前言
2006 年誕生的 hadoop 和 她周邊的生態, 在過去的這些年里為大資料的火熱提供了足夠的能量, 十幾年過去了, 場景在變化,技術在演變, 大家對資料的認知已經不再局限于 T+1 與 高吞吐高延遲 為主要特征的上一代框架理念, 在真實的場景里, 實時, 準確, 多變的資料也發揮著越來越重要的作用,
為滿足這些新的需求, 各種框架和中間件如雨后春筍般不斷涌出
hive 的出現讓這頭大象有了一個精致但呆滯的面龐, hbase 與 impala 開始嘗試將其提速, spark/flink 作為新的流處理框架, 嘗試通過實時計算的方式, 將資料更快地輸送到業務方面前, presto/dremio 從資料模型入手, 嘗試通過虛擬化實時集合來自不同資料源的資料, 變相達到實時的目的, 而各種新型的 OLAP 資料庫, 以 clickhouse 為代表, 試圖提供近實時的海量資料統計分析方案, 在不同的細分領域, 比如 時序/特征 等領域, 也各自涌現了富有特色的產品出來

與傳統的商業軟體發展方式不同, 這個實時資料相關的賽道中, 開源已經逐漸成為不約而同的選擇, talk is cheap, show me the code, 大家各憑本事說話
而基礎框架就像是心愛的姑娘, 每個人都覺得自己的才是最好的, TAPDATA 在實時資料方案的落地程序中, 也逐漸感覺到了現有的各種技術產品總是在什么地方差點東西, 一個個場景做下來, 一個個客戶談下來, 去實作一個屬于自己的流計算框架的想法在腦海中越來越明確,

在給客戶產生直接價值的同時, 把這些經驗累積起來, 去做一個可以影響更多人的技術產品, 可能是一件更有意思的事情
為此, 我前幾天登錄了好久沒用的知乎賬號, 在這個人均百萬的平臺下, 開始了這個系列的分享, 去把 TAPDATA 對于實時計算引擎的一些思考整理成文字, 大家看了如果覺得有用, 可以默默收藏, 如果覺得哪里寫得不對, 可以評論或者私信我, 如果覺得這個東西方向有問題, 或者說就是一些沒有價值的垃圾, 也歡迎提醒我, 我們共同進步
新鮮的, 才是最好的
完成一個實時的資料計算, 第一步是資料來源怎么取得, 基于 JDBC 或者各個資料庫驅動的 Query, 可以很方便拿到批量的資料, 但是更實時的資料拿起來, 就不是那么的顯而易見和標準化
實時資料的獲取, 有一個名詞叫 CDC, 全稱是 change data capture, 可以想見一個場景如果有一個專門的名詞縮寫來描述, 一般都不會很簡單
CDC 的實作一般有以下幾種方式
- 輪詢
最直接的想法是通過 Query, 定期輪詢最新的資料, 這么做的好處是幾乎全部的資料庫都可以直接支持, 開發起來成本也低, 但是問題也很明顯, 主要有:
輪詢需要有條件, 這個條件一般是遞增欄位, 或者時間屬性, 對業務上有 入侵
最小 延時 為輪詢間隔
輪詢對資料庫造成了額外的查詢 壓力
最致命的是, 輪詢 無法獲取被洗掉的資料, 也無法得知更新的資料更新了哪些內容, 這些雖然在工程上可以通過各種手段去找一個折衷方案, 但終究會存在各種各樣的問題
由于實作容易, 輪詢是最早也是目前最廣泛被應用于實際場景的方案, 但是也由于缺點很多, 在最近出現的各種計算框架中, 輪詢一般作為保底而不是首選方案出現
- 觸發器
不少資料庫都有觸發器(Trigger) 的設計, 在對資料行列進行讀寫時, 可以觸發一個存盤程序, 完成一系列的操作, 基于這個前提, 可以對資料庫的寫操作撰寫一個自定義觸發器, 完成資料獲取, 常見的方案有:
資料觸發保存到單獨的一張表, 典型的產品化實作有 SQL Server, 其他的資料庫也可以自己實作類似的邏輯, 然后通過輪詢這張表獲得變更
資料觸發到外部訊息佇列, 消費者通過訊息佇列獲取資料
通過 api 直接發送到目標端
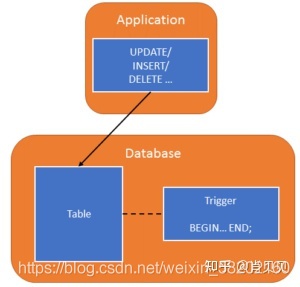
相比輪詢, 觸發器可以更全面地獲取更詳細的實時資料, 不過問題也有很多, 主要是的問題有:
-
沒有標準: 用戶需要根據每種資料庫的觸發器去設計自己的資料獲取方案
-
通用性不夠: 部分資料庫沒有觸發器設計
-
影響性能: 觸發器在資料寫入的時候, 在資料處理邏輯里增加了一段邏輯,
雖然有些觸發器的設計是異步的,不影響延時,但是因為占用了資料庫本身的計算資源, 對吞吐有一些影響
相比輪詢, 觸發器子方案在延時和資料準確性上有了一些突破, 是一種方案的進步
- 資料庫日志
絕大資料資料庫都有各種各樣的日志, 其中一種日志用來記錄每個操作產生的資料變更, 很多資料庫都用這份日志來做多副本同步, 或者用來做資料恢復
而外部服務也可以通過這種方式拿到最新的實時變更, 相比輪詢, 通過日志拿到的資料延時一般在亞秒內, 而且對資料庫的性能影響非常低, 同時支持的資料庫型別相比觸發器更多, 只要存在副本, 就存在類似的日志設計
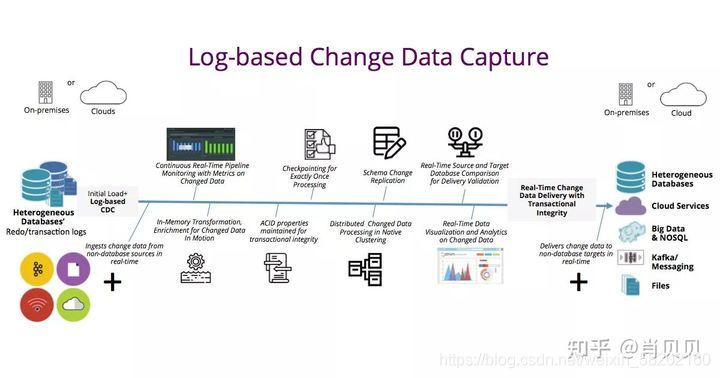
由于基于資料庫日志的方案具備其他兩種方案不可比擬的優勢, 已經逐漸成為實時計算框架首選的資料獲取方案, 但是這種方案由于使用了資料庫內部的設計, 開發難度和實作成本是最高的, 這個也限制了方案的使用
- 訊息佇列
除此之外, 還有一些來自應用的訊息, 或者一些其他的業務自定義資料, 大多數都通過各種訊息佇列來中轉, 典型的有 kafka 和 各種名字的 MQ, 由于更多是業務定制在里面, 這里各家都有各家的場景, 統一來做是比較困難的
資料庫日志的難題
在之前提到的各種 CDC 方案中, 資料庫日志具有非常明顯的結果優勢, 但是因為開發困難, 目前應用范圍也不是特別廣泛, 資料庫日志方案的問題主要有以下幾種:
- 資料庫種類繁多
資料庫日志屬于資料庫內部實作邏輯, 除了特意為兼容去設計之外, 很少有相同或者相似的對外介面, 不管是從 API, 還是日志格式上來說, 基本是各家有各家的做法, 對流計算框架來說, 適配起來要一個個做, 沒有捷徑可以走, 成本很高

當前市面上用的比較多的資料庫少說有幾十種, 如果想覆寫全, 大概有兩百種左右的適配作業量, 放眼看去目前并沒有哪個開源或者閉源的方案, 在這方面做得比較全面, 除了開源資料庫之外, 還有一些商業資料庫, 比如 db2, gaussdb, hana, 檔案的缺失, 開源方案的缺失, 導致這些方案實作起來很麻煩
- 不兼容的版本
即使是同一種資料庫, 不同的版本之間也往往有不兼容的情況, 極少有資料庫可以在一個副本內運行不同的大版本, 比如 oracle 的 8 到 20 之間的版本, mongodb 的 2 到 5 之間的版本, 會存在很多細節和設計的不同
資料庫種類已經很多, 加上版本的不兼容, 要完整處理這些場景, 適配的數量一下子增加到五百種以上, 困難成倍提升
- 部署架構多種多樣
第三種多樣性來自于部署架構, 即使是同一個資料庫的同一個版本, 也存在各種各樣的部署架構, 比如對 Mysql, 有包括 PXC, Myshard, Mycat 在內的各種集群方案, PG 也有 GP, XL, XC, Citus 在內的各種方案, oracle 有 DG, RAC, mongodb 有 副本, 分片
這些多樣性與前幾種相互組合, 最后的完整的作業量已經達到幾乎人力不可為的程度
- 不標準的格式
如果說多樣性只是作業量上的問題, 資料庫日志的一些設計, 則從理念上造成了一些困難
由于資料庫的日志更多是為了主從同步設計, 主要是保證資料的最終一致, 這個與實時計算的場景需求存在一些差異, 比如我們以 MongoDB 的一個洗掉日志來做示例
rs0:PRIMARY>usemockswitchedtodbmockrs0:PRIMARY>db.t.insert({a:1,b:1}) WriteResult({"nInserted" : 1 }) rs0:PRIMARY>db.t.remove({}) WriteResult({"nRemoved" : 1 }) rs0:PRIMARY>uselocalswitchedtodblocalrs0:PRIMARY>db.oplog.rs.find({ns:"mock.t"}).pretty() {"op" : "i", "ns" : "mock.t", "ui" : UUID("9bf0197e-0e59-45d6-b5a1-21726c281afd"), "o" : { "_id" : ObjectId("610eba317d24f05b0e9fdb3b"), "a" : 1, "b" : 1 },"ts" : Timestamp(1628355121, 2), "t" : NumberLong(1), "wall" : ISODate("2021-08-07T16:52:01.890Z"), "v" : NumberLong(2) }{"op" : "d", "ns" : "mock.t", "ui" : UUID("9bf0197e-0e59-45d6-b5a1-21726c281afd"), "o" : { "_id" : ObjectId("610eba317d24f05b0e9fdb3b") },"ts" : Timestamp(1628355126, 1), "t" : NumberLong(1), "wall" : ISODate("2021-08-07T16:52:06.191Z"), "v" : NumberLong(2) }
插入一條資料, 將其洗掉, 查詢一下資料庫日志, 關注洗掉那條記錄, 里面只記錄將主鍵洗掉的資訊, 并無法得到原始欄位的值
實時計算一個比較典型的場景是多表 JOIN, 如果我們以 a 為欄位進行 JOIN, 來自資料源為 MongoDB 的實時流由于無法拿到被洗掉的資料中 a 欄位的值是多少, 這個會導致實時的 JOIN 無法獲取最新的結果
為了實作完整的流計算的需求, 只保證資料同步一致性的日志是不足夠的, 我們往往需要完整的資料庫變更資料
一些現存的解決方案
雖然資料庫日志有著各種各樣的問題, 但是由于其過于明顯的優勢, 越來越成為實時流框架的當紅炸子雞選型, 那上面的問題, 也逐漸有了解法
針對實作作業量的問題, 現在出現了三種流派 :
一個是專精派, 每個方案只解決一個資料庫, 或者只專注解決一個資料庫, 比如 oracle 的 ogg, mysql 的 canal, 都專注在自己的領域去做到很高的深度
一個是包容萬象派, 典型的有 debezium, 通過插件的形式去兼容各個資料庫的標準
最后一個是融合派, 他們自己不做實作, 只是將來自一和二的方案再經過一次抽象, 做成融合的一個解決方案(沒錯的, 說的就是 https://github.com/ververica/flink-cdc-connectors)
而針對資料日志不標準的問題, 在技術上一般是通過一個完整資料的快取層來實作日志的二次加工, 雖然在功能上實作了較好的補充, 但是由于完整保存了資料, 資源消耗也比較高, 而且目前沒有看到統一的產品出現, 更多是停留在一些場景里做方案補充
TAPDATA 的解決方案
在我們的方案里, 是按照 包容萬象 + 必要的資料快取 結合的方式去解決的這個問題
相比與 debezium, 我們在性能上做了大量的優化, 在 決議速度上有數倍提升, 同時, 支持的資料庫種類已經擴展到 三十種以上
對資料庫日志不標準的問題, 也完成了必要的存盤抽象, 一個典型的用法如下:
CacheConfigcacheConfig=TapCache.config("source-cache")..setSize("1g").setTtl("3d");DataSource<Record>source=TapSources.mongodb("mongodb-source").setHost("127.0.0.1").setPort(27017).setUser("root").setPassword("xxx").withCdc().formatCdc(cacheConfig).build()
來構建一個完整的實時資料流, 其中流出的資料, 包含了完整的 全量 + 增量資料, 并使用了記憶體快取對增量日志做了規整化
對下游來講, 這就是新鮮的, 實時的資料流了
留一個小問題
細心的朋友已經已經發現了, 這里的資料包含了全量與增量, 但是我們的資料格式, 并沒有像 flink 或者 hazelcast jet 這些通用的做法一樣, 分成了 BatchSource, Record, ChangeRecord 這些類別, 是出于什么考慮呢?
關注 Tapdata 微信公眾號, 帶給你最新的實時計算引擎的思考,本文作者為tapdata 技術合伙人 肖貝貝,更多技術博客:https://tapdata.net/blog.html

轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/295374.html
標籤:其他