系列目錄
記憶體吞金獸(Elasticsearch)的那些事兒 -- 認識一下
記憶體吞金獸(Elasticsearch)的那些事兒 -- 資料結構及巧妙演算法
記憶體吞金獸(Elasticsearch)的那些事兒 -- 架構&三高保證
記憶體吞金獸(Elasticsearch)的那些事兒 -- 寫入&檢索原理
記憶體吞金獸(Elasticsearch)的那些事兒 -- 常見問題痛點及解決方案
架構圖
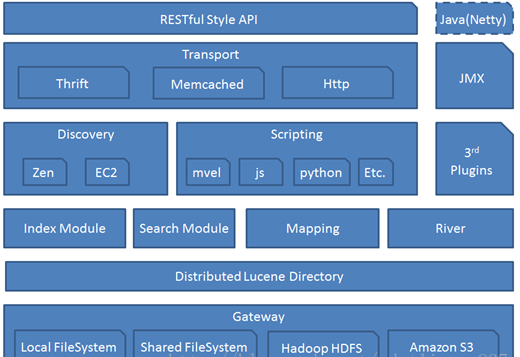
Gateway
代表ElasticSearch索引的持久化存盤方式,
在Gateway中,ElasticSearch默認先把索引存盤在記憶體中,然后當記憶體滿的時候,再持久化到Gateway里,當ES集群關倍訓重啟的時候,它就會從Gateway里去讀取索引資料,比如LocalFileSystem和HDFS、AS3等,
DistributedLucene Directory
是Lucene里的一些列索引檔案組成的目錄,它負責管理這些索引檔案,包括資料的讀取、寫入,以及索引的添加和合并等,
River
代表是資料源,是以插件的形式存在于ElasticSearch中,
Mapping
映射的意思,非常類似于靜態語言中的資料型別,比如我們宣告一個int型別的變數,那以后這個變數只能存盤int型別的資料,
eg:比如我們宣告一個double型別的mapping欄位,則只能存盤double型別的資料,
Mapping不僅是告訴ElasticSearch,哪個欄位是哪種型別,還能告訴ElasticSearch如何來索引資料,以及資料是否被索引到等,
Search Moudle
搜索模塊
Index Moudle
索引模塊
Disvcovery
主要是負責集群的master節點發現,比如某個節點突然離開或進來的情況,進行一個分片重新分片等,
(Zen)發現機制默認的實作方式是單播和多播的形式,同時也支持點對點的實作,以插件的形式存在EC2,
一個基于p2p的系統,它先通過廣播尋找存在的節點,再通過多播協議來進行節點之間的通信,同時也支持點對點的互動,
Scripting
腳本語言,包括很多,如mvel、js、python等,
定制化功能非常便捷,但有性能問題
Transport
代表ElasticSearch內部節點,代表跟集群的客戶端互動,包括 Thrift、Memcached、Http等協議
RESTful Style API
通過RESTful方式來實作API編程,
3rd plugins
第三方插件,(想象一下idea或vscode的插件
Java(Netty)
開發框架,其內部使用netty實作
JMX
監控
部署節點
- master
- index node(也是coordinating node
- coordinating node
三高保證
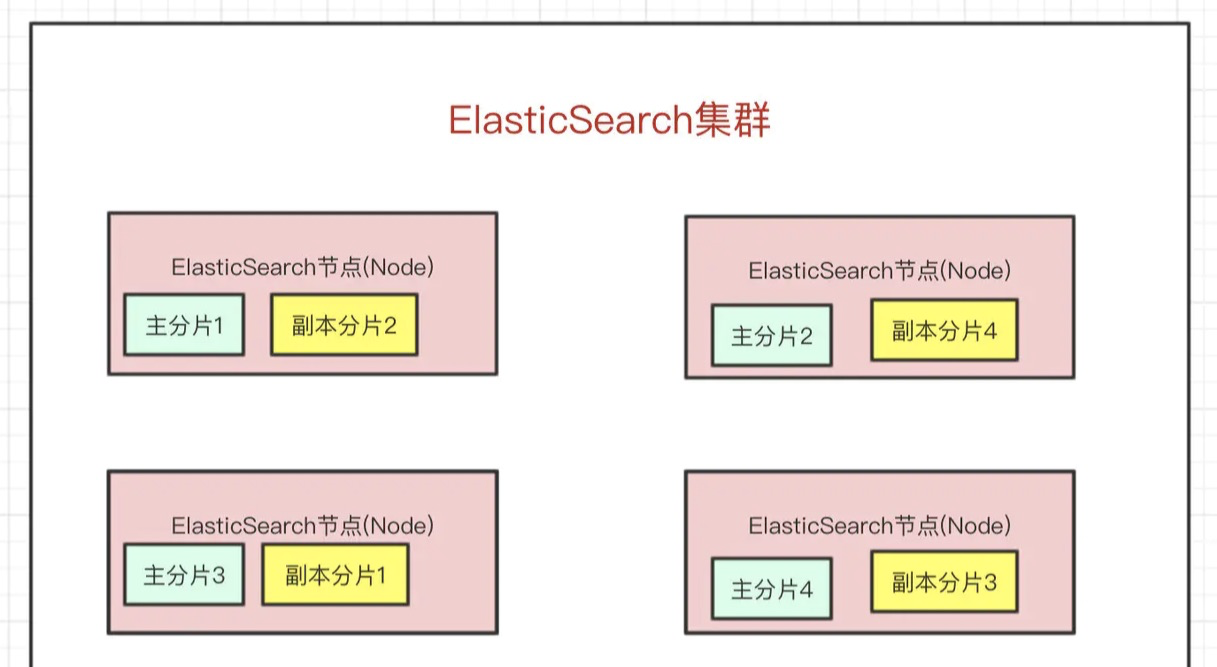
- 一個es集群會有多個es節點
- 在眾多的節點中,其中會有一個
Master Node,主要負責維護索引元資料、負責切換主分片和副本分片身份等作業,如果主節點掛了,會選舉出一個新的主節點- 如果某個節點掛了,
Master Node就會把對應的副本分片提拔為主分片,這樣即便節點掛了,資料就不會丟,
- 如果某個節點掛了,
- es最外層的是Index(相當于資料庫 表的概念);一個Index的資料我們可以分發到不同的Node上進行存盤,這個操作就叫做分片,
- 比如現在我集群里邊有4個節點,我現在有一個Index,想將這個Index在4個節點上存盤,那我們可以設定為4個分片,這4個分片的資料合起來就是Index的資料
- 分片會有主分片和副本分片之分(防止某個節點宕機,保證高可用)
-
Index需要分為多少個分片和副本分片都是可以通過配置設定的
為什么需要分片?
- 如果一個Index的資料量太大,只有一個分片,那只會在一個節點上存盤,隨著資料量的增長,一個節點未必能把一個Index存盤下來,
- 多個分片,在寫入或查詢的時候就可以并行操作(從各個節點中讀寫資料,提高吞吐量)
分詞器:
在分詞前我們要先明確欄位是否需要分詞,不需要分詞的欄位將type設定為keyword,可以節省空間和提高寫性能,
1)es的內置分詞器
常用的三種分詞:Standard Analyzer、Simple Analyzer、whitespace Analyzer
standard 是默認的分析器,英文會按照空格切分,同時大寫轉小寫,中文會按照每個詞切分
simple 先按照空格分詞,英文大寫轉小寫,不是英文不再分詞
Whitespace Analyzer 先按照空格分詞,不是英文不再分詞,英文不再轉小寫
2)第三方分詞器
es內置很多分詞器,但是對中文分詞并不友好,例如使用standard分詞器對一句中文話進行分詞,會分成一個字一個字的,這時可以使用第三方的Analyzer插件,分別是HanLP,IK,Pinyin分詞器三種;
- HanLP-面向生產環境的自然語言處理工具包,支持有多重分詞配置
兩個官網分詞例子測驗效果,分詞效果較內置的分詞有很大明顯,可以支持中文的詞語分詞;


- IK分詞器:
可以根據粒度拆分
ik_smart: 會做最粗粒度的拆分
ik_max_word: 會將文本做最細粒度的拆分
如果是最細粒度,我是中國人,會被分詞為我,是,中國人,中國,國人,相對于Hanlp的分詞更加準確和多樣;
- PinYin
會對特定的資訊進行分詞,對用戶搜索有更好的體驗,該分詞會對漢字的首字母進行分詞,例如劉德華,會被分詞為ldh,張學友,會被分詞為zxy,用戶根據拼音首字母就可以搜索出對應的特定資訊,
(C) 房上的貓 , 保留所有權利, https://www.cnblogs.com/lsy131479/ 如需轉載,請注明出處!!!
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/296413.html
標籤:架構設計
上一篇:Spring系列之多個資料源配置