏈接的部分文本獲取超鏈接
# 如 <a href="https://xiaoke.kaikeba.com/example/X-Man/">你好,X戰警</a>
driver.find_element_by_partial_link_text('你好')
以上方法均只能提取第一個元素,需要提取全部元素時,將“element”改為“elements”即可,提取出的元素型別為:WebElement,這個型別與Tag類似,也有一個屬性為.text,用于把提取出的元素用字串格式顯示;并且它也有一個方法.get_attribute(),可以通過屬性名提取屬性的值,
| WebElement | Tag | 作用 |
|---|---|---|
| .text | .text | 獲取文字內容 |
| .get_attribute() | [’’] | 依據屬性名獲取屬性值 |
舉個例子介紹這個屬性:
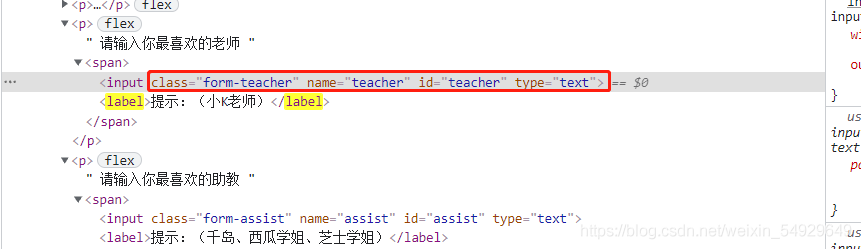
假如我們想找到type對應的值:
from selenium import webdriver
import time
driver = webdriver.Chrome()
driver.get('https://xiaoke.kaikeba.com/example/X-Man/')
time.sleep(2)
label = driver.find_element_by_class_name('form-teacher')
print(type(label))
print(label.get_attribute('type'))
# 獲取type屬性的值
driver.close()
# 結果為:<class 'selenium.webdriver.remote.webelement.WebElement'>
# text
那么,有的小伙伴可能會說,我已經習慣使用.find()和.find_all()來提取內容了,selenium提取的內容可以用BeautifulSoup決議嗎?
當然可以了,下面我們就介紹一下selenium如何與BeautifulSoup愉快合作,webdriver有一個方法page_source,可以獲取到渲染完整的網頁代碼,我們只需要使用該方法將獲取到的網頁源代碼交給BeautifulSoup來決議就好了,上代碼:
from selenium import webdriver
import time
from bs4 import BeautifulSoup as bs
driver = webdriver.Chrome()
driver.get('https://xiaoke.kaikeba.com/example/X-Man/')
time.sleep(2)
p=driver.page_source
# 獲取到渲染完整的網頁源代碼,這種方式獲取到的內容已經是
# str型別,可以直接給BeautifulSoup決議,
page_source=bs(p,'html.parser')
want = page_source.find_all('span')[1].find('input')
print(type(want))
print(want)
print(want['type'])
# 獲取type屬性的值
driver.close()
# 輸出為:<class 'bs4.element.Tag'>
# <input class="form-teacher" id="teacher" name="teacher" type="text"/>
# text
很好,我們已經學會了selenium與BeautifulSoup合作了,那么接下來給大家重點解釋一下這句代碼:
want = page_source.find_all('span')[1].find('input')
首先,使用.find_all()找到的內容為一個串列,里面每個元素的型別均為Tag,
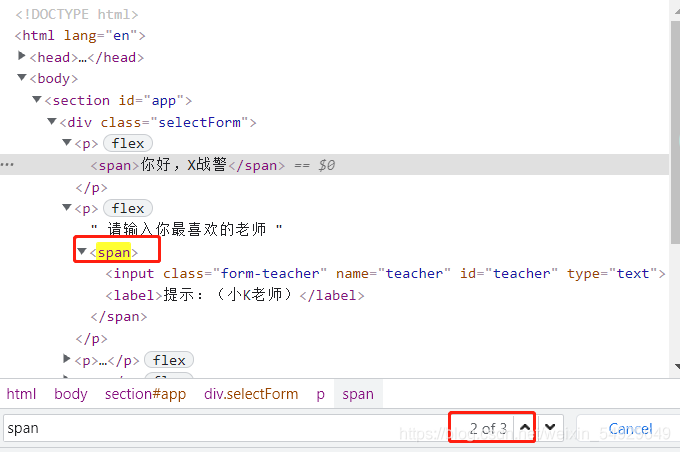
從這張圖中不難發現,我們想找的標簽在第二個span標簽下,因此我們需要使用.find_all()找到所有的span標簽,并鎖定這個串列中第二個(下標為1的)元素,然后再尋找input標簽,當然,這里有很多更簡單的方法找到我們想要的內容,故意選擇這種方法只是和大家分享一下這種用法,
4.文本輸入與模擬點擊
上面我們已經把提取內容講解的十分清楚了,接下來繼續講解如何利用代碼向網頁輸入內容并進行模擬點擊,
現給大家介紹我們會用到的方法:
| 方法 | 作用 |
|---|---|
| .clear() | 清除元素的所有內容 |
| .send_keys() | 模擬鍵盤輸入,引數為需要輸入的內容 |
| .click() | 模擬點擊元素 |
我們可以通過之前介紹的方法找到需要填寫內容的位置:
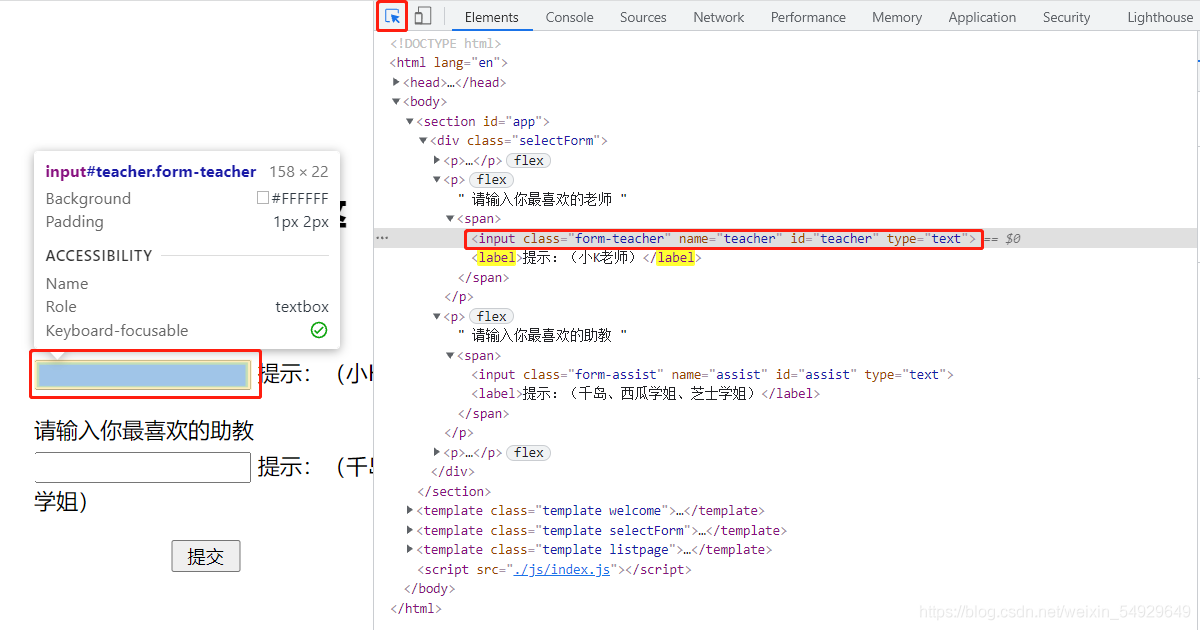
找到后我們就開始實踐:
from selenium import webdriver
import time
driver = webdriver.Chrome()
# 設定引擎為 Chrome,真實地打開一個 Chrome 瀏覽器
driver.get('https://xiaoke.kaikeba.com/example/X-Man/')
# 訪問頁面
# 暫停兩秒,等待瀏覽器緩沖
time.sleep(2)
# 暫停兩秒,等待瀏覽器緩沖
teacher = driver.find_element_by_id('teacher')
# 找到【請輸入你喜歡的老師】下面的輸入框位置
teacher.send_keys('1')
# 輸入文字
time.sleep(1)
# 等待一秒,小伙伴們要盯住【請輸入你喜歡的助教】下面的輸入框
teacher.clear()
# 清除之前輸入的內容
# .clear()多用于輸入框有字但不是我們想輸入的內容時
time.sleep(1)
teacher.send_keys('k老師')
# 重新輸入內容
time.sleep(1)
assistant = driver.find_element_by_name('assist')
# 找到【請輸入你喜歡的助教】下面的輸入框位置
assistant.send_keys('學姐')
# 輸入文字
time.sleep(1)
button = driver.find_element_by_tag_name('button')
# 找到【提交】按鈕
button.click()
# 點擊【提交】按鈕
time.sleep(2)
driver.close()
這樣一來,這節理要講的最后的一部分內容已經包含在代碼里了,要重點看注釋,在學習輸入、清除內容和模擬點擊的同時,也順帶復習一下之前學的東西吧,然后我們進行下一節的學習,
三、讓爬蟲學會定時匯報
有時候,我們撰寫爬蟲的目的不是一次性爬取內容,而是需要爬蟲定期匯報,比如每天早晨上班之前為我們發送天氣預告,關于定時功能,python自帶的標準庫——time和datetime都可以完成,但是,這兩個基本庫只有最原始基礎的功能,實作起來的操作邏輯比較復雜,因此選擇使用第三方庫schedule是實作,其代碼也比較簡單,
1.schedule的使用方法
首先,先給大家提供schedule的官方檔案介紹,看不懂也沒有關系,下面我們一起學習這個庫的一些基本用法:
import schedule
import time
def job():
print("Working in progress...")
# 定義job函式,執行函式會'I'm working...',用以監視代碼是否正常作業
# 部署情況
schedule.every(5).seconds.do(job)
# 每 5s 執行一次 job() 函式
schedule.every(10).minutes.do(job)
# 部署每 10 分鐘執行一次 job() 函式的任務
schedule.every().hour.do(job)
# 部署每 x 小時執行一次 job() 函式的任務
schedule.every().day.at("10:30").do(job)
# 部署在每天的 10:30 執行 job() 函式的任務
schedule.every().monday.do(job)
# 部署每個星期一執行 job() 函式的任務
schedule.every().wednesday.at("13:15").do(job)
# 部署每周三的 13:15 執行函式的任務
while True:
schedule.run_pending()
# 檢查部署的情況,如果任務準備就緒,就開始執行任務
time.sleep(1)
# 程式每秒進行一次檢查部署,防止檢查頻率過高占用計算機資源
實戰中,我們需要自己寫好job()函式,然后確定部署時間,需要注意的是,如果部署情況為1秒執行一次job()函式,而檢查部署為3秒檢查一次,那么運行結果是3秒執行一次job()函式,也就是取這兩者的最小公倍數,
下面舉個例子:
import schedule
import time
def job():
print("Working in progress...")
# 定義job函式,執行函式會'I'm working...',用以監視代碼是否正常作業
# 部署情況
schedule.every(1).seconds.do(job)
while True:
# 檢查部署的情況,如果任務準備就緒,就開始執行任務
schedule.run_pending()
time.sleep(1)
運行的結果是每隔一秒,計算機輸出一次“Working in progress…”,
2.schedule的實戰應用
上面我們已經學會了schedule的基本使用方法,下面我們就來做一個實戰,讓我們的的爬蟲每天以郵件方式向我們匯報明天天氣,
i.爬取明天的天氣資訊
首先先找到中國天氣網,選擇自己所在的城市,這里以北京為例,選擇七天的天氣預報:
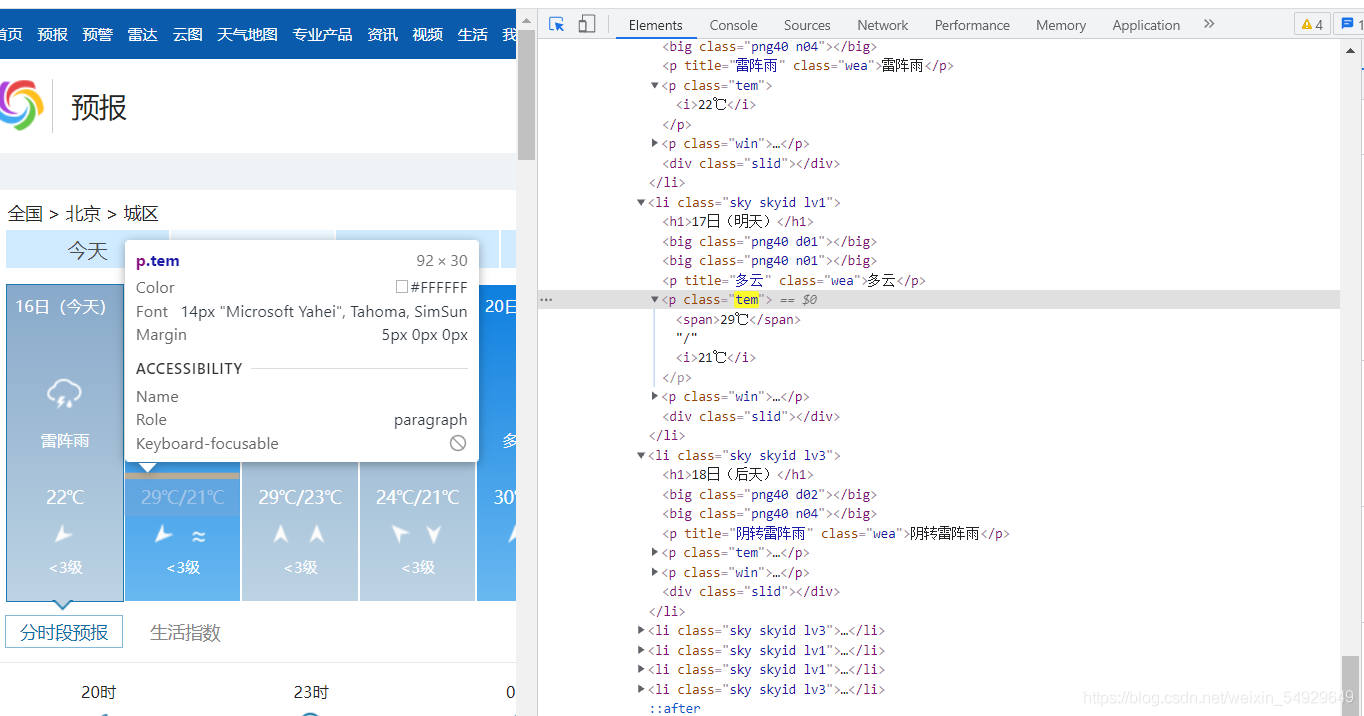
還是用老方法找到源代碼中氣溫的位置(這個網頁的HTML源代碼就包含了全部的網頁的全部資訊,要養成動手實踐之前要注意先查看一下的習慣,)找到位置以后,我們確定要爬取的內容,這里僅選取氣溫和天氣,
下面先撰寫這部分代碼:
我們先看看全部代碼,驗證一下有沒有問題:
import requests
from bs4 import BeautifulSoup as bs
url='http://www.weather.com.cn/weather/101010100.shtml'
headers= {'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.87 Safari/537.36'}
res=requests.get(url, headers=headers, verify=False)
print(res.text)
運行這段代碼,可以很明顯看出,提取到的內容是滿足我們的需求的,但是卻出現了很多亂碼:
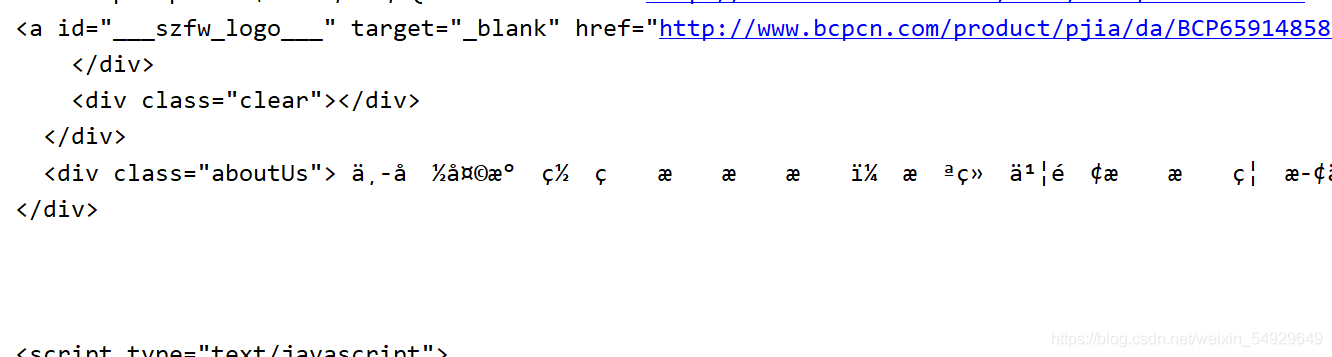
出現這種問題一定是編碼解碼的程序出現了問題,運用之前介紹的知識可以解決這個問題,但是這里給大家介紹一種新的方法,首先我們看到網頁源代碼的最開始部分:
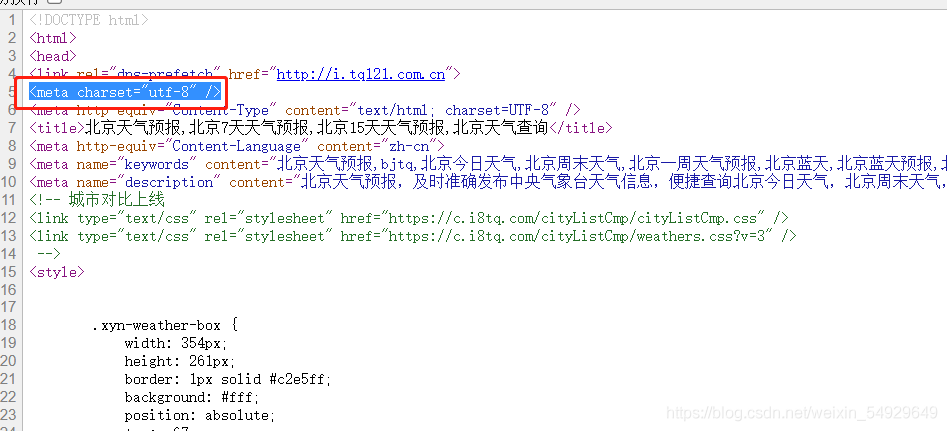
這里是這個網站所用到的編碼方式,那么我們只需要在給res賦值之后,設定res的編碼方式為utf-8即可,代碼改進如下:
res=requests.get(url, headers=headers, verify=False)
res.encoding = 'utf-8'
下面我們就正式爬取天氣內容:
import requests
from bs4 import BeautifulSoup as bs
url='http://www.weather.com.cn/weather/101010100.shtml'
headers= {'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.87 Safari/537.36'}
res=requests.get(url, headers=headers, verify=False)
# 定義 Response 物件的編碼
res.encoding = 'utf-8'
analysis=page_source=bs(res.text,'html.parser')
tem=analysis.find_all(class_='tem')[1]
print('明天氣溫為:'+tem.text.replace('\n',''),end=',')
weather=analysis.find_all('p',class_="wea")
print('天氣為:'+weather[1]['title'].replace('\n','')+',')
# 輸出為:明天氣溫為:29℃/21℃,天氣為:多云,
ii.使用QQ郵箱發送郵件
如何使用python發送郵件在之前的文章中有過具體介紹,這里不做贅述,直接給出代碼,忘記的小伙伴可以去復習,
import smtplib
from email.mime.text import MIMEText
from email.header import Header
# 采集資訊
from_addr = input('請輸入發件人的郵箱: ')
password = input('請輸入發件人的 QQ 郵箱授權碼: ')
to_addrs=input('請輸入收件人郵箱:')
text = '將天氣資訊寫入郵件正文內容'
msg = MIMEText(text, 'plain', 'utf-8')
# 設定郵件頭資訊
msg['From'] = Header(from_addr)
msg['To'] = Header(to_addrs)
# 這句是群發格式,單發也可以這樣寫
msg['Subject'] = Header('明日天氣預報')
try:
server = smtplib.SMTP_SSL()
server.connect('smtp.qq.com', 465)
server.login(from_addr, password)
server.sendmail(from_addr, to_addrs, msg.as_string())
print('發送成功')
server.quit()
except :
print('發送失敗')
iii.設定定時資訊
應用之前講的知識設定發送時間,當然,測驗運行時可以把發送時間設定成幾秒:
import schedule
import time
def send():# 這里之后會換成具有實際意義的函式
return 0
# 部署情況
schedule.every().day.at("22:30").do(send)
while True:
schedule.run_pending()
time.sleep(1)
iv.代碼整合
各部分的功能都實作之后,我們將代碼整合:
import requests
from bs4 import BeautifulSoup as bs
import smtplib
from email.mime.text import MIMEText
from email.header import Header
import schedule
import time
url='http://www.weather.com.cn/weather/101010100.shtml'
headers= {'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.87 Safari/537.36'}
from_addr = input('請輸入發件人的郵箱: ')
password = input('請輸入發件人的 QQ 郵箱授權碼: ')
to_addrs = input('請輸入收件人郵箱:')
def find_weather():# 查找函式,用于查看明天天氣
res = requests.get(url, headers=headers, verify=False)
# 定義 Response 物件的編碼
res.encoding = 'utf-8'
analysis = page_source = bs(res.text, 'html.parser')
tem = analysis.find_all(class_='tem')[1]
weather = analysis.find_all('p', class_="wea")
return '明天氣溫為:' + tem.text.replace('\n', '')+','+'天氣為:' + weather[1]['title'].replace('\n', '') + ','
def send_email():
weather=find_weather()
text = weather
msg = MIMEText(text, 'plain', 'utf-8')
# 設定郵件頭資訊
msg['From'] = Header(from_addr)
msg['To'] = Header(to_addrs)
# 這句是群發格式,單發也可以這樣寫
msg['Subject'] = Header('明日天氣預報')
try:
server = smtplib.SMTP_SSL()
server.connect('smtp.qq.com', 465)
server.login(from_addr, password)
server.sendmail(from_addr, to_addrs, msg.as_string())
print('發送成功')
server.quit()
except:
print('發送失敗')
schedule.every().day.at("22:30").do(send_email)
while True:
schedule.run_pending()
time.sleep(1)
到此為止,我們的目的已經完成了,感興趣的小伙伴可以自己運行試試,這節的內容就到這里了,我們下篇文章見~
實際操作中,可以選擇上面的Doc標題,可以快速找到狀態碼為302的請求, ??
靜態網頁中,HTML源代碼就包含了全部的網頁的全部資訊動態網頁展現在網頁的內容除了寫在HTML的內容以外,還有其他的請求包含的內容,如果網頁顯示的內容有變但網址沒有變化,就可以判斷它是動態網頁, ??
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/294754.html
標籤:其他
上一篇:我用 MATLAB 提取圖片曲線