文章目錄
- 0 前言
- 1 Auto-encoder
- 1.1 PCA
- 1.2 Deep Auto-encoder
- 2 Some Applications
- 2.1 Text Retrieval(文字檢索)
- 2.2 Similar Image Search(相似圖片搜索)
- 2.3 Pre-training(預訓練)
- 3 De-noising Auto-encoder(加噪的自編碼器)
- 4 Auto-encoder for CNN
- 4.1 Unpooling(反池化)
- 4.2 Deconvolution(反卷積)
- 4.3 Generate Image
- 5 More Than Minimizing Reconstruction Error(其他計算Error的方法)
- 5.1 Representative Embedding
- 5.2 Sequential Data
- 6 More Interpretable Embedding(更易解釋)
- 6.1 Feature Disentangle(特征決議)
- 6.2 Discrete Representation(離散的表示)
- 6.2.1 Base Method
- 6.2.2 Vector Quantized Variational Auto-encoder (向量量化變異的自編碼器)
- 6.2.3 Sequence as Embedding
0 前言
本節學習的是Auto-encoder,這是一種無監督的學習演算法,主要用于資料的降維或者特征的抽取,自編碼器是一種特殊的神經網路架構,其的輸入和輸出是架構是相同的,先獲取輸入資料的低維度表達,然后在神經網路的后段重構回高維的資料表達,在此基礎還有諸多應用,本文由整理李宏毅老師視頻課筆記和個人理解所得,詳細講述了Auto-encoder的原理及最新的技術,我會及時回復評論區的問題,如果覺得本文有幫助歡迎點贊 😃,
1 Auto-encoder
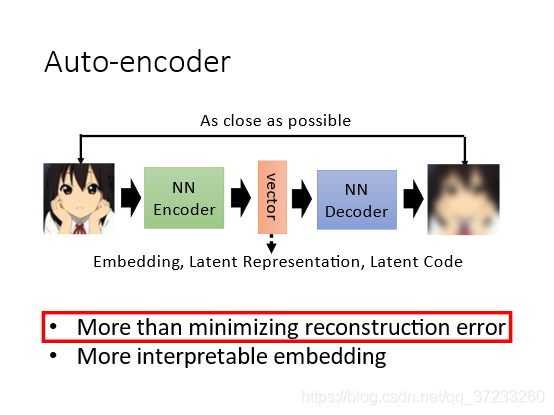
Auto-encoder是一個基本的生成模型,更重要的是它提供了一種encoder-decoder的框架思想,廣泛的應用在了許多模型架構中,簡單來說,Auto-encoder可以看作是如下的結構:
- Encoder(編碼器):它可以把原先的影像壓縮成更低維度的向量,
- Decoder(解碼器):它可以把壓縮后的向量還原成影像,通常它們使用的都是神經網路,
Encoder接收一張影像(或是其他型別的資料)(hidden layer)輸出一個低維的vector,它也可稱為Embedding或者code,然后將vector輸入到Decoder中就可以得到重建后的影像,希望它和輸入影像越接近越好,即最小化重建誤差(reconstruction error),Auto-encoder本質上就是一個自我壓縮和解壓的程序,具體如下圖:
第一個流程圖:假設輸入是一張圖片,有784個像素,輸入一種network的Encoder(編碼器)后,輸出一組遠小于784的code vector,認為這是一種緊湊的表示,
第二個流程圖:輸入是一組code vector,經過network的Decoder(解碼器)之后可以輸出原始圖片,
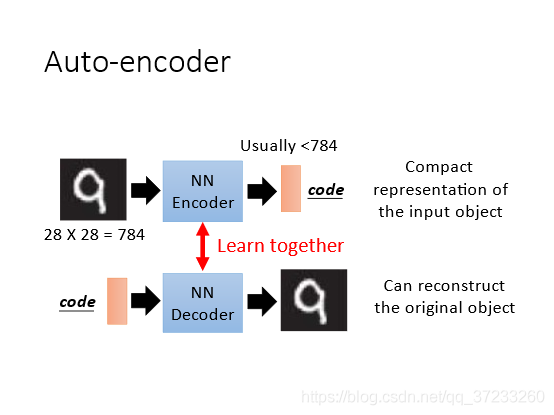
兩者單獨來看都是無監督學習,不能獨立訓練,因為不知道輸出是什么,所以將兩者結合起來訓練,
1.1 PCA
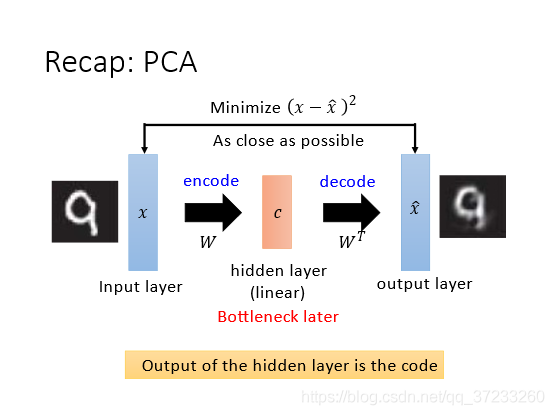
先回顧PCA的概念,PCA輸入是 x x x,乘上W的權值矩陣,可以得到component c c c,然后再乘上 W T W^T WT ,可以得到 x ^ \hat{x} x^,目標函式即使得 x x x和 x ^ \hat{x} x^的差值最小:Minimize ( x ? x ^ ) 2 (x-\hat{x})^{2} (x?x^)2,
將PCA類比為network的話,就可以分為input layer,hidden layer和output layer,hidden layer又稱Bottleneck(瓶頸) layer,因為hidden layer的通常維數比output和input要小很多,所以整體看來hidden layer形如瓶頸一般, Hidden layer 的輸出就可以等同于Auto-encoder的code vector,
1.2 Deep Auto-encoder
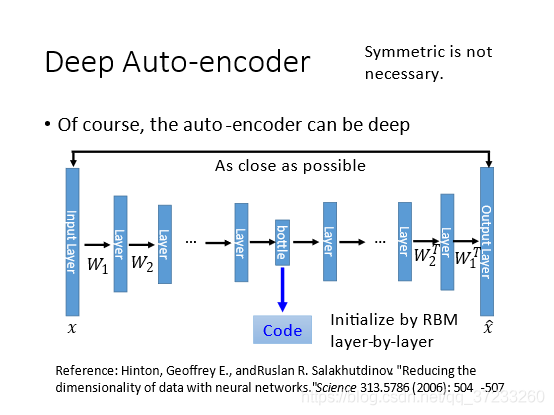
但是PCA只有一個hidden layer,如果我們將hidden layer增加,就變成了Deep Auto-encoder,目標函式也是:Minimize ( x ? x ^ ) 2 (x-\hat{x})^{2} (x?x^)2,訓練方法和訓練一般的神經網路一樣,
將中間最窄的hidden layer作為bottleneck layer,其輸出就是code,bottleneck layer之前的部分認為是encoder,之后的部分認為是decoder,
可認為
W
1
W_1
W1?和
W
1
T
W_1^T
W1T?互為轉置的關系,引數的值是相同的,但是實際上這種對稱是沒有必要的,直接訓練就可以了,
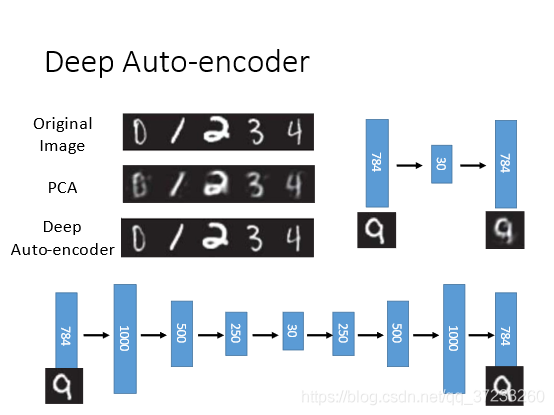
對比使用PCA和Deep Auto-encoder的結果,可以發現后者的結果要好很多:
為了可視化,將bottleneck layer的輸出降到2維后拿出來顯示,不同顏色代表不同的數字,PCA就比較混雜,而Deep Auto-encoder分得比較開,
2 Some Applications
2.1 Text Retrieval(文字檢索)
一般的文字搜索的方法是Vector Space Model,把每一篇文章表示為空間中的一個點,將輸入的查詢詞匯也變成空間中的一個點,計算輸出的查詢詞匯和文章在空間的距離,比如內積和cosine similarity,用距離來retrieve,
這個模型的核心是將一個document表示成一個vector,假設我們有一個 bag of word,假設所有的詞匯有十萬個,那么這個document的維度就是十萬維,涉及到某個詞匯,對應的維度就置為1,但是這樣的模型無法知道具體的語意,對它來說每一個詞匯都是獨立的,忽略了相關性,
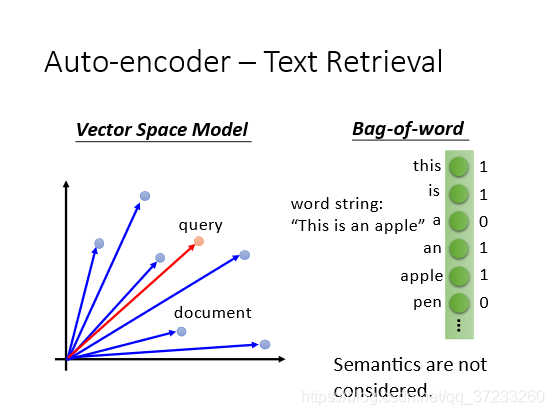
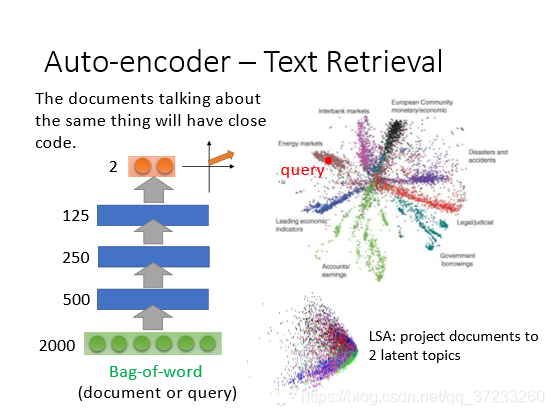
可以使用Auto-encoder來表示這種相關性,
降到2維后做可視化,右上的每個點表示一個document,可以發現同一類的document都分散在一起,如果用剛剛的LSA模型,如右下,就得不到類似的結果,
2.2 Similar Image Search(相似圖片搜索)
可以用在圖片的搜索上面,用圖片來尋找類似的圖片,如果使用歐式距離在像素密度空間去搜索的話,結果如下,效果不是很好,

Auto-encoder的方法就是將圖片變成一個code,在code空間去做搜索,變成code之后再通過一個decoder,reconstruct回來可以得到下圖的結果:

如果在code上做搜索的話,可以得到以下結果,至少都是人臉,

2.3 Pre-training(預訓練)
在訓練DNN的時候希望能選擇好的初始值,這類方法稱為Pre-training,可以用Auto-encoder來做Pre-training,假設目標是一個如下的network:
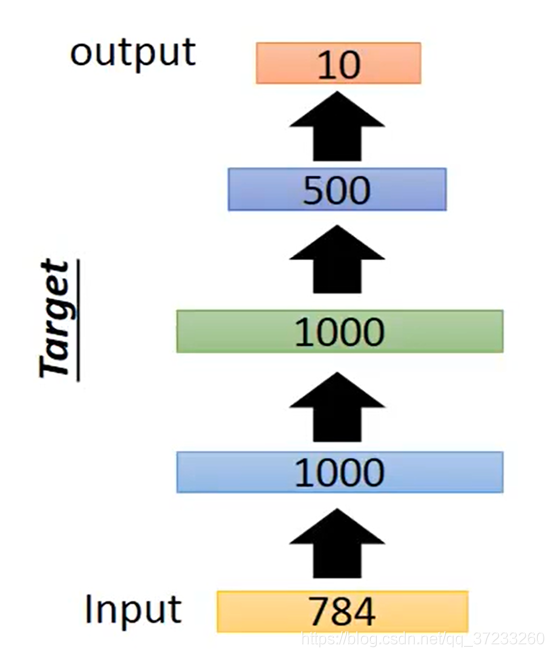
開始使用Auto-encoder對第一個hidden layer進行訓練:
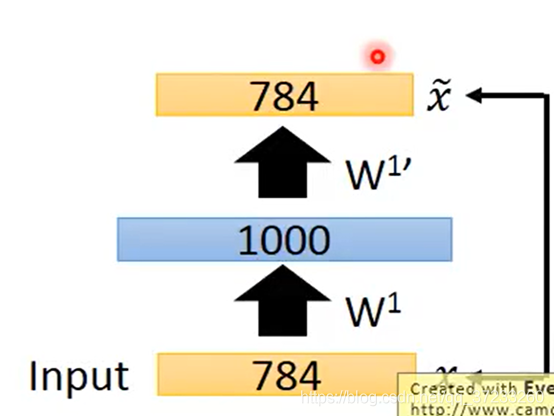
但是有個問題,就是這里的hidden layer是1000維,code比兩邊都大,可能什么都learn不到,直接把引數復制一遍就可以一模一樣了,所以要加一個很強的regularization 來約束,比如使得這1000維是稀疏(sparse)的,某幾個維度才有值,這樣才能learn下去,
現在將學好的第一層的
W
1
W^1
W1固定下來,再學習第二層hidden layer:
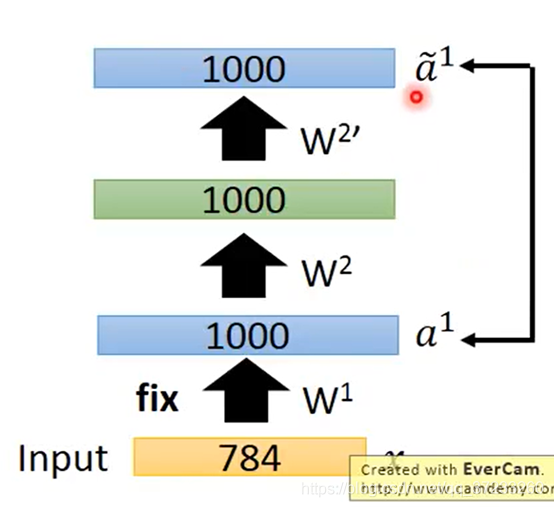
同理得到其他的W:
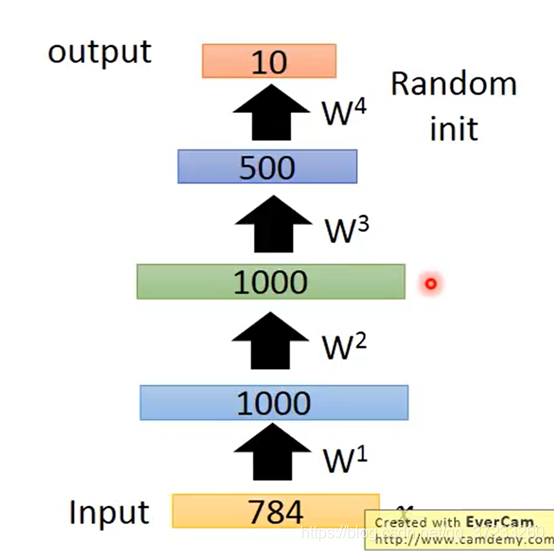
已經得到很好的W了,最后使用BP(back propagation)演算法fine-tune微調一下即可,不過現在訓練的技術進步,Pre-training用的不多了,但是如果你unlabeled data很多,labeled data1很少,那么可以使用這個方法,
3 De-noising Auto-encoder(加噪的自編碼器)
這是一種改進的Auto-encoder演算法:訓練的時候,在x輸入前加入噪聲,這樣做的結果會使得學習的模型有更好的魯棒性,
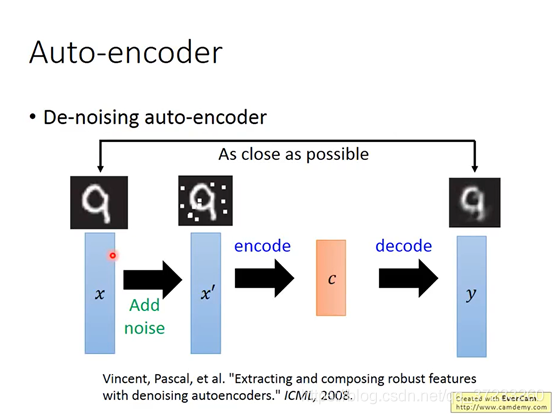
還有很多線性的降維法:

深度信念網路:

4 Auto-encoder for CNN
一般影像處理會使用CNN,如果將Auto-encoder的思想用在CNN上,那么encoder和decoder的卷積、池化和反卷積、池化將是一一對應的,如下圖所示:
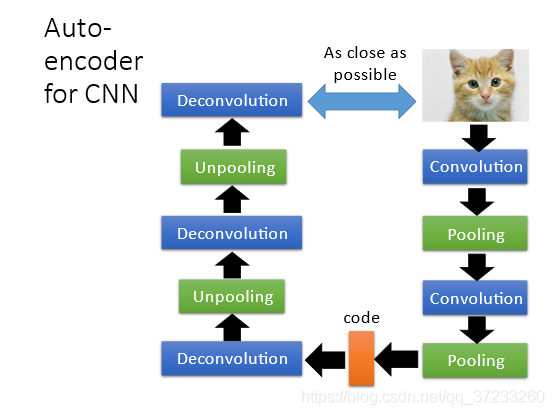
但是反卷積和反池化到底是什么呢?
4.1 Unpooling(反池化)
首先看反池化的部分,池化的意思原本是對特征進行提取,比如是在22的矩陣中選取一個作為特征,那么此時使用一個Max location的層來記錄篩選特征的位置,在后面進行反池化(unpooling)的時候就依據Max location的位置reconstruction這些特征,原本1414的資料,經過unpooling之后就會變成28*28的資料,具體程序如下圖所示:
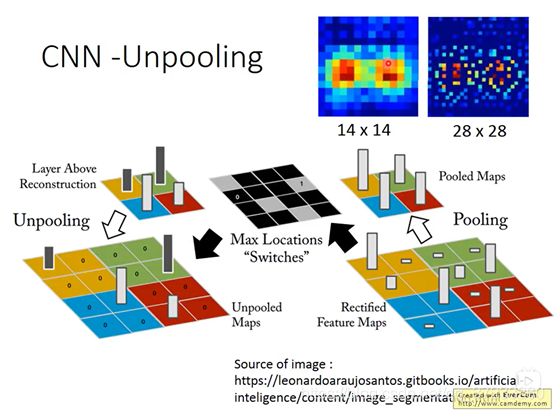
上述只是一種方式,也有不管位置資訊,直接將特征復制4份的做法,
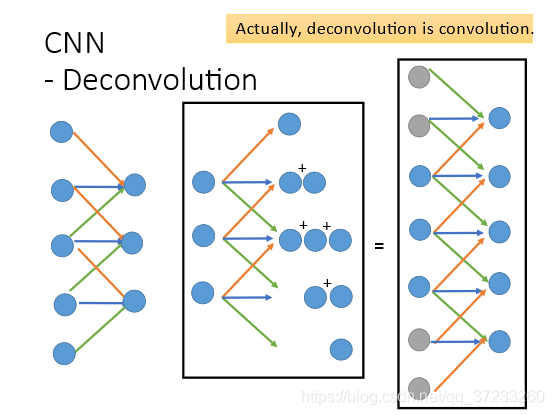
4.2 Deconvolution(反卷積)
那對于反卷積來說,本質上就是做卷積,我們知道卷積的本質就是相乘相加,再移位后繼續重復,用一維的卷積舉例,輸入5個點,卷積核為紅色藍色綠色的3個weight,最后相加得到3個值,而Deconvolution 的就是反過來,因為剛才是三個點乘上3個weight,相加后變成1個值,這里Deconvolution就需要從1個值乘3個weight變成3個值,其他點操作一樣,產生在相同位置的值可以相加,最后初始的3個點就變成了5個點,這件事其實等價于padding后的convolution,在3個點周圍補上4個零,仍然使用3個weight,最后得到的結果是一模一樣的,不同之處在于,卷積核即weight的順序是相反的:
4.3 Generate Image
Decoder還有一個特別的用法,因為已經訓練好了整個模型,將Decoder抽出來,隨機丟入一個二維的code,希望可以輸出一張圖,李宏毅老師將圖片通過hidden layer 投影到2維上,然后再通過Decoder解成圖片,2維是可以畫圖的,分布如下圖所示,按照一定步長取紅色方框中的code輸入到decoder中,可以解出如下圖片:
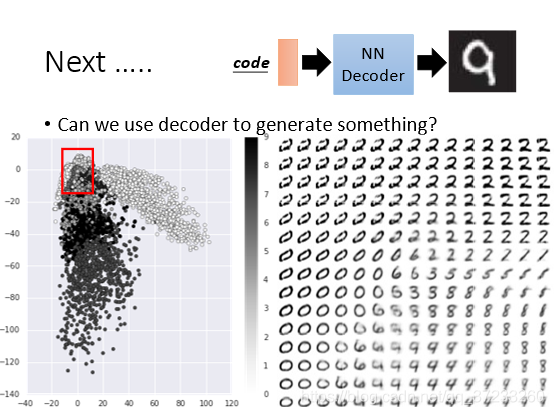
加上L1的正則項后,資料分布向0靠攏,重新選取資料得到以下結果,可以觀察到這兩個維度其實是有一定物理意義的,反映了圖片的變化規律:

我們知道一般的Auto-encoder的目標函式是最小化重構誤差(上文),但是除此之外還有別的方法,
5 More Than Minimizing Reconstruction Error(其他計算Error的方法)
5.1 Representative Embedding
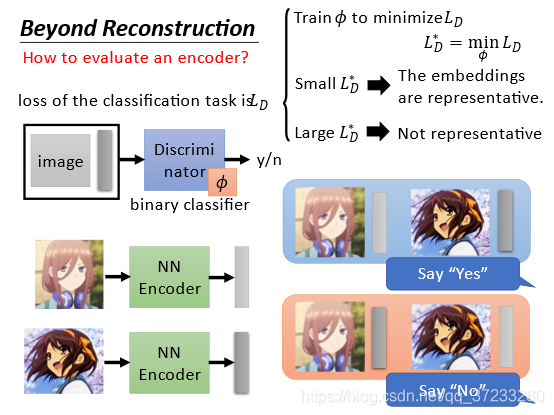
先思考對Auto-encoder的目標來說什么樣的embedding(嵌入,這里可以理解為低維表示)是好的呢?希望這個embedding可以代表原來的object,比如出現這個embedding就會聯想到這個object,比如出現一個耳機,就會想到“三玖”(動漫人物):

這里涉及一點對抗生成網路的概念,即使用一個二分類的判別器對結果進行判別,如果覺得輸入和輸出是一對就是yes,反之就是no,通過使得判別器的損失最小來訓練這個網路:
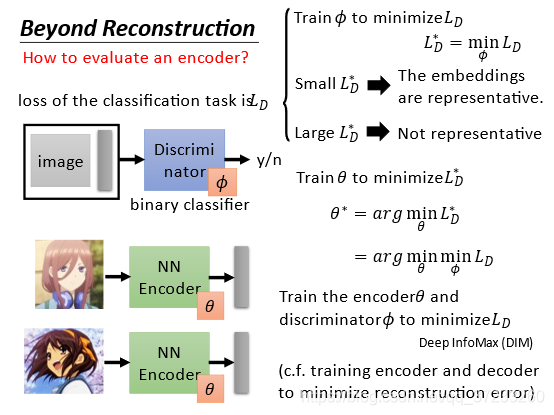
具體是首先通過訓練判別器
L
D
?
=
min
?
?
L
D
L_{D}^{*}=\min _{\phi} L_{D}
LD??=min??LD? 最小化損失函式
L
D
L_D
LD?,然后再訓練encoder的
θ
?
=
arg
?
min
?
θ
L
D
?
=
arg
?
min
?
θ
min
?
?
L
D
\begin{aligned} \theta^{*} &=\arg \min _{\theta} L_{D}^{*} =\arg \min _{\theta} \min _{\phi} L_{D} \end{aligned}
θ??=argθmin?LD??=argθmin??min?LD??,訓練最好的encoder和最好的discriminator:
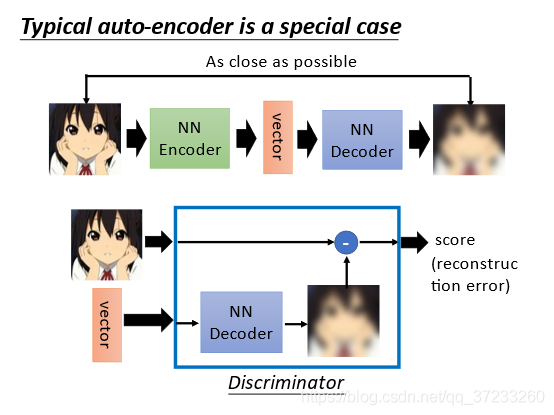
可以將這個程序類比如下:
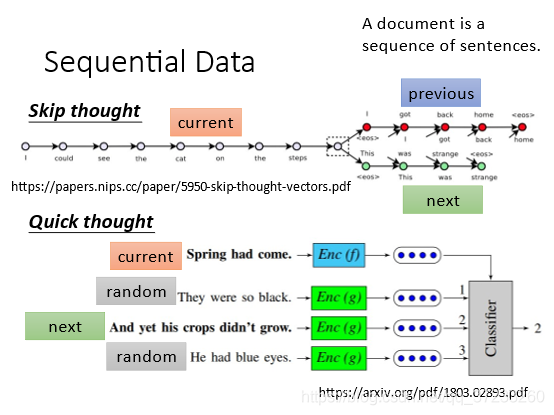
5.2 Sequential Data
也可以用于訓練有順序的資料:
6 More Interpretable Embedding(更易解釋)
讓encoder的output,即code,更容易被解釋,
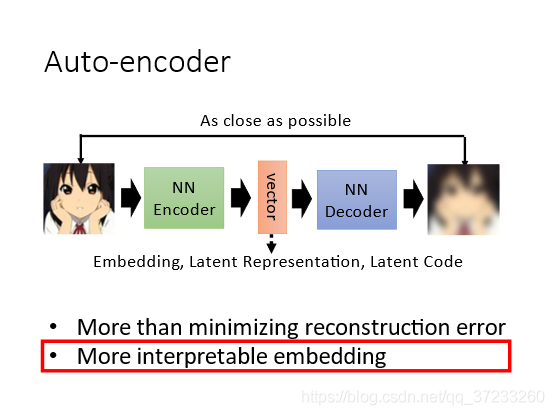
6.1 Feature Disentangle(特征決議)
比如一段聲音信號里面除了語意本身,還包含了說話人的語音語調和環境噪聲等資訊,那么code vector中也含有以上所有資訊,但是我們不知道各個維度的具體含義,所以期望Encoder能指出維度和各類資訊的對應關系,
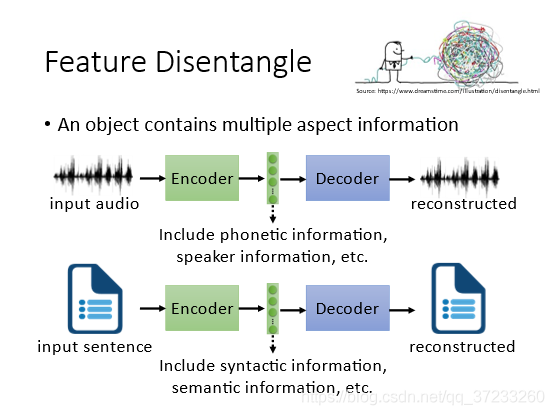
具體做法如下,假設只有說話人和內容兩種資訊,一種是將vector進行劃分,另外一種是直接就訓練兩個encoder處理不同的資訊:
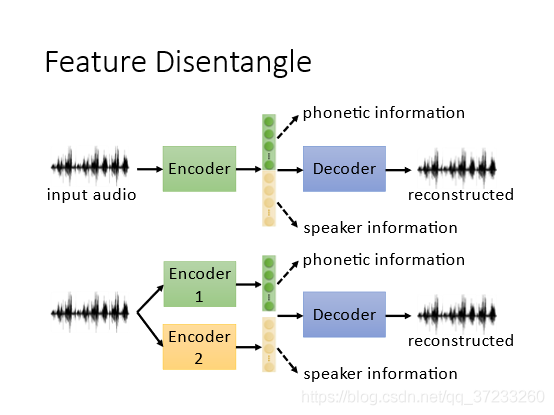
可以將聲音和語意分開:
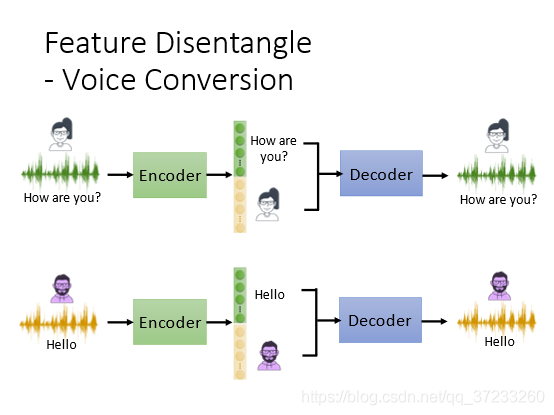
然后將不同的聲音和語意組合,得到完全不同的語音輸出,可以做成一個變聲器:
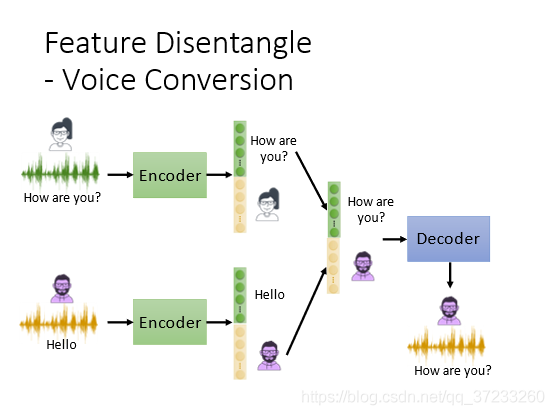
變聲器的應用:

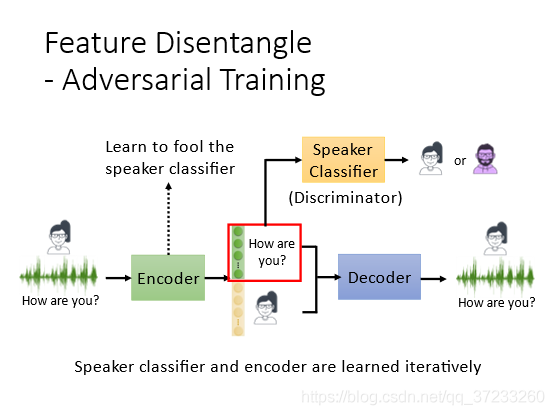
引入對抗訓練的概念,也就是在訓練中加入了Discriminator,目的是訓練讓前面的維度是語意,后面的維度代表男聲還是女聲,先訓練一個語者的Classifier,可以分辨男聲女聲,但是encoder需要訓練來騙過classifier,讓這個classifier不能區分男聲還是女聲,正確率越低越好,這樣就使得語者的資訊從前部分的維度剔除了出來,只剩下內容的資訊,語者資訊都在了后部分的維度中:
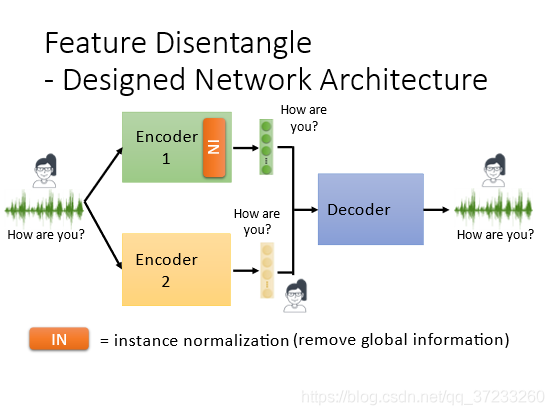
或者直接修改encoder的架構可以區分語者和語意資訊,假設有一種特殊的layer,instance normalization,可以抹除語者的資訊:
6.2 Discrete Representation(離散的表示)
6.2.1 Base Method
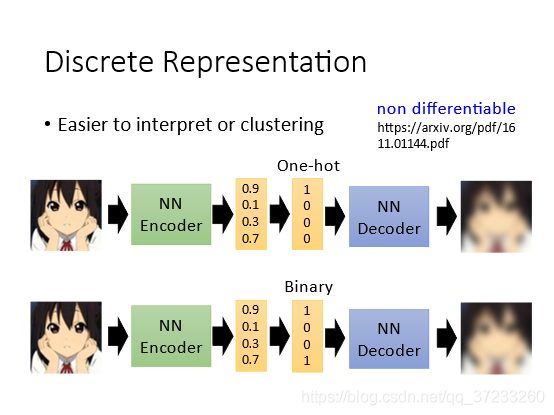
我們之前講的code都說是一個連續的vector,如果Encoder能夠輸出離散的向量,那么更有利于我們解讀code的資訊,比如可以用一些聚類的方法將向量分成一些簇,可以將code直接變成One-hot或者Binary的形式,取最大值或者設定閾值即可實作,這樣看維度資訊就可以直接完成分類了,但是老師認為binary更好,因為可表示的資訊更大,而one-hot過于稀疏,
6.2.2 Vector Quantized Variational Auto-encoder (向量量化變異的自編碼器)
設定一個codebook,里面是一排向量,這個也是需要學習的,Encoder輸出原始向量vector,這是連續的,接下來用這個vector去計算和codebook里面的向量的相似度,相似度最高的vector3作為decoder的輸入,這樣可以固定向量的類別,相當于做了離散化,離散化之后資訊 更易分類:
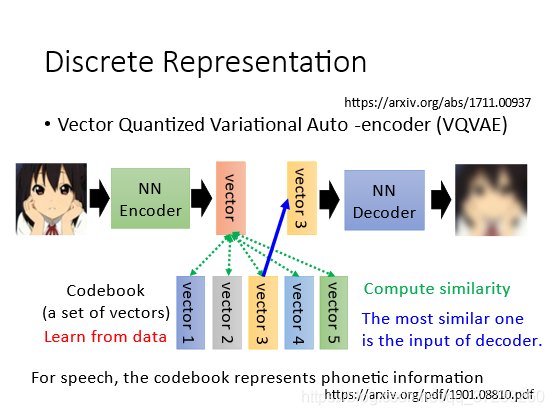
有一些trick來讓你訓練這些沒辦法微分的部分,一般是用強化學習直接做,
6.2.3 Sequence as Embedding
可以讓embedding不再是向量而是句子,比如一個 seq2seq2seq auto-encoder 模型,使用這些sequence 作為code來還原文章,期待這些code可以就是原來那篇文章的摘要或者精簡版本,但是實際上由于encoder和decoder的存在,這些code會參雜一些“暗號”,雖然是文字的組合,但沒有實際含義,如果要讓這些code有實際含義,將會用到GAN的概念,就是預先訓練一個可以識別人類是否能讀懂的句子的discriminator,然后去訓練這些code,使得code具有可讀性:
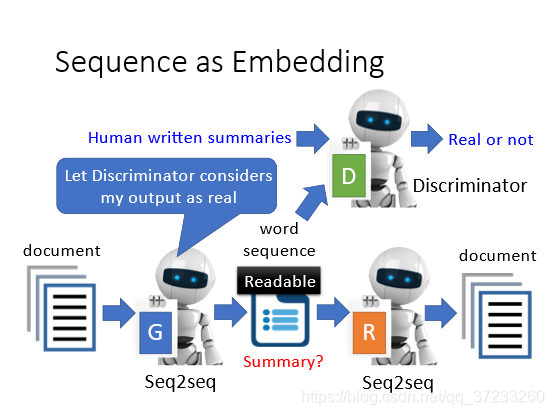
一些實驗的例子:


轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/295456.html
標籤:其他