文章目錄
- 參考
- 參考概念
- 參考的使用方式:
- 參考特性
- 常參考
- 使用場景
- 傳值、傳參考效率比較
- 參考和指標的區別
參考
參考概念
參考不是新定義一個變數,而是給已存在變數取了一個別名,編譯器不會為參考變數開辟記憶體空間,它和它參考的變數共用同一塊記憶體空間,
比如 : 李逵,在家稱為"鐵牛",江湖上人稱"黑旋風"",

再比如說:講普法的羅翔老師經常談到的張三,網友們送其外號“法外狂徒”,這也是起別名的方式,
參考的使用方式:
型別 & 參考變數名(物件名) = 參考物體;
#include<iostream>
using namespace std;
void TestRef()
{
int a = 10;
int& ra = a;//定義參考型別
cout << a << endl;
cout << ra << endl;
}
int main()
{
TestRef();
return 0;
}
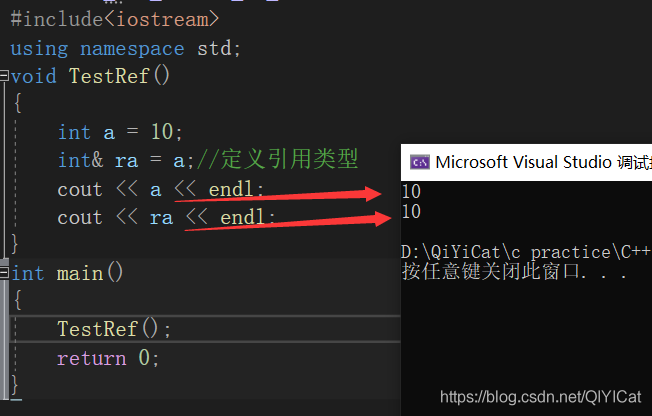
注意:參考型別必須和參考物體是同種型別的
& 在這個地方表示參考,而不是取地址,一個運算子有多種含義,也就是運算子的多載,
注意區分:
型別& 表示參考 (&在型別后面,比如 int& b = a;)
& 變數 表示取地址(&在變數前面,比如 int* pa = &a;)
兩者沒有什么必然的關系,

參考特性
1)參考在定義時必須初始化
2)—個變數可以有多個參考
3)一旦參考—個物體,再不能參考其他物體(參考物件不能更改)
#include<iostream>
using namespace std;
void TestRef()
{
int a = 10;
int b = 20;
//int& ra;//該條陳述句編譯時會報錯
int& ra = a;//定義參考變數的時候就需要給其賦初始值
int& rra = a;//一個變數可以有多個參考
ra = b;//不能更改參考物件,這句實際上是將b的值賦值給ra
cout << a << endl;
cout << ra << endl;
cout << rra << endl;
}
int main()
{
TestRef();
return 0;
}
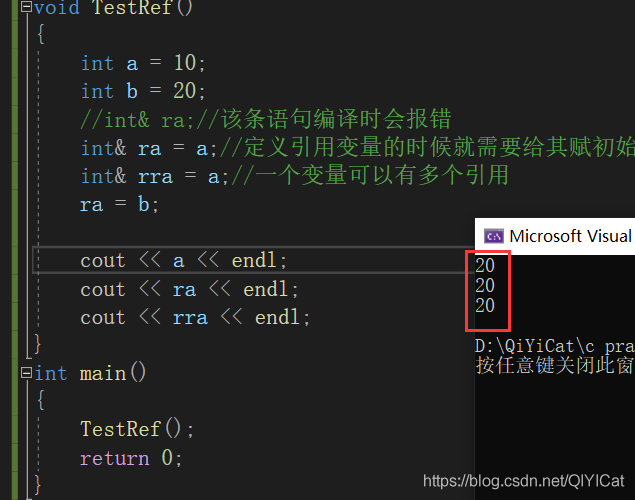
常參考
void TestConstRef()
{
const int a = 10;
//int& ra = a;//該陳述句編譯時會出錯,a為常量
const int& ra = a;
//int& b = 10;//該陳述句編譯時會出錯,b為常量
const int& b = 10;
double d = 12.34;
//int& rd = d;l/該陳述句編譯時會出錯,型別不同
const int& rd = d;
}
當a時const int型別時,表示a是一個常變數,常變數具有常屬性-- - 值不可改變,這時候如果用int & 來參考a,就會得到一個int型別的別名,這個別名是普通的變數,可以修改,就有可能會改變a的值,造成a常變數被修改的沖突!所以為了避免這個沖突,在參考const int 型別的a變數時,應該用 const int& b = a;
總結:參考取別名時,變數訪問的權限可以縮小(如 const int -> int ),不能放大(如 const int -> int ),
不能放大權限:不能將const型別的變數給非const型別的別名
可以權限縮小:即可以將非const型別的變數給非const型別的別名,也可以給const型別的別名,
提示:權限的縮小和放大,僅適用于參考和指標
const int a = 10;
int* p = &a;//這種不行,權限的放大
const int* pa = &a;//需要這種形式
int c = 1;
const int* pc = &c;//可以,屬于權限的縮小
注意區分:
const int a = 10;
int& b = a;//這種是不行的,b是a的別名
const int x = 10;
int y = x;//這種是可以的,y和x沒什么關系
//這種是不受影響的
#include<iostream>
using namespace std;
int main()
{
int i = 1;
double d = i;//隱式型別轉換
double& ri = i;//可以這樣取別名嗎? error
const double& rri = i;//這樣呢?ok
return 0;
}
double d = I; 這句話是先產生了一個double的臨時變數
double& ri = I; 也是一個會先產生一個double型別的臨時變數,然后真正參考的是這個臨時變數,而這個臨時變數具有常屬性,所以直接用double& 不可以,加上const又ok了,

使用場景
1.做引數 (①輸出型引數 ②提高效率)
#include<iostream>
using namespace std;
void Swap(int& left, int& right)
{
int temp = left;
left = right;
right = temp;
}
int main()
{
int a = 1;
int b = 2;
Swap(a, b);
cout << a << " " << b << endl;
return 0;
}
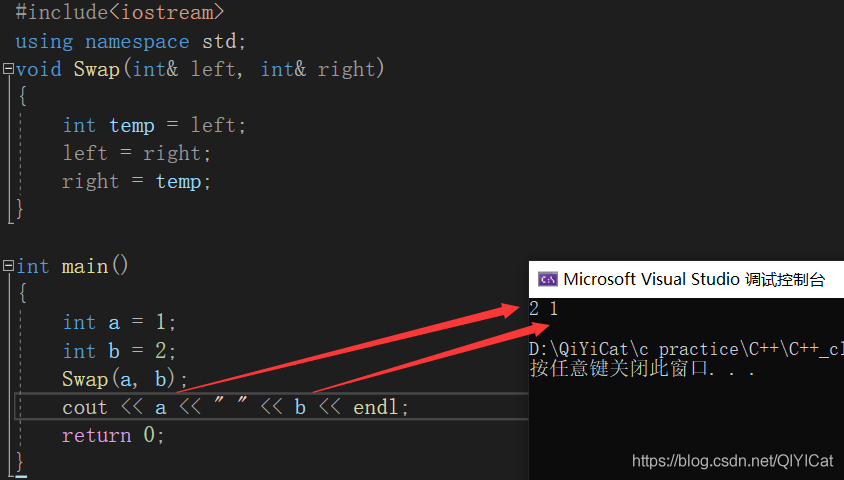
問:不是說參考定義的時候需要初始化嗎?這里并沒有初始化?
答:這個地方的參考并不是定義,什么時候才是定義呢?傳參的時候才是定義,傳參過來就會進行初始化操作,
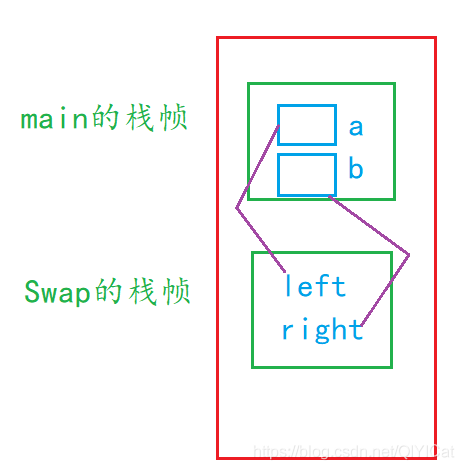
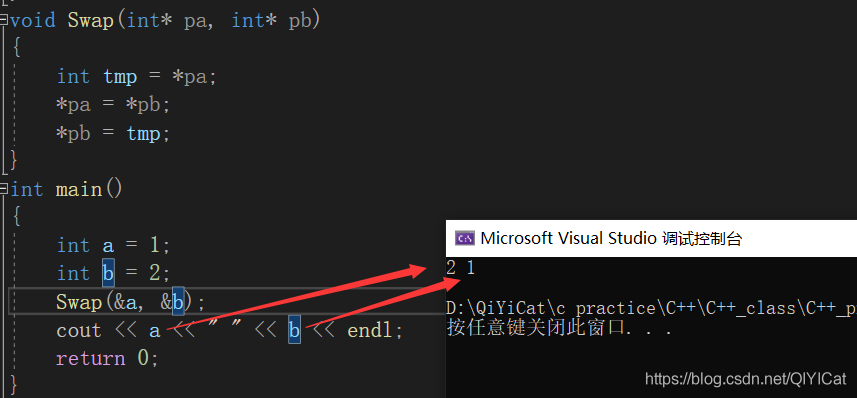
當然這里也可以用指標的方式來實作:
#include<iostream>
using namespace std;
void Swap(int* pa, int* pb)
{
int tmp = *pa;
*pa = *pb;
*pb = tmp;
}
int main()
{
int a = 1;
int b = 2;
Swap(&a, &b);
cout << a << " " << b << endl;
return 0;
}
2.做回傳值 (①提高效率 ②以后再講)
int& Count()
{
static int n = 0;
n++;
// ...
return n;
}
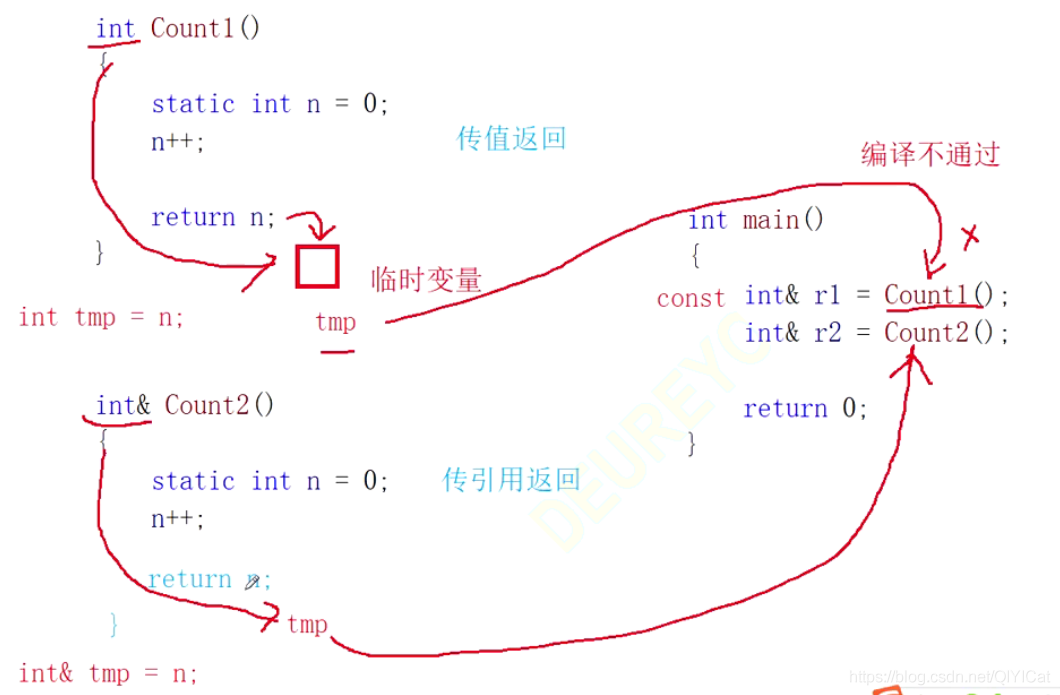
凡是傳值的方式(引數傳值、傳值回傳),都會產生一個拷貝的臨時變數,傳參考的方式不會,
static 改變變數的生命周期,不會修改變數的訪問權限
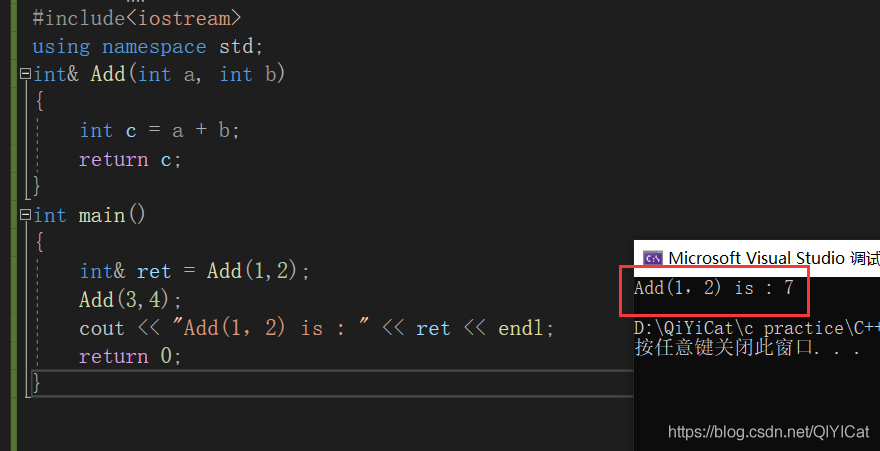
下面代碼輸出什么結果 ? 為什么 ?
#include<iostream>
using namespace std;
int& Add(int a, int b)
{
int c = a + b;
return c;
}
int main()
{
int& ret = Add(1, 2);
Add(3, 4);
cout << "Add(1,2) is : " << ret << endl;
return 0;
}
注意:如果函式回傳時,出了函式作用域,如果回傳物件還未還給系統,則可以使用參考回傳,如果已經還給系統了,則必須使用傳值回傳,(說明參考回傳說不安全的!)

那么使用參考回傳有什么好處呢?
可以少創建一個臨時變數,提高程式(傳遞)的效率
其實還有一個作用,以后會講(很多庫函式的回傳也會用參考回傳)
傳值、傳參考效率比較
以值作為引數或者回傳值型別,在傳參和回傳期間,函式不會直接傳遞實參或者將變數本身直接回傳,而是傳遞實參或者回傳變數的一份臨時的拷貝,因此用值作為引數或者回傳值型別,效率是非常低下的,尤其是當引數或者回傳值型別非常大時,效率就更低,
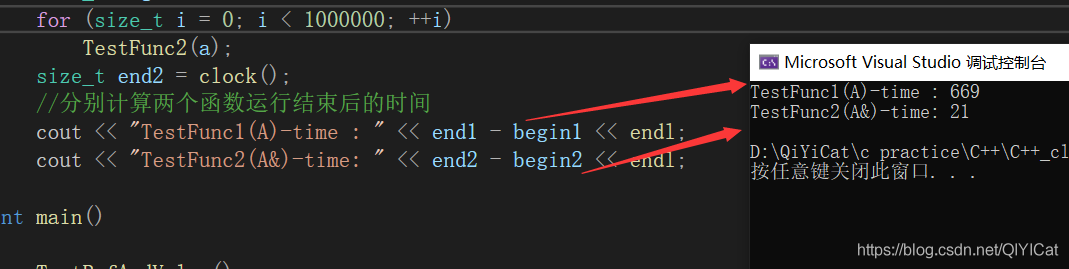
值和參考的作為引數的性能比較
#include<iostream>
using namespace std;
#include <time.h>
struct A
{
int a[10000];
};
void TestFunc1(A a)
{
}
void TestFunc2(A& a)
{
}
void TestRefAndValue()
{
A a;
//以值作為函式引數
size_t begin1 = clock();
for (size_t i = 0; i < 1000000; ++i)
TestFunc1(a);
size_t end1 = clock();
//以參考作為函式引數
size_t begin2 = clock();
for (size_t i = 0; i < 1000000; ++i)
TestFunc2(a);
size_t end2 = clock();
//分別計算兩個函式運行結束后的時間
cout << "TestFunc1(A)-time : " << end1 - begin1 << endl;
cout << "TestFunc2(A&)-time: " << end2 - begin2 << endl;
}
int main()
{
TestRefAndValue();
return 0;
}
值和參考的作為回傳值型別的性能比較
#include<iostream>
using namespace std;
#include <time.h>
struct A
{
int a[10000];
};
A a;
A TestFunc1()
{
return a;
}
A& TestFunc2()
{
return a;
}
void TestRefAndValue()
{
A a;
//以值作為函式的回傳值型別
size_t begin1 = clock();
for (size_t i = 0; i < 1000000; ++i)
TestFunc1();
size_t end1 = clock();
//以參考作為函式的回傳值型別
size_t begin2 = clock();
for (size_t i = 0; i < 1000000; ++i)
TestFunc2();
size_t end2 = clock();
//分別計算兩個函式運行結束后的時間
cout << "TestFunc1()-time : " << end1 - begin1 << endl;
cout << "TestFunc2()-time: " << end2 - begin2 << endl;
}
int main()
{
TestRefAndValue();
return 0;
}

通過上述代碼的比較,發現傳值和指標在作為傳參以及回傳值型別上效率相差很大,
參考和指標的區別
在語法概念上參考就是一個別名,沒有獨立空間,和其參考物體共用同一塊空間,
#include<iostream>
using namespace std;
int main()
{
int a = 10; int& ra = a;
cout << "&a = " << &a << endl;
cout << "&ra = " << &ra << endl;
return 0;
}
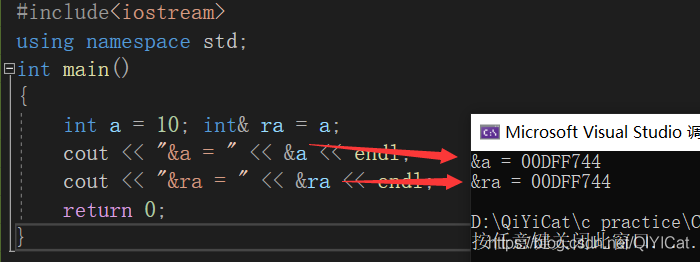
在底層實作上實際是有空間的,因為參考是按照指標方式來實作的,
#include<iostream>
using namespace std;
int main()
{
int a = 10;
int& b = a;
int* p = &a;
return 0;
}
我們來看下參考和指標的匯編代碼對比:
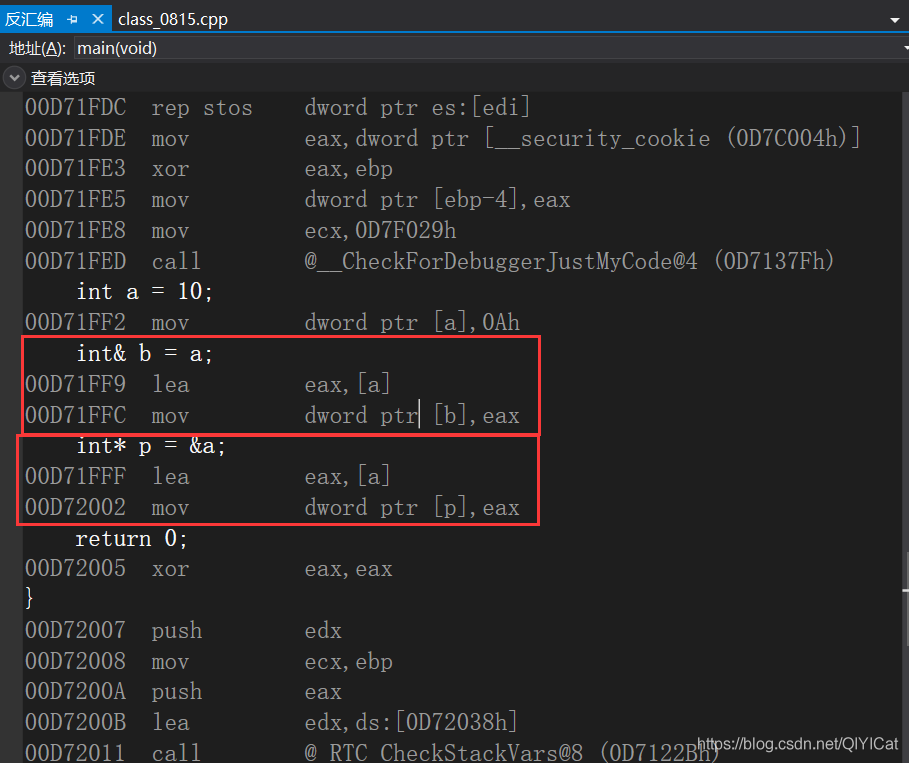
參考和指標都是存放地址
參考和指標的不同點 :
1.參考在定義時必須初始化,指標沒有要求
2.參考在初始化時參考一個物體后,就不能再參考其他物體,而指標可以在任何時候指向任何一個同型別物體
3.沒有NULL參考,但有NUL指標
4.在sizeof中含義不同 : 參考結果為參考型別的大小,但指標始終是地址空間所占位元組個數(32位平臺下占4個位元組)
5.參考自加即參考的物體增加1,指標自加即指標向后偏移一個型別的大小
6.有多級指標,但是沒有多級參考
7.訪問物體方式不同,指標需要顯式解參考,參考編譯器自己處理
8.參考比指標使用起來相對更安全
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/295699.html
標籤:其他
上一篇:拒絕B站邀約,從月薪3k到年薪47W,我的經驗值得每一個測驗人借鑒
下一篇:【LeetCode】一個整型陣列里除兩個數字之外,其他數字都出現了兩次,請找出這兩個只出現一次的數字(劍指 Offer 56 - I. 陣列中數字出現的次數) | 陣列、分組異或