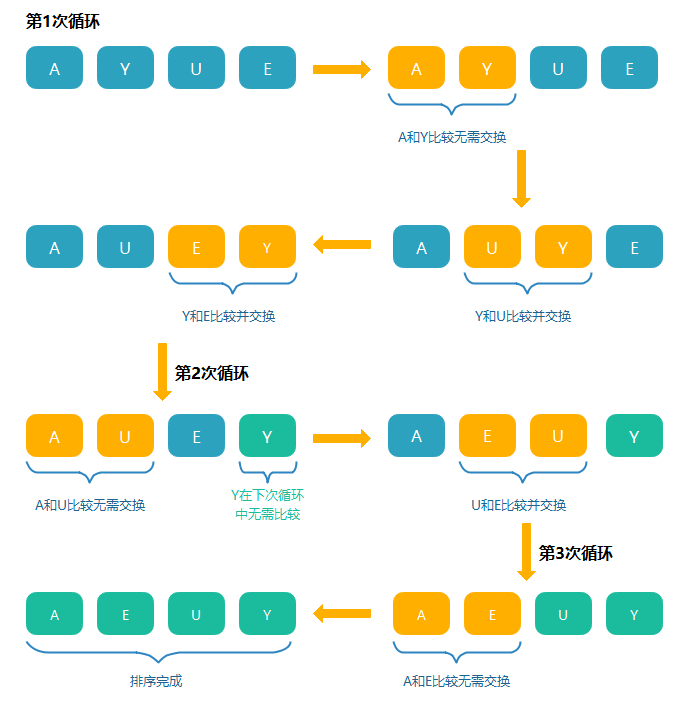
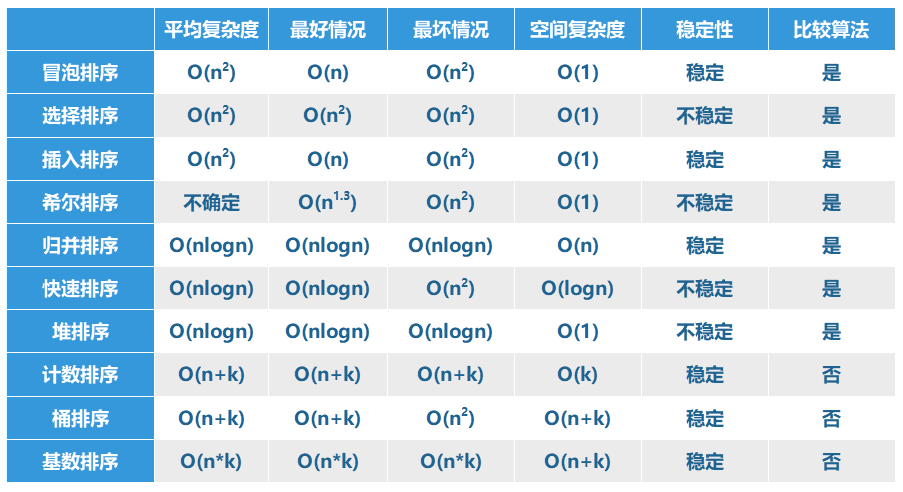
冒泡排序
- 從陣列頭開始,比較相鄰的元素,如果第一個比第二個大(小),就交換它們兩個
- 對每一對相鄰元素作同樣的作業,從開始第一對到尾部的最后一對,這樣在最后的元素應該會是最大(小)的數
- 重復步驟1~2,重復次數等于陣列的長度,直到排序完成
代碼實作
對下面陣列實作排序:{24, 7, 43, 78, 62, 98, 82, 18, 54, 37, 73, 9}
代碼實作
public class BubbleSort {
public static final int[] ARRAY = {24, 7, 43, 78, 62, 98, 82, 18, 54, 37, 73, 9};
public static void main(String[] args) {
print(ARRAY);
System.out.println("============================================");
print(sort(ARRAY));
}
public static int[] sort(int[] array) {
if (array.length == 0) {
return array;
}
for (int i = 0; i < array.length; i++) {
//array.length - 1 -i 已經冒泡到合適位置無需在進行排序,減少比較次數
for (int j = 0; j < array.length - 1 -i; j++) {
//前面的數大于后面的數交換
if (array[j + 1] < array[j]) {
int temp = array[j + 1];
array[j + 1] = array[j];
array[j] = temp;
}
}
}
return array;
}
public static void print(int[] array) {
for (int i : array) {
System.out.print(i + " ");
}
System.out.println("");
}
}
時間復雜度
對于上面12個資料項,從第一個元素開始,第一趟比較了11次,第二趟比較了10次,依次類推,一直到最后一趟,就是:
11 + 10 + 9 + 8 + 7 + 6 + 5 + 4 + 3 + 2 + 1 = 66次
若有n個元素,則第一趟比較為(n-1)次,第二趟比較為(n-2)次,依次類推:
(n-1) + (n-2) + (n-3) + ...+ 2 + 1 = n * (n-1)/2
在大O表示法中,去掉常數系數和低階項,該排序方式的時間復雜度為:O(n2)
演算法穩定性
假定在待排序的記錄序列中,存在多個具有相同的關鍵字的記錄,若經過排序,這些記錄的相對次序保持不變,即在原序列中,r[i]=r[j],且r[i]在r[j]之前,而在排序后的序列中,r[i]仍在r[j]之前,則稱這種排序演算法是穩定的;否則稱為不穩定的,——百度百科
在代碼中可以看到,array[j + 1] = array[j]的時候,我們可以不移動array[i]和array[j],所以冒泡排序是穩定的,
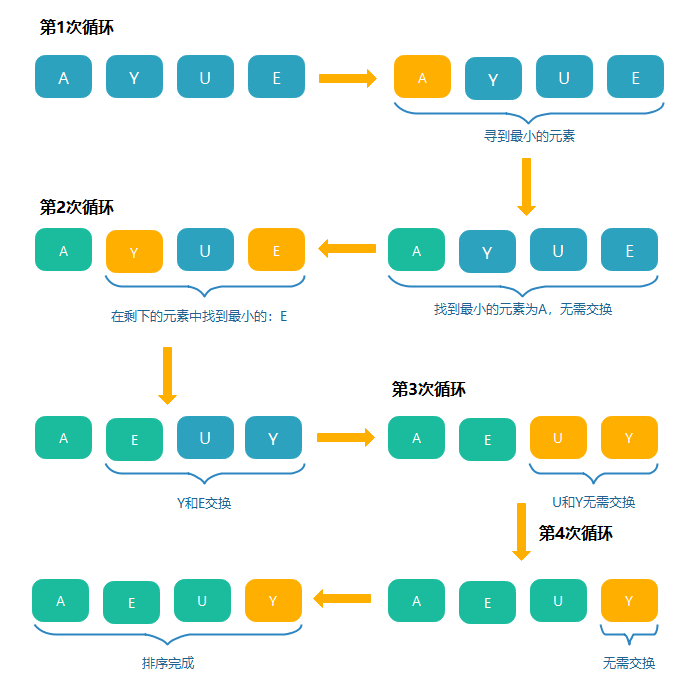
選擇排序
- 找到陣列中最大(或最小)的元素
- 將它和陣列的第一個元素交換位置(如果第一個元素就是最大(小)元素那么它就和自己交換)
- 在剩下的元素中找到最大(小)的元素,將它與陣列的第二個元素交換位置,如此往復,直到將整個陣列排序,
代碼實作
對下面陣列實作排序:{87, 23, 7, 43, 78, 62, 98, 81, 18, 53, 73, 9}
動圖演示

代碼實作
public class SelectionSort {
public static final int[] ARRAY = {87, 23, 7, 43, 78, 62, 98, 81, 18, 53, 73, 9};
public static int[] sort(int[] array) {
if (array.length == 0) {
return array;
}
for (int i = 0; i < array.length; i++) {
//最小數的下標,每個回圈開始總是假設第一個數最小
int minIndex = i;
for (int j = i; j < array.length; j++) {
//找到最小索引
if (array[j] < array[minIndex]) {
//保存最小索引
minIndex = j;
}
}
//最小索引的值
int temp = array[minIndex];
array[minIndex] = array[i];
array[i] = temp;
}
return array;
}
public static void print(int[] array) {
for (int i : array) {
System.out.print(i + " ");
}
System.out.println("");
}
public static void main(String[] args) {
print(ARRAY);
System.out.println("============================================");
print(sort(ARRAY));
}
}
時間復雜度
很明顯,和冒泡排序相比,在查找最小(或最大)元素的索引,比較次數仍然保持為O(n2)
,但元素交換次數為O(n),
演算法穩定性
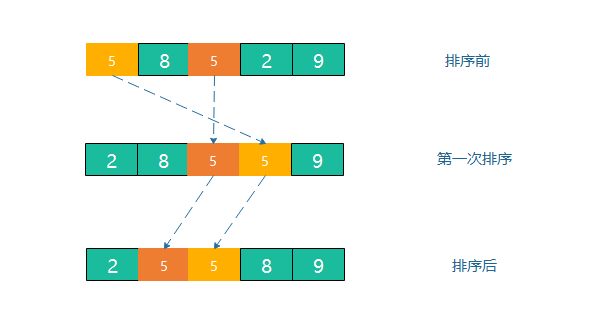
選擇排序是給每個位置選擇當前元素最小的,比如給第一個位置選擇最小的,在剩余元素里面給第二個元素選擇第二小的,依次類推,直到第n-1個元素,第n個元素不用選擇了,因為只剩下它一個最大的元素了,那么,在一趟選擇,如果一個元素比當前元素小,而該小的元素又出現在一個和當前元素相等的元素后面,那么交換后穩定性就被破壞了,舉個例子,陣列5,8,5,2,9,我們知道第一遍選擇第1個元素5會和2交換,那么原序列中兩個5的相對前后順序就被破壞了,所以選擇排序是一個不穩定的排序演算法,
插入排序
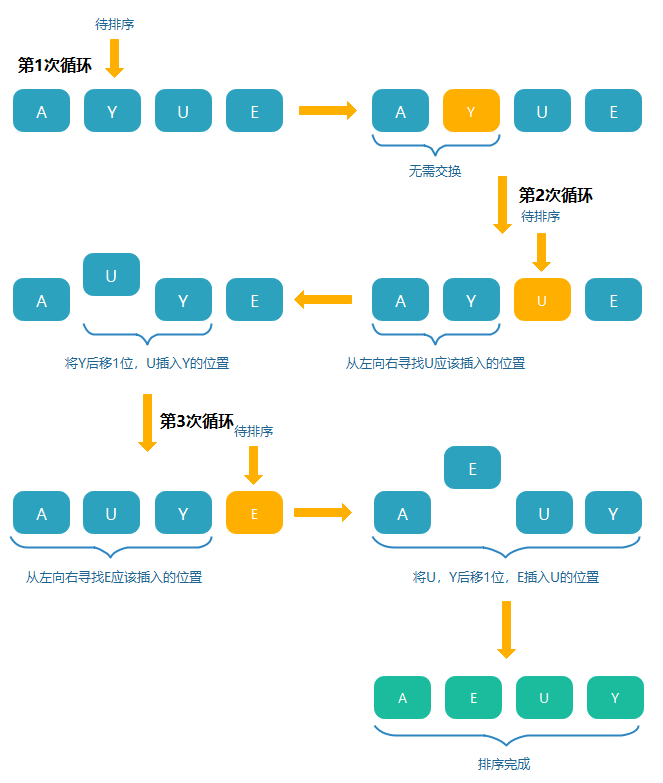
當我們在玩撲克牌的時候,總是在牌堆里面抽取最頂部的一張然后按順序在手中排列,
插入排序是指在待排序的元素中,假設前面n-1(其中n>=2)個數已經是排好順序的,現將第n個數插到前面已經排好的序列中,然后找到合適自己的位置,使得插入第n個數的這個序列也是排好順序的,
- 對于未排序資料(一般取陣列的二個元素,把第一個元素當做有序陣列),在已排序序列中從左往右掃描,找到相應位置并插入,
- 為了給要插入的元素騰出空間,需要將插入位置之后的已排序元素在都向后移動一位,
代碼實作
對下面陣列實作排序:{15, 51, 86, 70, 6, 42, 26, 61, 45, 81, 17, 1}
動圖演示

代碼實作
public class InsertionSort {
public static final int[] ARRAY = {15, 51, 86, 70, 6, 42, 26, 61, 45, 81, 17, 1};
public static int[] sort(int[] array) {
if (array.length == 0) {
return array;
}
//待排序資料,改資料之前的已被排序
int current;
for (int i = 0; i < array.length - 1; i++) {
//已被排序資料的索引
int index = i;
current = array[index + 1];
//將當前元素后移一位
while (index >= 0 && current < array[index]) {
array[index + 1] = array[index];
index--;
}
//插入
array[index + 1] = current;
}
return array;
}
public static void print(int[] array) {
for (int i : array) {
System.out.print(i + " ");
}
System.out.println("");
}
public static void main(String[] args) {
print(ARRAY);
System.out.println("============================================");
print(sort(ARRAY));
}
}
時間復雜度
在上面圖示中,第一趟回圈比較一次,第二趟回圈兩次,依次類推,則最后一趟比較n-1次:
1 + 2 + 3 +… + n-1 = n*(n-1)/2
也就是說,在最壞的情況下(逆序),比較的時間復雜度為O(n2)
在最優的情況下,即while循壞總是假的,只需當前數跟前一個數比較一下就可以了,這時一共需要比較n-1次,時間復雜度為O(n),
演算法穩定性
在比較的時候,過兩個數相等的話,不會進行移動,前后兩個數的次序不會發生改變,所以插入排序是穩定的,
希爾排序
一種基于插入排序的快速的排序演算法,簡單插入排序對于大規模亂序陣列很慢,因為元素只能一點一點地從陣列的一端移動到另一端,例如,如果主鍵最小的元素正好在陣列的盡頭,要將它挪到正確的位置就需要n-1次移動,
希爾排序為了加快速度簡單地改進了插入排序,也稱為縮小增量排序,
希爾排序是把待排序陣列按一定的數量分組,對每組使用直接插入排序演算法排序;然后縮小數量繼續分組排序,隨著數量逐漸減少,每組包含的元素越來越多,當數量減至 1 時,整個陣列恰被分成一組,排序便完成了,這個不斷縮小的數量,就構成了一個增量序列,這里的數量稱為增量,
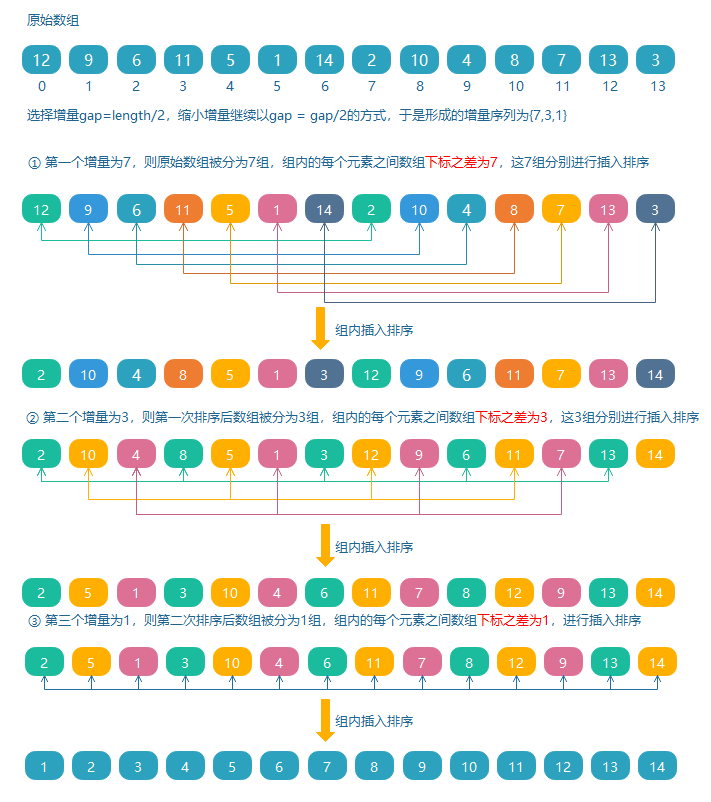
代碼實作
public class ShellSort {
public static final int[] ARRAY = {12, 9, 6, 11, 5, 1, 14, 2, 10, 4, 8, 7, 13, 3};
public static int[] sort(int[] array) {
int len = array.length;
if (len < 2) {
return array;
}
//當前待排序資料,該資料之前的已被排序
int current;
//增量
int gap = len / 2;
while (gap > 0) {
for (int i = gap; i < len; i++) {
current = array[i];
//前面有序序列的索引
int index = i - gap;
while (index >= 0 && current < array[index]) {
array[index + gap] = array[index];
//有序序列的下一個
index -= gap;
}
//插入
array[index + gap] = current;
}
//int相除取整
gap = gap / 2;
}
return array;
}
public static void print(int[] array) {
for (int i : array) {
System.out.print(i + " ");
}
System.out.println("");
}
public static void main(String[] args) {
print(ARRAY);
System.out.println("============================================");
print(sort(ARRAY));
}
}
時間復雜度
希爾排序的復雜度和增量序列有關,
在先前較大的增量下每個子序列的規模都不大,用直接插入排序效率都較高,盡管在隨后的增量遞減分組中子序列越來越大,由于整個序列的有序性也越來越明顯,則排序效率依然較高,
從理論上說,只要一個陣列是遞減的,并且最后一個值是1,都可以作為增量序列使用,有沒有一個步長序列,使得排序程序中所需的比較和移動次數相對較少,并且無論待排序列記錄數有多少,演算法的時間復雜度都能漸近最佳呢?但是目前從數學上來說,無法證明某個序列是最好的,
常用的增量序列:
- 希爾增量序列 :{n/2, (n / 2)/2, …, 1},其中N為原始陣列的長度,這是最常用的序列,但卻不是最好的
- Hibbard序列:{2k-1, …, 3,1}
- Sedgewick序列:{… , 109 , 41 , 19 , 5,1} 運算式為9 * 4i- 9 * 2i + 1,i = 0,1,2,3,4…
演算法穩定性
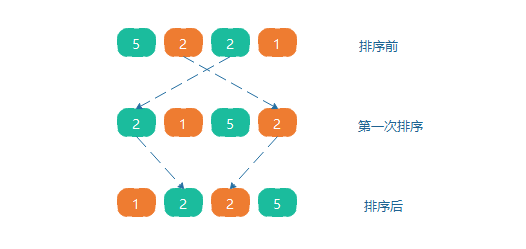
由于多次插入排序,我們知道一次插入排序是穩定的,不會改變相同元素的相對順序,但在不同的插入排序程序中,相同的元素可能在各自的插入排序中移動,如陣列5,2,2,1,第一次排序第一個元素5會和第三個元素2交換,第二個元素2會和第四個元素1交換,原序列中兩個2的相對前后順序就被破壞了,所以希爾排序是一個不穩定的排序演算法,
歸并排序
歸并,指合并,合在一起,歸并排序(Merge Sort)是建立在歸并操作上的一種排序演算法,其主要思想是分而治之,什么是分而治之?分而治之就是將一個復雜的計算,按照設定的閾值進行分解成多個計算,然后將各個計算結果進行匯總,即“分”就是把一個大的通過遞回拆成若干個小的,“治”就是將分后的結果在合在一起,
若將兩個有序集合并成一個有序表,稱為2-路歸并,與之對應的還有多路歸并,
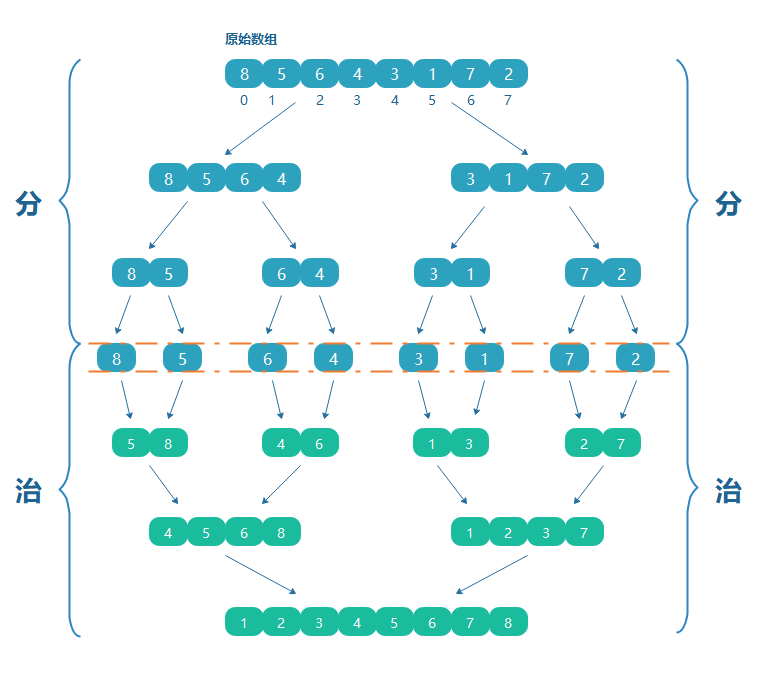
怎么分
- 對于排序最好的情況來講,就是只有兩個元素,這時候比較大小就很簡單,但是還是需要比較
- 如果拆分為左右各一個,無需比較即是有序的,
怎么治
借助一個輔助空陣列,把左右兩邊的陣列按照大小比較,按順序放入輔助陣列中即可,
以下面兩個有序陣列為例:
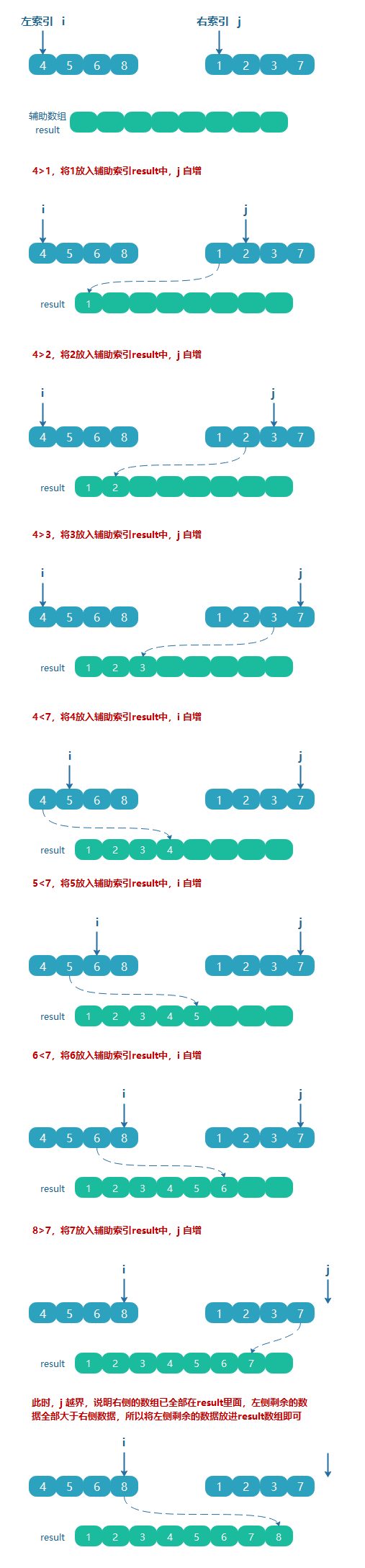
代碼實作
public class MergeSort {
public static final int[] ARRAY = {8, 5, 6, 4, 3, 1, 7, 2};
public static int[] sort(int[] array) {
if (array.length < 2) return array;
int mid = array.length / 2;
//分成2組
int[] left = Arrays.copyOfRange(array, 0, mid);
int[] right = Arrays.copyOfRange(array, mid, array.length);
//遞回拆分
return merge(sort(left), sort(right));
}
//治---合并
public static int[] merge(int[] left, int[] right) {
int[] result = new int[left.length + right.length];
//i代表左邊陣列的索引,j代表右邊
for (int index = 0, i = 0, j = 0; index < result.length; index++) {
if (i >= left.length) {//說明左側的資料已經全部取完,取右邊的資料
result[index] = right[j++];
} else if (j >= right.length) {//說明右側的資料已經全部取完,取左邊的資料
result[index] = left[i++];
} else if (left[i] > right[j]) {//左邊大于右邊,取右邊的
int a = right[j++];
result[index] = a;
} else {//右邊大于左邊,取左邊的
result[index] = left[i++];
}
}
return result;
}
public static void print(int[] array) {
for (int i : array) {
System.out.print(i + " ");
}
System.out.println("");
}
public static void main(String[] args) {
print(ARRAY);
System.out.println("============================================");
print(sort(ARRAY));
}
}
時間復雜度
歸并排序方法就是把一組n個數的序列,折半分為兩個序列,然后再將這兩個序列再分,一直分下去,直到分為n個長度為1的序列,然后兩兩按大小歸并,如此反復,直到最后形成包含n個數的一個陣列,
歸并排序總時間 = 分解時間 + 子序列排好序時間 + 合并時間
無論每個序列有多少數都是折中分解,所以分解時間是個常數,可以忽略不計,則:
歸并排序總時間 = 子序列排好序時間 + 合并時間
假設處理的資料規模大小為 n,運行時間設為:T(n),則T(n) = n,當 n = 1時,T(1) = 1
由于在合并時,兩個子序列已經排好序,所以在合并的時候只需要 if 判斷即可,所以n個數比較,合并的時間復雜度為 n,
- 將 n 個數的序列,分為兩個 n/2 的序列,則:T(n) = 2T(n/2) + n
- 將 n/2 個數的序列,分為四個 n/4 的序列,則:T(n) = 4T(n/4) + 2n
- 將 n/4 個數的序列,分為八個 n/8 的序列,則:T(n) = 8T(n/8) + 3n
- …
- 將 n/2k 個數的序列,分為2k個 n/2k 的序列,則:T(n) = 2kT(n/2k) + kn
當 T(n/2k) = T(1)時, 即n/2k = 1(此時也是把n分解到只有1個資料的時候),轉換為以2為底n的對數:k = log2n,把k帶入到T(n)中,得:T(n) = n + nlog2n,
使用大O表示法,去掉常數項 n,省略底數 2,則歸并排序的時間復雜度為:O(nlogn)
演算法穩定性
從原理分析和代碼可以看出,為在合并的時候,如果相等,選擇前面的元素到輔助陣列,所以歸并排序是穩定的,
快速排序
快速排序是對冒泡排序的一種改進,也是采用分治法的一個典型的應用,JDK中Arrays的sort()方法,具體的排序細節就是使用快速排序實作的,
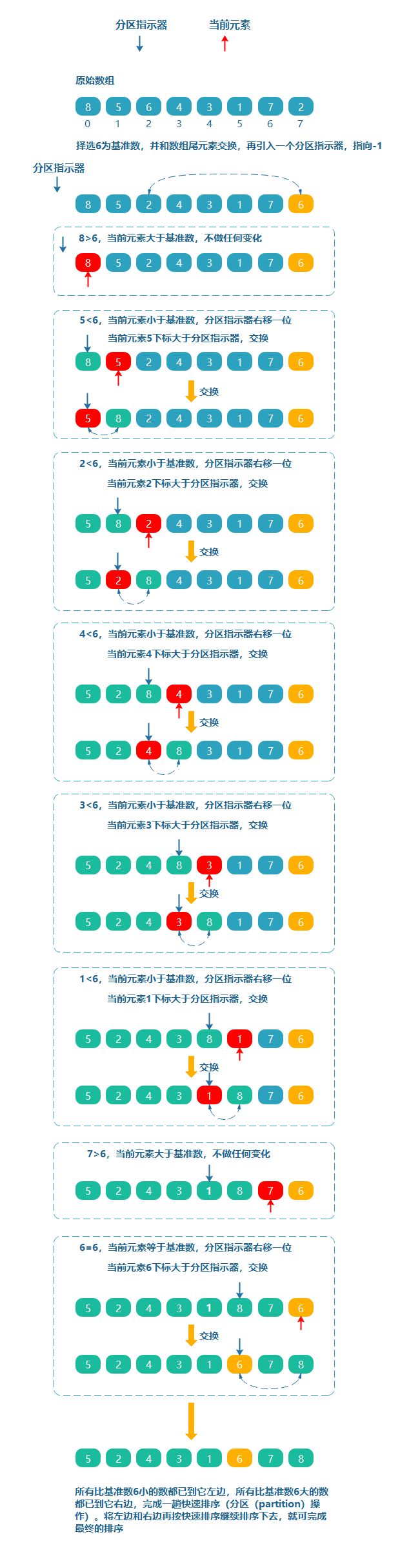
從陣列中任意選取一個資料(比如陣列的第一個數或最后一個數)作為關鍵資料,我們稱為基準數(pivot,或中軸數),然后將所有比它小的數都放到它前面,所有比它大的數都放到它后面,這個程序稱為一趟快速排序,也稱為磁區(partition)操作,
問題
若給定一個無序陣列 [8, 5, 6, 4, 3, 1, 7, 2],并指定一個數為基準,拆分陣列使得左側的數都小于等于它 ,右側的數都大于它,
基準的選取最優的情況是基準值剛好取在無序區數值的中位數,這樣能夠最大效率地讓兩邊排序,同時最大地減少遞回劃分的次數,但是一般很難做到最優,基準的選取一般有三種方式:
- 選取陣列的第一個元素
- 選取陣列的最后一個元素
- 以及選取第一個、最后一個以及中間的元素的中位數(如4 5 6 7, 第一個4, 最后一個7, 中間的為5, 這三個數的中位數為5, 所以選擇5作為基準),
思路
- 隨機選擇陣列的一個元素,比如 6 為基準,拆分陣列同時引入一個初始指標,也叫磁區指示器,初始指標指向 -1
- 將陣列中的元素和基準數遍歷比較
- 若當前元素大于基準數,不做任何變化
- 若當前元素小于等于基準數時,分割指示器右移一位,同時
- 當前元素下標小于等于磁區指示器時,當前元素保持不動
- 當前元素下標大于磁區指示器時,當前元素和磁區指示器所指元素交換
荷蘭國旗問題
荷蘭的國旗是由紅白藍三種顏色構成,如圖:

若現在給一個隨機的圖形,如下:

把這些條紋按照顏色排好,紅色的在上半部分,白色的在中間部分,藍色的在下半部分,這類問題稱作荷蘭國旗問題,
對應leetcode:顏色分類
給定一個包含紅色、白色和藍色,一共 n 個元素的陣列,原地對它們進行排序,使得相同顏色的元素相鄰,并按照紅色、白色、藍色順序排列,
分析:
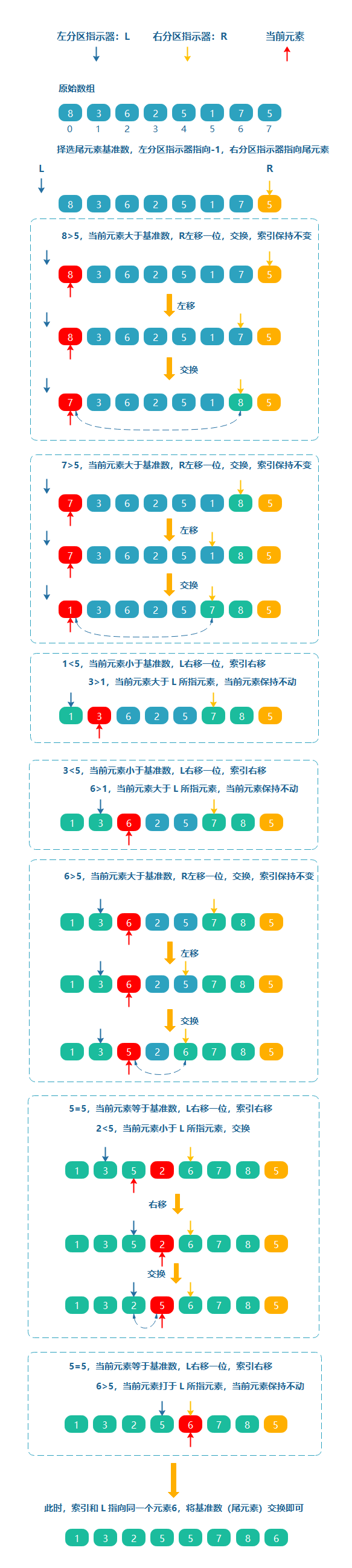
假如給定一個陣列[8, 3, 6, 2, 5, 1, 7, 5],做如下操作:
-
隨機選擇陣列的一個元素,比如 5 為基準,拆分陣列同時引入一個左磁區指示器,指向 -1,右磁區指示器指向基準數(注:此時的基準數為尾元素)
-
若當前元素大于基準數,右磁區指示器左移一位,當前元素和右磁區指示器所指元素交換,
索引保持不變
-
若當前元素小于等于基準數時,左磁區指示器右移一位,索引右移
- 當前元素大于等于左磁區指示器所指元素,當前元素保持不動
- 當前元素小于左磁區指示器所指元素,交換
簡單來說就是,左磁區指示器向右移動的程序中,如果遇到大于或等于基準數時,則停止移動,右磁區指示器向左移動的程序中,如果遇到小于或等于主元的元素則停止移動,這種操作也叫雙向快速排序,
代碼實作
public class QuickSort {
public static final int[] ARRAY = {8, 5, 6, 4, 3, 1, 7, 2};
public static final int[] ARRAY2 = {8, 3, 6, 2, 5, 1, 7, 5};
private static int[] sort(int[] array, int left, int right) {
if (array.length < 1 || left > right) return null;
//拆分
int partitionIndex = partition(array, left, right);
//遞回
if (partitionIndex > left) {
sort(array, left, partitionIndex - 1);
}
if (partitionIndex < right) {
sort(array, partitionIndex + 1, right);
}
return array;
}
/**
* 磁區快排操作
*
* @param array 原陣列
* @param left 左側頭索引
* @param right 右側尾索引
* @return 磁區指示器 最后指向基準數
*/
public static int partition(int[] array, int left, int right) {
//基準數下標---隨機方式取值,也就是陣列的長度隨機1-8之間
int pivot = (int) (left + Math.random() * (right - left + 1));
//磁區指示器索引
int partitionIndex = left - 1;
//基準數和尾部元素交換
swap(array, pivot, right);
//按照規定,如果當前元素大于基準數不做任何操作;
//小于基準數,磁區指示器右移,且當前元素的索引大于磁區指示器,交換
for (int i = left; i <= right; i++) {
if (array[i] <= array[right]) {//當前元素小于等于基準數
partitionIndex++;
if (i > partitionIndex) {//當前元素的索引大于磁區指示器
//交換
swap(array, i, partitionIndex);
}
}
}
return partitionIndex;
}
/**
* 雙向掃描排序
*/
public static int partitionTwoWay(int[] array, int left, int right) {
//基準數
int pivot = array[right];
//左磁區指示器索引
int leftIndex = left - 1;
//右磁區指示器索引
int rightIndex = right;
//索引
int index = left;
while (index < rightIndex) {
//若當前元素大于基準數,右磁區指示器左移一位,當前元素和右磁區指示器所指元素交換,索引保持不變
if (array[index] > pivot) {
swap(array, index, --rightIndex);
} else if (array[index] <= pivot) {//當前元素小于等于基準數時,左分割指示器右移一位,索引右移
leftIndex++;
index++;
//當前元素小于等于左磁區指示器所指元素,交換
if (array[index] < array[leftIndex]) {
swap(array, index, leftIndex);
}
}
}
//索引和 L 指向同一個元素
swap(array, right, rightIndex);
return 1;
}
//交換
private static void swap(int[] array, int i, int j) {
int temp = array[i];
array[i] = array[j];
array[j] = temp;
}
public static void print(int[] array) {
for (int i : array) {
System.out.print(i + " ");
}
System.out.println("");
}
public static void main(String[] args) {
print(ARRAY);
System.out.println("============================================");
print(sort(ARRAY, 0, ARRAY.length - 1));
System.out.println("====================雙向排序==================");
print(ARRAY2);
System.out.println("============================================");
print(sort(ARRAY2, 0, ARRAY2.length - 1));
}
}
時間復雜度
在拆分陣列的時候可能會出現一種極端的情況,每次拆分的時候,基準數左邊的元素個數都為0,而右邊都為n-1個,這個時候,就需要拆分n次了,而每次拆分整理的時間復雜度為O(n),所以最壞的時間復雜度為O(n2),什么意思?舉個簡單例子:
在不知道初始序列已經有序的情況下進行排序,第1趟排序經過n-1次比較后,將第1個元素仍然定在原來的位置上,并得到一個長度為n-1的子序列;第2趟排序經過n-2次比較后,將第2個元素確定在它原來的位置上,又得到一個長度為n-2的子序列;以此類推,最終總的比較次數:
C(n) = (n-1) + (n-2) + … + 1 = n(n-1)/2
所以最壞的情況下,快速排序的時間復雜度為O(n^2)
而最好的情況就是每次拆分都能夠從陣列的中間拆分,這樣拆分logn次就行了,此時的時間復雜度為O(nlogn),
而平均時間復雜度,則是假設每次基準數隨機,最后算出來的時間復雜度為O(nlogn)
參考:快速排序的時間復雜度與空間復雜度
演算法穩定性
通過上面的分析可以知道,在隨機取基準數的時候,資料是可能會發生變化的,所以快速排序有不是穩定的情況,
堆排序
這里的堆并不是JVM中堆疊的堆,而是一種特殊的二叉樹,通常也叫作二叉堆,它具有以下特點:
- 它是完全二叉樹
- 堆中某個結點的值總是不大于或不小于其父結點的值
知識補充
二叉樹
樹中節點的子節點不超過2的有序樹
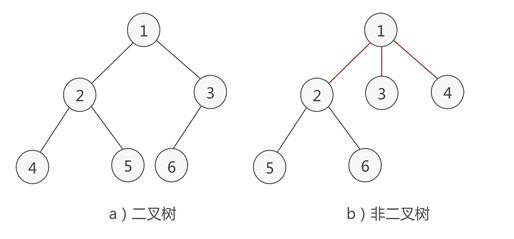
滿二叉樹
二叉樹中除了葉子節點,每個節點的子節點都為2,則此二叉樹為滿二叉樹,
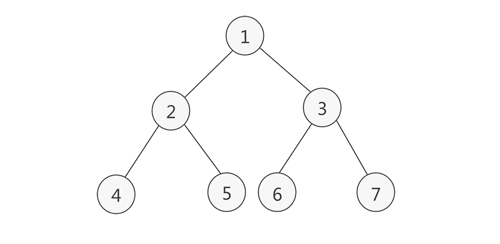
完全二叉樹
如果對滿二叉樹的結點進行編號,約定編號從根結點起,自上而下,自左而右,則深度為k的,有n個結點的二叉樹,當且僅當其每一個結點都與深度為k的滿二叉樹中編號從1至n的結點一一對應時,稱之為完全二叉樹,
特點:葉子結點只能出現在最下層和次下層,且最下層的葉子結點集中在樹的左部,需要注意的是,滿二叉樹肯定是完全二叉樹,而完全二叉樹不一定是滿二叉樹,
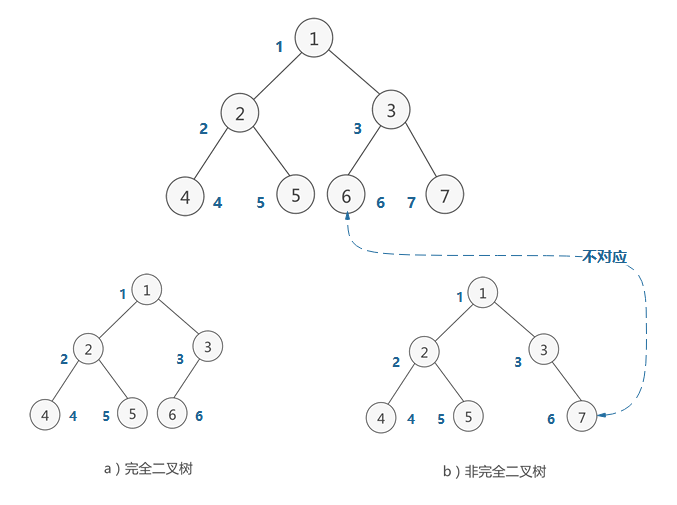
二叉堆
二叉堆是一種特殊的堆,可以被看做一棵完全二叉樹的陣列物件,而根據其性質又可以分為下面兩種:
- 大根堆:每一個根節點都大于等于它的左右孩子節點,也叫最大堆
- 小根堆:每一個根節點都小于等于它的左右孩子節點,也叫最小堆
如果把一個陣列通過大根堆的方式來表示(陣列元素的值是可變的),如下:
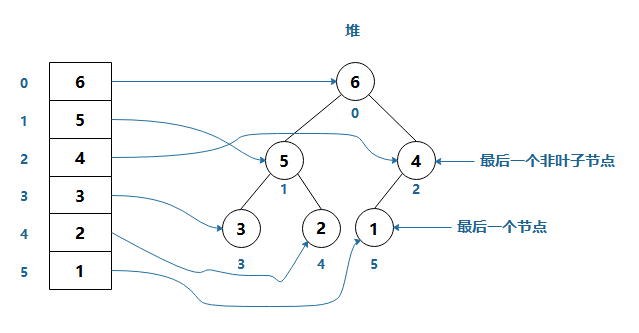
由此可以推出:
-
對于位置為 k 的節點,其子節點的位置分別為,左子節點 = 2k + 1,右子節點 = 2(k + 1)
如:對于 k = 1,其節點的對應陣列為 5
左子節點的位置為 3,對應陣列的值為 3
右子節點的位置為 4,對應陣列的值為 2
-
最后一個非葉子節點的位置為 (n/2) - 1,n為陣列長度
如:陣列長度為6,則 (6/2) - 1 = 2,即位置 2 為最后一個非葉子節點
給定一個隨機陣列[35,63,48,9,86,24,53,11],將該陣列視為一個完全二叉樹:
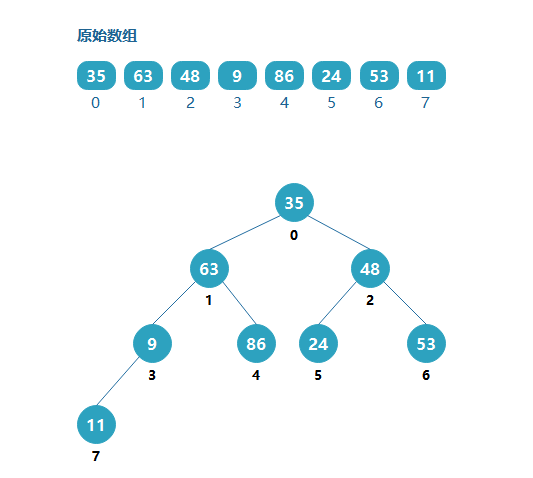
從上圖很明顯的可以看出,這個二叉樹不符合大根堆的定義,但是可以通過調整,使它變為最大堆,如果從最后一個非葉子節點開始,從下到上,從右往左調整,則:

通過上面的調整,該二叉樹為最大堆,這個時候開始排序,排序規則:
- 將堆頂元素和尾元素交換
- 交換后重新調整元素的位置,使之重新變成二叉堆

代碼實作
public class HeapSort {
public static final int[] ARRAY = {35, 63, 48, 9, 86, 24, 53, 11};
public static int[] sort(int[] array) {
//陣列的長度
int length = array.length;
if (length < 2) return array;
//首先構建一個最大堆
buildMaxHeap(array);
//調整為最大堆之后,頂元素為最大元素并與微元素交換
while (length > 0) {//當lenth <= 0時,說明已經到堆頂
//交換
swap(array, 0, length - 1);
length--;//交換之后相當于把樹中的最大值彈出去了,所以要--
//交換之后從上往下調整使之成為最大堆
adjustHeap(array, 0, length);
}
return array;
}
//對元素組構建為一個對應陣列的最大堆
private static void buildMaxHeap(int[] array) {
//在之前的分析可知,最大堆的構建是從最后一個非葉子節點開始,從下往上,從右往左調整
//最后一個非葉子節點的位置為:array.length/2 - 1
for (int i = array.length / 2 - 1; i >= 0; i--) {
//調整使之成為最大堆
adjustHeap(array, i, array.length);
}
}
/**
* 調整
* @param parent 最后一個非葉子節點
* @param length 陣列的長度
*/
private static void adjustHeap(int[] array, int parent, int length) {
//定義最大值的索引
int maxIndex = parent;
//parent為對應元素的位置(陣列的索引)
int left = 2 * parent + 1;//左子節點對應元素的位置
int right = 2 * (parent + 1);//右子節點對應元素的位置
//判斷是否有子節點,再比較父節點和左右子節點的大小
//因為parent最后一個非葉子節點,所以如果有左右子節點則節點的位置都小于陣列的長度
if (left < length && array[left] > array[maxIndex]) {//左子節點如果比父節點大
maxIndex = left;
}
if (right < length && array[right] > array[maxIndex]) {//右子節點如果比父節點大
maxIndex = right;
}
//maxIndex為父節點,若發生改變則說明不是最大節點,需要交換
if (maxIndex != parent) {
swap(array, maxIndex, parent);
//交換之后遞回再次調整比較
adjustHeap(array, maxIndex, length);
}
}
//交換
private static void swap(int[] array, int i, int j) {
int temp = array[i];
array[i] = array[j];
array[j] = temp;
}
public static void print(int[] array) {
for (int i : array) {
System.out.print(i + " ");
}
System.out.println("");
}
public static void main(String[] args) {
print(ARRAY);
System.out.println("============================================");
print(sort(ARRAY));
}
}
時間復雜度
堆的時間復雜度是 O(nlogn)
參考:堆排序的時間復雜度分析
演算法穩定性
堆的結構為,對于位置為 k 的節點,其子節點的位置分別為,左子節點 = 2k + 1,右子節點 = 2(k + 1),最大堆要求父節點大于等于其2個子節點,最小堆要求父節點小于等于其2個子節點,
在一個長為n的序列,堆排序的程序是從第n/2開始和其子節點共3個值選擇最大(最大堆)或者最小(最大堆),這3個元素之間的選擇當然不會破壞穩定性,但當為n/2-1,n/2-2,… 1 這些個父節點選擇元素時,就會破壞穩定性,有可能第n/2個父節點交換把后面一個元素交換過去了,而第n/2-1個父節點把后面一個相同的元素沒有交換,那么這2個相同的元素之間的穩定性就被破壞了,所以,堆排序不是穩定的排序演算法,
參考:排序的穩定性
思考
對于快速排序來說,其平均復雜度為O(nlogn),堆排序也是O(nlogn),怎么選擇?如下題:
leetcode:陣列中的第K個最大元素
此題的意思是對于一個無序陣列,經過排序后的第 k 個最大的元素,
我們知道快速排序是需要對整個陣列進行排序,這樣才能取出第 k 個最大的元素,
如果使用堆排序,且是最大堆的方式,則第k次回圈即可找出第 k 個最大的元素,并不需要吧整個陣列排序,
所以對于怎么選擇的問題,要看具體的場景,或者是兩者都可,
計數排序
一種非比較排序,計數排序對一定范圍內的整數排序時候的速度非常快,一般快于其他排序演算法,但計數排序局限性比較大,只限于對整數進行排序,而且待排序元素值分布較連續、跨度小的情況,
如果一個陣列里所有元素都是整數,而且都在0-k以內,對于陣列里每個元素來說,如果能知道陣列里有多少項小于或等于該元素,就能準確地給出該元素在排序后的陣列的位置,
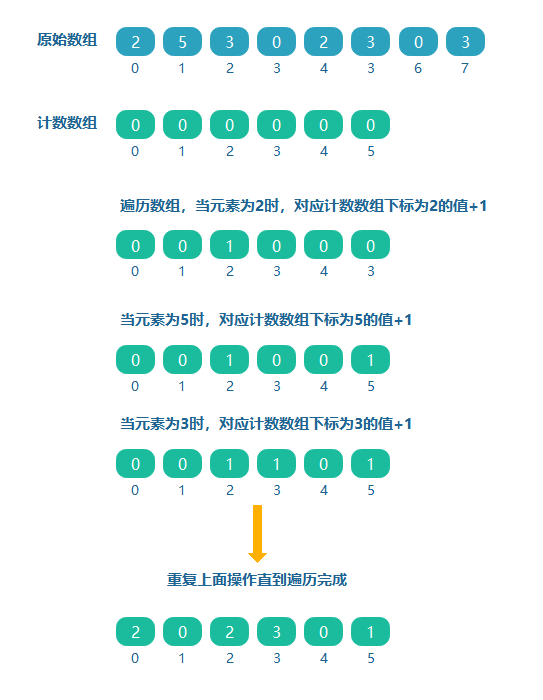
如給定一個0~5范圍內的陣列[2,5,3,0,2,3,0,3],對于元素5為其中最大的元素,創建一個大小為(5-0+1 = 6)的計數陣列,如果原陣列中的值對應計數陣列的下標,則下標對應計數陣列的值加1,
問題
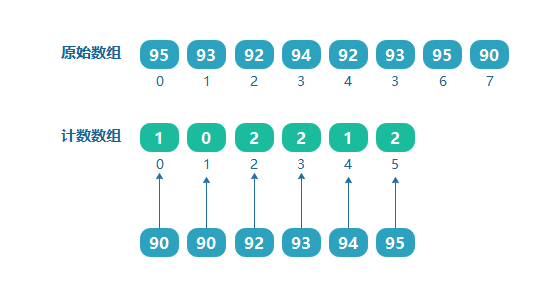
上面是通過陣列的最大值來確定計數陣列的長度的,但如果需要對學生的成績進行排序,如學生成績為:[95,93,92,94,92,93,95,90],如果按照上面的方法來處理,則需要一個大小為100的陣列,但是可以看到其中的最小值為90,那也就是說前面 0~89 的位置都沒有資料存放,造成了資源浪費,
如果我們知道了陣列的最大值和最小值,則計數陣列的大小為(最大值 - 最小值 + 1),如上面陣列的最大值為99,最小值為90,則定義計數陣列的大小為(95 - 90 + 1 = 6),并且索引分別對應原陣列9095的值,我們把090的范圍用一個偏移量來表示,即最小值90就是這個偏移量,
代碼實作
public class CountSort {
public static final int[] ARRAY = {2, 5, 3, 0, 2, 3, 0, 3};
public static final int[] ARRAY2 = {95,93,92,94,92,93,95,90};
//優化前
private static int[] sort(int[] array) {
if (array.length < 2) return array;
//找出陣列的最大值
int max = array[0];
for (int i : array) {
if (i > max) {
max = i;
}
}
//初始化一個計數陣列且值為0
int[] countArray = new int[max + 1];
for (int i = 0; i < countArray.length; i++) {
countArray[i] = 0;
}
//填充計數陣列
for (int temp : array) {
countArray[temp]++;
}
int o_index = 0;//原陣列下標
int n_index = 0;//計數陣列下標
while (o_index < array.length) {
//只要計數陣列的下標不為0,就將計數陣列的值從新寫回原陣列
if (countArray[n_index] != 0) {
array[o_index] = n_index;//計數陣列下標對應元素組的值
countArray[n_index]--;//計數陣列的值要-1
o_index++;
} else {
n_index++;//上一個索引的值為0后開始下一個
}
}
return array;
}
//優化后
private static int[] sort2(int[] array) {
if (array.length < 2) return array;
//找出陣列中的最大值和最小值
int min = array[0], max = array[0];
for (int i : array) {
if (i > max) {
max = i;
}
if (i < min) {
min = i;
}
}
//定義一個偏移量,即最小值前面0~min的范圍,這里直接用一個負數來表示
int bias = 0 - min;
//初始化一個計數陣列且值為0
int[] countArray = new int[max - min + 1];
for (int i = 0; i < countArray.length; i++) {
countArray[i] = 0;
}
for (int temp : array) {
countArray[temp + bias]++;
}
//填充計數陣列
int o_index = 0;//原陣列下標
int n_index = 0;//計數陣列下標
while (o_index < array.length) {
if (countArray[n_index] != 0) {
array[o_index] = n_index - bias;
countArray[n_index]--;
o_index++;
} else {
n_index++;
}
}
return array;
}
public static void print(int[] array) {
for (int i : array) {
System.out.print(i + " ");
}
System.out.println("");
}
public static void main(String[] args) {
print(ARRAY);
System.out.println("============================================");
print(sort(ARRAY));
System.out.println("=================優化排序====================");
print(ARRAY2);
System.out.println("============================================");
print(sort2(ARRAY2));
}
}
時間復雜度
很明顯,在排序程序中,我們至少遍歷了三次原始陣列,一次計數陣列,所以它的復雜度為Ο(n+m),因此,計數排序比任何排序都要塊,這是一種犧牲空間換取時間的做法,因為排序程序中需要用一個計數陣列來存元素組的出現次數,
演算法穩定性
在新建的計數陣列中記錄原始陣列中每個元素的數量,如果原始陣列有相同的元素,則在輸出時,無法保證元素原來的排序,是一種不穩定的排序演算法,
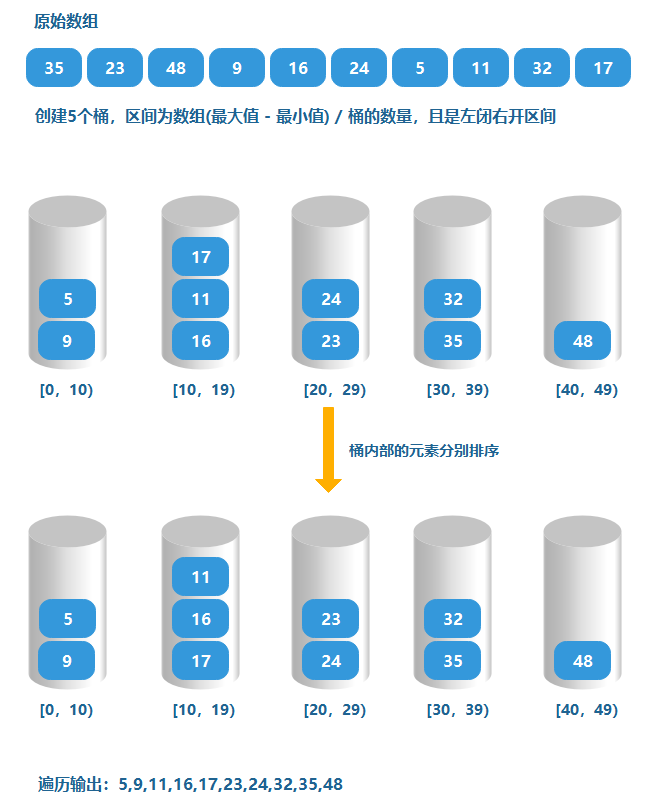
桶排序
桶排序是計數排序的升級,計數排序可以看成每個桶只存盤相同元素,而桶排序每個桶存盤一定范圍的元素,通過函式的某種映射關系,將待排序陣列中的元素映射到各個對應的桶中,對每個桶中的元素進行排序(有可能再使用別的排序演算法或是以遞回方式繼續使用桶排序),最后將非空桶中的元素逐個放入原序列中,
桶排序需要盡量保證元素分散均勻,否則當所有資料集中在同一個桶中時,桶排序失效,
代碼實作
-
找出陣列中的最大值max和最小值min,可以確定出陣列所在范圍min~max
-
根據資料范圍確定桶的數量
- 若桶的數量太少,則桶排序失效
- 若桶的數量太多,則有的桶可能,沒有資料造成空間浪費
所以桶的數量由我們自己來確定,但盡量讓元素平均分布到每一個桶里,這里提供一個方式
(最大值 - 最小值)/每個桶所能放置多少個不同數值+1 -
確定桶的區間,一般是按照
(最大值 - 最小值)/桶的數量來劃分的,且左閉右開
public class BucketSort {
public static final int[] ARRAY = {35, 23, 48, 9, 16, 24, 5, 11, 32, 17};
/**
* @param bucketSize 作為每個桶所能放置多少個不同數值,即數值的型別
* 例如當BucketSize==5時,該桶可以存放{1,2,3,4,5}這幾種數字,
* 但是容量不限,即可以存放100個3
*/
public static List<Integer> sort(List<Integer> array, int bucketSize) {
if (array == null || array.size() < 2)
return array;
int max = array.get(0), min = array.get(0);
// 找到最大值最小值
for (int i = 0; i < array.size(); i++) {
if (array.get(i) > max)
max = array.get(i);
if (array.get(i) < min)
min = array.get(i);
}
//獲取桶的數量
int bucketCount = (max - min) / bucketSize + 1;
//構建桶,初始化
List<ArrayList<Integer>> bucketArr = new ArrayList<>(bucketCount);
List<Integer> resultArr = new ArrayList<>();
for (int i = 0; i < bucketCount; i++) {
bucketArr.add(new ArrayList<>());
}
//將原陣列的資料分配到桶中
for (int i = 0; i < array.size(); i++) {
//區間范圍
bucketArr.get((array.get(i) - min) / bucketSize).add(array.get(i));
}
for (int i = 0; i < bucketCount; i++) {
if (bucketSize == 1) {
for (int j = 0; j < bucketArr.get(i).size(); j++)
resultArr.add(bucketArr.get(i).get(j));
} else {
if (bucketCount == 1)
bucketSize--;
//對桶中的資料再次用桶進行排序
List<Integer> temp = sort(bucketArr.get(i), bucketSize);
for (int j = 0; j < temp.size(); j++)
resultArr.add(temp.get(j));
}
}
return resultArr;
}
public static void print(List<Integer> array) {
for (int i : array) {
System.out.print(i + " ");
}
System.out.println("");
}
public static void main(String[] args) {
print(Arrays.stream(ARRAY).boxed().collect(Collectors.toList()));
System.out.println("============================================");
print(sort(Arrays.stream(ARRAY).boxed().collect(Collectors.toList()), 2));
}
}
時間復雜度
桶排序演算法遍歷了2次原始陣列,運算量為2N,最后,遍歷桶輸出排序結果的運算量為N,初始化桶的運算量為M,
對桶進行排序,不同的排序演算法演算法復雜度不同,冒泡排序演算法復雜度為O(N^2),堆排序、歸并排序演算法復雜度為O(NlogN),我們以排序演算法復雜度為O(NlogN)進行計算,運算量為N/M * log(N/M) * M
最終的運算量為3N+M+N/M * log(N/M) * M,即3N+M+N(logN-logM),去掉系數,時間復雜度為O(N+M+N(logN-logM))
參考:桶排序演算法詳解
演算法穩定性
桶排序演算法在對每個桶進行排序時,若選擇穩定的排序演算法,則排序后,相同元素的位置不會發生改變,所以桶排序演算法是一種穩定的排序演算法,
基數排序
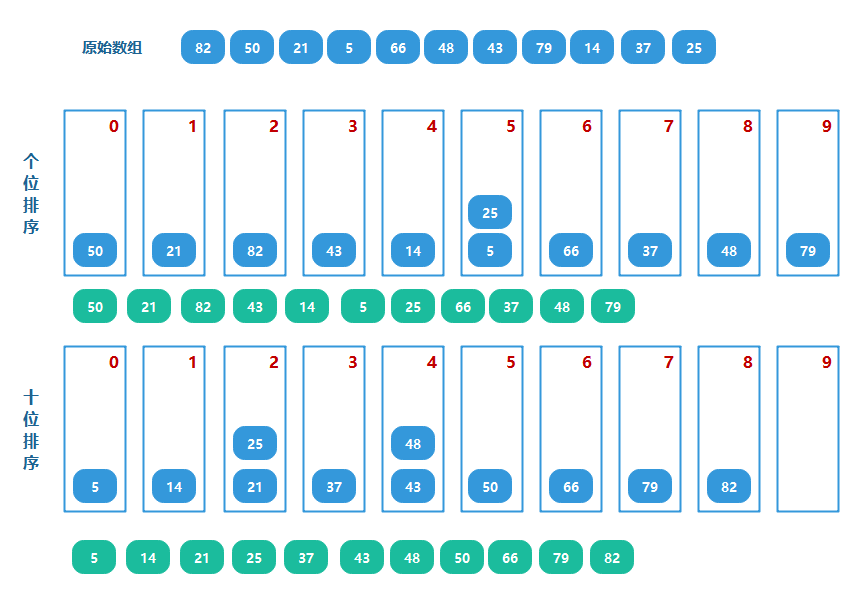
常見的資料元素一般是由若干位組成的,比如字串由若干字符組成,整數由若干位0~9數字組成,
基數排序按照從右往左的順序,依次將每一位都當做一次關鍵字,然后按照該關鍵字對陣列排序,同時每一輪排序都基于上輪排序后的結果;當我們將所有的位排序后,整個陣列就達到有序狀態,基數排序不是基于比較的演算法,
基數是什么意思?對于十進制整數,每一位都只可能是0~9中的某一個,總共10種可能,那10就是它的基,同理二進制數字的基為2;對于字串,如果它使用的是8位的擴展ASCII字符集,那么它的基就是256,
基數排序有兩種方法:
- MSD 從高位開始進行排序
- LSD 從低位開始進行排序
對于大小范圍為0~9的數的組合(若是兩位數,就是個位數和十位數的組合),于是可以準備十個桶,然后放到對應的桶里,然后再把桶里的數按照0號桶到9號桶的順序取出來即可,
代碼實作
public class RadixSort {
public static final int[] ARRAY = {82, 50, 21, 5, 66, 48, 43, 79, 14, 37, 25};
public static int[] sort(int[] array) {
if (array.length < 2) return array;
//根據最大值算出位數
int max = array[0];
for (int temp : array) {
if (temp > max) {
max = temp;
}
}
//算出位數digit
int maxDigit = 0;
while (max != 0) {
max /= 10;
maxDigit++;
}
//創建桶并初始化
ArrayList<ArrayList<Integer>> bucket = new ArrayList<>();
for (int i = 0; i < 10; i++) {
bucket.add(new ArrayList<>());
}
//按照從右往左的順序,依次將每一位都當做一次關鍵字,然后按照該關鍵字對陣列排序,每一輪排序都基于上輪排序后的結果
int mold = 10;//取模運算
int div = 1;//獲取對應位數的值
for (int i = 0; i < maxDigit; i++, mold *= 10, div *= 10) {
for (int j = 0; j < array.length; j++) {
//獲取個位/十位/百位......
int num = (array[j] % mold) / div;
//把資料放入到對應的桶里
bucket.get(num).add(array[j]);
}
//把桶中的資料重新寫回去,并把桶的元素清空,開始第二輪排序
int index = 0;
for (int k = 0; k < bucket.size(); k++) {
//桶中對應的資料
ArrayList<Integer> list = bucket.get(k);
for (int m = 0; m < list.size(); m++) {
array[index++] = list.get(m);
}
//清除桶
bucket.get(k).clear();
}
}
return array;
}
public static void print(int[] array) {
for (int i : array) {
System.out.print(i + " ");
}
System.out.println("");
}
public static void main(String[] args) {
print(ARRAY);
System.out.println("============================================");
print(sort(ARRAY));
}
}
時間復雜度
計數排序演算法的時間復雜度是O(N+M),基數排序演算法執行了k次計數排序,所以基數排序演算法的時間復雜度為O(K(N+M)),
演算法穩定性
從上面的分析可以看出,相同元素會按照順序放進固定的桶內,取出的時候也是按照順序取出來的,所以基數排序演算法是一種穩定的排序演算法,
基數排序 vs 桶排序 vs 計數排序
這三種排序演算法都利用了桶的概念,但對桶的使用方法上有明顯差異
- 基數排序:根據每一位的關鍵字來分配桶
- 桶排序:存盤一定范圍的值
- 計數排序:每個桶只存盤一個型別值,但是數量不限
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/295707.html
標籤:其他
下一篇:面向程序與面向物件概述