本文禁止其他人轉載,違者必究!
目錄
??1、專案背景
??2、奧運會相關資訊爬取
???① 匯入相關庫
???② 爬蟲代碼完整講解
??3、資料預處理
???① 資料替換
???② 資料分組
???③ 中英文名映射轉換
??4、可視化展示
???① 2020東京奧運會各國金牌分布地圖
???② 2020東京奧運會獎牌榜詳情堆積柱形圖
???③ 2020東京奧運會獎牌榜總數前十名柱形圖
???④ 2020東京奧運會金牌榜總數前十名柱形圖
???⑤ 2020東京奧運會中國各專案獲獎詳情餅圖
???⑥ 中國選手每榷訓得獎牌數折線圖
???⑦ 中國選手每榷訓得金牌數折線圖
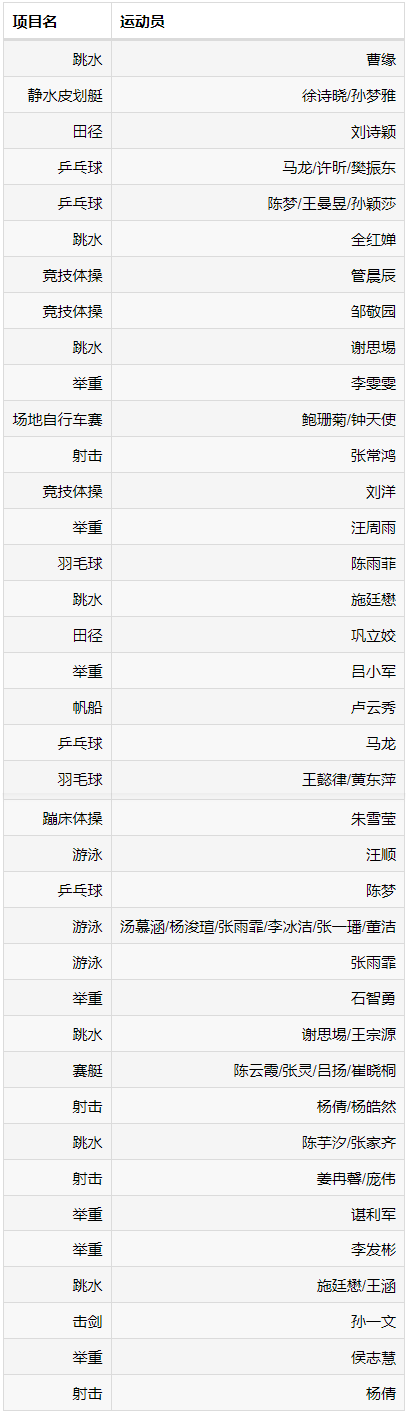
???⑧ 中國選手奪金詳細資料表格
???⑨ 組合為可視化大屏
整體思路

1、專案背景
奧運會剛剛過去,你是否已經看過2020東京奧運會呢?本文將手把手帶你爬取奧運會相關資訊,并利用可視化大屏為你展示奧運詳情,讓一個沒關注過奧運會的朋友,也能夠秒懂奧運會,
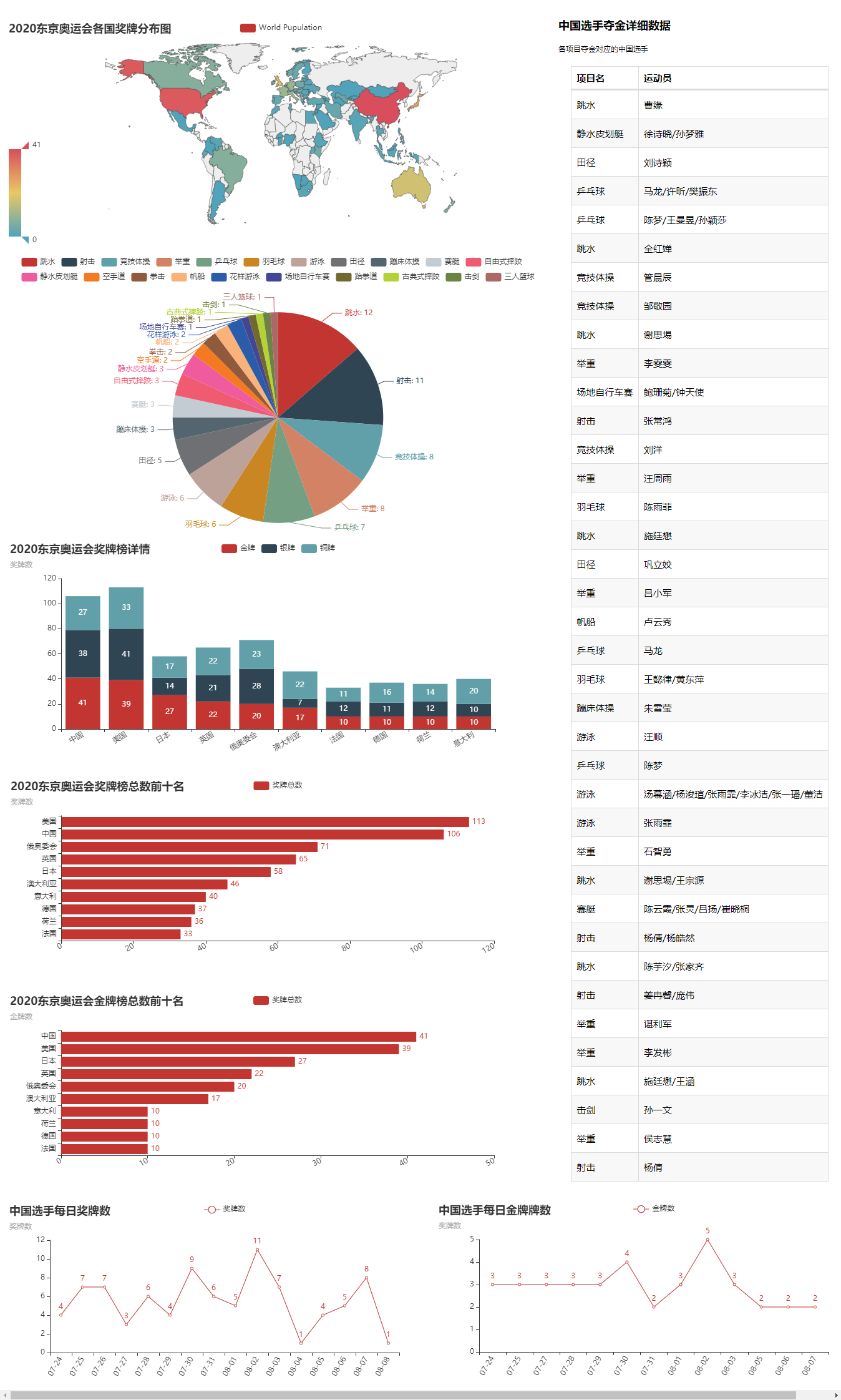
學完本文后,你將學會如下可視化大屏的制作,
2、奧運會相關資訊爬取
- 爬取欄位: 國家、國家ID、排名、金牌數、銀牌數、銅牌數、獎牌總數、專案名、運動員、獲獎型別、獲獎時間;
- 爬取說明: 基于兩個介面的資料爬取【json格式的資料】,直接采用鍵值對的方式獲取相關資料;
- 使用工具: Pandas+requests
本文是基于兩個介面的資料爬取,相對容易的多,
# 這個鏈接主要展示:各國的金銀銅牌及其總數!
https://app-sc.miguvideo.com/vms-livedata/olympic-medal/total-table/15/110000004609
# 這個鏈接主要展示:每個參賽隊員的參賽專案和獲得的獎牌情況!
https://app-sc.miguvideo.com/vms-livedata/olympic-medal/total-table/15/110000004609
① 匯入相關庫
import requests
import pandas as pd
from pprint import pprint
requests庫用于發起網頁請求,獲取網頁中的源代碼;pandas庫用于存盤和讀取獲取到的資訊;pprint庫是漂亮的列印,對于json格式的資料,能夠很好的展示結構,方便我們決議;
② 爬蟲講解
url = 'https://app-sc.miguvideo.com/vms-livedata/olympic-medal/total-table/15/110000004609'
data = requests.get(url).json()
pprint(data)
三行代碼就可以獲取到網頁的源代碼,利用pprint庫,可以清晰的展示json結構,對于我們決議資料很有幫助,
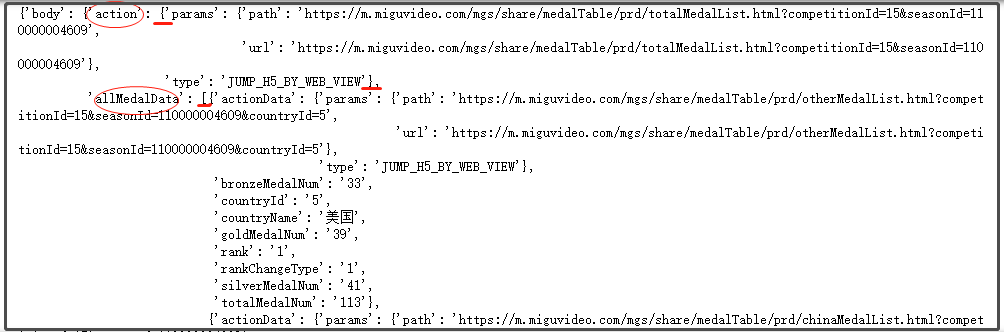
從圖中可以很清晰地看到,我們要的資料,都存在于body鍵下面的allMedalData鍵中,allMedalData鍵的值是一個串列,里面有很多字典組成的鍵值對資訊,就是我們要爬取的資料,
直接利用鍵獲取對應的值資訊,代碼如下:
df1 = pd.DataFrame()
for info in data1['body']['allMedalData']:
name = info['countryName']
name_id = info['countryId']
rank = info['rank']
gold = info['goldMedalNum']
silver = info['silverMedalNum']
bronze = info['bronzeMedalNum']
total = info['totalMedalNum']
# 組織資料
orangized_data = [[name,name_id,rank,gold,silver,bronze,total]]
# 然后追加df
df1 = df1.append(orangized_data)
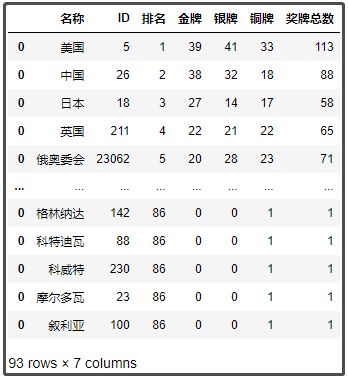
df1.columns = ['名稱', 'ID', '排名', '金牌', '銀牌', '銅牌', '獎牌總數']
df1
結果如下:
對于另外一個網頁,我們采取同樣的方式,
url = 'https://app-sc.miguvideo.com/vms-livedata/olympic-medal/detail-total/15/110000004609'
data2 = requests.get(url).json()
pprint(data2)
結果如下:
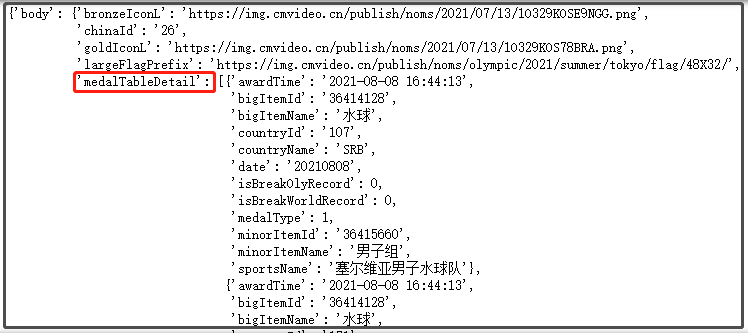
是不是此時感覺結構更清楚了?
df2 = pd.DataFrame()
for info in data2['body']['medalTableDetail']:
english_name = info['countryName']
name_id = info['countryId']
award_time = info['awardTime']
item_name = info['bigItemName']
sports_name = info['sportsName']
medal_type = info['medalType']
# 組織資料
orangized_data = [[english_name,name_id,award_time,item_name,sports_name,medal_type]]
# 然后追加df
df2 = df2.append(orangized_data)
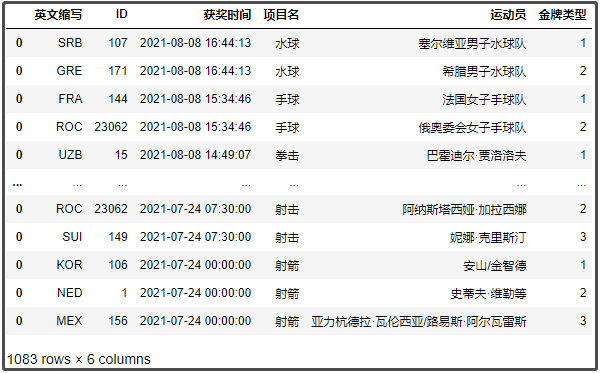
df2.columns = ['英文縮寫', 'ID', '獲獎時間', '專案名', '運動員', '金牌型別']
df2
結果如下:
3、資料預處理
對于爬取到的資料,往往是有問題的,我們需要提前預處理一下,方便后續做可視化展示,
① 資料替換
對于上述爬取到的資料,我們做一個資料篩選,
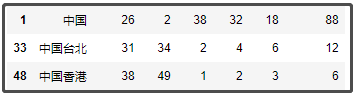
df1 = pd.read_excel("各國獎牌數.xlsx")
df1[df1["名稱"].str.contains("中國")]
結果如下:
雖說中國香港、中國臺灣都單獨參加了奧運會,但她們都屬于中國,我們將她們的都改為中國,ID也都改為26,
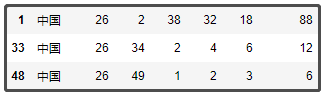
df1["名稱"].replace(["中國臺北","中國香港"],"中國",inplace=True)
df1["ID"].replace([31,38],26,inplace=True)
df1[df1["名稱"].str.contains("中國")]
結果如下:
② 資料分組
經過上述處理,那么中國就相當于有3條資料了,我們以名稱+ID作為聯合欄位,進行分組,然后求和,將這3條資料進行合并,最后,再以金牌欄位為基準,進行降序排列,
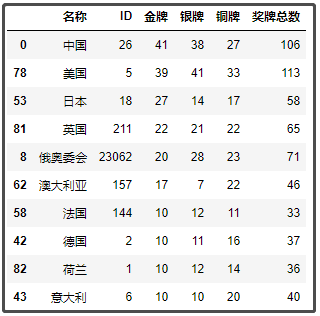
df2 = df1.groupby(["名稱","ID"])[["金牌","銀牌","銅牌","獎牌總數"]].sum().reset_index().sort_values(by="金牌",axis=0,ascending=False)
df2.head(10)
結果如下:
③ 中英文名映射轉換
由于使用pyecharts繪制世界地圖時,名稱必須是英文的,所以我們需要將這里的中文名稱映射為英文名稱,于是我在網上找到了下面這個檔案:
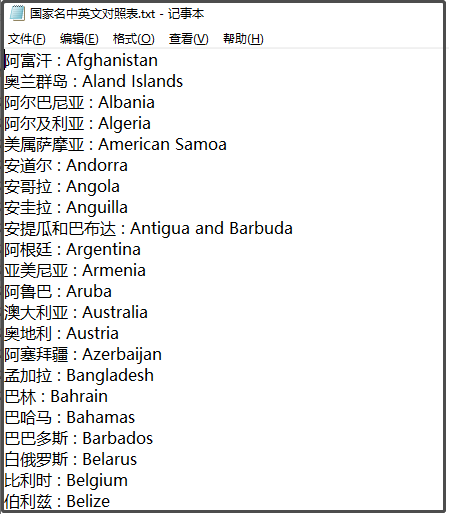
我們要做的就是將它與表格中的資料,做個映射轉換,先把它轉換為一個Excel檔案吧,方便我們以后直接使用,
with open("國家名中英文對照表.txt","r",encoding="utf-8") as f:
x = f.read()
df3 = pd.DataFrame()
for i in x.split("\n"):
x = i.split(":")[0].strip()
y = i.split(":")[1].strip()
orangined_data = [[x,y]]
df3 = df3.append(orangined_data)
df3.columns = ["名稱","英文名稱"]
df3.to_excel("國家名中英文對照表.xlsx",index=None)
然后,在和上述的df2表格做一個左連接即可,
df4 = pd.merge(df2,df3,on="名稱",how="left")
df4
結果如下:
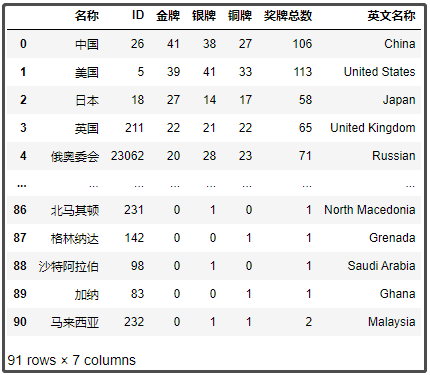
4、可視化展示
關于可視化部分,使用的是pyecharts庫,這部分一共分以下8個主題:
- ① 2020東京奧運會各國獎牌分布圖;
- ② 2020東京奧運會獎牌榜詳情;
- ③ 2020東京奧運會獎牌榜總數前十名;
- ④ 2020東京奧運會金牌榜總數前十名;
- ⑤ 2020東京奧運會中國各專案獲獎詳情;
- ⑥ 中國選手每榷訓得獎牌數;
- ⑦ 中國選手每榷訓得金牌數;
- ⑧ 中國選手奪金詳細資料;
① 2020東京奧運會各國金牌分布圖
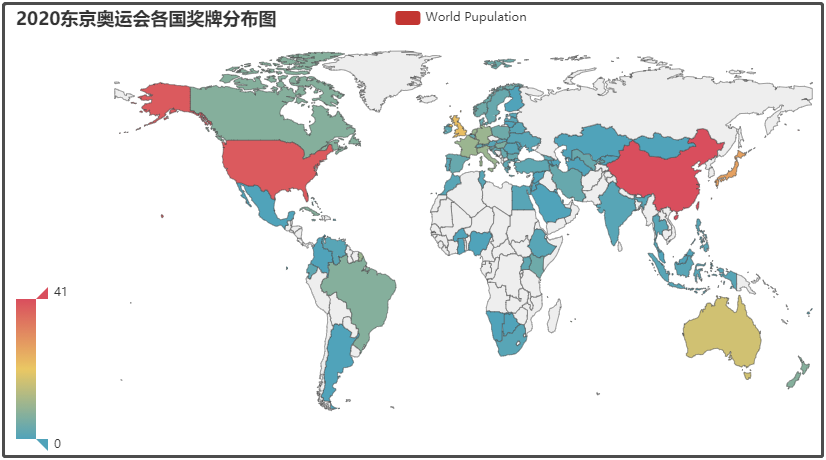
② 2020東京奧運會獎牌榜詳情
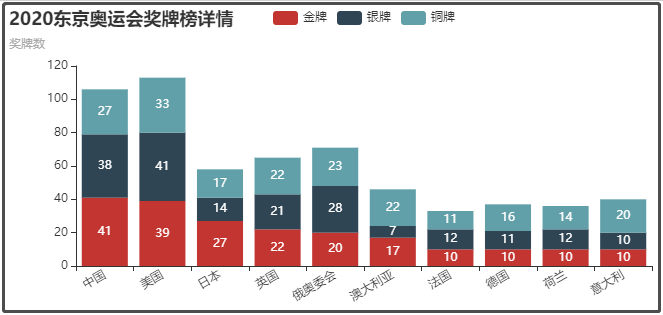
③ 2020東京奧運會獎牌榜總數前十名
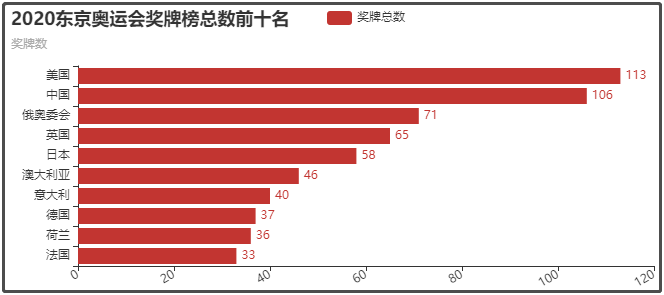
④ 2020東京奧運會金牌榜總數前十名
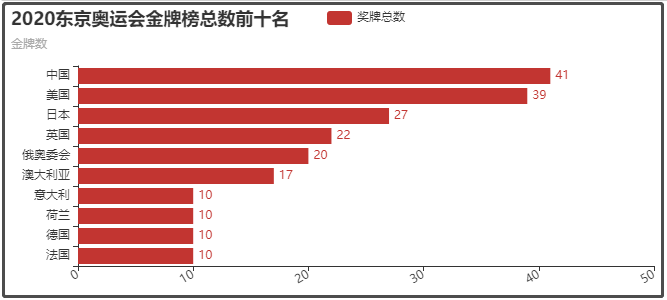
⑤ 2020東京奧運會中國各專案獲獎詳情
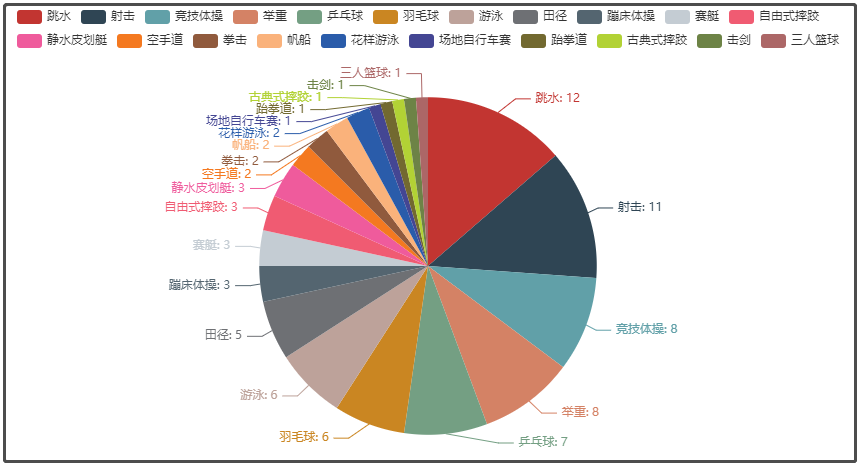
⑥ 中國選手每榷訓得獎牌數
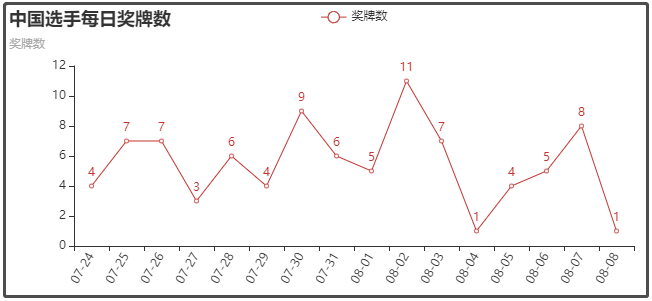
⑦ 中國選手每榷訓得金牌數

⑧ 中國選手奪金詳細資料
⑨ 組合為可視化大屏
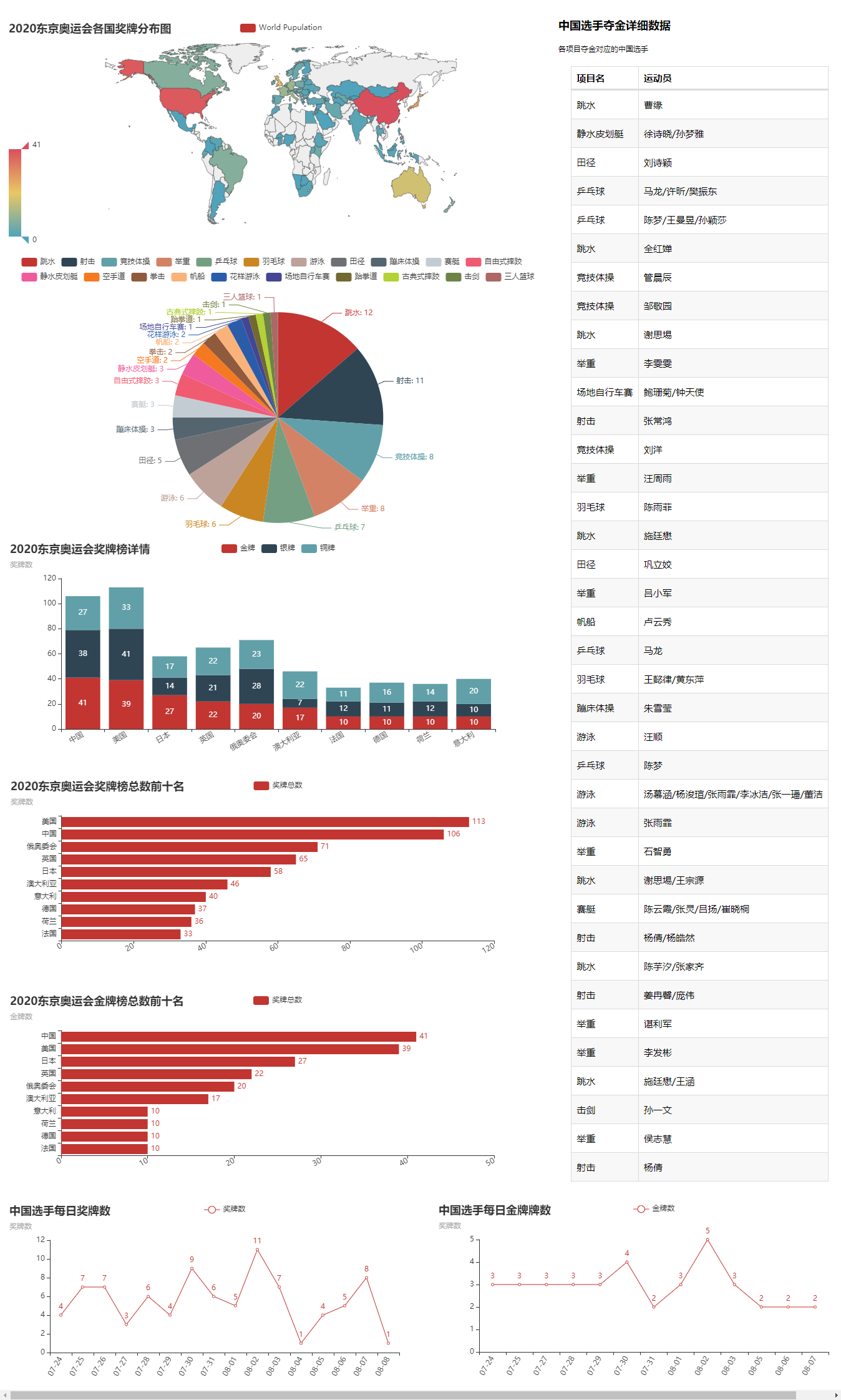
說明: 這里就不做結果分析了,因為通過上圖,相信大家應該能夠很清晰的了解到2020東京奧運會,哪怕你沒看過,
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/295230.html
標籤:其他
下一篇:世界上第一部智能手機27歲了