本文的排序演算法都用升序來講解,
常見的排序演算法有:
- 插入排序 —— 直接插入排序 && 希爾排序
- 選擇排序 —— 選擇排序 && 堆排序
- 交換排序 —— 冒泡排序 && 快速排序
- 歸并排序
- 基數排序
- 計數排序 (非比較排序)
插入排序
插入排序就像摸一張牌插入到正確的位置,
假設 [0, end] 有序, end+1 位置的插入到 [0, end] 中, 讓 [0, end+1] 有序,
void InsertSort(int* a, int n)
{
for (int i = 0; i < n - 1; ++i)
{
//單趟排序
int end = i;
int tmp = a[end + 1];
while (end >= 0)
{
if (a[end] > tmp)
{
a[end + 1] = a[end];
--end;
}
else
{
break;
}
}
a[end + 1] = tmp;
}
}
時間復雜度:O(N^2)
最壞情況下移動:1 + 2 + …… + n-1
最好情況:完全順序有序 時間復雜度 是 O(N)
穩定性: 穩定
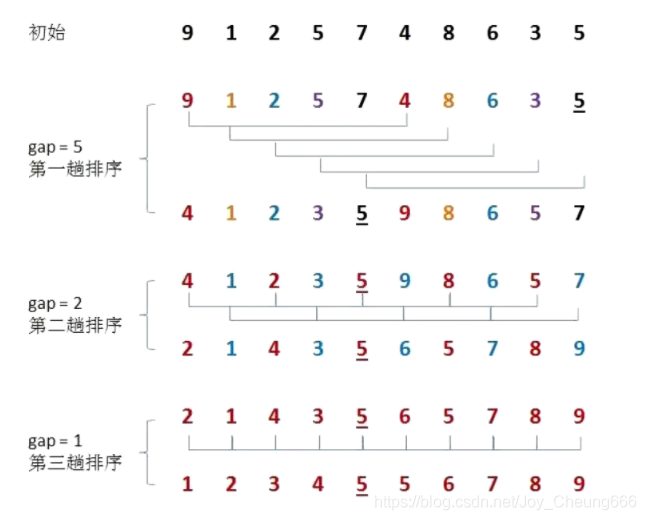
希爾排序
希爾排序是在直接插入排序基礎上的優化排序演算法,
- 進行預排序,讓陣列接近有序,預排序,就是分組(gap > 1)
- 直接插入排序(gap == 1)
void ShellSort(int* a, int n)
{
int gap = n;
while (gap > 1)
{
gap = gap / 2;
//間隔為gap的多組資料同時排序
for (int i = 0; i < n - gap; ++i)
{
//一個gap里的一組資料
int end = i;
int tmp = a[end + gap];
while (end >= 0)
{
if (a[end] > tmp)
{
a[end + gap] = a[end];
end -= gap;
}
else
{
break;
}
}
a[end + gap] = tmp;
}
}
}
時間復雜度:
gap = gap/ 2 時, 是logN
gap = gap/3 + 1時, 是log3N
當gap很大的時候,預排序的時間復雜度是 O(N),
當gap很小的時候,陣列已經接近有序了,時間復雜度是 O(N),
所以時間復雜度是 O(logNN) 或者 O(log3NN)
平均的時間復雜度是O(N^1.3)
直接選擇排序
基本思想:每一次從待排序的資料元素中選出最小(或最大)的一個元素,存放在序列的起始位置,直到全部待排序的資料元素排完,
- 在元素集合 array[i] ~ array[n-1]中選擇最大(小)的元素
- 若它不是這組元素中的最后一個(第一個)元素,則將它與這組元素中的最后一個(第一個)元素交換,
- 在剩余的array[i] ~array[n-2] (array[i+1] ~ array[n-1])集合中,重復上述步驟,直到集合剩余1個元素,
下面實作的是選出最大和最小的數,一起進行排序,
void SelectSort(int* a, int n)
{
int begin = 0, end = n - 1;
while (begin < end)
{
int mini = begin, maxi = end;
//單趟選擇排序
//找出最大,最小的下標
for (int i = begin; i <= end; i++)
{
if (a[i] < a[mini])
{
mini = i;
}
if (a[i] > a[maxi])
{
maxi = i;
}
}
//最小值、最大值分別和begin、end交換
Swap(&a[begin], &a[mini]);
//如果begin和maxi重合,要把mini賦值給maxi
if (begin == maxi)
{
maxi = mini;
}
Swap(&a[end], &a[maxi]);
++begin;
--end;
}
}
時間復雜度: O(N^2)
堆排序
堆的邏輯結構:完全二叉樹
物理結構:陣列(層序)
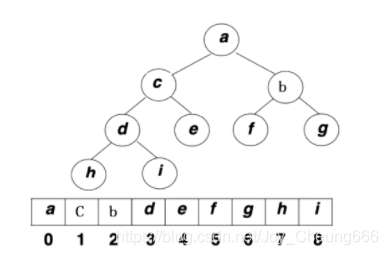
通過觀察可以得出父子結點的關系:
leftchild = parent *2 + 1
rightchild = parent *2 + 2
parent = (child - 1) / 2
大堆中,樹中所有的父親都大于等于孩子,小堆中,樹中所有的父親都小于等于孩子,
向下調整演算法

在這里,我們先引入向下調整演算法(建堆用),以建小堆為例,這里說一句很重要的事情!!!向下調整演算法建立小堆的前提條件是 左右子樹都是小堆,演算法思想是從根結點開始,選出左右子樹中小的那一個,和父結點比較,如果比父結點要小就交換,然后繼續向下進行調整,知道葉子節點終止,
建大堆代碼
// 建大堆
void AdjustDown(int* a, int n, int root)
{
int parent = root;
int child = parent * 2 + 1; //默認是左節點
while (child < n)
{
//選出左右孩子中大的那一個
if (child + 1 < n && a[child + 1] > a[child])
{
++child;
}
if (a[child] > a[parent])
{
Swap(&a[child], &a[parent]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
自底而上的建堆方式
向下調整演算法是建堆的單趟步驟,如果左右子樹不是小堆,是不能直接使用向下調整演算法的,這時候我們應該怎么辦呢?
—— 倒著從最后一棵子樹開始調整, 但是再想一想,倒著走最后一棵子樹葉子是不需要調整的,所以最后決定從倒數最后一個非葉子的子樹開始調整,
下面是建堆的代碼
// 建堆
for (int i = (n - 1 - 1) / 2; i >= 0; --i)
{
AdjustDown(a, n, i);
}
到了這時候,會有一個疑問,排升序,是建大堆還是建小堆?
如果是建小堆,最小數在堆頂,被選出來之后,用剩余的樹再去選數,剩下樹的結構都亂了,需要重新建堆,建堆的時間復雜度是O(N),這樣不是不可以,但是堆排序就沒有效率的優勢了,整體的時間復雜度是O(N^2),
正確的方法是建大堆,第一個數和最后一個數交換,不把這個數當作樹的一部分,前n-1個數向下調整,選出次小的數,再和倒數第二個數交換……
實作的代碼
void HeapSort(int* a, int n)
{
// 建堆 時間復雜度:O(N)
for (int i = (n - 1 - 1) / 2; i >= 0; --i)
{
AdjustDwon(a, n, i);
}
// 排升序,建大堆還是小堆?建大堆
int end = n - 1;
while (end > 0)
{
Swap(&a[0], &a[end]);
AdjustDwon(a, end, 0);
--end;
}
}
時間復雜度: O(N*log N)
冒泡排序
這個是最基本的排序演算法,兩層回圈,外層回圈代表排序的趟數,內層回圈代表比較次數,這里設定一個變數區分陣列是否已經有序,
void BubbleSort(int* a, int n)
{
for (int i = 0; i < n - 1; i++)
{
int exchange = 0;
for (int j = 0; j < n - i - 1; j++)
{
if (a[j] > a[j + 1])
{
Swap(&a[j], &a[j + 1]);
exchange = 1;
}
}
if (!exchange)
break;
}
}
時間復雜度:O(N*N)
最好情況:O(N)
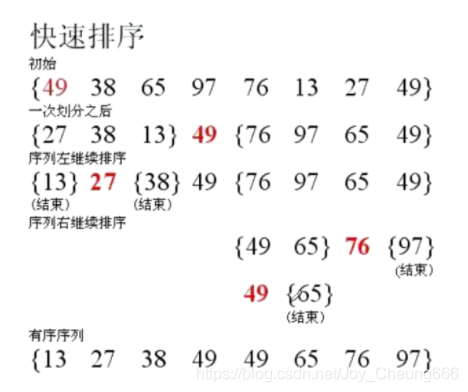
快速排序
基本思想:選擇一個key關鍵字(一般是第一個或者是最后一個),左邊的數都比key要小,右邊的key都大,
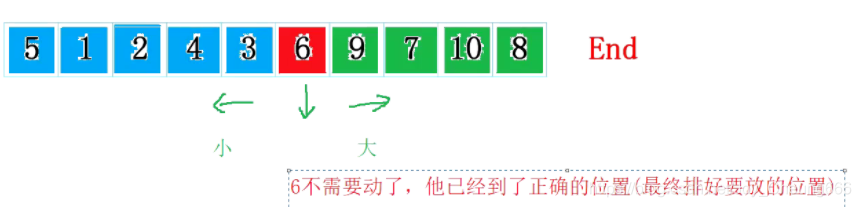
之后只需要對左邊的數和右邊的數進行排序,
對于單趟排序有三種常見的方法,分別是挖坑法,左右指標,前后指標,
快排在有序的情況下情況最壞,最壞情況下退化成冒泡排序,時間復雜度是O(N^2),針對這種情況,使用三數取中和小區間優化的方法對原有的快速排序進行優化,
三數取中避免出現key的值是最小或者最大的情況,
代碼:
int GetMidIndex(int* a, int left, int right)
{
int mid = (left + right) >> 1;
if (a[left] < a[mid])
{
if (a[mid] < a[right])
{
return mid;
}
else if (a[left] > a[right])
{
return left;
}
else
{
return right;
}
}
else //a[left] > a[mid]
{
if (a[mid] > a[right])
{
return mid;
}
else if (a[left] > a[right])
{
return right;
}
else
{
return left;
}
}
這里的快速排序采用的是分治演算法,到每組的數分到后面的時候,呼叫的堆疊幀是以2的指數次增長的,所以采用小區間采用插入排序的方法,
下面,我們只需要考慮單趟排序,前面已經提到過單趟排序有三種方法,下面會詳細介紹,
函式介面
void QuickSort(int* a, int left, int right)
{
if (left <= right)
{
return;
}
int keyindex = PartSort1(a, left, right);
//[left, keyIndex - 1] keyIndex[keyIndex + 1, right]
//QuickSort(a, left, keyindex - 1);
//QuickSort(a, keyindex + 1, right);
//小區間優化
if (keyindex - 1 - left > 10)
{
QuickSort(a, left, keyindex - 1);
}
else
{
InsertSort(a + left, keyindex - left);
}
if (right - (keyindex + 1) > 10)
{
QuickSort(a, keyindex + 1, right);
}
else
{
InsertSort(a + keyindex + 1, right - (keynidex + 1) + 1);
}
}
挖坑法
- 右邊找比key的值小的數,放到左邊,小的數放到左邊的坑里,自己形成新的坑位
- 左邊找比key的值大的數,放到右邊,大的數放到右邊的坑里,自己形成新的坑位
代碼實作
int PartSort1(int* a, int left, int right)
{
int index = GetMidIndex(a, left, right);
Swap(&a[left], &a[index]);
int begin = left, end = right;
int pivot = begin;
int key = a[begin];
while (begin < end)
{
//右邊找小,放到左邊
while (begin < end && a[end] >= key)
{
--end;
}
//小的放到左邊的坑位,自己原本的位置形成新的坑位
a[pivot] = a[end];
pivot = end;
//左邊找大,放到右邊
while (begin < end && a[begin] <= key)
{
++begin;
}
//大的放到右邊的坑位,自己形成新的坑位
a[pivot] = a[begin];
pivot = begin;
}
a[pivot] = key;
return pivot;
}
左右指標法
基本思想:
- begin從左邊開始找大,end從右邊開始找小,找到一大一小就交換,
- 最后,交換begin和keyi的值,回傳相遇的下標
int PartSort2(int* a, int left, int right)
{
int index = GetMidIndex(a, left, right);
Swap(&a[left], &a[index]);
int begin = left, end = right;
int keyi = begin;
while (begin < end)
{
//右邊找小
while (begin < end && a[end] >= a[keyi])
{
--end;
}
//左邊找大
while (begin < end && a[begin] <= a[keyi])
{
++begin;
}
//交換
Swap(&a[begin], &a[end]);
}
Swap(&a[begin], &a[keyi]);
return begin;
}
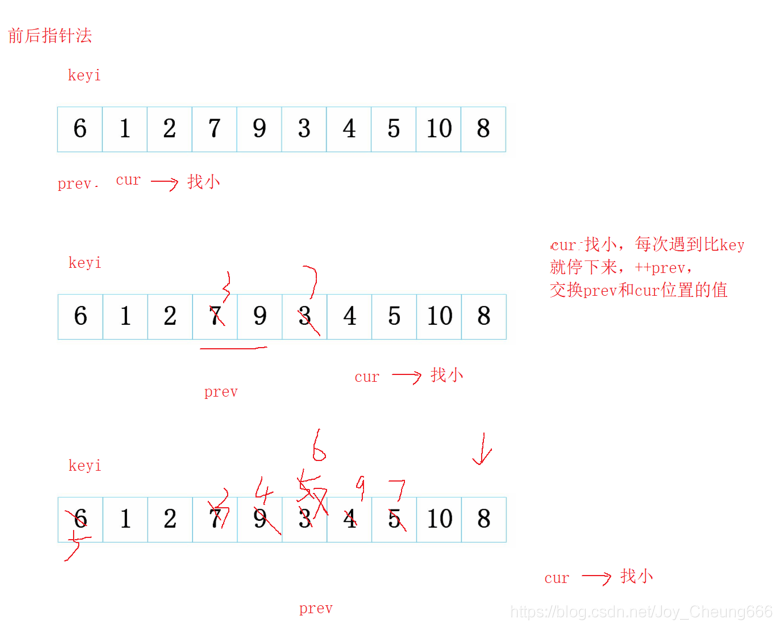
前后指標法
- cur找比key小的數,每次遇到比key小的值就停下來,++prev,交換prev和cur位置的值,++cur,
- 交換keyi和prev對應的值,
int PartSort3(int* a, int left, int right)
{
int index = GetMidIndex(a, left, right);
Swap(&a[left], &a[index]);
int keyi = left;
int prev = left, cur = left + 1;
while (cur <= right)
{
if (a[cur] < a[keyi] && ++prev != cur)
{
Swap(&a[prev], &a[cur]);
}
++cur;
}
Swap(&a[keyi], &a[prev]);
return prev;
}
歸并排序
基本思想:
歸并排序(MERGE-SORT)是建立在歸并操作上的一種有效的排序演算法,該演算法是采用分治法的一個非常典型的應用,將已有的子序列合并,得到完全有序的序列;即先使每個子序列有序,再使子序列段間有序,若將兩個有序表合并成一個有序表,稱為二路歸并,
遞回解法
void _MergeSort(int* a, int left, int right, int* tmp)
{
if (left >= right)
return;
//分解
int mid = (right + left) >> 1;
//[left, mid] [mid+1, right]
//假設左右區間有序,可以開始歸并
_MergeSort(a, left, mid, tmp);
_MergeSort(a, mid + 1, right, tmp);
//歸并
int begin1 = left, end1 = mid;
int begin2 = mid + 1, end2 = right;
int index = left;
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] < a[begin2])
{
tmp[index++] = a[begin1++];
}
else
{
tmp[index++] = a[begin2++];
}
}
while (begin1 <= end1)
{
tmp[index++] = a[begin1++];
}
while (begin2 <= end2)
{
tmp[index++] = a[begin2++];
}
//拷貝回到原陣列
for (int i = left; i <= right; ++i)
{
a[i] = tmp[i];
}
}
void MergeSort(int* a, int n)
{
int* tmp = (int*)malloc(sizeof(int) * n);
_MergeSort(a, 0, n - 1, tmp);
free(tmp);
}
非遞回解法
設定gap來模擬陣列分解之后歸并的程序,gap從1開始,每次乘2遞增,

void MergeSortNonR(int* a, int n)
{
int* tmp = (int*)malloc(sizeof(int) * n);
int gap = 1; //每組資料的個數
while (gap < n)
{
for (int i = 0; i < n; i += 2 * gap)
{
int begin1 = i, end1 = i + gap - 1;
int begin2 = i + gap, end2 = i + 2 * gap - 1;
//歸并程序中右半區間不存在
if (begin2 >= n)
{
break;
}
//歸并程序中右半區間不足,修正一下
if (end2 >= n)
{
end2 = n - 1;
}
int index = i;
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] < a[begin2])
{
tmp[index++] = a[begin1++];
}
else
{
tmp[index++] = a[begin2++];
}
}
while (begin1 <= end1)
{
tmp[index++] = a[begin1++];
}
while (begin2 <= end2)
{
tmp[index++] = a[begin2++];
}
// 拷貝回去
for (int j = i; j <= end2; ++j)
{
a[j] = tmp[j];
}
}
gap *= 2;
}
free(tmp);
}
基數排序
123 45 12 9 88 43
依次分別取他們的個位、十位、百位……排序
個位: 12 123 43 45 88 9
十位:9 12 123 43 45 88
百位:以此類推
只能對整數進行排序,實際中這個排序沒啥意義,
計數排序
計數排序是一種非比較排序,思想很巧,適用范圍具有局限性,適合范圍集中的一組整形資料排序,
void CountSort(int* a, int n)
{
int max = a[0], min = a[0];
for (int i = 0; i < n; ++i)
{
if (a[i] > max)
{
max = a[i];
}
if (a[i] < min)
{
min = a[i];
}
}
int range = max - min + 1;
int* count = (int*)malloc(sizeof(int)*range);
memset(count, 0, sizeof(int)*range);
// 統計次數
for (int i = 0; i < n; ++i)
{
count[a[i]-min]++;
}
int j = 0;
for (int i = 0; i < range; ++i)
{
while (count[i]--)
{
a[j++] = i+min;
}
}
free(count);
}
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/295705.html
標籤:其他