前言
相信大部分人看完電影或者電視劇之后,都難免會去豆瓣刷刷別人的評論以及打分,來看看這部電影或者電視劇到底如何或者與自己喜惡相同的有哪些人,
那么豆瓣評論與豆瓣評分之間是否有一定的聯系,我們可以訓練BERT中文分類模型,通過輸入豆瓣評論輸出輸出預測的豆瓣評分,觀察其與真實的豆瓣評分是否有差別,
在這個專案中,我們需要做:
- 文本的預處理
- 模型訓練及評估
- 實際資料測驗
首先一起來看看最終實作的豆瓣評分預測效果,以《掃黑風暴》的評論為例:
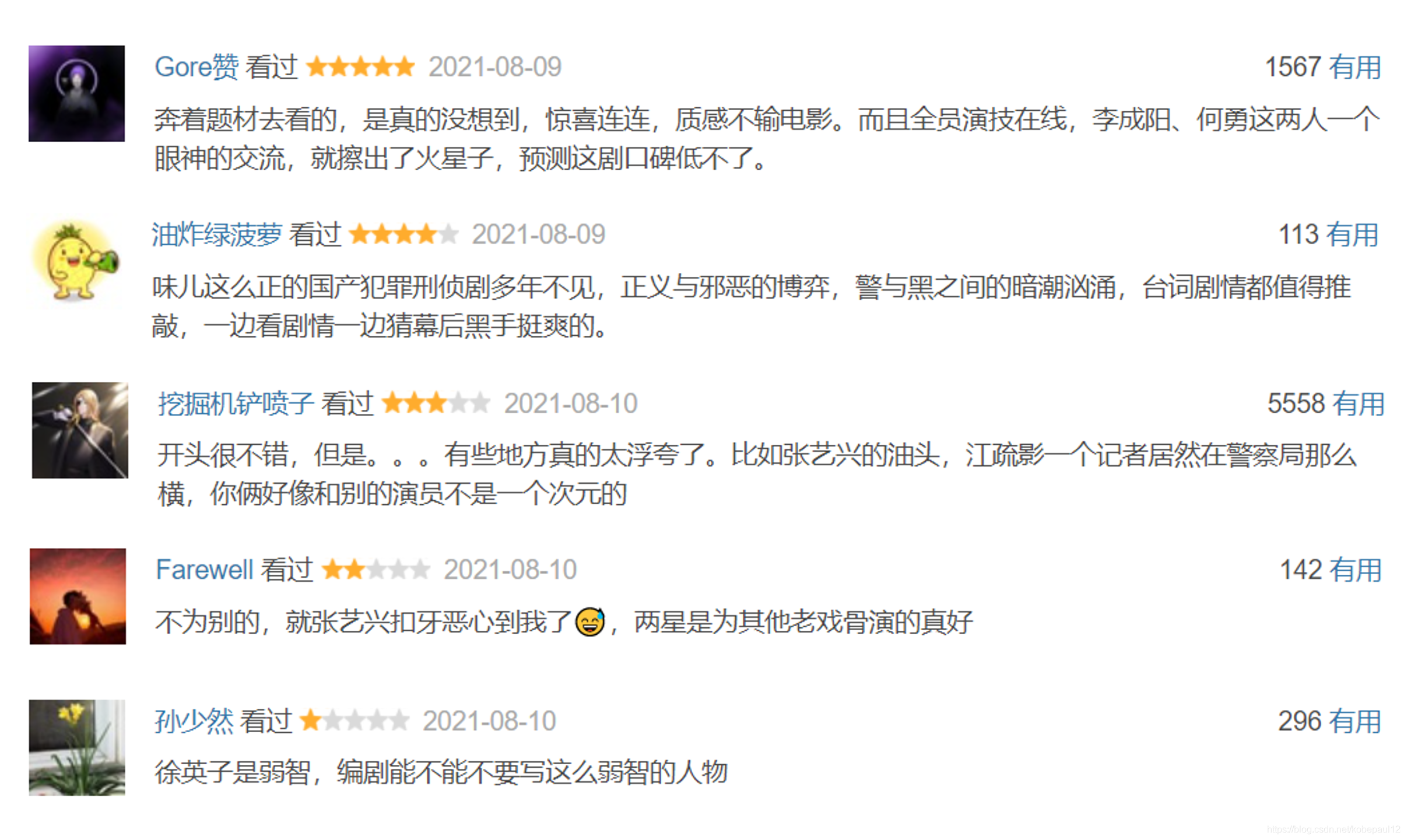
預測結果:

下面,我們就開始介紹如何實作豆瓣評分預測,
一、專案概述
首先我們是基于EasyBert這個github開源專案里面的中文文本分類來實作豆瓣評分預測的,其實這就是個分類問題,
配置相關環境:
python 3.7
pytorch 1.1
tqdm
sklearn
tensorboardX
資料集:
我們豆瓣評論資料集為DMSC.csv格式,而原專案的資料集是從THUCNews中抽取了20萬條新聞標題,文本長度在20到30之間,一共10個類別,每類2萬條,資料以字為單位輸入模型,
THUCNews
├── data
│ ├── train.txt # 訓練集資料
│ ├── test.txt # 測驗資料
│ ├── dev.txt # 驗證資料
│ └── class.txt # 資料類別
└── saved_dict

所以我們接下來需要將豆瓣評論資料進行預處理并保存成一樣的格式,
代碼:
TextClassifier檔案夾下包含三個主要的函式以及models和bert_pretrian檔案夾,models檔案夾下包含bert.py以及ernie.py,bert_pretrian檔案夾中包含預訓練模型,bert.py以及ernie.py里面可以設定模型以及訓練引數,run.py為主函式,在這里設定引數,進行模型訓練,train_eval.py里面是寫好定的具體訓練函式,通過predict.py進行資料分類預測,
具體代碼分析且看下文分解!!!
TextClassifier
├── models
│ ├── bert.py # bert模型
│ └── ernie.py # ernie模型├── bert_pretrain #預訓練模型
│ ├── bert_config.json
│ ├── pytorch_model.bin
│ └── vocab.txt├── run.py
├── predict.py
└── train_eval.py
演算法流程:
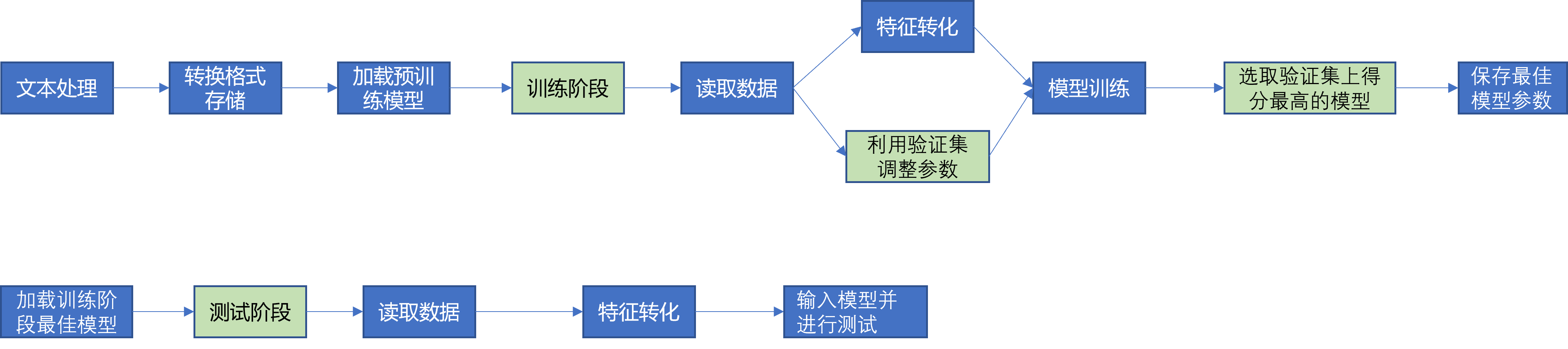
二、文本處理
1.加載資料
由于豆瓣資料為DMSC.csv格式,所以我們通過pd.read_csv函式讀取資料,該函式是用來讀取csv格式的檔案,將表格資料轉化成dataframe格式,
#讀取資料
data = pd.read_csv('DMSC.csv')
#觀察資料格式
data.head()
#輸出資料的一些相關資訊
data.info()
#只保留資料中我們需要的兩列:Comment列和Star列
data = data[['Comment','Star']]
#觀察新的資料的格式
data.head()輸出結果:
| Comment | Star | |
|---|---|---|
| 0 | 連奧創都知道整容要去韓國, | 3 |
| 1 | “一個沒有黑暗面的人不值得信任,” 第二部剝去冗長的鋪墊,開場即高潮、一直到結束,會有人覺... | 4 |
| 2 | 奧創弱爆了弱爆了弱爆了啊!!!!!! | 2 |
| 3 | 與第一集不同,承上啟下,陰郁嚴肅,但也不會不好看啊,除非本來就不喜歡漫威電影,場面更加宏大... | 4 |
| 4 | 看畢,我激動地對友人說,等等奧創要來毀滅臺北怎么辦厚,她拍了拍我肩膀,沒事,反正你買了兩份... | 5 |
2. 文本預處理
由于一開始送訓練資料進入BERT時,提示出現空白字符無法轉換以及label標簽范圍不符合的問題,所以再一次將資料進行預處理,將空白去除以及標簽為評分減一,
def clear_character(sentence):
new_sentence=''.join(sentence.split()) #去除空白
return new_sentence
data["comment_processed"]=data['Comment'].apply(clear_character)
data['label']=data['Star']-1
data.head()輸出結果:
| Comment | Star | comment_processed | label | |
|---|---|---|---|---|
| 0 | 連奧創都知道整容要去韓國, | 3 | 連奧創都知道整容要去韓國, | 2 |
| 1 | “一個沒有黑暗面的人不值得信任,” 第二部剝去冗長的鋪墊,開場即高潮、一直到結束,會有人覺... | 4 | “一個沒有黑暗面的人不值得信任,”第二部剝去冗長的鋪墊,開場即高潮、一直到結束,會有人覺得只... | 3 |
| 2 | 奧創弱爆了弱爆了弱爆了啊!!!!!! | 2 | 奧創弱爆了弱爆了弱爆了啊!!!!!! | 1 |
| 3 | 與第一集不同,承上啟下,陰郁嚴肅,但也不會不好看啊,除非本來就不喜歡漫威電影,場面更加宏大... | 4 | 與第一集不同,承上啟下,陰郁嚴肅,但也不會不好看啊,除非本來就不喜歡漫威電影,場面更加宏大,... | 3 |
| 4 | 看畢,我激動地對友人說,等等奧創要來毀滅臺北怎么辦厚,她拍了拍我肩膀,沒事,反正你買了兩份... | 5 | 看畢,我激動地對友人說,等等奧創要來毀滅臺北怎么辦厚,她拍了拍我肩膀,沒事,反正你買了兩份旅... | 4 |
3.劃分訓練集和測驗集
通過train_test_split()函式進行資料集的劃分,
from sklearn.model_selection import train_test_split
X = data[['comment_processed','label']]
test_ratio = 0.2
comments_train, comments_test = train_test_split(X,test_size=test_ratio, random_state=0)
print(comments_train.head(),comments_test.head)4.保存txt格式
由于BERT里面的存盤格式為txt以及文本加標簽,所以通過dataframe.to_csv函式存盤,
comments_train.to_csv('train.txt', sep='\t', index=False,header=False)
comments_test.to_csv('test.txt', sep='\t', index=False,header=False)輸出結果:

三、BERT模型
1. 特征轉換
在run.py中先將保存好的訓練資料、測驗資料、驗證資料轉化為BERT向量,
print("Loading data...")
train_data, dev_data, test_data = build_dataset(config)
train_iter = build_iterator(train_data, config)
dev_iter = build_iterator(dev_data, config)
test_iter = build_iterator(test_data, config)
time_dif = get_time_dif(start_time)
print("Time usage:", time_dif)
def load_dataset(path, pad_size=32):
contents = []
with open(path, 'r', encoding='UTF-8') as f: # 讀取資料
for line in tqdm(f):
lin = line.strip()
if not lin:
continue
if len(lin.split('\t')) == 2:
content, label = lin.split('\t')
token = config.tokenizer.tokenize(content) # 分詞
token = [CLS] + token # 句首加入CLS
seq_len = len(token)
mask = []
token_ids = config.tokenizer.convert_tokens_to_ids(token)
if pad_size:
if len(token) < pad_size:
mask = [1] * len(token_ids) + [0] * (pad_size - len(token))
token_ids += ([0] * (pad_size - len(token)))
else:
mask = [1] * pad_size
token_ids = token_ids[:pad_size]
seq_len = pad_size
contents.append((token_ids, int(label), seq_len, mask))
return contents呼叫tokenizer,使用tokenizer分割輸入,將資料轉換為特征,
特征中包含4個資料:
- tokens_ids:分詞后每個詞語在vocabulary中的id,補全符號對應的id為0,[CLS]和[SEP]的id分別為101和102,應注意的是,在中文BERT模型中,中文分詞是基于字而非詞的分詞,
- mask:真實字符/補全字符識別符號,真實文本的每個字對應1,補全符號對應0,[CLS]和[SEP]也為1,
- seq_len:句子長度
- label :將label_list中的元素利用字典轉換為index標識,
轉換特征中一個元素的例子是:
輸入:劇情有的承接欠缺,畫面人設很棒, 3
tokens_ids:[101, 1196, 2658, 3300, 4638, 2824, 2970, 3612, 5375, 8024, 4514, 7481, 782, 6392, 2523, 3472, 511, 0,...,0]
mask:[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,...,0]
label:3
seq_len:17
2.模型訓練
完成讀取資料、特征轉換之后,將特征送入模型進行訓練,
訓練演算法為BERT專用的Adam演算法
訓練集、測驗集、驗證集比例為6:2:2
每100輪會在驗證集上進行驗證,并給出相應的準確值,如果準確值大于此前最高分則保存模型引數,否則flags加1,如果flags大于1000,也即連續1000輪模型的性能都沒有繼續優化,停止訓練程序,
for epoch in range(config.num_epochs):
print('Epoch [{}/{}]'.format(epoch + 1, config.num_epochs))
for i, (trains, labels) in enumerate(train_iter):
outputs = model(trains)
model.zero_grad()
loss = F.cross_entropy(outputs, labels)
loss.backward()
optimizer.step()
if total_batch % 100 == 0:
# 每多少輪輸出在訓練集和驗證集上的效果
true = labels.data.cpu()
predic = torch.max(outputs.data, 1)[1].cpu()
train_acc = metrics.accuracy_score(true, predic)
dev_acc, dev_loss = evaluate(config, model, dev_iter)
if dev_loss < dev_best_loss:
dev_best_loss = dev_loss
torch.save(model.state_dict(), config.save_path)
improve = '*'
last_improve = total_batch
else:
improve = ''
time_dif = get_time_dif(start_time)
msg = 'Iter: {0:>6}, Train Loss: {1:>5.2}, Train Acc: {2:>6.2%}, Val Loss: {3:>5.2}, Val Acc: {4:>6.2%}, Time: {5} {6}'
print(msg.format(total_batch, loss.item(), train_acc, dev_loss, dev_acc, time_dif, improve))
model.train()
total_batch += 1
if total_batch - last_improve > config.require_improvement:
# 驗證集loss超過1000batch沒下降,結束訓練
print("No optimization for a long time, auto-stopping...")
flag = True
break
if flag:
break
test(config, model, test_iter)訓練結果:
1245it [00:00, 6290.83it/s]Loading data...
170004it [00:28, 6068.60it/s]
42502it [00:07, 6017.43it/s]
42502it [00:06, 6228.82it/s]
Time usage: 0:00:42
Epoch [1/5]
Iter: 0, Train Loss: 1.8, Train Acc: 3.12%, Val Loss: 1.7, Val Acc: 9.60%, Time: 0:02:14 *
Iter: 100, Train Loss: 1.5, Train Acc: 25.00%, Val Loss: 1.4, Val Acc: 20.60%, Time: 0:05:10 *
...
Iter: 5300, Train Loss: 0.75, Train Acc: 65.62%, Val Loss: 1.0, Val Acc: 50.07%, Time: 2:45:41 *
Epoch [2/5]
Iter: 5400, Train Loss: 1.0, Train Acc: 62.50%, Val Loss: 1.0, Val Acc: 51.02%, Time: 2:48:46
...
Iter: 7000, Train Loss: 0.77, Train Acc: 75.00%, Val Loss: 1.0, Val Acc: 52.84%, Time: 3:38:26
No optimization for a long time, auto-stopping...
Test Loss: 1.0, Test Acc: 50.89%
Precision, Recall and F1-Score...
precision recall f1-score support
1 0.6157 0.5901 0.6026 3706
2 0.5594 0.1481 0.2342 3532
3 0.4937 0.5883 0.5369 9678
4 0.4903 0.5459 0.5166 12899
5 0.6693 0.6394 0.6540 12687
accuracy 0.5543 42502
macro avg 0.5657 0.5024 0.5089 42502
weighted avg 0.5612 0.5543 0.5463 42502
Time usage: 0:02:25從訓練結果可以看出準確率和F1分數最多只能達到60%,其實仔細分析評論也可以知道原因:
相近分數的差異性與評論相關性不大,比如兩分的評論可能有時候與一分三分是一樣的,這就導致很難根據評論準確的預測出分數,但是從測驗結果可以明顯的看出好評和差評能夠明顯區分出來,準確率能達到百分之九十,
3.模型測驗
測驗的時候與訓練同樣的原理,也是先將資料轉化為特征,送入訓練好的模型中,得到結果,
def final_predict(config, model, data_iter):
map_location = lambda storage, loc: storage
model.load_state_dict(torch.load(config.save_path, map_location=map_location))
model.eval()
predict_all = np.array([])
with torch.no_grad():
for texts, _ in data_iter:
outputs = model(texts)
pred = torch.max(outputs.data, 1)[1].cpu().numpy()
pred_label = [match_label(i, config) for i in pred]
predict_all = np.append(predict_all, pred_label)
return predict_all
def main(text):
config = Config()
model = Model(config).to(config.device)
test_data = load_dataset(text, config)
test_iter = build_iterator(test_data, config)
result = final_predict(config, model, test_iter)
for i, j in enumerate(result):
print('text:{}'.format(text[i]))
print('label:{}'.format(j))測驗結果:

總結
本專案基于pytorch的 BERT中文文本分類實作豆瓣評分預測,通過以實際資料測驗,還是有一定的效果,不得不說目前BERT在自然語言處理任務中效果還是杠杠的!
希望能不斷推陳出新,推動NLP進一步發展!!!
今天我們就到這里,明天繼續努力!

如果該文章對您有所幫助,麻煩點贊,關注,收藏三連支持下!
創作不易,白嫖不好,各位的支持和認可,是我創作的最大動力!
如果本篇博客有任何錯誤,請批評指教,不勝感激 !!!
參考:
如何使用BERT實作中文的文本分類(附代碼)
EasyBert,基于Pytorch的Bert應用
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/295459.html
標籤:其他
上一篇:前端 登錄權限 本地快取用戶資訊